
Abstract
Researchers often want to examine the relationship between a variable of interest and multiple related outcomes. To avoid problems of inference that arise from testing multiple hypotheses, one can create a summary index of the outcomes. Summary indices facilitate generalizing findings and can be more powerful than individual tests. In this article, we introduce a
1 Introduction
In statistical analysis, one is often interested in looking at the causal relationship between a variable of interest and multiple outcomes. Intuitively, the more hypotheses one tests, the more likely one is to erroneously reject a null hypothesis. Various corrections exist, including the familywise error rate, the false discovery rate, or the particularly conservative Bonferroni correction. Using a summary index as an outcome is an alternative or complementary solution. A summary index combines multiple indicators into a single index, allowing one to test the single hypothesis of whether the index is affected by a causal variable of interest, as opposed to testing multiple related hypotheses individually. This accommodates a statistical test for whether a program has a general effect on a set of outcomes as opposed to a series of related tests.
For example, a study might be interested in estimating the impact of a program on empowerment. Empowerment is a multidimensional concept, and a variety of indicators could be used to measure it. Such indicators might include decision-making power regarding spending over a particular item or items, ownership of a particular asset or assets, freedom to travel to a specific location or locations, and values or behaviors regarding intimate partner violence. Rather than test for the relationship between each of these indicators and the program of interest, which suffers from the multiple comparison problem, a researcher may wish to simply say something about the effect of a program on empowerment, broadly speaking. A summary index compiles information from each of these indicators into a single measure of empowerment, accommodating a single hypothesis test.
Aggregating multiple related outcomes into a summary index of a broader outcome can also facilitate generalizing findings, particularly when it comes to making broad conclusions about an intervention’s effectiveness. For instance, a researcher could find a program increases women’s control over spending decisions and improves a woman’s freedom to travel, while having no significant impact on asset ownership or reported intimate partner violence. With only the estimates of impact for multiple indicators over a range of related outcomes, coming to a succinct conclusion as to whether the program improves women’s empowerment can be difficult. Suppose instead the researcher creates a summary index of empowerment, which reveals a positive impact on the summary index. The researcher can then say the program, broadly speaking, increases women’s empowerment.
One obvious criticism of this generalized conclusion is that it fails to really explain or unpack what is going on. In some sense, the summary index is a “black box”. In response to this criticism, the researcher could then unpack the index by estimating the same regression using each of the components of the index as individual outcomes, as we will show in the example presented later in this article. In this way, using a summary index does not preclude researchers from going into greater detail about the mechanisms behind the generalized findings. Reporting and discussing individual indicator impacts remains common practice and can help unpack the “black box” index-based findings— with the caveat that doing so retains the multiple comparison problem and is therefore often considered exploratory.
Summary index-based tests can also be more statistically powerful than individual- level tests. As described in Anderson (2008), multiple outcomes that approach significance may aggregate into a single index that attains statistical significance. Each indicator is measured with some error and may exhibit (pretreatment) imbalance in finite samples. When one aggregates variables into an index, random errors that are uncorrelated across indicators are more likely to cancel each other out as the number of indicators increases. Thus, summary indices as outcomes can be less noisy than individual variables.
In some cases, an established summary index exists for some broadly defined outcome. For example, Alkire et al. (2013) propose the women’s empowerment in agriculture index, which was developed through collaboration among the United States Agency for International Development, the International Food Policy Research Institute, and Oxford Poverty and Human Development Initiative and has been implemented as part of the United States Agency for International Development’s Feed the Future initiative to monitor changes in empowerment in many countries and across multiple continents. Established indices like the women’s empowerment in agriculture index can be helpful in many contexts, but by definition they are not very flexible. A given dataset may not always have the requisite indicators, such indices often rely on arbitrary weights, and missing observations can be problematic. Moreover, it is often the case that an established summary index does not exist, and it is up to the researcher to develop one from scratch. Such ad hoc indices can lead to p-hacking, especially if a researcher constructs the index ex post.
The new
2 Constructing a summary index
Anderson (2008) proposes constructing a summary index using a generalized least-squares (GLS) weighting procedure, which has two primary advantages. First, it increases efficiency by ensuring highly correlated indicators receive less weight than uncorrelated indicators. Intuitively, uncorrelated indicators, which represent “new” information, receive more weight. Second, the procedure uses all available data but ascribes lower weight to indicators with missing values, which allows for the calculation of the summary index even for observations with missing indicators.
The index requires k ≥ 2 indicators related to the outcome the researcher seeks to summarize. All indicators should be related to a singular theme (for example, an index of “freedom and prosperity” combines two separate concepts rather than a singular theme). Indices can be constructed using a mix of continuous and binary indicators, and combinations of the two are commonly used (see Haushofer and Shapiro [2016] and Janzen et al. [2018] for examples). The researcher is simply required to assign each variable with a direction (that is, polarity)—positive or negative. In the empowerment example, an indicator that takes a higher value for greater control over assets could enter into an empowerment index without any adjustment, and higher values for the indicator would also lead to a higher summary index. An indicator that takes a higher value for experiencing more or worse intimate partner violence decreases empowerment, so the indicator must enter the index negatively.
Categorical or ordinal variables that might otherwise be analyzed as outcomes using a multinomial or ordered logit regression could be incorporated by creating a binary variable for each response if we classify some responses as contributing positively to the index and others as contributing negatively. For an example of how a categorical variable can be incorporated into a summary index, suppose we want to create a “green behavior” index. Suppose we have binary variables for “walk”, “bicycle”, “public transportation”, and “private vehicle”. The first three indicators could enter positively into the index, while a binary variable for “private vehicle” could enter negatively into the index. Alternatively, a single binary variable could be created for “green transport” that takes on a value of 1 for “walk”, “bicycle”, or “public transport” and 0 otherwise, and this variable could enter positively into the index. With an ordinal variable, we could either treat it as cardinal or dichotomize it and choose a reference level above which it should enter positively into the index and below which it should enter negatively. As an example, suppose we wanted to include the response to a question about attitudes toward climate change posed using a Likert scale as an indicator to be included in a “green attitudes” index. Suppose the respondent is asked to state whether he or she agrees with the statement “Combatting climate change should be a top policy priority.” Response options are 1 = disagree, 2 = somewhat disagree, 3 = neither agree nor disagree, 4 = agree, and 5 = strongly agree. We could either allow the variable to enter as a continuous variable with values ranging from 1 to 5 or create a binary variable for a negative response (1 or 2) that enters negatively into the index and a binary variable for a positive response (4 or 5) that enters positively into the index.
Using the Anderson (2008) approach, we can calculate the standardized weighted index Select k indicators relevant for outcome j. Adjust sign: For all k indicators, ensure the positive direction always indicates a “better outcome”. Normalize indicators: Demean all k indicators by subtracting the mean of the indicator in the reference group (the full sample is the default reference group). Then, convert them to effect sizes, Construct weights: Create weights using Σ−
1, the inverse of the covariance matrix of the normalized indicators.
2
Specifically, set the weight Construct index: Calculate the weighted average of Normalize index: Demean index
3 The swindex command
3.1 Syntax
The syntax of

3.2 Options
3.3 Stored results
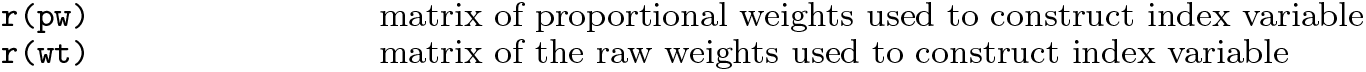
3.4 Summary of swindex command
The command stores the inverse-covariance weights for each variable in varlist calculated by
Several options are provided to allow the user to customize the calculation. Variables included in the index should work in the same direction (for example, increases in the variables all indicate better outcomes).
The recommended method standardizes the indicator variables in varlist prior to constructing the inverted covariance matrix used in the GLS weighting procedure. This standardization can use a subsample (for example, the control group) as a reference group, or otherwise use the full sample as a reference group, for calculating the mean and standard deviation used for normalization. By default, the program normalizes against the full sample mean and standard deviation, which is equivalent to obtaining the weights by inverting the correlation matrix. If the user wishes to use the mean and standard deviation from a subsample, the user may specify the subsample varname using the
By default, the program rescales the calculated index to the mean and standard deviation of the sample used for the standardization in the GLS weighting procedure. This rescaling results in an “effect size” interpretation where the index is normally distributed with mean zero and standard deviation one for the sample used. The
The procedure accommodates construction of the index even when data on indicators are missing. It does so by setting missing indicator values to zero, which is the mean of the reference group following normalization. The
4 Example
To illustrate how
Blattman, Fiala, and Martinez (2014) measure intent-to-treat (ITT) estimates of the YOP impact across a range of individual outcomes. In each regression, they control for a set of individual baseline characteristics and district fixed effects. Errors are clustered at the group level (the level of treatment), and observations are weighted by the inverse probability of selection into endline tracking. The original analysis groups the estimation into six key outcomes. At the four-year endline, more than one indicator is used for four of these main outcomes—business formality, income, employment, and migration and urbanization.
In this example, we will replicate the estimated impact of YOP after four years for each indicator related to business formality, income, employment, and migration and urbanization. This replicates a subset of the results originally presented in table 3 of Blattman, Fiala, and Martinez (2014). We then calculate a summary index of the indicators for each outcome using the
Descriptive statistics and ITT estimates of program impacts on key outcomes

NOTES: Column 1 reports the control group mean at the four-year endline, weighted by the inverse probability of selection into the endline sample. Columns 4–5 report the ITT estimate and standard error of program assignment at endline. Standard errors are heteroskedastic robust and clustered by group. We calculate the ITT via a weighted least-squares regression of the dependent variable on a program assignment indicator, 13 district (randomization stratum) fixed effects, and a vector of control variables that includes all the baseline covariates reported in table II of Blattman, Fiala, and Martinez (2014). Variable names preserved from the original replication code of Blattman, Fiala, and Martinez (2014).
***p < .01, **p < .05, *p < .1.
First, we consider business formality, which contains three dummy variables as indicators: maintenance of formal records (

The proportional weights assigned to each indicator are presented as part of the output because the
We are now ready to estimate the impact of the program on each indicator related to business formality (replicating the results of Blattman, Fiala, and Martinez [2014]), as well as our newly generated summary index (
The local
We then analyze the impact of the intervention on income, where Blattman, Fiala, and Martinez (2014) also report impacts using three indicators: monthly cash earnings (
The third outcome, employment, uses a greater number of indicators and requires a little more thought to construct and understand the index. The indicators included in our summary index are the following: average employment hours per week ( nonworking hours ( skilled trade working hours ( a dummy variable for working zero hours in the past month that enters negatively ( a dummy variable for being engaged in any skilled trade ( a dummy variable if the individual worked at least 30 hours a week in a skilled trade (
We omit one of the original indicators reported in Blattman, Fiala, and Martinez (2014)—the number of hours spent working on agricultural activities. We do this because the intervention targeted business development rather than agriculture, and it is not immediately obvious if agricultural hours should enter the index positively or negatively. (Notably, there is no discernible impact of the YOP intervention on the number of hours worked.) We use the

We see much greater variation in the weights assigned to the indicators. Recall the index ascribes greater weight to an indicator if it contributes “new” information—that is, if it is not highly correlated with other indicators. In this example, several indicators are highly correlated for obvious reasons. For example, a dummy variable for being engaged in any skilled trade and a dummy variable for being engaged in at least 30 hours of skilled trade are directly derived from the number of skilled trade hours worked; hence, we observe skilled trade hours entering the index with a partially offsetting negative weight. When estimating the impact of the treatment on the employment summary index, we observe a 0.355 standard-deviation impact.
The final outcome we consider is an index of migration and urbanization. For this index, we have only two indicators, one a dummy variable indicating recent migration to a different parish (
As a final word of caution, we note that
5 Conclusion
Using a summary index accommodates testing a single hypothesis of whether the index is affected by a causal variable of interest, as opposed to testing multiple related hypotheses individually. This article presented the
Supplemental Material
Supplemental Material, st0622 - Constructing a summary index using the standardized inverse-covariance weighted average of indicators
Supplemental Material, st0622 for Constructing a summary index using the standardized inverse-covariance weighted average of indicators by Benjamin Schwab Kansas, Sarah Janzen, Nicholas P. Magnan and William M. Thompson in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.