
Abstract
Statistical methods that quantify the discourse about causal inferences in terms of possible sources of biases are becoming increasingly important to many social-science fields such as public policy, sociology, and education. These methods are also known as “robustness or sensitivity analyses”. A series of recent works (Frank [2000, Sociological Methods and Research 29: 147–194]; Pan and Frank [2003, Journal of Educational and Behavioral Statistics 28: 315– 337]; Frank and Min [2007, Sociological Methodology 37: 349–392]; and Frank et al. [2013, Educational Evaluation and Policy Analysis 35: 437–460]) on robustness analysis extends earlier methods. We implement these recent developments in Stata. In particular, we provide commands to quantify the percent bias necessary to invalidate an inference from a Rubin causal model framework and the robustness of causal inferences in terms of correlations associated with unobserved variables.
Keywords
1 Introduction
Statistical inferences are often challenged on their uncontrolled bias. There may be bias due to uncontrolled confounding variables or nonrandom selection into a sample. Methods for sensitivity analysis have been developed to assess the robustness of inferences to various sources of bias and inform debate about causal inference. However, most of the previous methods either accounted only for particular sources of bias (such as an unobserved variable) or applied only to certain types of data (such as the categorical treatment variable; see DiPrete and Gangl [2004]; Gill and Robins [2001]; Robins [1987]; Robins, Rotnitzky, and Scharfstein [2000]; Rosenbaum [1986, 2002]; Scharfstein and Irizarry [2003]; VanderWeele [2010]; and VanderWeele and Arah [2011]). In a series of articles (Frank [2000]; Pan and Frank [2003]; Frank and Min [2007]; and Frank et al. [2013]), researchers have extended previous work and developed two robustness-analysis frameworks. The first uses Rubin’s causal model to interpret how much bias there must be to invalidate an inference in terms of replacing observed cases with counterfactual cases or cases from an unsampled population. The second quantifies the robustness of causal inferences in terms of correlations associated with unobserved variables in a regression framework.
In this article, we introduce the
2 Robustness of an inference
2.1 Impact threshold for an omitted confounding variable
In observational studies and quasiexperiments, a key concern pertaining to causal inference is the omitted variable bias problem. That is, there are some unobserved confounding variables that may be correlated with both the outcome and the predictor of interest, which will bias the estimates of the model and thus invalidate inferences. To quantify the impact of a confounding variable necessary to alter a statistical inference, Frank (2000) defined the impact of a confounding variable as rx · cv ry · cv, where rx · cv is the correlation between the unobserved confound and the predictor of interest and ry · cv is the correlation between the unobserved confound and the outcome. For example, if the relationship of interest is between one’s father’s occupation (X) and one’s own educational attainment (Y ), an omitted confounding variable might be one’s father’s education (cv). And the index developed by Frank (2000) allows us to quantify the impact of father’s education in terms of its correlation with the predictor father’s occupation and its correlation with the outcome—educational attainment. Frank (2000) then shows how strongly an omitted confounding variable (cv) would have to be correlated with the predictor (father’s occupation, X) and the outcome (educational attainment, Y ) to invalidate an inference of the effect of X on Y

The impact of a confounding variable on a regression coefficient
Formally, the calculations follow a partial correlation framework (for more details, see Frank [2000] and Pan and Frank [2004]). For a bivariate regression,
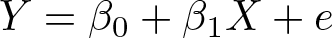
the correlation between X and
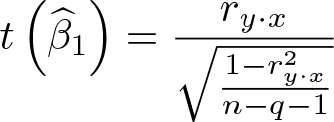
where t is the t ratio of
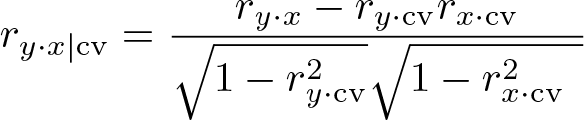
To invalidate an inference, we consider the conditions necessary to reduce

To calculate the correlations associated with an omitted confounding variable necessary to invalidate an inference, assume the component correlations are equal,

and then solve for impact:

Thus, to invalidate the inference, the impact of the confounding variable

Furthermore, the approach also applies to estimated coefficients that are less than their thresholds,

Thus, (1) quantifies the smallest impact of the confounding variable necessary to invalidate a statistical inference based on the threshold, r#. 1
The above calculations can also be extended to models that control for observed covariates as in multiple regression, where the interpretation of the impact and the correlation can be conditioned on other covariates in the model. In the multiple regression case, the raw component correlation before conditioning on covariates can also be derived; interested readers should see Frank (2000). This is available in the
2.2 Percent bias necessary to invalidate an inference
A second approach starts by assessing what proportion of an estimate must be due to bias to invalidate an inference (Frank et al. 2013). The proportion is then interpreted in terms of the proportion of observed cases that would have to be replaced with null hypothesis cases to invalidate the inference. These replacement cases can come from counterfactual data as in Rubin’s causal model (Rubin 1974) or from a population from which observed cases were not sampled. This framework enables researchers to identify a “switch point” (Behn and Vaupel 1982) where the bias is large enough to undo one’s belief about an effect (for example, from inferring an effect to inferring no effect). Using the switch point, this framework addresses the concerns pertaining to external validity (such as the extent to which the sampling process has to be biased to invalidate the inference) or concerns pertaining to internal validity (such as the extent to which bias because of uncontrolled preexisting differences can invalidate the inference of the treatment effect).
The approach begins when one compares an estimate with a threshold to represent how much bias there must be to switch the inference. For example, consider figure 2, in which the treatment effect from hypothetical study A (with an estimated effect of 6) and B (with an estimated effect of 8) each exceeds the threshold for making an inference of 4. But note that the estimated effect from study B exceeds the threshold by more than the estimate from study A (assuming that the estimates were obtained with similar levels of control for selection bias in the design of the study and similar levels of precision). Therefore, we state that the inference from study B is more robust than that from study A because a greater proportion of the estimate from study B must be due to bias to invalidate the inference.

Percent bias necessary to invalidate an inference
To formally derive the percent bias necessary to invalidate an inference, define a population effect as δ, the estimated effect as
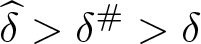
To express how much bias there must be in the estimate to invalidate the inference, we can rewrite the above equation as

Let’s define bias as bias

For example, in the hypothetical study A in figure 2, percent bias to invalidate the inference = 1 − (4/6) = 1/3. Thus, 33% of the estimate would have to be due to bias to invalidate the inference. In study B, 1 − (4/8) = 50% of the estimate would have to be due to bias to invalidate the inference. Readers should also see Frank et al. (2013) and Frank and Min (2007) for other extensions and more details of the derivations following the Rubin causal model.
3 The konfound command
3.1 Syntax
3.2 Description
3.3 Options
3.4 Example
To illustrate the use of the
First, we will regress the outcome on all the independent variables:
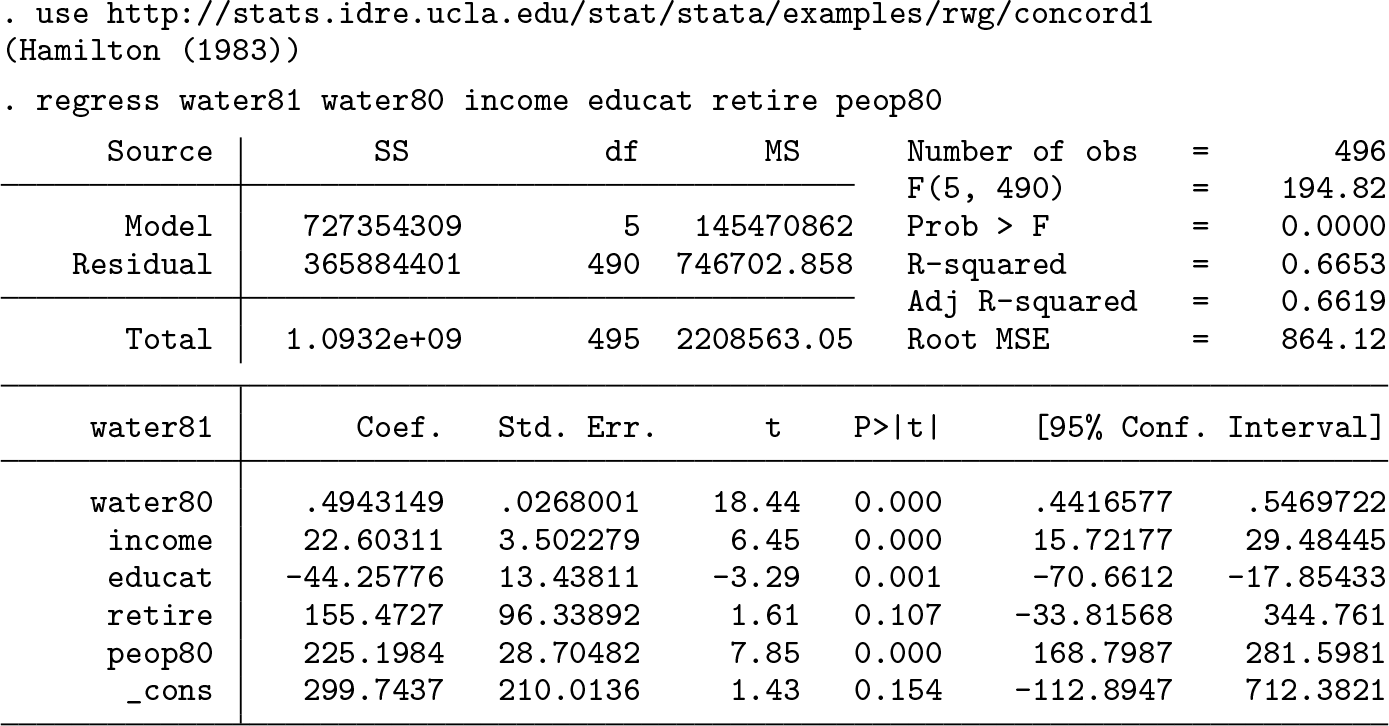
The estimated effect of the number of people in the household (

The first table is based on unconditional correlations. The second table is based on partialled correlations.
The first part of the output calculates the percent bias needed to invalidate the inference for

Percent bias to invalidate the inference for the effect of
The second part of the output calculates the impact of an omitted variable necessary to invalidate or sustain an inference. First, it shows the impact (0.2697) and the component correlations (0.519) between the omitted variable and the outcome (
Next, two observed impact tables are shown. For each observed covariate in the model, the first table contains its correlation with the predictor of interest (

Visualization of the impact of an omitted confounding variable on the partial correlation between
Finally, note several things: First-time users of Users must run the original regression each time before applying the Bar graphs are generated only for variables that are statistically significant. Users can evaluate the robustness of inference for multiple variables at the same time; in the previous example, to evaluate the robustness of inference of two variables—
The previous example illustrates how the
The next example we use comes from Hamilton (1992), which is from survey data concerning toxic waste in Williamstown, Vermont (Hamilton 1985). The outcome of interest is a dichotomous variable indicating whether the respondent believed the contaminated school should be closed (
First, we run a logistic regression using

The results show that the estimated effect of


Percent bias necessary to invalidate the inference for the effect of
Results show that to invalidate the inference, 70.5% (108) cases would have to be replaced with cases for which there is an effect of 0. The calculation is based on average marginal effects instead of on the original coefficient; in this case, the inference is more robust compared with the calculation based on the original coefficient, which would be 58.23% (89). 4
4 The mkonfound command
4.1 Syntax
4.2 Description
4.3 Options
4.4 Example
To illustrate the use of the

Next, we calculate the percent bias necessary to invalidate or sustain the inference and impact threshold for omitted variables using the

To calculate the impact threshold for omitted variables,
To calculate the percent bias necessary to invalidate or sustain the inference, the command
5 The pkonfound command
5.1 Syntax
5.2 Description
The user must input four numbers. The first number is the estimated value of the effect (for example, the estimated regression coefficient); the second number is the standard error of the estimated effect (regression coefficient); the third number is the sample size; the fourth number is the number of covariates in the model.
5.3 Options
5.4 Example
To illustrate the use of the

Similarly to the
6 Examples of publishable write-ups
To facilitate the interpretation of the robustness analysis, here we provide some examples of publishable write-ups for correlation-based and case replacement-based robustness analysis. The example of the correlation-based approach comes from Frank et al. (2008), where the main focus is on whether teachers certified by the National Board of Professional Teaching Standards (NBPTS) provide more instructional help to other teachers: While we may be close to exhausting our ability to reduce bias that can be attributed to confounding variables measured in our data, we use Frank’s (2000) indices to quantify how much the impact of an unobserved confound must be to invalidate the inference that NBPTS certification affects the number of others a teacher helps with instructional matters. Here we base the analysis on the estimate and inference using propensity weighting to estimate the EOTM, the most conservative of the estimates that used the full sample and controlled for covariates. Given the sample size of 1,131, the threshold for statistical significance, Though the magnitude of the impact threshold for an unmeasured variable can be interpreted in terms of general findings in the social sciences, it is also helpful to compare the threshold with the impacts of measured covariates. The extent to which a teacher believes leadership will enhance teaching has the strongest impact of the measured covariates. Its impact on the coefficient for NBPTS certified teachers on help provided is 0.011 which is the product of the correlation with being an NBPTS certified teacher (0.17) and the correlation with number of other teachers helped (0.06). Thus the impact of an unmeasured confound necessary to invalidate the inference of .068 would have to be more than six times greater than the strongest impact of the measured covariates, .011, to invalidate the inference that NBPTS certification affects the number of colleagues a teacher helps with instruction.
An example of the case replacement-based approach comes from Saw et al. (2017), where the focus is the impact of being labeled as a persistently lowest-achieving (PLA) school on students’ academic performances: To inform policy debates and theoretical interpretations of the causal effects of the PLA list, it is useful to quantify the discourse about the robustness of the inferences in this study. We quantify how much bias there must be in our RD estimates to invalidate inferences in terms of replacement data, 16 focusing only on the positive PLA list effects on the average of students’ scale scores in writing and the percentage of students who met proficiency level in social studies. As shown in table 5, to invalidate our causal inference of the PLA list effects on the average of students’ scale scores in writing, we would need to replace about 25% to 32% of our PLA schools with school samples for which there is no effect of being on the list. These 17 to 22 replacement schools could represent populations not directly in our sample, such as schools from outside of the selected bandwidth. Additionally, to invalidate the inference of an effect of assignment to the PLA list on social studies achievement, we would have to replace 6% to 8.6% of schools with schools in which there was no effect of being on the PLA list.
More write-up examples from other fields can be found in appendix B.
7 Programs and supplemental materials
Supplemental Material, st0565 - konfound: Command to quantify robustness of causal inferences
Supplemental Material, st0565 for konfound: Command to quantify robustness of causal inferences by Ran Xu, Kenneth A. Frank, Spiro J. Maroulis and Joshua M. Rosenberg in The Stata Journal
Footnotes
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
Appendix A. Maximizing the impact of an omitted variable
The formula for partial correlation can be represented as (also applies to regression)
We want to minimize the function of partial correlation given (assuming all terms are positive)
To maximize the impact, we want to minimize the function. This occurs when the denominator is maximized as follows:
The positive term is used when k is positive. Otherwise, the negative root is used for suppression.
Note the second derivative is
which is less than zero when
This condition always holds, so the first derivative above defines a maximum.
Appendix B: Examples of applications of indices for quantifying the robustness of causal inferences
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.