
Abstract
In this article, we introduce a new command,
Keywords
1 Introduction
A cluster randomized controlled trial (CRT), also known as a group randomized trial, is an experimental study design commonly used, for example, in health, social science, policy, and education research. In CRTs, the unit of randomization consists of a group of individuals. For example, it could be a hospital, geographical area, or school (each constituting a “cluster”), with the clusters, rather than individuals, randomly allocated to different interventions.
Statistical analysis must account for the correlation among individuals within the same cluster, which can be achieved using individual data analysis methods such as generalized linear mixed models, generalized estimating equations, or cluster–robust standard errors with a generalized linear model. Alternatively, it can be achieved by collapsing the data to summary statistics for each cluster, which is known as a clusterlevel analysis or sometimes a cluster-summary analysis. In addition, the number of randomization units (clusters) is often small; a recent review of medical journals found a median of 25 clusters (Kahan et al. 2016) per trial. There is a need for methods that can provide robust inference even with a small number of clusters. This also increases the risk of a chance imbalance in potential confounders between the arms, and adjustment of potential confounders in the analysis becomes important.
Here we introduce a command for cluster-level analysis. Individual-level data are summarized for each cluster, and simple independent data analysis methods can be used on these summaries. The method can be used with continuous, binary, incidencerate, and ordinal outcomes. It has been found to perform well in a range of scenarios, including nonnormality of cluster-level means and with a small number of clusters (Gail et al. 1996; Bennett et al. 2002; Thompson et al. 2022; Ukoumunne, Carlin, and Gulliford 2007).
There are several advantages to this method over individual-level methods. Clusterlevel analysis is known to maintain type-one error with as few as 4 clusters in total, whereas individual-level methods have inflated type-one errors with as many as 40 clusters and require small-sample corrections that have variable success (Leyrat et al. 2018; Thompson et al. 2022). Another advantage is the ease of calculating a risk ratio for a binary outcome when some individual-level methods struggle with convergence (Blizzard and Hosmer 2006). Last, a cluster-level analysis is the only known way to account for a matched-pairs trial design in the analysis of a binary or incidence-rate outcome (Hayes and Moulton 2017).
However, the method is not without limitations. Unweighted cluster-level analysis can be less efficient than an individual-level analysis when cluster size varies and there are many clusters (Thompson et al. 2022). Weighted cluster-level analysis using weighted least squares or a weighted t test has been proposed to improve the method efficiency, but difficulties incorporating uncertainty in the weights generally lead to standard errors that are too small and have inflated type-one errors (Westgate 2013). In addition, adjusting for individual-level covariates becomes more difficult; it requires several steps before the data are summarized by cluster (Bennett et al. 2002).
In this article, we introduce the
2 Statistical methods
In this section, we provide the technical details of this method as proposed by Bennett et al. (2002) and Hayes and Moulton (2017).
2.1 Unadjusted analysis: Calculating intervention effects
We define yijk as the observed outcome of individual k = 1,…, mij in cluster j = 1,…, Ci in arm i = 0, 1 for control and intervention, respectively, where Ci is the number of clusters in arm i and mij is the number of individuals in cluster j in arm i. For example, yijk could be the body mass index (BMI) of student k in school j, receiving a diet program i. For each individual, we define nijk as the person follow-up time of person k in cluster j in arm i for rate outcomes and set nijk = 1 for continuous and binary outcomes.
We begin by calculating a summary statistic of the outcome for each cluster j and arm i as the sum of the observed outcomes divided by the cluster size:
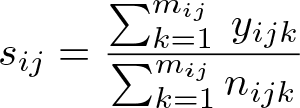
In each cluster, this gives the risk (or proportion or prevalence) for a binary outcome, the incidence rate (number of events per person-time) for a rate outcome, or the mean for a continuous outcome. In our diet program example, sij would correspond to the average BMI observed in school j in arm i.
2.1.1 Absolute effect size: Risk difference, rate difference, and mean difference
The risk, incidence rate, or mean in each arm i can be estimated by the arithmetic mean of the cluster-summary statistics for the clusters in that arm:
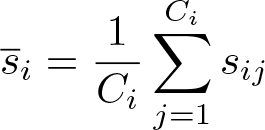
In our diet program example, this would correspond to the mean of the average BMIs across the schools in arm i. Note that each cluster is here given an equal weight.
The unadjusted absolute effect can then be estimated by the difference of these arithmetic means between the intervention and control arm:
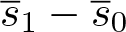
This could be derived arithmetically or, equivalently, using an ordinary least-squares regression. This is the approach used in
The following linear model is fit to the cluster-level summary statistics,
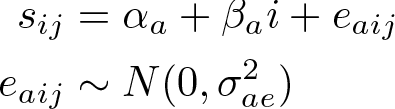
where the a index indicates parameters for the absolute effect model; αa
is the intercept corresponding to the mean of the cluster-level statistics in the control arm,
For risk or rate outcomes, the assumption of normality may be violated, but the method is typically robust to this nonnormality (Bennett et al. 2002).
In our diet program example, αa is the arithmetic mean of the school-mean BMIs in the control arm, and βa is the difference in the mean BMI between the two diet programs.
2.1.2 Relative effect size: Risk ratio and incidence-rate ratio
The risk ratio and incidence-rate ratio are both examples of relative intervention effects. For relative effects, we use the natural logarithms of the cluster summaries. This facilitates calculation and inference of ratio measures as described below. We can estimate the risk or rate in each arm by the geometric mean of the cluster summaries:
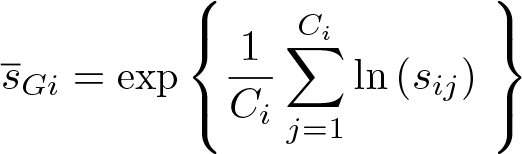
These geometric means are displayed in the output of
The unadjusted risk or incidence-rate ratio can be estimated as the ratio of these geometric means in the intervention and control arms:
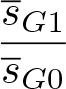
As with the absolute effect, we can estimate this relative effect arithmetically or using ordinary least squares. This time, the linear model is fit to the logarithm of the clustersummary statistics,
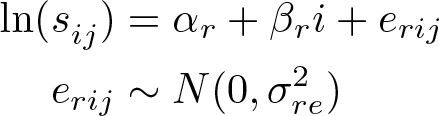
where the r index is used to indicate parameters for the relative effect model; αr
is the intercept corresponding to the logarithm of the geometric mean in the control arm ln
Because we use logarithms in this method, the relative effect size estimator is not defined if any cluster has no events
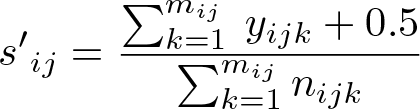
We then substitute s′ij for sij in the calculations above.
2.2 Unadjusted analysis: p-value and confidence interval
We calculate p-values using Wald tests of the ordinary least-squares regression estimate of the intervention effect coefficient with the variance of the coefficient estimate estimated using standard formulas for ordinary least squares.
For an absolute effect, the p-value for the statistical test H
0 :
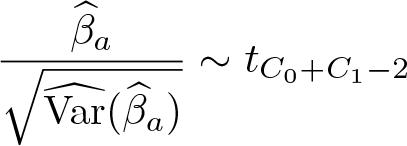
and 95% confidence intervals (CIs) are calculated as
For the relative effect, calculations are similar. The p-value is taken from the t distribution
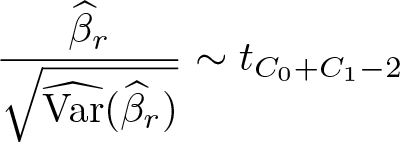
and CIs are calculated as
2.3 Adjusted analysis: Estimating the intervention effect
Adjusting for individual-level covariates is done in a two-stage approach. First, we estimate a cluster-summary residual for each cluster, and second, we analyze these residuals. The process is summarized for each intervention effect measure in table 1.
Summary of steps to calculate each adjusted intervention effect measure

2.3.1 Stage one: Calculating cluster-summary residuals
A. Fit regression of outcome on covariates
In the first stage, we regress the outcome on the adjustment covariates, ignoring clustering and the trial arm. We use a generalized linear model,
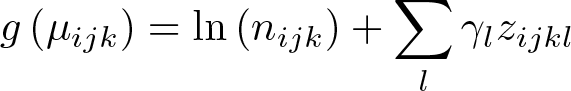
where g is the link function: the logit function for a binary outcome, the logarithm function for a rate outcome, and the identity function for a continuous outcome. µijk is the expected outcome of individual k in cluster j in arm i and is assumed to follow a binomial distribution for a binary outcome, a Poisson distribution for an incidence-rate outcome, and a normal distribution for a continuous outcome. γl is a coefficient for the lth covariate, and zijkl is the value of the lth covariate for individual k in cluster j in arm i. ln(nijk ) is an offset that equals zero for binary and continuous outcomes because nijk = 1 for these outcomes.
B. Predict outcomes
From this regression model, we predict the expected outcome for each individual, µijk . For a binary outcome, this is a predicted probability of the outcome. For a rate outcome, this is the expected number of events in each individual’s follow-up time. For a continuous outcome, this is the expected value of the outcome.
C. Calculate residuals
For each cluster, we then calculate the observed cluster-summary statistics sij (defined in section 2.1) and cluster-summary statistics for expected outcomes, which are defined as
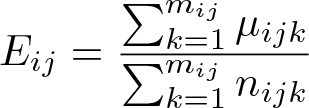
From these, we calculate residuals for each cluster. If we plan to estimate an absolute effect (risk difference, rate difference, mean difference), we calculate a difference residual:
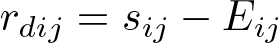
If we plan to estimate a relative effect (risk ratio, rate ratio), we calculate a ratio residual:
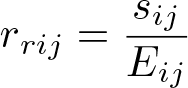
2.3.2 Stage two: Analyze the residuals
These cluster-level residuals become our new unit of comparison between the clusters. Inference is conducted by substituting rdij or rrij for sij in section 2.1.
2.4 Adjusted analysis: p-value and CI
The p-value for the intervention effect is calculated using a Wald test from the second stage regression using the same methods as the unadjusted analysis, with rdij or rrij substituted for sij .
The DF are recalculated to account for adjustment of any cluster-level covariates. This is because the stage-2 regression model is on cluster-level data, and any adjustment for cluster-level variables at stage 1 imposes linear constraints on the cluster-level parameters (while adjustment for individual-level variables does not). We reduce the DF by P, the number of parameters corresponding to these cluster-level covariates in the first-stage regression. The DF are then calculated as
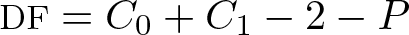
2.5 Accounting for stratified randomization
Stratified randomization can be used to ensure balance of key characteristics between the arms of the trial. Strata are created with similar values of these characteristics, and randomization is implemented ensuring an equal number of clusters in each arm within the strata. Accounting for the stratification in the analysis is recommended because it can greatly improve precision (Hayes and Moulton 2017).
In the
3 The clan command
The syntax of the
3.1 Syntax
depvar is the dependent variable and indepvars are the adjustment covariates.
3.2 Options

3.3 Illustrative examples
We will now illustrate the use of the
3.4 Binary outcome
To demonstrate the use of the
The dataset is described below:

The HIV knowledge outcome in each cluster is summarized in table 2.
Proportion of children with good HIV knowledge in each cluster of the MkV trial

We can estimate the risk ratio between the trial arms using

In the control clusters (
Because the effect measure is a ratio, the risk estimates are based on the geometric means of the cluster-level risks. The test statistic follows a t distribution with 18 DF (the number of clusters minus two).
The output also indicates the number of clusters and the number of observations in each cluster.
Inclusion of the
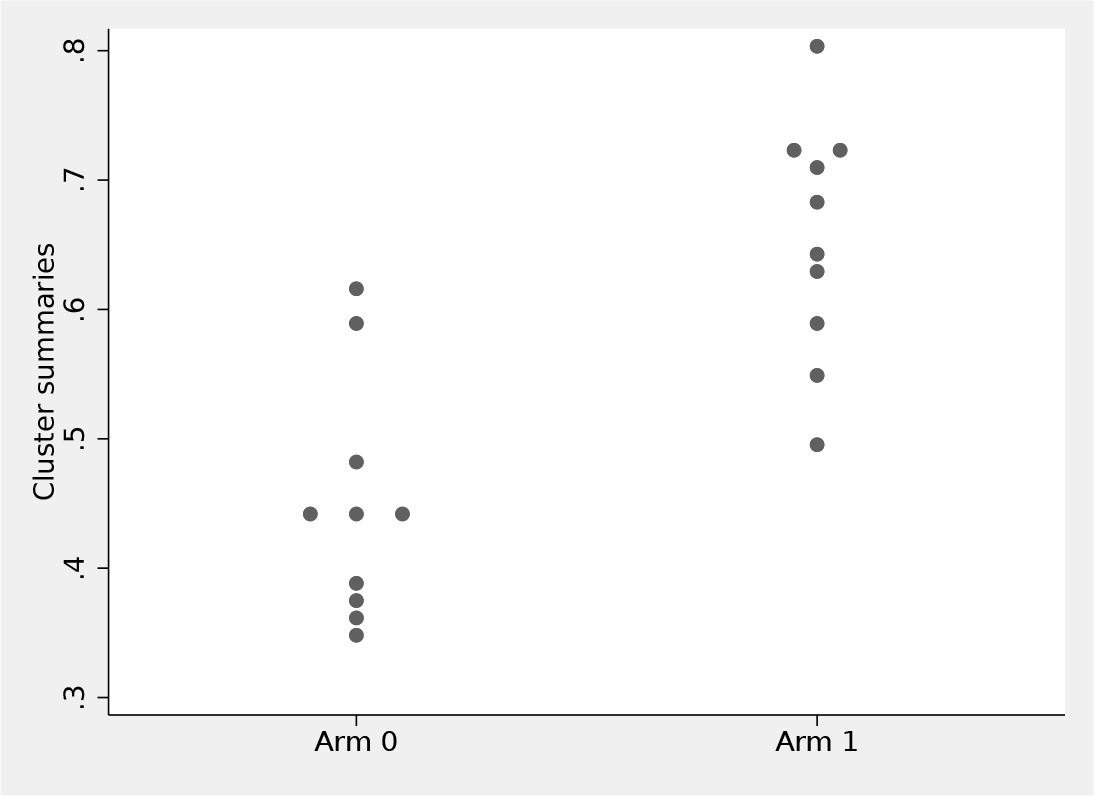
Plot of cluster-level summaries (proportion of good HIV knowledge) by arm
We may wish to adjust for baseline covariates (
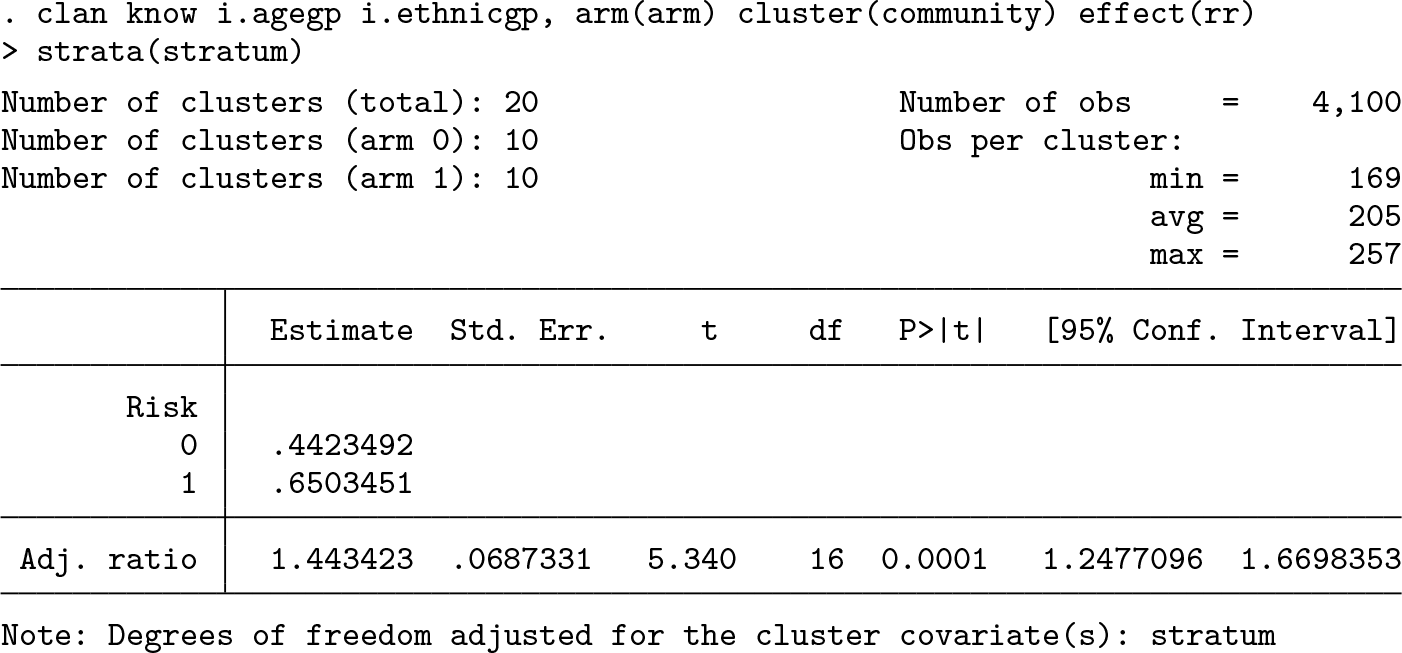
After we adjust for age group, ethnicity and strata, the risk ratio is 1.44 (95% CI: [1.25 to 1.67]). The DF were reduced by two to account for the cluster-level stratum variable, with three categories. Adjusting for individual-level variables (such as age and ethnicity) does not affect the DF.
3.5 Rate outcome
Binka et al. (1996) conducted a CRT to measure the impact of insecticide-impregnated bednets on child mortality in Northern Ghana. The study area was divided into 96 geographical clusters, and 48 were randomly selected to receive impregnated bednets while the remaining 48 acted as controls. A demographic surveillance system was set up to record births, deaths, and migration for two years. The dataset contains data on children aged 6–59 months at the beginning of the trial and shows their person-years of follow-up and whether the child died during follow-up.

The primary trial outcome was all-cause mortality in children. Table 3 summarizes the total number of deaths, person-years of follow-up, and mortality rate for the first six clusters.
Cluster-level mortality rates in the Ghana bednet trial
We can estimate the rate ratio between arms using the
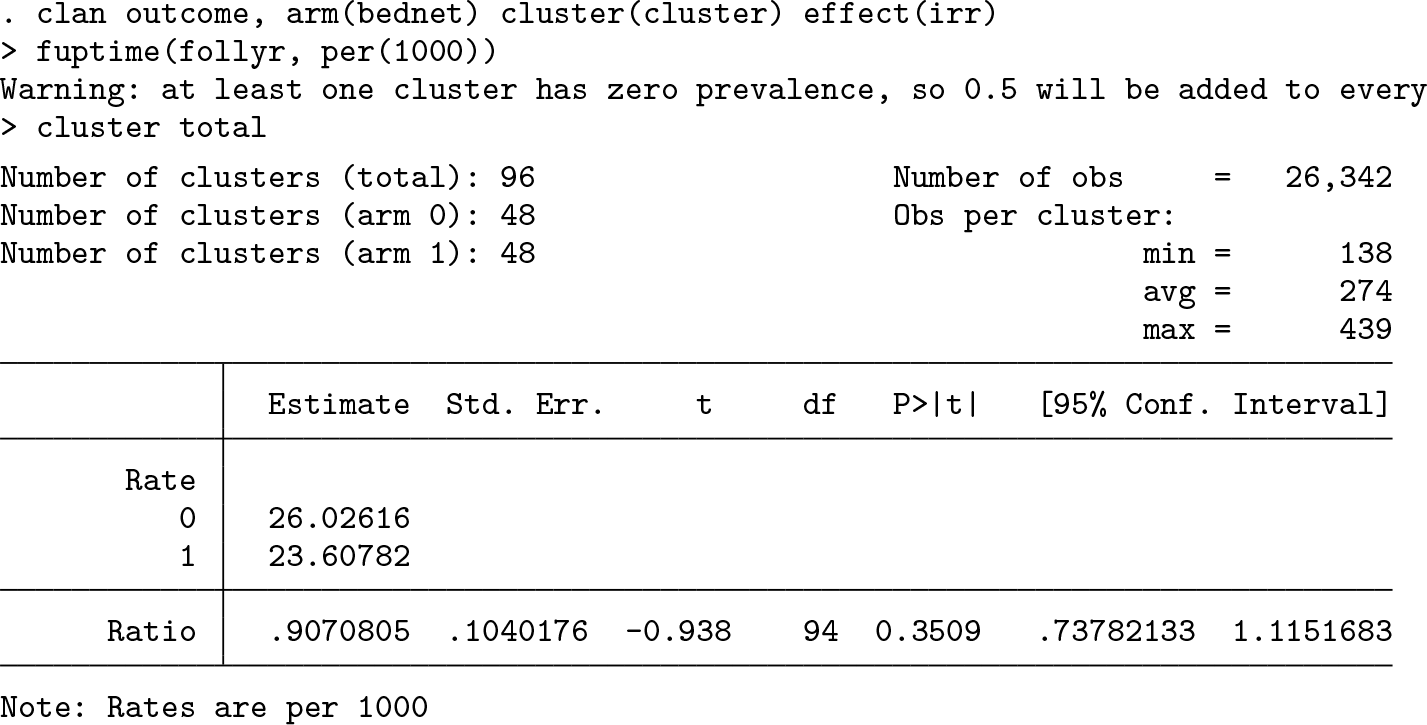
In the control clusters, there was an average of 26.0 deaths for each 1,000 person-years of follow-up, while in the bednet clusters, this rate was around 23.6 per 1,000 personyears. This corresponds to a rate ratio of 0.91 (95% CI: [0.74 to 1.11], p-value=0.35).
A warning message indicates that because one cluster has no events, a 0.5 event was added to each cluster before calculating the log-rate.
3.6 Continuous outcome
The SHARE trial aimed to improve sexual health knowledge through a school-based sexual health program in Scotland (Wight et al. 2002). A total of 25 secondary schools were randomly allocated to the intervention or control arms, and a measure of sexual health knowledge, −8 (poor knowledge) to 8 (good knowledge), was measured through a questionnaire two years later. The analysis was conducted separately for boys and girls, and we focus here on the analysis in the boys.
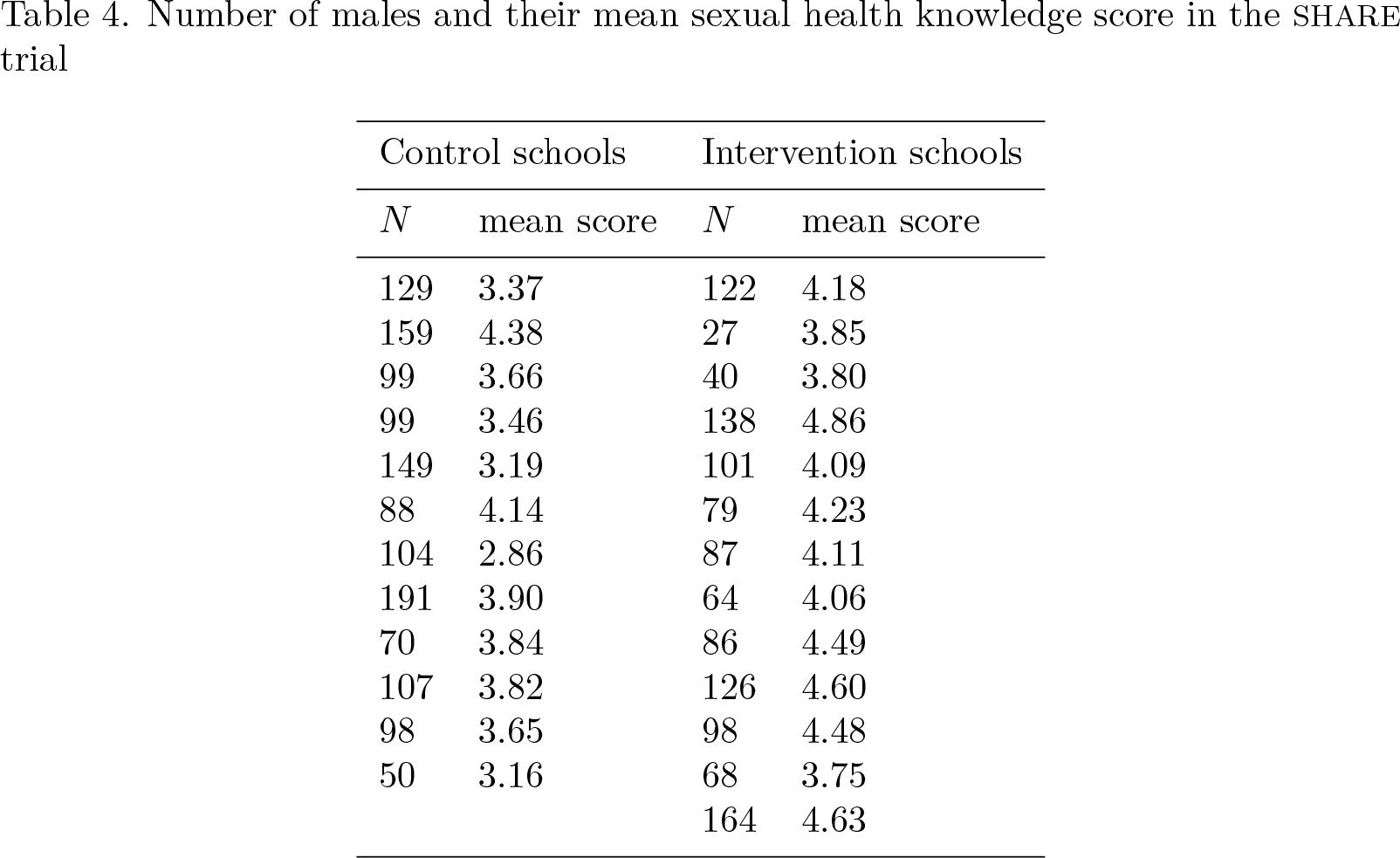
Table 4 shows the number of male respondents and their mean sexual health knowledge score for each of the 25 schools:
Number of males and their mean sexual health knowledge score in the SHARE trial
We can use

The average knowledge score for boys was 3.62 in the control schools compared with 4.24 in the intervention schools.
We can also estimate the mean difference adjusted for
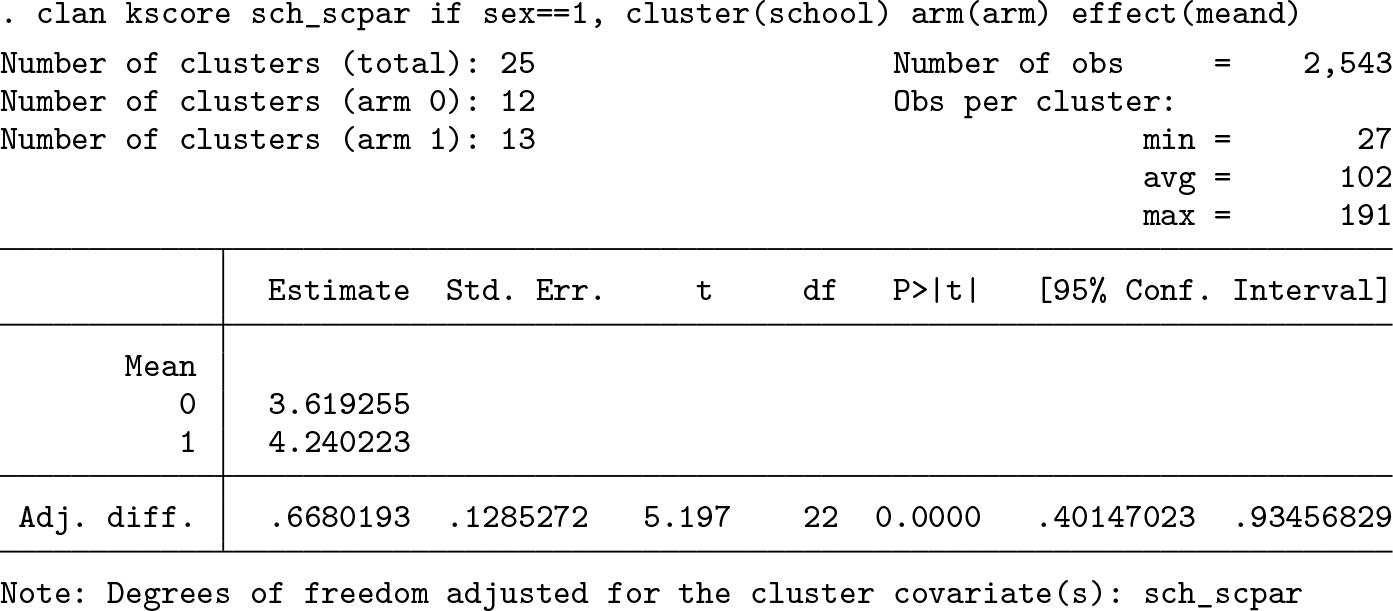
Because social class is a cluster-level variable, 1 degree of freedom was lost. After adjustment, the mean difference in knowledge score between the two arms was 0.67 (95% CI: [0.40 to 0.93], p-value < 0.0001).
3.7 Conclusions
The
There are some general limitations of the cluster-level analysis method and potential for further developments that should be considered when using
While the validity of the cluster-level analysis is well studied for both adjusted and unadjusted analyses (Bennett et al. 2002; Ukoumunne, Carlin, and Gulliford 2007) and unadjusted analyses have been compared with individual-level analysis (Leyrat et al. 2018; Thompson et al. 2022), there is a need for comparisons of the adjusted clusterlevel analysis method to individual-level analysis methods to ascertain the difference in power.
Future developments of the
This command will facilitate the conduct of cluster-level analysis of CRTs and encourage more widespread use of this robust approach.
5 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231196294 - Cluster randomized controlled trial analysis at the cluster level: The clan command
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231196294 for Cluster randomized controlled trial analysis at the cluster level: The clan command by Jennifer A. Thompson, Baptiste Leurent, Stephen Nash, Lawrence H. Moulton and Richard J. Hayes in The Stata Journal
Footnotes
4 Acknowledgments
J. A. Thompson, B. Leurent, S. Nash, and R. J. Hayes are funded by the U.K. Medical Research Council (MRC) and the U.K. Department for International Development (DFID) under the MRC/DFID Concordat agreement and also part of the EDCTP2 programme supported by the European Union (grant ref: MR/R010161/1).
5 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
For the latest version of the
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.