
Abstract
In this article, we present commands to enable fixing the value of the correlation between the unobservables in Heckman models. These commands can solve two practical issues. First, for situations in which a valid exclusion restriction is not available, these commands enable exploring how the results could be affected by sample-selection bias. Second, stepping through values of this correlation can verify whether the global maximum of the likelihood function has been found. We provide several commands to fit these and related models with a fixed value of the correlation between the unobservables.
Keywords
1 Introduction
Heckman’s (1976, 1978) work on sample-selection and endogenous treatment models has been widely used in applied research. Convincing identification of these models requires an exclusion restriction (often referred to as an “instrument”), that is, a variable that affects selection or treatment but not the outcome directly. For many applications, a valid exclusion restriction is not available. Without a valid exclusion, identification of the model is only possible through the distributional assumptions placed on the model.
One approach to fitting a Heckman model without an exclusion restriction is to fix the value of the correlation between the unobservables in the selection and outcome equations (which we refer to as “rho”) at multiple plausible values. The idea is to treat rho as if it were unidentified rather than to identify it based on distributional assumptions. We can then see how the results are affected by the value of rho. As we discuss in the next section, we can think of rho as the degree of sample-selection bias. This approach was taken for endogenous treatment and sample-selection models by Altonji, Elder, and Taber (2005) and Chan and Cook (2020), respectively. Altonji, Elder, and Taber also propose using the correlation in observable characteristics to bound the possible values of the correlation in unobservable characteristics, which we do not discuss in this article.
We provide commands that enable fixing the value of rho and which are based on Altonji, Elder, and Taber (2005) and Chan and Cook (2020). This article’s commands have been used to address concerns about sample-selection bias when a valid exclusion is not available (as in Aobdia [2019]; Choudhary, Merkley, and Schipper [2019]; Downey, Bedard, and Boland [2020]; and Tran and Dinh [Forthcoming]).
Another benefit of fixing the value of rho is improved ease of maximizing the likelihood function. The likelihood functions for these models are known to be difficult to maximize. Zuehlke (2017) reports several instances in which authors have reported estimates that are not the global maximum of the likelihood function. The likelihood function is not globally concave, but if the value of rho is fixed, the likelihood is concave in the remaining parameters. Olsen (1982) suggests stepping through values of rho to find the global maximum of the likelihood function. Zuehlke notes that standard statistical software does not provide the option of maximizing the likelihood function in this manner. Rodemeier (2020) uses this article’s commands for this purpose.
We provide an example in section 4 of how to use these commands to step through values of rho to maximize the likelihood function. For this example, Stata’s
The next section reviews Heckman’s sample-selection model and discusses the effect of fixing rho. Section 3 provides the syntax for the commands that we are introducing. In this section, we also discuss related models, including endogenous treatment models. Examples are provided in section 4. Section 5 concludes.
2 Heckman’s sample-selection model
When the observations used for a regression are nonrandomly selected, there is a concern that selection could affect the results. In the classic example of regressing education on wage for married women, there is a concern that the decision to work may be affected by both education and unobserved factors. 1 The women with lower education who enter the workforce are those who expect higher wages. This self-selection can overstate the average wage for women with low education and bias the relationship between education and wage downward relative to the true causal effect.
We illustrate this effect in figure 1. Figure 1a presents a scatterplot and line of best fit for all observations (both observed and unobserved). A circle denotes that an instance was unobserved. Figure 1b removes the unobserved instances and adds a new line of best fit based on only the observed instances. The line of best fit from figure 1a is also presented for reference. Selection has decreased the slope of the line of best fit. An important point is that sample selection is a problem of bias, not of generalization to a wider population.
(b) Only selected observations

Illustration of the effect of sample selection
The approach developed by Heckman (1976) to combat these concerns is to jointly estimate the selection and outcome processes. We begin by defining latent outcome and selection variables,


where

We refer to (1) as the “outcome equation” and (2) as the “selection equation”. We are assuming a linear relationship between the latent variables and the regressors
We observe an indicator for selection, si , and outcome, yi , defined as

The value of yi when si = 0 is arbitrary and unimportant because these values will not be used for estimation. The parameters of interest (β, γ, σ, and ρ) can be estimated by maximizing the likelihood function

where φ(·) and Φ(·) are the standard normal density and distribution functions and 1(A) is the indicator function, which takes a value of 1 if the event A is true and a value of 0 otherwise. Stata’s
2.1 Fixing the value of ρ
For the observed data, the expected value of the outcome is

The term ɸ(·)/Φ(·), known as the inverse Mills ratio, follows from the bivariate normality assumption that was placed on εi
and ui
. An insight from Heckman (1979) is that sample-selection bias can be thought of as an omitted-variable bias, where the omitted variable is the inverse Mills ratio. Naively regressing yi
on

where
We first discuss the role of fixing the value of ρ on identification, and then we turn to the problem of maximizing the likelihood function. For discussing identification, it is useful to contrast this model to semiparametric sample-selection models. The inconsistency of Heckman’s estimator in the presence of nonnormal errors (as shown by Arabmazar and Schmidt [1982] and Robinson [1982]) inspired the creation of several semiparametric estimators. These estimators relax the bivariate normality assumption to accommodate a broader class of bivariate distributions. While Heckman’s parametric estimator is identified even when
To be clear, throughout this article, we refer to the exclusion restriction as “valid”, meaning that the excluded variable or variables do not affect the outcome directly. It may be tempting to simply omit a variable from the outcome equation so that the model has an excluded variable. This approach, however, can result in estimates that are worse than those obtained by ordinary least squares (Wolfolds and Siegel 2019). 2
The assumption that the unobservables follow a bivariate normal distribution, which is required for identification without an exclusion restriction, is generally untestable without a valid exclusion restriction. To identify the distribution of εi , we need to identify β. The coefficients β could be estimated using a semiparametric estimator, but these estimators require a valid exclusion restriction.
Regarding finding the maximum of the likelihood function, once the value of ρ is fixed, Stata can easily find the values of the other parameters that maximize the likelihood function. If we step through different values of ρ, we can see where the likelihood function is maximized. This can be used to verify that the results returned by
Having discussed both a sensitivity test and a method for finding the maximum of the likelihood function, there are two points that should be made explicit. First, one should not step through values of rho to maximize the likelihood function when a valid exclusion restriction is not available. While exploring how the results differ for different values of ρ illustrates how sensitive the results are to the degree of sample-selection bias, this procedure cannot be used to reliably estimate the value of ρ when there is no exclusion restriction. Second, for situations in which an exclusion restriction is available, to get the correct standard errors and p-values, Stata’s
3 Syntax
This section provides the syntax for the eight commands that we are introducing:
In this section, we also provide a brief overview about the relevant models that are fit with the Stata commands
3.1 Heckman’s sample-selection model
Syntax for heckman_fixedrho
We now present the syntax for the first command,
Options for heckman_fixedrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
maximize_options control the maximization process. Options include
Syntax for heckman_scanrho
We now present the syntax for the next command,
Options for heckman_scanrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
maximize_options control the maximization process. Options include
We now turn to discussing related models that can be thought of as extensions to the sample-selection model discussed above. Our discussion of each is brief, but we provide references for the reader wishing to gain more information.
3.2 Bivariate probit with sample selection
For an outcome that is binary instead of continuous, it is straightforward to extend the model above (as was done by Van de Ven and Van Praag [1981]). We maintain the latent variables in (1) and (2) and the selection indicator in (3):

But now we define the observed outcome as

The likelihood function is

Syntax for heckprobit_fixedrho
In Stata, the command
Options for heckprobit_fixedrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
maximize_options control the maximization process. Options include
Syntax for heckprobit_scanrho
We now present
Options for heckprobit_scanrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
maximize_options control the maximization process. Options include
3.3 Endogenous binary regressors
Heckman (1978) tackles the problem of endogenous binary regressors using a similar strategy as that of sample selection. The problem is stated in terms of the observed variables:


where

The likelihood function can be expressed as
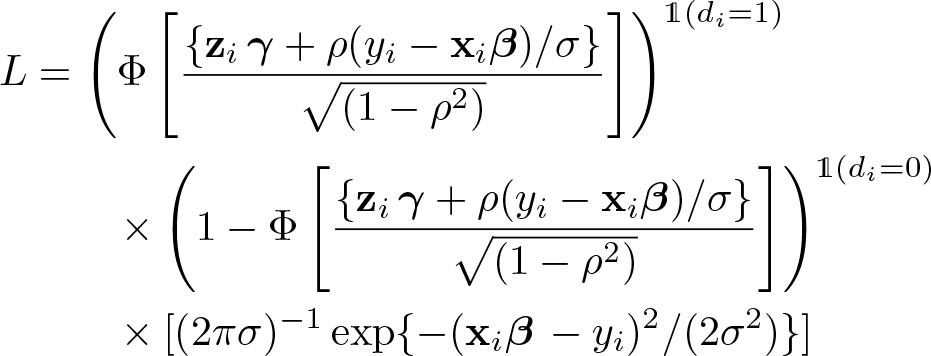
This problem can also be expressed in the context of the Neyman–Rubin potential-outcomes framework.
In the potential-outcomes framework, those receiving a treatment have the outcome
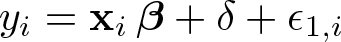
whereas those not receiving the treatment have the outcome

The parameter δ is the average treatment effect after removing the confounding effects of treatment assignment, which Heckman (1990, 314) calls the “experimental treatment effect”. In this potential-outcomes framework, the outcome and treatment can still be expressed as in (4) and (5), but the error term in (4) is defined as
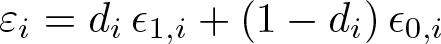
The variances of ∊
1
,i
and ∊
0
,i
and their correlations with ui
may differ. In Stata, the command
Syntax for etregress_fixedrho
The syntax for our command
Options for etregress_fixedrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
maximize_options control the maximization process. Options include
Syntax for etregress_scanrho
The syntax for
Options for etregress_scanrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
maximize_options control the maximization process. Options include
3.4 Bivariate probit
This next model (known as a recursive simultaneous-equation model) is not actually an extension of Heckman but was developed independently of Heckman’s work (see Maddala and Lee [1976]). We include this model in our discussion because it bears a similarity to the aforementioned models. We begin with (4) and (5) but now interpret (4) as a latent variable:
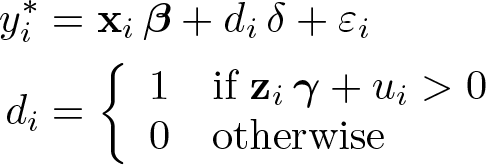
We denote the latent outcome as

The econometrician observes di and the outcome
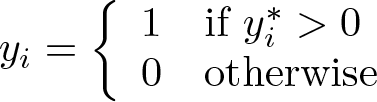
Syntax for biprobit_fixedrho
In Stata, the command
Options for biprobit_fixedrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
equations.
maximize_options control the maximization process. Options include
Syntax for biprobit_scanrho
Finally, we provide the syntax for
Options for biprobit_scanrho
depvar_s should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation.
maximize_options control the maximization process. Options include
4 Examples
The help file for each command provides some examples of the syntax. In this section, we discuss the application of these commands.
Identification without an exclusion restriction
Our first example considers bounding the potential effect of sample selection when we do not have a valid exclusion restriction. We use Mroz’s (1987) well-known dataset of married women’s wages in the 1970s. Some of the women in this dataset do not work, and thus there is no observed wage for these women. Our interest is in the effect of education on wage.
We can load this dataset by typing
Suppose that we want to regress log wage (
For this regression, assume that we do not have access to a variable that affects the decision to enter the workforce but that does not affect wages directly.
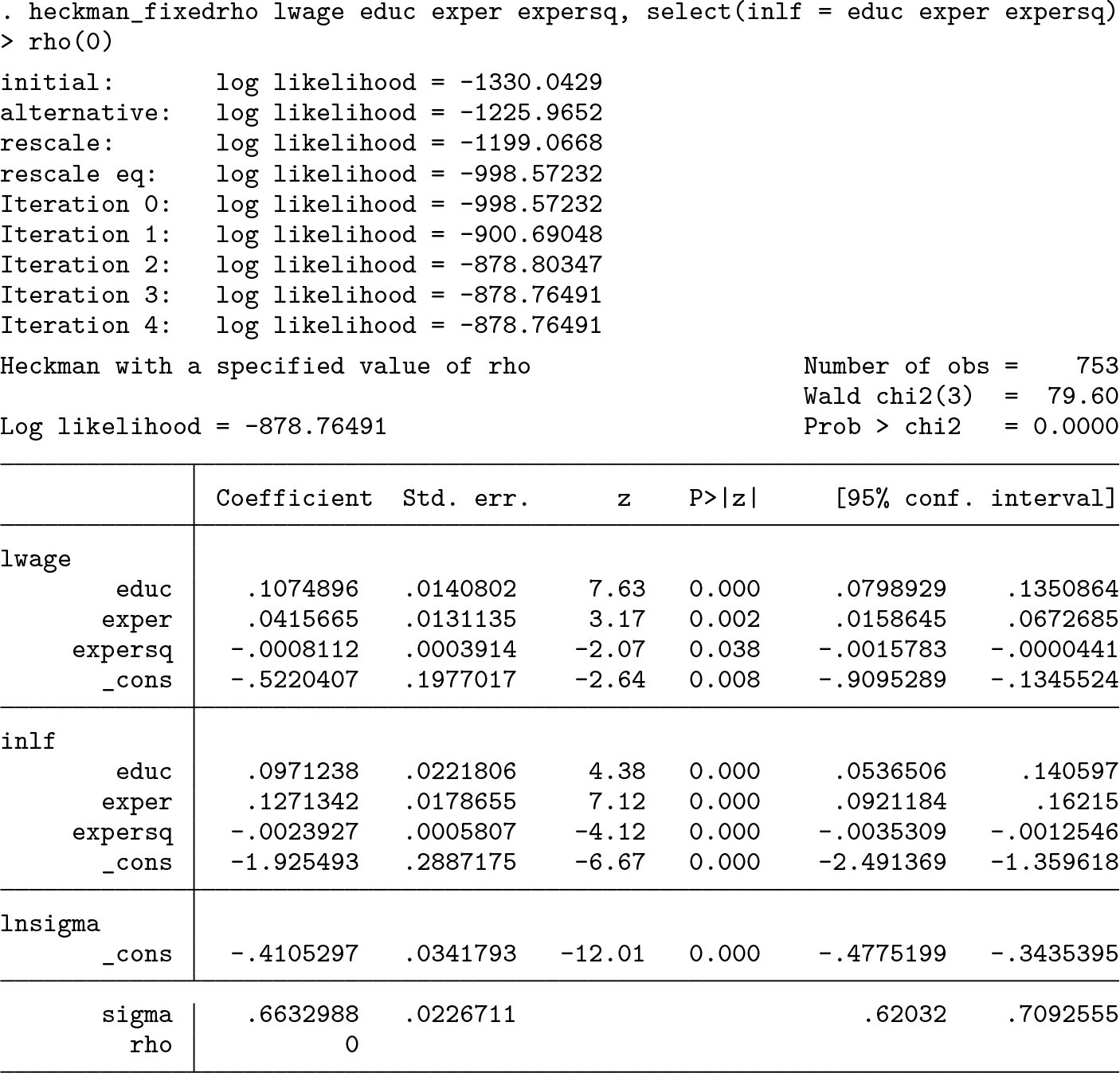
Let us begin by examining the results when ρ is 0, that is, when there is no bias for linear regression:
On the other extreme, we can see the results that would be found when fixing ρ at 0.99:
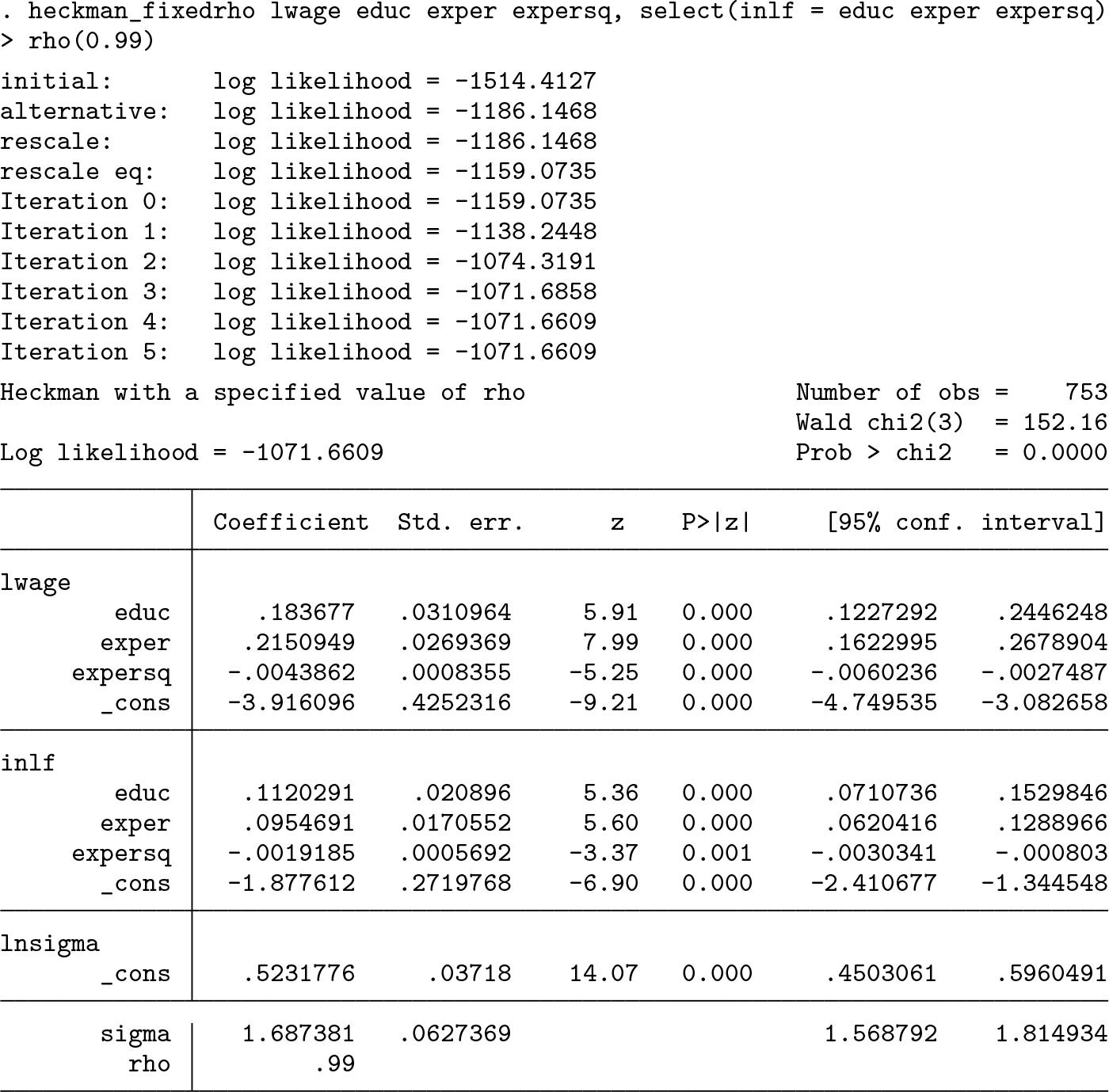
The coefficient on
Seeing the possible values of the coefficient for different values of ρ provides bounds on the true value of the coefficient. In figure 2, we plot the estimated coefficient on

The estimated coefficient for various values of ρ
Finding maximum likelihood estimates
Our next example is a situation in which we have a valid exclusion and want to verify that we found the (true) maximum likelihood estimate. We use the specification from Zuehlke (2017), for which an author had reported a local rather than a global maximum of the likelihood function.
We begin with the Mroz dataset used in the previous example. We now use the data on family income (
Set up by loading the dataset and creating two new variables:

Call

It is strange that Stata has reported a negative value of ρ; our intuition tells us that this should be positive.
Next we use

The resulting plot is presented in figure 3. There is a root at ρ = −0.07, which is the result reported by Stata. The global maximum is around ρ = 0.89. Also note the difference in the log likelihoods reported for these two estimates. At the global maximum of 0.89, the log likelihood is −1, 518.58, whereas at −0.07 it is −1, 579.50.
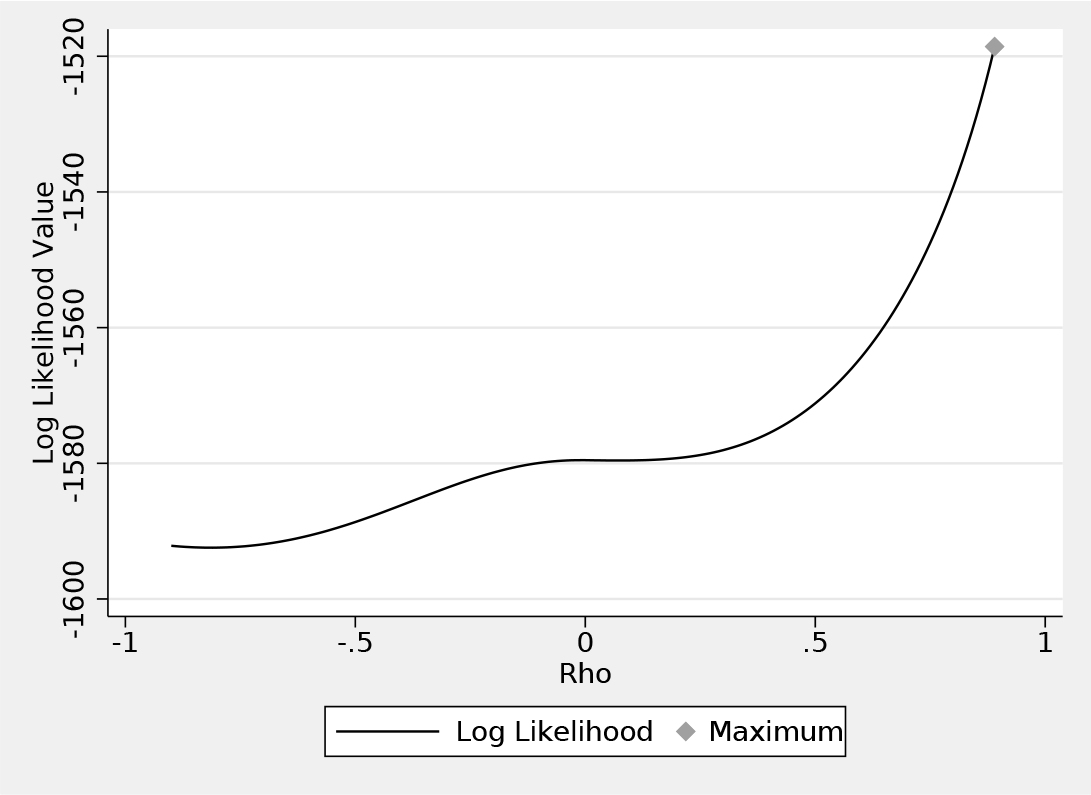
The value of the log-likelihood function for various values of ρ; the dot indicates the point at which the likelihood is maximized
By default, the step size is set to 0.01. It may be advisable to use a smaller step size to obtain a more accurate estimate. This may be especially helpful if the results of
We can find the correct standard errors by setting initial values for Stata’s
We first save this matrix:
We then pass this matrix to

We are confident that these are the true maximum likelihood estimates from the plot in figure 3. Note that
Comparing heckman estimates with those of heckman_fixedrho
Finally, we want to mention the differences between

We now call

The coefficients between these two are noticeably different. The source of difference is the maximization procedure being employed. The procedure used by
5 Discussion and conclusion
Several extensions of this work are possible. We maintained the bivariate normality assumption in all of these models. This could be relaxed in several ways. Altonji, Elder, and Taber (2005) use Heckman and Singer’s (1984) approach for allowing for deviations for normality, which involves treating the stochastic terms as having a discrete component. Modeling the stochastic terms as a mixture of normals would also allow for some deviations from normality.
Another extension would be to change the maximization procedure used. Stata has several options for maximizing likelihood functions, which differ in whether derivatives of the likelihood functions are provided. The maximization methods that we used do not use any information about derivatives of the likelihood function. As a result, there may be specifications for which
The commands that we presented can be used to examine the sensitivity of regression results to sample selection or endogenous treatment and to verify that the results of a Heckman model are the global maximum of the likelihood function.
6 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063149 - On identification and estimation of Heckman models
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063149 for On identification and estimation of Heckman models by Jonathan Cook, Joon-Suk Lee and Noah Newberger in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
7 Acknowledgments
Jonathan Cook thanks Victor Jarosiewicz, Arshad Rahman, Sarah Wolfolds, Thomas Zuehlke, and an anonymous referee for helpful comments.
The views expressed in this article are the views of the authors and do not necessarily reflect the views of the authors’ employers or any other entities with which the authors may be associated.