
Abstract
When one analyzes the determinants of production efficiency, regressing efficiency scores estimated by data envelopment analysis on explanatory variables has much intuitive appeal. Simar and Wilson (2007, Journal of Econometrics 136: 31–64) show that this conventional two-stage estimation procedure suffers from severe flaws that render its results, and particularly statistical inference based on them, questionable. They additionally propose a statistically grounded bootstrap-based two-stage estimator that eliminates the above-mentioned weaknesses of its conventional predecessors and comes in two variants. In this article, we introduce the new command
Keywords
1 Introduction
Analyzing the technical efficiency of production or decision-making units (DMUs) has developed into a major field in empirical economics and management science. 1 From a methodological perspective, the two most popular strands of the literature can be distinguished: i) analyses that rest on parametric, regression-based methods, namely, stochastic frontier analysis (Aigner, Lovell, and Schmidt 1977), and ii) analyses that use nonparametric methods, namely, data envelopment analysis (DEA) (Charnes, Cooper, and Rhodes 1978). The pros and cons of either approach have been discussed extensively (for example, Hjalmarsson, Kumbhakar, and Heshmati [1996]; Murillo-Zamorano [2004]).
One of the advantages of the parametric approaches, namely, the truncated normal stochastic frontier model, is that it not only allows for measuring inefficiency but also incorporates a model of the determinants of inefficiency. 2 In contrast, nonparametric approaches are primarily concerned with estimating a production-possibility frontier (or an input-requirement frontier) and with measuring the distance of observed input-output combinations to this frontier. However, shedding light on what determines the magnitude of this distance is out of the narrow 3 scope of nonparametric approaches such as DEA.
For many research questions, however, identifying determinants of inefficiency is more relevant than determining its magnitude for specific DMUs. For this reason, in the domain of nonparametric efficiency analysis, semiparametric two-stage approaches that combine efficiency measurement by DEA with a regression analysis that uses DEA estimated efficiency as dependent variables have become popular. Simar and Wilson (2007) list almost 50 published articles and mention hundreds of unpublished articles that use such two-stage procedures. In these (early) applications, the second stage is typically a censored (tobitlike) regression to account for the bounded nature of DEA efficiency scores or just simply ordinary least squares (Simar and Wilson 2007).
Despite their popularity and their intuitive appeal, such conventional two-stage estimators are criticized by Simar and Wilson (2007) mainly for two reasons. First, they stress the absence of a clear theory of the underlying data-generating process that would justify the conventional two-stage approach. 4 Second, they criticize the conventional inference that is pursued in most two-stage applications for ignoring that estimated DEA efficiency scores are calculated from a common sample of data. Treating them as if they were independent observations is not appropriate, because the problems related to invalid inference due to serial correlation arise. Simar and Wilson (2007) develop a two-stage procedure that accounts for the above-mentioned issues. They describe an underlying data-generating process that is consistent with a two-stage estimation procedure, which—as the most obvious difference to the earlier conventional approach—implies a truncated rather than censored regression model. This reflects that the substantial share of fully efficient DMUs typically found in DEA is an artifact of the finite-sample bias inherent in DEA but does not represent a feature of the true underlying data-generating process. Moreover, they propose two parametric bootstrap procedures that are consistent with the assumed data-generating process and address the second issue. They yield estimated standard errors and confidence intervals that do not suffer from bias due to estimated efficiency scores being correlated.
The Simar and Wilson (2007) procedure has become a workhorse of empirical efficiency analysis with hundreds of applications from various fields of economics.
5
This popular, but technically involved estimator, has not yet been available to Stata users unless they developed their own code. In this article, we introduce the new command
The remainder of this article is organized as follows. Section 2 gives a brief summary of the Simar and Wilson (2007) two-stage estimator. Section 3 describes the syntax of
2 The Simar and Wilson (2007) estimator in brief
2.1 Some essential ideas
Simar and Wilson (2007) consider a setting in which a researcher observes three types of variables
The output-input set (
The key idea in Simar and Wilson (2007) about the data-generating process is that efficiency θ
i linearly depends on

where β denotes a column vector of coefficients, the estimation of which is the ultimate objective of the empirical analysis. The disturbances ε
i are assumed to be statistically independent across DMUs
10
and to follow a truncated normal distribution with parameters
It is key for understanding the shortcomings of conventional two-stage approaches that θ
i is genuinely unobservable. Consequently, the estimated efficiency score
In the procedure
14
suggested in Simar and Wilson (2007), the former issue is addressed by estimating standard errors and confidence intervals for
Figure 1 graphically illustrates (and the notes below describe) the concepts of true, DEA estimated, and bias-corrected estimated inefficiency, using randomly generated data and considering a simple single input–single output production technology.
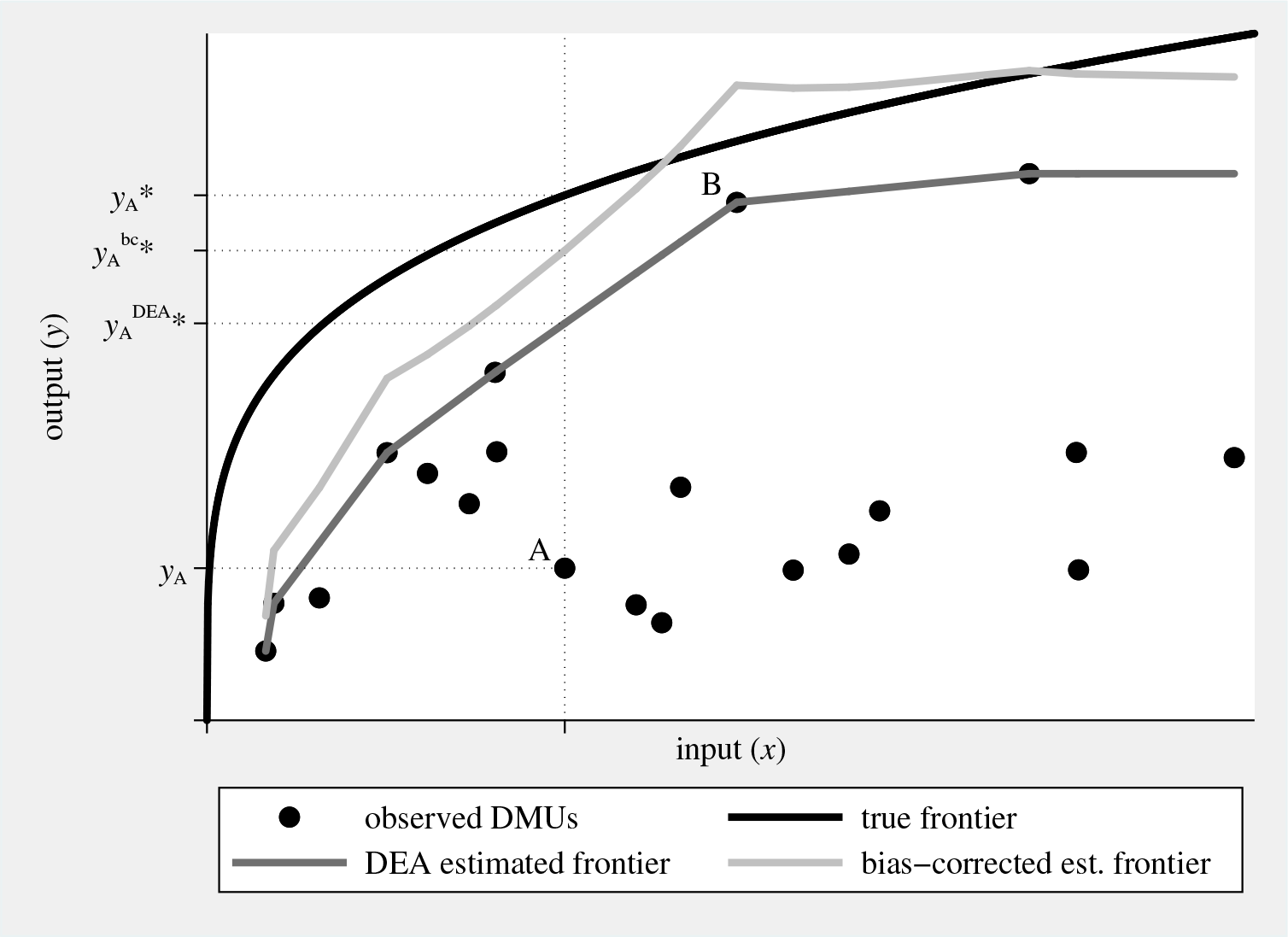
Graphical illustration of true and estimated inefficiency. Considering DMU A, true inefficiency θ
A is
2.2 The procedures suggested in Simar and Wilson (2007)
This subsection describes in detail the suggested procedures algorithm 1 and algorithm 2. In doing this, it almost exactly reproduces what is found on pages 41–43 in Simar and Wilson (2007). This particularly applies to the subsequent numbered paragraphs that describe the steps of the estimation procedures almost exactly as they are described in the key reference.
1. Compute 2. Use those M (with M < N) DMUs for which 3. Loop over the following steps 3.1–3.3 B times to obtain a set of B bootstrap estimates 3.1. For each DMU 3.2. Calculate artificial efficiency scores 3.3. Run a truncated regression (left-truncation at 1) of 4. Calculate confidence intervals and standard errors for
The more involved 1. Compute 2. Use those M (M < N) DMUs for which 3. Loop over the following steps 3.1–3.4 B
1 times to obtain a set of B
1 bootstrap estimates 3.1. For each DMU 3.2. Calculate artificial efficiency scores 3.3. Generate 3.4. Use the N artificial DMUs, generated in step 3.3, as reference set in a DEA that yields 4. For each DMU 5. Run a truncated regression (left-truncation at 1) of 6. Loop over the following steps 6.1–6.3 B
2 times to obtain a set of B
2 bootstrap estimates ( 6.1. For each DMU 6.2. Calculate artificial efficiency scores 6.3. Run a truncated regression (left-truncation at 1) of 7. Calculate confidence intervals and standard errors for
2.3 Some minor extensions
The new command One may opt for the Shephard rather than the Farrell distance measure (option Related to the discussion in Simar and Wilson (2007, 45), one may assume a data generating process that deviates from (1) by considering log (in)efficiency as the left-hand-side variable (option Here ε
i is assumed to be truncated normally distributed, with left-truncation at −

3 The simarwilson command
3.1 Syntax
The syntax for
outputs is the list of outputs from the production process, and inputs is the corresponding list of inputs. Either varlist may include only numeric, nonnegative variables. Factor variables and time-series operators are not allowed. The number of output and input variables must not exceed the number of considered DMUs.
depvar specifies an existing variable that contains an externally estimated efficiency measure (score) meant to enter the regression model as a dependent variable. Specifying depvar is possible only if
indepvars denotes the list of explanatory variables. Unlike outputs and inputs, factor variables are allowed in indepvars; see [U]
3.2 Options
maximize_options allows for all maximization options that are allowed with
3.3 Stored results

Note that
3.4 simarwilson postestimation
The postestimation commands available after
One should generally be careful in interpreting the results from postestimation commands, such as
4 An application of simarwilson
4.1 Comparison of estimation methods
To illustrate how
We consider a national-level production process that generates the single output real GDP (
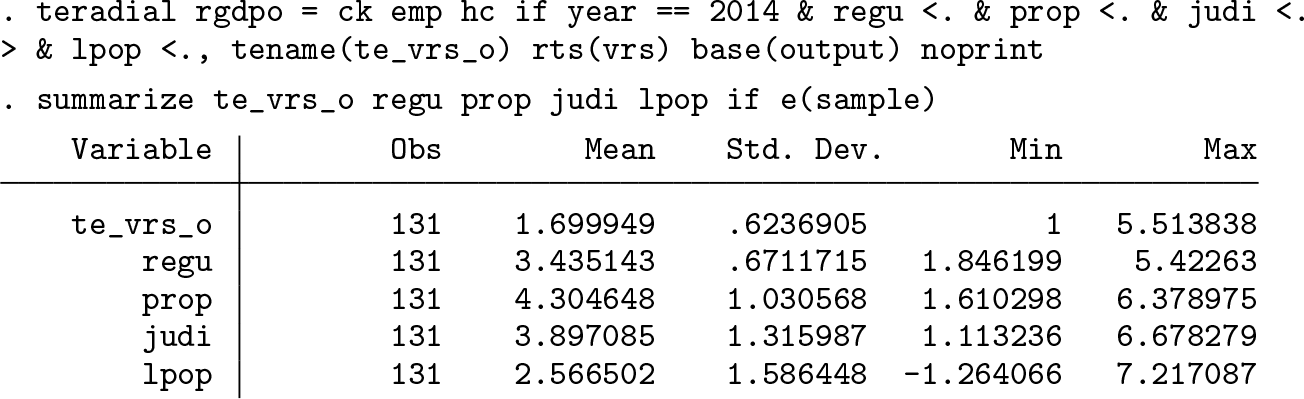
After loading the working data into Stata’s memory, we generate the explanatory variables that we actually need in the empirical analysis and give them more telling names. Because
quietly generate prop = EOSQ051[_n-1] if countrycode == countrycode[_n-1] quietly generate judi = EOSQ144[_n-1] if countrycode == countrycode[_n-1] quietly generate lpop = ln(pop[_n-1]) if countrycode == countrycode[_n-1]
Second, we use
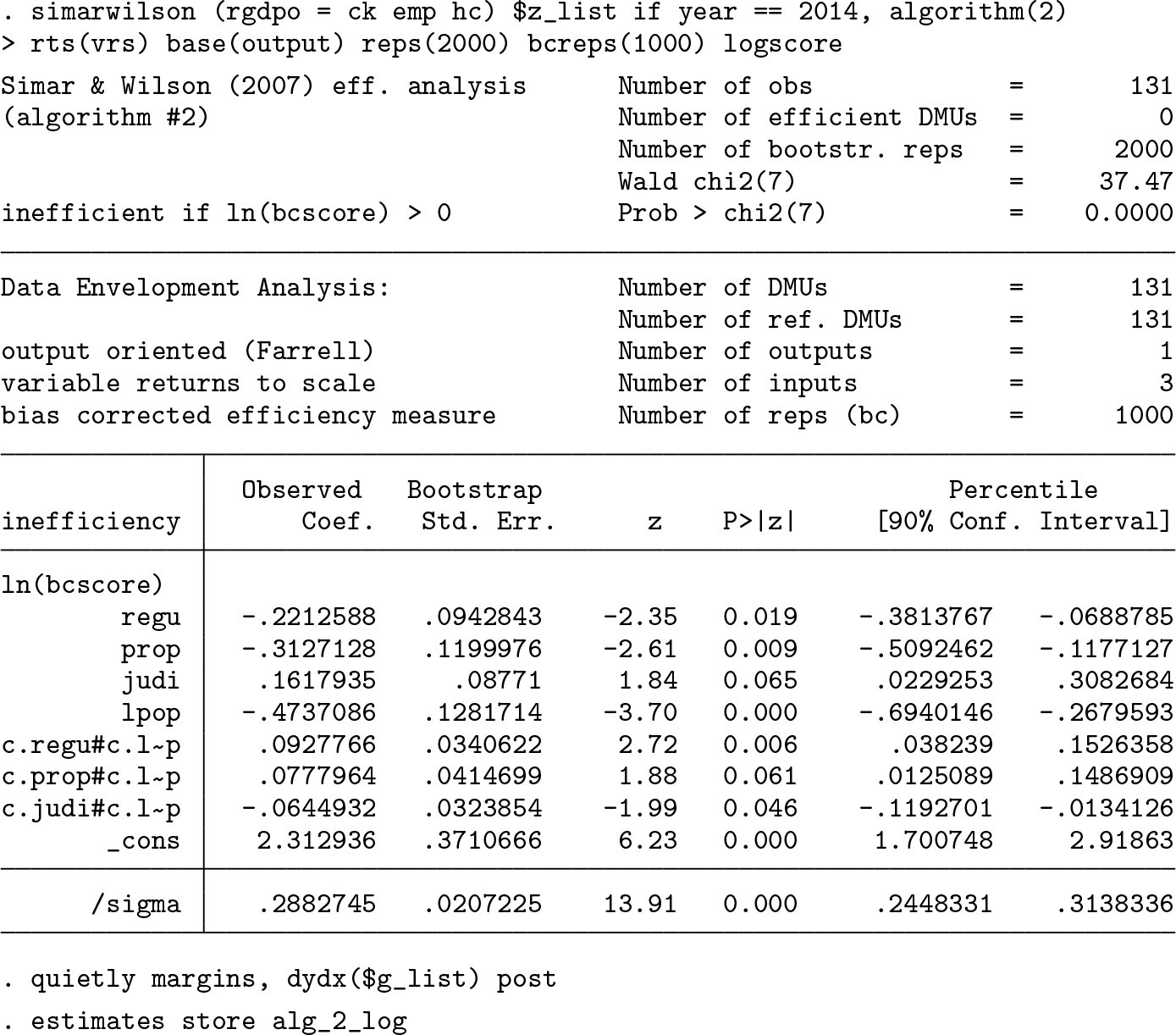
In the next step of the analysis, we use four empirical models to explain (in)efficiency in the GDP generation. Besides
We start with tobit estimation, which—according to Simar and Wilson (2007)— erroneously regards full efficiency (

Then, we turn to the truncated regression by using

Hence, in the next step, we turn to

Then, we turn to


To interpret the results qualitatively, we examine the estimated mean marginal effects. This yields a rather clear picture. While, on average, the regulatory burden and judicial independence appear to be immaterial for the efficiency of GDP generation, the protection of property rights matters. Except for

Measuring effects in terms of Farrell (output-oriented) efficiency units appears not to be particularly telling. Hence, one may prefer a scaled efficiency measure that allows for interpreting marginal effects in terms of percentage points. Thus, one may switch to the Shephard efficiency measure. Switching from outputto input-oriented efficiency, which would also yield efficiency scores within the unit interval, does not have much appeal for this application. It would imply the thought experiment of reducing input consumption, which appears rather odd given that the national capital stock and human capital are among the input variables.
While switching to the Shephard measure was straightforward for

One may force

To specify a model that renders interpreting estimation results in quantitative terms more convenient, one can use the option
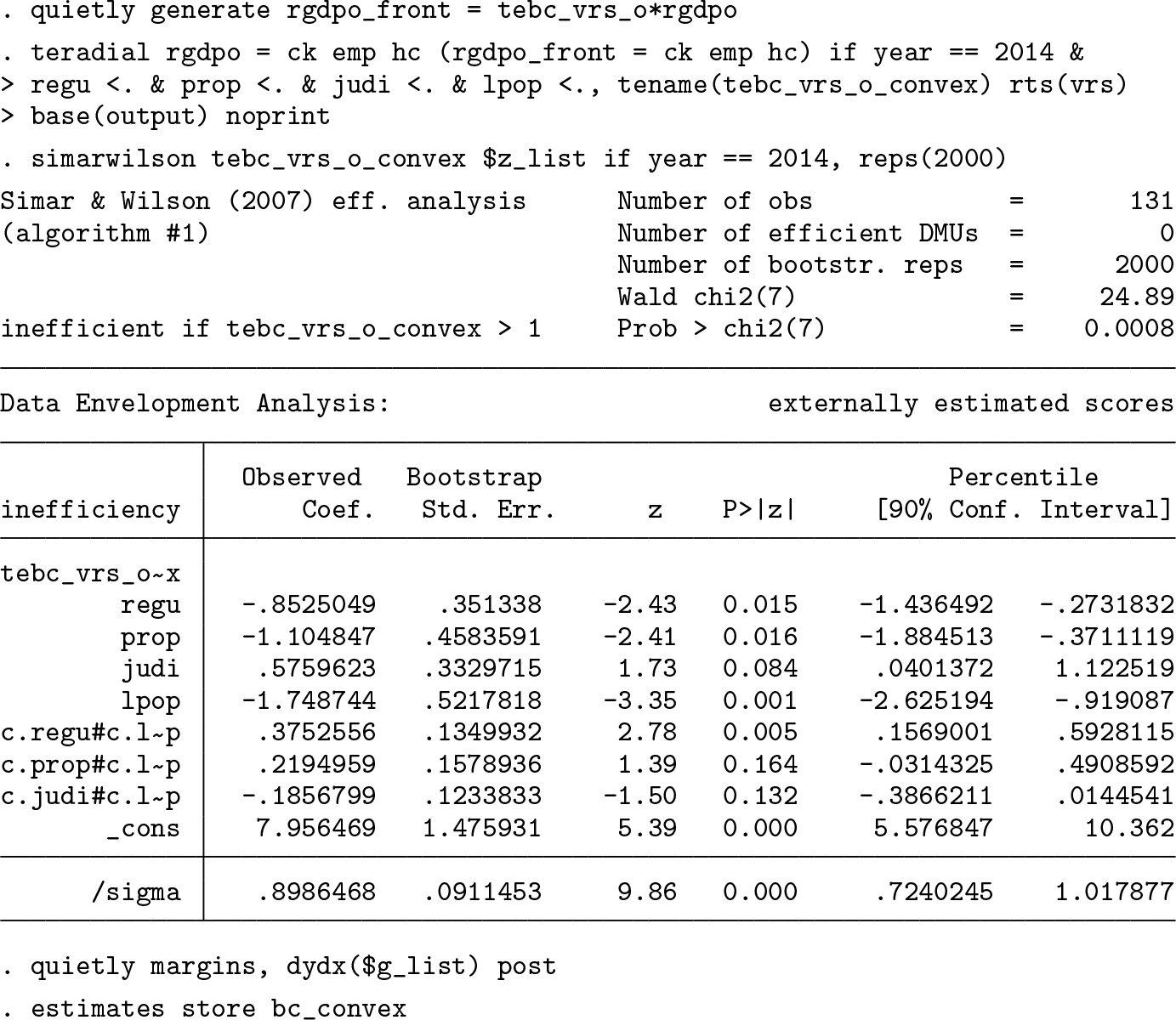
One may not feel comfortable with using a (bias-corrected) efficiency measure that conflicts with convexity of the production-possibility set; compare figure 1. One way of addressing this issue is to once again envelop the nonconvex bias-corrected estimated frontier with a convex hull and to use the distance to this convexified bias-corrected frontier as a dependent variable in the regression analysis (compare Badunenko, Henderson, and Russell [2013] and figure 5). The
Finally, we compare the marginal effects for all specifications of
Using the Shephard measure (option

4.2 Effect heterogeneity
We complete our application by analyzing possible heterogeneity in the efficiency effects of burden of government regulation, property rights protection, and judicial independence. In doing this, we focus on


Estimated marginal effects of governance-quality indices on inefficiency by country size (right panel) and its respective own value (left panel). NOTE: Farrell output-oriented efficiency as dependent variable; Simar and Wilson (2007), algorithm 2 used for estimation; 90% confidence bands indicated by shaded areas. SOURCE: Calculations are our own, based on Penn World Table and World Economic Forum Global Competitiveness Report data.
The left panel of figure 2 does not suggest that the effect heterogeneity with respect to the respective category of governance quality is a big issue, at least qualitatively. The effects of both the burden of government regulation and judicial independence on inefficiency are statistically insignificant at any level of
The overall picture is somewhat different for heterogeneity with respect to country size (figure 2, right panel). There the marginal effect of all three governance indicators exhibits substantial heterogeneity. While focusing on mean marginal effects suggested that the level of regulation was immaterial for national efficiency, considering effect heterogeneity challenges this finding. More specifically, figure 2 suggests that relaxing government regulation reduces inefficiency in small countries. Yet in big countries, it seems to exert a negative effect on national efficiency. This pattern corroborates our earlier hypothesis of regulatory burden being an ambiguous concept because in certain circumstances some regulation may be well required for efficient production. A similar pattern of heterogeneity is found for the effect of
4.3 The gciget command
As mentioned in section 4.1, importing the indices from the Global Competitiveness Report that we used in our empirical study is not straightforward. We have developed the new command
The syntax for
The user can optionally specify the varlist from the list of indices in the Global Competitiveness Report (see the Excel file
The following options are available:
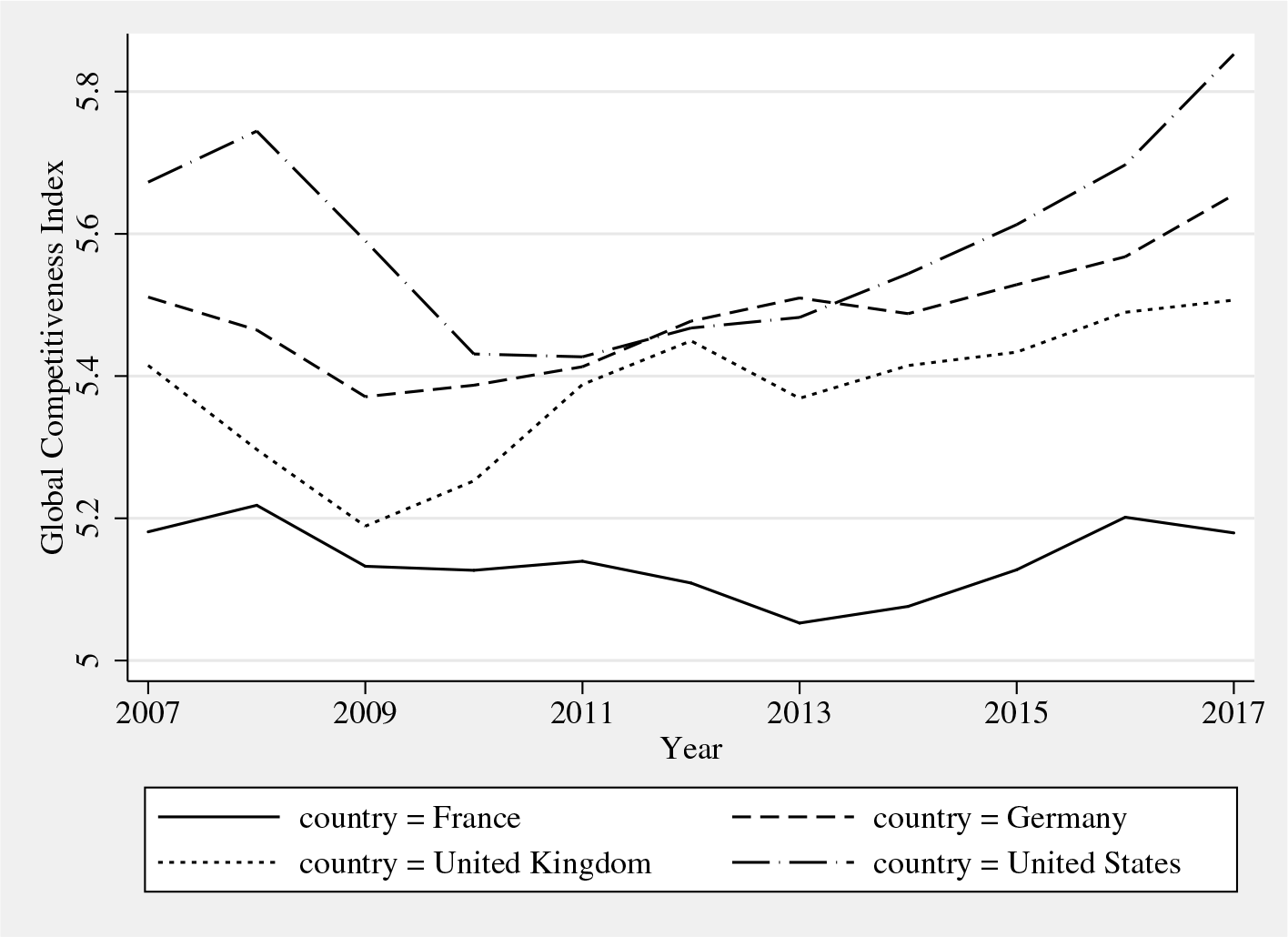
GCI for France, Germany, the UK, and the United States. Source: World Economic Forum’s Global Competitiveness Report.
5 Summary and conclusions
In this article, we introduced the new community-contributed command
8 Programs and supplemental materials
Supplemental Material, st0585 - Simar and Wilson two-stage efficiency analysis for Stata
Supplemental Material, st0585 for Simar and Wilson two-stage efficiency analysis for Stata by Oleg Badunenko and Harald Tauchmann in The Stata Journal
Footnotes
6 Acknowledgments
This work has been supported in part by the Collaborative Research Center “Statistical Modelling of Nonlinear Dynamic Processes” (SFB 823) of the German Research Foundation. The authors are grateful to Ramon Christen, Rita Maria Ribeiro Bastiao, Akash Issar, Ana Claudia Sant’Anna, Jarmila Curtiss, Meir José Behar Mayerstain, Erik Alda, Annika Herr, Hendrik Schmitz, Franziska Valder, Franz Josef Zorzi, Irina Simankova, Christian Merkl, Howard J. Newton, the participants of the 2015 German Stata Users Group meeting, and one anonymous reviewer for many valuable comments.
7 Supplementary figures
The figures below graphically illustrate the concepts of a restricted reference set (figure 4) and a convexified frontier ( Estimated inefficiency for subsample of DMUs used as reference. Considering only a subsample of DMUs as reference set renders DMU B seemingly superefficient, both according to conventional Convexified bias-corrected estimated frontier. Measuring inefficiency relative to the convexified bias-corrected frontier either does not affect estimated bias-corrected inefficiency (for example, DMU B) or increases estimated bias-corrected inefficiency (for example, DMU A). NOTE: Artificial data generated the same as figure 1. SOURCE: Calculations are our own.![]() ) that were referred to in this article, using the same artificial data that were used to illustrate DEA in figure 1.
) that were referred to in this article, using the same artificial data that were used to illustrate DEA in figure 1.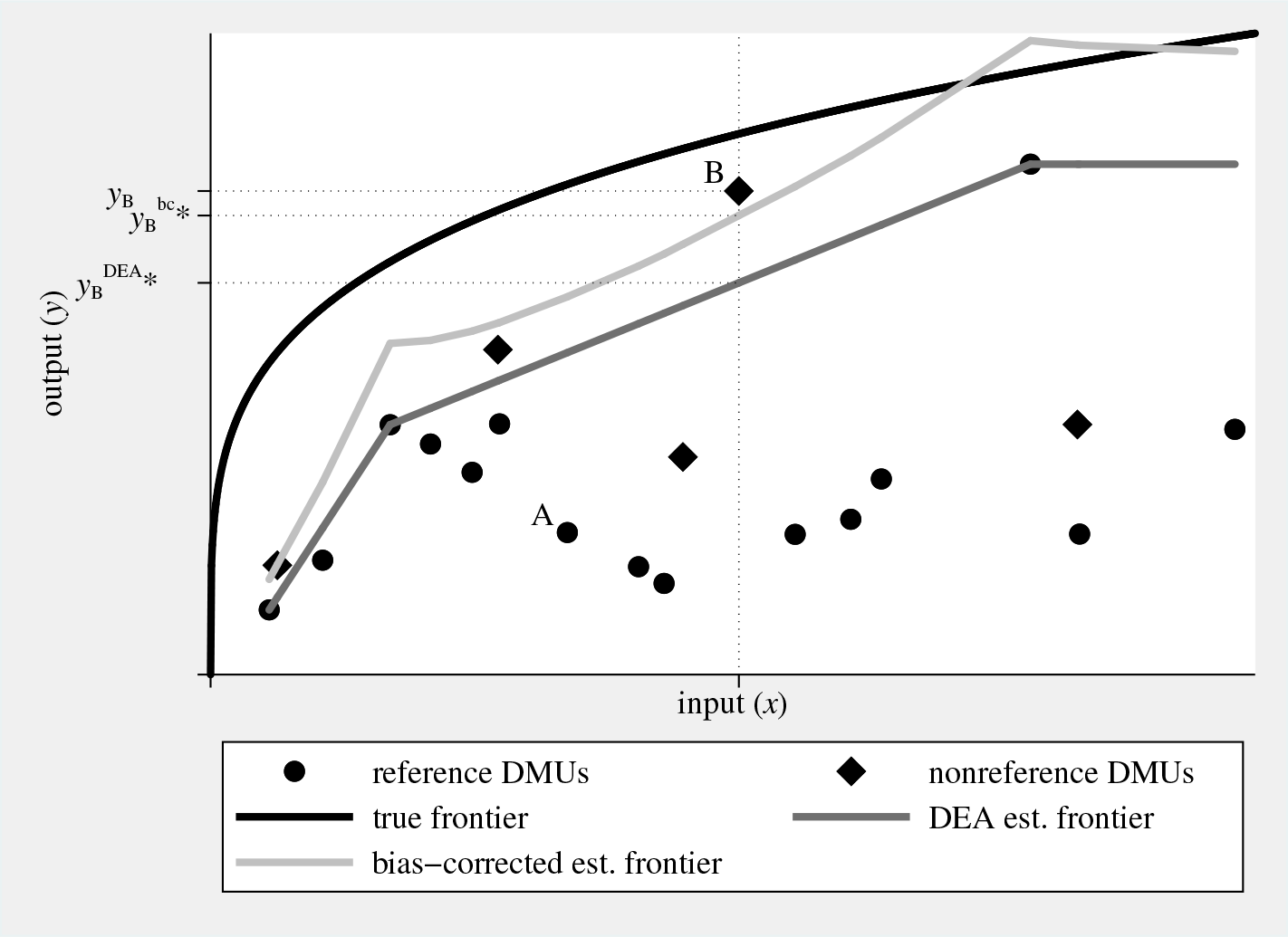

8 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.