
Abstract
In this article, I build on the work of Abadie and Gardeazabal (2003, American Economic Review 93: 113–132) and Abadie, Diamond, and Hainmueller (2010, Journal of the American Statistical Association 105: 493–505), extending the synthetic control method for program evaluation—implemented in Stata via the community-contributed command
1 Introduction
Social scientists nowadays recognize counterfactual evidence as an indispensable principle for reliably assessing the effects of specific events or policy interventions (Angrist and Pischke 2010).
Counterfactual program evaluation is particularly popular for microlevel analysis, the standard tool for detecting the effect of a program to specific target variables (Angrist and Pischke 2009; Cerulli 2015; Imbens and Rubin 2015). However, the current large availability of aggregated longitudinal (or panel) data has pushed some authors to extend the counterfactual logic to the macrolevel, where aggregate entities such as countries, regions, and cities are the units of interest.
The synthetic control method (SCM), recently proposed by Abadie and Gardeazabal (2003) and Abadie, Diamond, and Hainmueller (2010), is a powerful approach to extend the counterfactual approach to assess macropolicy effects. This approach imputes the missing counterfactual status of a specific treated unit as a weighted average of a number of control units (the so-called donors pool). The weights are computed by minimizing a vector distance between the treated unit and the donors over a series of preintervention covariates. The main philosophy underlying the SCM is that combining units (properly) often provides a better comparison for the unit exposed to the intervention than any single unit taken alone.
It is clear that the choice of the weights is at the heart of the model. The SCM proponents choose weights by minimizing a specific objective function, that is, the prediction error between the treated series of the covariates of interest (including the outcome) and the series generated by a linear combination of the same variables for the nonexposed units.
Such an approach entails a least-squares regression, which assumes a parametric estimation of the weights that are the parameters to estimate in the regression. This model implicitly assumes a linear conditional mean (or projection) of the treated unit’s covariates in the vector space spanned by the donors’ covariates. 1 If this conditional mean is not linear, or more generally is unknown, the weights may be inconsistently estimated, and the counterfactual imprecisely imputed.
Therefore, relaxing the linearity assumption by providing a nonparametric estimation of the weights may somehow improve their estimation under certain conditions, thus providing a more reliable imputation of the missing counterfactual.
I propose a procedure to nonparametrically estimate SCM weights using a local average kernel approach (Pagan and Ullah 1999; Hastie, Tibshirani, and Friedman 2009; Li and Racine 2007). It sets out the econometrics of the method and presents an application for a (parametric versus nonparametric) comparative assessment of the effects on exports of adopting the Euro as national currency in the case of Italy.
I present
The structure of the article is as follows. Section 2 provides a short account of the parametric SCM as proposed by Abadie and Gardeazabal (2003). In the exposition, I will follow the example presented by the authors in their article. Section 3 presents the proposed nonparametric approach. Section 4 sets out the main documentation of the command
2 Parametric approach
Abadie and Gardeazabal (2003) pioneered the SCM when estimating the effects of the terrorist conflict in the Basque Country, using other Spanish regions as a comparison group. In that article, the authors evaluated whether terrorism in the Basque Country had a negative effect on regional growth. Because none of the other Spanish regions followed the same time trend as the Basque Country, the authors could not use a standard difference-in-differences approach, because the parallel trend identification assumption was in this case violated (Card and Krueger 1994; Autor 2003).
They proposed therefore to take a weighted average of other Spanish regions as a “synthetic control” group to avoid relying either on a single region or on a sharp arithmetic mean of all the remaining regions as counterfactual. They showed both strategies would lead to a spurious imputation of the missing counterfactual. In what follows, I provide a concise account of the model by following the authors’ example and notation.
Suppose we have J available control regions (that is, the 16 Spanish regions other than the Basque Country). The main task of the authors’ proposed model is to assign weights ω = (ω
1
,…, ωJ
)′—which is a (J × 1) vector—to each region with ωj
≥ 0 and
Let

The optimal weights are those making the real per capita GDP path for the Basque Country during the 1960s (the preterrorism time span) best reproduced by the resulting synthetic Basque Country. Alternatively, the authors could have just chosen the weights to reproduce only the preterrorism growth path for the Basque Country.
The last step concerns the construction of the “counterfactual” using the optimal weights as follows: let let
Analytically, the authors obtain the counterfactual per capita GDP pattern (that is, the one in the absence of terrorism) as

To validate the estimation of the weights, the authors require that the patterns of
Finally, the authors provide inference for the statistical significance of results using a placebo test. This allows them to reject the null hypothesis of no effect anytime the treated unit’s treatment effect takes unusual values compared with those of the placebo units.
3 Nonparametric version
In this section, I provide an extension of the SCM to a nonparametric estimation of the weights (and, thus, of the missing counterfactual). 2 The basic idea is that of computing the weights as proportional to the vector distance between the treated unit and the controls, using a kernel weighting scheme. In other words, given a certain bandwidth, this method allows for estimating a vector of weights proportional to the distance between the treated unit and all the rest of untreated ones. Consequently, instead of relying directly on one single vector of weights common to the entire period, one can obtain a vector of weights for each of the periods considered, eventually averaging them to obtain the unique set of weights. To make the exposition clearer, the next section sets out a simple example for understanding the logic and econometrics of the proposed model. 3
3.1 An illustrative example
Suppose that the treated country is the United Kingdom (UK), with treatment starting in 1973. Assume that the pretreatment period is 1970, 1971, 1972 and that the post- treatment period is 1973, 1974, 1975. Suppose we use three countries as donors: France (FRA), Italy (ITA), and Germany (GER), using a set of M covariates,
We define a distance metric based on

Given a distance definition, the pretreatment weight for ITA will be

where K(·) is a specific kernel function, h the bandwidth chosen by the analyst, and ||·|| a specific norm. The kernel function defines a weighting scheme penalizing countries that are far away from the UK and giving more relevance to countries closer to the UK. Observe that closeness is measured in terms of a predefined
Based on the chosen vector distance defined over the covariates

where, in this example, j = UK and s = FRA, ITA, GER.
Figure 1 provides a graphical and intuitive representation of (1). Once one has set a bandwidth h, each country in each year obtains a weight decreasing with the increasing distance from the UK. In this illustrative example, ITA gets a positive value because its distance from the UK is smaller than h; GER, on the contrary, gets a weight equal to zero because its distance from the UK is larger than h. Of course, the UK itself obtains the largest weight by default.

Kernel weights representation
Following this simple example, we can define the weighting matrix

One issue is that we need just one single vector of weights, while the previous procedure provides a vector of weights for each pretreatment year. We can overcome this minor problem by taking the mean (or the median) of the yearly weights, thus defining the following augmented weighting matrix,

where
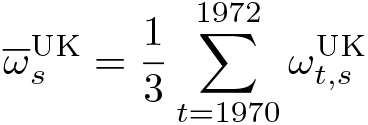
Define the matrix of outcomes

We can define a matrix

The diagonal of matrix

This vector is an estimation of the unknown counterfactual behavior of the UK. The generic element of the diagonal of

In the previous example,

Therefore, ct —that is, the synthetic outcome of the UK—is a weighted mean of controls’ y at time t, with weights provided by the previous procedure.
Previous estimation of the synthetic counterfactual is based on a specific choice of the bandwidth h. Thus, one question is how to select such bandwidth properly. As usual with nonparametric estimators, a cross-validation approach can be used (Li and Racine 2004). In this context, it reduces to select the optimal bandwidth as the one minimizing as loss objective function the preintervention root mean-squared prediction error (RMSPE) defined as

where T − 0 is the last pretreatment time. We can estimate the optimal bandwidth computationally by first forming a grid of possible values for h and then finding h ∗ as the value of the bandwidth minimizing the RMSPE over the grid. We provide an application of such a procedure in the next section.
4 The npsynth command
This section provides the documentation of the command
4.1 Syntax

outcome is the target variable over which one measures the impact of the treatment. varlist is the set of covariates (or observable confounding) predicting the outcome in the pretreatment period.
4.2 Description
4.3 Options

4.4 Stored results

4.5 Requirements
Before running
Finally, cross-validation optimal bandwidth can be obtained using the
5 Simulation
Before presenting an application on real data, I perform a simulation example to show how
I perform an SCM simulation using a data-generating process (DGP) where E(
Because the simulation code is pretty long, for the sake of brevity, I do not report the code here. One can reproduce it by running the do-file
We consider a setting with three normally distributed covariates x 1 , x 2 , x 3, one treated unit, and three donors {1, 2, 3}. We model the three covariates for the treated unit in a highly nonlinear way as a function of the respective covariates of the three donors,
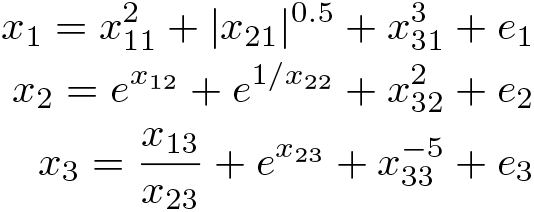
where ei
are normally distributed errors. This specification of E(

while the counterfactual is

where the year of treatment is 2009. Figure 2 sets out the plot of the factual and counterfactual pattern of the treated unit according to the above specified DGP.

Simulated factual and counterfactual pattern of the treated unit outcome when the policy occurs at year 2009
Also, we generate the donors’ pattern as the counterfactual pattern of the treated units plus a normally distributed shock with different means and variances. Results are plotted in figure 3.

Simulated treated and donors outcome pattern, when policy occurs in year 2009
We apply both

Estimated counterfactual: Comparison between
As expected, results show that
6 Application
In this section, I compare the proposed nonparametric approach and the parametric approach provided by Abadie, Diamond, and Hainmueller (2010) by focusing on the effects of adopting the Euro as the national currency. In 2001, some European countries abandoned their national currencies to adopt the Euro. It is thus interesting to understand whether this relevant institutional change has had an impact on European economies. Of course, one can consider many outcome variables over which to measure such an effect. In this exercise, we focus on one specific country, Italy, and one specific outcome, namely, the domestic direct value added (DDVA) exports obtained by using the gross export decomposition suggested by Wang, Wei, and Zhu (2013).
To evaluate the goodness of fit of both procedures, we consider the preintervention RMSPE for Italy (that is, the average of the squared discrepancies between DDVA in Italy and in its synthetic counterpart during the pretreatment period). As donors, we consider a set of 18 countries worldwide that experienced no change in currency adoption during the period under scrutiny. In this case, the RMSPE formula is

with T − 0 = 1999. We consider 2000 as the year of treatment because many transactions were done using the Euro starting from one year before the currency was officially adopted.
The model specification is a type of gravity model, which is standard in the economics of trade, taking as explanatory variables the same DDVA, the log of the distance between each pair of countries, the sum of their GDP, the presence of a common language, and a contiguity measure between countries.
By applying the Abadie, Diamond, and Hainmueller (2010) model to this dataset and specification, we obtain the following results:

The RMSPE is equal to 0.008, which is quite small. The donors’ optimal weights, as reported above, show that only four countries are used as donors: Great Britain, Japan, Poland, and Sweden. The largest weight is the one of Poland, with a value of around 0.6, followed by that of Japan (0.18), and Great Britain (0.12). The subsequent panel, finally, shows that all the predictors are sufficiently balanced, thus entailing a good quality in the construction of the pretreatment synthetic counterfactual.
The good performance provided by the Abadie, Diamond, and Hainmueller (2010) method is confirmed by figure 5, plotting over the years the treated and synthetic pattern of the outcome variable DDVA. This figure clearly shows an effect of adopting the Euro, because after 2000, the synthetic and treated patterns diverge considerably. In particular, it seems that in the absence of the Euro, the DDVA would have been lower than that experienced in adopting the Euro. This means that the Euro seems to have had positive effects in increasing the DDVA component of the gross export for Italy.
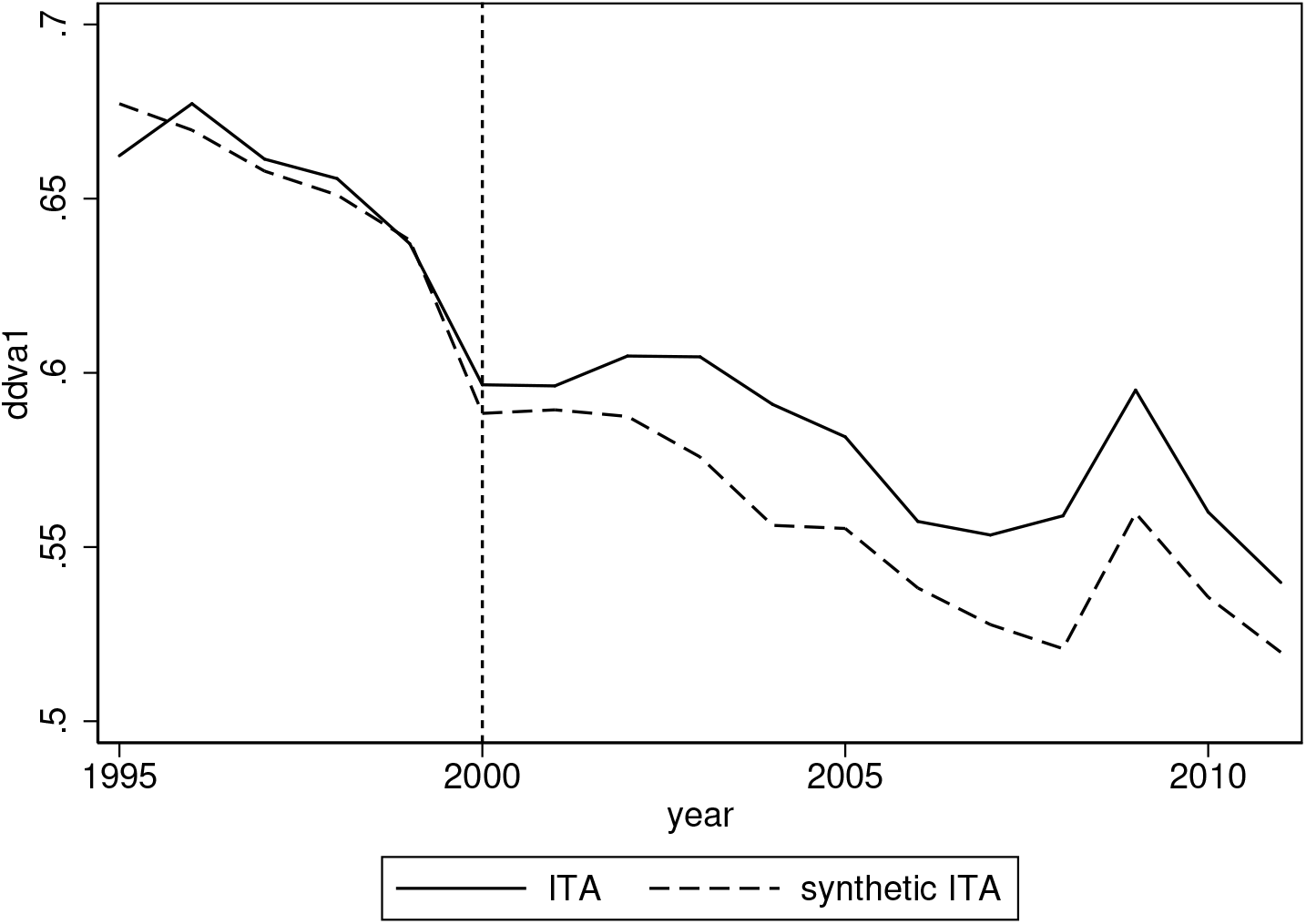
Treated and synthetic pattern of the outcome variable DDVA. Parametric model.
When applying the nonparametric approach proposed here, one has to first find the optimal bandwidth. As said, we select the bandwidth by minimizing the RMSPE. Results are reported in figure 6, where we can see that the RMSPE is minimized at a bandwidth equal to 0.5. Both the optimal bandwidth and the graph in the figure can be obtained by inserting the option

Optimal bandwidth by minimizing the RMSPE
A graphical inspection, however, shows that a bandwidth equal to 0.4 (namely, a slight undersmoothing) performs better for years closer to the treatment year, thus making it more appropriate to use such a bandwidth as the optimal one in the estimation of the synthetic pattern. The panel of results below sets out that the value of the RMSPE is 0.01, a bit larger than that found in the parametric case. Also, the weighting scheme is different, with more donors having a nonzero weight, and China obtaining the lion’s share.

The graph in figure 7 shows a good fit of the model, which slightly outperforms the parametric method when gradually approaching the treatment time. This improvement is not signaled by overall RMSPE, because the nonparametric estimation performs worse than the parametric one at the very beginning of the pretreatment period, which is less relevant, however, for assessing the overall quality of the fit. To assess that


Treated and synthetic pattern of the outcome variable DDVA. Nonparametric model.
In this case, we can see that the nonparametric approach behaves a bit better than the parametric one (with a RMSPE of 0.0034 against 0.0048), although both provide a small pretreatment prediction error.
7 Conclusions
This article has provided an extension of the SCM for program evaluation to the case of a nonparametric identification of the synthetic (or counterfactual) time pattern of a treated unit. After briefly presenting the parametric method, I introduced the nonparametric alternative by focusing on
The novel approach herein proposed can thus complement the traditional one by providing more robustness to program evaluation results obtained using the SCM.
Supplemental Material
Supplemental Material, st0619 - Nonparametric synthetic control using the npsynth command
Supplemental Material, st0619 for Nonparametric synthetic control using the npsynth command by Giovanni Cerulli in The Stata Journal
Footnotes
8 Acknowledgments
I thank the organizers of and participants in the 23rd London Stata Conference, held on the 7–8 September 2017 at Cass Business School (London, UK), where a preliminary version of this article was presented. In particular, I thank Kit Baum for the careful reading of this article.
9 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
This routine is freely downloadable from the Stata Statistical Software Components archive,
. ssc install npsynth
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.