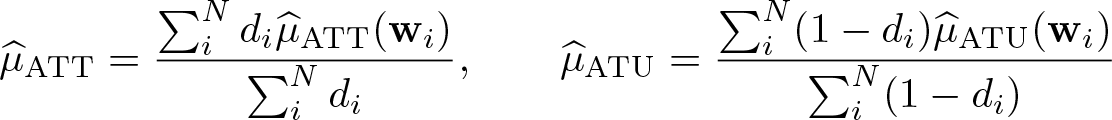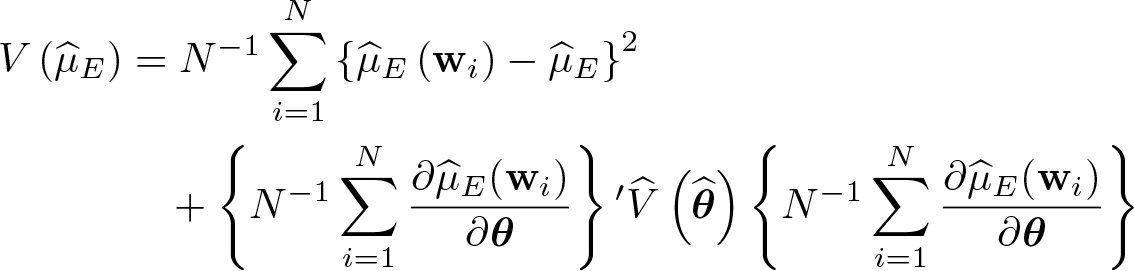In this article, I describe the escount command, which implements the estimation of an endogenous switching model with count-data outcomes, where a potential outcome differs across two alternate treatment statuses. escount allows for either a Poisson or a negative binomial regression model with lognormal latent heterogeneity. After estimating the parameters of the switching regression model, one can estimate various treatment effects with the command teescount. I also describe the command lncount, which fits the Poisson or negative binomial regression model with lognormal latent heterogeneity.
Count data, which are nonnegative and integer, are common in empirical studies of health economics and other applied microeconomics. Another common feature of empirical studies of applied microeconomics is a selection issue. A self-selection issue is particularly relevant in estimating effects of a certain treatment when an individual chooses to receive treatment depending on individual-specific heterogeneity that is unobservable by empirical researchers. Similarly, the problem of external selection may also arise when an external entity, such as a public agency, cherry-picks specific individuals as part of a treatment group. Such selection on unobservables complicates causal inference of treatment effects.
In this article, I present the command escount, which implements the maximum likelihood estimation (MLE) of the endogenous-switching regression model with countdata outcomes proposed by Terza (1998). In this model, potential outcomes, which are count data, differ across two alternate treatment statuses, and the treatment status is endogenously determined. Potential outcomes are not independent of treatment even after controlling for observable characteristics. To model the dependence between the potential outcome and the selection process, one relies on the assumption of lognormal latent heterogeneity. As Greene (2009) discusses, the lognormal latent heterogeneity provides a versatile specification. In addition to the command escount, I introduce the command lncount, which fits the regression model of count-data outcome with the lognormal latent heterogeneity. lncount is used to find initial values for the MLE of the switching regression model, but it can be a useful alternative specification of a Poisson regression (poisson) and a negative binomial (NB) regression (nbreg).
The virtue of a switching regression model is that it enables us to derive various treatment effects straightforwardly. Building on a switching regression model, Heckman, Tobias, and Vytlacil (2003) derive various treatment-effect parameters for continuous outcomes. Hasebe (2018) derives the count-data counterparts of these treatment-effect estimators. The treatment effects can be estimated with the command teescount after executing escount.
The structure of this article is as follows. The next section outlines the switching regression model with count-data outcomes and the MLE of the model. In section 3, I briefly discuss various treatment effects proposed in the literature and show the expressions of these treatment effects based on the parameters of the switching regression model. In section 4, I describe the commands escount, lncount, and teescount. In section 5, I discuss data applications. In section 6, I conclude the article.
2 Model
We consider a model of potential outcomes. There are two potential outcomes, y0i and y1i, which are count data, that is, nonnegative integers, for an individual i, i = 1,…, N. Depending on a treatment status, di ∊ {0, 1}, we observe one of the two outcomes but not both simultaneously for an individual i. That is, an observed outcome yi is yi = (1 − di)y0i + diy1i. The selection problem arises when y0i and y1i are not independent of di even after conditioning on observable characteristics xi.
We consider a model with parametric distributional assumptions originating in Terza (1998). We assume lognormal latent heterogeneity to model the dependence between yji and di for j = 0, 1. Assume that yji follows either a Poisson or an NB distribution conditional on xi and εji, which is latent heterogeneity. The selection mechanism depends on observable characteristics zi and an unobservable term νi: di = 1(zi′γ + νi > 0), where 1(·) is an indicator function. yj and d are dependent on each other through the correlation between εj and ν. We assume the joint normality of ν, ε0, and ε1,
where σj is a standard deviation of εj and ρj is the coefficient of correlation between ν and εj for j = 0, 1. The parameter ρ01 is the coefficient of correlation between ε0 and ε1, but it is not identified in the model. Let φ(·) and Φ(·) be the probability density function and cumulative distribution function of a standard normal distribution, respectively. Under the normality assumption, the joint probability fj(yi, di|xi,zi) can be written as follows,
where fj(yi|xi, εj) is
for a Poisson distribution and
for an NB distribution with the overdispersion parameter αj.
The command escount estimates the parameters θ = (β0′, β1′, γ′, σ0, σ1, ρ0, ρ1)′ using the MLE method. In the case of an NB distribution, θ additionally includes α0 and α1. The log-likelihood function has the following form:
The integration of fj(yi, di|xi,zi) is evaluated numerically via Gauss–Hermite quadrature. To obtain initial values for γ, we fit the probit model of the treatment status di. Initial values for βj and σj (and αj for the NB distribution) are obtained from the model without the selection process, of which the log-likelihood function is , using subsamples with di = 1 and di = 0 separately. The MLE routine for this model is named lncount.
This switching model is a generalization of the Poisson regression model with an endogenous treatment dummy variable that the command etpoisson estimates. While the endogenous dummy variable model restricts σ0 = σ1 and ρ0 = ρ1, the switching model allows for more flexible behaviors of unobservable heterogeneity. Because the endogenous treatment dummy variable is more parsimonious, it usually has more precise estimates than the switching model. However, if the restrictions on ρ and σ do not hold, the endogenous treatment dummy variable model is misspecified and suffers from biases. In such cases, the switching model is preferable. In practice, applied researchers do not usually know the behaviors of unobservable heterogeneity in advance. One of the advantages of the switching model is that because it nests the endogenous dummy variable model, we can test the restrictions easily with Wald and likelihood-ratio tests after fitting the switching model. In this sense, the command escount provides applied researchers with not only an additional model option but also a model-selection tool. Furthermore, escount allows for an NB specification, while etpoisson implements only a Poisson specification.
3 Treatment effects
Several treatment effects have been defined to allow for heterogeneous effects of the treatment among different populations in the literature. Estimating heterogeneity of treatment effects is useful and important to conduct policy analysis. See, for example, Heckman (2010). Heckman, Tobias, and Vytlacil (2003) derive the estimators of treatment effects for a continuous outcome based on a switching regression model under the assumption of joint normality. Building on the switching regression model with count-data outcomes, Hasebe (2018) derives the estimators of the average treatment effect (ATE), average treatment effect on the treated (ATT), average treatment effect on the untreated (ATU), local average treatment effect (LATE), and marginal treatment effect (MTE). This article shows the derived expressions. The following expressions of the treatment effects are the same regardless of whether the conditional distribution of yj is either Poisson or NB. After one executes the command escount, the command teescount estimates these treatment effects.
ATE measures the expected effect of the treatment for an individual randomly chosen from the entire population. Conditional on x, µATE(x) = E(y1−y0|x). In the lognormal latent heterogeneity model, the expectation of each potential outcome yj conditional on x can be expressed as . That is, . The estimated effect is obtained by replacing the population parameters with , , , and . The unconditional ATE is estimated by averaging the whole sample: .
The treatment effects may be different between those who select the treatment and those who do not. Let w be a union of x and z: w = x∪z. ATT is the average effect of the treatment for those who actually select the treatment: µATT(w) = E(y1− y0|x, d=1) = E(y1− y0|x, ν >−z′γ). In contrast, ATU measures the average effect for those who do not receive the treatment: µATU(w) = E(y1− y0|x, d = 0) = E(y1− y0|x, ν ≤ −z′γ). The expectation conditional on the treatment status is
The unconditional versions of ATT and ATU are estimated by averaging over relevant subsamples:
LATE is the average effect of the treatment for those who are induced to switch their treatment status in response to changes in an instrument variable. Suppose that a value of the kth variable of z, zk changes from the lower value zk,L to the upper value zk,U . Accordingly, the treatment status changes; d = 0 with zL′γ while d = 1 with zU ′γ. Then, LATE can be defined as µLATE(w, zk) = E(y1− y0|x, −zU ′γ ≤ ν ≤ −zL′γ). The relevant conditional expectation of yj is
Note that we cannot identify exactly which observations are induced to change the treatment status in response to the change in an instrument variable. Thus, it is standard to estimate the unconditional LATE as the average of the whole sample: . When there are multiple instrument variables, LATE can be defined for each instrument.
Finally, MTE measures the average effect of the treatment for those who have a particular value of ν. MTE at is . MTE evaluated at low values of measures the treatment effects for those less likely to receive the treatment, while MTE at high values of measures the treatment effects for those more likely to receive the treatment. The expected potential outcome conditional on is
Like ATE and LATE, the unconditional version of MTE is estimated by averaging the whole sample: .
MTE is a unifying parameter in policy evaluation. ATE, ATT, and ATU can be expressed as weighted averages of MTE (Heckman and Vytlacil 2005). ATE is a simple average of MTE over the entire range of ν. ATT puts more weight on MTE at larger values of ν, that is, those more likely to select into the treatment. In contrast, ATU more heavily weighs those less likely to receive the treatment. MTE can also be interpreted as the limiting case of LATE as . Thus, it measures the ATE for those who are indifferent between receiving treatment and not at a given value of ν. By estimating MTE over a range of ν, we can understand how treatment effects are heterogeneous, and we can also tell who is more likely to benefit from marginal policy expansion. For example, constant MTE over ν indicates homogeneous treatment effects across different populations. Treatment effects can be heterogeneous. For example, MTE may be large among those unlikely to receive treatment. In this case, a policy maker may design an intervention targeting such a population to make the intervention more effective. Furthermore, MTE can be used to construct not only conventional treatment effects such as ATE and ATT but also treatment effects of hypothetical policy changes with different weights from ATE and ATT. See, for example, Heckman and Vytlacil (2005, 2007) for further discussion.
Note that the treatment-effect estimators in this article heavily rely on the assumption of joint normality discussed in section 2. Such parametric assumptions are often considered as restrictive in the recent literature of program evaluation, and the literature has moved toward less stringent assumptions in modeling and estimating causal effects. See, for example, Imbens and Wooldridge (2009). Indeed, several semiparametric estimators for MTE have been proposed. The package mtefe by Andresen (2018) implements several estimation methods for MTE. However, these estimators are not developed specifically for count-data outcome. Our treatment-effect estimators can serve as a benchmark estimation result in empirical studies with count-data outcome, although it is necessary to keep rather stringent distributional assumptions in mind.
As for the derivation of the asymptotic variance of these treatment-effect estimators, note that the estimation of the treatment effect involves two steps sequentially. The first step estimates the parameters of the switching regression model. Then, in the second step, the treatment effects are estimated using these estimated parameters. The asymptotic variance of the conditional treatment effects can be obtained by applying the delta method, which accounts for the fact that the parameters of the switching model are fit. To consistently estimate the asymptotic variances of the unconditional treatment effects, we must additionally consider the sampling variability from the randomness of wi. Our derivation of the asymptotic variance is based on Newey and McFadden (1994). See also Terza (2016) for the correct asymptotic variance of sample means of nonlinear transformations such as our proposed treatment-effect estimators.
Assuming independence over observations, we estimate the asymptotic variance of the treatment-effect estimator by
where is the estimated asymptotic variance of for E = ATE, LATE, and MTE. The expressions for ATT and ATU are slightly different because we average over subsamples, but the essential structure is the same. The second term of this expression corresponds to the delta-method approach, and the first term reflects the variability arising from the randomness of wi. Furthermore, one can estimate a cluster–robust variance estimator. The first term of the expression above becomes , where G denotes the number of clusters and Ng is the number of observations with each cluster such that . is replaced with the cluster–robust variance of θ in the second term.
4 The commands
This section describes the commands escount and lncount to implement the MLE of the models with lognormal latent heterogeneity. These commands use the Stata command ml, and likelihood-evaluator programs are written in Mata. We also describe the command teescount, which estimates the treatment effects after the execution of escount.
aweights, fweights, iweights, and pweights can be used depending on the methods chosen; see [U] 11.1.6 weight.
Options
select(depvars=varlists, noconstant offset(varnameo)) specifies the variables and options for the selection equation. select() is required.
model(model) specifies the distribution for count-data outcomes. The default is model(poisson). The alternative specification is nb.
noconstant suppresses a constant term of the outcome equation.
exposure(varnamee) includes ln(varnamee) in the model with the coefficient constrained to 1.
offset(varnameo) includes varnameo in the model with the coefficient constrained to 1.
constraints(constraints); see [R] Estimation options.
intpoints(#) specifies the number of integration points to use for integration by quadrature. The default is intpoints(24); the maximum is intpoints(512).
vce(vcetype) specifies the type of standard error reported, which includes types that are robust to some kinds of misspecification (robust), that allow for intragroup correlation (clusterclustvar), and that are derived from asymptotic theory (oim, opg); see [R] vce_option.
maximize_options: difficult, technique(algorithm_spec), iterate(#), [no]log, trace, gradient, showstep, hessian, showtolerance, tolerance(#), ltolerance(#), nrtolerance(#), nonrtolerance, and from(init_specs); see [R] Maximize. These options are seldom used.
Stored results
escount stores the following in e():
Prediction
After an execution of escount, the predict command is available to compute several statistics with the following syntax:
psel, the default, calculates the probability of receiving the treatment status d = 1 for each observation: Φ(zi′γ).
xb0 calculates the linear prediction of the outcome variable of the treatment status d = 0 for each observation: xi′β0.
xb1 calculates the linear prediction of the outcome variable of the treatment status d = 1 for each observation: xi′β1.
xbsel calculates the linear prediction of the selection equation for each observation: zi′γ.
mu0 calculates the expected value of the potential-outcome variable of the treatment status d = 0 for each observation: .
mu1 calculates the expected value of the potential-outcome variable of the treatment status d = 1 for each observation: .
mu0d0 calculates the expected value of the potential-outcome variable of the treatment status d = 0 conditional on receiving the treatment status d = 0 for each observation: .
mu0d1 calculates the expected value of the potential-outcome variable of the treatment status d = 0 conditional on receiving the treatment status d = 1 for each observation: .
mu1d0 calculates the expected value of the potential-outcome variable of the treatment status d = 1 conditional on receiving the treatment status d = 0 for each observation: .
mu1d1 calculates the expected value of the potential-outcome variable of the treatment status d = 1 conditional on receiving the treatment status d = 1 for each observation: .
4.2 teescount
Syntax
The syntax for the command is as follows:
teescount [, ate att atu late(varname lower upper) mte(nu)]
This command estimates the treatment effects and their standard errors using the estimated parameters of the switching regression model with count-data outcomes. It can be executed only after the execution of escount.
Options
ate estimates ATE. This is the default.
att estimates ATT.
atu estimates ATU.
late(varname lower upper) estimates LATE when the value of varname (zk) changes from lower (zk,L) to upper (zk,U ). lower and upper should be numerical.
mte(nu) estimates MTE evaluated at nu (ν). nu should be numerical.
Stored results
teescount stores the following in r():
Matrices
The matrix r(table) contains the estimated treatment effect in the first column, its standard error in the second column, the z-value in the third column, and the p-value in the fourth column. When only one option is specified, this matrix is a row vector. When more than one option is specified, the rows of this matrix correspond to the treatment effects that are specified as options.
aweights, fweights, iweights, and pweights can be used depending on the methods chosen; see [U] 11.1.6 weight.
Options
model(model) specifies the distribution for count-data outcomes. The default is model(poisson). The alternative specification is nb.
noconstant suppresses a constant term of the outcome equation.
exposure(varnamee) includes ln(varnamee) in the model with the coefficient constrained to 1.
offset(varnameo) includes varnameo in the model with the coefficient constrained to 1.
constraints(constraints); see [R] Estimation options.
intpoints(#) specifies the number of integration points to use for integration by quadrature. The default is intpoints(24); the maximum is intpoints(512).
vce(vcetype) specifies the type of standard error reported, which includes types that are robust to some kinds of misspecification (robust), that allow for intragroup correlation (clusterclustvar), and that are derived from asymptotic theory (oim, opg); see [R] vce_option.
maximize_options: difficult, technique(algorithm_spec), iterate(#), nolog, trace, gradient, showstep, hessian, showtolerance, tolerance(#), ltolerance(#), nrtolerance(#), nonrtolerance, and from(init_specs); see [R] Maximize. These options are seldom used.
Stored results
lncount stores the following in e():
Prediction
After an execution of lncount, the predict command is available to compute several statistics with the following syntax:
predict [type]newvar[if][in][, n xb]
The options for predict are the following:
n computes the predicted number of events for each observation: exp(xi′β+σ2/2). This is the default.
xb computes the linear prediction of the dependent variable for each observation: xi′β.
4.4 Notes
In the MLE, σ and ρ are not directly estimated to guarantee that σ > 0 and −1 < ρ < 1. Instead, ancillary parameters ln σ and ρ∗ are estimated. These ancillary parameters are transformed as σj = exp(ln σj) and ρj = {exp(ρj∗) − exp(−ρj∗)}/{exp(ρj∗) + exp(−ρj∗)}. The estimates of these ancillary parameters are respectively reported as lnsigma and athrho, while the estimates of these transformed parameters are reported as sigma and rho. For the switching model, the estimates of the ancillary and transformed parameters are reported with 0 or 1 indicating the treatment status. Similarly, when model is nb, the ancillary parameter ln α is estimated and then transformed to α. The estimates of these parameters are reported as lnalpha and alpha, respectively.
5 Example
To illustrate the use of escount, we show some examples using a dataset from the Stata website. This is the same dataset used for the example of etpoisson and a simulated random sample of households. The outcome of interest is the number of trips (trips), and a possible endogenous treatment indicator is car ownership (owncar). There are some other controlling variables of household characteristics. realinc, which is the ratio of household income to the median income of the census tract, serves as an instrumental variable. See the example in [TE] etpoisson for the details.
First, we execute escount to fit the switching regression model with the Poisson specification. It is followed by the command that tests whether the self-selection matters, that is, tests the null hypothesis H0 : ρ0 = ρ1 = 0. It is equivalent to testing H0 : ρ0∗ = ρ1∗ = 0.1
This is the result of MLE of the switching regression model with count-data outcomes. Each of the coefficients of correlation between ν and εj for j = 0, 1 is statistically significant at any meaningful level. The result of the test command also shows that these parameters are jointly significant. These results indicate the presence of the self-selection problem. Households that tend to own a car are more likely to make a trip, even controlling for observable characteristics. Without considering the self-selection, the estimation of the treatment effects is biased.
Next, we estimate the treatment effects: ATE, ATT, and ATU. We also report the estimated LATE when the value of realinc changes from 1.0 to 1.1, which may not necessarily be an interesting quantity but is shown for illustration. Besides, we also show the estimated treatment effects ignoring the self-selection problem, that is, restricting ρ0 = ρ1 = 0.
The estimated treatment effects from the model without considering the self-selection problem are more than twice as large as those from the switching regression model. This result is consistent with the positive values of the estimated ρ0 and ρ1. Ignoring the self-selection problem results in the upward biases of the treatment effects. Note that when ρ0 = 0 and ρ1 = 0, the treatment effects are not heterogeneous so that ATE and LATE are the same. Although not reported here, MTE is also constant at the same value as ATE and LATE over the entire range of ν. The reason why ATT and ATU are different is that we average over different subsamples to obtain the unconditional effects.
When considering the self-selection issue, we find that ATE is marginally significant at the 5% level. Although ATU is highly significant, ATT is not significant even at the 10% level. The insignificance of ATT may be due to the efficiency loss from the estimation of the switching regression model. An endogenous dummy variable model may be parsimonious and lead to a more efficient estimator when the restrictions that σ0 = σ1, ρ0 = ρ1, and β0 = β1, except for constant terms being correct. As shown below, when we conduct the Wald test of the restrictions, we fail to reject the null hypothesis with the p-value of 0.3472.
Given this result, we next fit the model and the treatment effects under the restrictions. For comparison and as an example of lncount, we also fit the dummy variable model without considering the self-selection issue.
The estimation result of the restricted model, that is, the endogenous dummy variable model, is identical to the result from the built-in command etpoisson, which is not reported here. The coefficient on the endogenous dummy variable corresponds to the difference in the constant terms between the treatment statuses. The command lincom returns the estimated difference. This estimate is much lower than the estimated coefficient on owncar from lncount, which ignores the endogeneity of car ownership. The estimates of the treatment effects based on the endogenous dummy variable model are similar to those from the switching regression model, but with smaller standard errors.
Based on the endogenous dummy variable model, we estimate and plot MTEs over normalized values of ν with 95% confidence intervals. The normalized value of ν is Φ(ν), and thus it takes values between 0 and 1. It represents the propensity for treatment. MTE and its standard error are estimated at each point of the normalized value using a loop.
Figure 1 presents the estimated MTEs. The figure shows that MTE increases with higher propensity for treatment. The effect of car ownership on the number of trips is larger for a household that is more likely to own a car. The result, that ATT is larger than ATU, reflects this upward slope of MTE. At higher values of treatment propensity, where ATT puts more weight on MTE, the treatment effect is larger.
MTEs
6 Conclusion
In estimating the effects of treatment, endogeneity is a common problem that researchers face. Researchers in health economics and other applied microeconomics also come across count-data outcomes frequently. It is important to equip researchers with a statistical tool to address endogenous treatment with a count-data outcome. In this article, I introduced the command escount, which implements the MLE of the endogenously switching regression model with count-data outcomes, where a possible outcome differs between different treatment statuses and an individual selects into one of the statuses endogenously. Based on lognormal latent heterogeneity, the model allows for the dependence between the selection process and potential outcomes. After one estimates the parameters of the switching regression model, various treatment effects can be estimated with the command teescount.
Supplemental Material
Supplemental Material, st0612 - Endogenous switching regression model and treatment effects of count-data outcome
Supplemental Material, st0612 for Endogenous switching regression model and treatment effects of count-data outcome by Takuya Hasebe in The Stata Journal
Footnotes
7 Acknowledgments
I thank an anonymous referee for helpful suggestions. This study was partially funded by Grant-in-Aid for Young Scientists from the Japan Society for the Promotion of Science: JSPS KAKENHI grant number JP18K12801.
8 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
HasebeT.2018. Treatment effect estimators for count data models. Health Economics27: 1868–1873. https://doi.org/10.1002/hec.3790.
4.
HeckmanJ. J.2010. Building bridges between structural and program evaluation approaches to evaluating policy. Journal of Economic Literature48: 356–398. https://doi.org/10.1257/jel.48.2.356.
5.
HeckmanJ. J.TobiasJ. L.VytlacilE.2003. Simple estimators for treatment parameters in a latent-variable framework. Review of Economics and Statistics85: 748–755. https://doi.org/10.1162/003465303322369867.
HeckmanJ. J.VytlacilE. J.2007. Econometric evaluation of social programs, part II: Using the marginal treatment effect to organize alternative econometric estimators to evaluate social programs, and to forecast their effects in new environments. In Handbook of Econometrics, vol. 6B, ed. HeckmanJ. J.LeamerE. E., 4875–5143. Amsterdam: Elsevier. https://doi.org/10.1016/S1573-4412(07)06071-0.
8.
ImbensG. W.WooldridgeJ. M.2009. Recent developments in the econometrics of program evaluation. Journal of Economic Literature47: 5–86. https://doi.org/10.1257/jel.47.1.5.
9.
NeweyW. K.McFaddenD.1994. Large sample estimation and hypothesis testing. In Handbook of Econometrics, vol. 4, ed. EngleR. F.McFaddenD. L., 2111–2245. Amsterdam: Elsevier. https://doi.org/10.1016/S1573-4412(05)80005-4.
10.
TerzaJ. V.1998. Estimating count data models with endogenous switching: Sample selection and endogenous treatment effects. Journal of Econometrics84: 129–154. y.
11.
TerzaJ. V.2016. Inference using sample means of parametric nonlinear data transformations. Health Services Research51: 1109–1113. https://doi.org/10.1111/1475-6773.12494.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.