
Abstract
The blopmatching estimator for average treatment effects in observational studies is a nonparametric matching estimator proposed by Díaz, Rau, and Rivera (2015, Review of Economics and Statistics 97: 803–812). This approach uses the solutions of linear programming problems to build the weighting schemes that are used to impute the missing potential outcomes. In this article, we describe
1 Introduction
In this article, we provide an introduction to the “blopmatching” estimators for average treatment effects proposed by Díaz, Rau, and Rivera (2015) and describe
The blopmatching approach imputes the missing potential outcome to each unit as a weighted average of observed outcomes of the units with opposite treatment, where the vector of weights is the solution of a nested pair of optimization problems. The first of these optimization problems looks for the weighting schemes that build the “synthetic covariate” defined by Abadie, Diamond, and Hainmueller (2010). Geometrically, the synthetic covariate is the projection of the covariate vector of the unit that needs imputation onto the convex hull of covariate values of the units with opposite treatment.
However, although the synthetic covariate is unique, this first optimization problem often has multiple solutions because there might be several weighting schemes building the synthetic covariate. To overcome this issue of multiplicity of solutions, the “second optimization problem” proposed by Díaz, Rau, and Rivera (2015) implements a refinement criterion for choosing one of the weighting schemes that solves the first optimization problem. More precisely, it chooses the solution that uses the covariate values of units with opposite treatment that are as close as possible to the covariate value of the unit needing imputation. Thus, blopmatching selects the weighting scheme that maximizes the unit-level covariate balance and, simultaneously, uses the units with opposite treatment with closest covariate values.
Because in the blopmatching approach the counterfactual units and the weighting scheme are determined by solving an optimization problem, it does not need an arbitrary rule to fix these parameters ex ante, a crucial aspect of most of the nonparametric approaches currently available in the literature. 1 Finally, as Díaz, Rau, and Rivera (2015) point out, the two optimization problems involved in the blopmatching approach can be collapsed into a single linear programming program, which allows us to implement this estimator by using standard linear programming techniques.
This article is organized as follows. Section 2 presents the blopmatching estimator of average treatment effects where, in addition to presenting the general framework, a simple example illustrates what the blopmatching estimator does. Section 3 shows the procedure to estimate the marginal variances of the blopmatching estimator of average treatment effects. Section 4 details the specific method to solve the aforementioned linear program. Section 5 explains the
2 Blopmatching estimator of average treatment effects
2.1 A motivating example
A simple example may be illustrative of what blopmatching does. Suppose that there are three units that are exposed to the control treatment (“control” units), whose observed outcomes are Y 1 = Y 1(0), Y 2 = Y 2(0), Y 3 = Y 3(0) and whose real valued covariates (continuous) are X 1, X 2, and X 3, such that X 1 < X 2 < X 3, so that the convex hull of these covariates is the closed interval [X 1 , X 3] ⊂ ℝ. Moreover, suppose that a unit that is exposed to the active treatment (“treated” unit) has observed outcome Y 4 = Y 4(1) ∊ ℝ and covariate X 4 ∊ ℝ. Without loss of generality, we can assume that X 4 ≠ Xj, j = 1, 2, 3. Here the goal is to estimate the treatment effect on this fourth unit, that is, Y 4(1) − Y 4(0), but the crucial complication is that Y 4(0), the outcome of the treated unit under control treatment, is not observed. How does the blopmatching estimator impute the missing potential outcome Y 4(0)?
Let Proj(X 4) be the projection of X 4 onto the closed interval [X 1 , X 3], that is, the nearest element of that interval to X 4. That projection is the synthetic covariate as defined by Abadie, Diamond, and Hainmueller (2010). Notice that when X 4 < X 1, then Proj(X 4) = X 1; when X 3 < X 4, then Proj(X 4) = X 3; and when X 4 ∊ [X 1 , X 3], then Proj(X 4) = X 4.
Regardless of the specific value of the projection, we notice now that the convex combinations of covariate values of control units generating Proj(X
4) use vectors of weights

Because in general there are multiple vectors

Problem (2) is the first optimization problem used in the blopmatching estimator. Note that, with any weighting scheme solving this problem, we are attaining the best possible covariate balance or, alternatively, we are explaining the covariate of the treated unit through the covariates of the control units as best as possible. However, because there are more than one weighting scheme attaining the best possible covariate balance, a refinement criterion should be implemented to choose one of them. In doing this, we notice that any vector

The second optimization proposed by the blopmatching aims to minimize this function among the solutions of the first optimization. Hence, using (1) we see that this problem can be posed as the next linear program in terms of weights:

It is clear that when X
4 < X
1, then the solution of (3) is

Thus, the blopmatching estimator imputes the missing potential outcome of the treated unit as

Lastly, the blopmatching estimator of the unit-level treatment effect that we wanted to estimate is given by
2.2 General framework
The binary program to be evaluated is defined by the collection

where N is the number of units, i) N
0 > 1 and N
1 > 1, ii) Wi
= 0 for i ∊ {1,…, N
0}, and Wi
= 1 for i ∊ {N
0 + 1,…, N}.
Condition ii states that the first N
0 units of the sample are control units, while the remaining N
1 = N − N
0 are the treated ones. Under condition ii, the covariate vectors of the control units are
We are interested in estimating the average treatment effect (ATE) of the program, that is, τ =
Throughout, the Simplex of dimension n ∊ ℕ is denoted as

with
For a treated unit i ∊ {N 0 + 1,…, N} whose Yi (0) needs to be estimated, the blopmatching method uses the vector of weights that solves the next linear programming program, a straightforward extension of (3) to a higher dimension of the vector of covariates,

where || · || denotes a given norm in the underlying vector space and Proj(

Let

A completely analogous procedure can be presented when the unit needing imputation belongs to the control group, that is, when i ∊ {1,…, N
0} and Yi
(1) needs to be imputed. Specifically, for that case,
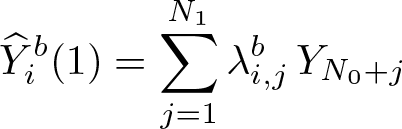
Having imputed all the missing potential outcomes, we define the blopmatching estimators of the ATE and the ATT as follows:

We highlight that, to impute the missing potential outcome of any unit, the blop-matching approach does not exclude a priori any unit with opposite treatment. We also highlight that the blopmatching approach does not need to fix an exogenous number of neighbors, a crucial tuning parameter in most nonparametric approaches (see Imbens and Wooldridge [2009]).
We note now that for a treated unit i ∊ {N
0 + 1,…, N}, the observed outcome of control unit j ∊ {1,…, N
0} participates in the realization of
We end this section saying that, under the assumption of strong ignorability and some additional mild conditions, Díaz, Rau, and Rivera (2015) prove that the blop-matching estimators of the ATE and ATT are consistent. We recall that the assumption of strong ignorability holds if two conditions are satisfied: unconfoundedness, which means that the treatment assignment and the potential outcomes are conditional independent given covariates (this condition is also known as selection on observed covariates); and positivity, which means that the conditional probability of being treated given covariates is strictly above zero and strictly below one (this condition is also known as overlap in the propensity score). See chapter 12 in Imbens and Rubin (2015) for a detailed discussion on observational studies under strong ignorability and chapter 21 for a procedure to assess the plausibility of this assumption in practice.
3 Estimating the marginal variance
Díaz, Rau, and Rivera (2015) propose consistent estimators of the variances of

where Proj
⋆
(

where || · ||2 is the Euclidean norm in ℝ N 1 − 1.
For i ∊ {1,…, N
0}, a completely analogous procedure can be implemented to obtain an estimator of the conditional variance σ
2(

where
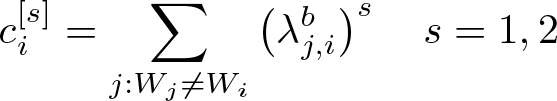
that is, the sum of weights, to the power of s, corresponding to unit i when i is used to impute the missing potential outcomes of units in the group with opposite treatment.
4 Implementation
This section presents our strategy to solve (4). Because of the similar nature of both (4) and (6), this procedure can be accommodated to solve the linear programs given by (6) and estimate the marginal variances of the treatment-effect estimators.
To solve (4), we first need to obtain the projection of

Let
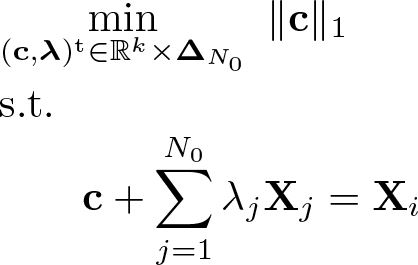
Denoting

implying that
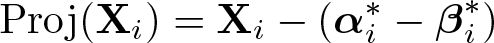
with

where
In the following,

It is clear that the (2k + N
0)-column of matrix

Hence, by using the basic feasible solution above, we can solve (8) by the revised Simplex method, which gives the vector Proj(
Having found Proj(
We observe now that

We observe also that any solution

Identifies
5 The blopmatch command
5.1 Syntax
ovar is a binary, count, continuous, fractional, or nonnegative outcome of interest. omvarlist specifies the covariates in the outcome model. omvarlist may contain factor variables; see [U]
tvar must contain integer values representing the treatment levels. Only two treatment levels are allowed.

5.2 Stored results

5.3 Example
We illustrate the use of

Table 1 describes all variables in this dataset.
Description of all variables in

Now we use
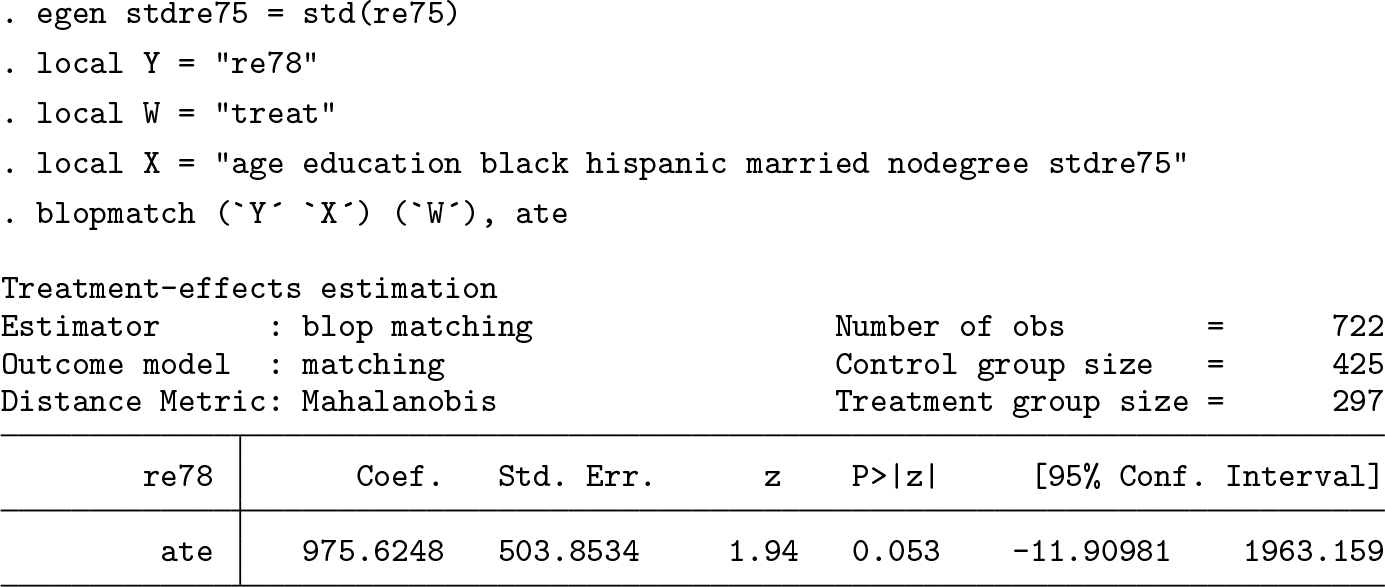
Thus, the ATE of the National Supported Work Demonstration on postintervention earnings is 975.6 USD (of 1978). In contrast, the ATE estimated with

Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000021 - Implementing blopmatching in Stata
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000021 for Implementing blopmatching in Stata by Juan D. Díaz, Iván Gutiérrez and Jorge Rivera in The Stata Journal
Footnotes
6 Acknowledgments
The authors gratefully acknowledge financial support from ANID PIA/APOYO AFB180003 and from FONDECYT-Chile, grant number 1130468.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
You can also install this package from GitHub by typing the following commands:
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.