
Abstract
Social scientists frequently rely on the cardinal comparability of test scores to assess achievement gaps between population subgroups and their evolution over time. This approach has been criticized because of the ordinal nature of test scores and the sensitivity of results to order-preserving transformations that are theoretically plausible. Bond and Lang (2013, Review of Economics and Statistics 95: 1468–1479) document the sensitivity of measured ability to scaling choices and develop a method to assess the robustness of changes in ability over time to scaling choices. In this article, I present the
Keywords
1 Introduction
With enrollments at a historical high for low- and middle-income countries, the focus in education has shifted away from enrollment and toward improving quality of education (World Bank 2018). Countries around the world are focusing on both increasing learning and closing substantial gaps across subpopulations, particularly in favor of disadvantaged groups. These gaps have been extensively documented in the United States, where much literature has identified stubborn test score gaps by sex (Bertrand and Pan 2013; Fryer and Levitt 2010), socioeconomic status (Reardon 2011, 2013), and race (Hanushek and Rivkin 2006; Clotfelter, Ladd, and Vigdor 2009; Fryer and Levitt 2004, 2006, 2013).
Gap measurement is essential to make inferences about equitable learning. What is surprising, though, despite the seemingly large gaps across subgroups, is that different studies often come to different conclusions. For instance, Fryer and Levitt (2004) first noted that a substantial black–white test score gap that had received extensive attention in the literature (see Coleman et al. [1966]; 1 Kaufman and Kaufman [1983]; Krohn and Lamp [1989]; Phillips et al. [1998]; Phillips [2000]) disappeared after controlling for covariates. Additionally, they found that over the first four years of school, blacks lose about −0.10 standard deviations per year compared with other races. Bond and Lang (2013) then demonstrated that even this seemingly rock-solid racial gap in the United States is not robust to arbitrary scale transformations. That is, transformations that minimize or maximize learning by weighting test items differently, while still preserving order, create lower and upper bounds that are too wide to be informative or definitive.
These findings contribute to an ongoing debate around test score measurement, particularly on whether the assumptions that justify cardinality are satisfied in most tests (Ballou 2009; Ho 2009; Bond and Lang 2013; Jacob and Rothstein 2016). Three alternatives have been proposed. The first is to argue that the test at hand has been constructed in a manner that allows for cardinal measures of ability; this is the approach of the Rasch measurement, and Domingue (2014) provides statistical methods to verify the assumptions required for cardinality. The second is to give up on cardinality entirely and focus only on ordinal comparisons. Reardon et al.’s (2017)
A third approach, which this article focuses on, is to assess the robustness of findings to arbitrary scaling choices as proposed by Bond and Lang (2013). Specifically, their method builds on the idea that any monotone transformation of an ordinal scale is rank preserving and is therefore an equally valid measure of the underlying variable. They present an optimization method that searches for monotone transforms that minimize and maximize test score gaps, thus allowing researchers to provide bounds to their estimates of test score evolution across subgroups over time. 2 Here I extend their technique to more general cases and optimize their algorithm to work with large datasets. This allows for the simulation of multiple monotone transforms several times and bound differences by choosing transformations that maximize or minimize differences between subgroups.
2 Robustness to scaling
The ordinal nature of test scores implies that any monotonic transformation to a test score scale is potentially valid. We see this concept applied when colleges arbitrarily put more weight on grades from “harder” classes for admission purposes or when, within a particular test, a teacher decides that one question is worth more points because it is more “challenging”. Thus, when comparing test scores, we can ascertain only that someone with a high test score performed better than someone with a low one. It is much more difficult to know by how much. Standardizing test scores, which is the most common scale transformation, does not solve this issue. In fact, any analysis that relies on comparing standardized test scores implicitly assumes that test scores are interval scales. This assumption means that, in a scale from 0 to 100 points, the difference in underlying knowledge between individuals who scored 0 and 10 points is the same as that of those who score 90 and 100 points. In reality, this is seldom the case because there is no theoretical justification for this assumption; most exams have questions with varying levels of difficulty and use scales that are arbitrary in their mean, range, and distribution. Without interval scale properties, mean differences and standard deviations can be distorted depending on the weight each question receives.
Even when we equate test scores using item response theory, most of the time the underlying
An assumption that is more reasonable and appropriate in most settings is that test scores are ordinal. Unlike temperature and distance, where the magnitude of a given difference corresponds to the same underlying measurement at different parts of the distribution, test score differences of the same “magnitude” can mean very different things at different points of the distribution. The only inference that we can make between someone with a score of 90 points and another person with a score of 100 is that the individual with a score of 100 demonstrated a larger amount of underlying knowledge or ability than the individual who scored 90.
Bond and Lang (2013) noted that the current literature does not adequately ensure that results are robust to scaling transformations and devised a methodology to find bounds for estimates measuring differences in test scores across subgroups and over time, such as the black–white test score gap in the United States. In particular, they created an algorithm that finds the upper and lower bounds for the estimates of differences in test scores across two subgroups at two points of time. To do so, they transform test scores using a sixth-degree polynomial monotonic transformation and optimize over the test score gap growth (that is, the difference in test scores between two subgroups in t 0 minus the difference in t 1) to make it as large or small as possible.
In the next section, I describe the step-by-step methodology developed by Bond and Lang (2013) and how the
3 The scale_transformation command
3.1 Bond and Lang (2013) methodology
The Bond and Lang (2013) methodology tests the robustness to scaling of subgroup differences using arbitrary monotone transformations of an underlying ability or test score distribution. Relying on sixth-degree polynomial transformations, the original code tries to minimize or maximize the differences in test score growth between any two subgroups. These growth-minimizing and growth-maximizing transformations present lower and upper bounds, respectively, of the differences between subgroups.
Step-by-step methodology
1. Define the objective function as
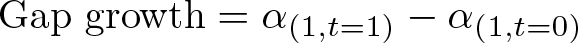
where α (1,t) is the difference in test scores between groups at time t (see step 2d for more details on how to obtain α (1,t)). Note that test scores need to be already vertically equated. That is, they should be completely comparable and mapped into a single scale regardless of the time in which they were captured.
2. Optimize the following function over the defined objective: Take the original test scores, and scale them down to be between 0 and 1 (for computational speed). Transform original test scores (s) using a sixth-degree polynomial monotonic transformation T(s), optimizing over the gap growth by choosing five coefficients (β
2
, β
3
, β
4
, β
5, and β
6) and one constant (c) for the polynomial transformation:
Standardize transformed test scores in both periods (that is, t
0 and t
1) together. The original Bond and Lang (2013) code standardizes test scores separately, which could artificially increase or decrease the resulting gap. By jointly standardizing both years, we ensure that they remain vertically equated and that the resulting gap is only due to the transformations. Run an ordinary least-squares regression separately for each period using a subgroup dummy and controlling for other desired variables. Given this setup, the coefficient on the subgroup dummy can be interpreted as the difference between each subgroup.
Find the gap growth between t
0 and t
1, as defined in step 1.


3. Run step 2 multiple times from different random starting values, checking that transformations preserve order (monotonic rule).
3.2 Improvements
The process described in section 3.1 is complex and computationally demanding. Most of the original public code is written in Mata, which might restrict its wider use among researchers. Furthermore, the public code was written for the specific estimation in their article. Thus, it makes some assumptions that might not necessarily extrapolate to other data and might affect the speed or magnitude of the results. This left space for two areas of improvement: 1) making the methodology more accessible to Stata users and 2) improving the precision, flexibility, and efficiency of the methodology.
In terms of accessibility, the
Methodologically, the original process also sacrificed precision for efficiency. For instance, the parameter β
1 was not optimized, and the monotonicity rule used did not check every single plausible value but rather checked monotonicity in small, equally spaced intervals. The
Specifically, the original methodology has been improved by computing more accurate estimates (in quad precision) using QR decomposition tools in Mata. The monotonicity rule has also been enhanced to be more accurate and flexible with three variants: 1) a default rule that checks for monotonicity at every possible score value up to four decimals within the plausible range in a transformed scale between 0 and 1; 2) a quick rule that checks for monotonicity only at the unique score values present in the sample data; and 3) a theoretical rule that checks for monotonicity at every possible value using an external file. The last is of particular value if test scores come from a larger dataset that has scores for multiple years (that are not included in the optimization) or includes scores for subgroups not being analyzed. Furthermore, other options such as time-specific controls and weights have been included, as well as options to specify the number of times the command will run (yielding different results), the optimization methodology to be used at certain stages of the process, and the maximum number of iterations before the optimization cycle stops and returns results as if convergence were achieved.
Another important improvement of the
Finally, other robustness checks used by Bond and Lang (2013) have been added to the command. In particular, the
3.3 Description
The
A sixth-degree polynomial monotonic transformation is used because it provides flexibility to approach numerous continuous functions. Nevertheless, monotonicity checks need to be applied because this type of transformation does not necessarily preserve order. Furthermore, the monotonicity restriction introduces a discontinuity into the objective function that creates multiple local maximums and minimums. These characteristics yield a complex optimization problem that does not have a closed-form solution.
The
3.4 Syntax
3.5 Options

3.6 Optimization objectives
Gap growth: gap difference between the bottom and top groups from the option Correlation: coefficient from regressing test scores in period 1 on test scores in period 2 (no controls allowed).
R-squared: from regressing test scores in period 1 on test scores in period 2 (no controls allowed). Controls explanation: measures how much gap growth coefficients change when including controls in
4 Resulting output
4.1 Example
In this section, we use

Note that, given the above command, the command will run 40 times from different initial parameters and that each time, the command will report convergence after 15 iterations, performing a “sample” monotonicity check. Given the option
Figure 1 shows the resulting dataset from the gap growth maximization example above. The missing values for the optimization object and transformation coefficients (that is, columns 1 through 8) correspond to transformations that are not order preserving. Thus, they are omitted in the final dataset.

Resulting dataset from example
For this particular example, we can also plot the original and transformed scores to understand what the command did. Because we are searching for the gap growth maximization (that is,
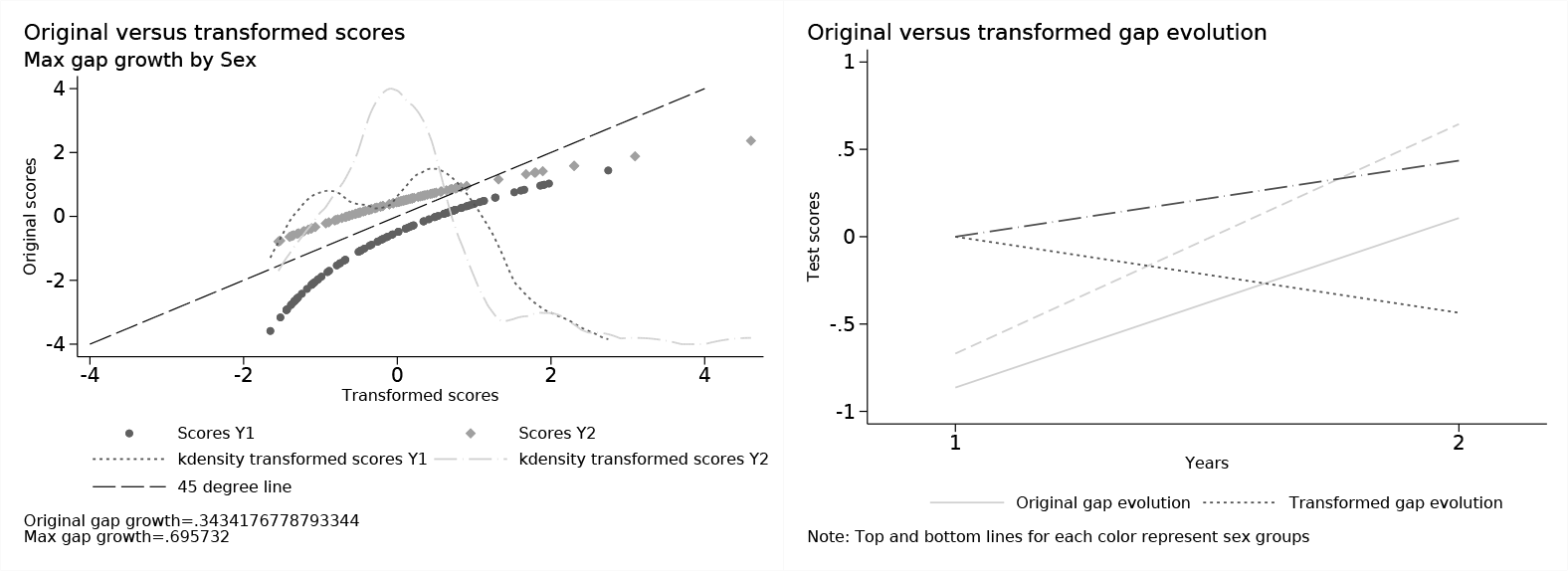
Original versus transformed scores
Note that the original gap magnitude was 0.343418, about half the size of the transformed gap. These results are particular to this specific scenario, and in practice the algorithm might behave differently depending on the data and the objective function at hand.
4.2 Interpretation
Regardless of the optimization object chosen, the resulting dataset has a similar structure. Each row contains the results for one simulation. The
For the gap growth maximizing and minimizing options, one should be aware that the command finds the most extreme transformations, some of which might be extremely unlikely (although theoretically plausible). Thus, for instances where the bounds are too wide, it might be useful to benchmark against likely transformations (such as those found by the
5 Conclusion
One simple step that researchers can take to address some of the challenges of scaling and the ordinal nature of test scores is to test the robustness of their results to changes in the test score scales. The
When using the
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045574 - Test scores’ robustness to scaling: The scale_transformation command
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045574 for Test scores’ robustness to scaling: The scale_transformation command by Andres Yi Chang in The Stata Journal
Footnotes
6 Acknowledgments
I am grateful to Jishnu Das for his constant guidance, feedback, and encouragement to publish this article. I also thank Timothy Bond and Kevin Lang for their correspondence during the development of the article and command, as well as to Benjamin Daniels for his diligent feedback. Financial support for this research was made available through the World Bank Group Research Support Budget RSB714 grant. The findings, interpretations, and conclusions expressed in this article are those of the authors and do not necessarily represent the views of the World Bank, its executive directors, or the governments they represent.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Alternatively, install from the Statistical Software Components Archive:
You can also find the latest version of the program at
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.