
Abstract
In this article, we describe how to test for the presence of measurement error in explanatory variables. First, we discuss the test of such hypotheses in parametric models such as linear regressions and then introduce a new command,
1 Introduction
In this article, we describe how to test for the presence of measurement error in explanatory variables. Specifically, consider an outcome Y (for example, earnings) that depends on an explanatory variable X ∗ (for example, schooling). We do not observe X ∗ directly, but only two variables, X and Z, that are related to X ∗. We suspect X is an error-contaminated measurement of X ∗ (for example, schooling as reported in a survey) and Z is a variable related to X ∗, perhaps an instrument (for example, distance to college) or a repeated measurement (for example, schooling as reported in another survey). The hypothesis of no measurement error in X is

In the schooling example, testing H 0 could be useful as a first-step model specification test to tell the researcher whether measurement error is an important feature of the data that should be modeled. However, testing H 0 may be of direct economic interest because, for example, the null of no measurement error can often be shown to be implied by the absence of frictions in a structural economic model (for example, Chetty [2012]; Wilhelm [2018]). Therefore, a test of H 0 can be interpreted as a test of the absence of such frictions.
In a finite sample, we may not be able to detect measurement error even though X is in fact mismeasured, because measurement errors might be small relative to the overall sampling noise. In this sense, we can interpret the test of H 0 as finding out whether measurement error is severe enough for the data to tell the difference between models with and without measurement error.
In this article, we describe how to test for the presence of measurement error without imposing any parametric restrictions and, in fact, without requiring the model to be identified. Both of these aspects are important for empirical practice. First, when one tests for measurement error, it is important to allow for nonlinearities in the relationship of Y and X ∗ because measurement error in X can make the relationship appear nonlinear when it is not and make it appear linear when it is not (Chesher 1991). Therefore, to disentangle measurement error from nonlinearities requires a procedure that can allow for nonlinearities. Second, nonparametric measurement error models are identified only under fairly strong conditions, and their estimation involves complicated procedures such as Fourier transforms and operator inversions (Schennach 2013, 2016; Hu 2017). However, Wilhelm (2018) shows that testing for the presence of measurement error does not require identification of the model and is thus possible without such strong assumptions. In particular, the test can detect many nonclassical measurement error models, that is, models in which the measurement error depends on the true latent variable. Another by-product of avoiding identification of the model is that complicated estimation techniques are not necessary. In fact, the test we describe employs only standard nonparametric regression techniques.
The null hypothesis depends on the latent variable X
∗ and thus cannot directly be tested. In section 2, therefore, we first describe how to convert the null hypothesis into a testable restriction in terms of the observable variables Y, X, Z in a simple example, a linear regression model. In this model, H
0 can easily be tested using existing Stata commands following Hausman (1978). Section 3 then describes the extension of such ideas to the nonparametric framework as recently proposed by Wilhelm (2018). We also introduce a new command,
Related literature
Mahajan (2006) proposes a test for the presence of measurement error when the explanatory variable X ∗ and the observed measure X are binary. There are some existing tests for the presence of measurement error in parametric models that require identification and consistent estimators of the model: Hausman (1978); Chesher (1990); Chesher, Dumangane, and Smith (2002); Hahn and Hausman (2002); and Hu (2008). Related to Hausman (1978), in empirical work it is common to estimate linear regressions by ordinary least squares (OLS) and instrumental variables (IV) and then attribute a difference in the two estimates to the presence of measurement error, treating the IV estimate as the consistent and unbiased one. Of course, this strategy is valid only if the true relationship of interest is actually linear, the measurement error is classical, and the model is identified. None of these assumptions is required in the nonparametric approach described in this article.
In principle, one could imagine constructing a test for the presence of measurement error by comparing an estimator of the model that accounts for the possibility of measurement error with one that ignores it, similar in spirit to the work by Durbin (1954), Wu (1973), and Hausman (1978). If the difference between the two is statistically significant, then one could conclude that this is evidence for the presence of measurement error. However, this strategy would require identification and consistent estimation of the measurement error model, which leads to overly strong assumptions, the necessity of solving ill-posed inverse problems in the continuous variable case, and potentially highly variable estimators. These difficulties can all be avoided by the nonparametric approach described in this article.
2 Linear regression model
Consider the linear regression model for an outcome Y and an explanatory variable X ∗, assuming for simplicity that there are no further regressors (the extension to the presence of additional controls is straightforward and discussed below),
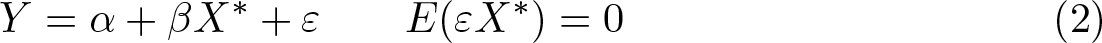
Instead of X ∗, we observe a measurement X of X ∗ and IV Z, which depends on X ∗ [that is, E(X ∗ Z) ≠ 0], but is excluded from the outcome equation [that is, E(εZ) = 0]. Testing for the presence of measurement error in this context is straightforward (Hausman 1978). Under the null of no measurement error, OLS consistently estimates β, but under the alternative of some measurement error, it is inconsistent. The IV estimator, however, is consistent under both the null and the alternative. Therefore, one can simply compute both estimators and compare them. If their difference is statistically significant, that indicates the presence of measurement error.
To better understand the connection to the nonparametric test described in the next section, note that the test based on the difference of OLS and IV estimators is equivalent to testing significance in an expanded regression. To see this, suppose there is no measurement error in X, then
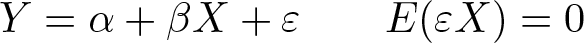
Therefore, when we regress Y onto both X and Z, the exclusion of the IV implies that the coefficient of Z must be zero; 1 that is, we test the hypothesis of no measurement error by instead testing

in the regression
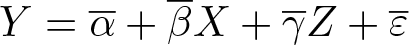
In conclusion, we have shown that the null of no measurement error, (1), implies (3) in the linear regression model. The only assumption for this to be true is that (2) holds and that the IV is excluded from the outcome equation; that is, E(εZ) = 0. Therefore, a rejection of the restriction (3) implies a rejection of the hypothesis of no measurement error, (1).
However, without further assumptions, failing to reject (3) does not necessarily imply failing to reject the null of no measurement error, (1). Suppose X = X ∗ + ηX so that ηX represents the measurement error in X. If the measurement error in X is assumed to be classical [that is, it is uncorrelated with the latent regressor, E(X ∗ ηX ) = 0] and uncorrelated with the regression error, E(εηX ) = 0, and if some further regularity conditions hold, then it is easy to see that the null hypothesis H 0 not only implies but also is in fact implied by (3). Therefore, failing to reject (3) may be interpreted as failing to reject H 0, and rejecting (3) may be interpreted as rejecting H 0.
Consider the following simulated example that illustrates the finite sample performance of the test by Hausman (1978). First, we simulate data without measurement error in the regressor (X = X ∗),

Then, we regress Y on X and Z (and a constant),
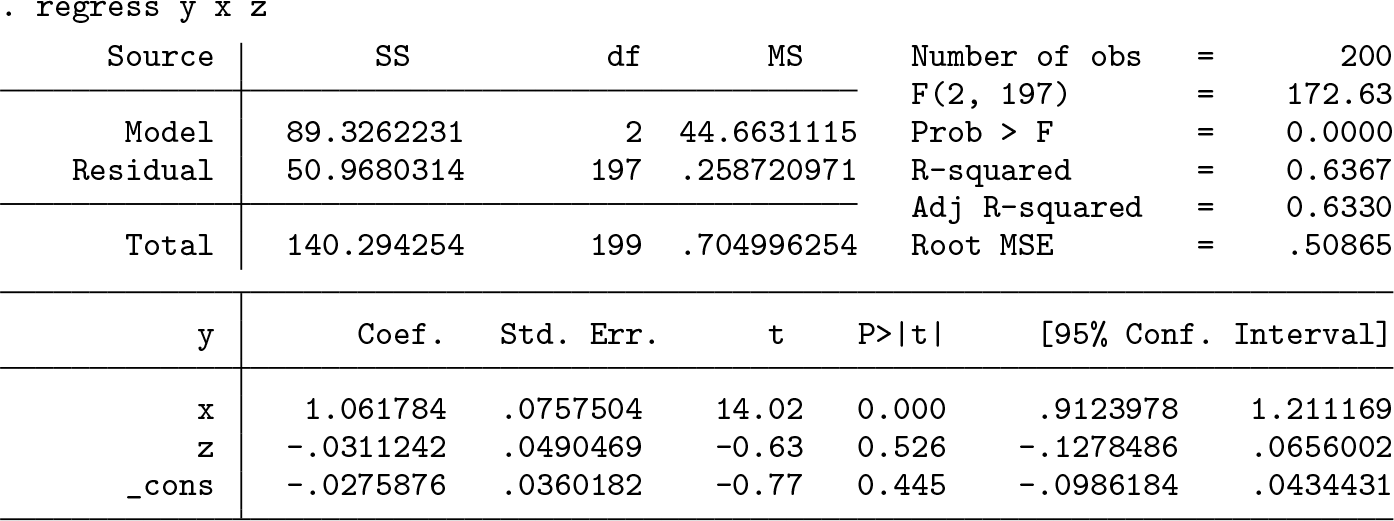
to find that Z is not significant at any reasonable confidence level (p-value is 0.526). Therefore, we fail to reject the null of no measurement error as expected. Now, we generate a measurement error contaminated regressor (X ≠ X ∗),
Again, we regress Y on X and Z (and a constant),
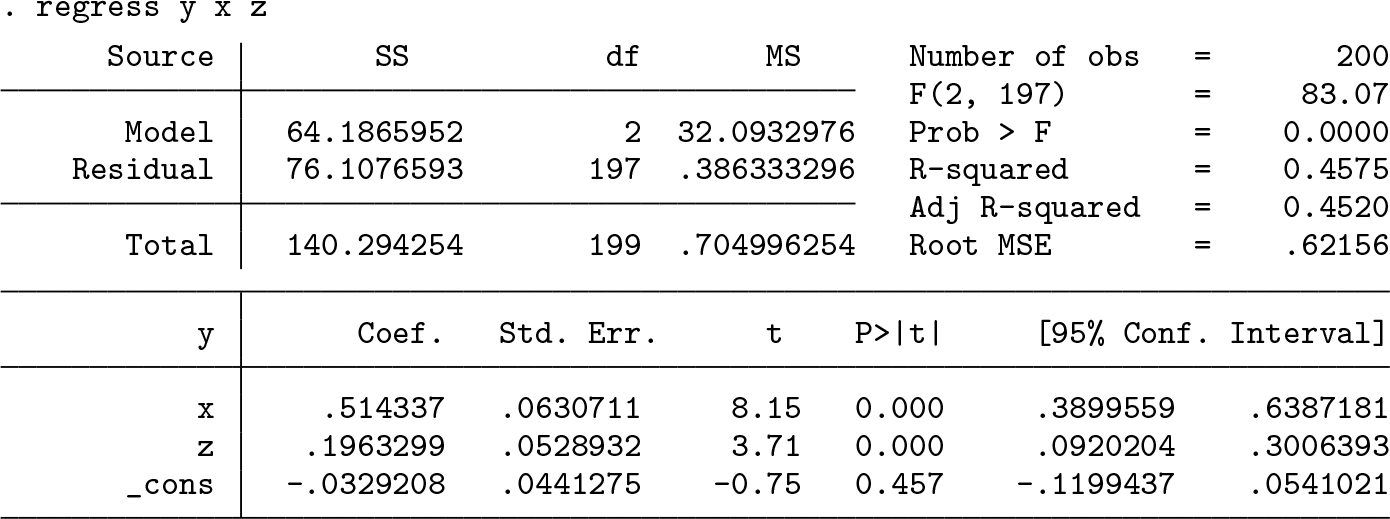
to find that now Z is significant at every reasonable confidence level (p-value is 0.000). Therefore, we strongly reject the null of no measurement error.
In the presence of additional, correctly measured controls in the regression model, we would proceed exactly as above except that we would include the additional controls in the regression command.
3 Nonparametric model—The new dgmtest command
While the approach to testing H 0 in the previous section is straightforward and intuitive, its validity relies on strong assumptions: linearity in the outcome equation and classical measurement error in X. Because nonlinearities in the regression equation and measurement error in X may manifest themselves similarly (Chesher 1991), it is important to allow for nonlinearities in the relationship between Y and X ∗ when testing for measurement error. In addition, a large literature has documented that measurement error in economic data is rarely classical (see the survey by Bound, Brown, and Mathiowetz [2001], for example). In this section, we describe how to test H 0 in nonlinear models with nonclassical measurement error.
Suppose the variable Z is related to X ∗, but the measurement X is excluded from the outcome model in the sense that

That is, they can affect outcomes only through the true explanatory variable X ∗. Then, it is easy to see that, under H 0, Z must be excluded from the outcome equation conditional on the observed X,
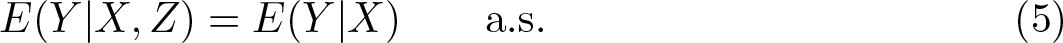
Unlike H 0, this is a restriction that depends only on observables and can directly be tested without making any parametric assumptions about how the conditional mean of Y depends on X ∗. The test by Delgado and González Manteiga (2001) introduced
in the next subsection and implemented in the new command,
The exclusion restriction (4) is standard in the literature on identification and estimation of measurement error models (Carroll et al. 2006; Chen, Hong, and Nekipelov 2011; Schennach 2013, 2016; Hu 2017) and has already been justified in many empirical applications. Because the assumption is central to the validity of the test for measurement error, we now provide a few examples.
Consider a generic production problem in which Y is an output that is produced from a vector of inputs X ∗. The inputs are measured by the vectors X and Z alternatively. In this context, the exclusion restriction is often a natural assumption because it requires the “true” inputs X ∗ to be the factors that matter for production, not the measurements (X, Z). Therefore, conditional on knowing X ∗, the measurements X and Z should not provide any additional information about the output Y . Cunha, Heckman, and Schennach (2010); Heckman, Pinto, and Savelyev (2013); Attanasio et al. (2015); and Attanasio, Meghir, and Nix (2017) are examples of empirical articles in the skillformation literature that have justified the exclusion restriction in this fashion. The same argument applies to many other production problems in which inputs are difficult to measure (for example, Olley and Pakes [1996]).
In the empirical part of Wilhelm (2018) and in section 5 below, Y , X, and Z are three measurements of earnings, but Y and (X, Z) come from two different data sources, one from a survey and the other from an administrative dataset. We then argue the exclusion restriction holds because the error in Z has a different origin from the error in Y , at least conditional on X ∗.
There are many other empirical applications that impose the exclusion restriction (4): For instance, Altonji (1986) studies labor supply; Kane and Rouse (1995) and Kane, Rouse, and Staiger (1999) study the returns to education; Card (1996) studies the effect of unions on the wage structure; Hu et al. (2013) study auctions with unobserved heterogeneity; Feng and Hu (2013) study unemployment dynamics; and Arellano, Blundell, and Bonhomme (2017) study earnings dynamics.
Wilhelm (2018) actually shows that, under additional assumptions, H 0 not only implies but also is implied by the observable restriction (5). Therefore, failing to reject (5) may be interpreted as failing to reject H 0, and rejecting (5) may be interpreted as rejecting H 0.
The main assumptions required for this equivalence result are first, the exclusion restriction (4); second, a relevance condition that ensures Z is sufficiently strongly related to X
∗; and third, monotonicity of the conditional mean function
To satisfy the relevance condition, we need to find two values of Z, say, z
1
, z
2, such that the probability mass functions of
We now heuristically explain why the exclusion restriction, the relevance condition, and the monotonicity condition together guarantee equivalence of H 0 and (5). We have already argued why H 0 implies (5) under the exclusion restriction, so we need to show only that the reverse holds as well.
Consider the special case when X
∗ and X are continuously distributed and X
∗, X, and Z are scalars. Suppose the observable implication (5) holds. Then, for any two values z
1
, z
2, we have
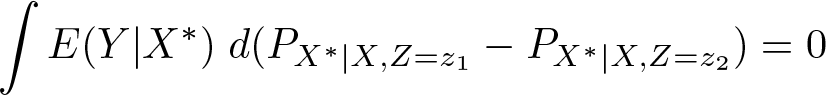
if E(Y |X ∗ = ·) is differentiable, then integration by parts yields
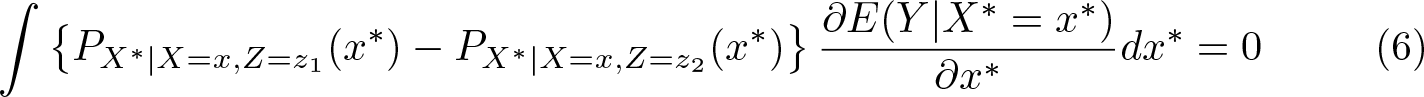
We want to show that this equation implies the null hypothesis H
0. On the contrary, assume that this is not the case. To generate a contradiction, we want to ensure that (6) does not hold under the alternative H
1. This is the case, for example, when E(Y |X
∗ = ·) is monotone (and not constant) and
In some applications, Z may be excluded from the outcome equation only after conditioning on some additional, correctly measured controls W; that is, the exclusion restriction (4) is replaced by
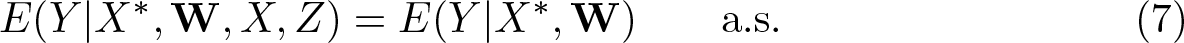
This additional conditioning on

The null hypothesis is, in fact, equivalent to (8) under conditions like those required for the equivalence of H
0 and (5). In the implementation of the test, we allow for two types of additional controls, say,
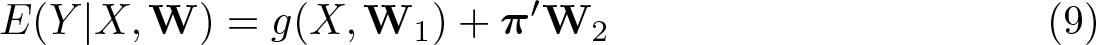
for some function g and some vector of coefficients
There exist many nonparametric tests of the conditional mean independence in (5) and (8), for example, Gozalo (1993); Fan and Li (1996); Delgado and González Manteiga (2001); Mahajan (2006); and Huang, Sun, and White (2016). Therefore, any of those could be used for nonparametrically testing for the presence of measurement error. In the presence of several additional covariates
In the following subsections, we introduce a new command,
3.1 The test by Delgado and González Manteiga (2001)
We briefly describe the approach by Delgado and González Manteiga (2001) for testing the conditional mean independence (5). There are many other reasons why one might want to test such a restriction, and the test for the presence of measurement error as described in this article is only one of these. To simplify the description, we focus on the case in which there are no additional controls W .
The authors rewrite the null hypothesis of conditional mean independence, (5), as
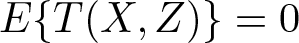
where
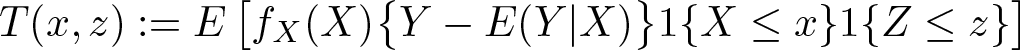
1{A} is equal to 1 if the event A holds, 0 otherwise, and fX
is the density of X. Given a random sample
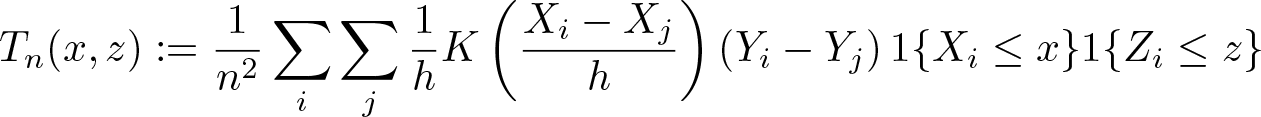
where h is a bandwidth parameter and K a kernel function. Delgado and González Manteiga (2001) propose two test statistics: the Cramér–von Mises statistic
Testing the version with additional controls, (8), is a simple extension of the above test. In the presence of additively separable controls
3.2 Syntax
The
The two required arguments of the command are depvar (the outcome variable Y ) and expvar (a list of variables containing all elements of X,
3.3 Options
3.4 Stored results

3.5 A simple example
Consider again the simple simulated example from section 2. First, perform the non-parametric test for measurement error on the correctly measured explanatory variable, using the default settings of the
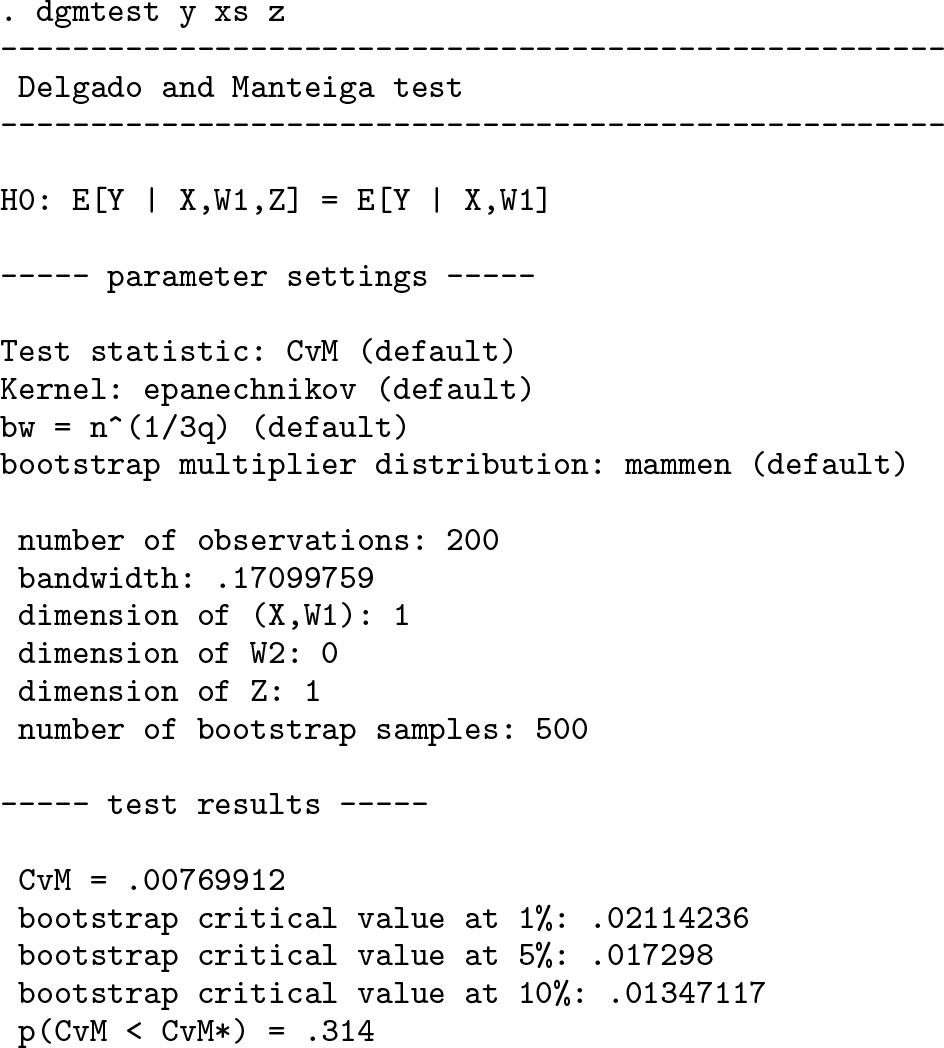
The p-value of the Cramér–von Mises version of the test is 0.314, which means we fail to reject the null of no measurement error at all reasonable confidence levels.
Now, we perform the test on the mismeasured explanatory variable, again using the default settings of the command:
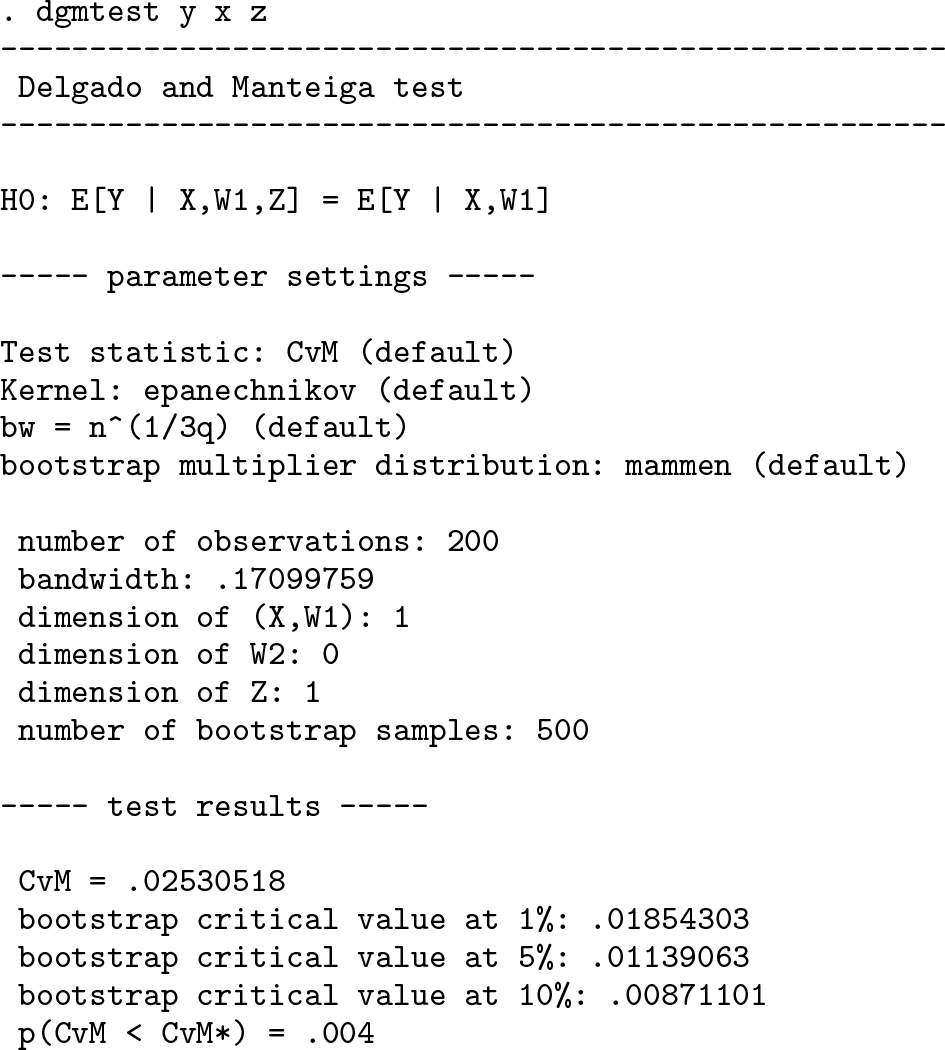
As expected, the nonparametric test detects the measurement error and strongly rejects the null of no measurement error (p-value is 0.004) at all reasonable confidence levels.
4 Monte Carlo simulation
In this section, we present a small simulation study investigating the finite sample performance of the measurement error test.
We consider the outcome equation
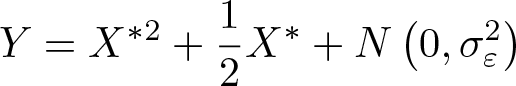
with different models for the measurement system:
Model I :
Model II :
Model III :
Model IV :
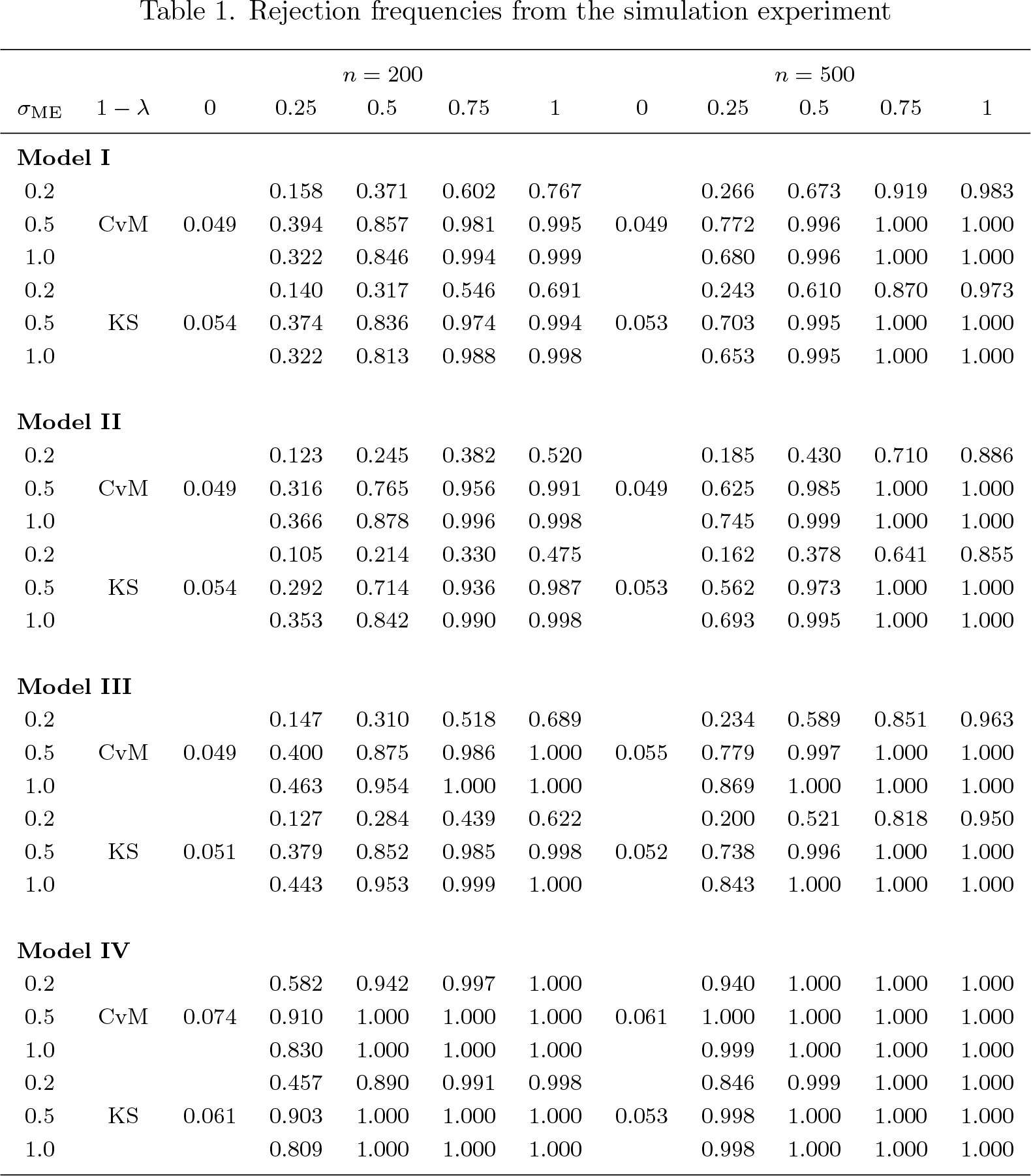
The value for σε is 0.5 for models I, II, and III and 0.2 for model IV. In all four models, X ∗ ∼ U [0, 1], and the random variable D is Bernoulli(1 − λ), where 1 − λ is the probability of measurement error (ME) in X occurring. 1 − λ = 0 means there is no measurement error in X, which represents the null hypothesis. To generate alternatives, we increase 1−λ on a grid up to 1. We vary the standard deviation of the measurement error in X, σ ME, in {0.2, 0.5, 1}. Therefore, alternatives get closer to the null as we decrease 1 − λ or σ ME, or both. We vary the sample size n ∊ {200, 500}, but all models are simulated on 1,000 Monte Carlo samples (we set the seed at 1234). Following Delgado and González Manteiga (2001), we use the bandwidth rule-of-thumb value n −1/3. Simulation results for different choices of bandwidths, which are not presented here, are similar.
The Cramér–von Mises statistics are generated by
The Kolmogorov–Smirnov test statistics with 10 grid points are generated by
Table 1 shows the rejection frequencies of the test. Overall, the test controls size well and possesses power against all alternatives. These findings are consistent with the Monte Carlo simulation results in Wilhelm (2018).
Rejection frequencies from the simulation experiment
5 Example: Testing for the presence of measurement error in administrative earnings data
In this section, we test for measurement error in the U.S. Social Security Administration’s measure of earnings. While measurement error in survey responses is a widespread concern that has occupied a large literature (Bound, Brown, and Mathiowetz 2001), only recently empirical researchers have emphasized concerns about the reliability of administrative data (for example, Fitzenberger, Osikominu, and Völter [2006]; Kapteyn and Ypma [2007]; Abowd and Stinson [2007]; Groen [2012]).
The data come from the March 1978 Current Population Survey/Social Security Summary Earnings (U.S. Census Bureau 2009). The sample selection is similar to Wilhelm (2018), except that we consider only white singles between ages 25 and 60 who work full time the full year. The sample size is 2,683 individuals. The dataset contains a survey measure of earnings in 1977 (
Figure 1 shows nonparametric density estimates of survey and administrative earnings. Figure 2 plots the nonparametric density estimate of the difference between administrative and survey earnings. There is substantial probability mass within USD ±1,000, which is a large deviation relative to the maximum earnings in the sample (USD 16,500).
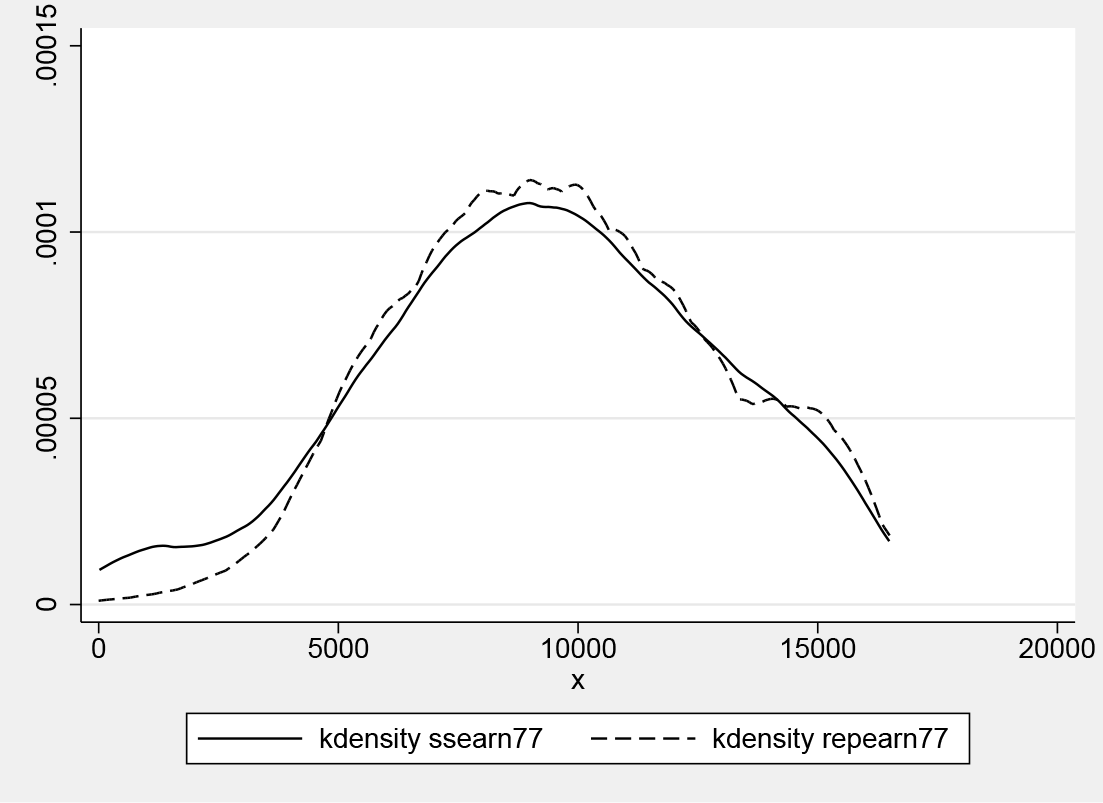
Nonparametric density estimates of administrative earnings (
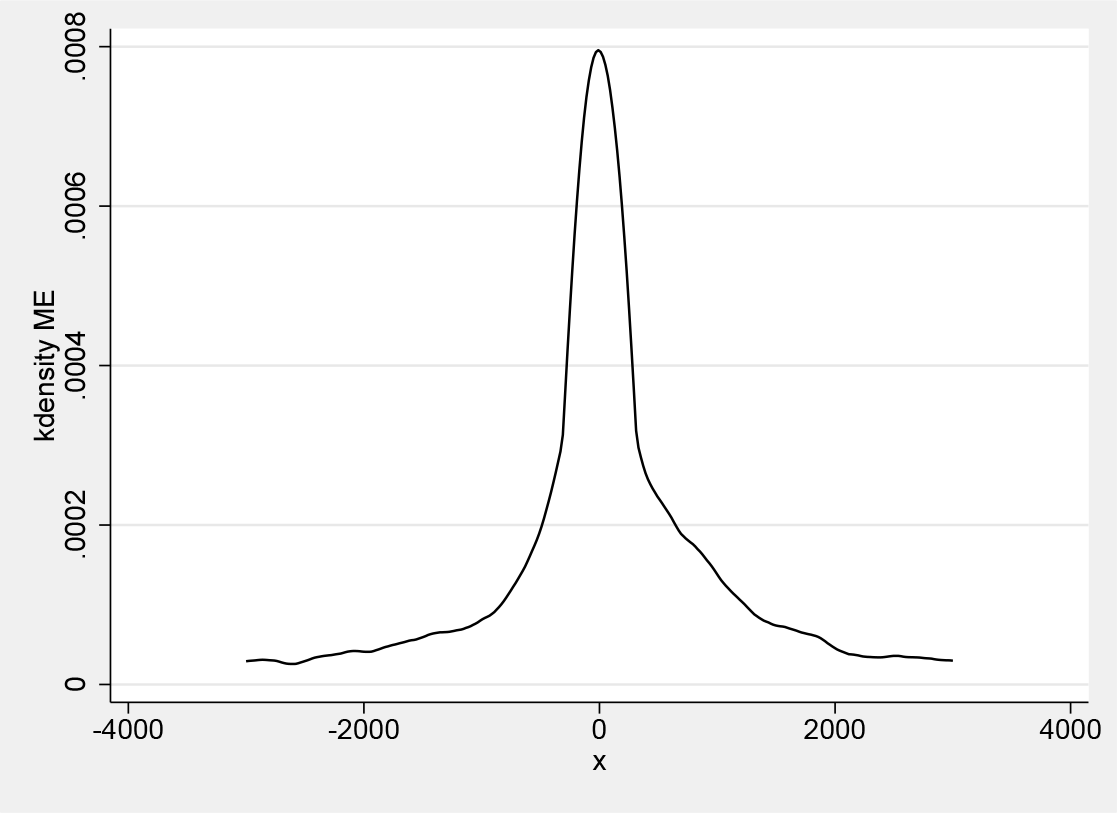
Nonparametric density estimate of the difference in administrative and survey earnings in 1977, using a cross-validated bandwidth
The exclusion restriction (4) is likely to hold in this context because the measurement errors in survey and administrative earnings come from different sources (see the more detailed discussion in Wilhelm [2018]). To assess the relevance of the second measurement Z, which here is lagged administrative earnings, we plot the density of administrative earnings in 1977 given those in 1976. Figure 3 shows this density for those individuals with lagged earnings in the 10th and 90th percentile of the 1976 earnings distribution. The graph shows that the second measurement Z, lagged administrative earnings, shifts the earnings distribution in the next period to the right as we go from the 10th to the 90th percentile. In particular, the two densities seem to cross only once, which is consistent with the relevance condition that is needed for the equivalence of H 0 and the observable restriction (5).
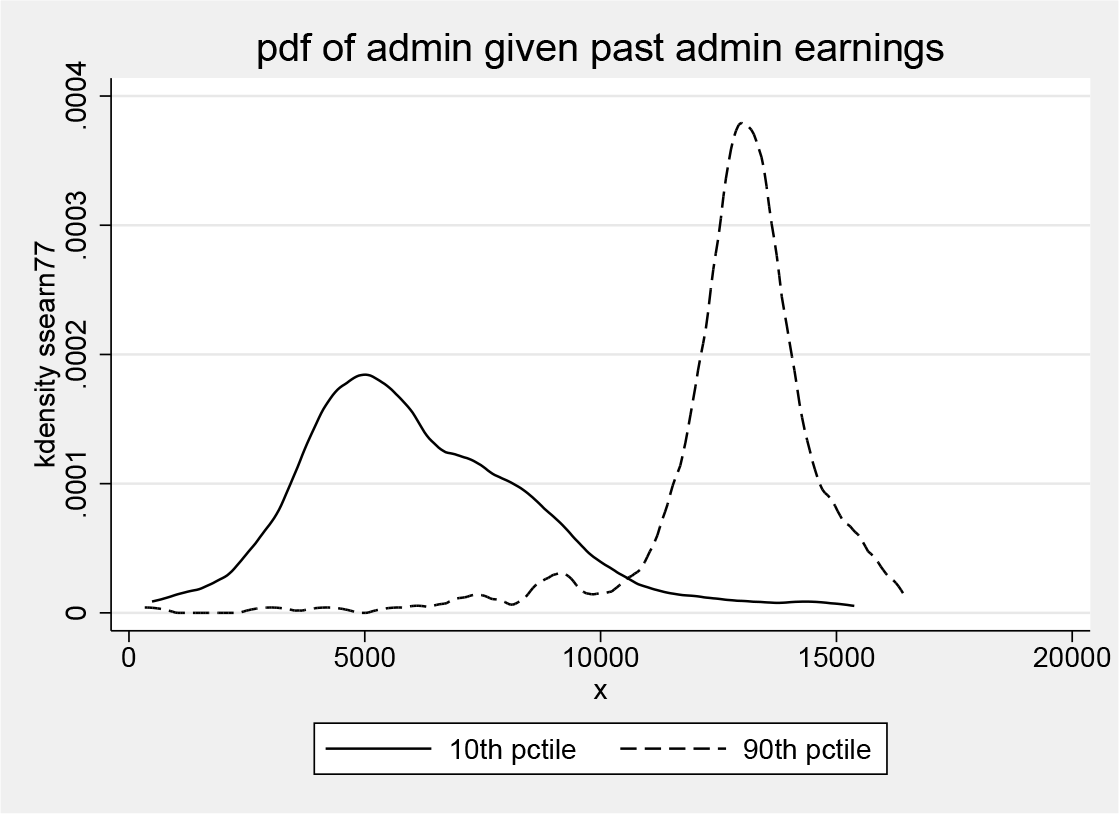
Nonparametric estimate of the conditional density of administrative earnings in 1977 given lagged administrative earnings being in the 10th or 90th percentile. Bandwidths are chosen by cross-validation.
Figure 4 shows nonparametric estimates of the conditional mean E(Y |X = x, Z = z) as a function of z for three values of x. If there was no measurement error in X, then (5) implies that this conditional mean should not vary with z. The graph suggests that there is some variation in that dimension, particularly for small and large values of earnings, but the graph does not contain any information about whether this variation is statistically significant, so we will now discuss the results of the formal test of H 0.
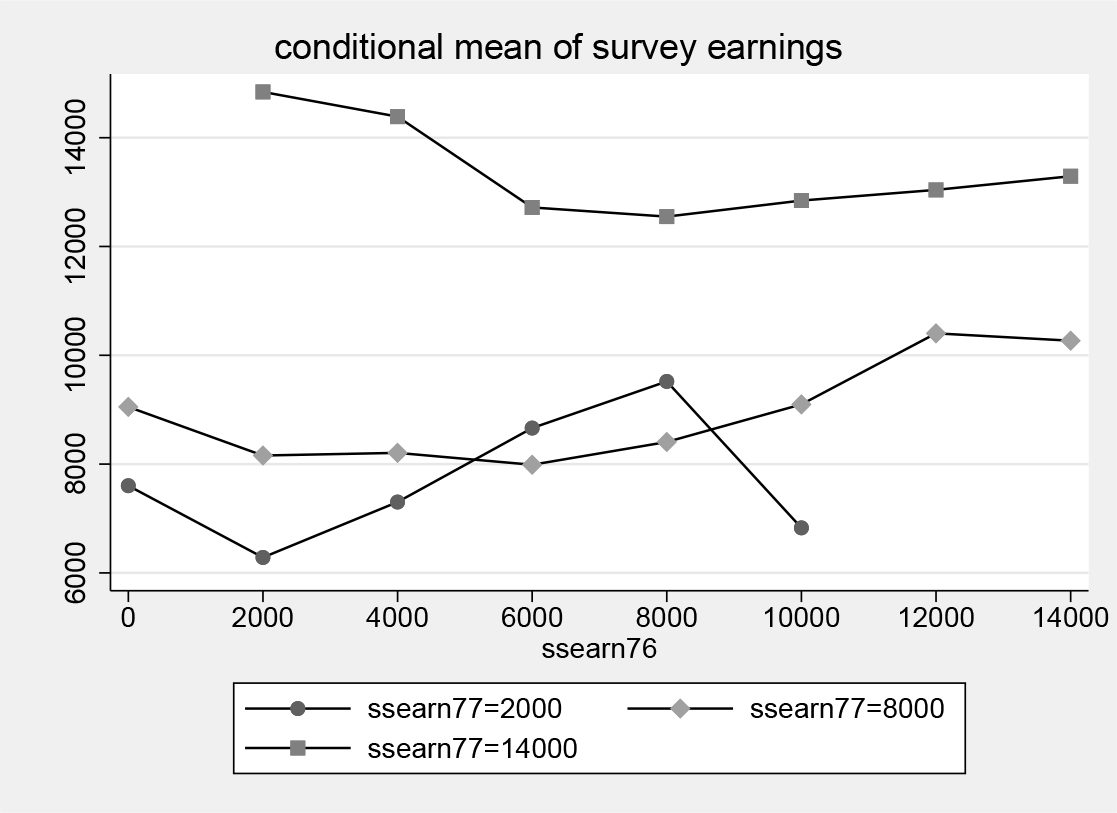
Nonparametric estimate of E(Y |X, Z), where Y is survey earnings in 1977 and X and Z are administrative earnings in 1977 and 1976, respectively. Bandwidths are chosen by cross-validation.
The test is performed using the new command,
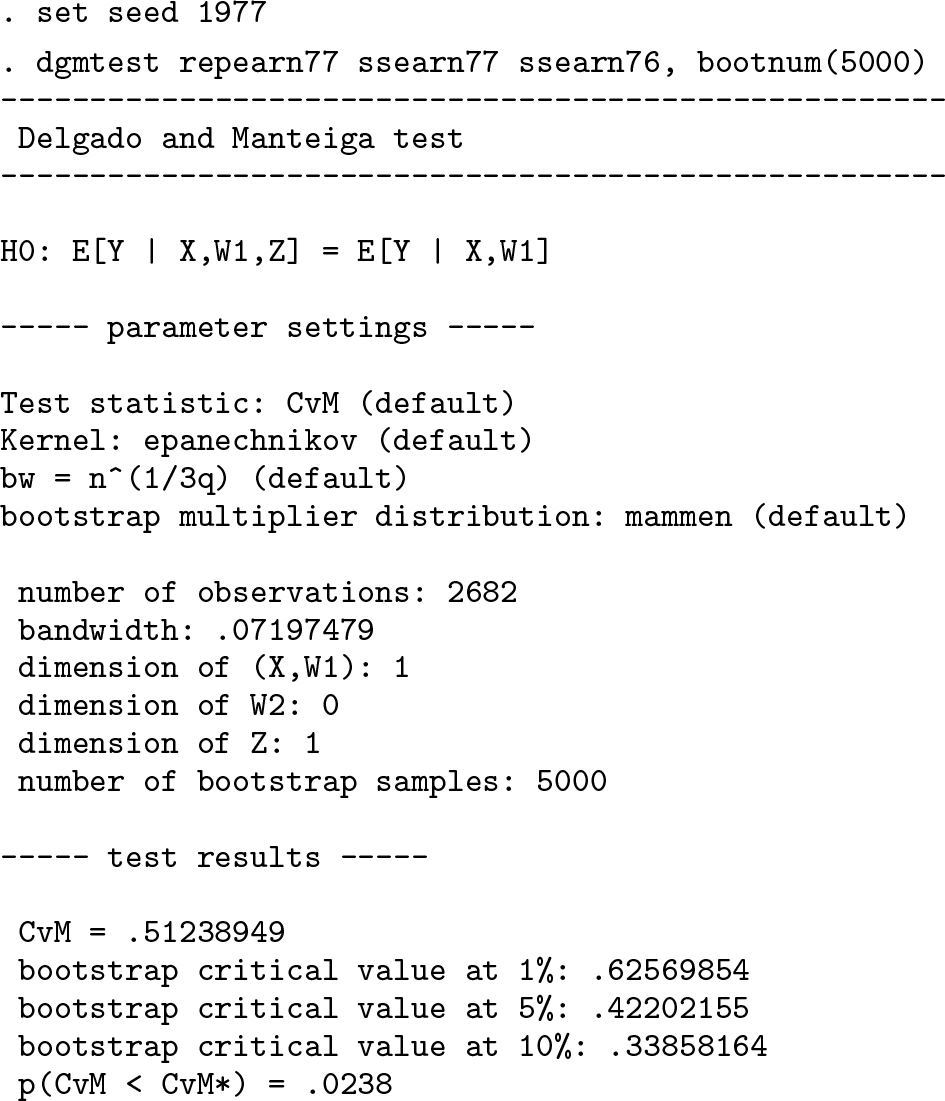
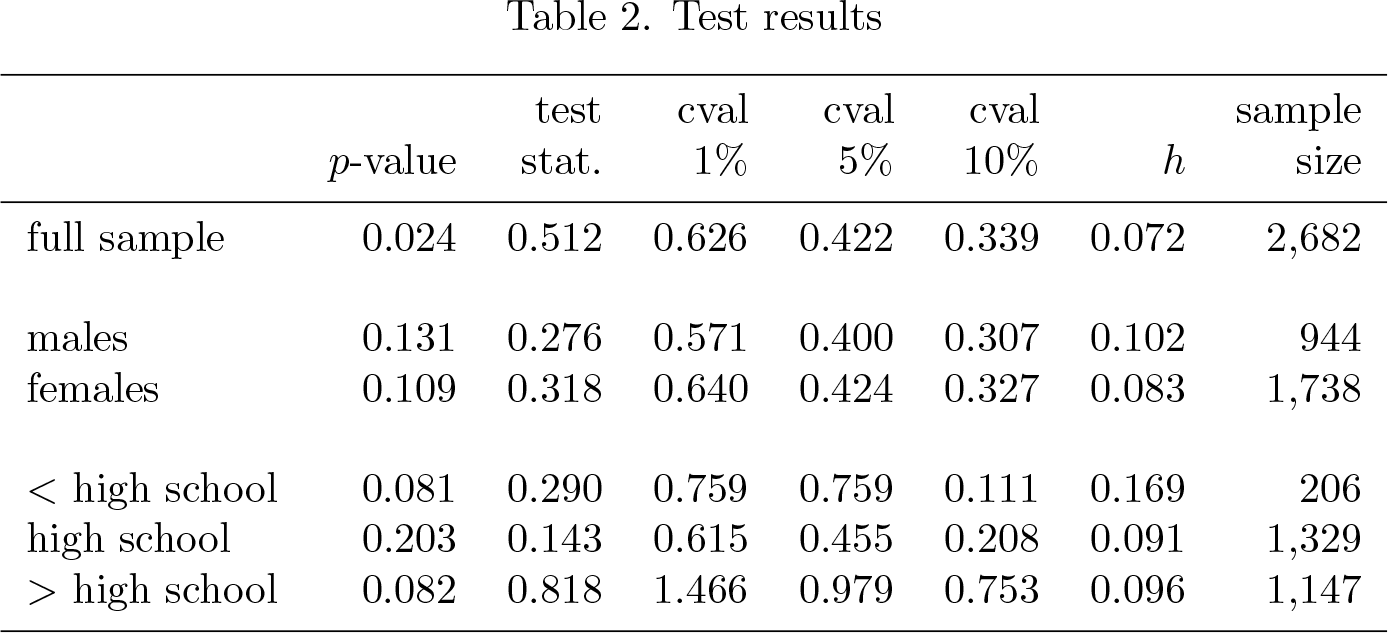
The test produces a p-value of 0.0238, so we reject the null of no measurement error in administrative earnings at high confidence levels. Table 2 shows the test results for the full sample as well as for subsamples with the same gender and education. The p-values for the low and high education groups are about 8%, which is some evidence for the presence of measurement error but is weaker than in the full sample. For individuals in the middle education group, there is no evidence of measurement error. Similarly, we cannot reject the null on the subsamples of males and females. Of course, the sample sizes on the subsamples are significantly smaller than on the full sample, so it may be harder to reject the null for that reason.
Test results
6 Conclusion
This article describes how to test for the presence of measurement error in covariates. While in linear regression models with classical measurement error, testing the null of no measurement error can be carried out using simple linear regression techniques, we introduce the
The command is an implementation of the Delgado and González Manteiga (2001) test of conditional mean independence, a hypothesis that might be of interest in applications other than testing for the presence of measurement error.
Footnotes
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type