
Abstract
In some applications, only a coarsened version of a categorical outcome variable can be observed. Parametric inference based on the maximum likelihood approach is feasible in principle, but it cannot be covered computationally by standard software tools. In this article, we present two commands facilitating maximum likelihood estimation in this situation for a wide range of parametric models for categorical outcomes—in the cases both of a nominal and an ordinal scale. In particular, the case of probabilistic information about the possible values of the outcome variable is also covered. Two examples motivating this scenario are presented and analyzed.
Keywords
1 Introduction
1.1 Background
In some applications, only a coarsened version C of a categorical outcome variable Y can be observed; that is, C is a subset of all categories indicating the “possible” values of Y but including in any case the true value of Y. The theory of fitting a parametric model
We start with presenting two examples motivating this setup. Next, we establish the likelihood for C, and we present the commands
1.2 Motivating example 1: Coarsened age categories in human osteoarchaeology
Analyzing former populations represented by human skeletal remains excavated from archaeological sites is a core task of human osteoarchaeology (White, Black, and Folkens 2011). Determining age and sex of each skeletal individual is usually the first basic step, allowing researchers to describe the demographic structure (age and sex distribution) of the skeletal population. Skeletal age determination is based on traits that become fully expressed only around a certain age in infancy or adolescence or that change or degenerate during adulthood. Because of the variability in physical development, determining the exact, that is, chronological, age is not feasible, and the use of classification systems with classes like infant, juvenile, adult, mature, and senile is common. But even with such categories, often an individual’s age cannot be determined with sufficient precision to be attributed to a single category or class, and only two or more possible categories can be determined (Chamberlain 2006). However, it is often possible to judge that one category is more likely than another, for example, if a fully grown individual who might equally be attributed to either the adult or mature age classes shows signs of intense physical activity but little osteoarthritis, this would be an indicator for a younger rather than an older age at death. Consequently, we may assign in this case a higher probability to the category “adult” than to the category “mature”. A crucial question in assigning such probabilities is whether to account for a prior expectation about the age distribution. To go back to our previous example: if we have an individual for whom we can exclude only that it is an infant or a juvenile, we may assign it a lower probability to be senile than to be mature or adult, respectively, if we expect only few senile individuals in the population. An alternative is to assume that we do not have such expectations and that each age category has the same prior probability.
1.3 Motivating example 2: Probabilistic reference standards in medical diagnostic accuracy studies
Determining the accuracy of a diagnostic test T requires a reference standard Y assigning to each subject the true disease state. Typically, reference standards are established diagnostic tests, which either are not yet available at the time of diagnosis (for example, based on an autopsy or lab tests requiring some processing time) or are expensive or invasive and are aimed to be replaced by a less demanding test. However, there are at least two scenarios in which we have reference standards that assign (in some subjects) only the probability of the disease state of interest instead of the exact disease state. The first scenario is given by expert-based reference standards; that is, a group of experts tries to reach a consensus about the true disease state based on all available clinical information. If this information is ambivalent, the group may make only a probabilistic statement about the true disease state. Actually, the experts should not be forced to reach a definite decision in any case, because this may introduce bias (Jenniskens et al. 2019). In deciding on the probability for a single patient, the expert group may start with the a priori assumption that both disease states are equally likely, or the group may account for the assumed disease prevalence in the study population. For example, if a patient has to the same degree signs for both possible disease states, in the first case, the group assigns the probability 0.5, and in the second, the assumed disease prevalence. The second scenario is given by automatic tools, assigning the probability of the disease state of interest to each subject based on some input chosen (for example, symptom lists or a whole genome sequencing). It is then less obvious which a priori assumption about the distribution of Y such probabilities refer to. In appendix 1, we point out that the adequate choice is the distribution of Y in the population used to develop the prediction rule implemented in the automatic tool but that additional considerations might be necessary.
2 Statistical methodology
2.1 Notation
We make use of the following notation:

In general, the specified probabilities
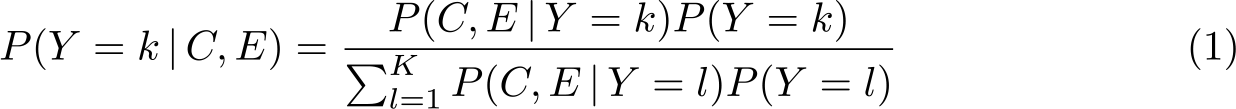
For a likelihood-based inference, we need to know P(C, E | Y = k), and hence we need to know the distribution of P (Y ) assumed when assigning the values pk ∗. So we need in addition

2.2 The likelihood
The likelihood to observe a subset C and an external information E can be expressed as
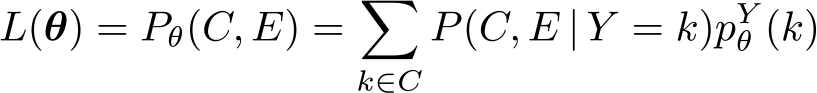
The relation (1) allows us to relate pk
:= P (C, E | Y = k) to

which is solved by
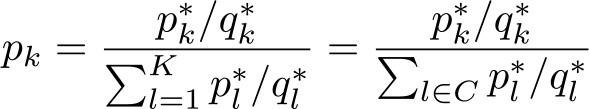
Consequently, we have

and this likelihood does not depend on E. Hence, its computation is feasible, even if E is not explicitly measured.
The classical CAR assumption can be expressed as

This implies
The considerations above can be extended by accounting for additional variables X. We can replace pθ
(y) by a regression model, that is, by pθ
(y|x), or we can replace it by a multivariate distribution pθ
(y, x) with only the first variable affected by coarsening. In both situations, the prespecified probabilities
2.3 The scope of pccfit and pccprob
Because an explicit representation of the likelihood is available, we can use Stata’s
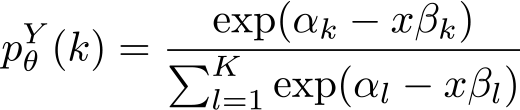
with αb = 0 and βb = 0 for one prespecified base outcome category b. This choice can be also used to fit simply a multinomial distribution by omitting any covariate. The second choice supports fitting regression models for ordered data. Here θ = (κ 0 ,…, κK, β) and

with
However, the presence of coarsened data already makes the estimation of the distribution of Y cumbersome. Hence, in many applications, the aim is not to fit regression models but just to obtain estimates of
2.4 A note of caution
We would like to point to one weakness of the ML approach: if there is a category with
3 The pccfit command
3.1 Syntax
The command expects to find K variables with the prespecified values pk
∗ for each observation. Categories outside C should have the value 0. The variables should share the same prefix with suffixes 1 to K. The syntax of
[
The command fits the model specified by modelspecification to the data using the ML principle and the likelihood outlined in section 2.2. indepvars denotes potential covariates to be accounted for in the model specification.
We now consider modelspecification. Here the user can explicitly define an expression for
modelspecification = usermodelspecification | prespecifiedmodelspecification
usermodelspecification =
prespecifiedmodelspecification =
paramspecifications = paramspecification [
paramspecification = {scalarpardef | vectorpardef }
scalarpardef = name
vectorpardef = name numlist
In general, in the expression used to define
exprspecification is a Stata expression that may include additional constructs evaluated in a preprocessing step for any possible value of k ∊ {1, 2,…, K}. After this preprocessing step, exprspecification should be a valid Stata expression if all (indexed) parameters are replaced by numbers.
The following additional constructs are allowed and evaluated during the preprocessing in the specified order:
Note that the additional constructs described above do not allow additional spaces within the identifying parts of the different constructs, in particular, after a
Besides modelspecification, there is one additional option to be specified:
The following options can also be used:
maximize_options are passed to the
3.2 Methods and formulas
The

with the value of

with F denoting the distribution function defined by expr. If
3.3 Stored results

4 The pccprob command
The
4.1 Syntax
The syntax of
subsetspecifications is a sequence of numlists separated by

nlcomoptions are passed to
4.2 Methods and formulas

If you want to include the set {1, 2,…, K} in the subsetspecification, you typically run into troubles because this set has the probability 1.0. For example, using the standard logit transformation to compute confidence intervals does not work. Thus, the numlist 1, 2,…, K is omitted when using the
4.3 Stored results
As long as the
4.4 A final note on the exact option
Both
When you specify an expression corresponding to a multivariate distribution pθ
(y, x), you must specify the
5 Examples
5.1 Example 1: Osteoarchaeological analysis
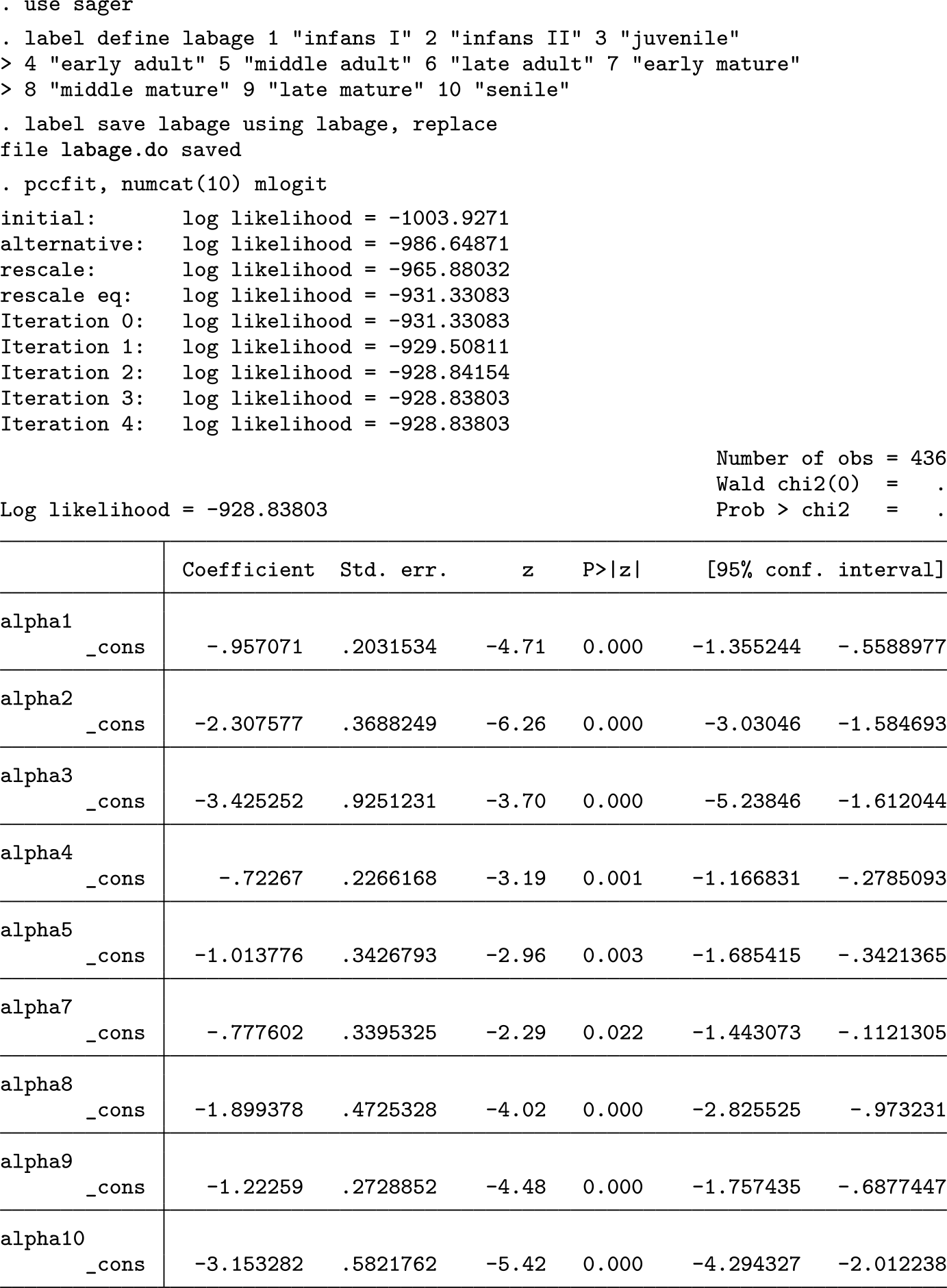
The Gallo–Roman burial site Im Sager is part of the Roman city of Augusta Raurica in northwest Switzerland (Berger 2012). The site comprises about 600 graves with inhumations and cremated skeletal remains of 436 individuals (Alder 2020). The burials were archaeologically and bioarchaeologically examined in an interdisciplinary study (Ammann Forthcoming). Determination of the age at death of the individuals buried at Im Sager is based on a system with the K = 10 categories infans I, infans II, juvenile, early adult, middle adult, late adult, early mature, middle mature, late adult, and senile (Großkopf 2004).
Only 81 subjects (18.6%) could be assigned to a single age class, and all other subjects could be assigned only to two or more classes. One hundred twenty-eight subjects (29.4%) were assigned to two classes, and 90 to three (20.6%). For 18 subjects (4.1%), it was impossible to exclude any class, and the remaining 119 subjects were assigned to 4 to 8 classes. On average, the age determination included 3.2 classes per individual. During the process of age determination, each possible class was labeled either as “more likely” or as “less likely” for each subject analyzed. These labels were transformed into probabilities by assigning the weights 1 and 2, respectively, and dividing the weight by the sum of weights within each subject. Among the 81 subjects assigned to a single class, 38 were classified as infans I, reflecting the straightforwardness of classifying young children. The age determination was performed by one assessor (Cornelia Alder), who made the decision between “less likely” or “more likely” solely based on the osteological findings without any assumptions on the underlying demographic distribution. This, together with the fact that each age class was assumed to have an age span of 7 years, justifies basing our analyses on the choice
In a first step, we estimate the age distribution of the skeletal individuals and visualize this distribution as a bar chart mimicking a histogram. We obtain the following output and the graph shown in figure 1.
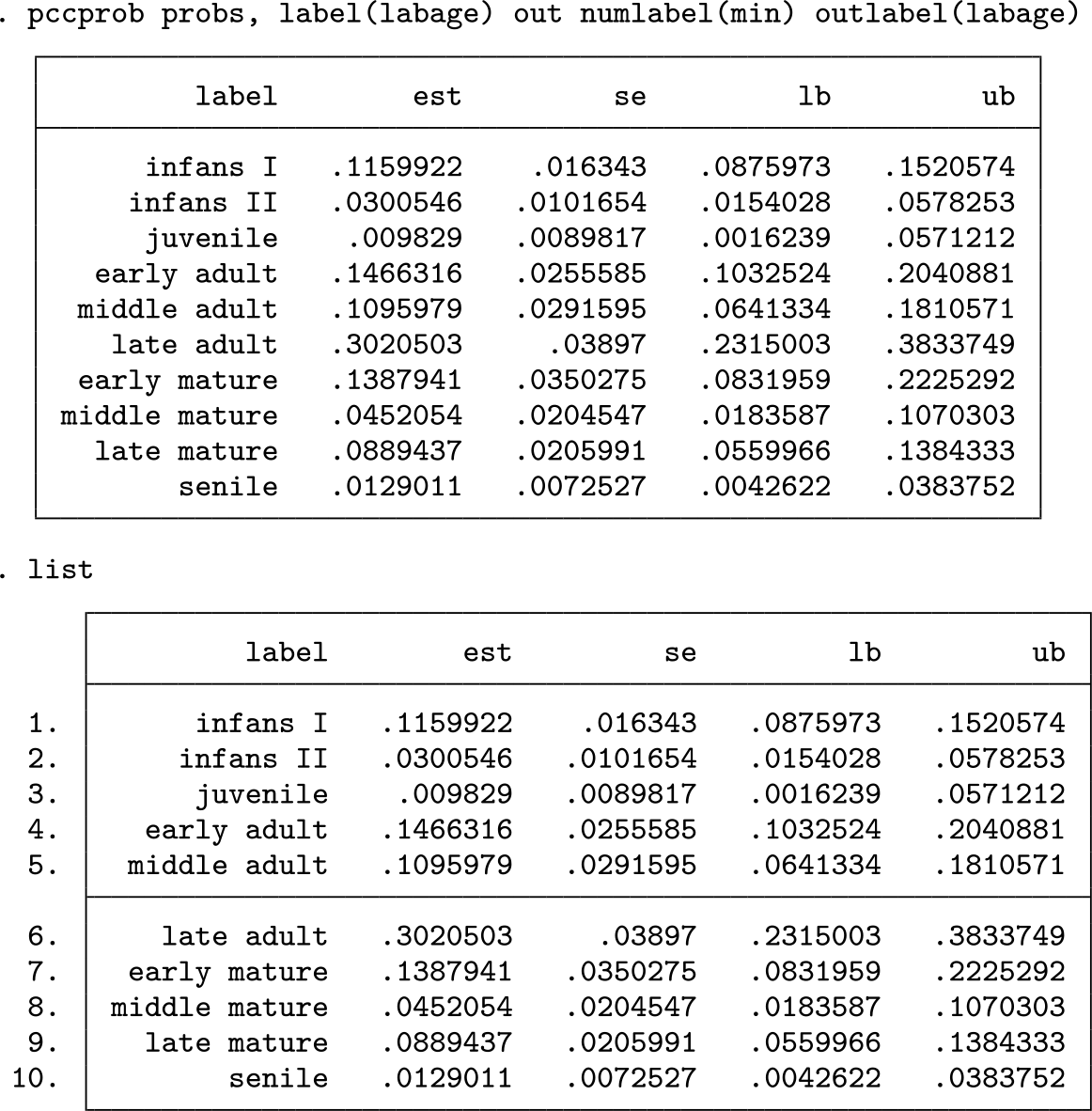

A histogramlike visualization of the estimated age distribution in example 1
We would like to point out that the confidence intervals for the single probabilities are rather wide. This is due to observing coarsened data, which carry less information than noncoarsened data. To illustrate this point, we compute the standard errors we would expect for noncoarsened data and consider the ratio of the observed standard errors to these standard errors:
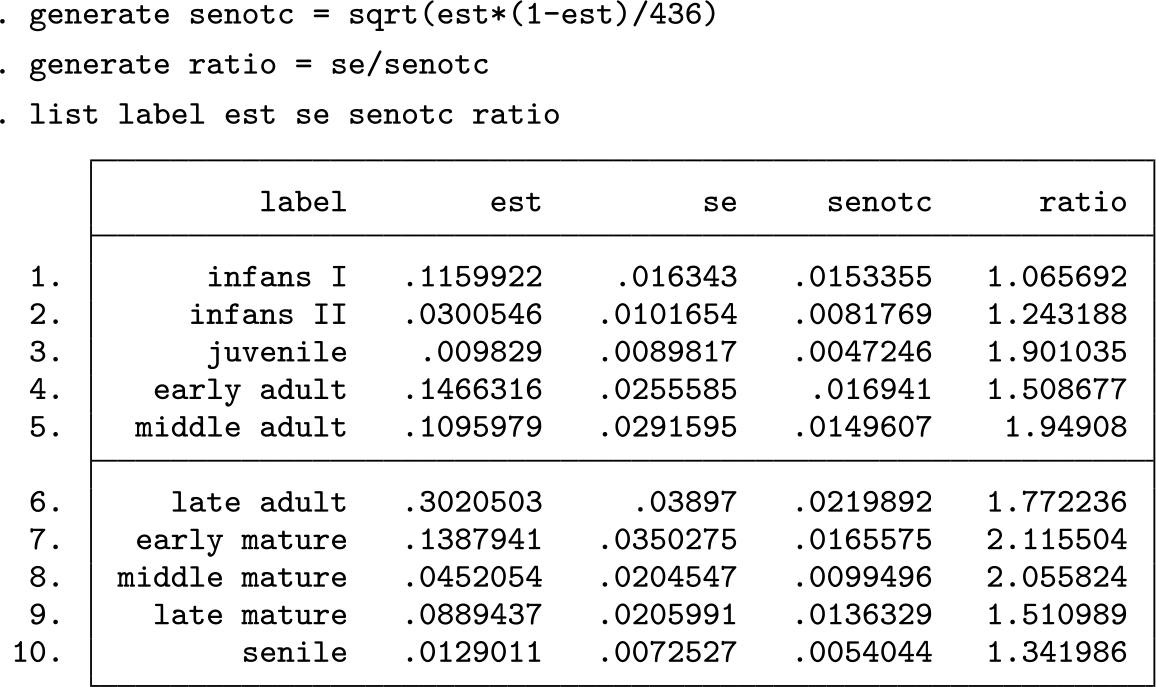
We observe standard errors inflated by a factor up to 2.1. The inflation is most pronounced for the middle-aged categories and least pronounced for infans I, infans II, and senile. This probably reflects the fact that individuals in these latter age groups are easier to determine because there are distinct indicators for either young or old, that is, high age. However, the gradual changes in trait morphology used to determine age in the “middle” categories lack distinctive cutoff markers, thus assigning individuals to many classes and increasing standard errors.
Consequently, we should be aware that the effective sample size is not 436 but probably less than 200. Any unreflected attempt to estimate the age distribution in 10 categories will hence suffer from limited precision, as reflected in rather wide confidence intervals. It might be more appropriate to visualize the age distribution by the cumulative distribution function because cumulative probabilities are less sensitive to coarsening. (To estimate the probability to be in a specific age category or above this category, any observation with a coarsened interval completely above or below this class contributes the same information as a subject with a noncoarsened observation.) We can approach this in the following way producing the graph shown in figure 2.


The cumulative distribution function of the estimated age distribution in example 1
Using a parametric model for the class probabilities is another approach to obtain more stable estimates. We consider here a cubic spline with 5 knots equally spaced between 1.5 and 9.5. We can approach this by the following code producing the graph shown in figure 3.


A histogramlike visualization of the estimated age distribution in example 1 based on using a cubic spline
We can now perform the same exercise as above and compare the standard errors with those to be expected frSom noncoarsened data and fitting a full multinomial model:

We observe ratios close to or below 1. This reflects that we estimate only four instead of nine parameters and that borrowing information from neighboring categories reduces the negative impact of coarsening.
Instead of estimating the full age distribution, we may focus on characteristics of the distribution like the mean. This can be approached by posting the estimates of the class probabilities and then building a weighted sum with weights, assigning to each age class the medium age according to the assumed span of seven years:

We can conclude that the average age at death in the skeletal population considered is about 34 years, with a rather small stochastic uncertainty visible in a narrow confidence interval.
The graves of the burial site Im Sager can be divided into two subgroups: inhumination and cremation burials. The burial practice may be related to the age at death of an individual; hence, it might be of interest to compare the age distribution between the two groups. The group of inhumination burials includes only 51 individuals; hence, we need to use a parametric model to come to stable estimates. We again use cubic splines and arrive at the graph shown in figure 4, indicating frequent use of inhumination in young children.


Histogramlike visualizations of the estimated age distributions in cremation and inhumination burials in example 1 based on using a cubic spline
Finally, we may be interested in performing a formal significance test of the difference in age between the two groups. Because we may expect a shift in the age distribution— and the actually observed difference is also compatible with a shift—we can approach this using an ordered logistic regression model:


So the final conclusion is that we have a statistically significant difference in age between the two subpopulations with a p-value less than 0.0001, indicative of cultural processes affecting burial practices at Im Sager.
5.2 Example 2: Palaeodemographic analysis
So far, we have focused on analyzing the age distribution of the skeletal population. Palaeodemography goes one step further and attempts to make a link to the former living population the observed skeletal population originated from (Chamberlain 2006; Hoppa and Vaupel 2002a). When analyzing the skeletal population of a burial site associated with a settlement, we assume this to be the population living in the settlement and using the burial site for a certain period in time. The distribution of age at death among the deceased in the living population during the period the burial site was in use may be approximated by the age at death distribution in the skeletal population, if we can regard the latter as representative, that is, to be a random sample from the first. The validity of this assumption depends on many factors. It may be violated if some individuals died far from the settlement and were consequently not buried in the community where they had lived (for example, warriors or traders); if some of the deceased were buried elsewhere by cultural choice (for example, criminals or young children); or for taphonomic reasons, if, for example, age at death determined how deep graves were dug, thus affecting the preservation of childrens’ graves and skeletons (Knüsel and Robb 2016).
The next fundamental step is given by moving from the distribution of age at death to the age distribution among the living population and to age-specific mortality rates. Such quantities can be derived from the distribution of age at death, if we assume that the background population was stable in size and age composition over time (Coale 1972). This is a rather idealistic assumption (Sattenspiel and Harpending 1983) but nevertheless represents the basic assumption for demographic analysis of skeletal populations (Chamberlain 2006; Margerison and Knüsel 2002; Bonneuil 2005), which can give important insights into demographic side conditions for the society present in the settlement. The key step is that under these assumptions, the fraction of subjects at a certain age in the living population is equal to the fraction of subjects dying at this age or above this age when considering the distribution of age at death. So we can estimate the age distribution in the living population by computing the upper tail probabilities and rescaling them to probabilities, and we can then visualize them by a bar chart similar to a population pyramid (figure 5).


Visualization of the estimated age distribution in the living population in example 2
Similarly, we can now compute mortality rates by comparing those dying while being in a certain age category with those dying at this age or above this age. The following piece of code generates a list of mortality rates for each age category together with a standard error:

We observe a very low mortality in the categories infans II and juvenile but an increased mortality rate in the category infans I, reflecting a well-known phenomenon. The mortality rates are about 15% in the first two adult age categories before we can see a substantial increase at higher age categories. The lack of a monotone trend suggests an instability that is not necessarily visible in the standard errors and suggests one perform some smoothing to obtain more reliable results. After such a postprocessing, the mortality rates can then be used to depict further aspects of mortality, for example, conditional survival probabilities or the life expectancy. Such computations are known as “life table analysis” (Halli and Rao 1992, chap. 2).
5.3 Example 3: A diagnostic accuracy study with an expert-based probabilistic reference standard
Here we consider an artificial dataset from a diagnostic accuracy study with a probabilistic reference standard based on an expert consensus. Not all subjects could be classified uniquely as diseased or undiseased; the experts assigned to some subjects a probability of 2/3 to be diseased and to some a probability of 1/3. Adding later the result of the index test to be evaluated in the variable

Category 1 refers to being undiseased (D = 0), and category 2 refers to being diseased (D = 1). Our interest is in sensitivity P (T = 1 | D = 1) and specificity P (T = 0 | D = 0).
The use of

After transforming the three parameters from the probability to the logit scale, we can fit the model using

Because we have now used a multivariate model for the analysis, we have to ensure that the probabilities specified refer to the conditional probabilities of D given E and T. Of course, the experts were blinded to the index test T, and hence they definitely specified probabilities referring to D given E. We thus have to make here the additional assumption that the information in E was strong enough such that T would not have added additional information, if it had been known to the experts.
6 Discussion
6.1 Alternatives to ML estimation
6.1.1 Weighting
One simple alternative would be to interpret the specified probabilities p
∗ just as weights. This means, for example, that we count a unit with
Unfortunately, this simple approach is just wrong and leads to biased results. To understand this, let us consider a simple example with two categories and a sample in which 80% of the observations fall in category 1 and 20% in category 2. We now introduce coarsened observations, and within these observations, the external information is so weak that we have to regard both categories as equally likely. This can be reflected by the choice
We can observe this issue also in our data, if we incorrectly apply the weighting approach. Figure 6 compares the result of the weighting approach with the ML approach. The rare categories are assigned a higher probability by the weighting approach than by the ML approach, and the frequent categories are assigned a lower probability. This flattening is in line with the considerations in the previous paragraph: The observations with high degree of coarsening are incorrectly flattened out over the whole range, whereas the ML approach avoids this and tries to distribute the coarsened data in line with the distribution observed in the less or noncoarsened observations.

Visualization of the estimated age distribution in example 1 using the weighting approach or the ML approach
Nevertheless, the distinct peak for the category late adult in the distribution estimated by the ML approach is somewhat surprising. A closer look at the data in table 1, however, reveals that this reflects a true property of the dataset. We can observe that on one side the category late adult constitutes the category that is most rarely completely excluded. On the other side, it is also often assigned a probability of 1 (only exceeded by the category infans I) or a probability above 0.5 or at least above 1/3. Hence, in this dataset, some individuals could be assigned rather precisely to or close to this category, in spite of the gradual changes in trait morphology used to determine age in the “middle” categories mentioned above.
The distribution of the assigned probabilities p ∗ for each age category in the total sample

6.1.2 Bayesian inference
At first sight, the prespecified probabilities
6.1.3 Multiple imputation
Multiple imputation is another alternative to ML estimation. Luy and Wittwer-Backofen (2008) actually already considered a multiple imputation approach to obtain an estimate of the age distribution from coarsened age determination data without probabilistic information: for each coarsened observation of Y, they made a random draw from C (assuming a uniform distribution) and derived from this imputed dataset an estimate of the survival curve. And then they repeated this many times. However, this way to generate multiple imputations follows the spirit of the weighting approach, regarding the prespecified probabilities (constant within each C) as an estimate of the true distribution of Y. This is an example of an improper imputation method in the sense of Rubin (Rubin 1987; Nielsen 2003), resulting in biased estimates. Correct implementation of a multiple imputation approach would require one to develop a technique for generating proper multiple imputations.
6.1.4 Assuming CAR
Another approach would be to ignore the probabilistic information and to assume CAR. This can be a valid approach, too, because specifying probabilistic information does not necessarily imply that the CAR assumption is invalid. If the probabilistic information is based on measured additional external information, we just ignore this information, and hence become less efficient, but we do not necessarily introduce bias. However, the probabilistic information may also reflect an assumed violation of the CAR assumption. If we assume that one category implies more often a coarsening than another, we may account for this in the prespecification: We may tend to give this category a higher probability, even if otherwise several categories look equally likely.
6.2 Arriving at the probabilistic information
In both our examples, we considered the case that one or some subjects specify the probabilistic information. This is obviously a crucial step. One important aspect of this step is to make these subjects aware about the prior distribution of Y (reflected in the values
6.3 Investigating the sensitivity to the specification of the probabilistic information
Because we may be in doubt about the validity of the prespecified probabilities, it seems reasonable to investigate the influence of these specifications on the results. One approach would be to ask different subjects to specify the probabilities and to compare the results. We may also add some noise to the probabilities and investigate the resulting fluctuation of the results. As pointed out above, we may also perform an analysis ignoring the probabilistic information and assuming CAR. In example 1, this approach results in the age distribution shown in figure 7, and this distribution is very similar to the one obtained when accounting for the probabilistic information (figure 1). So we can conclude that in this application, the prespecified probabilities have little influence on the final results.
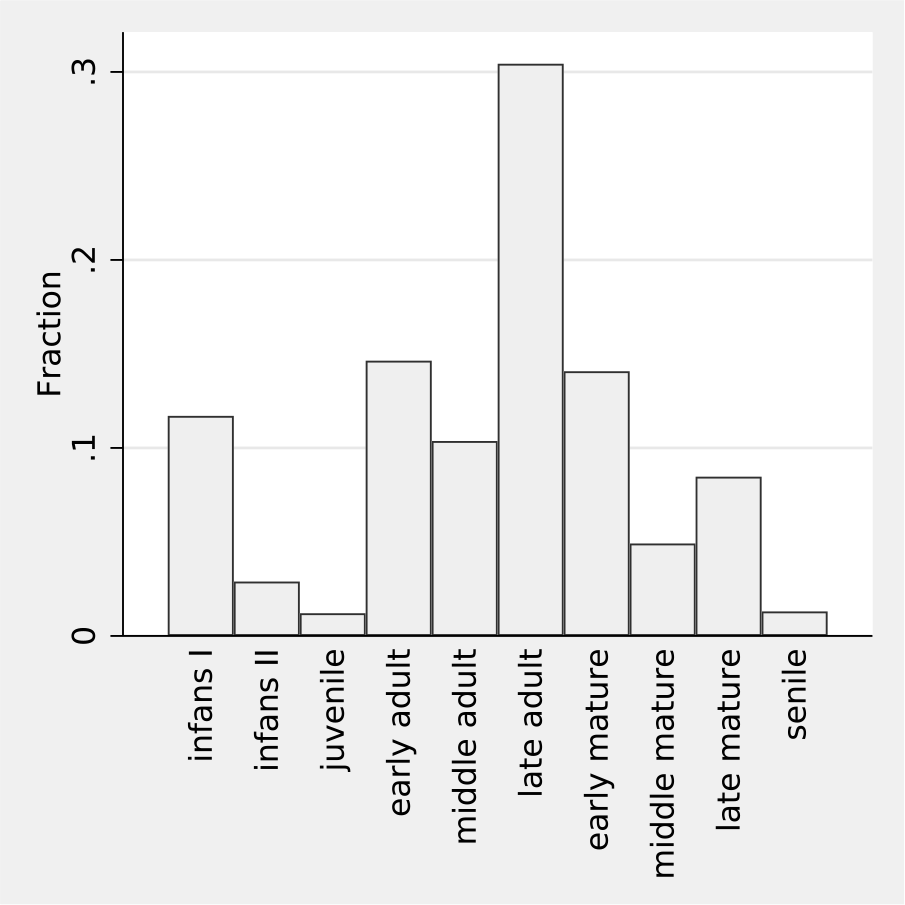
Visualization of the estimated age distribution in example 1 assuming CAR
6.4 Outlook
Human osteoarchaeology is a field where coarsened data with or without probabilistic information occurs as a matter of fact. In osteological sex determination, the traditional approach was to develop rules assigning sex on a 3-point-scale (f, ?, m) or a 5-point scale (f, f?, ?, m?, m), that is, in a specific way to code probabilistic information on the binary variable sex. However, this is now changing by publishing rules allowing computation of posterior probabilities (Brůžek et al. 2017), that is, exact probabilistic information. The Rostock manifesto has emphasized the need of using posterior probabilities not only for sex but also for anthropological age determination (Hoppa and Vaupel 2002b).
In the field of archaeology, in general, coarsened data appear in the context of working with chronological orders. For many features of objects, it is known how to map them to a certain time span, and even within this time span, frequency differences are known, resulting in probabilistic information. The mathematical procedure to develop such mappings, known as “seriation” was developed by Sir William Flinders Petri as early as the end of the 19th century (Renfrew and Bahn 2019), and today many such chronologies are available.
We considered an expert-based reference standard as a further example for coarsened data. The emphasis on prediction in the upcoming field of data sciences will probably generate many prediction models in the future, which then will be applied to generate input in further applications. In all of these cases, we will be forced to work with coarsened data with probabilistic information.
7 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X221083902 - Analyzing coarsened categorical data with or without probabilistic information
Supplemental Material, sj-zip-1-stj-10.1177_1536867X221083902 for Analyzing coarsened categorical data with or without probabilistic information by Werner Vach, Cornelia Alder and Sandra Pichler in The Stata Journal
Footnotes
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Appendix 1: Choice of q k * in the case of using a predefined prediction rule
We consider now the specific situation of a binary outcome Y, C = {0, 1} always and E = X representing measured covariates. The probabilities
This suggests that we should choose q 1 ∗ as the prevalence of Y in the external population. This is a safe choice, if a potential difference in the prevalence between the external population and the current study population can be explained by a selection in dependence on Y. In this case, we know that P (X|Y ) is identical in the two populations, which is the assumption we make in deriving the likelihood in section 2.2, if the values p 1 ∗ are derived from an external population. However, if there is a selection in dependence on X, the situation is more complicated because P (X|Y ) will change, too. However, the relation (1) may still hold approximately because P(X|Y = 1) and P (X|Y = 0) are affected similarly. This question requires further investigation.
Appendix 2: Accounting for additional variables X
In the case of interest in a model pθ (y|x), the likelihood of interest is
The values
and connects the prespecified probabilities to the likelihood.
In the case of interest in a multivariate model pθ (y, x), the likelihood of interest is
and exactly the same arguments can be applied.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.