
Abstract
To compare distributions of ordinal data such as individuals’ responses on Likert-type scale variables summarizing subjective well-being, we should not apply the toolbox of methods developed for cardinal variables such as income. Instead, we should use an analogous toolbox that accounts for the ordinal nature of the responses. In this article, I review these methods and introduce a new command,
Keywords
1 Introduction
This article is about how to compare distributions of personal well-being where wellbeing is measured using an ordinal scale, and it introduces a new command,
Leading examples of personal well-being indicators are self-assessed (“subjective”) life satisfaction or health status for which individuals provide responses on a Likert-type scale. For instance, regarding life satisfaction, respondents may be presented with a linear integer scale running from 0 to 10 (11 levels) and asked to respond to the question “Overall, how satisfied are you with your life nowadays where 0 is ‘not at all satisfied’ and 10 is ‘completely satisfied’?” (Data based on this scale are used in section 4.) Other life satisfaction scales use 5, 7, or 10 levels. Some subjective well-being (SWB) scales employ a mixture of negative and nonnegative integers to label the levels. For example, people are asked to rate how satisfied they are with their life, choosing between “completely dissatisfied” (scaled as −3), “mostly dissatisfied” (−2), “somewhat dissatisfied” (−1), “neither satisfied nor dissatisfied” (0), “somewhat satisfied” (1), “mostly satisfied” (2), and “completely satisfied” (3).
SWB measures are increasingly being used in tandem with the monetary measures of personal economic well-being such as income or wealth that national and international statistical agencies and most researchers have conventionally focused on. A catalyst for the new emphasis was the “Report by the Commission on the Measurement of Economic Performance and Social Progress” (Stiglitz, Sen, and Fitoussi 2009), which set out a comprehensive agenda for going “Beyond GDP”. The report’s Quality of Life sections emphasize that “well-being is multidimensional” (2009, 14) and that “objective and subjective dimensions of well-being are both important” (2009, 16). The Organisation for Economic Co-operation and Development (OECD) has played an important role in implementing the report’s recommendations in this area, launching its Better Life Initiative (in 2011), regularly reporting on well-being outcomes (How’s Life; see, for example, OECD [2020]), and developing the Better Life Index and multiple online resources (see https://www.oecd.org/statistics/better-life-initiative.htm). In parallel, the national statistical agencies of OECD member countries have introduced initiatives to address the Beyond GDP agenda, including a greater emphasis on collection of and reporting on SWB data.
Income and wealth are cardinal variables, and there are well-established methods for comparing distributions of them in terms of levels and inequality. There are also many community-contributed commands for undertaking distributional comparisons of cardinal variables, including my
In contrast, SWB measures are ordinal in nature, which raises the question of how to undertake distributional comparisons in this situation. How do we assess whether average well-being or well-being inequality has increased over time or differs between countries or social groups? A growing literature (cited below) has shown on the one hand that it is inappropriate to apply comparison methods developed for cardinal well-being measures to ordinal SWB measures, although many researchers continue to do this—the World Happiness Report (Helliwell, Huang, and Wang 2019) is a leading example. However, on the other hand, there is now a toolbox of methods for application to ordinal data that is analogous to the toolbox long applied to distributions of cardinal variables such as income. See Jenkins (Forthcoming) for development of this argument and illustrations.
2 Comparisons of distributions of ordinal data
This section provides a brief overview of methods used for undertaking comparisons of distributions of ordinal data and discusses
Let us suppose that we have individual-level SWB data held in a variable called
A commonly used measure of inequality of such ordinal data, especially life satisfaction and happiness data, is the standard deviation. Use of this measure is inappropriate because it assumes that
Economists specializing in inequality measurement have long been critical of the application to ordinal data of the standard deviation and other inequality indices typically applied to variables measured on a ratio scale. These indices use the mean as the reference point for assessing spread, but with ordinal data, the value of the mean is contingent on the scale used. Orderings of distributions according to their means or standard deviations are not robust to changes in the scale used.
Critiques by economists include the papers by Allison and Foster (2004), Cowell and Flachaire (2017), and Dutta and Foster (2013). These authors and others propose measures that respect the ordinal nature of the data. In one tradition, indices characterize greater inequality as greater spread about the median. The other tradition characterizes greater inequality as greater spread away from a maximum value.
2.1 Polarization indices
The Allison–Foster index is the difference between the mean score for respondents with scores above the median minus the mean score for respondents with scores below the median. This index was first proposed by Allison and Foster (2004). Dutta and Foster (2013) provide more extensive discussion of it, and the formulas used by
The two-parameter indices proposed by Abul Naga and Yalcin (2008), ANY(a, b), with a, b ≥ 1, are a form of weighted difference between the cumulative percentages of individuals in the lower half of the distribution and the cumulative percentages in the upper half of the distribution. The parameters tune the weights given to the two halves. ANY(1, 1) weights the two halves equally. Broadly speaking, when b > a, ANY(a, b) gives greater weight to the bottom half of the distribution; when a > b, it gives greater weight to the top half of the distribution. According to Abul Naga and Yalcin (2008, 1621), “For a given value of β,…, as α → ∞, the inequality index abstracts from the dispersion below the median.” (Their α and β correspond to my a and b.) On the other hand, when b > a, ANY(a, b) gives greater weight to the bottom half of the distribution. For a given value of a, choosing larger values of b places less weight on the distribution in categories above the median. In the limiting case when b → ∞, only below-median categories are relevant. Thus, for example, the indices ANY(1, 1), ANY(1, 2), and ANY(1, 4) give increasingly greater weight to the lower half of the distribution when assessing overall polarization.
Apouey’s (2007) P 2(e) indices each aggregate the “distances” between Fk
and 0.5 (the value of Fk
at the median) across the levels of
The average jump index is the average across respondents of the absolute difference between each observed value of
2.2 Inequality indices
Cowell and Flachaire (2017) build inequality measures from axiomatic first principles, providing two families of one-parameter indices based on downward-looking and upwardlooking measures of individual “status”, respectively.
Members of the two Cowell–Flachaire inequality index families I(α) are distinguished by parameter α, which encapsulates the sensitivity of overall inequality to the dispersion of individual status in different ranges of the status distribution, with 0 ≤ α < 1. The smaller that α is, the more sensitive is the overall index to differences in status at the bottom of the status distribution rather than at the top. If the distribution of responses on
Jenkins’s (2019) Jd index is defined for Cowell–Flachaire’s peer-inclusive downwardlooking status measure, and his Ju index is defined for their peer-inclusive upwardlooking status measure. Each index is equal to the area between the generalized Lorenz (GL) curve for the relevant status distribution and the GL curve for the distribution with no status inequality [in which case the GL curve is a straight line between the origin and point (1, 1)], divided by the total area beneath the perfect equality curve (= 0.5). Equivalently, each index is equal to one minus twice the area beneath the GL curve for status. The GL curve for status, GL(p), plots cumulative status per capita against cumulative population share, 0 ≤ p ≤ 1, of individuals ranked in ascending order of status. GL(0) = 0 and GL(1) is the arithmetic mean of status. See Jenkins (2019) for details.
2.3 Index properties
All the polarization and inequality indices calculated by
Cowell–Flachaire I(α) and J indices need not reach a maximum value with this distribution of responses: this is because the indices summarize inequality as spread rather than as polarization. For example, for any given K, I(α) and J indices record greater inequality for a uniform distribution than for a totally polarized distribution (Jenkins 2019).
I(α) and J indices are invariant to order-preserving transformations of the ordinal scale variable, that is, scale independent. The Allison–Foster index is not scale independent, and hence, Dutta and Foster (2013), in their empirical application, provide estimates based on linear, convex, and concave scales. Abul Naga–Yalcin and Apouey indices are scale independent (but also see the remarks in section 2.5).
2.4 Dominance checks for unanimous orderings by classes of indices
Allison and Foster (2004) provide results for “F-dominance” and “S-dominance”. The former refers to comparisons of CDFs and rankings by average well-being levels (first-order dominance): if the CDF for distribution A lies everywhere on or above the CDF below that for distribution B, then A has higher average well-being than B, regardless of scale. S-dominance (spread dominance) refers to comparisons of S-curves, which are derived from CDFs, so the criterion can also be expressed in terms of these. That is, if A and B have the same median, and the CDF for A lies above that for B at scale values below the median but above that for B at scale values at the median and above, all polarization indices respecting the property that greater spread about the median corresponds to greater polarization will show A as having greater polarization than B. S-dominance can arise only if the pair of distributions have a common median and if there is no F-dominance.
Jenkins (2019) shows that, for each of the two Cowell–Flachaire definitions of status, if the GL curve for status distribution A lies nowhere above the GL curve for status distribution B, all Cowell–Flachaire I(α) indices and the J index will record A as having more inequality than B. These GL curve comparisons can be applied if the distributions have different medians.
Gravel, Magdalou, and Moyes (Forthcoming) do not refer to any existing indices when discussing their dual dominance criteria. The relationships between the dual dominance and GL dominance criteria are a topic of current research.
2.5 Some computational and conceptual issues
For correct calculation of the Abul Naga–Yalcin, average jump, Apouey, and Jenkins indices,
Apouey P2(e) indices refer to the case in which the ordered-response categories are labeled with positive integers (1 for the lowest level, 2 for the second-lowest level, etc.), which is a linear integer scale. For correct calculation of these indices, it is the user’s responsibility to check that the scale underlying
The precise definition of the median is fundamental to the estimation of polarization indices. I use Stata’s definition of the median, as set out in Methods and formula of [R]
There are other possible definitions of the median. For example, Abul Naga and Yalcin’s definition is that level “m is the median…if Pm− 1 ≤ 0.5 and Pm ≥ 0.5” (2008, 1616), where Pk is the fraction of individuals reporting level k or less, that is, what I have referred to as Fk . The definition means that the median is undefined if the fraction reporting the lowest level k = 1 is greater than one half (P 1 > 0.5), though, of course, this case is likely to be rare in practice. Cowell and Flachaire (2017, 300) discuss other potential issues and refer to them when motivating their nonmedian-based approach.
Although use of Stata’s definition of the median almost invariably works well in real-world situations, there is one tricky special case to deal with—the situation in which Stata reports a noninteger median (having taken the average value of the scale in two adjacent categories—see the Stata Base Reference Manual again). This is most likely to occur if there are scale levels in the middle of the range that do not receive any responses. Using a noninteger median “as is” leads to an error when calculating ANY indices using Abul Naga and Yalcin’s (2008) formulas. Thus, the code for
Bootstrapped standard errors for the indices can be derived using
Finally, note that the indices and the dominance results cited earlier refer to levels and dispersion of a categorical well-being variable with an arbitrary scale. They do not refer to levels and dispersion of some underlying unobserved SWB variable. This is an important distinction because it is often assumed that discrete categorical responses on a Likert-type scale are manifestations of a latent continuous variable. For example, Delhey and Kohler’s (2011) adjustment to the standard deviation measure to account for the bounded nature of a Likert-type scale, implemented in
3 The ineqord command
3.1 Syntax
This section describes the syntax of the
ineqord varname [if] [in] [weight] [,
3.2 Options
3.3 Stored results

4 Examples
This section illustrates
4.1 Life satisfaction data from the UK Annual Population Survey (APS)
Most of my examples are based on data about life satisfaction drawn from the Annual Population Survey (APS) Three-Year Pooled Dataset January 2015–December 2017 (Office for National Statistics, Social Survey Division 2018), a nationally representative survey of UK adults. The data and documentation are downloadable from the UK Data Service by researchers who register. For brevity, I refer to the data as “the APS”. Data drawn from the APS are used by the UK’s Office for National Statistics to provide annual reports on personal well-being; see, for example, Office for National Statistics (2019).
The dataset contains 530,300 (unweighted) observations of which 275,336 provide a nonmissing response to the life-satisfaction question set out in section 1. Responses are held in the variable named

Only around 12% of respondents report a value of 5 or lower on the 0 to 10 scale. Almost 15% report that they are completely satisfied with their life (scale point 10), with the modal value equal to 8.
To proceed further, we have to address the fact that the linear integer scale runs from 0 to 10. It does not start at 1. If

Applying strategy 2, we derive the following estimates for the UK adult population. It is easily verified that the code

The first components of the output provide descriptive statistics. For example, we see that the median response is 8 on the 0–10 scale. The average jump index estimate is 0.24514. Because we have a linear integer scale, the average number of category “jumps” required to change from the observed level to the median level (normalized by the total number of levels minus one = 10) is 0.24514 and is also equal to the estimates of ANY(1, 1) and P2(1) in this case. The Allison–Foster index value, 2.45139, is 10 times the average jump index.
The earlier tabulation of
Let us therefore proceed to some distributional comparisons, considering how life satisfaction distributions differ between UK adults according to their marital status. I create a new variable,

A first look at the distributions of life satisfaction broken down by marital status indicates that married individuals are more satisfied than single, never married (SNM) or separated, divorced, or widowed (SDW) individuals. (In what follows, I ignore the “other” group given their small size.) For convenience, I use the rescaled variable

4.2 Dominance checks
I begin by reporting dominance checks rather than indices, for two reasons. First, from a robustness point of view, it is useful to know whether a pair of distributions can be unanimously ranked by all indices of a given family sharing key common characteristics. Even if you and I disagree about which is the best index within the family but there is dominance, you and I will agree about how to rank a pair of distributions—though of course we may disagree about the magnitudes of differences. Second, because dominance checks are usually implemented using graphs, using them is also a way of “showing the data”.
All the raw materials for the various dominance checks can be created by

A listing of the values of new variables for married individuals is shown below. Going from left to right, we see there are scale labels followed by the estimates of the density function, the CDF (with estimates corresponding to those shown by the earlier
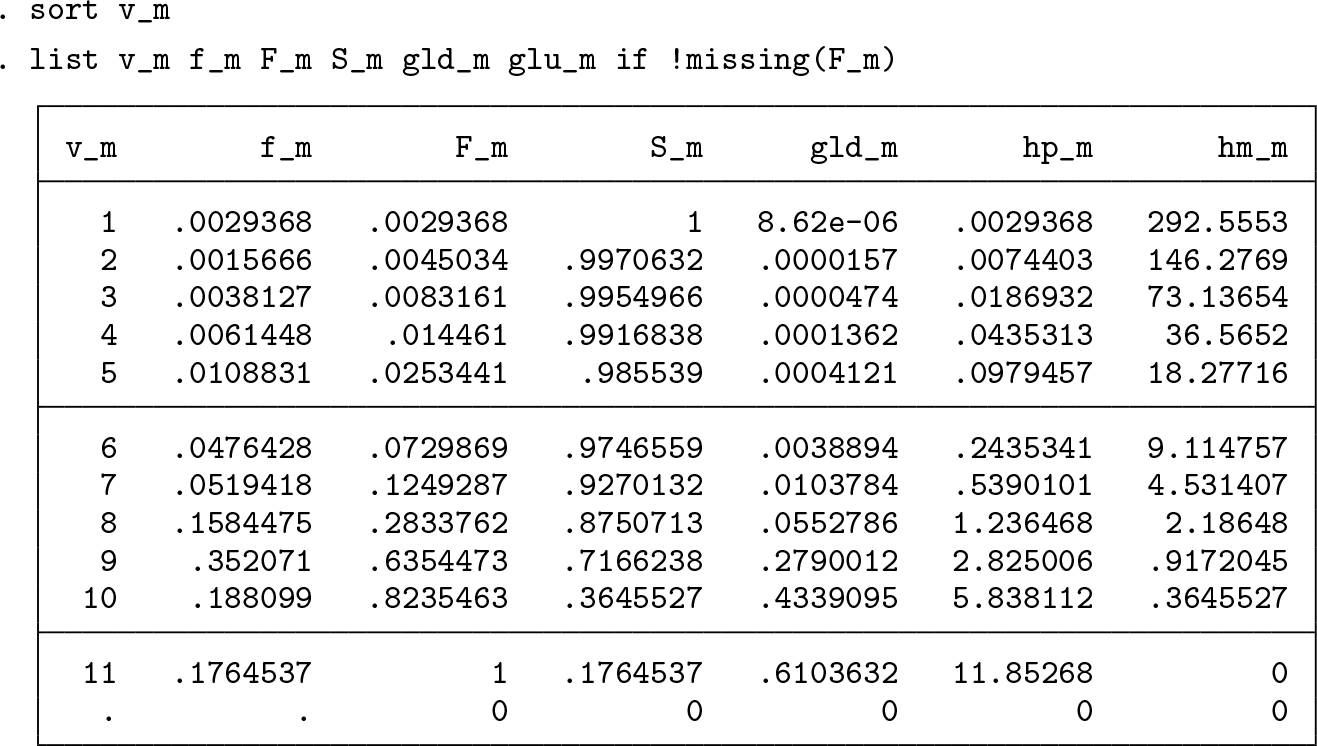
Figure 1 shows the CDFs for the three marital status groups. The code used to produce the graph follows below. (Stata 14 users should omit the “%55”, which refers to a transparency option introduced in Stata 15.)


Cumulative distribution functions (CDFs) for life satisfaction, by marital status group
We can see immediately that 9 is the median value of
CDF for the SDW group is further from the median than the CDF for the SNM group, and the reverse is the case above the median. Thus, there is greater polarization in the distribution of life satisfaction among the SDW group than among the SNM group according to all standard polarization indices—including all members of the ANY(a, b) and P2(e) families of indices.
To check for unanimous rankings by Cowell–Flachaire and J indices, I focus on the peer-inclusive downward-looking definition of status for brevity. Figure 2 shows the results of the three pairwise comparisons between groups. Below, I show the code used for the married and SDW groups’ comparison. Analogous code for the other two pairwise comparisons followed by
Generalized Lorenz curve comparisons for life satisfaction, by marital status group
All three pairwise comparisons reveal dominance. The clearest result, in the sense that the gap between the GL curves for status is greatest, is in the top-right picture: life satisfaction is more unequal for the SDW group than the married group according to all Cowell–Flachaire indices and the J index. The other two charts show that inequality is greater among the SNM group than the married group and among the SDW group compared with the SNM group. Thus, there is an unambiguous ranking from highest to lowest inequality according to all Cowell–Flachaire indices and J, with the SNM group the most unequal, the married group the least unequal, and the SDW group in between.
Figure 3 summarizes checks of Gravel, Magdalou, and Moyes’s (Forthcoming) dual dominance criteria based on H
+ and H−
curve comparisons. The code used for the comparison of H
+ curves for married and single, never-married groups is shown below. Analogous code for the other two pairwise H
+ comparisons and for the three H−
comparisons followed by

H + and H− curve comparisons for life satisfaction, by marital status group
Recall that for Gravel, Magdalou, and Moyes’s dual dominance criteria to be satisfied, we need to find the H + and H− curves for one group nowhere above the corresponding curves for another group. For these data, the orderings of the groups according to the H + criterion are the same as the orderings by the F-dominance criterion (because F-dominance implies H + dominance). See the charts on the left-hand side of figure 3. However, there is dual dominance in only one case. The distribution of life satisfaction among the single, never-married group is more equal than the distribution among the separated, divorced, widowed group: the H + and H− curves for the former group are nowhere below those for the latter group. This ordering of the two groups, based on Hammond transfer principles, is the same as their ordering according to the S-dominance criterion (referring to greater polarization about the median) and is also the same as their GL dominance ordering (see figure 2).
4.3 Indices of polarization and inequality
Estimates of specific polarization and inequality indices are consistent with this dominance result and also the S-dominance result cited earlier (the SDW group is more polarized about the median than the SNM group). Specific indices are also useful for deriving inequality and polarization orderings when there is no dominance result and, of course, can be used to place a number on the magnitude of differences. To illustrate these points, I present estimates of a selection of inequality indices [I(α) for α = 0, 0.25, 0.5, 0.75, 0.9; and J; all using a peer-inclusive downward-looking status definition] and three polarization indices, ANY(1, 1), the top-sensitive ANY(4, 1), and the bottom-sensitive ANY(1, 4). In addition, I show how one can derive standard errors for the indices using Saigo, Shao, and Sitter’s (2001) repeated half-sample bootstrap using Van Kerm’s (2013)
The code below shows the derivations for the married group. First, I drop observations with missing values. Second, I use

I repeated this code for the SNM and SDW groups as well, specifying different arguments for

All indices are very precisely estimated, and all between-group differences are statistically significantly different from 0.
The rankings of marital status subgroups in figure 3 are of course consistent with the dominance results discussed earlier. However, there was no S-dominance result for the polarization comparisons between the married group and each of the other two groups, so index values are valuable for providing a polarization ranking. Interestingly, figure 4 shows that this depends on the index chosen. For ANY(1, 1) and ANY(1, 4), the ranking is the same as for the inequality indices. However, for top-sensitive index, ANY(4, 1), the married group shows the greatest polarization rather than the lowest. What is driving this result is that the married group has relatively large fractions of responses in the top-two life-satisfaction scale categories in contrast with the other two groups (see the tabulation of life satisfaction by marital status shown earlier).
Indices also tell us about the magnitudes of differences across groups. As it happens, the I(α) and J indices provide similar estimates. For example, all of them indicate that the difference in life satisfaction inequality between the most unequal group (SDW) and the least unequal group (married) is around 7%. More marked differences are apparent for the ANY polarization indices. For example, for ANY(1, 1), which is also the average jump index, the difference in polarization between the SDW and married groups is around 39%, whereas for ANY(1, 4), it is around 17%. For ANY(4, 1), it is −20%.

Indices of life-satisfaction inequality and polarization, by marital status group
4.4 Using grouped data with ineqord
For example, Abul Naga and Yalcin (2008, table 2) report the empirical CDF for self-reported health status recorded on a 5-level scale (“very bad”, “bad”, “so so”, “good”, “very good”) for each of seven statistical areas in Switzerland. The empirical CDF for the Central region can be reproduced using the following code to characterize the distribution of responses:
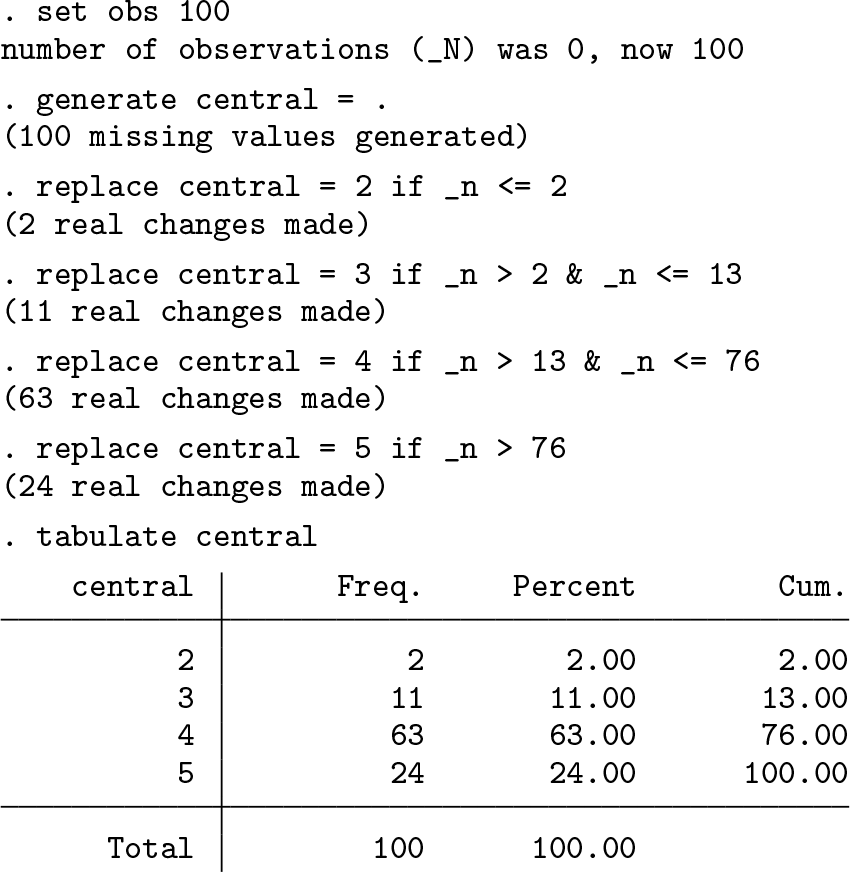
No individuals in the Central region reported “very bad” health status and so simply typing
Using the same grouped-data approach, I have verified that
5 Summary and conclusions
The personal well-being of individuals is increasingly being measured using questions requiring responses on a Likert-type scale. Life satisfaction and self-assessed health status are leading examples of these measures, and they yield distributions of ordinal data. To compare such distributions across groups of individuals or over time, we should not apply the toolbox of methods developed for cardinal variables such as income. These methods rely on the mean as a reference point, but changing the scale in the ordinal data case can change the orderings of distributions according to their means or other measures based on the mean, including conventional inequality indices. Thus, we should use an analogous toolbox that accounts for the ordinal nature of the responses. This article reviewed these methods and introduced a new command,
Footnotes
6 Acknowledgments
I developed
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type