
Abstract
In this article, I present the community-contributed
1 Introduction
Clustered survival data are often observed in many settings. Within medical research, a common example is the analysis of recurrent-event data, where individual patients can experience the event of interest multiple times throughout the follow-up period, and the inherent correlation within patients can be accounted for using a frailty term (Gutierrez 2002).
In the field of meta-analysis, applications of individual patient data meta-analysis to survival data are growing because it is recognized as the gold standard approach (Simmonds et al. 2005). Analyzing the individual patient data simultaneously within a hierarchical structure allows direct adjustment for confounders and incorporation of nonproportional hazards in covariate effects (Smith, Williamson, and Marson 2005; Crowther et al. 2012; Crowther, Look, and Riley 2014). Often, a random treatment effect is assumed to account for heterogeneity present in treatment effects across the pooled trials.
A further area of interest is relative survival. Particularly prevalent in cancer survival studies, relative survival allows the modeling of excess mortality associated with a diseased population compared with that of the general population (Dickman et al. 2004). Such data often exhibit a hierarchical structure with patients nested within geographical regions such as counties. Patients living in the same area may share unobserved characteristics, such as environmental aspects or medical care access (Charvat et al. 2016).
With the release of Stata 14 came the
In essence,
This article is arranged as follows. Section 2 describes the multilevel parametric survival framework and derives the likelihood used to fit the models, including the extension to relative survival models as well as left-truncation (delayed entry). Section 3 details the model syntax of
2 Multilevel mixed-effects survival models
For ease of exposition, I describe the methods in the context of a two-level model, but
2.1 Proportional-hazards parametric survival models
The proportional-hazards mixed-effects survival model can be written as
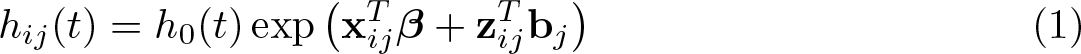
where h
0(t) is the baseline hazard function of a standard parametric model, such as the exponential, Weibull, or Gompertz distribution; a more general spline-based approach, such as using restricted cubic splines on the log-hazard scale (Bower, Crowther, and Lambert 2016); or even a user-defined function. I define design matrices
2.2 Flexible parametric models
An alternative to the standard proportional-hazards distribution is the flexible parametric model of Royston and Parmar (2002) modeled on the cumulative hazard scale, which has recently been extended to incorporate random effects by Crowther, Look, and Riley (2014). Therefore,

where H 0(t) is the cumulative baseline hazard function. The spline basis for this specification is derived from the log cumulative-hazard function of a Weibull proportional hazards model. The linear relationship with log time is relaxed through the use of restricted cubic splines. Further details can be found in Royston and Parmar (2002) and Royston and Lambert (2011). On the log cumulative-hazard scale, we have

where s(·) are our basis functions with knot vector

In this framework, I am assuming proportional cumulative hazards. However, this in fact implies proportional hazards as in the models described in section 2.1.
Nonproportional (cumulative) hazards
Relaxing the assumption of proportional hazards allows the investigation of whether the effect of a covariate changes with time. This is called nonproportional hazards or time-dependent effects, the occurrence of which is commonplace in the analysis of survival data. Examples include treatment effects that vary over time (Mok et al. 2009); in registry-based studies, where follow-up can be substantial, covariate effects have been found to vary (Lambert et al. 2011).
Nonproportional cumulative hazards have been incorporated into the flexible parametric framework by Royston and Parmar (2002), achieved by interacting covariates with spline functions of log time and including them in the linear predictor (Lambert and Royston 2009). This provides even greater flexibility in capturing complex effects that are not restricted to linear functions of time. Equation (2) becomes
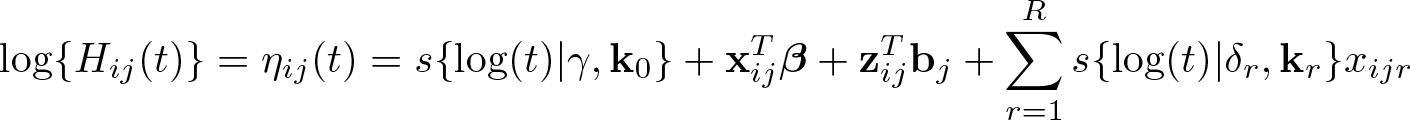
Each time-dependent effect can have a varying number of spline terms, depending on the number of knots,
Within
2.3 User-defined survival models
2.4 Relative survival
Relative survival allows us to model the excess mortality associated with a diseased population compared with that of the general population, matched appropriately on the main factors associated with patient survival, such as age and gender (Dickman et al. 2004). For a recent extensive description and implementation of the tools available for relative survival analysis in Stata, along with a description of the differing approaches, see Dickman and Coviello (2015) and references therein.
Concentrating on applications of relative survival to cancer settings, the data generally come from population-based registries. Such data often exhibit a hierarchical structure with patients nested within geographical regions such as counties. Patients living in the same area may share unobserved characteristics, such as environmental aspects or medical care access. Charvat et al. (2016) recently described a flexible relative survival model allowing a random intercept, with the baseline log-hazard function modeled with B-splines or restricted cubic splines. In this article, I extend the multilevel Royston–Parmar survival model described in Crowther, Look, and Riley (2014) and essentially any other hazard-based survival model to the relative survival setting, further allowing any number of random effects, including random coefficients. Modeling on the log cumulative-hazard scale avoids the need for numerical integration, which is required when modeling on the log-hazard scale with splines and will generally require fewer spline terms than when modeling on the log-hazard scale.
Within a multilevel modeling framework, I therefore define the total hazard at the time since diagnosis, t, for the jth patient in the ith cluster (area) to be h ij(t), with
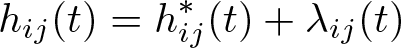
where
and our model is
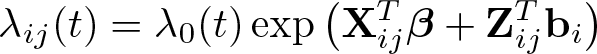
where λ 0(t) is the baseline hazard function with available choices including exponential, Weibull, Gompertz, spline based, or user defined.
Alternatively, I could model on the (log) cumulative excess-hazard scale using the flexible parametric model of Royston and Parmar (2002), where I define the total cumulative hazard at the time since diagnosis, t, for the jth patient in the ith cluster (area) to be H ij(t), with

where
and our model is

where Λ0(t) is the baseline cumulative hazard function modeled with restricted cubic splines.
2.5 Likelihood and estimation
Defining the likelihood for the ith cluster under the mixed-effects framework, we have

with parameter vector θ. Under a hazard-scale model,

with h(T ij) defined in (1). Under the flexible parametric survival model,

Finally, I assume the random effects follow a multivariate normal distribution
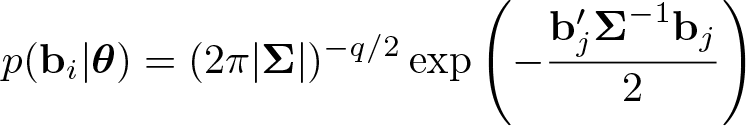
with variance–covariance matrix Σ and number of random effects q. The (possibly multidimensional) integral in (3) is analytically intractable, requiring numerical techniques to evaluate.
2.6 Relative survival likelihood
The adaptation to the likelihood in (3) to turn it into a relative survival model is relatively simple. All that is needed is the expected mortality rate at each event time, which is usually obtained from national or regional life tables. Under a hazard-scale model, (4) becomes

and under a cumulative hazard-scale model, (5) becomes

which provides substantial extensions to the relative survival literature.
2.7 Left-truncation and delayed entry
The addition of left-truncation and delayed entry within a random-effects survival setting raises a particular extra level of complexity. The random-effects distributions are defined at t = 0. As such, the left-truncation time point is conditional on each patient’s subject-specific random-effects contributions. For more details, I refer the reader to van den Berg and Drepper (2016). Our likelihood function becomes

where S(T 0 i|θ) is the marginal survival function at the entry time T 0 i, defined as

Thus, there are two sets of analytically intractable integrals to evaluate in (6), which increases computation time.
3 The stmixed command
3.1 Syntax
and the syntax of re_equation is
levelvar
3.2 Options
Model
Integration
[
Estimation
maximize options:
Reporting
4 stmixed postestimation
4.1 Syntax for obtaining predictions
4.2 Options
Note that if a relative survival model has been fit using the
5 Examples
In this section, I illustrate the command in two areas of research, namely, recurrent-events analysis and the individual participant data meta-analysis of survival data.
5.1 Recurrent event data
I consider the commonly used
I now fit a Royston–Parmar proportional hazards model with a normally distributed frailty, adjusting for age and gender:

Random effects are named with an
The model estimates a hazard ratio of 0.231 (95% CI: [0.088, 0.606]) for a female compared with a male of the same age and a nonstatistically significant age effect (note coefficients in the results table are log hazard-ratios). The estimated frailty standard deviation is 0.801 (95% CI: [0.411, 1.563]), indicating a highly heterogeneous baseline hazard function.
We can relax the assumption of proportional hazards by forming an interaction between a covariate of interest and a function of time.

Given the statistically significant interaction, we observe evidence of nonproportionality in the effect of
Predictions
A variety of predictions can be obtained following the fitting of a model. I can obtain the predicted survival function, shown in figure 1 with 95% CI, based on the fixed portion of the model for a 45-year-old female through use of the
which can be plotted by
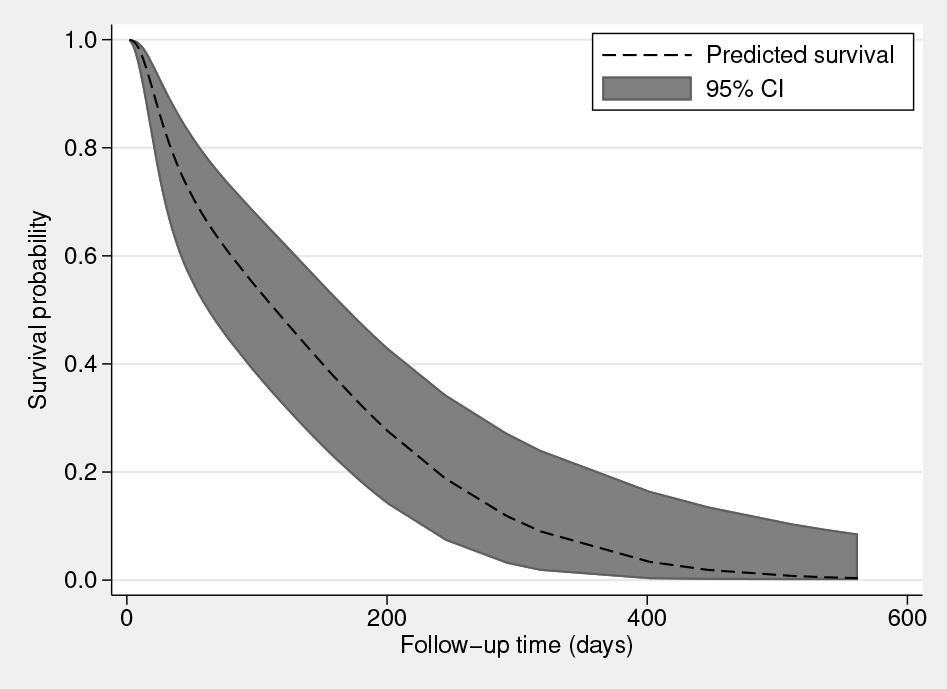
Predicted survival for a 45-year-old female based on the fixed portion of the model
To compare across covariate patterns—for example, to assess the impact of gender— we can predict restricted mean survival by typing
and plotting

Restricted mean survival for a male or female aged 45
Figure 2 shows restricted mean survival as a function of time for a male or female patient with the same age of 45. The impact of being female is shown clearly, indicating that females live substantially longer than males of the same age.
5.2 Individual participant data meta-analysis of survival data
In this example, I will illustrate a simple approach to simulating clustered survival data, in the setting of an individual patient data meta-analysis of survival data through use of the

A key trick to note here is that in the
In the
6 Conclusion
In this article, I introduced the
Given that
7 Programs and supplemental materials
Supplemental Material, st0584 - Multilevel mixed-effects parametric survival analysis: Estimation, simulation, and application
Supplemental Material, st0584 for Multilevel mixed-effects parametric survival analysis: Estimation, simulation, and application by Michael J. Crowther in The Stata Journal
Footnotes
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.