
Abstract
We introduce a command,
Keywords
1 Introduction
Various national and international institutions, including the United Nations (Leadership Council of the Sustainable Development Solutions Network 2015) and the Organisation for Economic Co-operation and Development (Piacentini 2014), collect comprehensive indicator sets for monitoring purposes. Many indicators refer to subnational areas or domains: federal states, economic sectors, societal groups, etc.
In the socioeconomic context, domain-level indicators are usually derived from population surveys by direct estimation. Direct estimates are based only on the survey data, so small sample sizes can limit their precision. Thus, institutions that provide these indicators usually require a minimum number of observations per domain or impose limits on the variability of the estimates (Eurostat 2013; Tzavidis et al. 2018). Further more, direct estimates cannot be obtained for out-of-sample domains, that is, domains without any observation in the sample.
Small-area estimation techniques use auxiliary data from additional data sources to improve the precision of survey-based direct estimates. Two basic model types can be distinguished: unit- and area-level models. Unit-level models require survey and auxiliary data at the unit level, that is, individual- or household-level information in each domain. Examples are the model proposed by Battese, Harter, and Fuller (1988) and the empirical best predictor by Molina and Rao (2010). In comparison, area-level models, such as the Fay–Herriot (FH) model (1979), 1 require only domain-level auxiliary data, hence their popularity in applied research.
estimation of the FH model as described in Rao and Molina (2015, 123–129) with restricted maximum likelihood (REML) and maximum likelihood estimation (MLE) of the variance of the random effects, estimation of the mean squared error (MSE) as proposed in Datta and Lahiri (2000) and Prasad and Rao (1990), prediction and MSE estimation for out-of-sample domains (Rao and Molina 2015, 126 and 139), estimation with adjusted methods as proposed in Li and Lahiri (2010) and Yoshimori and Lahiri (2014) to deal with nonpositive estimates of the variance of the random effects, estimation of the log-transformed FH model including a bias correction by Slud and Maiti (2006) to deal with violations of model assumptions, for example, non normality of the error terms, and estimation of the FH model for proportions defined on the [0, 1] interval, that is, with the dependent variable transformed by the arcsine square root transformation. The back-transformation and the corresponding boundaries of a bootstrap confidence interval following Casas-Cordero Valencia, Encina, and Lahiri (2016, 394–397) and Schmid et al. (2017, 1173–1177) are provided.
2 The FH model
2.1 Modeling
The FH model (Fay and Herriot 1979) combines domain-level direct estimates (based on survey data) with aggregated domain-level covariates (for example, from register or administrative data). The direct estimator should be a linear statistic such as an arithmetic mean, total, or share.
The FH model builds on a sampling and a linking model. According to the sampling model,

the observed direct estimator for domains
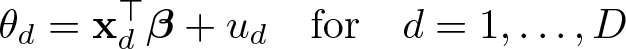
the true value, θd
, is explained by the domain-specific covariates,
Combining the sampling and the linking models gives the FH model, which is a linear mixed model of the form

The FH estimator (EBLUP) is given by

The estimate
For out-of-sample domains,
2.2 Estimating the variance of the random error
The FH model requires an estimation of the variance of the random error,
Adjusted estimation methods, such as the adjusted maximum residual-likelihood approach (ARYL) following Yoshimori and Lahiri (2014) and the adjusted maximum-profile likelihood (AMPL) following Li and Lahiri (2010), ensure strictly positive variance estimates.
2.3 Evaluating the precision
The precision of the EBLUP is evaluated by means of the MSE, defined as

Because the true value θd
is unobserved, MSE(
2.4 Dealing with model-assumption violations
The FH model assumes linearity and normality of its two error terms. If there is a violation of these assumptions, a log-transformation of the direct estimator might be an option (Slud and Maiti 2006). Choosing this option requires an appropriate transformation of the variance of the original direct estimator. 3 Neves, Silva, and Correa (2013) suggest the transformation,

with ∗ indicating the transformed scale.
Equation (1) is estimated using

with ∗ indicating the transformed scale.
The Slud–Maiti back-transformation relies on MLE for the estimation of
For estimating the precision of the back-transformed EBLUPs, Slud and Maiti (2006, 248) developed an MSE estimator when using the log-transformation. The crude method uses the estimates in the transformed scale and the following back-transformation:
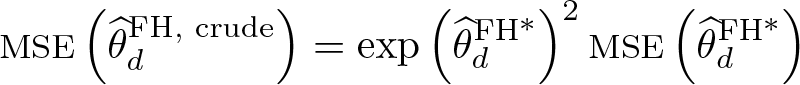
2.5 Overview of functionalities
Figure 1 gives an overview of the functionalities of the
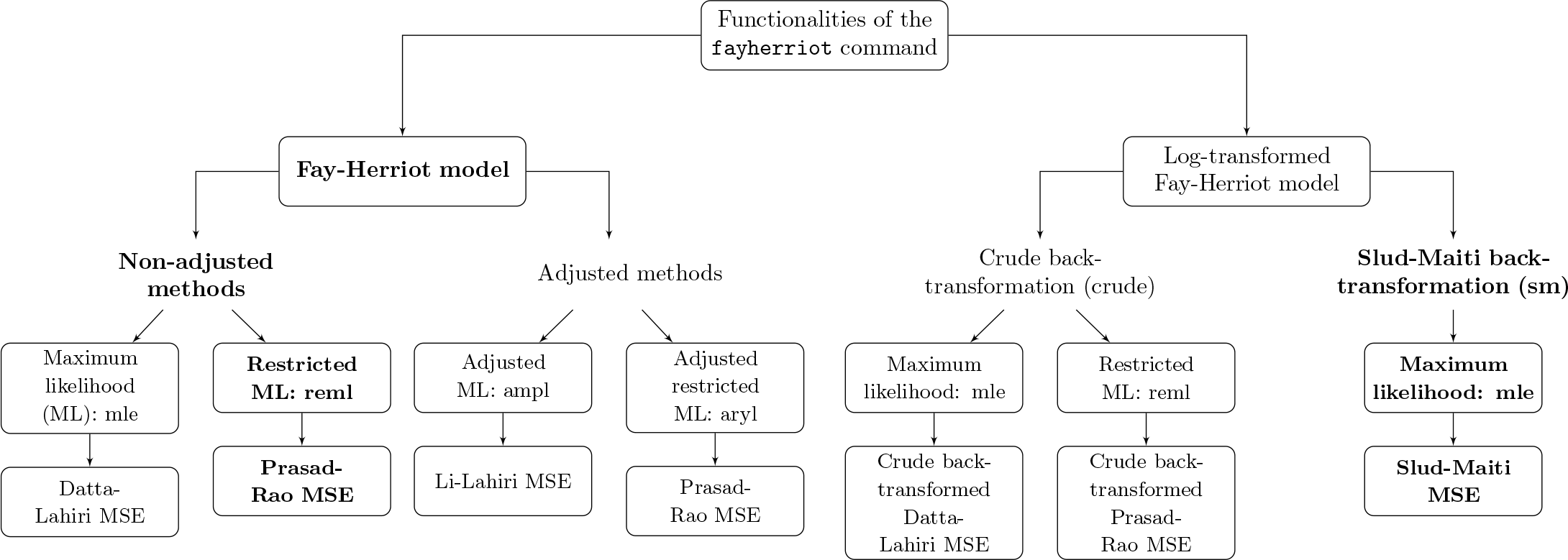
Functionalities of the
3 The fayherriot command
3.1 Syntax
The command runs on datasets on the domain level with one observation per domain. depvar is the direct estimate,
3.2 Options for fayherriot
3.3 predict after fayherriot
Syntax
The syntax for
Options
3.4 Stored resultssss

4 Example
We use the FH model to estimate households’ material well being in 2015 in Germany: at the level of federal states (16 divisions), planning regions (96 divisions), and districts (402 divisions). Material well being is defined as region-specific average equivalent income, that is, household disposable income divided by the Organisation for Economic Co-operation and Development modified scale (Hagenaars, de Vos, and Zaidi 1994).
Following the policies used by several statistical agencies to evaluate the precision of the regional estimates, we rely on the CV, which is the standard error of the estimate divided by the estimate (in percent). For instance, Statistics Canada releases data without warning about low precision if the CV is below 16.5% (Statistics Canada 2013; Eurostat 2013).
4.1 Data description and direct estimates
We derive the direct estimates from the German Socio-Economic Panel (SOEP), which is a household survey covering about 15,000 households per year (Goebel et al. 2019).
Table 1 provides the division-specific numbers of SOEP households. Sample sizes by federal states are large (median: 624), ranging from 114 to 3,159 observations. Sample sizes by planning regions are considerably smaller (median: 132), ranging from 32 to 665 observations. Sample sizes by districts range from 10 to 648 observations (median: 32). 4 Because of small sample sizes, we expect that many direct estimates for planning regions and districts are measured with high imprecision.
Number of regions and sample sizes

Note: Data are from SOEP v33.1. Computations are our own.
For each regional level, table 2 provides direct estimates of mean equivalent income and coefficients of variation, our precision indicator. 5 The table suggests considerable regional heterogeneities in material well being. Across federal states, mean equivalent income ranges from €1,362 to €1,863; across planning regions, from €1,298 to €2,101; and across districts, from €1,023 to €2,976. As expected, coefficients of variation increase as we move to smaller regional levels. In line with the policy of Statistics Canada, not all estimates could be reported for the planning regions and the districts without warning of low precision. In the following, we show how this can be achieved using the FH model. In particular, we can a) improve the precision of all estimates and b) receive estimates for the districts without a direct estimator.
Summary of mean equivalent household income and coefficients of variation by regional level

Note: Data are from SOEP v33.1. Computations are our own.
4.2 Estimation using fayherriot
For fitting the FH model, we rely on the direct estimates of average equivalent incomes (table 2); their sampling error variances,
FH model for the planning regions
In the following, we detail the application of

To fit the FH model, we type

The syntax of the command is inline with the familiar Stata regression syntax:
The variance of the random effects,
Log-transformed FH model for the districts
In the district-level analysis, not all regions are sampled, and the normality assumption of the model is violated. Hence, we log-transform equivalent incomes and the variances of the sampling error,

and fit the log-transformed FH model:
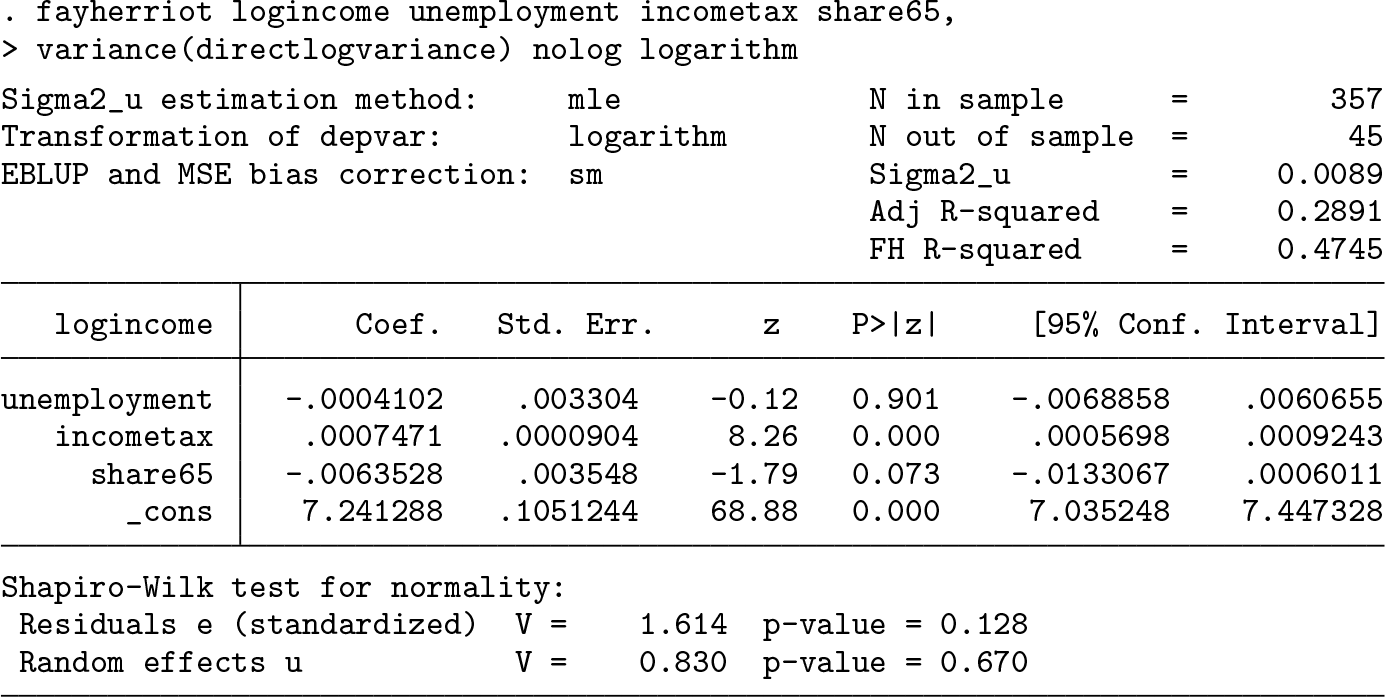
By specifying the
4.3 Comparison of direct and FH estimates
Next we compare the direct with the FH point estimates (EBLUP) and assess their precision. There are two equivalent ways to obtain the EBLUPs and their level of precision (MSE). The first is specifying the . fayherriot income unemployment incometax share65, > variance(directvariance) nolog eblup(eblupROR) mse(mseROR)
The second is using the postestimation . predict eblupROR, eblup . predict mseROR, mse
An additional feature of . predict cvROR_FH, cvfh . predict cvROR_direct, cvdirect
To assess the magnitude of adjustments, figure 2 presents the ratios of EBLUPs and direct estimates against region-specific sample sizes. 7 For federal states, the ratios are all close to 1, suggesting small adjustments of the direct estimator. For planning regions and districts, adjustments are larger, which is an expected result given smaller sample sizes of these domains.

Ratio of the EBLUP to the direct (income) estimates plotted against regional sample sizes for all three regional divisions—federal states, planning regions, and districts. Only in-sample domains are plotted. Data are from SOEP v33.1. Computations are our own.
To assess the gain in precision, figure 3 provides box plots of coefficients of variation for the direct and FH estimates. The horizontal line indicates the threshold of 16.5 suggested by Statistics Canada. For the direct estimates, several CVs at the district and planning region levels exceed the threshold. For the FH estimates, in contrast, CVs for all regional levels are under the threshold.

Box plots of the distribution of the coefficients of variation for the federal states, the planning regions, and the districts. The horizontal line indicates the precision threshold of 16.5%. Only in-sample domains are plotted. Data are from SOEP v33.1. Computations are our own.
5 Conclusion
We implemented the FH model in Stata. It is a small-area estimation technique and aims at improving the precision of direct estimators from a survey by using additional domain-level covariate information. We introduced the
7 Programs and supplemental materials
Supplemental Material, st0570 - The fayherriot command for estimating small-area indicators
Supplemental Material, st0570 for The fayherriot command for estimating small-area indicators by Christoph Halbmeier, Ann-Kristin Kreutzmann, Timo Schmid and Carsten Schröder in The Stata Journal
Footnotes
6 Acknowledgments
Halbmeier and Schröder thank Johannes König for his valuable remarks and comments, as well as Paul Brockmann, Deborah Anne Bowen, and Fabian Nemeczek for excellent research assistance. Kreutzmann and Schmid gratefully acknowledge support by the German Research Foundation within the project QUESSAMI (281573942) and the MIURDAAD Joint Mobility Program (57265468). We thank the editor and the referee for their constructive comments that helped to improve the article.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.