
Abstract
We introduce three new commands—
Keywords
1 Introduction
We introduce the commands
In unordered categorical data, in which choices can be grouped into the nests of similar options, the nested logit model is a popular method. Nested models for ordinal data are rare though the rationale behind them is similar: choosing among a negative response (decrease), a neutral response (no change), or a positive response (increase) is quite different from choosing the magnitude of a negative or positive response; and choosing the magnitude of a negative response can be driven by quite different determinants than choosing the magnitude of a positive response. This leads to three implicit decisions: an upper-level regime decision (a choice among the nests) and two lower-level outcome decisions (the choices of the magnitude of the negative and positive responses). See the top left panel of figure 1.

Decision trees of nested and zero-inflated ordered probit models.
Furthermore, it would be reasonable for the zero (no-change) alternative to be in three nests: its own, one with the negative responses, and one with the positive responses. Hence, some zeros can be driven by similar factors as the negative or positive responses. This leads to a three-part cross-nested model with the nests overlapping at the zero response; hence, the probability of zeros is “inflated”. Because the regime decision is not observable, the zeros are observationally equivalent—it is never known to which of the three nests the observed zero belongs. Several types of models with overlapping nests for unordered categorical responses have been developed (Vovsha 1997; Wen and Koppelman 2001). Cross-nested models for ordinal outcomes are rare (Small 1987).
The prevalence of status quo, neutral, or zero outcomes is observed in many fields, including economics, sociology, technometrics, psychology, and biology. The heterogeneity of zeros is widely recognized—see Winkelmann (2008) and Greene and Hensher (2010) for a review. Studies identify different types of zeros, such as no visits to a doctor due to good health, iatrophobia, or medical costs; no illness due to strong immunity or lack of infection; no children due to infertility or choice. In the studies of survey responses using an odd-point Likert-type scale, where the respondents must indicate a negative, neutral, or positive attitude or opinion, the heterogeneity of indifferent responses (a true neutral option versus an undecided, or ambivalent, or uninformed one, commonly reported as neutral) is also well recognized and sometimes labeled as the middle category endorsement or inflation (Bagozzi and Mukherjee 2012; Hernández, Drasgow, and Gonzáles-Romá 2004; Kulas and Stachowski 2009).
Two-part zero-inflated models, developed to address the unobserved heterogeneity of zeros, combine a binary choice model for the probability of crossing the hurdle (to participate or not to participate; to consume or not to consume) with a count or ordered-choice model for nonnegative outcomes above the hurdle: the two parts are estimated jointly, and zero observations can emerge in both parts. The two-part zero-inflated models include the zero-inflated Poisson (Lambert 1992), negative binomial (Greene 1994), binomial (Hall 2000), and generalized Poisson (Famoye and Singh 2003) models for count outcomes, and the zero-inflated OP model (Harris and Zhao 2007) and zero-inflated proportional odds model (Kelley and Anderson 2008) for nonnegative ordinal responses. 1
The model of Harris and Zhao (2007) is suitable for explaining decisions such as the levels of consumption, when the upper hurdle is naturally binary (to consume or not to consume), the responses are nonnegative, and the inflated zeros are situated at one end of the ordered scale (see the bottom left panel of figure 1). Bagozzi and Mukherjee (2012) and Brooks, Harris, and Spencer (2012) modified the model of Harris and Zhao (2007) and developed the middle-inflated OP model for an ordinal outcome, which ranges from negative to positive responses, and where an abundant outcome is situated in the middle of the choice spectrum (see the bottom right panel of figure 1).
The three-part zero-inflated OP model (see the top right panel of figure 1) introduced in Sirchenko (2020) is a natural generalization of the models of Harris and Zhao (2007), Bagozzi and Mukherjee (2012), and Brooks, Harris, and Spencer (2012). A trichotomous regime decision is more realistic and flexible than a binary decision (change or no change) if applied to ordinal data with negative, zero, and positive values.
2 Models
2.1 Notation and assumptions
The observed dependent variable yt
, t = 1, 2,…, T, is assumed to take on a finite number of ordinal values j coded as {−J
−
,…, −1, 0, 1,…, J
+}, where a potentially heterogeneous (and typically predominant) response is coded as 0. The latent unobserved (or only partially observed) variables are denoted by “∗”. Each model assumes an ordered-choice regime decision and the ordered-choice outcome decisions conditional on the regime. The regime decision can be correlated with each outcome decision. We denote the following: by

2.2 Three-part nested ordered probit model
Despite the widespread use of nested logit models for unordered categorical responses, we are aware of only one example of the nested OP model in the literature (Sirchenko 2020). The two-level nested ordered probit (NOP) model can be described as

The probabilities of the outcome j in the NOP model are given by

where Ij < 0 is an indicator function such that Ij < 0 = 1 if j < 0 and Ij < 0 = 0 if j ≥ 0 (analogously for Ij =0 and Ij > 0).
In the case of exogenous switching (when ρ − = ρ + = 0), the probabilities of the outcome j in the NOP can be computed as

In the case of two- or three-outcome choices, the NOP model degenerates to the conventional single-equation OP model.
2.3 Two-part zero-inflated ordered probit model
The two-part zero-inflated ordered probit (ZIOP-2) model, which represents the zero-inflated OP model of Brooks, Harris, and Spencer (2012) and the middle-inflated OP model of Bagozzi and Mukherjee (2012), can be described by the following system:

The probabilities of the outcome j in the ZIOP-2 model are given by

In the case of exogenous switching (when ρ = 0), these probabilities can be computed as follows:

If yt ≥ 0 for ∀t, the ZIOP-2 model becomes the model of Harris and Zhao (2007).
2.4 Three-part zero-inflated ordered probit model
The three-part zero-inflated ordered probit (ZIOP-3) model developed by Sirchenko (2020) is a three-part generalization of the ZIOP-2 model and can be described by the following system:

The probabilities of the outcome j in the ZIOP-3 model are given by
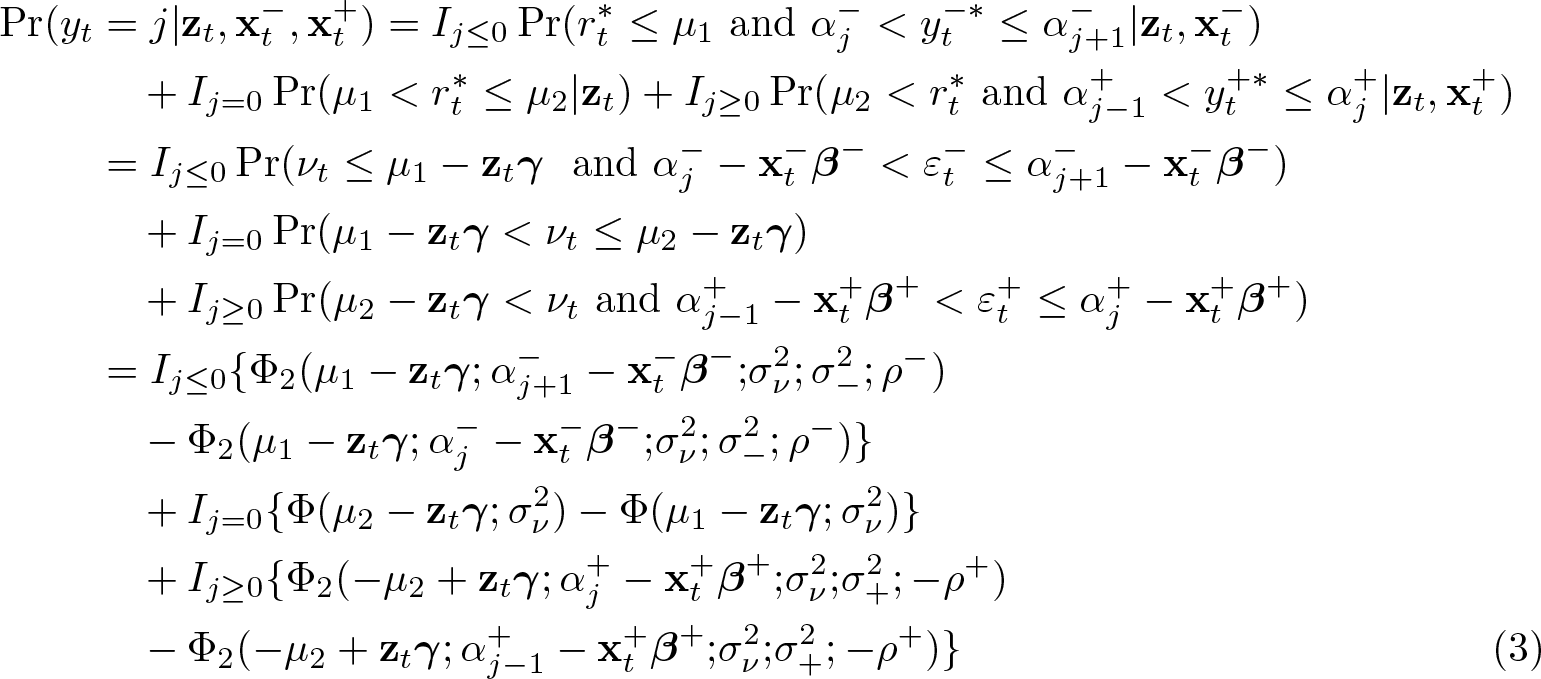
where Ij ≤ 0 is an indicator function such that Ij ≤ 0 = 1 if j ≤ 0 and Ij ≤ 0 = 0 if j > 0 (analogously for Ij ≥ 0).
In the case of exogenous switching (when ρ − = ρ + = 0), these probabilities can be computed as

The inflated outcome does not have to be in the very middle of the ordered choices. If it is located at the end of the ordered scale—that is, if yt ≥ 0 for ∀t—the ZIOP-3 model reduces to the ZIOP-2 model of Harris and Zhao (2007).
2.5 Maximum likelihood estimation
The probabilities in each OP equation can be consistently estimated under fairly general conditions by an asymptotically normal maximum likelihood (ML) estimator (Basu and de Jong 2007). The simultaneous estimation of the OP equations in the NOP, ZIOP-2, and ZIOP-3 models can also be performed using an ML estimator of the vector of the parameters

where Itj
is an indicator function such that Itj
= 1 if yt
= j and Itj
= 0 otherwise;
The intercept components of
The three regimes (nests) in the NOP model are fully observable, contrary to the latent (only partially observed) regimes in the ZIOP-2 and ZIOP-3 models. The likelihood function of the NOP model in the case of exogenous switching—again in contrast
with the ZIOP-2 and ZIOP-3 models—is separable with respect to the parameters in the three equations. 2 In the case of endogenous switching, the likelihood function in the ZIOP-2 and ZIOP-3 models, similar to the likelihood in mixture models, sample-selection models, and zero-inflated negative binomial models (Olsen 1982; Silva 2017), may have multiple local maximums. The ML estimates may depend on the starting values of the parameters; ideally, the initial values in the neighborhood of the global maximum can facilitate estimation.
To avoid the local maximums problem and to reduce computation costs, the following scanning procedure is implemented. The starting values for the slope and threshold parameters in the exogenous-switching models are obtained using the independent OP estimations of each equation. The starting values for ρ, ρ −, and ρ + in the endogenous-switching models are obtained by maximizing the likelihood functions over a grid search from −0.95 to 0.95 in increments of 0.05, holding the other parameters fixed at their estimates in the corresponding exogenous-switching model. Olsen (1982) suggests a scanning procedure for ρ in the context of the sample-selection model and demonstrates that the likelihood function has a unique maximum for fixed values of ρ. To ensure that the maximum obtained is the global one, it make sense to try several starting points. The implemented estimators allow selecting any starting points. The Monte Carlo experiments confirm that the proposed estimators converge at the global maximum.
2.6 Marginal effects
We combine the marginal effects of each independent variable on the probability of each discrete outcome into a matrix

where f is the probability density function of the standard normal distribution, and
The MEs for the NOP model are computed by replacing Ij ≥ 0 in the above formula with Ij > 0 and Ij ≤ 0 with Ij < 0.
The MEs for the ZIOP-2 model are computed as

where
The asymptotic standard error of
2.7 Relations among the models and their comparison
We now discuss the choice of a formal statistical test to compare the NOP, ZIOP-2, ZIOP-3, and conventional OP models. The choice depends on whether the models are nested in each other.
The exogenous-switching version of each model is nested in its endogenous-switching version as its uncorrelated special case; their comparison can be performed using any classical likelihood-based test for nested hypotheses, such as the likelihood-ratio (LR) test.
The OP is not nested either in the NOP or ZIOP-3 model. We can compare the OP model with them by using a likelihood-based test for nonnested models, such as the Vuong (1989) test.
3
The OP model is, however, nested in the ZIOP-2 model. The latter reduces to the former if µ → −∞; hence,
The NOP model is nested in the ZIOP-3 model. The latter becomes the former if
Generally, the ZIOP-2 model is not a special case of the ZIOP-3 model, and vice versa. We can compare them by using the Vuong test. A special case when the ZIOP-3 model nests the ZIOP-2 model emerges under certain restrictions on the parameters, as explained below. In this case, the selection between the ZIOP-3 and ZIOP-2 models can be performed using any classical likelihood-based test for nested hypotheses, such as the LR test.
The special case emerges if yt
takes on only three discrete values j ∊ {−1, 0, 1}, the regressors in

because
Similarly, according to (3) the probabilities of the outcome j in the ZIOP-3 model are given by

Suppose the regressors in
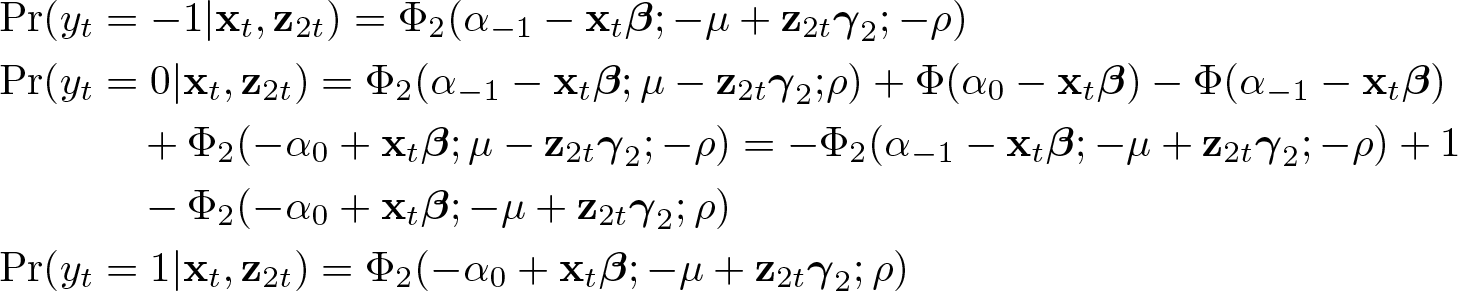
which are identical to the probabilities for the ZIOP-2 model in (5).
Notice that the restrictions −

In general, if
3 The nop, ziop2, and ziop3 commands
The accompanying software includes the three new commands, the postestimation commands, and the supporting help files.
3.1 Syntax
The following commands fit, respectively, the NOP, ZIOP-2, and ZIOP-3 models for discrete ordinal outcomes:
An ordinal dependent variable, depvar, is assumed to take on at least five discrete ordinal values in the NOP model, at least two in the ZIOP-2 model, and at least three in the ZIOP-3 model. A list of the independent variables in the regime equation, indepvars, may be different from the lists of the independent variables in the outcome equations.
Options
Stored results
The descriptions of the stored results can be found in the help files.
3.2 Postestimation commands
The following postestimation commands are available after
The predict command
This command computes the predicted probabilities of the discrete choices (by default), the regimes and the types of zeros conditional on the regime, and the predicted outcomes and the expected values of the dependent variable for all observed values of the independent variables in the sample. The command creates (J − + J + + 1) new variables under the names with a newvar prefix. The following options are available:
The ziopprobabilities command
This command shows the predicted probabilities estimated at the specified values of the independent variables along with the standard errors. The options
The ziopcontrasts command
This command shows the differences in the predicted probabilities, estimated first at the values of the independent variables in
The ziopmargins command
This command shows the marginal effects of each independent variable on the predicted probabilities estimated at the specified values of the independent variables, along with the standard errors. The options
The ziopclassification command
This command shows the classification table (or confusion matrix); the percentage of correct predictions; the two strictly proper scores—the probability, or Brier, score (Brier 1950) and the ranked probability score (Epstein 1969); and the precisions, hit rates (or recalls), and adjusted noise-to-signal ratios (Kaminsky and Reinhart 1999).
The classification table reports the predicted choices (the ones with the highest predicted probability) in columns, the actual choices in rows, and the number of (mis)classifications in each cell.
The Brier probability score is computed as
The precision, hit rate (or recall), and adjusted noise-to-signal ratios are defined as follows. Let TP denote a true positive event, that is, the outcome was predicted and occurred; let FP denote a false positive event, that is, the outcome was predicted but did not occur; let FN denote a false negative event, that is, the outcome was not predicted but did occur; and let TN denote a true negative event, that is, the outcome was not predicted and did not occur. The desirable outcomes fall into categories TP and TN, while the noisy ones fall into categories FP and FN. A perfect prediction has no entries in FP and FN, while a noisy prediction has many entries in FP and FN but few in TP and TN. The precision is defined for each choice as TP/(TP + FP); the recall is defined as TP/(TP + FN); and the adjusted noise-to-signal ratio is defined as {FP/(FP + TN)}/{TP/(TP + FN)}.
The ziopvuong command
This command performs the Vuong test for nonnested hypotheses, which compares the closeness of two models to the true data distribution by using the differences in the pointwise log likelihoods of the two models. The null hypothesis is that both models are misspecified but equally close to the unknown true model. The test statistic is equal to the average difference of the pointwise log likelihoods divided by the estimated standard error of those pointwise differences. Under the null hypothesis, the Vuong test statistic converges in distribution to a standard normal one. The arguments modelspec
1 and modelspec
2 are the names under which the estimation results are saved using the
4 Monte Carlo experiments
We performed three sets of Monte Carlo simulations to illustrate the finite-sample performance of the ML estimators of each model. In the first set of experiments, we studied the performance of the ML estimators of the NOP, ZIOP-2, and ZIOP-3 models when simulated and estimated processes are the same, using artificial explanatory variables. The simulations demonstrate that the proposed ML estimators deliver consistent and reliable estimates even in small samples.
In the second set of experiments, using the real-world values of explanatory variables and the values of parameters from the empirical example, we compared the performance of the ML estimators of the OP and ZIOP-3 models if the data are generated by one of them and then fit by both models, and the performance of various measures of fit, information criteria, and statistical tests in selecting the best model. The ZIOP-3 estimator under the OP data-generating process (DGP) performs substantially better than the OP estimator under the ZIOP-3 DGP, and it produces reliable inference in small samples under both DGPs. AIC and BIC outperform the other criteria and tests in correctly selecting the true model under both DGPs.
In the third set of experiments, we compared the performance of the asymptotic and nonparametric bootstrap estimators of the standard errors. The simulations suggest that, in small samples, the bootstrap estimator of the standard errors of the parameters in the models with endogenous switching may provide substantially better coverage rates than the asymptotic estimator, especially with regard to the correlation coefficients. However, the bootstrap estimator of the standard errors of the choice probabilities does not necessarily perform better than the asymptotic one at the same time.
4.1 Monte Carlo design
In the first set of experiments, we simulated six DGPs according to the NOP, ZIOP-2, and ZIOP-3 models (each of them with both exogenous and endogenous switching) and then estimated each process by using the true model. Three independent variables,
In the second set of experiments, we simulated two DGPs. One is generated by the OP model, and the other is generated by the ZIOP-3 model with exogenous switching. For each DGP, we fit both models. We simulated data by mimicking the real-world sample used in our empirical application in section 5. The values of four regressors (
In the third set of experiments, we simulated four DGPs according to the NOP and ZIOP-3 models (each of them with both exogenous and endogenous switching), as in the first set of experiments, and we estimated each process using the true model and using both the asymptotic and the bootstrap estimators of the standard errors. We generated 3,000 replications in the case of exogenous switching and 1,000 replications in the case of endogenous switching. To compute a nonparametric bootstrap estimator of standard errors, we drew with replacement 200 bootstrap samples for each Monte Carlo iteration, recalculated the statistics, and obtained the standard deviations of the replicated statistics.
To avoid the divergence of the ML estimates due to the problem of complete separation (perfect prediction), which could happen if the actual number of observations in any outcome category is 0 or very low, the samples with any outcome category frequency lower than 6% (in the first and third sets of experiments), 4% (in the second set), and 3% (in the bootstrap samples) were discarded. The variances of the normal error terms in all experiments were fixed to 1.
4.2 Monte Carlo results
Table 1 reports the measures of accuracy for the ML estimates of the slope parameters
The accuracy of the estimators of parameters

Table 2 reports the measures of accuracy of the estimates of choice probabilities. The accuracy of estimated probabilities is more interesting and informative than the accuracy of estimated parameters. In the latent class models, the parameters are identified only up to scale and location and cannot be easily interpreted in terms of ME on the probabilities (for example, in the OP models, the sign of the coefficient on a certain covariate does not imply the direction of the ME of that covariate). In contrast, the choice probabilities are absolutely estimable and invariant to the identifying assumptions, which are necessary to estimate the latent class models. The estimates of the choice probabilities are the primary objectives of empirical studies. Besides, the percent bias of parameter estimates in simulations depends on the chosen absolute values of the parameters, whereas the percent bias of probability estimates is invariant to them.
The accuracy of the estimators of choice probabilities
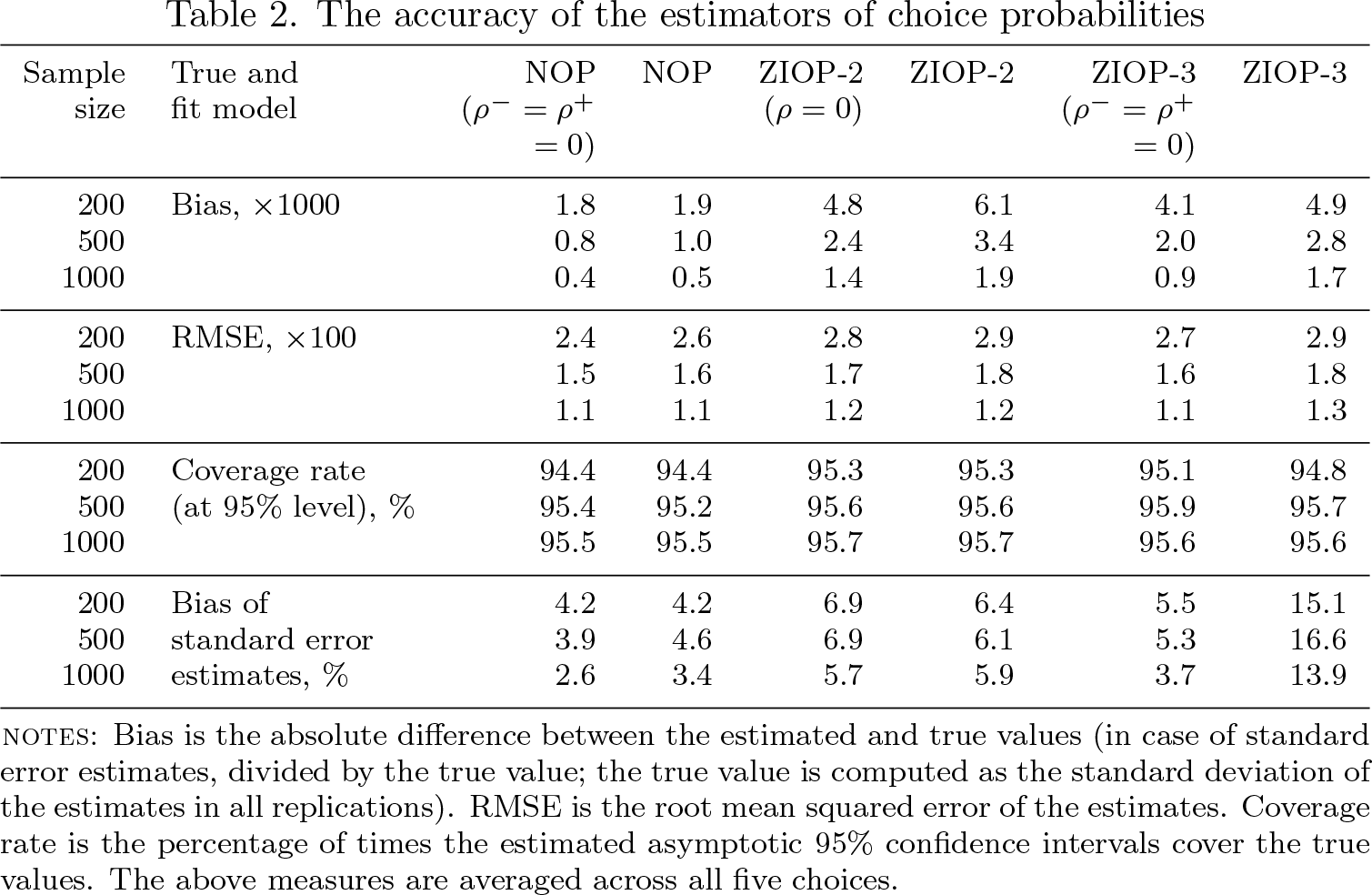
The values of the choice probabilities, which depend on the values of the regressors, are computed for table 2 at the population means of the simulated regressors. The probability estimates are more accurate than the parameter estimates. The simulations show that the ML estimates of probabilities are consistent and reliable even in samples with only 200 observations: the biases are smaller than five percent and the asymptotic coverage rates differ from the nominal 0.95 level by less than 1%. With 1,000 observations, the biases of choice probability estimates are around 1%. For each model, the biases and RMSE sharply decrease as the sample size increases from 200 to 1,000. The RMSE decreases, in most cases, faster than the asymptotic rate
Table 3 reports the results of the second set of experiments. To compare the performance of the OP and ZIOP-3 models fit under each DGP, the two top panels of table 3 show for both fitted models the accuracy of the estimated probability of the actual (observed) choice and the accuracy of the estimated ME of the regressor
The performance of the OP and ZIOP-3 models under each DGP

The bottom panel of table 3 shows the fractions of times when a model is selected under each DGP according to the following measures of fit, information criteria, and statistical tests: the percentage of correct predictions (according to a maximum probability rule), the Brier score, the ranked probability score, the LR test, the information-based selection criteria AIC and BIC, the Vuong tests, and the pared sign tests (Clarke 2003). Information criteria are computed as AIC = −2l(
The model selection results demonstrate the superiority of the ZIOP-3 model and back the need for its zero-inflation component. Under its own DGP, the ZIOP-3 model is selected in 95%–100% of cases by all criteria except for the Vuong test with Bayesian penalty (54% of cases) and sign test with Bayesian penalty (41%), while the OP model is never selected by any criteria except for the percentage of correct predictions (in 2% of cases only), BIC (5% only), and sign tests with Akaike (1% only) and Bayesian (12% only) penalties. In contrast, under the OP DGP, the selection results are not so overwhelmingly in favor of the true model: the OP model is preferred in 96%–100% of cases by AIC, BIC, and the Vuong and sign tests with Bayesian penalty, but in 5% of cases only by the Vuong test, in 13% of cases only by the sign test, and in 84% of cases by the sign test with Akaike penalty; the other tests and criteria select the true OP model in 45%–56% of cases only. The ZIOP-3 model is selected under the OP DGP far more often than the OP model under the ZIOP-3 DGP. Under the OP DGP, the ZIOP-3 model is even more often preferred by the sign test (in 26% of cases) than the true model (in 13% of cases only).
BIC and AIC do the best job correctly selecting the true model in at least 95% of cases under both DGPs. Under the zero-inflated DGP, when the ZIOP-3 model clearly outperforms the OP model, most of the criteria perform well and correctly favor the true model in at least 95% of cases except for the Vuong and sign tests with Bayesian penalty: the former selects the true model in 54% of cases only but never selects the OP model, while the latter selects the ZIOP-3 model in 42% of cases but prefers the OP model in 12% of cases. Under the OP DGP, when the performance of the ZIOP-3 model is quite close to that of the OP model, only AIC, BIC, and the Vuong and sign tests with Bayesian penalties perform well and correctly select the true model in more than 95% of cases. The classical LR/Vuong/sign tests select the true model only in 53%/5%/13% of cases, prefer the wrong model in 47%/2%/26% of cases, and are indifferent between the two alternatives in 0%/93%/61% of cases. Such criteria as the percentage of correct predictions, the Brier score, and the ranked probability score, which are not based on the ML approach, select each alternative in roughly one half of cases, though the ranked probability score performs slightly better than the others, selecting the true model in 55% of cases.
Table 4 summarizes the results of the third set of experiments. As the upper panel shows, the asymptotic estimates of the standard errors of the slope parameters are rather slightly underestimated (by 9%–13%), whereas the bootstrap estimates are severely overestimated (by 155%–325% for exogenous switching and by 16%–22% for endogenous switching). The more complicated the model, the worse (the lower) are the asymptotic coverage rates: 95% for the NOP with exogenous switching, but only 86% for the ZIOP-3 with endogenous switching. The bootstrap coverage rates are above the 95% nominal level (in the 96.6%–98.4% interval); they are closer to the nominal level than the asymptotic ones for both models with endogenous switching, have the same deviation from the nominal level (but in the opposite directions) for the ZIOP-3 model with exogenous switching, and are further from the nominal level for the NOP model with exogenous switching.
Comparison of the asymptotic and bootstrap estimators of standard errors

As the middle panel shows, the bootstrap coverage rates for the correlation coefficients (89%) are substantially better than the asymptotic ones (only 71%) for both models, and the biases of the estimates of the standard errors are below 10% for both estimators and models. Nevertheless, as the bottom panel reports for the choice probabilities, the bootstrap and asymptotic estimators have similar biases of the standard error estimates and similar coverage rates in the NOP models, but in the ZIOP-3 models the asymptotic estimator performs better than the bootstrap one.
The experiments suggest that there is no need to apply the bootstrap estimator of the standard errors of the choice probabilities, even if the number of observations per parameter is as small as 15. However, with respect to the slope parameters and especially the correlation coefficients, the bootstrap estimator in the models with endogenous switching in small samples may avoid the severe overestimation of the standard errors and provide better coverage rates than the asymptotic estimator.
5 Examples
The new commands are applied to a real-world time-series sample of all decisions of the U.S. Federal Open Market Committee (FOMC) on the federal funds rate target made at scheduled and unscheduled meetings during the 9/1987–9/2008 period.
The dependent variable, the change to the rate target, is classified into five ordered categories: “−0.5” (a cut of 0.5% or more), “−0.25” (a cut less than 0.5% but more than 0.0625%), “0” (no change or change by no more than 0.0625%), “0.25” (a hike more than 0.0625% but less than 0.5%) and “0.5” (a hike of 0.5% or more). The FOMC decisions are aligned with the real-time values of the explanatory variables as they were truly available to the public on the previous day before each FOMC meeting. The explanatory variables include
We start by fitting the conventional OP model with the

We now allow the negative, zero, and positive changes to the rate target to be generated by different processes, and we fit the three-part NOP model. The

The NOP model provides a substantial improvement of the likelihood and is preferred to the standard OP model according to AIC and the Vuong test (the p-value is 0.01). However, the Vuong tests with the corrections based on AIC and BIC are indifferent between the two models. Endogenous switching does not significantly improve the likelihood of the NOP model (the log likelihood with endogenous switching is −151.0, the p-value of the LR test of the null of exogenous switching is 0.48), the correlation coefficients ρ − and ρ + are not significant, and both AIC and BIC favor the NOP model with exogenous switching.
Next we allow for an inflation of zero outcomes and fit the three-part ZIOP-3 model. The
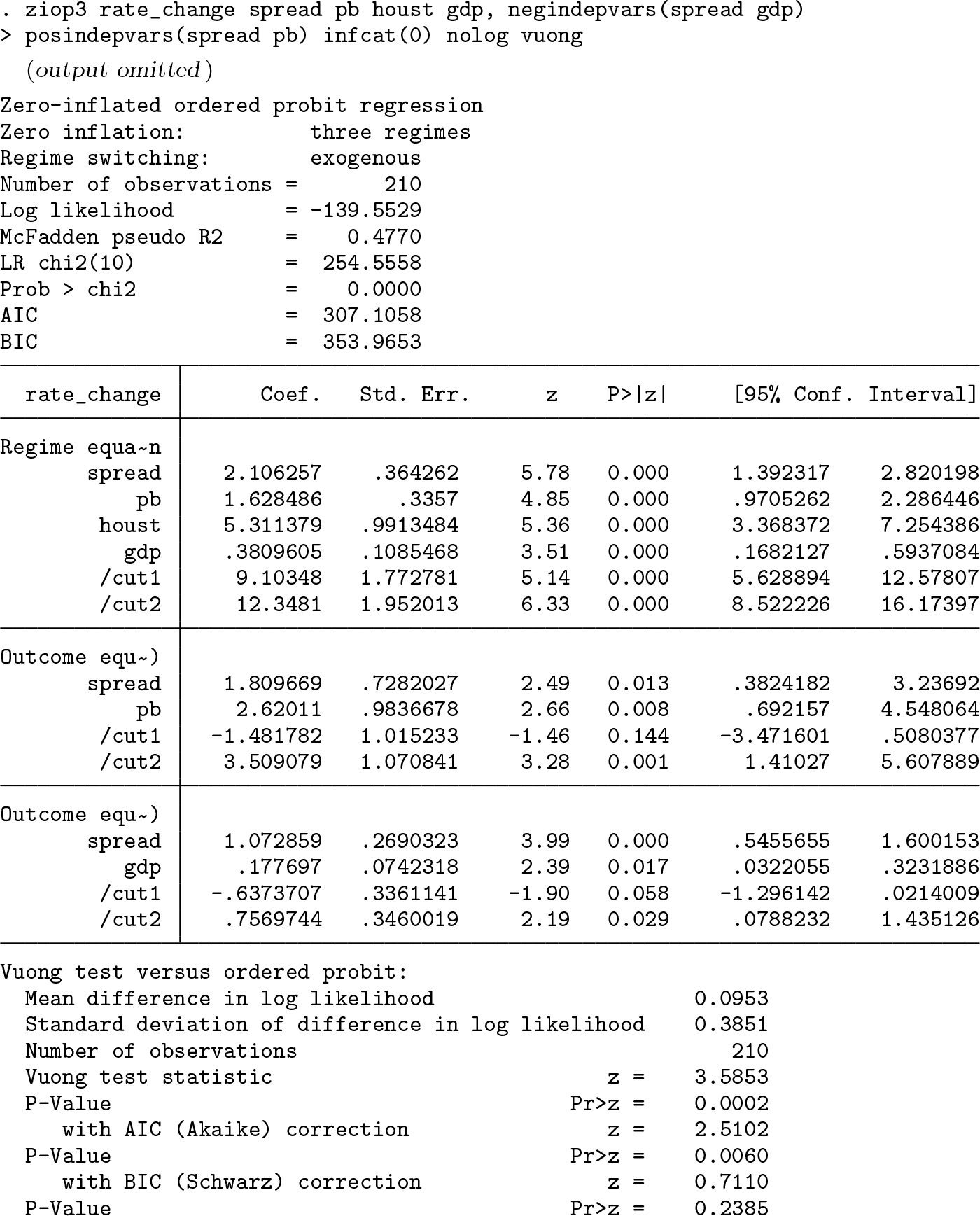
The empirical evidence in favor of zero inflation is convincing: with only two extra parameters, the ZIOP-3 model has a much higher likelihood than the NOP model (−139.6 versus −151.0) and is clearly preferred by both AIC and BIC to the NOP and OP models. The Vuong tests for zero inflation (the standard one and one with the correction based on AIC) favor the ZIOP-3 model over the OP model at the 0.001 and 0.01 level, respectively. Endogenous switching does not significantly improve the likelihood of the ZIOP-3 model either (the p-value of the LR test of exogenous switching is 0.30, and both AIC and BIC prefer the exogenous switching).
In contrast, the likelihood of the two-part ZIOP-2 model is even lower than that of the NOP model. According to both AIC and BIC, the ZIOP-2 model is inferior to all the above models, including the OP one. The

The Vuong tests prefer the ZIOP-3 model to the ZIOP-2 model at the 0.01 significance level using the standard test statistic and at the 0.02 and 0.03 levels using the corrected statistics based, respectively, on AIC and BIC:

Now we report the selected output of the postestimation commands, performed for the ZIOP-3 model.
The predicted choice probabilities at the specified values of the independent variables can be estimated using the

The predicted probabilities of the three latent regimes

The average predicted probabilities of the regimes st = −1, st = 0, and st = 1 in the sample are 0.40, 0.39, and 0.21, respectively. However, the average probability of zeros conditional on the regime st = −1 (0.15) is much higher than on the regime st = 1 (0.00).
The marginal effects of the independent variables on the choice probabilities at the specified values of the independent variables can be estimated using the
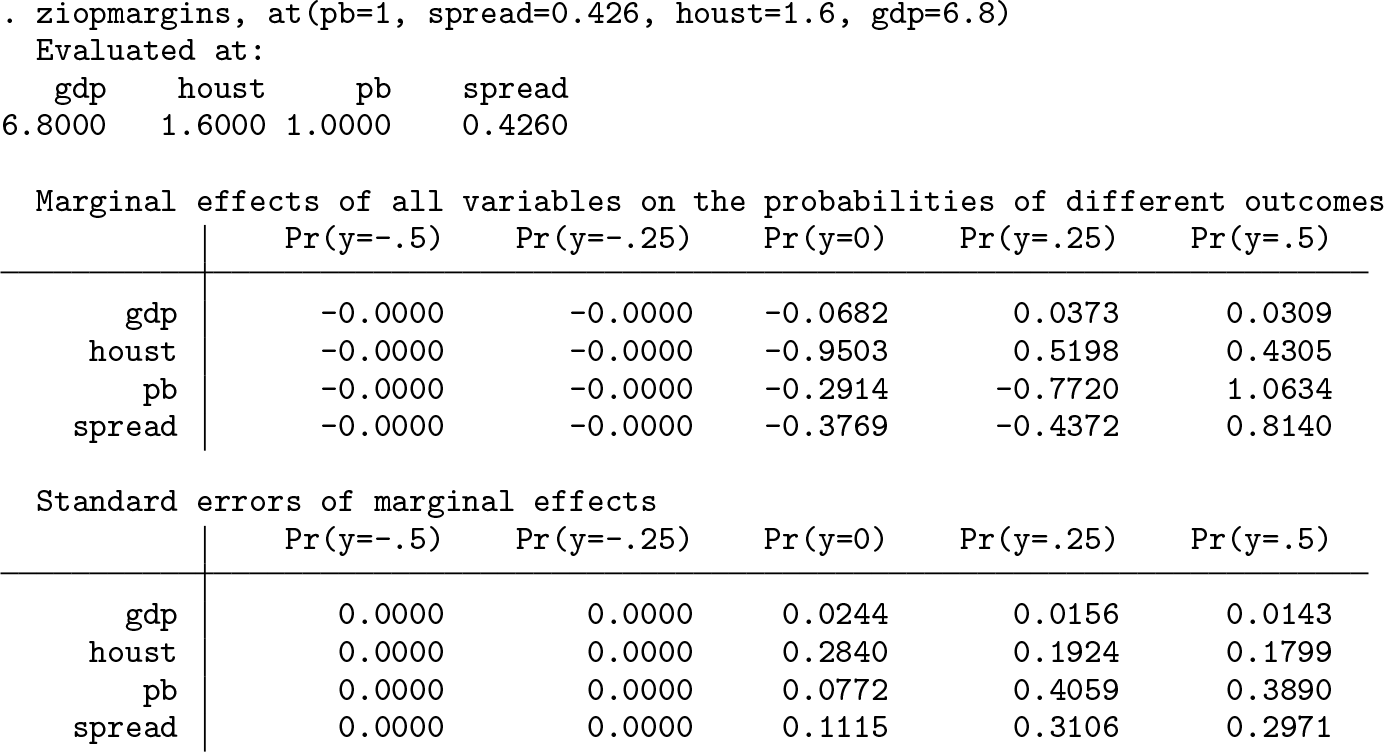
The differences in the predicted choice probabilities (along with the standard errors) at two different values of the independent variables can be estimated using the

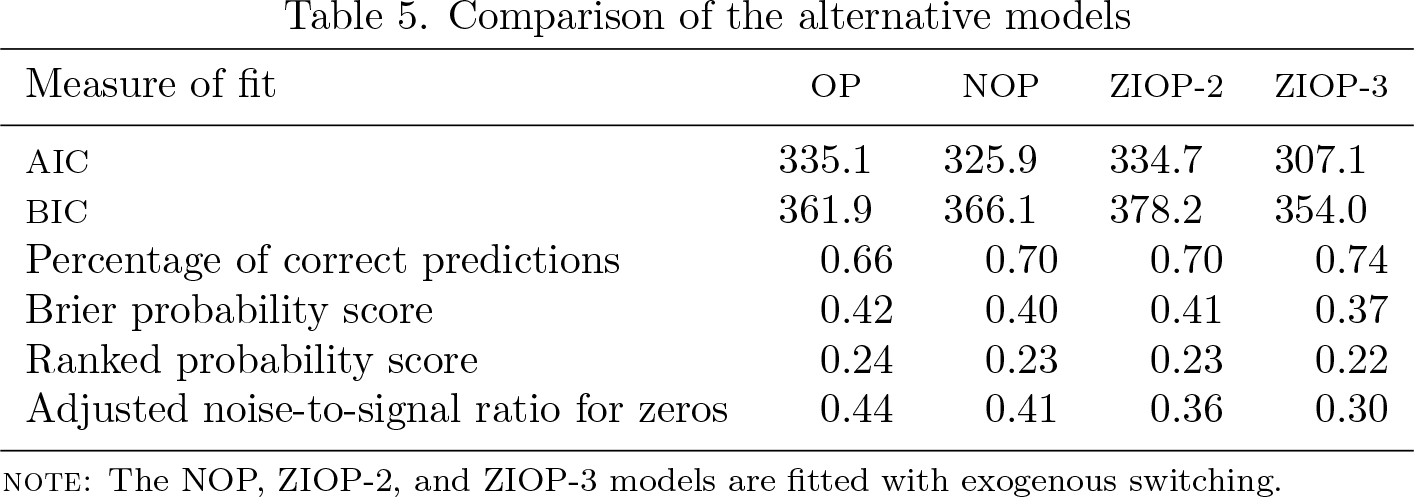
Finally, the different measures of model fit and the accuracy of the probabilistic predictions can be computed using the

As table 5 reports, the ZIOP-3 model demonstrates the best fit according to all the criteria.
Comparison of the alternative models
6 Concluding remarks
In this article, we described the ML estimation of the nested and cross-nested zero-inflated OP models using the new commands
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000002 - Estimation of nested and zero-inflated ordered probit models
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000002 for Estimation of nested and zero-inflated ordered probit models by David Dale and Andrei Sirchenko in The Stata Journal
Footnotes
7 Acknowledgments
We gratefully acknowledge support from the Basic Research Program of the National Research University Higher School of Economics in Moscow.
8 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
A Appendix
Monte Carlo experiments: The true values of parameters in the first set of simulations

| NOP (exog) | NOP | ZIOP-2 (exog) | ZIOP-2 | ZIOP-3 (exog) | ZIOP-3 | |
|---|---|---|---|---|---|---|
| γ | (0.6, 0.4)′ | (0.6, 0.4)′ | (0.6, 0.8)′ | (0.6, 0.8)′ | (0.6, 0.4)′ | (0.6, 0.4)′ |
| µ | (0.21, 2.19)′ | (0.21, 2.19)′ | 0.45 | 0.45 | (0.9, 1.5)′ | (0.9, 1.5)′ |
| β | (0.5, 0.6)′ | (0.5, 0.6)′ | ||||
| β− | (0.3, 0.9)′ | (0.3, 0.9)′ | (0.3, 0.9)′ | (0.3, 0.9)′ | ||
| β+ | (0.2, 0.3)′ | (0.2, 0.3)′ | (0.2, 0.3)′ | (0.2, 0.3)′ | ||
| α | (−1.45, −0.55, 0.75, 1.65)′ | (−1.18, −0.33, 0.9, 1.76)′ | ||||
| α− | −0.17 | −0.5 | (−0.67, 0.36)′ | (−0.88, 0.12)′ | ||
| α+ | 0.68 | 1.3 | (0.02, 1.28)′ | (0.49, 1.67)′ | ||
| ρ | 0 | 0.5 | ||||
| ρ− | 0 | 0.3 | 0 | 0.3 | ||
| ρ+ | 0 | 0.6 | 0 | 0.6 |
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.