
Abstract

A rank-deficient design matrix of explanatory variables
There are two ways to enable the use of
The alternative approach is to expand
Much of the relevant econometric literature focuses on the identification of rankdeficient matrices of mutually exclusive binary variables and the interpretation of their intercepts, a problem so ubiquitous and well understood that it has earned its colloquial moniker of “dummy variable trap”. The interpretation of constrained intercepts is indeed elementary because it is a simple matter of weighted constants.
However, as I discuss in Christodoulou (2018), a more rigorous discussion on the effect on slope coefficients of a rank-deficient
Consider the question of how capital investment in operating assets affects sales revenue in fixed asset-intensive firms. Companies with high stakes in tangible assets rely on capital investment to boost revenue, but the more the assets are used in operations, the more their value is depleted and needs to be replenished. The economic transactions describing this relation are captured by the accounting identity
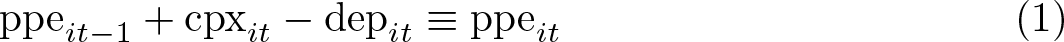
or equivalently stated as
The following simple simulation generates data that describe this scenario:

The parameters of the random normal distributions are selected so that they appear somewhat realistic, considering that these are a result of log-transformations from originally log-normally distributed variables.
Let’s say that someone is interested in learning how much revenue would change if a company decides to spend more in new capital expenditure and, at the same time, how depletion would affect sales, conditional of course on the capital investment stock. Then, the variation of sales revenue could be written as a function of the structural relation of (1) plus a random-error term:
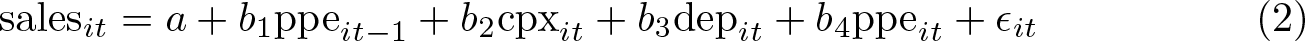
Given the rank deficiency in
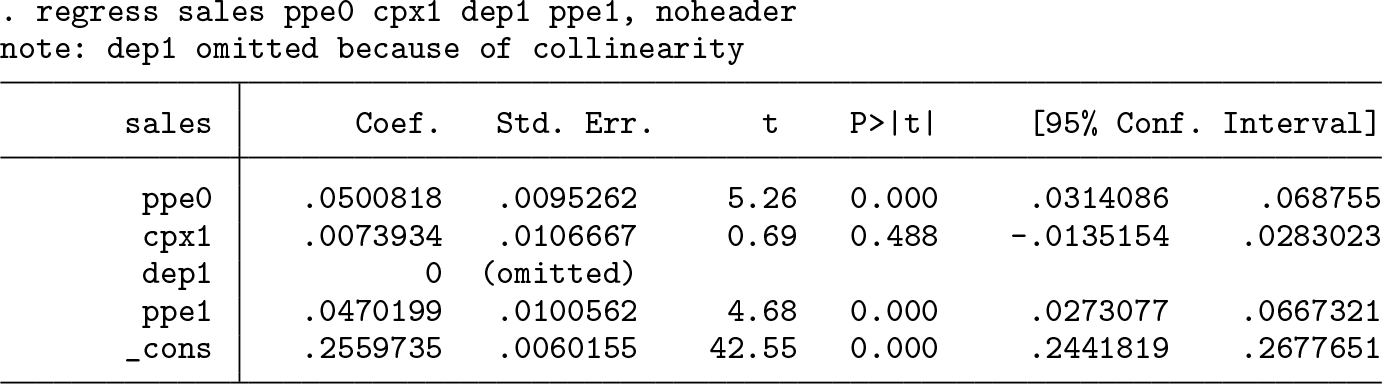
Stata decided to drop the variable
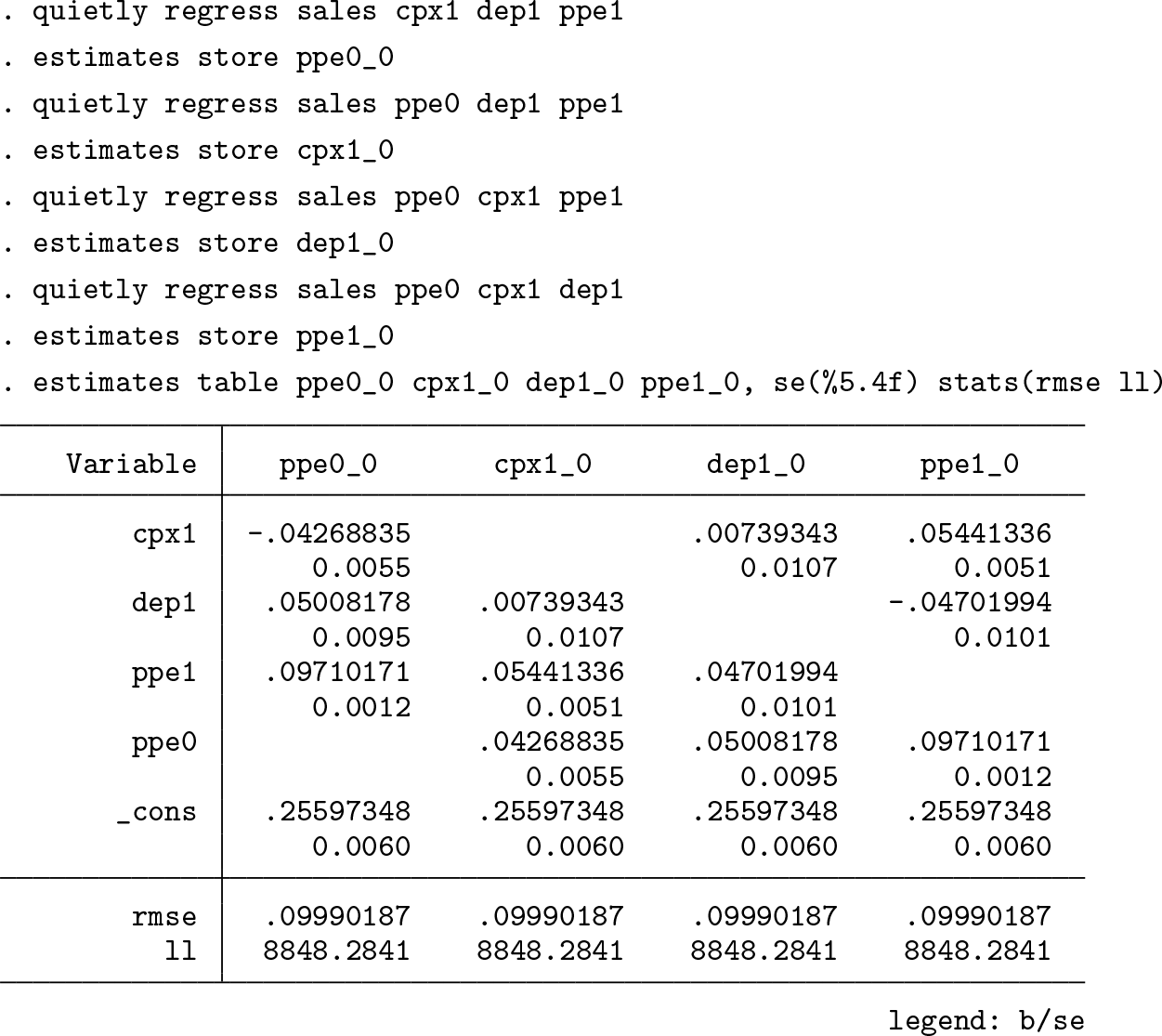
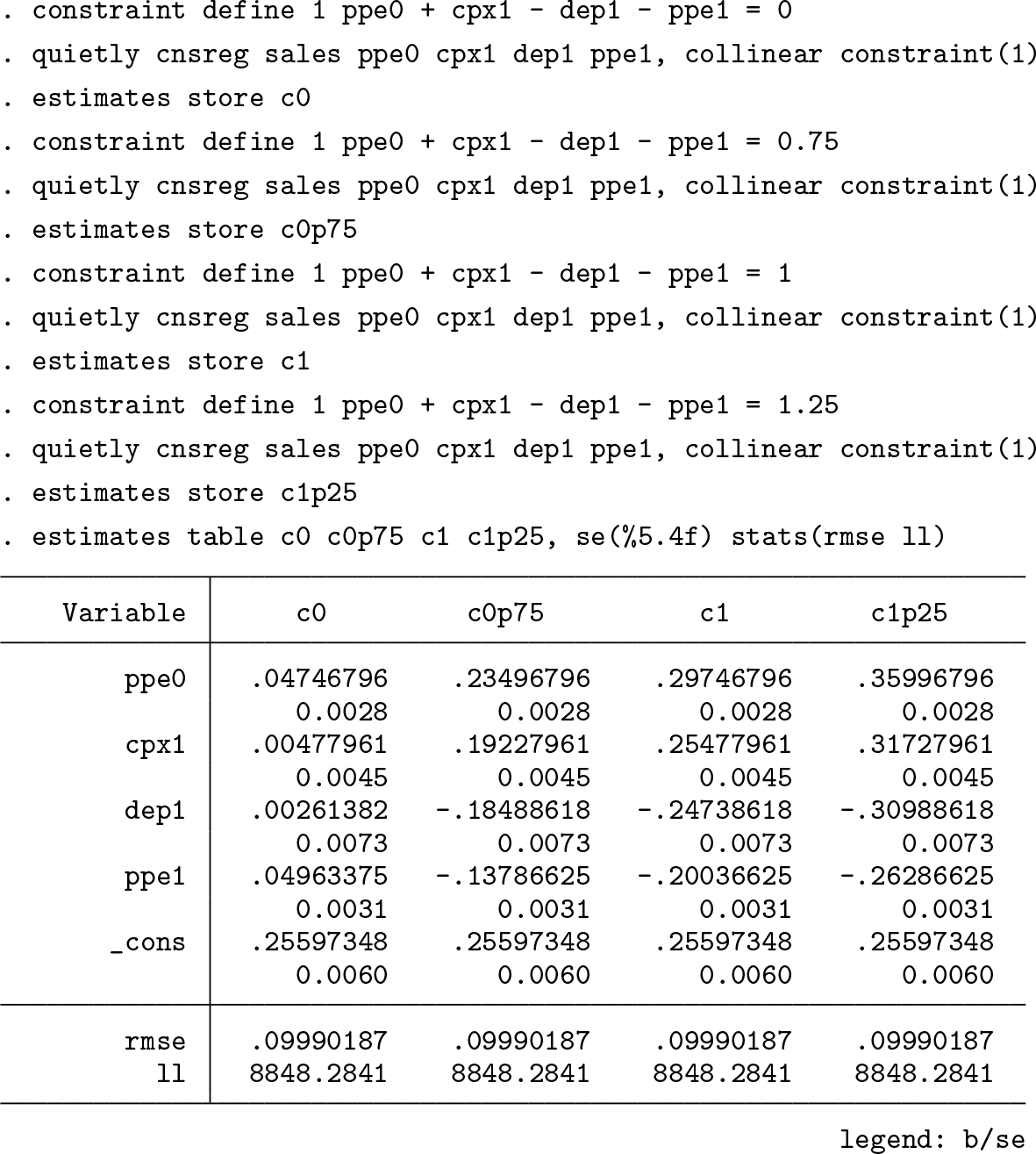
Note how the magnitudes of the estimated slopes switch place depending on the variable that is omitted from estimation. This is because each restriction sways estimation so that the collection of all estimated slopes remains parallel to the null vector that describes the linear dependency (for an illustration, see figure 1 in Christodoulou [2018]). This sort of behavior makes any discussion on marginal effects entirely meaningless.
Such ad hoc imposed constraints, whose only purpose is to enable mere estimation, are dangerous practices when applied on rank-deficient design matrices involving slope coefficients. A zero-parameter restriction on a slope suggests a zero marginal effect, and in this case such restrictions are simply untenable.
Another way to enable estimation is to expand
For example, for c = 0, a fixed change would result in no change in the dependent variable. For c = 1, a fixed change would result in a linear change in the dependent variable, or what the economists call a “constant return to scale” within the right context; for c < 1, we have decreasing returns to scale, and for c > 1 we have increasing returns to scale. Consider the following examples:
The option
Note how the addition of all estimated slopes is always the same, at
The coefficients are simply scaled up or down by a fixed amount as c changes. This means that because the constraints are needed for identification, the rank-deficient nature of the data does not allow one to say which structural constraint is most appropriate. One must assume it.
The model with the homogeneous function of degree zero, with c = 0, can also be fit using the Moore–Penrose pseudoinverse (for example, see Mazumdar, Li, and Bryce [1980]; Searle [1984]), using the

These are identical coefficients to those reported in the table just above under the heading

and similarly for any other c. Similarly, because the Moore–Penrose pseudoinverse gives the solution for c = 0, we could use this result to see what would be the set of estimates for any given zero-parameter restriction. Here is the case of the zero-parameter restriction on the coefficient of ppe it −1, which is the same as that reported in the first column of the first estimates table above:

Finally, an important note about standard errors—they remain the same across all specifications. As shown in Greene and Seaks (1991), the individual standard errors of regressions involving rank-deficient design matrices are no longer informative. We cannot speak of coefficient-specific statistical significance. For example, in the first table of estimates reported, the coefficient on
In Christodoulou and McLeay (2014, 2019), we use Stata to explain how this lack of insight has proven to be an acute problem in financial research that relies on inputs from the rank-deficient accounting data matrix of articulated financial statements. Accounting data, governed by a double-entry data-generating process whereby a transaction is recorded twice, is purposefully designed to be rank deficient of order one. This is a matter of structural nonidentification and requires the additional specification of a suitable constraint to enable estimation. If the constraint is arbitrarily imposed, then inference is entirely useless.
Footnotes
Acknowledgment
I acknowledge the useful comments by an anonymous reviewer.