
Abstract
In this article, we describe
1 Introduction
Unit nonresponse rates in household socioeconomic surveys have been increasing over the last decades (Meyer, Mok, and Sullivan 2015). Unit nonresponse is problematic for the measurement of inequality and poverty when response is not random, especially when it is related to the variable of interest.
There is evidence that household income systematically affects survey response. Using the current population survey (CPS) of the United States, Bollinger et al. (2019) show that nonresponse increases in the tails of the income distribution. This empirical evidence rejects the ignorability assumption (the fact that nonresponse is random within some arbitrary subgroup of the population). Moreover, they show that approximately one-third to one-half of the difference in inequality measures between the survey and administrative data (tax records) is accounted for by nonresponse.
Korinek, Mistiaen, and Ravallion (2007, 2006) show how the latent income effect on compliance can be consistently estimated with the available data on average response rates by groups (for example, geographic areas) and the measured distribution of income across them. This strategy has been recently used with data of several countries (see Hlasny and Verme [2018a,b] and Hlasny [2020]). In this article, we present
This article is organized as follows. In section 2, we describe the methodology. In section 3, we describe the
2 Methodology
As described in Korinek, Mistiaen, and Ravallion (2006, 2007), the proposed method has two main advantages: First, it does not assume that within the smallest subgroup the decision to respond is independent of income (ignorability assumption). Second, it relies only on the survey data and does not require any external information.
Here we sketch how the estimator is derived. We start by assuming that the probability of response denoted by P (Dⲉ
= 1), where Dⲉ
is an indicator function equal to 1 when the household ⲉ responds, depends on a K-vector
For a given group j ∊ J, the mass of respondents with a given value of

where mij
is the total (unobserved) number of households with a value of

where the last equality comes from the fact that the probability of response for a given value of

where the right-hand side corresponds to the observed total mass of sampled households in group j. To complete the moment condition, we need to assume a functional form for Pi , which we assume to be a logistic function such that

where

Finally, the estimator is constructed by stacking the J sample moment conditions into Ψ(

where
The variance of the estimator

with

Alternatively, the variance can be computed using a bootstrap by randomly sampling J groups with replacement and applying the estimator to each sample. After a given number of repetitions, the bootstrapped variance is computed as the average squared deviation of the bootstrapped estimates from the original estimate. This method is computationally intensive because it needs to solve the minimization problem again for each bootstrapped sample. Nevertheless, it can be easily implemented by using the commands
3 The kmr command
3.1 Syntax
The syntax of the
varlist includes the determinants of the response rate.
3.2 Options
3.3 Stored results

In addition, the command optionally generates four new variables: the predicted probability of compliance, the upper and lower values of its 95% confidence interval, and corrected survey weights.
3.4 Dependency of kmr
4 Empirical example
To illustrate the use of

where yi corresponds to log of total household gross income per capita in current dollars. 3
We begin by loading the dataset and looking at the state-level geographical variation in nonresponse rates in the United States. We can use the community-contributed command


Nonresponse rates
Now, we can create the regressors and two sets of weights that have no correction for nonresponse. The first set corresponds to using the raw data (in other words, no weights or weights equal 1). The second set assumes equal weights within states (“grossed-up” weights by state), in which weights are constructed by dividing the population of each state (as derived by summing the official CPS weights) by the number of respondents: 4

We can estimate the probability of response as a function of the log of total household gross income per capita, produce a line graph of it together with its 95% confidence interval, and generate a set of corrected weights called

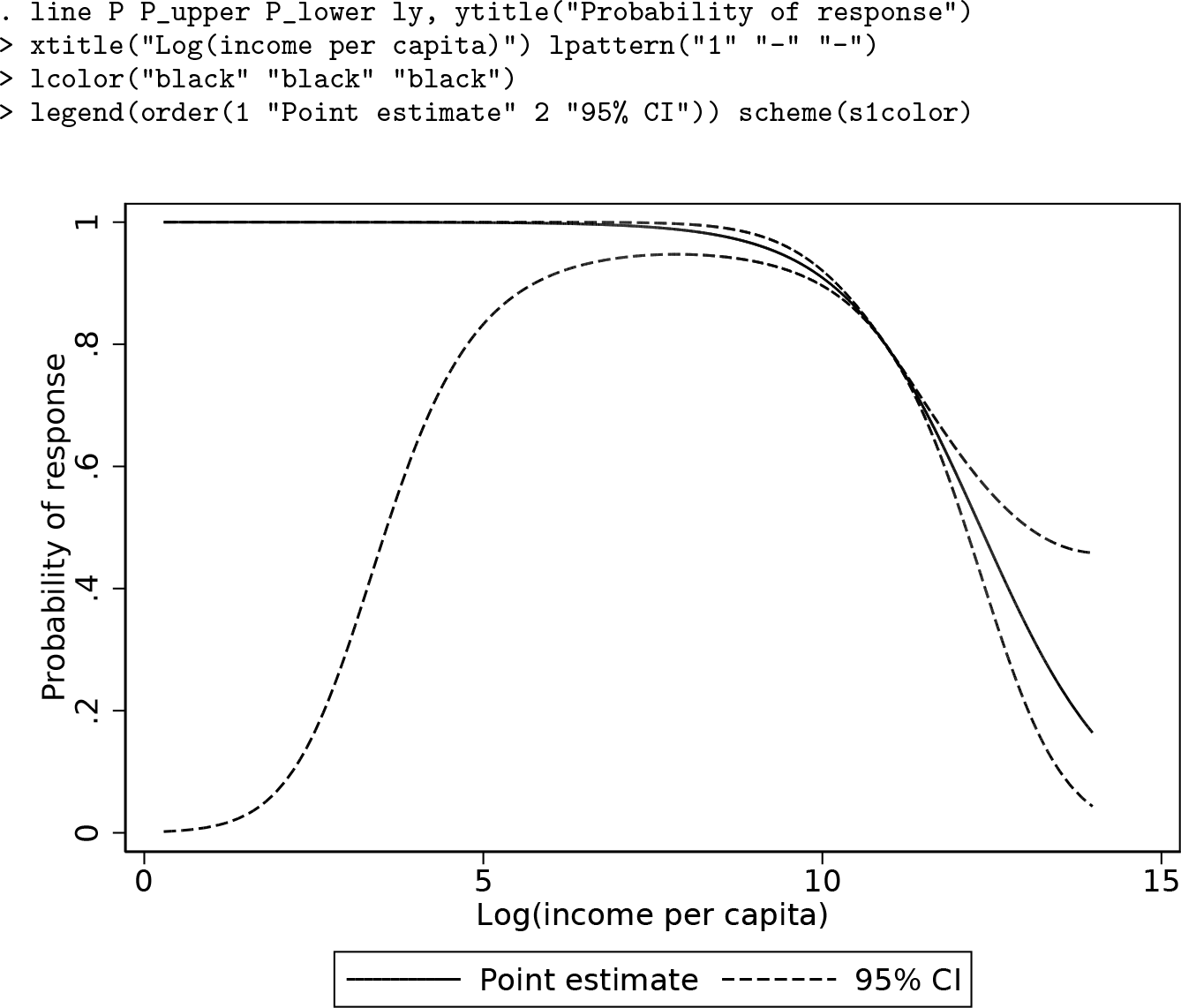
Compliance function
Now, we try a different specification that adds the squared log of income per capita as a second regressor. This will help to capture the fact that high nonresponse rates may occur in both tails of the income distribution, not just among rich households, as documented in Bollinger et al. (2019).
The inclusion of the log of income squared does capture some nonlinearity of compliance with respect to income. However, the estimates appear to be less precisely estimated (two of the coefficient’s p-values are below 5% confidence level). Moreover, the Akaike criterion suggests that the linear specification is preferable.
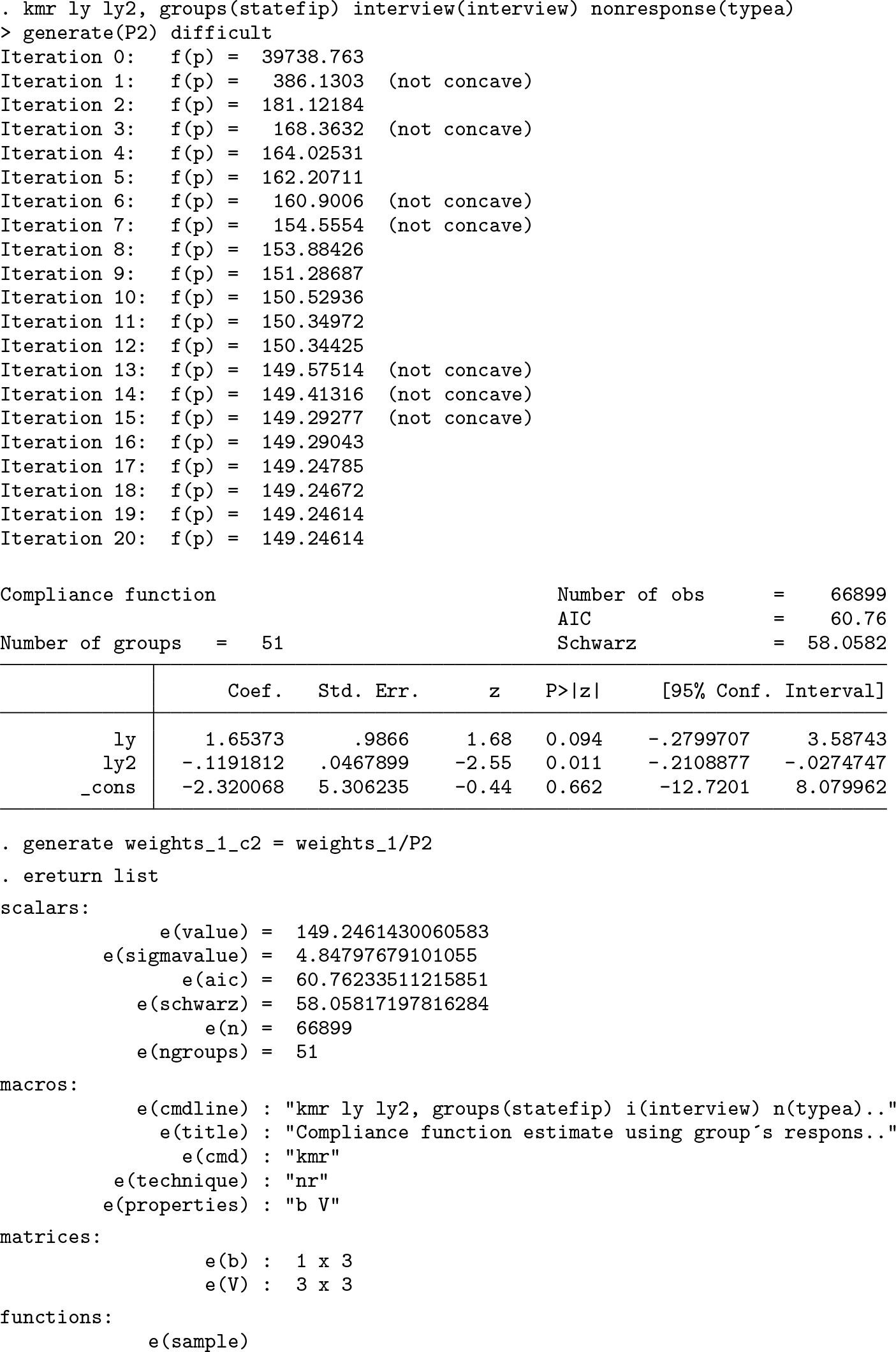

Compliance function quadratic on log(income)
As we mention at the end of section 2, we can also compute the standard errors using bootstrap. We do so by defining a small program called


From the results of the bootstrap exercise, we find a level of uncertainty surrounding the parameter estimates that is similar to the standard errors previously reported, although the confidence interval is slightly wider.
Finally, we can use the community-contributed command


In our exercise, we derive a range of values for our corrected Gini coefficient using the point estimates of the compliance function and its upper and lower bounds derived from the 95% confidence interval (row
We can summarize the results as follows. The use of sample weights does not significantly change the Gini coefficient compared with the use of unweighted data (comparing the two rows,
5 Conclusion
Unit nonresponse in household surveys could lead to biases in inequality and poverty measurement. The typical methods to correct survey weights for unit nonresponse assume ignorability within some arbitrary subgroup of the population, which recent empirical evidence suggests may not hold in the case of household survey data.
In this article, we presented the
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000025 - kmr: A command to correct survey weights for unit nonresponse using groups’ response rates
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000025 for kmr: A command to correct survey weights for unit nonresponse using groups’ response rates by Ercio Muñoz and Salvatore Morelli in The Stata Journal
Footnotes
6 Acknowledgments
We thank Carolyn Fisher for comments on the draft and Anton Korinek for providing a MATLAB code with the dataset used in their article, which greatly facilitated this project. We are also grateful for the insightful and critical comments received by two anonymous referees, which pushed us to improve the structure of the article.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.