
Abstract
In this article, I describe a community-contributed command,
1 Introduction
Many survey variables are naturally nonnegative integer-valued counts, for example, the number of times an action or event has occurred within a given observation period. Count-data regression models based on distributions, such as the Poisson and negative binomial models, are widely used to analyze these variables.
But complications arise when survey questions are not designed to reveal the count exactly. Survey designers sometimes argue that questions may yield more reliable (albeit less detailed) data if they ask the respondent to place the count within one of a number of prespecified intervals, rather than to report a specific figure.
Interval observation of count data causes difficulty in the estimation of count-data regressions, because most available software requires the count to be observed exactly. Therefore, there is a need for estimation procedures that can account for coarse interval observation. 1 Furthermore, many types of descriptive or policy analysis require exact rather than interval counts, so some form of imputation or interpolation is required.
In this article, I describe a new command for interval estimation of a number of count-data models, and I report results from an illustrative application. Section 2 sets out the estimation approach and the range of available models. Section 3 details the syntax of
2 Interval-observed count-data models
2.1 Basic setup
Let Yi ≥ 0 be the ith observation on a dependent variable that takes nonnegative integer values. Yi may be bounded or unbounded. However, our observations are not on Yi itself but rather an interval in which Yi lies. Consequently, we have two observed dependent variables, [Li, Ui], with the property that

The numerical values of the interval bounds [Li, Ui] vary across observations, but they are assumed to be observed and strictly exogenous. The two bounds may be equal for some observations where Yi is fully observed, and, for unbounded distributions like the Poisson and negative binomial, the upper bound Ui may be infinite for some observations.
A set of explanatory covariates appears in a vector

The conditional probability of observing the event Li ≤ Yi ≤ Ui is

where F (Li − 1|
2.2 Alternative base distributions
The model is completed by specifying a parameterized functional form for the distribution function F (·|
The Poisson model is

where λi is the conditional mean function E (Yi|
The binomial model is
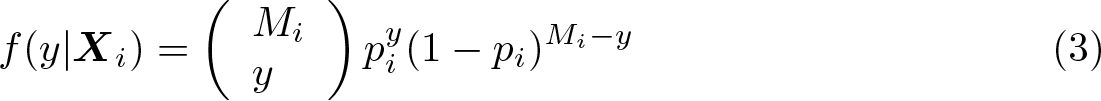
where Mi is the known maximum possible value, which may vary exogenously across observations, and pi is the binomial probability, parameterized as pi = (1 − e−
X
iβ)−1. The conditional mean function is E (Yi|
The negative binomial model is derivable as the Poisson-gamma mixture

where λi = eXi
β
, α > 0. This gives a distribution for y with mean λi and variance 1 + αλi. Note that, in the terminology of Cameron and Trivedi (2013), this is the NB2 parameterization of the negative binomial regression model and is consistent with the specification implemented in the Stata
2.3 Zero inflation
In some count-data applications, standard forms like the binomial, Poisson, and negative binomial are found to understate the frequency of zero counts. One way of dealing with this is to use a double hurdle or mixture process, where some individuals have a degenerate zero count with probability 1, while others have a count drawn from a standard distribution such as the Poisson.
Let the conditional probability of a degenerate zero be given by the linear index model

where

The probability of the observed interval [Li, Ui] is again given by (1).
The
standard model: π(
logit: π(
probit: π(
In practice, estimates of the logit and probit variants are usually almost identical apar
2.4 Estimation
Estimation is by maximum likelihood (ML), with probabilities of the form (1) used to construct the log-likelihood function. By default, numerical optimization of the log likelihood is carried out using Stata’s modified Newton–Raphson optimizer; other algorithms can be substituted if you have difficulty in obtaining convergence (see StataCorp [2017, 639–686] for details). Optimization is based on the
Experience to date suggests that this works well in most cases. Difficulties are most likely to be encountered with overspecified models involving zero inflation that is not required by the data, in which case one or more parameters in the coefficient vector γ will explode. Similar convergence Difficulties may be found also in zero-inflated specifications where zero inflation is required empirically for a group with certain values for the variables
Occasionally (usually in the more heavily parameterized zero-inflated specifications), the optimizer reaches a difficult region with almost flat likelihood or discontinuous approximate derivatives. Often, these problems can be resolved by passing down the estimates from a simpler specification as starting values for the optimization—for example, a model without zero inflation or with constant zero inflation or a Poisson model as a simpler alternative to the negative binomial.
2.5 Prediction and imputation
The estimates provided by
One is where we would like to use the unobserved variable Yi as a covariate in another model—for example, a regression of some dependent variable Wi on Yi and
Another common application is where exact values for Y are needed within some complex policy simulation. Again, multiple random draws Yi+ can be used in place of the unobserved Yi, and the policy calculations averaged across replications. The healthcare cost analysis by Davillas and Pudney (2019) is an example of this.
3 The intcount command
3.1 Syntax

3.2 Description
depvar1 and depvar2 are variables that specify the upper and lower limits Li and Ui of the interval containing the unobserved true count Yi. The covariates
3.3 Output
3.4 Options
At most, one of the options
3.5 predict
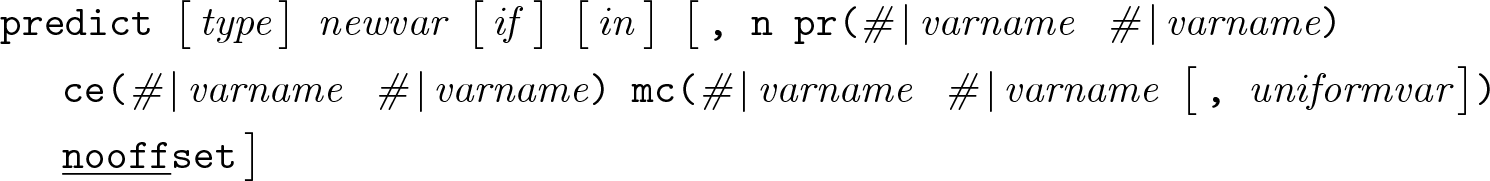
Description
Following
Options
ues) that the count lies in the interval defined by lower and upper limits that may each be a fixed number or a variable.
4 An application to healthcare demand
We apply the “In the last 12 months, approximately how many times have you talked to, or visited a GP or family doctor about your own health? Please do not include any visits to a hospital.” “And in the last 12 months, approximately how many times have you attended a hospital or clinic as an out-patient or day patient?”
Responses to these questions are reported as one of five intervals: 0, [1–2], [3–5], [6–10], 11 or more. Figure 1 shows the two empirical distributions.

Distributions of the number of GP and OP consultations in the preceding 12 months (UK Household Longitudinal Study [UKHLS wave 7; n = 6822])
The third question is “In the last 12 months, in all, how many days have you spent in a hospital or clinic as an in-patient?” Answers are given as “exact” integers.
The distribution of responses, shown in the first panel of figure 2 (here plotted over 0–10 days), is typical of count data for rare events. There is a large mode at zero and a highly skewed and dispersed distribution of positive values—the sample maximum is 182 days in this case. This distribution can pose challenging modeling and computational problems. The second panel of figure 2 shows the distribution after we artificially group the responses to conform with the reporting intervals used in the GP and OP questions. Note that ex post grouping should not be assumed to coincide automatically with the answer that would have been provided by the respondent given an interval response scale—respondent behavior may be influenced by question design.
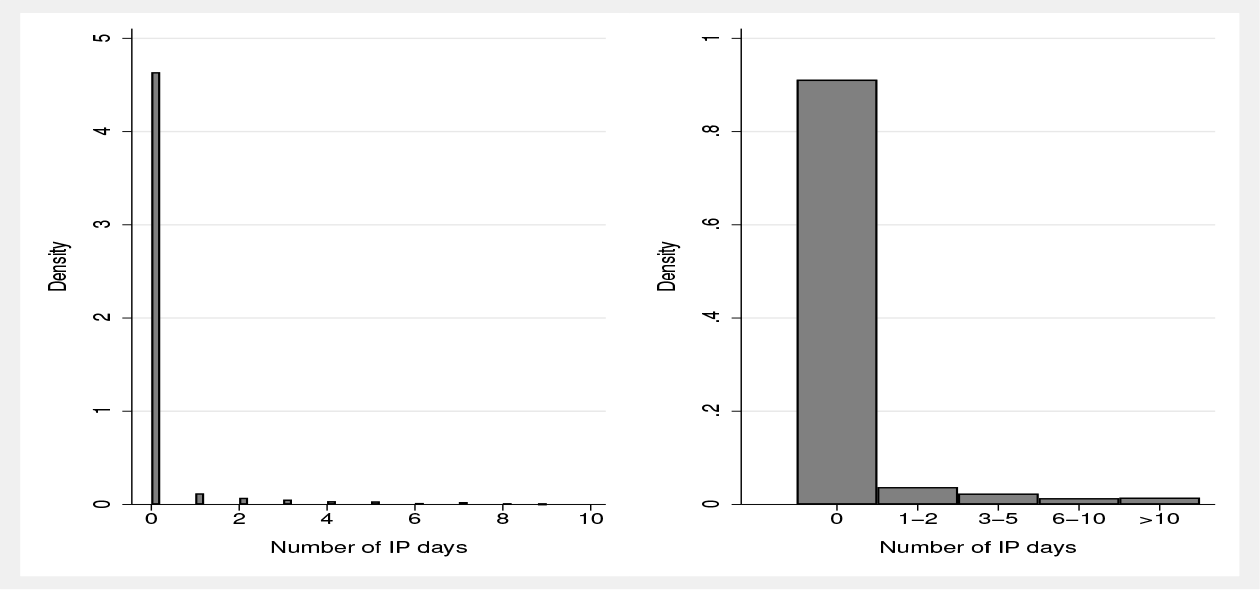
Distribution of the number of days as a hospital inpatient in the preceding 12 months, as observed and after grouping (UKHLS wave 7; n = 6824)
4.1 Hospital IP days: The effect of grouping
First, consider the choice of distributional form, using the original exact data. The

AIC and BIC for zero-inflated versions of Poisson, binomial, and negative binomial count-data models, estimated separately by gender from exact data on days spent in hospital

It is clear from table 1 that the negative binomial model is far superior in terms of sample fit to the Poisson and binomial models and also that zero inflation improves the fit substantially.
We now investigate the effect of data grouping by refitting the model using the artificially grouped form of the variable whose distribution is shown in figure 2. The code is as follows:

Table 2 compares the parameter estimates. There are substantial parameter differences, particularly for the age and education effects in the female sample.
Estimates of zero-inflated negative binomial model fit from exact and artificially grouped data

NOTES: § Age measured in decades from an origin of 50. Statistical significance: * = 10%, ** = 5%, *** = 1%
Figure 3 shows the implications of parameter differences for the estimated age profiles, plotting the probability of hospitalization Pr(y > 0|


Predicted age profile of zero-count probability by age for ethnic majority woman and man with midlevel education
The estimated age profiles remain broadly similar after grouping, but they display more variability for the estimates based on exact data, so coarsening the counts to interval form has a smoothing effect in this example.
It is also striking in this application that grouping has a perverse effect on the standard errors. It is clear theoretically that recoding count data to coarser interval form must reduce statistical precision of the parameter estimator for a well-specified count-data model (this is easily confirmed empirically using Monte Carlo simulation by applying
4.2 Interpolated healthcare measures
The
Estimates of negative binomial models for counts of GP and hospital OP consultations, estimated from grouped data

NOTES: § Age measured in decades from an origin of 50. Statistical significance: * = 10%, ** = 5%, *** = 1%
We now compare two interpolation methods. If the observed interval is [Li, Ui], the conditional expectation predictor of the unobserved true count is E(y|

The distributions for the interpolated GP and OP counts are shown in figures 4 and 5; the

Distributions of GP consultation count with conditional expectation and Monte Carlo interpolation

Distributions of OP consultation count with conditional expectation and Monte Carlo interpolation
Use of the

Means and standard deviations of GP and hospital OP consultations interpolated by alternative methods

NOTES: Group-specific standard deviations in square brackets.
4.3 Determinants of future healthcare demand
The UKHLS is a perpetual panel, and, in addition to healthcare use in wave 7, we can also observe a range of health measures and other characteristics at the wave 2 baseline. We use this rather than wave 1 as the baseline because a range of objective measurements was made by nurse interviewers at wave 2.
Our analysis dataset covers demographic covariates (age, gender); indicators of socioeconomic status (homeownership, log equivalized household income, education); and biometrics (waist–height ratio, grip strength, resting heart rate, lung function, HDL “good” cholesterol, hypertension). We fit standard negative binomial models from the interval data on GP and OP consultations. The following code produces three variants of the model for each dependent variable, and the parameter estimates are shown in table 5:

5-year-ahead predictive models of healthcare use

NOTES: § Age measured in decades from an origin of 50. Statistical significance: * = 10%, ** = 5%, *** = 1%
There is little evidence of a predictive role for socioeconomic status variables when the biometrics are included in the model, so we adopt variant (2), which uses only demographic and biometric covariates. Among the biometrics, only waist–height ratio and grip strength have a consistently significant impact, and the following code uses the

5 Conclusions
Survey count data often come in interval form rather than exact counts. It is common for ad hoc methods to be used for modeling such data—for example, regression applied to midpoint interpolations, or ordered probit regression that does not exploit the known interval limits or the count nature of the data. In this article, I presented a new command,
I illustrated the use of
7 Programs and supplemental materials
Supplemental Material, st0571 - intcount: A command for fitting count-data models from interval data
Supplemental Material, st0571 for intcount: A command for fitting count-data models from interval data by Stephen Pudney in The Stata Journal
Footnotes
6 Acknowledgments
I am grateful to Apostolos Davillas for help with preparing data from Understanding Society, which is an initiative funded by the Economic and Social Research Council and various government departments, with scientific leadership by the Institute for Social and Economic Research, University of Essex, and survey delivery by NatCen Social Research and Kantar Public. The research data are distributed by the UK Data Service. This work was supported by the Economic and Social Research Council through the project How can biomarkers and genetics improve our understanding of society and health? (grant ES/M008592/1), the Centre for Micro-Social Change (grant ES/L009153/1), and the Understanding Society study (grant ES/K005146/1). I am extremely grateful to the editors and an anonymous reviewer for comments that have greatly improved the code and its presentation in this article. The views expressed in this article, and any errors or omissions, are mine alone.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.