
Abstract
A major challenge of outcomes research is measuring hospital performance using readily available administrative data. When the outcome measure is mortality or morbidity, rates are adjusted to account for preexisting conditions that may confound their assessment. However, the concept of “risk-adjusted” outcomes is frequently misunderstood. In this article, we try to clarify things, and we describe Stata tools for appropriately calculating and displaying risk-standardized outcome measures. We offer practical guidance and illustrate the application of these tools to an example based on real data (30-day mortality following acute myocardial infarction in Latvia).
Keywords
1 Introduction
Outcomes research frequently aims to measure the performance of a physician or a hospital. This is often called provider profiling (Gatsonis 2005). The outcome rates are generally adjusted to remove the effect of age, allowing for an unbiased comparison between populations that may differ with respect to age. Countless biostatistics and epidemiology textbooks address this topic, so the direct and indirect methods to calculate age-adjusted rates are widely known.
Things get more complicated when other variables, such as clinical factors, are accounted for to derive risk-adjusted measures. Although age is generally the main source of confounding in epidemiological studies, other characteristics can significantly impact the patient’s individual risk and are outside the quality of care delivered. These additional characteristics can be retrieved from the hospital discharge records—also known as discharge abstracts or administrative claims—which are generally inexpensive and enable the analysis of large populations as well as many conditions and pathologies. This source of data is largely used in outcome studies but is nonetheless criticized because of limited accuracy of medical billing diagnosis and procedure coding. Despite this limitation, healthcare administrative databases are rich sources of information that are being leveraged for research purposes and used for policy decision making (Cadarette and Wong 2015).
In outcomes research, risk-adjustment techniques develop from logistic regression analysis. It seems trivial at first glance, but the assumption of independence does not hold when observations are clustered within second-level units (for example, hospitals), so one must take important precautions. We also think that the literature regarding risk adjustment still lacks structure, possibly because the topic is broad, disputed, and somewhat sensitive. Risk-adjusted outcomes are used to designate centers of excellence, to determine reimbursement levels in pay for performance programs, and to classify providers as outliers, so it is no surprise that their correct conceptualization and interpretation goes beyond the strict academic concern (Shahian and Normand 2008).
For whatever reason, the result is a list of definitions and abbreviations that might confuse someone first encountering this field of statistics. In this article, we try to clarify things by explaining step by step which techniques should be used to calculate and display the risk-adjusted outcome rates. We follow key methodological concepts with details of how to run risk-adjustment models in Stata using a practical example derived from real data (30-day mortality following acute myocardial infarction [AMI] in Latvia in 2016). Because this article is addressed to all health-services professionals and researchers skilled with numbers, we do not review advanced techniques, such as Bayesian hierarchical models.
2 Risk-standardized mortality rates
2.1 Logistic regression
The easiest way to obtain risk-adjusted outcome measures across providers is to build a conventional logistic regression model, where Y is a binary outcome measure expressed as 0/1 (say, death) and covariates Xi are the patient case mix (age, sex, comorbidities, etc.). We will describe methodological details on how these variables can be selected for inclusion in the model in section 3.
Regression coefficient estimates capture the effect of patient characteristics on the study outcome across all hospitals together. The predicted probability of the outcome can be derived for each patient by combining the regression coefficients estimated by the model with the patient set of covariates. In this way, each patient has both the actual outcome and the predicted probability of that outcome accounting for risk factors identified in the model. These measures are then summed over all records within each provider to derive the observed and the expected number of events. The expected number of events is the number of events that would occur if the “standard” event rates had happened, given the actual provider case mix. Standard event rates are estimated from the entire group of providers.
The adjusted outcome measure for each provider is presented as the ratio of the observed to the expected number of events. This is called the observed-to-expected ratio or, when the events are deaths, the standardized mortality ratio (SMR) (Naing 2000). The SMR compares the outcomes for the specific distribution of patients at a hospital with their expected results had they been treated by an average provider in the reference population. The SMR is favorable if less than 1 and unfavorable if greater than 1.
As a final step, the SMR should be multiplied by the overall outcome rate to allow for comparison of each hospital performance with the national or regional average. This measure is named either risk-standardized mortality rate (RSMR) or risk-adjusted mortality rate and is given by the following formula:

The RSMR is favorable when it is below the overall mortality rate and unfavorable when it is above the overall mortality rate.
2.2 Confidence intervals for RSMRs
Because the RSMRs for each hospital are derived from the reference population, it is appropriate to assess whether these rates are statistically different from the overall state or region mortality rate. This is achieved by determining whether the confidence interval (CI) for a hospital-specific RSMR includes the overall rate. If no overlap exists, the hospital is most commonly classified as a statistical outlier (Shahian and Normand 2008).
The analyst will have many choices because many formulas have been proposed to build CIs. These formulas are based on the assumption that the observed deaths are Poisson variates (that is, random variables with a Poisson distribution), while the expected deaths are not variates.
To avoid the iterative calculations needed for the exact results, we suggest constructing the CIs of RSMRs following the formula that relates the chi-squared distribution and the Poisson distribution:
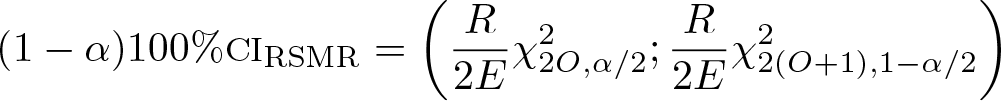
where O and E are, respectively, the number of observed and number of expected deaths for the provider, R is the overall mortality rate, and
2.3 Generalized estimating equations
It is likely that responses of patients from within the same hospital are correlated, even after adjusting for the effects of age, sex, and other potential confounders. This positive correlation is because each hospital has a unique mixture of staff, policies, and medical culture that combine to influence patient results. Fitting conventional regression models to correlated data often leads to inefficient parameter estimates and systematically small standard errors (Houchens, Chu, and Steiner 2007). Inefficient regression estimates are more widely scattered around the true population value than they would be if the within-group correlation were incorporated in the analysis.
Generalized estimating equations (GEEs) are one of the methods that account for correlated observations. GEEs are a flexible tool that can be trivially seen as an extension of conventional regression models, such as linear, logistic, or Poisson. A working correlation matrix reflecting average dependence among correlated observations must be specified when running GEEs to improve the efficiency of the parameter estimates. In Stata, the default within-group correlation structure corresponds to the equal-correlation model, also called “exchangeable”. The equal-correlation model is appropriate for profiling studies, where no time-varying outcomes or covariates must be investigated (Ballinger 2004).
Ample literature has suggested the use of a robust estimation of standard errors (also known as sandwich or Huber–White standard errors) when conducting analyses on correlated data and especially in conjunction with GEEs (Liang and Zeger 1986). These robust estimates allow the correct specification of the mean model while relaxing the assumption of correctly specifying the form of the variance model, that is, the working correlation matrix. In other words, GEEs are generally robust to misspecification of the variance model.
A known limitation of the robust variance estimate is that it can present issues in underestimating the variance when there are not enough clusters. A rule of thumb states that with fewer than 50 clusters, there may be concern about a biased estimate, while with more than 50 clusters, the estimate is likely to be asymptotically unbiased. It is thus advisable to correct robust standard error estimates for small sample sizes by using the divisor M − P, where M is the number of hospitals and P is the number of regression parameter estimates, instead of the default M (Huang, Fiero, and Mell 2016).
2.4 GEEs versus conventional logistic regression
GEEs should be generally preferred to conventional regression models when observations are clustered within groups. However, results from GEEs and logistic regression with robust standard errors are identical if the within-group correlation is close to 0.
To test whether observations are actually correlated, one should compare a GEE model with an exchangeable working matrix and with an independent working matrix. The best model between the two has the lowest quasilikelihood under independence criterion (QIC). The QIC is an extension of the widely used Akaike information criterion for model selection in GEE analysis (Pan 2001).
2.5 Stata code
A GEE model for a binary outcome (depvar) can be fit, and individual risk factors (indepvars) can be estimated using the Stata commands displayed below. The variable varname_i uniquely identifies providers. Note that, by adding the

To compare two GEE models with different within-group correlation structures (such as

The model with the lowest QIC must be preferred. If the model with an independent working matrix is the best fitting one, you can run a conventional logistic regression with clustered sandwich estimates to get the same output.

All these commands incorporate robust estimators. Of course, categorical indepvars must be preceded by
After running the best model between the two, we use

As a further step, one might want to calculate the RSMRs with 95% CIs for each hospital. To manipulate data at the hospital level, we use

Hospital-specific RSMRs (

Before restoring the original dataset, results must be saved as a new data file. If your filename contains embedded spaces, remember to enclose it in double quotes. This data file will be used to produce plots of either crude or risk-standardized rates (see section 5).
3 Confounder selection
The choice of predictive variables in regression analysis is somewhat of an art. Ideally, specific clinical variables to be included in each outcome model should be selected from expert panels and literature reviews of existing models.
There are some predefined sets of comorbidities, such as Elixhauser’s (Quan et al. 2005), that might be adopted to risk-adjust a broad spectrum of outcomes. However, to avoid model overfitting and misclassification, only significant risk factors should be included as covariates in regression analyses, either GEE or logistic. Many automated selection methods have been proposed—we describe in detail the one suggested by Austin and Tu (2004), which has the advantage to assess the stability of estimated regression coefficients. It can be summarized in four steps: Conditions whose prevalence is less than 1% in the population are excluded from further analyses. Simple regression models with clustered sandwich estimators are used to analyze the crude association between each potential confounder and outcome, and variables that are significantly associated with the outcome with a significance level of P < 0.25 are selected for possible inclusion in multivariable regression. A bootstrap backward procedure is adopted to determine which of these factors are significantly associated with the outcome in multivariable models. Using this approach, 1,000 replicated bootstrap samples are selected from the original data. In each replicated sample, age and sex are forced into the model, while a backward elimination of potential confounders is applied with a significance level of removal equal to 0.05. Risk factors selected in at least 500 (50%) of the replicates are included as confounders in the multivariable model, from which RSMRs are then computed.
To save time, the entire procedure might be based on logistic regression models instead of GEEs. To account for potential nonlinear relationships between age and outcome, age could be either transformed or subdivided into groups of similar size. Because a bootstrap assessment is performed to determine whether a given variable truly is an independent predictor of the outcome, this procedure does not necessarily have to be regularly done unless any changes occur in coding practices or disease epidemiology.
The Stata code to perform the bootstrap backward procedure is presented below. Note that the

Now that the individual risk factors have been selected, GEE analysis can be run using the commands described earlier (in section 2.5). That being said, note that more advanced tools are available in the
4 Direct comparison of hospitals
Hospital-specific RSMRs are the result of an indirect form of standardization. These measures are obtained by comparing the observed mortality rates of the patients with their expected rates. The estimated rate is the “counterfactual” (Holland 1986; Rubin 2005), an ideal result obtained under a different set of hypothetical circumstances, which is the primary motivator for risk-adjustment model development (Shahian and Normand 2008).
Almost all profiling studies and public reports use indirect standardization. As anticipated, because RSMRs are derived from the overall reference population, it is most appropriate to compare the RSMRs of each individual hospital with the overall mortality rate.
Furthermore, some seek to perform a side-by-side comparison of healthcare providers. Many statisticians have developed balancing methods, such as propensity scores (Rosenbaum and Rubin 1984; D’Agostino 2007; Rubin 2007), to improve case mix balance between institutions and to justify such comparisons. Some Italian authors (Arcà et al. 2006) have recommended including provider dummies in the regression model to allow a direct form of standardization and pairwise comparisons. Currently, the Programma Nazionale Esiti uses this approach to measure hospital performance in Italy. However, RSMRs should never be used to compare one provider with another unless study design or post hoc adjustments have been shown to be successful in balancing risk factor distribution (Shahian and Normand 2008).
5 Graphical representations of RSMRs
Outcome rates can be displayed in many ways. Bar graphs, in which bar height corresponds to the provider rate, are much appreciated by healthcare consumers, interested stakeholders, and the media. However, because these plots do not operate any distinction between small and large providers, it is impossible to ascertain whether large deviations from the state average are systematic or due to chance.
A common practice of agencies for healthcare quality is to exclude small hospitals from public report cards. We discourage this approach because it gives an incomplete representation of a country’s provision of healthcare services. Two effective graphs that illustrate outcome measures across providers and incorporate sample-size information are the caterpillar plot (sometimes inaccurately referred to as the forest plot) and the funnel plot (Spiegelhalter 2005).
The caterpillar plot is a sort of league table in which providers are ranked according to a performance indicator and, with the aid of CIs (section 2.2), outlying providers are identified. To avoid data misinterpretation, the providers should never be labeled with their rank, and outlying rates must be strictly determined using CIs. The providers that serve few patients have wider CIs that are due to small sample sizes.
Plots of estimates and CIs can be obtained in Stata using the
Funnel plots are an alternative graphical aid for reporting outcome rates. Each hospital rate (y axis) is plotted relative to its denominator size (x axis). The control limits form a sort of funnel around the target outcome, which corresponds to the state or regional average. These boundaries are a measure of precision of the hospital rates and depend on denominator sizes. In most cases, 95% (≈ 2 standard deviation) and 99.8% (≈ 3 standard deviation) limits around the overall mortality rate are superimposed on the scatterplot. Hospitals lying outside the control limits can be seen as outliers.
Given r as the overall rate, n as the hospital volume, and z as the standard normal distribution quantile, control limits are plotted at

where zα/ 2 is 1.96 for 95% control limits and 3.09 for 99.8% control limits. Alternative methods to compute control limits are described by Spiegelhalter (2005).
Funnel plots should be preferred to caterpillar plots because 1) the eye is instinctively drawn to important points that lie outside the funnel, 2) there is no spurious ranking of institutions, 3) there is allowance for additional variability in institutions with small volume, 4) the relationship of outcome with volume can be informally assessed, and most importantly, 5) pairwise comparisons between providers are naturally discouraged.
Funnel plots can be obtained using the
6 Example
As an example, we use real data from 20 hospitals in Latvia in 2016. The outcome of interest is the 30-day AMI mortality rate. Death within 30 days of hospital admission is
For each patient, we have collected this clinical information: ST elevation status (
First, clinical conditions whose prevalence is less than 1% must be identified and discarded from further analyses. With

The crude associations between each clinical condition and the outcome are analyzed using

Using

The bootstrap inclusion fractions for each variable can be easily derived from the

Variables with nonmissing values in at least half of the replicates (≥ 500) are eligible for inclusion in the final model. These are
The next step is to choose the best working correlation structure for the regression model. We first calculate the QIC value for the exchangeable correlation structure, and then we calculate the QIC value for the independent correlation structure. Both of the models have the covariates chosen in the previous analyses, plus age and sex. Because we have a large sample, the default matrix size must be augmented first to the maximum allowed. In this example, we use the

The exchangeable correlation structure has a QIC of 2479.168, while the independent correlation structure has a QIC of 2429.175. We conclude that conventional logistic regression is the best fitting model here:

The predicted probabilities and hospital-specific RSMRs with 95% CIs are calculated and saved in

The list of hospital-specific crude rates, RSMRs, and 95% CIs can be obtained from
Summary of volumes, crude, and risk-standardized 30-day AMI mortality rates in 20 hospitals in Latvia in 2016. The observed and expected number of deaths for each hospital are also reported.

Now we are ready to display the risk-standardized AMI mortality rates saved in

Figure 1 shows the result of these command lines. The RSMR of hospital #14 is significantly below the overall rate, while hospitals #7 and #18 have RSMR values significantly above the overall rate. There is no other statistically significant deviation from the state average.
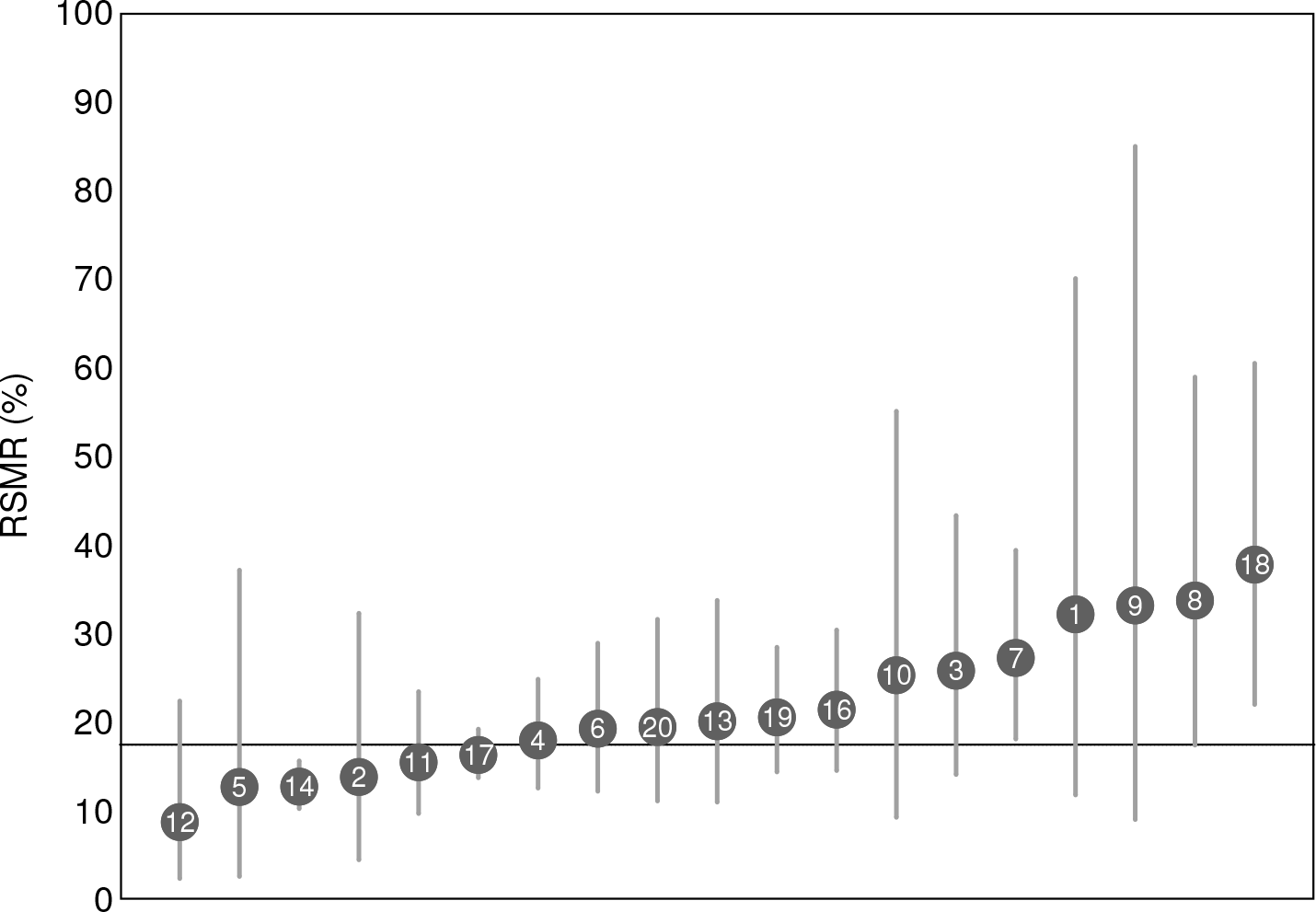
Caterpillar plot of RSMRs following AMI in 19 hospitals in Latvia in 2016. 95% CIs are plotted and compared with the overall rate of 17.5%. Hospital #15 is excluded.
Instead of using the command

Figure 2 shows the result of these command lines. The outlying positions of hospitals #7, #14, and #18 are confirmed. In addition, hospital #8 lies just outside the upper 95% control limit. We have seen that the two plots provide similar information in terms of outlier detection, although the caterpillar plot is slightly more conservative than the funnel plot.

Funnel plot of RSMRs following AMI in 19 hospitals in Latvia in 2016. The target is the overall rate of 17.5%. Hospital #15 is excluded.
7 Conclusions
In this article, we have tried to give a theoretical and methodological overview of risk adjustment and to provide some hopefully useful tips for calculating risk-standardized outcomes from regression modeling. Stata provides many powerful tools in this field of statistics, including automated model-selection techniques (
The RSMR of a hospital should be compared with the entire experience of a larger population of providers (that is, a country or region). Appropriate comparisons can be performed and made public with the aid of caterpillar plots, funnel plots, or both.
Supplemental Material
Supplemental Material, st0562 - Tips for calculating and displaying risk-standardized hospital outcomes in Stata
Supplemental Material, st0562 for Tips for calculating and displaying risk-standardized hospital outcomes in Stata by Jacopo Lenzi and Santa Pildava in The Stata Journal
Footnotes
8 Acknowledgments
The data presented in this article are based on work from the European Commission’s health systems performance assessment project “Developing Health System Performance Assessment for Slovenia and Latvia” (grant agreement: SRSS/S2017/019), in conjunction with the Ministry of Health of Latvia and the Management and Health Laboratory of the Sant’Anna School of Advanced Studies of Pisa, Italy.
We are grateful to Professor Sabina Nuti from the Sant’Anna School, who was appointed by the European Commission as the project leader for the Latvian health system performance assessment, and to Jana Lepiksone, head of the Research and Health Statistics Department at the Centre for Disease Prevention and Control of Latvia. We wish to thank Guido Noto, Federico Vola, and Ilaria Corazza, from the Sant’Anna School, for giving important contributions to this project. We also thank Professor Maria Pia Fantini from the University of Bologna for her inspiring lectures on outcomes research.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.