
Abstract
In this article, we describe the
Keywords
1 Introduction
The two-regime switching regression models have been widely used in applied economic analysis, such as in the estimation of the earnings equations for unionized and nonunionized workers or in the estimation of wage equations of subjects employed in the private sector and in the public sector (Lee 1978; Lee and Trost 1978). Researchers have adopted several estimation methods to obtain estimates of the coefficients of the outcome equations in both regimes. The model is usually extended, and a further selection equation is included. Within this framework, maximum likelihood (ML) methods (Poirier and Ruud 1981; Maddala 1983) and two-stage procedures (Heckman 1976, 1990; Lee 1978) provided estimated coefficients of the outcome equations and of the selection equation, including variances of the error terms and covariances between the errors of the outcome equations and the selection equation. 1 In such models, the selection equation allows one to identify the choice of the regime (the decision of the agent of belonging to regime 1 or to regime 2) supporting the two outcome equations. The estimation of the outcome equations in both regimes accounts for the endogenous effect of the selection by introducing, in the respective regressors set, a correction term obtained by the “generalized residuals” of the selection equation, estimated at a first stage.
In general, the two-stage method was recognized as consistent and computationally feasible. The ML approach also considers the same three-equation set, simultaneously estimating all parameters.
However, these methods did not provide the estimation of the parameter measuring the correlation between the error terms of the two outcome equations, the so-called across-regime correlation (or covariance). The reason is that this parameter is not empirically identifiable because of the selection rule specifying a two-regime switching model, in which the dependent variable referred to an observation cannot be jointly observed in both regimes.
Despite the difficulty in identification, some “knowledge” about this parameter was considered relevant in terms of interpretation of the agent’s behavior in an endogenous switching model (see Heckman and Honoré [1990] and Vijverberg [1993]). The across-regime correlation measures the correlation in unobserved productivity (ability) of the subject in both regimes (or sectors). The traditional estimation methods allow estimating the cross-correlation parameter only “indirectly”, based on the estimate of coefficients and variances, and applying the relationships among the errors’ second-order moments as in Maddala (1983, 223–228) and in French and Taber (2010).
Differently from these approaches, which provide an “indirect” estimation of the across-regime correlation parameter, Calzolari and Di Pino (2017) suggested that identification and direct ML estimation of the across-regime correlation parameter are possible if the model specification is closer to the traditional Roy model rather than its more widely used generalized versions. The model is specified as “two equation”, implying a sort of “rational” behavior of the agent, who simply chooses the regime with the higher outcome. For each individual, the contribution to the likelihood is given by the probability density of the observed (larger) outcome and by the (conditional) probability that the alternative (censored) outcome has a smaller value.
This approach allows us to obtain a reliable simultaneous point estimation of both the outcome equations without introducing a further selection equation explaining the choice of the subject, such as in the specification of the “generalized” Roy model (for example, Carneiro, Hansen, and Heckman [2003]). This allows us to obtain more efficient estimates than those provided applying two-stage estimation methods. 2
In this article, we describe the
In the next section, we briefly discuss the properties of the across-regime correlation coefficient and its relevance for economic analysis. In section 3, we provide a brief description of the methodology and model specification.
Because our full-information approach relies on the assumption of normality of the error terms in each regime, we also provide a postestimation command to verify the hypothesis of normality of the error terms in both regimes (
In section 4, we describe the
To provide a comparison with the
2 Relevance and empirical content of the across-regime correlation coefficient
In many cases, the two-regime switching models extend the Roy model of self-selection to include the decision rule adopted for selecting into different regimes. For example, the two-regime wage’s model of self-selection aims to explain the workers’ occupational choice and its consequences for the distribution of earnings when individuals differ in their endowments of specific skills (see Heckman and Honoré [1990]; Vijverberg [1993]). In doing this, one should obtain information about the joint distribution of the potential (counterfactual) outcomes. A relevant parameter of such a distribution is the across-correlation coefficient, ρ 12. 3
Heckman and Honoré (1990) proved that the identification of the joint distribution of potential outcomes is essential to the empirical content of this model. As shown by these authors, if the ρ 12 coefficient is identified, one can, by adopting a two-regime specification as in a Roy model, estimate the population distribution of potential outcomes knowing only the outcomes of subjects observed into one of the two regimes.
The sign of the across-regime correlation, in particular, allows us to know more in detail what criterion the agents follow to select the regime. Considering a wage model in a public or private sector choice, for example, a positive sign of ρ 12 signals that the agents, supported by their own skills, manage to gain a higher-than-average level of outcome in both regimes. Thus, one of the two sectors (public sector) absorbs most of the above-average productive workers.
At the opposite, a negative sign of ρ 12 means that the agent has different skills in each regime, and he or she chooses the regime in which he or she is more productive. In this case, the workers are absorbed by the sector in which they gain a comparative advantage in terms of productivity. This condition generally increases the segmentation of the labor market.
An example on the use of ρ 12 to obtain information about the skills of the agents is provided by Calzolari and Di Pino (2017), who estimated the time devoted to domestic work by employed and unemployed women in Italy. In this case, a positive sign of ρ 12 indicated that common latent factors positively influence the domestic work supply of women in both regimes. This result led to the conclusion that employed and unemployed women do not have different skills regarding their commitment in domestic work.
Some studies showed that a knowledge of the ρ 12 coefficient supports methods for obtaining the predictive distributions of outcomes and, consequently, an estimation of the treatment parameters (average treatment effect, average treatment effect on the treated) measuring outcome gains from program participation. Poirier and Tobias (2003), in particular, showed how the entire distribution associated with these gains can be obtained in certain situations if the ρ 12 coefficient is, at least in part, identified.
Along this line, Fan and Wu (2010) provide sharp bounds to obtain a partial identification of the correlation coefficient of the potential outcomes, their joint distribution, and the distribution of treatment effects.
The aforementioned studies on the use of two-regime switching models adopt partial information on the ρ
12 coefficient to derive predictive distributions. Instead, an important result achieved by applying the estimator implemented by the
3 Methodological issues
Calzolari and Di Pino (2017) specified an endogenous switching model with two regression equations whose dependent variables (outcomes) are mutually exclusive in a cross-sectional framework and where selection is simply based on the choice of the larger outcome.
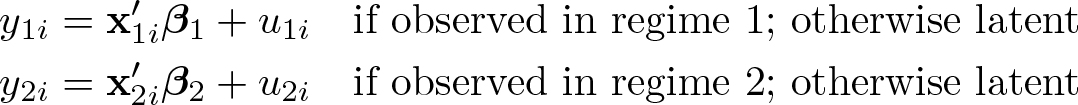
The agent is assumed to behave rationally; thus, if y 1 i > y 2 i , then y 1 i is observed and y 2 i is latent; otherwise, y 2 i is observed and y 1 i is latent.
A relevant characteristic of this model is that the two dependent variables, y 1 i and y 2 i , are explicitly factors in the choice of the regime. For each individual, y 1 i − y 2 i represents the net gain (or net loss) from the choice between two options.
The error terms u
1
i
and u
2
i
, given by

Hence,

where φ(·) is a normal probability density function.
We consider also the CMs of the error terms; namely,
Therefore, in (1) we have the probability that an agent does not belong to regime 2, under the condition that he or she chooses regime 1:

Analogously, in (2) we have the probability that an agent does not belong to regime 1, under the condition that he or she chooses regime 2:
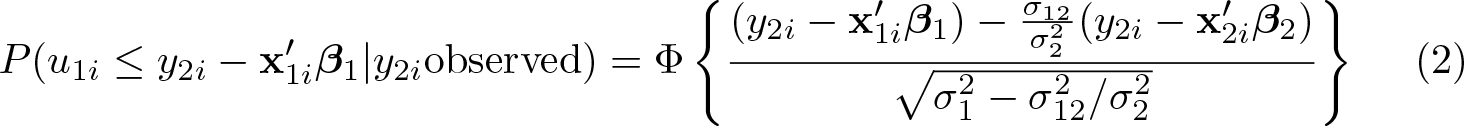
Φ(·) is the standard normal cumulative distribution function used to specify, in both (1) and (2), the contribution to the likelihood of censoring, respectively, y 2 i and y 1 i .
Therefore, given the conditional probabilities (1) and (2), we finally obtain the following contribution of the ith observation to the log likelihood,

with
3.1 A CM test of normality for a two-regime switching model
The ML estimator critically relies on the assumption of normality of the error terms of both equations. As a complement to the estimation procedure, we implement a CM test to verify the normality assumption. The proposed test procedure extends, to the two-equation case, the CM test available in the literature to verify the normality assumption in the context of the tobit model (for example, Skeels and Vella [1999]). In particular, the test is based on the comparison of the third and fourth moments of u 1 i and u 2 i with the theoretical values implied under the assumption of normally distributed error terms. Absent censoring, we could write
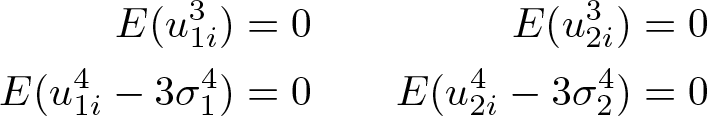
However, these equalities cannot be satisfied on the “observed” part of each regime, because of censoring.
The CM test is built by considering the following observed residuals:
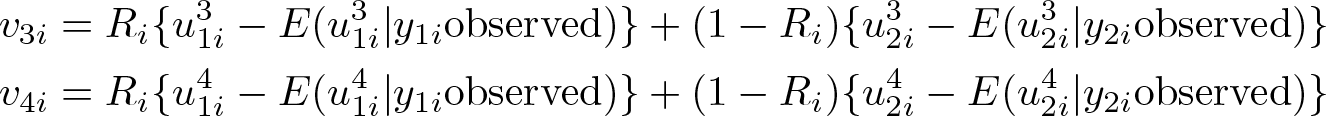
The moment conditions that we exploit to verify the normality assumption can therefore be written as

with v 3 i and v 4 i including powers of the observed residuals in regime 1 and regime 2 as defined before.
For observations in regime 1, we can write

Analogous formulas hold for observations in regime 2:

To perform the computations related to the testing procedure, we also need to evaluate the following CMs:

Focus on the computation related to u 1 i ; an analogous formula applies for u 2 i .
Under the assumption of joint normality of u 1 i and u 2 i , we note that the difference δi = u 1 i − u 2 i is also normally distributed. Thus, u 1 i can be written as a linear function of δi plus an independent error term,
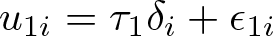
with ϵ
1
i
normally distributed, independent of δi
, and τ
1 = cov(δi, u
1
i
)/var(δi
). It holds that

The two expected values can be computed by exploiting the recursive formula that characterizes the moments of a truncated normal distribution (see, for example, Chesher and Irish [1987, 40]) and exploiting the independence of ϵ 1 i and δi (see also Pfaffermayr [2014]).
The computation in
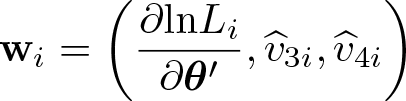
with

with
4 The mlcar command
4.1 Syntax
The dependent variable depvar is recorded across two regimes, as identified by the variable specified in the (required) option

It is assumed that the individual chooses the regime with the highest outcome; that is,

The variances of the error terms of the outcome equations are
4.2 Options
If
If
If
maximize_options specifies the options of the Stata command
4.3 Postestimation
The postestimation command
The following options are allowed to compute these conditional and unconditional expectations:

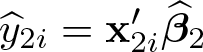


After
5 Examples
We illustrate the use of the
Still on page 6, three lines before the end or the page, in the expression of the conditional variance, σ 12 should be squared.
At the top of page 7, after (10), the lines 2 and 3 should be written as “Analogously, the probability of a subject not belonging to regime 2 under the condition that he or she chooses regime 1 is given by [equation (11) follows].”
In (10), (11), and (12) parentheses have been incorrectly applied to the denominators, that should be, respectively,
In appendix A, lines 5 and 6 should be rewritten as : “
Finally, between the two lines of (12), there was the sentence “if y 1 i is observed (regime 1); otherwise it is”, but the entire sentence was erroneously canceled.
5.1 Example 1
In the first example, we use


The outcome of interest is


Null hypothesis of normality of the errors is rejected. In this application, the set of regressors is not the same for both regimes, so we specify both the option
The option
The first panel of the output of
The estimation results show that the impact of the yearly worked hours on earned income is generally positive and stronger for nonunionized workers than unionized workers. Among the latter, the effect of worked hours is strongest for those who do not perform office work. Education exerts a positive influence on labor income of nonunionized workers. Finally, in both union and nonunion regimes, work experience exerts a positive influence on labor income, albeit with decreasing rates of growth.
The across-regime correlation,
We obtain a cross-correlation parameter with a negative sign (ρ 12 = −0.18) even if we apply the indirect procedure of the two-step Heckman estimation (appendix A). The model’s estimation results after the two-step Heckman estimation are reported in appendix B.
5.2 Example 2
In the second example, we use

The outcome of interest is
In this second example, we used the same covariates for both regimes. Thus, the list of variables is specified only in
As for the results of the estimates, we can observe that married people who are also associated with an IRA pension plan are generally more willing to participate in the 401k plan. In addition, the results show that income availability and married condition jointly affect the propensity to set aside financial assets and participate in the 401k plan. The availability of financial assets is positively correlated with age for those who choose to join the 401k plan; the opposite occurs for those who do not join the 401k, whose financial assets decrease with increasing age.


The null hypothesis of normality of the errors is rejected. The estimated acrossregime correlation,
5.3 Example 3
In this example, we use

In this example, the outcome of interest is
The basic syntax for


The null Hypothesis of normality of the errors is not rejected if we consider a nominal test size of 0.05 when the asymptotic formula is considered and a nominal size of 0.01 when the simulated version of the test is computed.
As for the estimation results, note in particular that women’s wage is lower than that of men in both regimes, especially if the women work outside the service industry. We did not obtain analogous results by performing a two-stage Heckman procedure (see appendix B).
The estimated across-regime correlation,
If we fit the model by performing a two-stage Heckman procedure, the value of
6 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025834 - Maximum likelihood estimation of an across-regime correlation parameter
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025834 for Maximum likelihood estimation of an across-regime correlation parameter by Giorgio Calzolari, Maria Gabriella Campolo, Antonino Di Pino and Laura Magazzini in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
A Indirect identification of across-regime covariance in a two-regime switching model
As shown above in section 3, adopting the two-equation ML method, the across-regime covariance is identified and estimated simultaneously with the regression coefficients and errors variances. Unlike this approach, that of previous two-regime switching models with a selection equation, generally following a two-stage procedure (Heckman 1976, 1990; Lee 1978), provided only an indirect identification (and a “gross” estimation) of the across-regime covariance. In the applications proposed in section 4, we compare the estimates applying both our two-equation ML method (![]() .
.
In a two-regime switching model, the error terms u
1
i
and u
2
i
are assumed to be normally distributed with zero mean and variances equal to
Then, the random variable vi/σv
is distributed as a standard normal. In this way, reparameterizing as
Hence, we can obtain an indirect estimation of the covariance σ
12 estimating preliminarily σv
2
. In doing this, we use the predicted values of the selection equation,
To estimate
and
Then, estimating
B Heckman two-stage estimation results
We show below the results of the Heckman two-stage estimation applied to the three examples of two-regime models exposed in section 4.4. In doing this, we describe more in detail the procedure, using the Stata command, to obtain the indirect
C Monte Carlo experiments on the mlcartestn procedure to test normality
Monte Carlo simulations allow us to evaluate the performance, in finite samples, of the proposed testing procedure (see section 3.1), implemented by the ![]() to check the properties of the two-equation ML estimator.
to check the properties of the two-equation ML estimator.
The simulated two-regime model is specified as follows:
The explanatory variables, x
1
i
and x
2
i
, are both generated from a normal distribution with mean 50 and variance 100. The error terms, u
1
i
and u
2
i
, are random variables with zero mean and variance, respectively,
Then, to simulate the presence of a large cross-correlation, we set the across-regime correlation alternatively with positive (ρ 12 = 0.90 and σ 12 = 28.4605) and negative signs (ρ 12 = −0.90 and σ 12 = −28.4605). We also simulated estimation and testing performance by setting absence of across-regime correlation (ρ 12 = 0).
We checked the performance of the testing procedure assuming normally distributed errors and, alternatively, accounting for some cases of misspecification given by the violation of the assumption of normality. To this end, we simulated error terms that deviate from the normal distribution in terms of higher kurtosis following Student t distributions with 9, 30, and 100 degrees of freedom, although the errors distributed as a Student t (100) reproduce the case in which the kurtosis is closer to the normality condition.
We also simulated the model whose error terms deviate from normality because of the presence of asymmetry. To this purpose, we generate error terms following a Skew Normal distribution (for example, ![]() ]) with the Shape parameter, α, equal to 5 (generally involving a level of skewness close to 0.8–0.9).
]) with the Shape parameter, α, equal to 5 (generally involving a level of skewness close to 0.8–0.9).
Summing up, we simulate several data-generating processes (DGPs) based on (5) and (6) under different distributive assumptions on the errors, accounting for, respectively, positive, negative, and null cross-correlation between the errors of the two equations:
Covariance matrix under positive cross-correlation: (ρ 12 = 0.90):
Covariance matrix under negative cross-correlation: (ρ 12 = −0.90):
Covariance matrix in absence of cross-correlation: (ρ 12 = 0):
In the following ![]() , we report the simulation results, given by the means of the empirical test sizes obtained setting several DGPs, under different assumptions of the errors distribution.
, we report the simulation results, given by the means of the empirical test sizes obtained setting several DGPs, under different assumptions of the errors distribution.
The results reported in ![]() show that the CM test, implemented with the command
show that the CM test, implemented with the command
If we simulate DGPs following normal or Student t(100) distributions, the results of empirical test size are consistent to the nominal size fixed for the rejection of the null hypothesis of normality.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.