
Abstract
A few years ago, we developed
Keywords
1 Introduction
Meta-analysis is a statistical methodology that combines the results of several independent studies, clinical trials or observational, that are considered appropriate to combine (Huque 1988). Traditionally, the term “meta-analysis” refers to pairwise meta-analysis of aggregate data. Pairwise implies a two-arm comparison, usually an intervention and a control arm, as opposed to the more recently developed network meta-analysis methods (Lumley 2002; Salanti, Ades, and Ioannidis 2011). Aggregate implies pooling reported results, usually in research articles, and involves extracting data on effects (or associations) and their variability, as opposed to the more challenging but also more promising individual patient data meta-analysis (Riley, Lambert, and Abo-Zaid 2010). Meta-analysis of aggregate data methodology focuses on the second step of a two-step process, the “pooling” of the extracted summary statistics into a weighted average, with the
Arguably the biggest threats to meta-analysis, particularly meta-analysis of aggregate data, are publication bias and heterogeneity. Publication bias is extremely difficult to identify and address convincingly, with methods to identify it being underpowered in small meta-analyses (Sterne, Gavaghan, and Egger 2000) and methods to account for it requiring strong assumptions, thus making them contentious. For example, the intuitive and widely used trim-and-fill method (Duval and Tweedie 2000) fails to account for funnel-plot asymmetry that could be due to heterogeneity and thus can be too conservative (Peters et al. 2007). Heterogeneity, or between-study variance, is also difficult to reliably identify and stems from differences in populations, interventions, outcomes, follow-up times (clinical heterogeneity), or differences in trial design and quality (methodological heterogeneity) (Higgins and Thompson 2002; Thompson 1994). The difficulty in quantifying heterogeneity, as with publication bias, primarily relates to the small size of a typical meta-analysis and the fact that the underlying methods are asymptotic and work well with large study numbers.
How to appropriately address heterogeneity is another key validity issue. Fixedeffects models will not account for identified heterogeneity, assuming a single “true” effect, and thus limit the generalizability of the findings to the pooled studies. Randomeffects models will incorporate identified heterogeneity by assuming multiple “true” effects (some will assume they are normally distributed as well) and are typically more conservative and allow generalization. Considering that in the presence of heterogeneity, the performance of a fixed-effects approach deteriorates rapidly (Brockwell and Gordon 2001) and that random-effects models are robust even when the “true” effects deviate from normality (Kontopantelis and Reeves 2012a,b), we think that heterogeneity should always be modeled for the results to be generalizable–at any level and not only when above a certain arbitrary threshold (for example, I 2 > 50% as is sometimes the case). Although methods to model heterogeneity are robust, the underlying problem is how to accurately estimate existing heterogeneity. Although homogeneity has been found to be the exception rather than the rule and some degree of “true” effect variability between studies is to be expected (Thompson and Pocock 1991), unobserved heterogeneity is a real problem, especially for meta-analyses of a few studies that tend to be the norm (Kontopantelis, Springate, and Reeves 2013).
To estimate heterogeneity, the standard approach is the method proposed by DerSimonian and Laird (1986), which has been widely implemented and is the default random-effects approach in generic and specialist meta-analysis statistical software. However, the between-study variance component can be estimated using alternative approaches, including iterative or nonparametric methods. These include maximum likelihood, profile likelihood, restricted maximum likelihood (REML) (Hardy and Thompson 1996; Thompson and Sharp 1999), and the nonparametric “permutations” method proposed by Follmann and Proschan (1999). A nonparametric bootstrap of the DerSimonian– Laird (DL) estimator was also shown to be a better performer, especially in small metaanalyses that were falsely assumed to be homogeneous under the standard DL model (Kontopantelis, Springate, and Reeves 2013), and that was recently verified in a more complete and independent simulation comparison (Petropoulou and Mavridis 2017). Because of the difficulty in detecting underlying heterogeneity in small meta-analyses and inaccurate estimates, sensitivity analyses using a range of heterogeneity levels have also been recommended (Kontopantelis, Springate, and Reeves 2013). Small meta-analyses are also more likely to end up with a sample of studies that is not representative, which can result in incorrect estimates of true heterogeneity.
We have implemented all these methods in
2 The metaan command
2.1 Updates to metaan
Since February 25, 2013: new meta-analysis models, bootstrap DL, and sensitivity analysis using preset values for I
2. August 14, 2014: dealing with proportions with the Freeman–Tukey transformation. September 5, 2014: support for α level other than 5%; reporting confidence intervals for heterogeneity measures. September 18, 2014: support for back-transforming effects to odds ratios (ORs) for binary outcomes. June 20, 2015: major update for forest plot to use program April 11, 2016: July 25, 2018: added support for binary data with all commonly used methods (Mantel–Haenszel, Peto, or inverse variance), with a new four-variable syntax. September 10, 2018: added back-transformation for meta-analyses of log-transformed effects.
Details on all these additions, along with the original capabilities and options for the command are described in detail below.
2.2 Description
The
The command requires the user to first specify either two or four variable names. When only two are specified,
When group-specific event and nonevent counts are specified,
For meta-analyses of time-to-event outcomes, the use of adjusted HRs is advised with the two-variable syntax. A reasonable alternative is the calculation of the log HR from a log
2.3 Syntax
Two syntaxes are possible. In the first, the user is expected to provide varname1 and varname2 only, which include information on study-effect sizes and study-effect variation (the default being standard error/deviation), respectively. If the
2.4 Options
Meta-analysis model
Binary outcome data with group-specific event and nonevent counts
General modeling options
Bootstrap DerSimonian–Laird options
Sensitivity analysis options
Graphs
Only one graph output is allowed in each execution.
Forest plot options
Various graph options can be used to specify overall graph options that would appear at the end of a
2.5 Stored results

3 Examples
We provide a few examples with the two-and four-variable syntaxes to give users a better understanding of the required data and the analysis options.
3.1 Meta-analysis based on effects and their standard errors
Let us assume an artificial dataset of 11 studies with information on a particular intervention, for example, a specific psychological intervention to reduce depression levels in populations diagnosed with severe depression in primary care. Let us also assume that various scales to quantify depression levels have been used across these studies and we have collected data on the mean difference in depression levels between the intervention and control group, six months following the intervention. In other words, for study i, we have the mean difference MD
i
= MNa6
Ai − MNa6
Bi
, where MNa6
Ai
and MNa6
Bi
are the mean depression levels in study i, six months postintervention, for the intervention (A) and control (B) groups, respectively. Assuming the studies are randomized controlled trials, as they often are, available preintervention data points are not used because the groups should be well balanced. If there is no balance in the outcome preintervention, as in many observational studies, then the last available preintervention time point needs to be accounted for. For example, the mean difference would be MD
i
= (MNa6
Ai − MNb0
Ai
) − (MNa6
Bi − MNb0
Bi
), where MNb0
Ai
and MNb0
Bi
are the mean depression levels in study i, just before the administering of the intervention, for the intervention (A) and control (B) groups, respectively. However, severely unbalanced group comparisons can be problematic for the validity of such analyses. Getting back to our example, we assume good preintervention group balance, but the outcome is measured across numerous scales (for example, BDI, CES-D, or PHQ-9). Therefore, we would need to calculate and meta-analyze the SMD for each study as

First, we meta-analyze studies using a random-effects model and bootstrap DL estimator, with 1,000 repetitions.
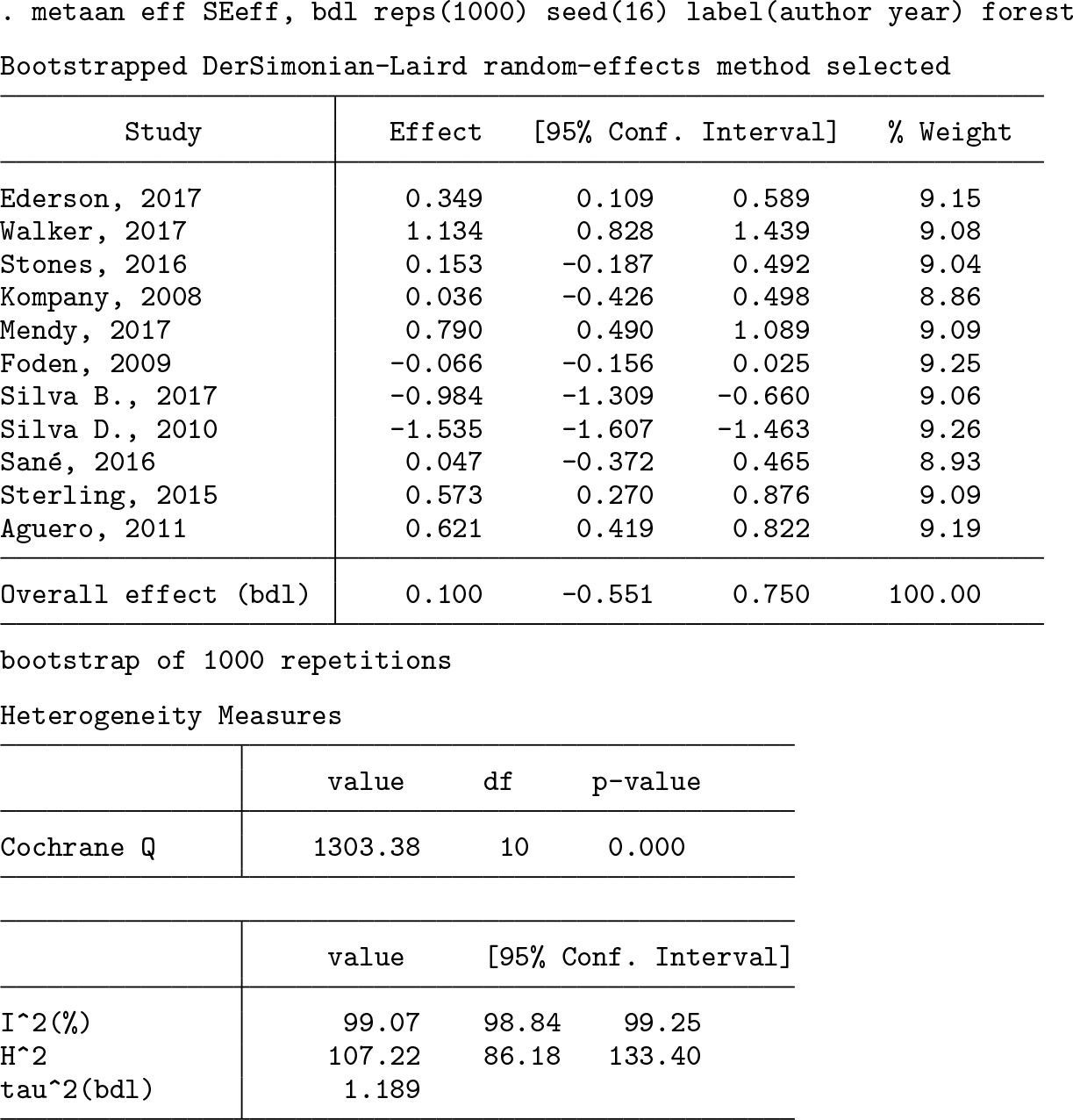
High levels of heterogeneity were observed and modeled. The overall effect is not statistically different from zero. Therefore, the conclusion would be that the overall effect of this hypothesized specific psychological intervention for severe depression is not statistically different from zero, although there was great variability in its effectiveness across included studies. Figure 1 shows the requested forest plot.

Bootstrap DL random-effects model
Next, we meta-analyze studies using the profile-likelihood random-effects model and request a likelihood plot for the overall effect estimate


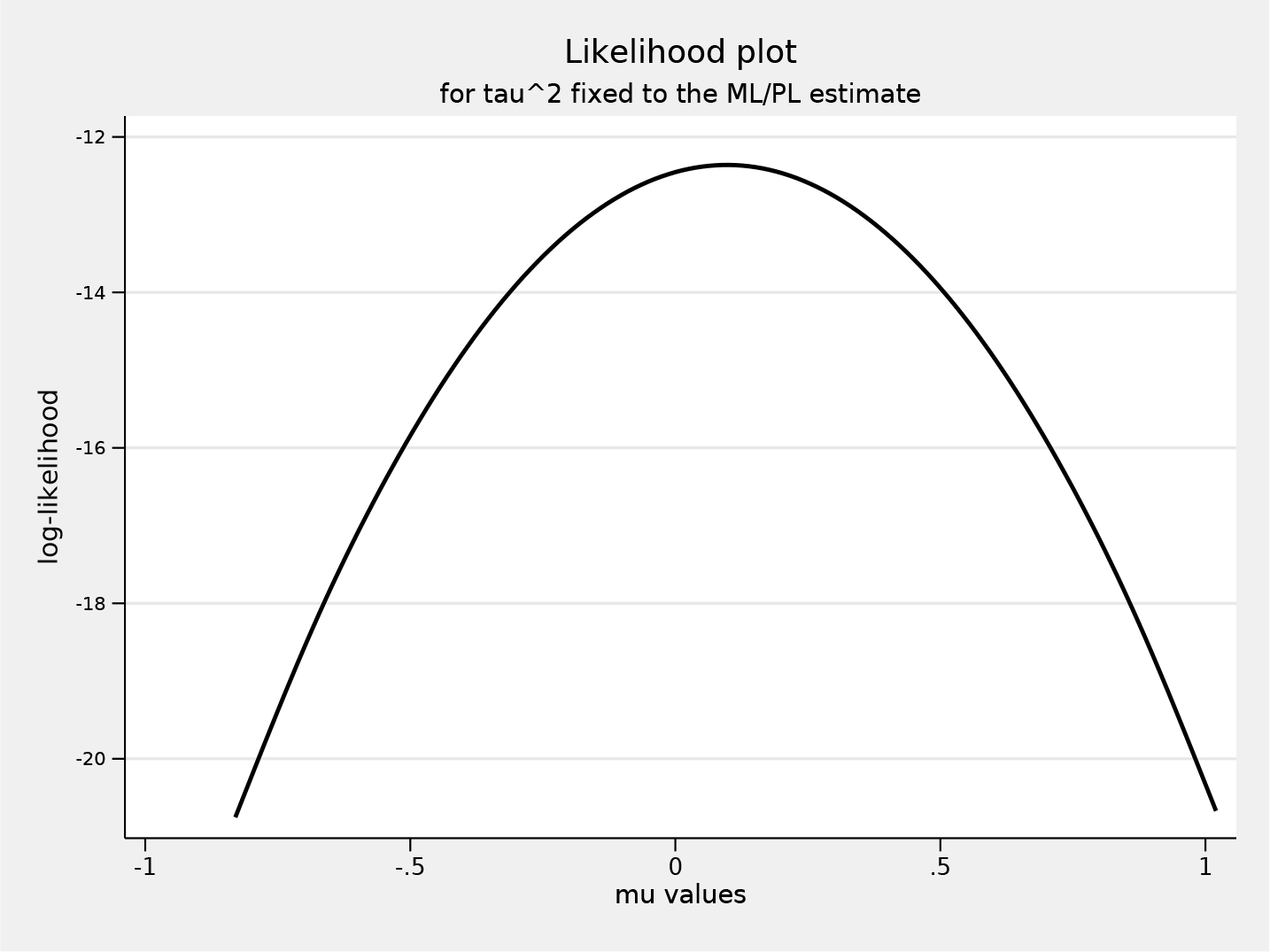
Likelihood plot for
The heterogeneity estimates are similar to what we observed with the bootstrap DL model, as is the overall effect. Figure 2 shows the requested likelihood plot for
3.2 Meta-analysis using event and nonevent counts
Let us assume that we are interested in treatment for heart attacks, particularly primary percutaneous coronary intervention. We hypothesize that the outcome of interest is five-year postoperative mortality and that there are no censored values (all patients are followed up for five years or until death). Our aim is to evaluate the role of a new blood-thinning medication, so we use a second dataset with events and nonevents for the binary outcome. Variable

First, we meta-analyze studies using a Peto OR fixed-effects model. Results are exponentiated, and a forest plot is requested.

We used the Peto fixed-effects approach (with Peto weighting), although heterogeneity was identified (under an inverse-variance approach). Assuming we are analyzing adverse events, the blood-thinning agent appears to have a modest prophylactic effect on five-year survival, which is also statistically significant. Figure 3 shows the requested forest plot.

Peto fixed-effects model
Next, we account for heterogeneity using the bootstrap DL random-effects model with inverse-variance weighting. In the first step, we use the Mantel–Haenszel risk-ratio approach to calculate the effect size and its variance for each study.


When we account for heterogeneity, the overall effect is closer to 1.0 and not statistically significant. This is not surprising considering random-effects models are generally more conservative from incorporating between-study variability. Finally, we wish to examine how results would change if this sample of studies underrepresented actual heterogeneity. For this, we use the sensitivity analysis model with a preset heterogeneity level of 70% (the upper limit of
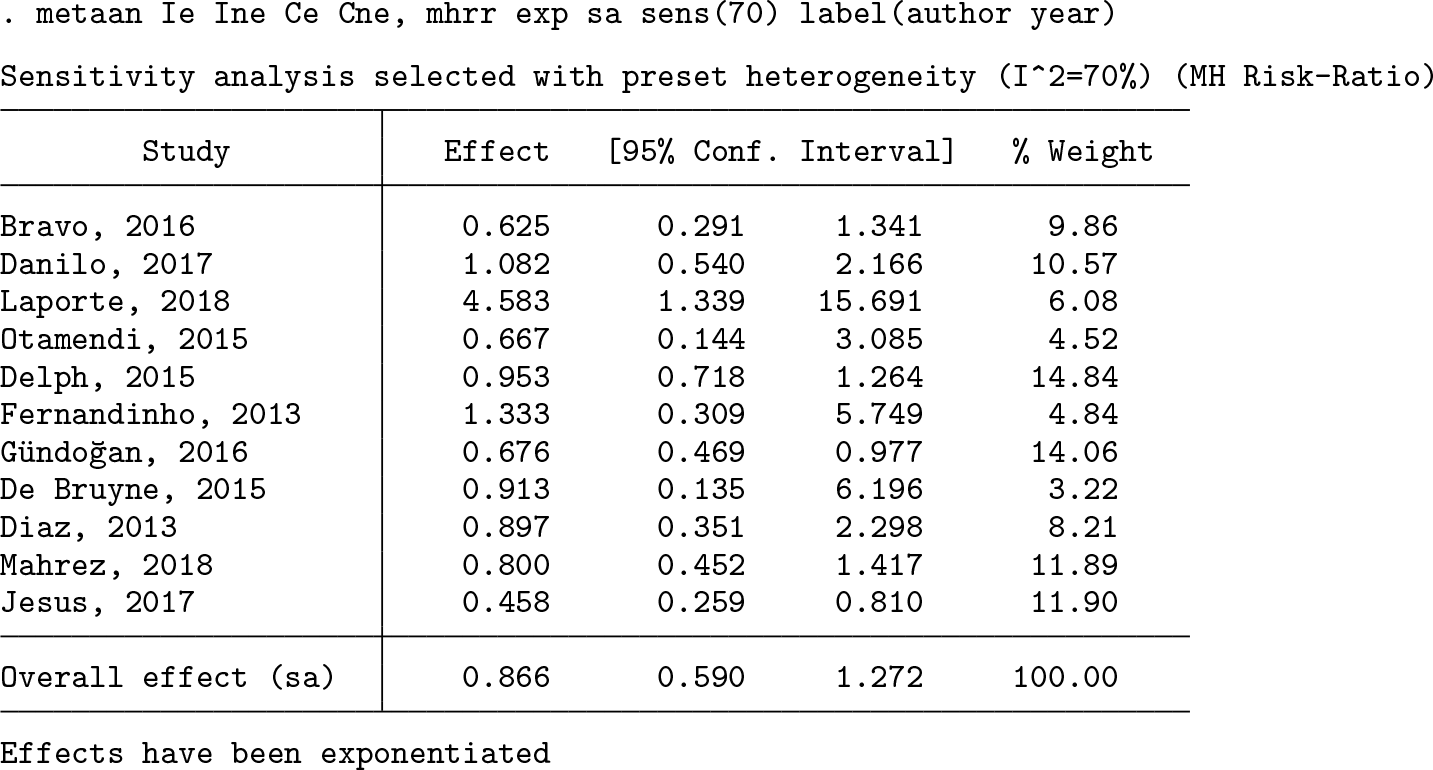

Under this higher heterogeneity assumption, the overall effect is even more slightly reduced, though the greater impact is a wider confidence interval. This approach can be useful in evaluating how sensitive analyses are to undetected or underestimated heterogeneity, something rather common in small meta-analyses in particular.
4 Discussion
The
Supplemental Material
Supplemental Material, st0201_1 - Pairwise meta-analysis of aggregate data using metaan in Stata
Supplemental Material, st0201_1 for Pairwise meta-analysis of aggregate data using metaan in Stata by Evangelos Kontopantelis and David Reeves in The Stata Journal
Footnotes
This study was partially funded by the National Institute of Health Research School for Primary Care Research through a personal fellowship for Evangelos Kontopantelis. The study represents independent research by the National Institute of Health Research. The views expressed in this publication are those of the authors.
Acknowledgments
We thank Mike Bradburn and Ross Harris, whose code helped shape the command.
Contributions
Evangelos Kontopantelis designed and developed the command and drafted the article. David Reeves critically commented on both the article and the functionality of the command.
Evangelos Kontopantelis and David Reeves declare no conflicts of interest.
5 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Alternatively, install from the Statistical Software Components archive, where updates are uploaded with a few days’ lag:
The data used in the examples are openly available from http://www.statanalysis. co.uk. From within Stata, to download the datasets in the current directory, type
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.