
Abstract
Recently, Eckert and Vach (2020, Biometrical Journal 62: 598–609) pointed out that both confidence and comparison regions are useful tools to visualize uncertainty in a two-dimensional estimate. Both types of regions can be based on inverting Wald tests or likelihood-ratio tests.
Keywords
1 Introduction
1.1 The value of two-dimensional confidence regions
Today, scientists are accustomed to describing the uncertainty of single-parameter estimates with confidence intervals. Even when several parameter estimates are considered simultaneously—for example, when reporting results from multiple regression models— the uncertainty is usually described separately for each single-parameter estimate. This is despite the fact that a methodology for describing uncertainty simultaneously in several parameters is available: confidence regions. The value of using confidence regions is illustrated in figure 1, depicting the joint uncertainty in two regression coefficient estimates from a multiple regression analysis. First, the confidence region is a gentle reminder that the two covariates—grip strength and age—are positively correlated, and consequently the two regression coefficient estimates are negatively correlated. When interpreting the magnitude of the two estimates, one should consider that an overestimation of one parameter probably implies an underestimation in the other. Second, it is immediately apparent that the point (0, 0) is outside the confidence region, which means that the null hypotheses of no effect of both covariates can be rejected. This can be highly relevant if both regression parameters are not significantly different from 0. In this case, the confidence region is a gentle reminder that this should not be misinterpreted as absence of any association between the outcome and these two covariates.

A 95% confidence region for two regression coefficients
Despite this rather obvious value of two-dimensional confidence regions in specific situations, they are rarely used in scientific publications, probably because of the lack of appropriate software for visualization. Indeed, when one uses the Wald test principle to construct two-dimensional confidence regions, visualization requires drawing an ellipsoid. This is usually not supported in standard statistical software packages. When one uses the likelihood-ratio (LR) test principle for construction, a fixed-point problem must be solved numerically for many directions in the two-dimensional space, as recently pointed out by Jaeger (2016). One aim of
1.2 The need for comparison regions
Formally, confidence regions allow the post hoc testing of null hypotheses that fix the parameter at a certain value. For such a value
In some statistical applications, such hypotheses on single specific point values are of minor interest. Instead, the interest is in demonstrating that the two parameters of interest are within a certain region R, for example, that their average is above a certain threshold. (Concrete examples are given in the following subsection.) Thus, the interest is in testing the null hypothesis H
0 :
However, this test approach is very conservative, and the actual level of the test is much lower than α. To address this issue, Eckert and Vach (2020) introduced the concept of a comparison region. A level-α comparison region is a data-dependent region C ⊆ ℝ2 with the following property:
Consequently, a comparison region can be used for post hoc testing of the null hypothesis of interest. The logic of the approach is illustrated in figure 2. Comparison regions can be constructed very similarly to confidence regions. Consequently,
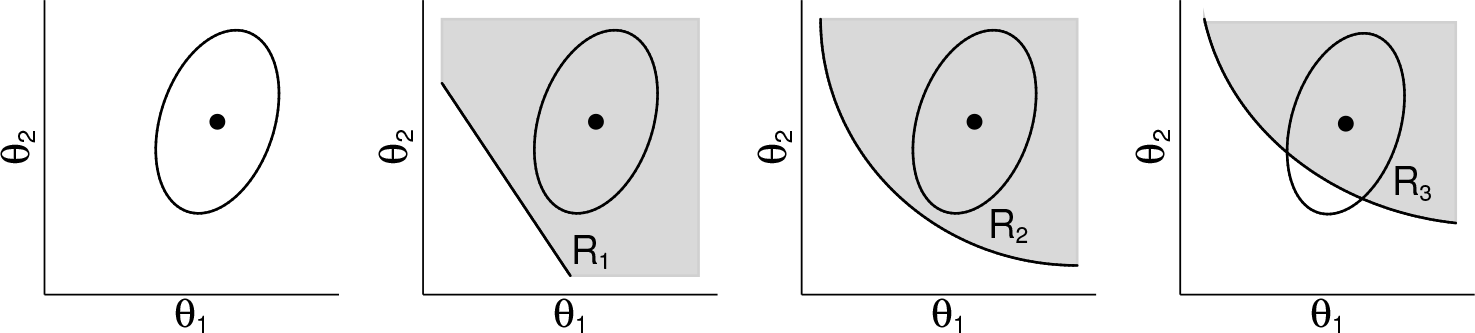
Presentation of a point estimate with a comparison region in a publication and three post hoc comparisons with regions of interest: The null hypotheses H
0 :
1.3 Motivating examples
1.3.1 Diagnostic accuracy studies
Diagnostic accuracy is a genuine two-dimensional concept. By sharpening the criteria of a diagnostic test, one can reduce the number of false-positive (FP) decisions, but the number of true-positive (TP) decisions decreases, too. Consequently, the standard approach to analyzing the diagnostic accuracy of one test is to consider a pair of parameters such as sensitivity and specificity, positive and negative predictive values, the relative frequency of TP and FP decisions, or the positive and negative LRs. When one analyzes screening tests, it might also be of interest to relate sensitivity to the rate of positive test results because the aim is to achieve a high sensitivity while keeping the number of subjects to be followed up with as low as possible. When one compares two diagnostic tests, the focus is typically on the change in such a pair of parameter values.
There is no universal answer to the question of how to combine the two parameter estimates when a final decision about the usefulness of the test (or the new test in a comparative study) must be made (compare Vach, Gerke, and Hœilund-Carlsen [2012]). When one considers sensitivity and specificity, one is often advised to think about which parameter is more important in the specific clinical context. It is a rather straightforward idea to consider a weighted average of sensitivity and specificity. In practice, however, it seems cumbersome to agree on specific weights. The use of a range of weights has been considered with respect to analyzing sensitivity and specificity (Newcombe 2001) as well as when considering the rate of TP and FP decisions, particularly as part of a decision curve approach (Vickers 2008).
When different stakeholders post hoc perform analyses of a diagnostic accuracy study, each stakeholder may specify different weights and thresholds. Each stakeholder is interested in demonstrating that w
1.3.2 Balancing between favorable and unfavorable consequences of an intervention
In evaluating a new intervention, one must often judge the balance between favorable and unfavorable consequences. Cost-effectiveness analyses are a classical example. Today, they are standard tools in health technology assessments and play important roles in deciding whether the additional costs can be justified by a gain in effectiveness or whether cost savings are so substantial that they can justify some loss in effectiveness. Similarly, there may be a need to balance the benefit and the risk associated with an intervention, and in benefit–risk assessments, it is common to consider a benefit–risk plane similar to a cost-effectiveness plane (Guo et al. 2010; Mt-Isa et al. 2014). Considering a two-dimensional approach can be particularly helpful to overcome some obstacles with noninferiority trials (Gladstone and Vach 2015).
In these types of analyses, because the parameters of interest are measured on differing scales, it is common to consider the ratio
1.4 Construction of confidence regions and comparison regions
1.4.1 A general construction principle for comparison regions
Eckert and Vach (2020) describe the following general construction principle for a comparison region:
Lemma 1: Let φH denote a family of level-α tests for all half spaces H ⊂ Θ, that is, all subsets of the two-dimensional parameter space Θ of the type {(

defines a level-α comparison region. Here
Roughly speaking, C can be interpreted as the intersection of all regions of interest that were “confirmed” by the tests. This general principle can be applied using the family of Wald tests or the family of LR tests. In both cases, the construction of comparison regions turns out to be very similar to the construction of confidence regions.
1.4.2 Explicit formulas for confidence regions and comparison regions
Given an estimate of the covariance matrix

The only difference is the choice of the threshold c.
Using (asymptotic) LR tests as construction principles results in confidence and comparison regions of the type
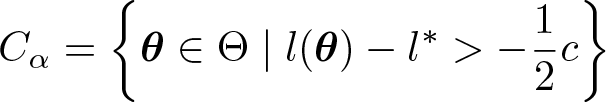
with l∗ denoting the value of the loglikehood function l(θ) at the maximum likelihood estimate. Again, the only difference is the choice of the threshold c.
Note that, for both approaches, it does hold that 74.2% confidence regions define 5% comparison regions. Consequently, 5% comparison regions are distinctly smaller than 95% confidence regions.
2 The confcomptwo command
2.1 The scope of confcomptwo
The command
Eckert and Vach (2020) considered the case of a two-parameter likelihood, but the approach can also be applied to a two-parameter profile likelihood obtained by maximizing a higher-dimensional likelihood over the remaining nuisance parameters. Hence,
Actually,
2.2 The syntax of confcomptwo
The syntax of
If you intend to use
and the program expects to find entries with the column names parname1 and parname2 in the vector
The immediate form has the syntax
with #1 and #2 denoting the values of the two parameter estimates. The standard errors are provided using the required
If you intend to use the LR test principle, the syntax is given by
and the expr in the required
In addition, any twoway_options affecting the entire graph can be used except those involving a variable (such as the
If you are using the LR principle, you can also specify some linesearch_options, which are explained in section 4.3.
The
This indicates that the line is drawn by
2.3 Stored results
2.4 Auxiliary commands to compute a log likelihood
To support the use of the LR principle, we provide the following three commands to compute the (profile) log likelihood for some standard situations that particularly appear in the context of analyzing diagnostic accuracy studies. All commands consider an open subset of R2 as parameter space.
computes the log likelihood for a binary outcome variable with success probabilities differing between two subgroups. The log likelihood is evaluated for the two probabilities #1 and #2, referring to the two subgroups that must be labeled with the values 1 and 2. The following two options are required:
computes the profile log likelihood for a categorical variable. The log likelihood is evaluated for the two probabilities #1 and #2, referring to the probabilities of two categories. The probabilities of the other categories remain unspecified. The following two options are required:
computes the profile log likelihood for two binary variables observed in two subgroups evaluated at two values #1 and #2, referring to the difference in the proportions between the two variables within subgroup 1 and within subgroup 2, respectively. The difference can be expressed as a difference, a log relative-risk, a log odds-ratio, a relative risk, or an odds ratio. The subgroups must be labeled with the values 1 and 2. The following options are required:
NOTE: For relative risks and odds ratios, it typically makes little sense to consider weighted averages. However, confidence and comparison regions still provide a visual impression about the imprecision of the estimates.
All three commands also allow a
3 Examples
3.1 Example 1: Joint confidence region for two regression coefficients
Stata provides


A 95% confidence region for the two regression coefficients considered in example 1.
The resulting figure 3 informs us that the two regression coefficients are positively correlated. This is a simple consequence of the negative correlation between the two covariates: on average, foreign automobiles have lower weights than domestic automobiles.
Note that the parameter rescale was used in this example. This was necessary because the two estimates have very different magnitudes. The value 1,666 reflects the ratio between the span on the x axis (5) and the span on the y axis (0.003). Here we also followed the tradition of drawing confidence regions with solid lines.
3.2 Example 2: Analysis of a single-arm diagnostic accuracy study
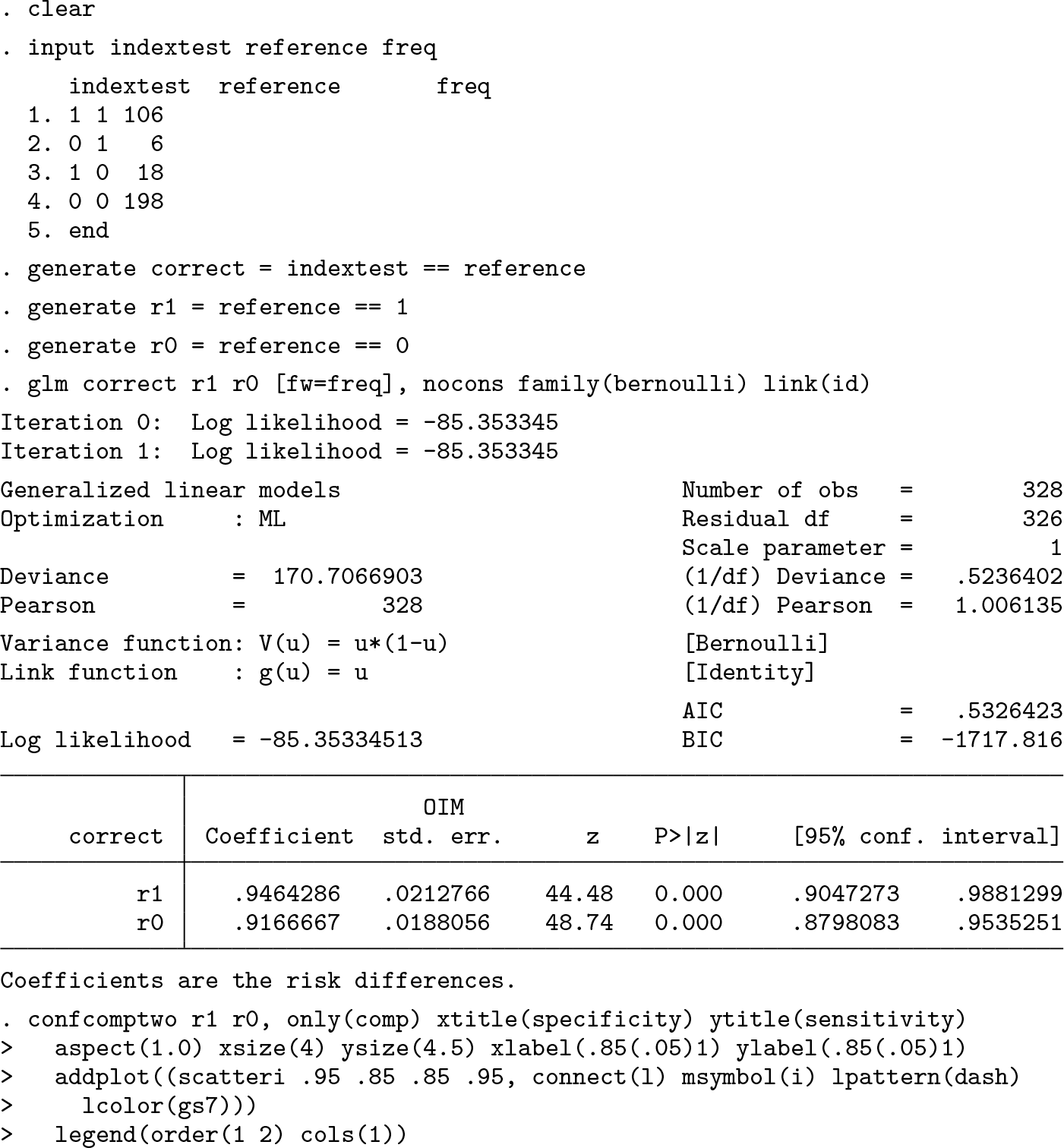
Xu et al. (2017) presented a study on the diagnosis of hemodynamically significant coronary stenosis defined by fractional flow reserve ≤ 0.80. One goal was to assess the diagnostic accuracy of angiography-based quantitative flow ratio measurements using the same cutpoint. Using fractional flow reserve as the reference standard, they observed a sensitivity of 106/112 = 94.6% and a specificity of 198/216 = 91.7% based on overall 328 interrogated vessels.
Computing the standard errors of sensitivity and specificity manually, we can use the immediate version of

To facilitate the interpretation of the comparison region, we can add a reference line referring to an average of sensitivity and specificity of 0.9 to mimic a specific posttest situation:


Wald-test-based 5% comparison region for sensitivity and specificity in example 2 with a reference line added
The resulting figure 4 allows the comparison of the reference line with the comparison region. The line is located below the comparison region. This supports the conclusion that the average between sensitivity and specificity is above 0.9.
In the computations carried out above, we have taken advantage of the fact that sensitivity and specificity are based on two separate samples, and we therefore know that they are uncorrelated when conditioning on the observed sample sizes. If manual computation of standard errors is to be avoided, we can use the postestimation version of
To obtain LR-test-based regions, we use the


LR-test-based 5% comparison regions for sensitivity and specificity in example 2 with three reference lines added
The resulting figure 5 indicates that the shape of the LR-test-based region is distinctly different from the shape of the Wald-test-based region. This can be explained by the proximities of sensitivity and specificity to 1.0. Two further reference lines were added to the figure, giving the sensitivity twice the weight of specificity and vice versa. For all three choices of weights, one can conclude that the weighted average of sensitivity and specificity is above 0.9.
3.3 Example 3: Analysis of a paired diagnostic accuracy study
Ng et al. (2008) reported a study comparing the diagnostic accuracy of 18F-fluoro-2-deoxyglucose positron emission tomography with extended-field multidetector computed tomography for the detection of distant malignancies in patients with oropharyngeal or hypopharyngeal squamous cell carcinoma. All patients were followed up with for at least 12 months or until death to construct a reference standard. For a suspected malignant lesion, a biopsy of the tissue was taken if possible or close clinical and imaging followup was performed. Distant malignancies were found in 26 out of 160 patients enrolled in the study. The two diagnostic tools investigated yielded a sensitivity/specificity of 50.0%/97.8% and of 76.9%/94.0%. The study was conducted in a paired design, so the results can be summarized in a 2 × 2 × 2 contingency table with the frequencies for each combination of results for the two index tests to be compared and the reference standard. This contingency table is available in

In a first analysis, the interest is in studying the changes in sensitivity and specificity when replacing test 1 with test 2. Because there are no simple formulas to compute the standard errors of the change, we use the postestimation version of



Wald-test-based 5% comparison and 95% confidence regions for the changes in sensitivity and specificity in example 3 with three reference lines added
The resulting figure 6 indicates a distinct improvement in sensitivity and a slight deterioration in specificity. Because of the low prevalence of the disease state of interest, the precision of the estimate of the change in sensitivity is rather low. We included three lines in the graph referring to the situation where some weighted averages of the changes in sensitivity and specificity are equal to zero. The dotted line refers to equal weights, and we can conclude that the increase in sensitivity is larger than the loss in specificity. However, because the sensitivity of the standard test is rather low and the specificity is already rather high, we are actually interested in a substantial improvement in sensitivity. The line with short dashes refers to giving the change in sensitivity a weight 1.5 times higher than the weight given to the change in specificity, and the line with long dashes refers to weighting the change in sensitivity two times higher than the change in specificity. In all three cases, the line does not hit the comparison region. Consequently, we can conclude that the gain in sensitivity is at least twice as great as the loss in specificity.
Note the use of the
To obtain LR-test-based regions, we store the two estimates, and then we use the

The resulting figure is not shown, because it is nearly identical to the one obtained using the Wald test.
Next we present a second analysis considering the change in the relative frequency of TP and FP decisions. Wald-test-based comparison and confidence regions can be approached similarly to above, starting with the empirical estimates of the four relative frequencies expressed as estimates from an intercept-only generalized linear model:

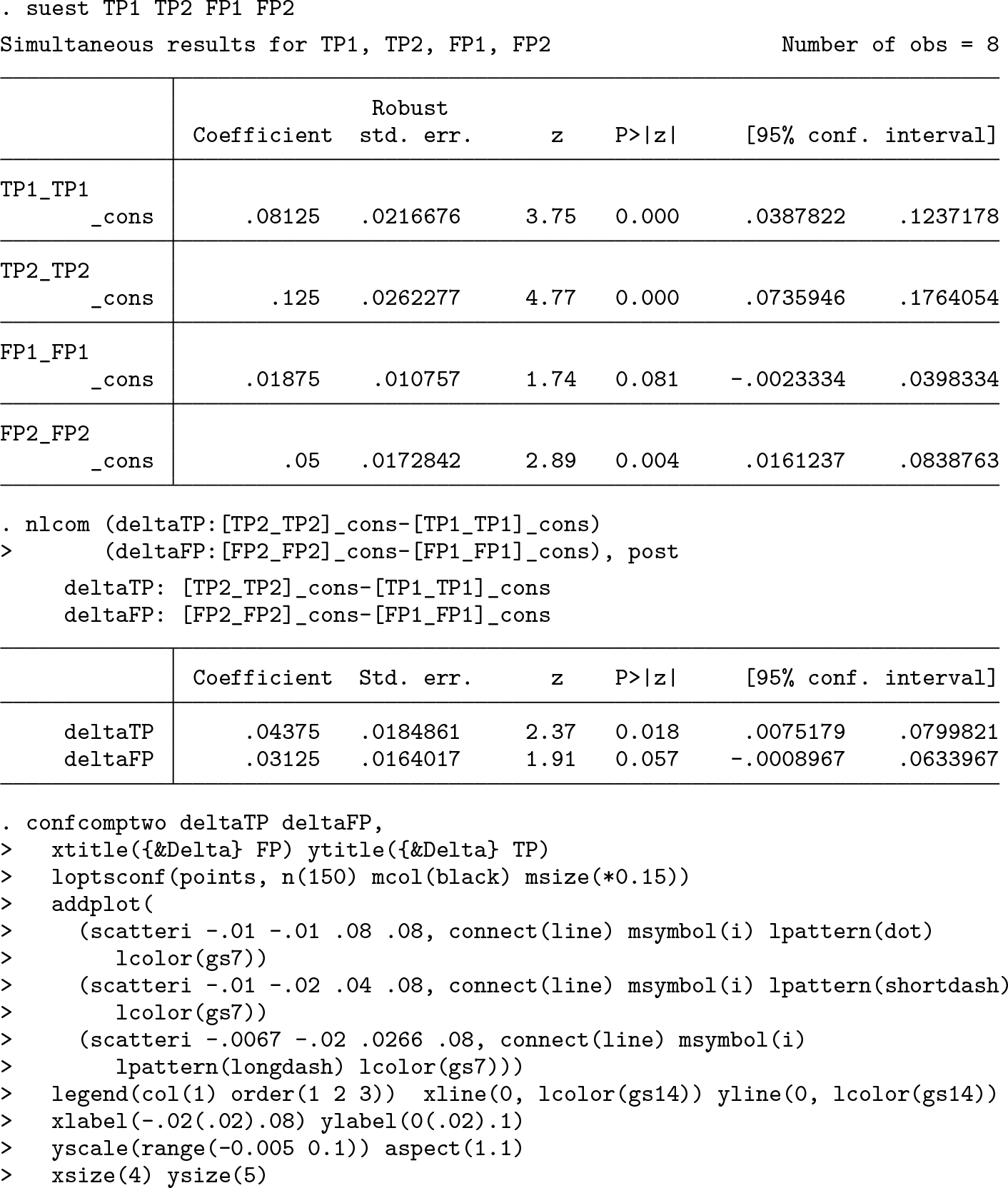

Wald-test-based 5% comparison and 95% confidence regions for the change in the relative frequency of TP and FP decisions in example 3 with three reference lines added
In the resulting figure 7, we observe an increase in the frequency of TP decisions by 4.4%, which is about a factor 1.5 higher than the increase in FP decisions. This looks less impressive than the changes in sensitivity and specificity, which are due to the low prevalence of the disease state of interest in this example. Different stakeholders may have different views on how many additional FP decisions they may accept for one additional TP decision. If they maximally accept only one FP, they are interested in demonstrating that the difference between the TP rate and the FP rate is above 0, that is, in points above the dotted line referring to the weights 1 and −1 for the TP rate and the FP rate, respectively. If they are willing to accept two FP decisions for a gain in one TP decision, they are interested in points above the line with short dashes referring to the weights 1 and −2 for the TP rate and the FP rate, respectively. If they are willing to accept three FP decisions for a gain in one TP decision, they are interested in points above the line with long dashes, which refers to the weights 1 and −3 for the TP rate and the FP rate, respectively. We can observe that they can conclude that the new test implies an advantage only in the last case.
To use the LR approach, we must write a specific program to evaluate the log likelihood. We will present this in section 5 after we have taken a closer look at the formulas used by
3.4 Example 4: Joint evaluation of benefit and risk in a randomized controlled trial
Saxer et al. (2018) reported the results of a randomized controlled trial comparing two surgical techniques to be used to treat femoral neck fractures in patients over 60 years of age requiring hemiarthroplasty. The aim was to demonstrate that an anterior minimally invasive approach is beneficial to patients in terms of accelerated remobilization compared with a standard lateral Hardinge approach. The primary endpoint was early mobility evaluated at three weeks via the “timed up and go” (TUG) test. This test measures the time needed to get up from a chair, to walk a distance of three meters, and to sit down again. A 20% reduction was regarded as clinically relevant. Various secondary endpoints were considered. We focus here on the endpoint occurrence of local infections, reflecting a potential safety concern about the minimally invasive approach.
The study analyzed the primary endpoint by applying a regression model with the covariates treatment arm, age, and functional independence measure at baseline to the log-transformed TUG values. The back-transformed treatment effect was interpreted as an estimate of the median reduction in time required for the TUG. This resulted in an effect estimate corresponding to a 21.5% reduction. The frequency for local infections was 5 out of 96 in the lateral Hardinge arm and 7 out of 79 in the anterior minimally invasive arm, corresponding to an increase of 3.6 infections in 100 patients.



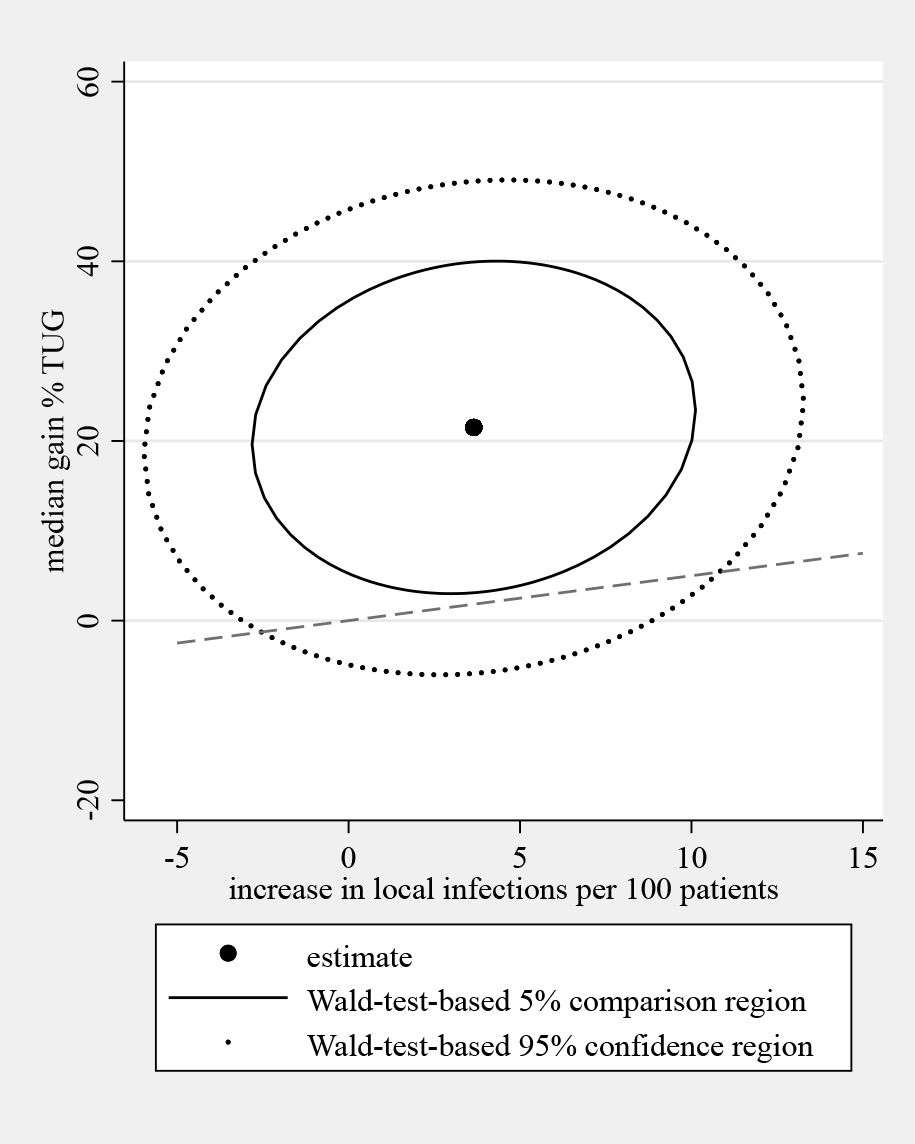
Wald-test-based 5% comparison and 95% confidence regions for the gain in TUG and the increase in number of local infections in example 4
The resulting figure 8 indicates that it is hard to draw firm conclusions because of the substantial imprecision of the estimates. Only if we would regard a very small gain in TUG time as justification for an increase by 1 local infection in 100 patients could we conclude that the true parameter values are above this line. To illustrate this, we show a reference line referring to a ratio between the gain in TUG and the number of additional local infections per 100 patients of 0.5. For 10 additional local infections, this would imply a 5% gain in TUG.
3.5 Example 5: LR-test-based regions for an estimate on the boundary
If the parameter space of a two-dimensional parameter estimation problem is bounded, it is possible for the point estimate to be on the boundary. LR-test-based comparison and confidence regions are then still defined, but drawing is slightly more complicated. However, if we restrict the drawing to directions into the inner part of the parameter space, it is still possible to draw regions. This is illustrated by an artificial example from a single-arm diagnostic study with a sensitivity estimate of 1.0, which results in figure 9:


LR-test-based 5% comparison region for sensitivity and specificity in example 5
Note that it was necessary to use the
4 Methods and formulas
4.1 Parameterization of directions
The following two subsections describe how to determine the point on the boundary of a comparison or confidence region when looking from the point estimate in a certain direction ξ ∊ ℝ2\(0, 0). A first, straightforward choice for the directions may be ξt = (cos t, sin t)′ with values t from the grid tj = {(j − 1)/(J − 1)}2π for j = 1,…, J with J denoting the overall number of directions considered. This implies that all angles between two neighboring directions are equal, and this is indeed also the default choice in
If the units of the axes in the plot plane roughly correspond to the same physical length and the shape of the regions is close to a circle, the default value of J = 101 is typically large enough to ensure that the boundary lines of the comparison and confidence regions appear as smooth lines when plotting the calculated points in a graph and connecting them with straight lines.
4.2 Drawing comparison and confidence regions based on the Wald test principle
Given a direction ξ ∊ ℝ2\(0, 0), the point on the boundary of Cα in this direction (starting at

(When
When we use the Wald test principle to construct (1 − α) confidence regions for

4.3 Drawing comparison and confidence regions based on the LR test principle
Given a direction

for γ > 0. Because γ ↦ l(
The same approach has been recently recommended by Jaeger (2016) for plotting LR-test-based confidence regions. This requires just the replacement of
The line search is conducted as follows. Let el(γ) := l(
For the first grid value t, γ
0 is specified by the
When the call to the program provided by the user results in an error code different from 0 or the log likelihood evaluates to a missing value, no point is plotted in the corresponding direction, and a warning message is shown.
The validity of the comparison and confidence regions drawn depends heavily on the correct specification of the values of the maximum likelihood (ML) estimate. Hence,
4.4 The llproptwosamples command
The
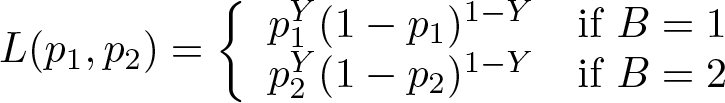
The command computes the sum of logL(p 1, p 2) over all observations.
4.5 The llproptwocats command
The

The command computes the sum of logL(p 1, p 2) over all observations.
4.6 The llriskcomptwosamples command
The implementation of the

With B denoting the grouping variable, the profile log likelihood is then obtained by maximizing for b = 1, 2

under the constraints on p 1 b and p 2 b specified when calling the command and then summing up the two values.
The maximization task is approached using Stata’s

Consequently, the profile log likelihood is obtained by maximizing

with

over ρ 1′, ρ 2′, α 1, and α 2.
Note that the profile likelihood can be interpreted as a conditional likelihood given the frequencies of B = 1 and B = 2 as well as an unconditional likelihood because, in the latter case, the additional contribution depending on the prevalence π does not affect the maximization task.
5 An example involving a user-defined program to compute the profile log likelihood
To continue with example 3 in section 3.3, we need an appropriate parameterization of the joint distribution of Y
1, Y
2, and D. We use the fact that the change in relative frequency of TP decisions ΔTP can be related to the change in sensitivity Δsens and the prevalence π, and the change in relative frequency of FP decisions ΔFP can be related to the change in specificity Δspec and the prevalence. To be precise, we have Δsens = ΔTP/π and Δspec = −ΔFP/(1 − π). We now use the framework developed for the

The profile log likelihood for given values of ΔTP and ΔFP is then obtained by maximization over
To apply the LR approach, we must provide a program to compute the profile loglikelihood function. We start with defining the program



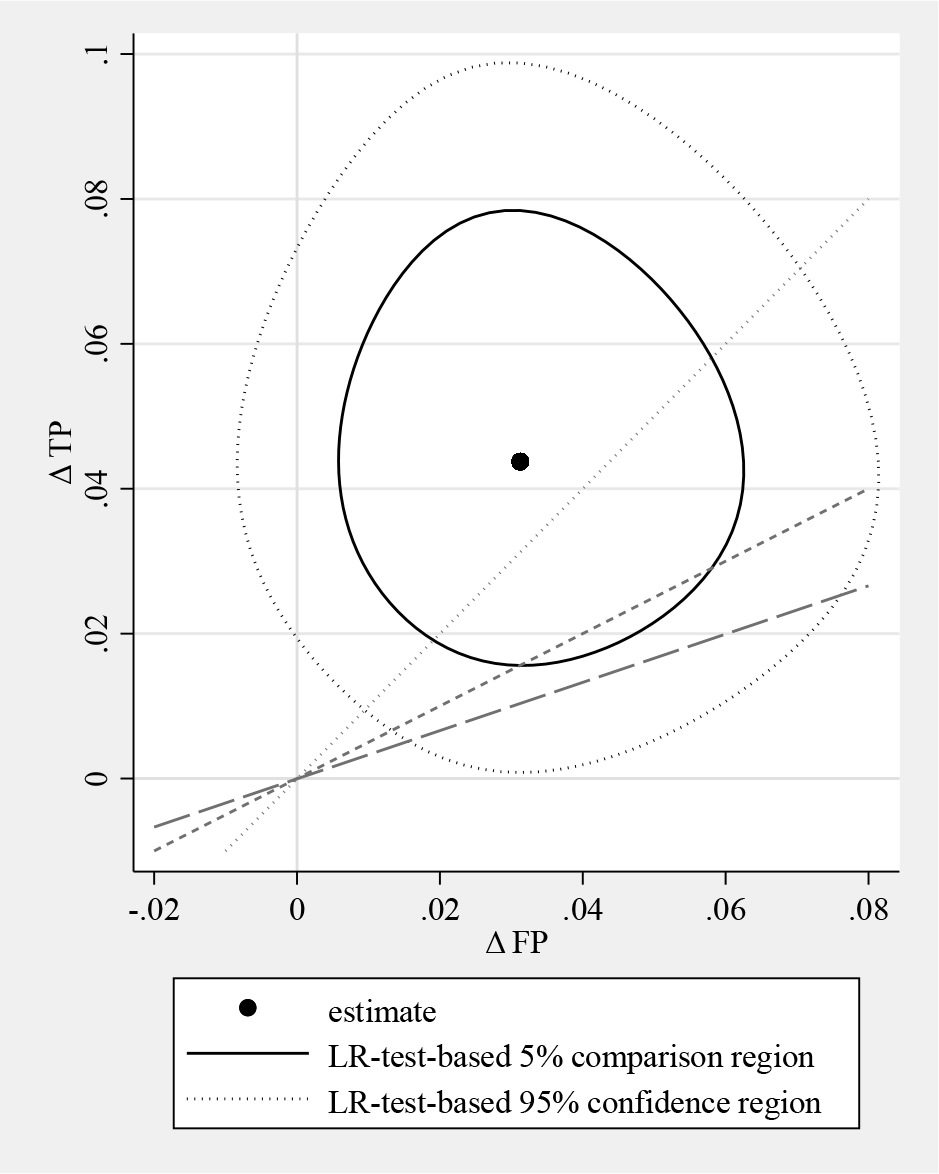
LR-test-based 5% comparison and 95% confidence regions for the change in the relative frequency of FP and TP decisions in example 3
In the resulting figure 10, we can observe that the shape of the regions based on the LR test principle deviates distinctly from the elliptic shape of the Wald-test-based regions. However, the conclusions remain the same.
6 Conclusions
In some areas of statistical applications (such as diagnostic accuracy studies), it is essential to present a joint evaluation of two parameter estimates. Two-dimensional confidence and comparison regions are useful tools supporting this goal. Drawing such regions is quite challenging and not easily accomplished within the existing graphical tools in Stata. Therefore, the
The examples presented in this article indicate that Wald-test-based and LR-test-based comparison regions may substantially differ in their shape. First investigations of finite-sample properties (Eckert and Vach 2020) suggest that LR-test-based comparison regions are closer to their nominal level than Wald-test-based comparison regions. Therefore, we recommend using LR-test-based comparison regions. However, LR-test-based comparison regions also rely on inverting tests that are only asymptotically valid. In the long run, the use of exact methods might be desirable.
The optimal choice of directions for drawing the boundary points of the regions is a nontrivial problem.
It can be seen as a disadvantage of
8 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231175314 - Visualizing uncertainty in a two-dimensional estimate using confidence and comparison regions
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231175314 for Visualizing uncertainty in a two-dimensional estimate using confidence and comparison regions by Maren Eckert and Werner Vach in The Stata Journal
Footnotes
7 Acknowledgment
This work was supported by the German Research Foundation (DFG) [VA 88/5-1].
8 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.