
Abstract
Suppose that a population, composed of a minority and a majority group, is allocated into units, which can be neighborhoods, firms, classrooms, etc. Qualitatively, there is some segregation whenever allocation leads to the concentration of minority individuals in some units more than in others. Quantitative measures of segregation have struggled with the small-unit bias. When units contain few individuals, indices based on the minority shares in units are upward biased. For instance, they would point to a positive amount of segregation even when allocation is strictly random. The command
Keywords
1 Introduction
We consider a population made of two groups (minority and majority) whose individuals are spread across units. Units can be geographical areas, residential neighborhoods, firms, classrooms, or other clusters provided that every individual belongs to exactly one unit. We seek to measure the extent to which individuals from the minority group are concentrated in some units more than in others. Throughout the article, we follow the literature and use the word “segregation” as a neutral term to refer to such concentration. Measuring the magnitude of segregation is a necessary step to understand the underlying mechanisms and to design adequate policies.
A natural way to measure segregation is to start from the minority shares Xi/Ki , where Xi is the number of individuals from the minority group and Ki the number of individuals (or unit’s size) in unit i ∊ {1,…, n}, and then compute an inequality index based on the distribution of the proportions Xi/Ki across the n units.
There are two possible benchmarks to assess the magnitude of these indices. Evenness relates to the case where all minority shares Xi/Ki are equal across units. Randomness relates to the case where the underlying allocation assigns minority individuals at random across units. If pi is the probability that an arbitrary individual in unit i belongs to the minority, randomness means that probabilities pi are equal across units i. Past research has stressed the difference between both benchmarks, especially when the units are small (Cortese, Falk, and Cohen 1976). The minority share Xi/Ki is only an estimate of pi , and even if p 1 ,…, pn are all equal, there will be some variation in the Xi/Ki , especially if the units’ sizes Ki are small. If one is interested in the deviations from the randomness case, indices based on minority shares, which measure the deviation from evenness, will overestimate the level of segregation. This issue is known as small-unit bias.
The problem is pervasive in applied research. For workplace and school segregation, a large share of firms have fewer than 10 employees and classrooms have usually between 20 and 40 students. The bias also arises when the units are not small per se but only surveys of individuals are available. This is the case when one attempts to measure residential segregation using the local strata of households surveys.
Two main approaches have been proposed in the literature to deal with the small-unit bias. One strand proposes to correct the so-called naive inequality indices based on the minority shares Xi/Ki . The idea was initially proposed by Cortese, Falk, and Cohen (1976) and Winship (1977) for the Duncan index. Carrington and Troske (1997, CT hereafter) extend the correction to other indices. Åslund and Skans (2009) adapt it to measure segregation conditional on covariates. Allen et al. (2015) develop another adjustment based on bootstrap. These corrections all aim at switching the benchmark from evenness to randomness by subtracting an estimate of the bias from the initial, naive index.
Another approach, adopted by Rathelot (2012, R hereafter) and D’Haultfœuille and Rathelot (2017, HR hereafter), defines segregation using an inequality index based on the unobserved probabilities pi as a functional of the distribution Fp of pi . In line with the rest of the literature, they assume that the Xi are independent and follow a Bin(Ki, pi ) distribution. Conditional on Ki and pi , R assumes a mixture of beta distributions for Fp and derives the segregation index as a function of the parameters of the distribution. HR follow a nonparametric method leaving Fp unspecified; they show that the first moments of Fp are identified under the previous binomial assumption and obtain partial identification results on the segregation measure. Both R and HR construct confidence intervals (CIs) for the segregation indices. HR also extend the methodology to study conditional segregation indices, namely, measures of “net” or “residual” segregation accounting for other covariates (either of units or individuals) that may influence allocation.
The command
This article describes the command and presents the three methods it implements. Section 2 defines the setup and the parameters of interest and synthesizes the estimation and inference methods of R, HR, and CT. Section 3 details the syntax, options, and stored results of the
2 Setup, estimation, and inference
2.1 The setting and the parameters of interest
The population studied is assumed to be split into two groups: a group of interest, henceforth the minority group, and the rest of the population. Individuals are distributed across units. For each unit, we assume that there exists a random variable p that represents the probability for any individual belonging to this unit to be a member of the minority. The total number of individuals in a unit is denoted by K.
We now introduce the segregation indices we focus on hereafter. We consider first unconditional indices; conditional indices are introduced in section 2.6. Let us first assume that K is fixed. A segregation index θ is then a functional of the cumulative distribution function (c.d.f.) Fp of p and of m 01 = E(p); that is θ = g(Fp, m 01). 1 Roughly speaking, one expects such an index to be minimal when Fp is degenerate and maximal when p ∊ {0, 1}. In the former case, the probability of belonging to the minority is the same in all units, whereas in the latter case, the minority group is concentrated in a subset of units only.
The command

When K is random and takes values in

whereas the individual-level segregation index θi is defined by

To estimate θ, we assume hereafter that the researcher has at his or her disposal K; however, the probability p remains unobserved. Instead, the researcher observes only X, the number of individuals belonging to the minority in the unit. By definition of p, we have E(X|K, p) = Kp, which implies that the proportion of individuals from the minority, X/K, is an unbiased estimator of p. However, because it varies conditional on p, X/K is more dispersed than p. Thus, we have for usual segregation indices including the five above,

In other words, even in the absence of statistical uncertainty on the distribution of X/K, we would still overestimate the segregation index by using X/K in place of p. Moreover, this bias increases as K decreases. We refer to this issue as the small-unit bias hereafter.
The binomial assumption
We assume henceforth that individuals are allocated into units independently from each other. Namely, X is assumed to follow, conditional on p and K, a binomial distribution Bin(K, p). This assumption may be restrictive when allocation is in some way sequential and influenced by the composition of units. But more importantly, this assumption is testable (see section 2.5).
2.2 Nonparametric approach
Identification
This approach, followed by HR, leaves the distribution Fp of p unrestricted. Combined with the binomial assumption, it entails a nonparametric binomial mixture model for X. Let us first suppose that K is constant; if not, we can simply retrieve aggregated indices θu and θi using (1) and (2). We also assume that K > 1; if K = 1, the distribution of X is not informative on θ, and we get only trivial bounds on it, namely, 0 and 1 for the five indices above.
First, some algebra yields a one-to-one mapping between the distribution of X, defined by the K probabilities

with
It follows that
When
Assumption 1 fails for the Gini but is satisfied by the Duncan, the Theil, the Atkinson, and the Coworker indices. Under this condition, the bounds on ∫ h(x, m
01) dF(x), and thus on θ, are attained by distributions with no more than K + 1 support points. Specifically, let

The following theorem, which reproduces theorem 2.1 of HR, summarizes the previous discussion. Hereafter, we let
– If
In the interior case, computing the bounds still requires a nonlinear optimization under constraints that are also nonlinear in the support points. Yet the problem can be further simplified under an additional assumption using the theory of Chebyshev systems. In particular, it requires that the function h in assumption 1 does not depend on m
01, a condition satisfied by the Theil and Atkinson indices. Basically, for those two indices, no numerical optimization is needed to compute the bounds
Estimation
Let us assume to have a sample (Xi
)
i
=1
,…,n
of independent and identically distributed variables with constant sizes equal to K > 1. Theorem 1 shows that θ is either point or partially identified

where

Second, we estimate
When
Inference
When assumption 1 holds, HR show that the estimators of the bounds are consistent:
Random unit size
The previous identification and estimation results can be adapted to cases where K is random and takes values in

Remark that as soon as for one size k the index θk
is not point identified, the resulting aggregated index will be partially identified too. To obtain point identification of θu
or θi
, one must be in the constrained case for each k ∊
As with the constant unit case, CIs for the aggregated indices θu and θi are constructed by the modified bootstrap procedure detailed in HR. The randomness of K just involves an additional step that consists in drawing K in its empirical distribution.
Assuming independence between K and p
The previous estimation and inference procedures are fully agnostic as regards possible dependence between K and p, which is a safe option when unit size may be a potential determinant of segregation. However, if one is ready to impose independence between these two variables, the identified bounds on θu
= θi
get closer to each other. This is because the
2.3 Parametric approach
This approach, followed by R, is like that of HR, except that it imposes a parametric restriction on Fp . Specifically, it is supposed to be a mixture of beta distributions. Combined with the binomial assumption for the conditional distribution of X, the model becomes fully parametric and thus can be estimated by maximum likelihood. The indices are therefore point identified, contrary to the nonparametric approach of HR.
A concern might be that the parametric restriction leads to invalid results when the model is misspecified. However, R shows through simulations that segregation indices associated with various distributions, both continuous and discrete, are accurately proxied by his parametric approach.
Estimation and inference
As in HR, we first assume that K is constant. Let B(., .) denote the beta function, c the number of components of the beta mixture,

In this model, the probability that k individuals belong to the minority group can be written, after some algebra, as

Thus, the log likelihood satisfies, up to terms independent of the parameter
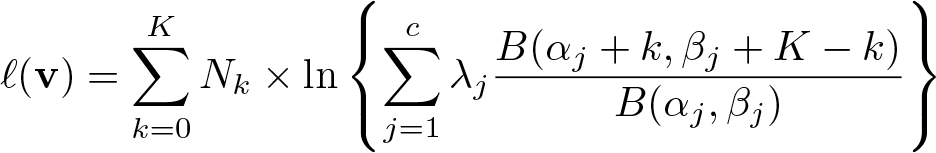
Maximizing
Random unit size
The adaptation to this case is exactly similar to HR method. For each k ∊
2.4 Correction of the naive index
The approaches of HR and R are immune to the small-unit bias as they directly estimate g(Fp, m 01). Other, previous approaches rather start from the naive index θN = g(FX/K, m 01) and attempt to modify it, so that the parameter becomes less sensitive to changes in K. We present here the correction proposed by CT, which is the most popular in applied work.
CT’s correction relies on the distinction between the randomness and evenness benchmarks, introduced notably by Cortese, Falk, and Cohen (1976) and Winship (1977). Evenness corresponds to X/K being constant, whereas randomness refers to the case where p is constant. Under the binomial model, however, evenness cannot occur. The central idea of CT is then to convert θN
, which measures departure from evenness, into a distance to randomness. Let
Links with HR and R
In general, θ CT ≠ θ. They do coincide, however, in the extreme cases of no segregation, where p is constant, and of “full” segregation, where p follows a Bernoulli distribution. We refer to section 2.3 of R and section 2.4 of HR for further discussion on the relationship between θ CT and θ.
2.5 Test of the binomial assumption
We have relied so far on the binomial assumption X|K, p ∼ Bin(K, p). This assumption implies that
HR propose a likelihood-ratio (LR) test of

where we let
With a random unit size, the test statistic is then

with c 1 −α (LR∗) the quantile of order 1 − α of LR∗.
The results of HR imply that the test has an asymptotic level equal to α and is consistent. Remark, however, that it tests
2.6 Conditional segregation indices
Conditional indices aim at accounting for the fact that part of the segregation along the dimension at stake may be driven by sorting according to other dimensions. In this sense, they measure the net or residual level of segregation, when the contribution of covariates to segregation is removed (see Åslund and Skans [2009]). To illustrate this point, let us consider workplace segregation between foreigners and natives. Foreigners may be hired more in some sectors of the economy on the basis of sector-specific skills. Imagine an extreme case where, within each sector, all firms hire foreigners with the same probability. As long as these probabilities differ from one sector to another, an unconditional segregation index would be positive. On the contrary, the conditional index defined in (4) below would indicate no segregation because it controls for the influence of the sector, a characteristic of units, in the allocation process. Similarly, foreigners may be hired with the same probability for all low-skilled jobs (respectively, all high-skilled jobs), but the probabilities for these two types of job may differ. In this case again, failing to account for this characteristic would lead to a positive unconditional index, while the conditional index defined in (5) below would indicate no segregation.
The previous discussion underscores that covariates can be defined either at the unit level or at the level of an individual (or of a position). We separate the two cases below because they lead to different treatments.
Unit-level covariates
Let
The index θ 0 z can be of interest by itself. We can also consider an aggregate conditional index defined as follows: 4

The estimation of
Individual- or position-level covariates
Let
For each unit and each type
Again, θ 0 w might be a relevant parameter of interest on its own. Researchers can also be interested in an aggregated conditional index:

The estimation of
the empirical counterpart of Pr(W = w). For HR and R methods, as previously, a modified bootstrap procedure provides asymptotic CIs for
3 The segregsmall command
The
3.1 Syntax
The syntax of
3.2 Description and main options
The command
3.3 Additional options
3.4 Stored results
The objects stored by
In this section, we list the objects stored in
Data included in the analysis
Below, names with prefix

Method used

Estimation and inference
Objects relative to unconditional analyses are in black (left-hand column); those relative to conditional analyses are in gray(right-hand column). Superscripts *np and *beta indicate that objects are relevant and stored only with

The matrices whose name includes
With
With
In conditional analyses, either with unit- or with individual- or position-level covariates, the matrices
With
With the
With the
3.5 Execution time
The times reported below are averaged over 50 repetitions on a desktop computer run under Windows 10 Enterprise with an Intel® CoreTM i5-6600 CPU 3.30 GHz processor (RAM 16 Go). The operations of
Preparation stage
The preparation stage is common to the three methods and reshapes the dataset. Its execution time is quick compared with the whole command and increases in the number n of units. For instance, with unit-level datasets, for K taking values in
Estimation and inference stage
The subsequent operations depend on the method used. The central brick of
Execution time in seconds. Setting: unit-level datasets, n = 300000,

As highlighted by table 2, the number n of units has a minor impact, mainly through the preparation stage.
Execution time in seconds. Setting: unit-level datasets, K = [5, 15], options

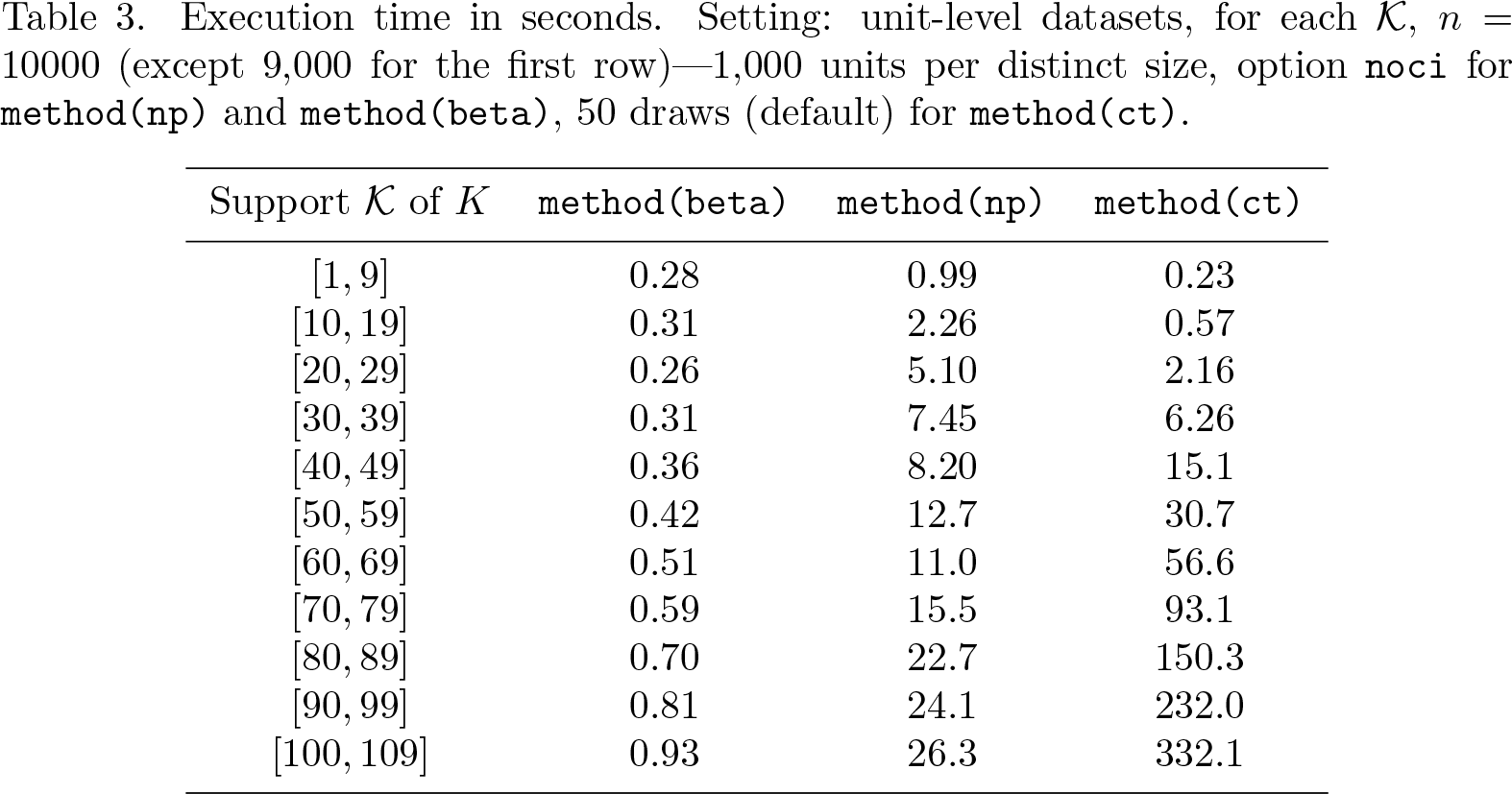
The primary determinant of the computation time is the unit sizes: both the number of distinct values of the support K and the magnitude of K, as shown by table 3. With
Execution time in seconds. Setting: unit-level datasets, for each
4 Example
We use the command to measure workplace segregation between natives and foreigners in France (see D’Haultfœuille and Rathelot [2017] for details about the context). A large share of workers is employed in small establishments. This section shows the importance of correcting for the small-unit bias, which may lead to erroneous economic conclusions.
The data used are the 2007 Déclarations Annuelles des Données Sociales, French data linking workers to their employer. Data are exhaustive in the private sector (1.77 million establishments). In the application, we use the 1.04 million establishments that have between 2 and 25 employees. The minority group consists of individuals born outside France and with the nationality of a country outside Europe. The overall proportion of minority individuals is 4.1% in the sample studied. Figure 1 shows the estimates of workplace segregation by firm size, for the Duncan, the Theil, the Atkinson (with parameter b = 0.5), and the Coworker indices. The Gini index does not satisfy the conditions required by the nonparametric method of HR and is thus not displayed (but see figure 2 in appendix A.2 for the graph on the Gini without the nonparametric estimator).

Duncan, Theil, Atkinson, and Coworker indices by firm size
The distinct methods of the package are used: the estimated bounds
Figure 1 shows that the naive indices overestimate the actual level of segregation: they are almost always above the CI obtained by
The point estimate
Interestingly, the naive indices exhibit a stronger negative relationship between segregation levels and unit size than corrected ones. Neglecting the small-unit bias would produce a statistical artifact as the magnitude of the bias decreases with K and therefore would support a negative correlation while it may not be so. On the contrary, the indices that account for the small-unit bias can address this question (see section 5 of HR for further details).
Finally, we report below the Stata output obtained with the

5 Conclusion
This article presented the
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000018 - segregsmall: A command to estimate segregation in the presence of small units
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000018 for segregsmall: A command to estimate segregation in the presence of small units by Xavier D’Haultfœuille, Lucas Girard and Roland Rathelot in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
A Appendices
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.