
Abstract
In this article, we review Interpreting and Visualizing Regression Models Using Stata, Second Edition, by Michael N. Mitchell (2021, Stata Press).
Keywords
1 Introduction
In 2016, for the first time, the second author taught a 12-week master’s-level statistics course for psychology students, and he used the first (2012) edition of Michael N. Mitchell’s Interpreting and Visualizing Regression Models Using Stata (IVRMUS-1) as the primary textbook. Because many students would likely use some type of regression modeling for their thesis project, the topics covered in IVRMUS-1 seemed to be a good fit for the course, providing students with a practical grounding in ordinary least-squares (OLS) linear models but also introducing them to some other types of models. In 2019, the first author was a student in that same course. We hope that by collaborating on this book review, we will manage to bring not just an instructor’s perspective, which is typical in such reviews, but also a student’s perspective, which we believe is valuable but less often considered.
2 Content
Mitchell opens the preface to the second edition of IVRMUS (which we denote IVRMUS-2) by commenting on some changes that arose from his use of Stata 16.1 in the second edition; he used Stata 12.1 in the first edition. He notes, for example, that when results for the levels of a factor variable are displayed, value labels are shown rather than values (for example, Unmarried versus Married rather than 1 versus 2). He also comments on the availability of new small-sample options for the
As with the first edition, I hope the examples shown in this book help you understand the results of your regression models so you can interpret and present them with clarity and confidence.
In the introductory chapter that follows, Mitchell draws a distinction between the teaching approach in his book (he calls it a “discovery learning perspective”) and the way one should approach research. He specifically cautions readers that his approach might seem to endorse some “bad research habits”: 1) letting the pattern of the data guide the analysis; 2) dissecting the results in every possible way; and 3) having no concern for the overall type I error rate. (We shall say more later about these bad habits.)
Mitchell then describes the datasets that he used, especially the General Social Survey dataset, which he uses most frequently. Four variables appear most often in his examples: income, age, years of education, and gender. For each variable, he gives some insight into analytic choices made in later chapters (for example, including the option
Although Mitchell does not say so explicitly in his preface, the commands
2.1 Part I: OLS models with continuous explanatory variables
Chapter 2 introduces readers to the
Chapter 3 shows readers how to include quadratic and cubic terms in OLS models and also introduces the
Chapter 4 introduces the One known knot, no jump Two known knots, no jumps One known knot with a jump Two known knots with two jumps One unknown knot Multiple unknown knots
Mitchell also introduces the
Chapters 5 and 6 discuss two-way and three-way interactions involving continuous (or quantitative) variables only. Examples of the following types of interactions are included: Linear × linear Linear × quadratic Linear × linear × linear
In these chapters, Mitchell also shows readers how they can easily obtain simple slopes for one variable at selected values of another variable (or at selected combinations of values in higher-order interactions) via the
2.2 Part II: OLS models with categorical explanatory variables
In part II, the emphasis is on interpreting and visualizing results pertaining to categorical explanatory variables. However, many of the models fit do include continuous covariates—age, for example.
Chapter 7 starts with an unpaired t test but then quickly moves on to fit a model including two categorical explanatory variables (marital status and gender) and one continuous covariate (age) by using the
Next he introduces the Reference group contrasts ( Grand mean contrasts ( Adjacent contrasts ( Reverse-adjacent contrasts ( Helmert contrasts ( Reverse Helmert contrasts ( Polynomial contrasts ( Custom contrasts Weighted contrasts (
The chapter ends with examples of pairwise comparisons obtained via
Table 7.1 is a highlight of chapter 7. It lists all the contrast operators along with descriptions of what they do and the chapter sections in which they are illustrated. The second author of this review has bookmarked that page.
Chapter 8 examines models with 2×2, 2×3, and 3×3 interactions. For 2×2 models, Mitchell shows how to estimate the “size” of the interaction (that is, the difference in differences). For the models with 2 × 3 and 3 × 3 interactions, he shows how to examine simple effects, simple contrasts, partial interactions, and interaction contrasts. The initial examples have balanced designs, but Mitchell also discusses unbalanced designs in section 8.5. In section 8.6, he shows that the 2 × 2 ANOVA fit earlier in the chapter using
Chapter 9 examines 2×2×2, 2×2×3, and 3×3×3 models. It shows readers how to examine simple interactions, simple effects, simple contrasts, partial interactions, and interaction contrasts.
2.3 Part III: OLS models with both continuous and categorical explanatory variables
Chapter 10 describes linear by categorical interactions. It starts with a first-order-effects-only model in which the two focal variables are age and college graduation status (1 = yes, 0 = no). Mitchell demonstrates how
Chapter 11 builds on chapters 3 and 10 to explore polynomial by categorical interactions. Mitchell illustrates a quadratic by two-level categorical variable interaction, a quadratic by three-level categorical variable interaction, and a cubic by two-level categorical variable interaction. In each section, he begins by using a
Chapter 12 expands on chapters 4 and 10 to explore piecewise by categorical interactions. Mitchell gives one-knot and two-knot examples, using gender as the categorical variable. He shows how to make various comparisons, including between- and within-gender comparisons of slopes, changes in slopes at knots, and changes in intercepts at knots. Adjusted means are also computed, with suggestions for automating graphs. (Here readers should see chapter 4 for a reminder of why the
Chapter 13 discusses two kinds of three-way interactions: linear by linear by categorical and linear by quadratic by categorical. Mitchell initially approaches these complex interactions by fitting separate regression models for each level of the categorical variable using
Chapter 14 examines categorical by categorical by continuous interactions. Here Mitchell interprets these interactions in terms of how the slope of the continuous variable varies, depending on the interaction of the two categorical variables. He forms contrasts with respect to this slope, examining simple effects, simple contrasts, and partial interactions.
2.4 Part IV: Some other types of models
In part IV, Mitchell introduces multilevel models, logistic regression, Poisson regression, and use of the
Chapter 15 covers multilevel models, wherein Mitchell introduces the Continuous by continuous Continuous (level-1 variable) by categorical (level-2 variable) Categorical (level-1 variable) by continuous (level-2 variable) Categorical by categorical
Chapter 16 covers longitudinal models with time as a continuous predictor. Mitchell acknowledges that several different approaches can be used to analyze longitudinal data, but as in chapter 15 he focuses strictly on multilevel models. He uses the
Chapter 17 covers multilevel models for longitudinal data with time as a categorical variable. Mitchell includes examples of time as the sole fixed effect, interacted with a two-level group variable, and interacted with a three-level group variable. The interactions are interpreted using techniques similar to those in earlier chapters on categorical interactions, such as partial interactions. Mitchell also discusses how to choose a residual covariance structure. New to this edition, the last section covers adjustment for small samples via the
Chapter 18 covers nonlinear models, including logistic, multinomial logistic, ordinal logistic, and Poisson models. Mitchell shows how the
Chapter 19 covers complex survey data. Using the
2.5 Part V: The appendices
Five appendices cover additional options, features, and ways to customize the output of focal commands covered in the book, including estimation commands
3 Suggestions for the future
We believe that Mitchell has accomplished what he set out to do. He has provided many examples of typical regression problems that arise in research and shown how to visualize and interpret the results. Nevertheless, we do have some suggestions about how to improve any future edition, starting with some suggestions related to Stata code.
3.1 Stata code
Our first suggestion is addressed to the wider Stata community, not just to Mitchell. It is conventional in Stata documentation and in books about Stata to show code that is copied from the output window rather than to show the code such as one might see in a do-file. Mitchell follows this convention. In most cases, it does not cause undue problems, but consider this example on page 76:

In our experience, students who are new to Stata transcribe the code as shown and are perplexed when it does not run (given the line numbers that are included in the output). This problem could be avoided if Mitchell showed do-file code instead. Presumably, it looks something like this:

A second suggestion about code is to show readers how to use the

We applaud the vertical alignment of the

Finally, we offer three more minor suggestions. Include the Rather than writing (output omitted), use the Show readers how to use the
3.2 The ibn and noconstant options
In chapters 11 to 13, Mitchell frequently uses the
Additionally, when
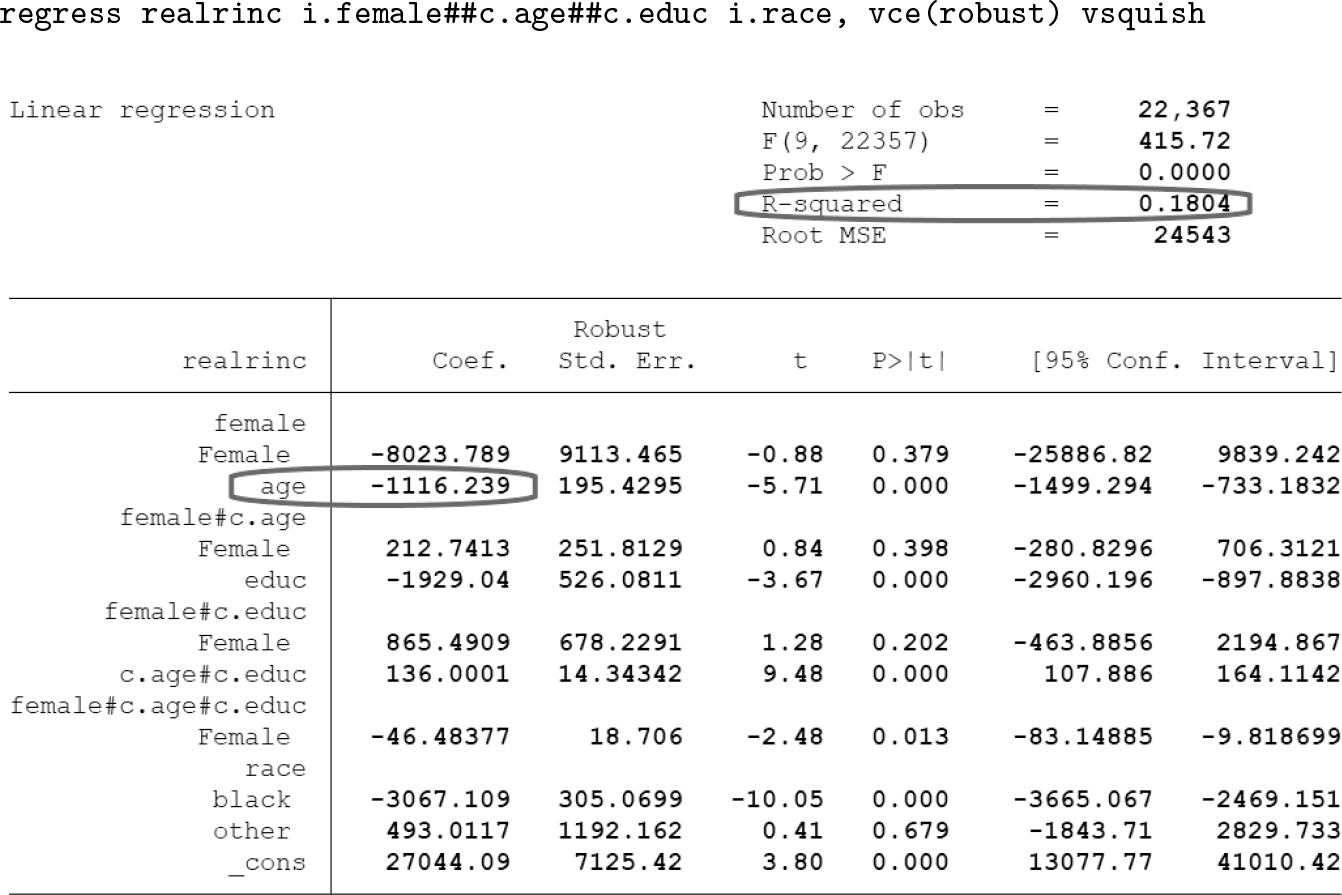
Compare this with Mitchell’s syntax and output for this example, repeated again here:
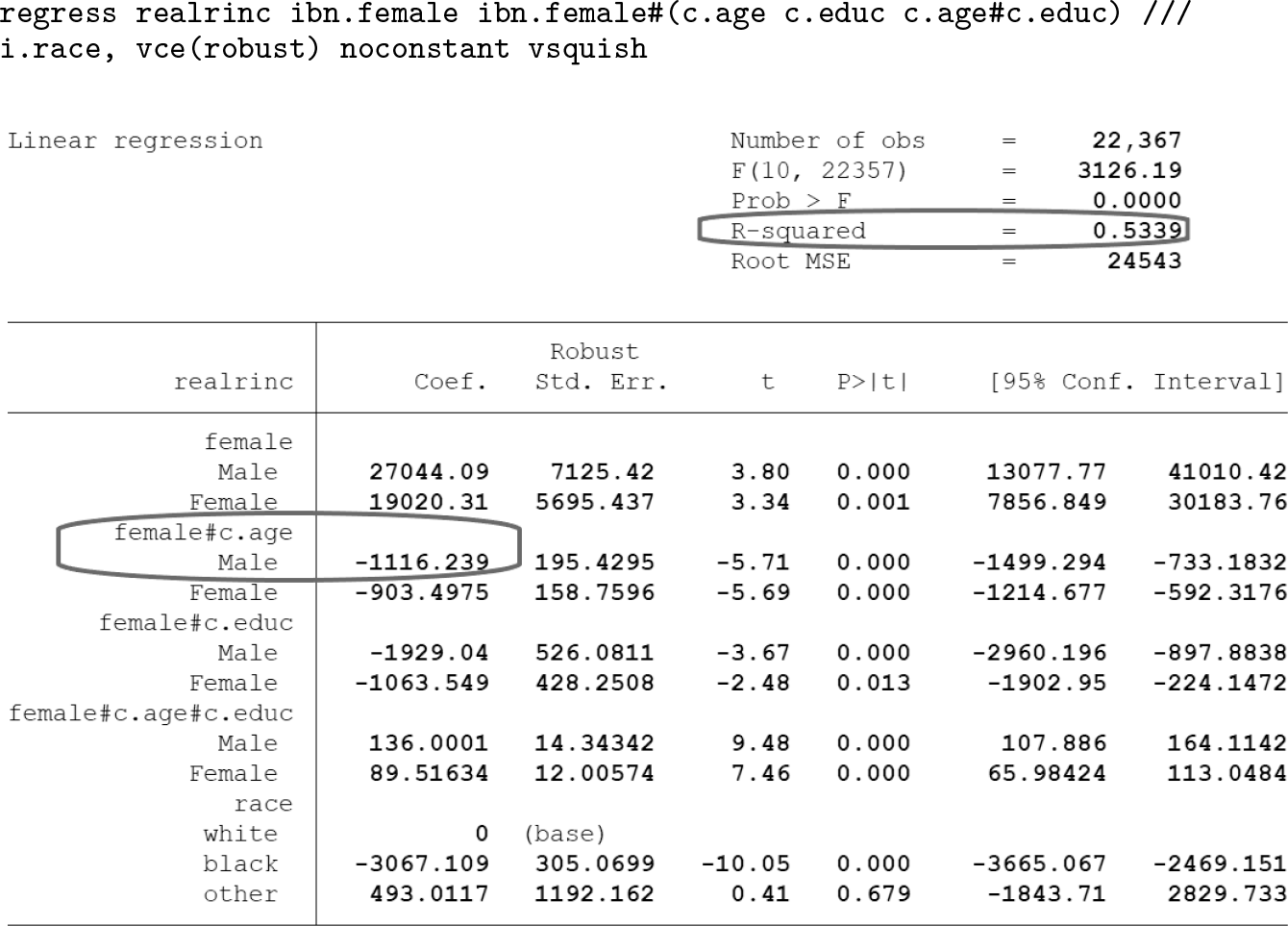
The lower-order effect for
Overall, we would suggest comparing the output of both approaches. It may also be helpful to direct the reader to more information on how this coding affects the regression output (for example, Higbee [2009]). One quick sentence is devoted to explaining the function of
3.3 Terminology
Imagine a regression model with explanatory variables A and B, as well as their product, A × B. In such a model, Mitchell frequently refers to the coefficients for A and B as showing the main effects of those variables. We suggest that the term “main effect” should be reserved for ANOVA models, where the main effect of A is the effect of A when one collapses across the levels of B. In a regression model, on the other hand, the coefficient for A shows the simple effect of A when B = 0 (or its reference category if it is categorical). To be fair, Mitchell does explain this to readers. Nevertheless, in the context of regression models, we recommend describing the coefficients for A and B as the first-order effects of A and B to avoid this potential confusion.
We also suggest that it could be helpful if Mitchell briefly mentioned the terms “moderated multiple regression” and “effect modification”. The latter term is commonly used in epidemiology and medical research, and the former term is commonly used in psychology and related fields. This might seem like a trivial suggestion, but it is motivated by the fact that a psychology student who had worked through all the examples in IVRMUS-1 believed that he had never fit a moderated multiple regression model. It is not difficult to imagine that an epidemiology student might similarly believe that she had never fit a model that addressed a question about effect modification.
In the same vein, the literature on moderation would likely describe the approach Mitchell takes to interpreting interactions as the pick-a-point, simple-slopes, or spotlight-analysis approach and contrast it to other approaches like the Johnson–Neyman technique. As with the relationship between the terms “moderation” and “interaction”, it might be worthwhile to point out that many of the examples in IVRMUS-2 are analogous to the pick-a-point approach readers might see elsewhere. Additionally, Mitchell’s examples can be easily extended to create what otherwise might be referred to as a Johnson–Neyman plot. For instance, chapter 5 explores an interaction between age and education (both continuous variables). The code below computes and graphs the slope of education for every value of age, highlighting the regions where the slope is statistically significant.

3.4 Reminding the reader about bad research habits
We find the discussion of three bad research habits (section 1.1—Read me first) vitally important. Otherwise, one might blindly follow Mitchell’s examples in each chapter until some sort of statistical significance is achieved. Students still learning about best research practices might be more prone to this, and as such it would be a good idea to flag these habits throughout the text. One way this is already done is when Mitchell uses the
3.5 Choosing values when probing interactions
When Mitchell interprets the effect of one predictor at specified values of another continuous predictor, the chosen values might seem randomly selected for the purpose of illustrating the example. Because readers might wonder which values to choose for their own analysis without conducting too many tests, it might be worth mentioning in IVRMUS-2 that often the choice of values to probe can be arbitrary, and this is sometimes noted as a drawback of the approach. Further, in these situations researchers sometimes choose to probe at the mean or certain percentiles (as recommended, for instance, by Hayes [2018], although sometimes no less arbitrary). Considering this, it would be worthwhile to use
3.6 Further explanations
Mitchell uses the
Finally, Mitchell uses the
3.7 Topics to add (or remove)
As noted above, we have used IVRMUS in a master’s-level statistics course for psychology students. In psychology and many other fields (for example, epidemiology), the hierarchical approach to building a regression model is quite popular. With that in mind, we believe that IVRMUS-2 would benefit from an example or two showing readers how to use the
Mediation analysis is also increasingly common in both psychology and epidemiology. It would be good, therefore, to have a short chapter showing how one can fit regression models via
4 Conclusion
As we noted earlier, Mitchell hoped that the examples shown in IVRMUS-2 would help readers understand the results of their own regression models and enable them to “interpret and present [their results] with clarity and confidence”. As our review shows, we do have some criticisms of the way Mitchell approached certain things, some suggestions for further aiding reader understanding, and some topics we would wish to see included in any future edition. But despite that, the second author has never regretted adopting IVRMUS-2 as the primary textbook for the master’s-level statistics course he recently taught for the fifth time. And the first author will continue to refer to IVRMUS-2 throughout her doctoral education and for years to come. In sum, we believe that Mitchell has achieved his objective admirably.
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063410 - Review of Michael N. Mitchell’s Interpreting and Visualizing Regression Models Using Stata, Second Edition
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063410 for Review of Michael N. Mitchell’s Interpreting and Visualizing Regression Models Using Stata, Second Edition by Angela MacIsaac and Bruce Weaver in The Stata Journal