
Abstract
Recently, a new statistical methodology to assess the bias and precision of a new measurement method, which circumvents the deficiencies of the Bland and Altman (1986, Lancet 327: 307–310) limits of agreement method, was developed by Taffé (2018, Statistical Methods in Medical Research 27: 1650–1660). Later, the methodology was extended to assess the agreement. In addition, to allow for inferences, simultaneous confidence bands around the bias, precision, and agreement lines were developed (Taffé, 2020, Statistical Methods in Medical Research 29: 778–796). The goal of this article is to introduce the extended
Keywords
1 Introduction
In clinical research, Bland and Altman’s limits of agreement (LoA) method is frequently used to assess the agreement or interchangeability between two measurement methods, when the characteristic of interest is continuous (Altman and Bland 1983; Bland and Altman 1986). Often, this is motivated by a new, perhaps less expensive or easier, method of measurement against an established reference standard. To evaluate the comparability of the methods, the investigator collects measurements, perhaps one or several, from each method for a set of subjects. Bland and Altman’s LoA are then computed by adding and subtracting 1.96 times the estimated standard deviation (SD) from the mean differences. A scatterplot of the differences versus the means of the two variables with the LoA superimposed is used to visually appraise the degree of agreement and quantify the magnitude. Further, a regression of the differences as a function of the means is added to the plot to indicate whether there is a bias and the direction of that bias (Bland and Altman 1999).
Bland and Altman’s plot may be misleading, however, in situations where the variances of the measurement error for each method differ from one another. When this is the case, the regression line may show an upward or downward trend when there is no bias or a zero slope when there is a bias (Carstensen 2010; Taffé 2018).
Recently, a new statistical methodology to assess the bias and precision of a new measurement method, which circumvents the deficiencies of the Bland and Altman’s LoA method, was developed (Taffé 2018). Later, that methodology was extended to include the assessment of the agreement, and the inference was developed to build simultaneous confidence bands (CBs) around the bias, precision, and agreement lines (Taffé 2020).
In this article, we will present the implementation of the extended methods proposed by Taffé (2020). A series of new graphs will be introduced to help the investigator assess bias, precision, and agreement between the different measurement methods. The methodology requires repeated measurements on each individual for at least one of the two measurement methods (otherwise, one cannot identify the differential and proportional biases). It was originally developed based on repeated measurements from the reference standard, but it has been extended to the setting where repeated measurements come from the new measurement method (however, this option has not been implemented in the current command and has to be done manually). This is a great advantage because it may sometimes be more feasible to gather repeated measurements with the new measurement method.
The extended
2 The measurement error model
2.1 Formulation and estimation of the model
Following Taffé (2018), we define the relationship between the true latent trait, xij , and the measured outcomes, y 1 ij (by method 1) and y 2 ij (by method 2), on individual i at measurement j, by
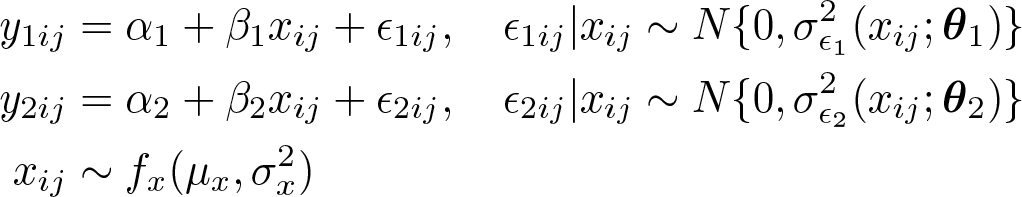
where ϵ 1 ij and ϵ 2 ij are the measurement errors by methods 1 and 2 and fx is the density of the true unknown trait. The parameters α 1 and α 2 measure the differential bias, whereas β 1 and β 2 the proportional bias. This formulation makes it clear that neither method 1 nor method 2 needs to be unbiased. The goal is to compare the two measurement methods and assess the bias of one of the two versus the other (which will be called the “reference method” whether genuinely unbiased or not).
For the sake of clarity, we now consider method 2 to be the reference standard and method 1 the new method to be evaluated. We also assume that the individual latent trait is constant within individual i; that is, xij ≡ xi , although this assumption could be relaxed (Taffé 2018). Therefore, the model reduces to

and α
1 measures the differential and β
1 the proportional bias relative to measurement method 2. We assume that there are replicate measurements j = 1,…, ni
on each individual i, i = 1,…, N, by at least one of the two measurement methods and that the variances

Actually, the form of the heterogeneity need not be a straight line, and a fractional polynomial may be used instead if the investigator believes that the straight-line model is too restrictive. The presence of the square root term
Taffé (2018) has developed a two-step procedure to estimate the parameters of (2) and (2), which does not rely on the density of the true unknown trait, fx . Simulations have shown that this two-step approach works well to estimate the differential and proportional biases, even with as few as three to five repeated measurements by one of the two methods and only one by the other.
When the repeated measurements are available for method 1 instead of method 2 (the reference), the two-step procedure operates the same way as in Taffé (2018), except that the role of y
2
ij
is taken by y
1
ij
and computation of the differential and proportional biases is modified accordingly. That is, in this case, the user proceeds by first fitting a regression model for y
1
ij
by marginal maximum likelihood. Then, the mean of the conditional distribution of xi
given the vector
When repeated measurements are available for both measurement methods, the user may start in the two-step procedure by fitting a regression model for either y 2 ij or y 1 ij . The estimates of the differential and proportional biases will be similar (but not the same). Our experience, along with limited simulations, suggests that it is advantageous to use the method having on average more repeated measurements as the reference (confidence intervals [CIs] are slightly narrower).
The (total) bias

where
2.2 Inference
Taffé (2020) developed a new methodology to allow the computation of simultaneous CBs around the bias (3) and each of the two SD (2) lines. The simultaneous CB approach guarantees a proper coverage rate for the simultaneous inference, whatever the number of points from the support considered. It therefore allows proper inference for the whole curve, whereas a pointwise CI guarantees that on average, only 95% of the computed intervals for each individual point from the support will cover the true value. The latter is appropriate only when the focus is on a single point (that is, value) from the latent trait but not for the whole curve.
Note that in the presence of a proportional bias, the new measurement method needs to be recalibrated, using
2.3 The mean squared error
As mentioned above, in the presence of a proportional bias, method 1 is not on the same scale as method 2; therefore, the variances of the measurement errors of the two instruments may not be compared without recalibration. However, if the user does not want to recalibrate method 1, then the mean squared errors (MSEs) may be compared instead of the SDs. As method 2 is the reference, its MSE equals its variance,

The user can compute 95% simultaneous CBs for MSE1 and MSE2 exactly in the same way as for the bias and the SD (Taffé 2020). Alternatively, the user may similarly compute the square root MSE to produce a figure in the same units as the reference standard.
2.4 The agreement
To assess the agreement between the two measurement methods, following a similar path as Bland and Altman, Taffé (2020) defines the α-level upper and lower limits of agreement

where the conditional distribution of the differences, dij = y 1 ij − y 2 ij |xi , is assumed to be normally distributed. The main difference between the Bland and Altman approach and the Taffé approach is that the Taffé methodology conditions on xi to resolve the issue of endogeneity and allow the variances to be heteroskedastic and depend on the level xi of the true latent trait.
The LoA are estimated by

where the estimate of the variance

Simultaneous 95% CBs for
2.5 The percentage of agreement
To assess the level of agreement between the two measurement methods, Taffé (2020) has developed a new index, the “percentage of agreement”, defined by (in terms of a proportion)

where Z 1 −α / 2 is the 1 − α/2 percentile point of the standard normal distribution. Note that for (4), the percentage of agreement is defined by the percentage of disagreement, captured by the fraction portion of the above equation. In the numerator, the 1 − α/2 percentile point Z 1 −α / 2SD(y 1 ij −y 2 ij |xi ) of the conditional distribution of the differences y 1 ij − y 2 ij (which is assumed to be normally distributed) is penalized by the absolute value of the bias and then divided by the value of the latent trait. Finally, one minus the fraction represents the percentage of agreement. Notice that the percentage of agreement may turn out to be negative whenever the numerator is larger than the denominator, in which case the agreement is extremely poor.
The original intention of Bland and Altman (1983, 1986), when they developed the LoA plot, was that it was up to the investigator to appraise the level of agreement between the two measurement methods, which is deliberately subjective. However, as an aid to interpreting results and because the agreement may not be constant over the whole support, we have developed the “percentage of agreement”, which is based on a formula.
The percentage of agreement is computed as
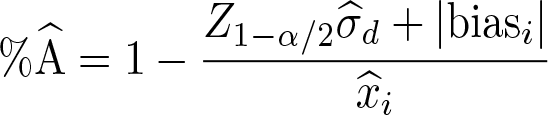
When method 1 has been recalibrated (to remove the bias), the user uses the “corrected percentage of agreement” instead:

which is estimated by

Again, simultaneous 95% CBs for %A, respectively %A∗, can be computed as above for the bias and two SDs.
3 The extended biasplot command
The extended
3.1 Syntax
The syntax for
3.2 Options
3.3 Stored results

4 Numerical examples
To illustrate the use of the extended
4.1 Simulation model 1

where i = 1,…, 100, and the number of repeated measurements of individual i from the reference standard was n 2 i ∼ Uniform[10−20] and n 1 i ∼ Uniform[1−3] for the new measurement method.
There are between 10 and 20 repeated measurements by the reference standard and between 1 and 3 by the new measurement method for each individual. The new method (method 1) has a differential bias of 4 and a proportional bias of 0.8. In addition, the variance of the measurement errors from method 1 is larger than that of the reference method 2. Notice that as the individuals do not have the same number of observations, the precision of the prediction (BLUP of x) of the latent trait will vary across individuals, and a smoothing of the CBs has been implemented using fractional polynomials of degree 2.
The data have been saved in the file named
We load the example dataset 1:
We call the


(a) Standard Bland and Altman LoA plot and (b) bias plot
Based on Taffé’s (2018) methodology, a differential bias of 3.5 (true value 4), 95% CI = [−1.87; 8.80], and a proportional bias of 0.82 (true value 0.8), 95% CI = [0.66; 0.97], are identified, whereas with the standard Bland and Altman methodology, a differential bias of −9.0 (true value 4), 95% CI = [−17.7; −0.4], and a proportional bias of 1.16 (true value 0.8), 95% CI = [0.96; 1.36], are found.
The bias plot may seem complicated to read at first sight because it has two y axes, but it is, in fact, a standard scatterplot. The left y axis represents the values (y 1 and y 2) of the measurements made by the two instruments, whereas the x axis represents the true value of the latent trait after measurement errors have been removed (more precisely, it is the best possible estimation of the latent trait, that is, BLUP). Therefore, the bias plot is simply a scatterplot of the measurements, y 1 and y 2, with the x axis representing the true latent trait. In Bland and Altman’s LoA plot, the true value of the trait is estimated by the mean of the two measurements, that is, (y 1 + y 2)/2, whereas in the bias plot, it is estimated using all the measurements of the individuals.
By inspecting the bias plot (shown here in grayscale), we see that the regression line of the new method y 1 (green in the actual plot) lies below the one of the reference y 2 (black) for all the values of the true latent trait. Clearly, the method y 1 has a negative bias over the whole support from 25 to 45. The bias of the method y 1 is equal to the vertical distance between the green line and the black one. Because it is difficult to read this distance directly on the plot, the bias plot has a second y axis on the right. This right y axis works like a magnifying glass and shows the distance between the two lines. For example, when the true trait is 45, the distance between the green and black lines is about −5, as can be read on the right y axis using the red bias line. Likewise, when the true trait is 25, the distance between the green and black regression lines is about −1 (here the magnifying glass is really useful because it is difficult to read the distance between the two lines directly on the scatterplot).
This example clearly illustrates a setting where Bland and Altman’s methodology provides biased and misleading results, whereas the “bias plot” methodology shows that the bias of the new method is larger the higher the latent trait.
We will present below the newly proposed graphs to help the investigator to assess bias, precision, and agreement between the two measurement methods. These may be obtained by running the

or, more compactly, by using a single command:

In both situations, the four graphs are saved in the current directory, but in the latter situation, only the last figure will be open:

(a) Total bias plot with simultaneous CBs; (b) precision plot with simultaneous CBs; (c) agreement plot without recalibration; and (d) agreement plot after recalibration
The total bias plot focuses on the (total) bias, which results from the two components of bias: the differential and proportional biases. It works as a magnifying glass of the bias line from the bias plot. The simultaneous CBs around the total bias line allow the user to formally assess whether bias is statistically significant and on which portion of the support.
The precision plot with its simultaneous CBs around the two SD lines allows the user to formally compare the precision of the two instruments under consideration (there is a statistically significant difference between 30 and 45), after recalibration of the new measurement method to resolve the scaling issue.
The agreement plot is similar to the classical Bland and Altman LoA plot, except that the x axis is the predicted true latent trait (that is, BLUP of x) instead of the mean of the two measurements. It allows the user, by inspecting the lower and upper limits, while accounting for the CBs, to visually and quantitatively (by reading the percentage of agreement on the right y axis) appraise the degree of agreement between the two measurement methods. Without recalibration, the LoA are centered on the bias line, whereas they are centered on the zero value after recalibration. After method 1 has been recalibrated, and the differential and proportional biases removed, the line of bias is confounded with the x axis, and the agreement plot shows that agreement is better for higher values of the latent trait.
The reading of the percentage of agreement is not always easy on the agreement plot, and no CB appears around the percentage of agreement index. To inspect thoroughly the percentage of agreement, the user may compute the “percentage of agreement” plots, using the commands

(a) Percentage of agreement plot without recalibration and (b) percentage of agreement plot after recalibration
The percentage of agreement plot allows for a formal assessment of the level of agreement. When there are three or more measurement methods to be compared, the percentage of agreement plot may turn out to be useful for formally comparing the levels of the agreement by superimposing the curves along with their simultaneous CBs on the same plot (illustrated below).
Because of the scale issue, in the presence of a proportional bias, the new measurement method was recalibrated before computing the SD of the measurement errors. However, if the user is reluctant to perform a recalibration and prefers to conserve the measurements by method 1 as is (despite a bias), then he or she may compare the precision of the two measurement methods using the MSE (to account for the bias) or the square root MSE (to produce a figure in the same units as the reference standard) instead of the SD:


(a) The MSE plot illustrates that the MSE of method 1 tends to be larger than that of method 2, although not statistically significant as the CBs’ overlap over the whole support; and (b) the MSE plot produces a figure in the same units as the reference standard.
Comparison of the MSE plot with the precision plot (compare with figure 2) reveals that, after we removed the bias from method 1, the precision of method 2 turned out to be clearly superior to that of method 1 almost over the whole support, whereas this was not as apparent on the MSE plot or its square root counterpart.
4.2 Illustration of the results option
Another feature we have added to this extended version of the

which will generate a file called
4.3 Simulation model 2
This dataset is based on the same simulation model (5), except we have increased the number of repeated measurements by the new method y 1, that is, n 1 i Uniform[10−20], and widened the support xi ∼ Uniform[20−100] to allow easier reading of the plots.
The data have been saved in the file named
4.4 Simulation model 3

with n
2
i ∼ Uniform[10−20] and n
1
i ∼ Uniform[10−20]. The simulated data have been saved in the file named
Notice that, in this dataset, we did not use the same values of the reference method as in the first simulation dataset. Rather, new values were simulated using the same model because we wanted to mimic the setting where the reference method had been used twice in two separate experiments but on the same population, with two different new measurement methods to be compared.
Consider, first, the comparison of the two total bias plots:


(a) The total bias plot from simulation model (5) and (b) total bias plot from simulation model (6)
These two total bias plots may be combined using the following code:

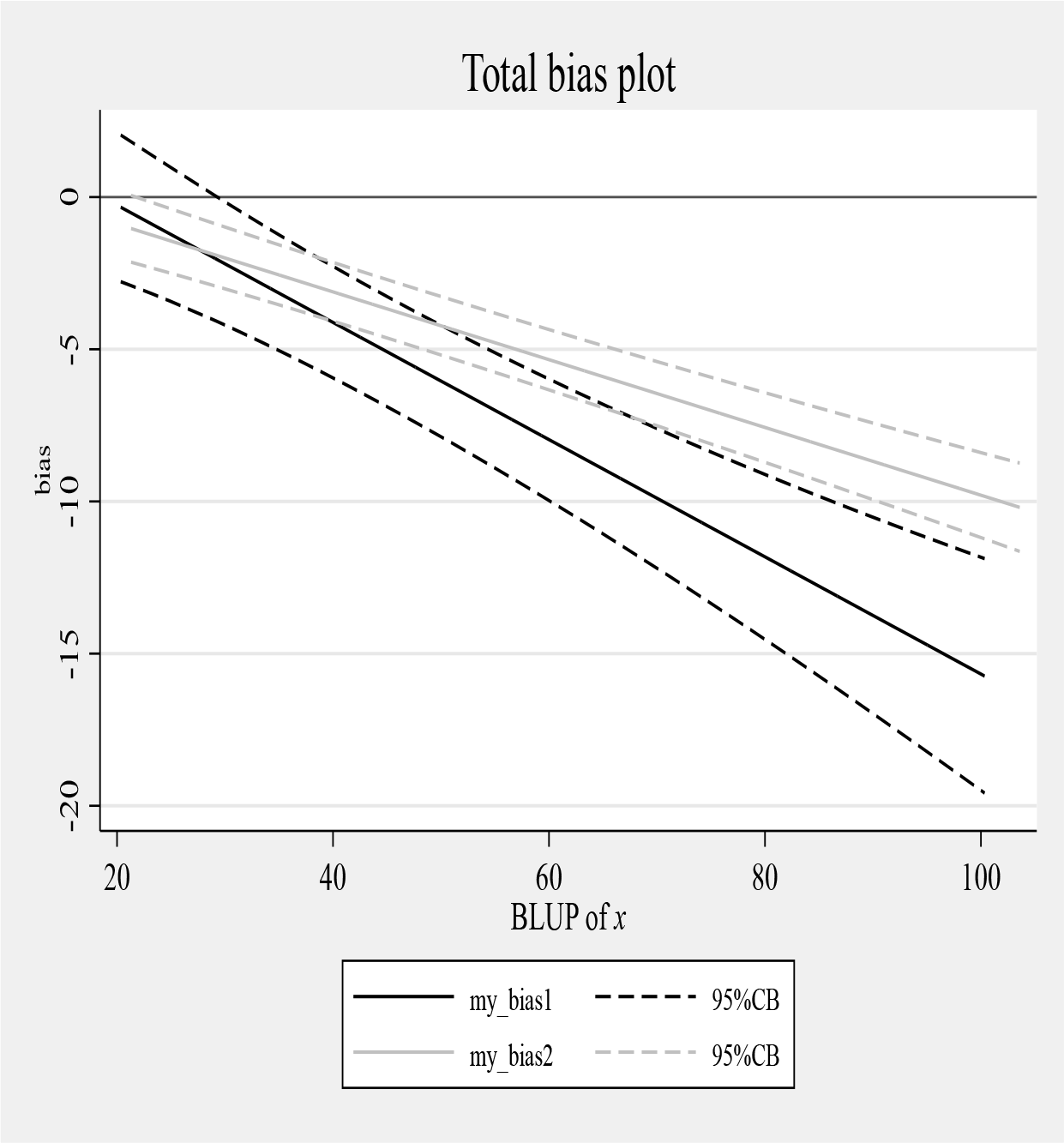
Total bias plot combining bias estimates from simulation models (5) and (6)
From 70, measurement method 2 has a lower bias than method 1.
Now we will consider the comparison of the two precision plots:

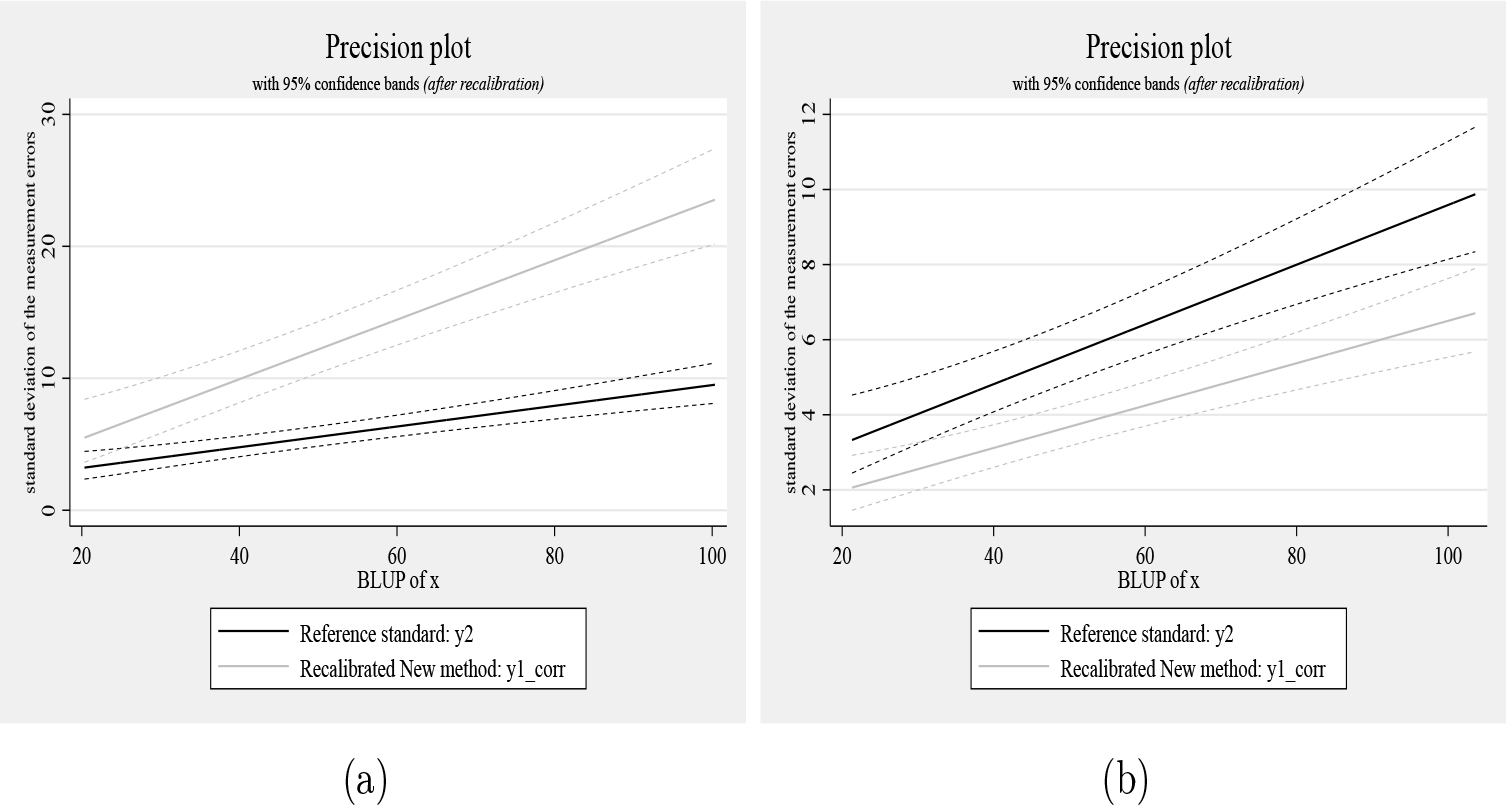
(a) The precision plot from simulation model (5) and (b) precision plot from simulation model (6)
These two precision plots may be combined using the following code:



Total bias plot combining bias estimates from simulation models (5) and (6)
Clearly, after recalibration, measurement method 1 (
5 Discussion
Based on simulated data, we have illustrated the use of the extended
Also, by superimposing the bias lines and simultaneous CBs obtained from several new measurement methods on the same plot, the user may assess which method performs best in terms of bias according to the level of the latent trait (note that this is not implemented in the current
The agreement plot is similar to the standard Bland and Altman LoA plot (Bland and Altman 1986), except that its x axis is the BLUP of the true latent trait and not the average of the two measurements (as in the Bland and Altman LoA plot). It is as simple to read and interpret as the traditional LoA plot but has the additional advantage of including on the right y axis a quantitative summary index of the degree of agreement. Having a quantitative index in addition to the plot may greatly help the interpretation of the results. As for the bias and precision plots, the user may draw on the same plot the percentage agreement and CB computed for different measurement methods. This provides a convenient way to compare the level of agreement between different competitive measurement methods.
In our experience, to get a reasonable estimate of the precision (that is, the SD of the measurement errors), at least 8 to 10 repeated measurements by one of the two measurement methods are needed. Note that the repeated measurements need not be from the reference standard. This is a great asset of our methodology because sometimes it may turn out to be easier to perform many measurements by the new measurement method. Requiring repeated measurements by one of the two methods might discourage the applied researcher to use our methodology. However, this is necessary for statistical identification. Indeed, when the variance of the measurement errors of each measurement method is not constant or their ratio is unknown, which is usually the case in the biomedical field (the variance of measurement errors often increases as the latent trait increases), having only one measurement by each of the two measurement methods does not allow the user to identify the bias (Dunn 2004).
When the focus is mainly on estimation of the differential and proportional biases, as few as three to five repeated measurements from the reference standard and only one measurement by the new method, or vice versa, is required to get good estimates (Taffé 2020).
Note that our modeling technique rests on the assumption that the individual latent trait is constant within individuals; that is, xij ≡ xi . This means that the repeated measurements should ideally be taken in sequence within a time interval where this assumption is sensible. For example, in our application to systolic blood pressure data, the measurements were taken in sequence with 30 seconds between each measurement, and the assumption of an average constant latent blood pressure was sensible (Taffé, Halfon, and Halfon 2020). It is theoretically possible to extend the methodology to other settings where the latent trait has a time trend (Taffé 2018). However, in that case, the simple and convenient decomposition of the bias into (constant) differential and proportional components is probably not sensible, and more sophisticated models should be developed.
6 Conclusions
In conclusion, the extension of the
8 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231161978 - Extended biasplot command to assess bias, precision, and agreement in method comparison studies
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231161978 for Extended biasplot command to assess bias, precision, and agreement in method comparison studies by Patrick Taffé, Mingkai Peng, Vicki Stagg and Tyler Williamson in The Stata Journal
Footnotes
7 Declaration of conflicting interests
The authors declare no potential conflicts of interest with respect to the research, authorship, or publication of this article.
8 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.