
Abstract
In this article, I review recent developments of the item-count technique (also known as the unmatched-count or list-experiment technique) and introduce a new package,
Keywords
1 Introduction
The item-count technique (also known as the unmatched-count or list-experiment technique) is a questioning technique for eliciting truthful responses to sensitive survey questions. The standard design for the item-count technique randomizes a survey sample into two groups. One group receives a list of items (that is, statements), while the other receives the same list plus an item that addresses a sensitive issue of interest to researchers. Instead of answering each item separately and directly, respondents report the number of items that fit certain criteria (for example, counting the items with which a respondent agrees). The item-count technique ensures the privacy and confidentiality of responses to the sensitive issue, thereby reducing respondents’ motives for deliberate misreporting. Furthermore, it still provides researchers with sufficient information for statistical inferences about the sensitive issue.
The item-count technique is becoming increasingly popular in various disciplines as a promising means of studying sensitive issues (Von Hermanni [2016]; Wolter and Laier [2014]; compare Gelman [2014]). However, data analysis for this technique is not straightforward and requires special methods that have not been built in most statistical software suites. I aim to fill this gap by introducing a new package—
2 The item-count technique
2.1 Basic idea
The item-count technique is essentially an encryption scheme that allows survey respondents to encode their answers to a sensitive question. Once encrypted, their answers can be deciphered only at a certain aggregate level for analysis (for example, the mean of a group of respondents’ answers). Therefore, it is safe for respondents to answer the sensitive question truthfully. 1
The 1991 National Race and Politics Survey (Sniderman, Tetlock, and Piazza 1991) is a classic example for illustrating the item-count technique. To measure the prevalence of racial prejudice among white Americans, the survey randomly divides a sample into two. Half the respondents (hereafter the “shortlist group”) are prompted with a question as follows: “Now I’m going to read you [several] things that sometimes make people angry or upset. After I read [them] all, just tell me HOW MANY of them upset you. I don’t want to know which ones, just how many.
the federal government increasing the tax on gasoline; professional athletes getting million-dollar-plus salaries; large corporations polluting the environment. How many, if any, of these things upset you?”
The other half (hereafter the “longlist group”) are prompted with the same list plus an item of interest (hereafter a “sensitive item” or “key item” as opposed to the three nonkey items above):
“a black family moving in next door.”
Racism is a sensitive issue in most modern societies. People who are upset about having new black neighbors may be reluctant to admit it publicly. Therefore, the itemcount question above asks respondents not to answer each item separately but to report the number of items that upset them, thereby allowing respondents to encrypt their answers to the sensitive item. Suppose that a respondent in the longlist group gives an answer of “two”; no one—not even the interviewer—can possibly know whether the answer counted in the key item (because it could be either two nonkey items or one nonkey item plus the key item). 2
The simplest tool to decrypt the item-count data is a difference-in-means estimator. For example, if the longlist group reports that, on average, 2.20 items upset them, and the shortlist group’s average count is 2.13, then the estimated prevalence of racial prejudice is 2.20 minus 2.13—that is, 7% of white Americans would be upset about a black family moving in next door.
2.2 Methods for data analysis
Consider a simple random sample of n respondents. Let Ti
be the group indicator for respondent i, where Ti
= 1 if the respondent is assigned to the longlist group and Ti
= 0 otherwise. Let Si
and Ri,j
be respondent i’s potential answers to the key item and to the jth nonkey item, respectively (where there are J nonkey items). Take the study of racial prejudice as an example: Si
= 1 if a black family moving in next door angers respondent i and Si
= 0 otherwise. Similarly, Ri,
2 = 1, if professional athletes getting million-dollar-plus salaries angers respondent i, and Ri,
2 = 0 otherwise. By design, Si
and Ri,j
are unobserved. The observed variable is the number of affirmative answers: Yi
= TiSi
+ Ri
, where
Under three assumptions—treatment randomization, no design effect, and no liar— any difference between the two groups’ average counts is attributed to the key item. 3 This justifies the use of the difference-in-means estimator, (1), to estimate the prevalence of the key item in the population. (Note that all estimators reviewed in this article rest on at least these three assumptions.)
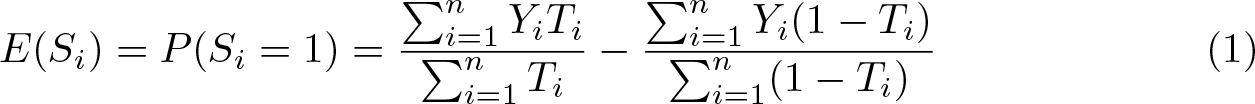
The difference-in-means estimate is identical to the slope coefficient of a simple linear regression of Yi
on Ti
. Holbrook and Krosnick (2010, 53–54) generalize this connection from univariate analysis to multivariate modeling. To model Si
, they regress Yi
on Ti
, a set of covariates

NOTES:
Additional assumption: E(∊i|Xi, Ti) = 0.
Holbrook and Krosnick’s (2010) method is essentially a linear probability model and so may produce nonsensical predicted values—that is, the predicted probability of answering the key item affirmatively,

NOTES:
Additional assumption: E(∊i|Xi, Ti) = 0.
Imai (2011, 409–411) also derives a maximum likelihood estimator as a more statistically efficient alternative to the nonlinear least-squares estimator. Note that Si
and Ri
, though unobserved, are mutually identifiable (Glynn 2013, 163). For instance, given Yi
= 2 and Ti
= 1, (Si, Ri
) must be either (1, 1) or (0, 1), and the probabilities of these combinations are also identifiable. Therefore, Imai proposes modeling the joint probability of Si
and Ri
. Because Si
is the primary focus, Imai factorizes the joint probability as P (Ri
|Si,

NOTES:
Additional assumption: the distribution of Ri
. For example, specifying a binomial distribution for Ri
is equivalent to assuming (Ri,j
⊥ Ri,k
|Si,
2.3 Nonstandard designs
The dual-list item-count technique
The standard item-count technique does not require the shortlist group to provide information about the key item, so the item-count estimates tend to be less precise (that is, have higher standard errors) than the estimates based on direct questioning. Droitcour et al. (1991, 189) partly overcome this limitation with a dual-list design. Consider the study of racial prejudice again. Suppose that, in addition to the original item-count question (labeled as QA ), we use another two nonkey items, together with the same key item, to form a second item-count question (QB ). As illustrated in table 1, there are still two random subgroups: group 0 answers to the short list of QA and then the long list of QB ; in contrast, group 1 answers to the long list of QA and then the short list of QB . This design prompts respondents with the key item in either QA or QB . All respondents, regardless of group, have to provide information about the key item.
An example of the dual-list design

For data analysis, Droitcour et al. (1991) propose applying the difference-in-means estimator to QA and QB separately to produce two estimates for the key item and then taking their arithmetic mean to obtain a more statistical efficient estimate. Formally, let Yi A and Yi B be respondent i’s answers to QA and QB , respectively. Ti is still the group indicator, but now Ti = 0 if respondent i is assigned to group 0 and Ti = 1 if he or she is in group 1. Equation (5) shows the difference-in-means estimator for the dual-list item-count technique.
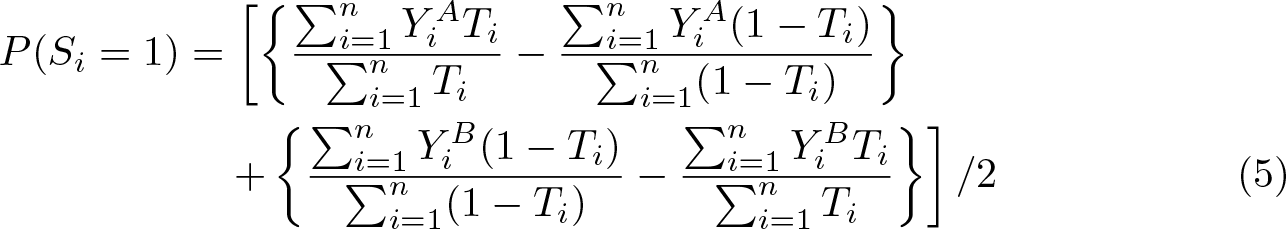
There is a lack of methods for multivariate analysis. To meet this need, I extend the methods reviewed in section 2.2 to the dual-list item-count technique (see the appendix).
The partial item-count technique
Corstange (2009) was among the first to develop a regression method for the itemcount technique. However, unlike those reviewed previously, Corstange’s (2009) method requires a nonstandard item-count design. His design (hereafter “partial item count”) requires respondents in the shortlist group to answer each nonkey item separately and directly (while those in the longlist group still answer to the question in the item-count format). Information on each nonkey item is then used to resolve the issue of model identification.
Unlike Imai’s (2011) maximum likelihood estimator that models the joint probabilities of Si
and Ri
, the partial item-count technique allows Corstange (2009) to model the marginal probabilities of Si
and each Ri,j
simultaneously (the primary focus is still Si
). Corstange (2009, 51) originally devised his estimator based on an approximate likelihood function. Blair and Imai (2012, 57) improve it by deriving an exact likelihood function as shown in (6) (
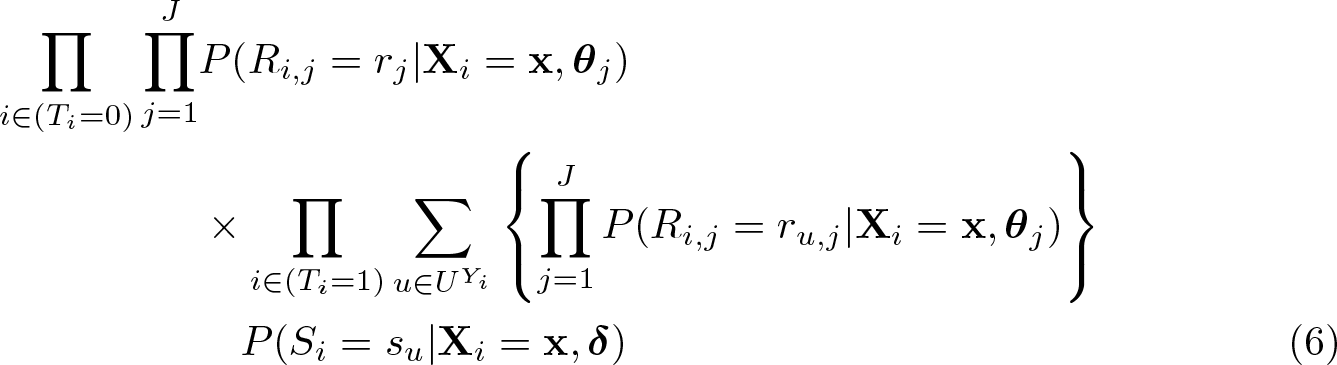
NOTES:
UY
i
is a set of combinations of Si
and Ri,j
that satisfy Si
+ Ri
= Yi
.
u is one of the combinations in UYi
.
su
= 1 if Si
= 1 in u, and su
= 0 otherwise.
ru,j
= 1 if Ri,j
= 1 in u, and ru,j
= 0 otherwise. Additional assumption:
Si
, Ri,j
, and Ri,k
(where j 6= k) are independent after controlling for
The item-sum technique
All the item-count techniques reviewed thus far require researchers to phrase the sensitive question as a dichotomous item (yes or no, agree or disagree, etc.) Trappmann et al. (2014) overcome this limitation using the item-sum technique. The item-sum technique differs from the item-count technique in two aspects: first, the key and nonkey items can be continuous variables; second, each respondent reports the sum of his or her answers to the items on the list. For example, Trappmann et al. (2014) in their study, prompted the shortlist group with two items as follows:
“Please answer each of the following questions truthfully. However, please keep the pencil and the piece of article ready. Please note the answer to each question on your piece of article. Afterward, please add the numbers from both answers together and tell me the total result. However, please do not tell me how you answered the individual questions so that I, as interviewer, do not know how you came to your result.
How many hours did you watch TV last week? How high are your monthly costs for your apartment or your house? Monthly costs can include rent, utilities, coop or condo fees, and mortgage. Thank you very much. What is your result?”
The longlist group was prompted with the same questions plus a key item:
“On average, how much do you earn per month from undeclared work?”
Suppose that a respondent in the longlist group watched television 10.5 hours last week, spent €430 for his or her house per month, and made €100 from undeclared work per week; he or she is expected to give an answer of 540.5. The difference-in-means estimator (1) and the linear least-squares estimator (2) are directly applicable to the item-sum technique. For instance, if the shortlist group’s average response is 516.4, and the longlist group’s is 664.3, the estimated earnings per month from undeclared work is e147.9.
2.4 Auxiliary information
Aronow et al. (2015) consider a scenario where a survey measures a sensitive issue not only by the item-count technique but also by direct questioning. For example, besides the item-count question mentioned at the beginning of section 2.1, the 1991 National Race and Politics Survey might have also asked every respondent a direct question on the key item, such as “Does a black family moving in next door make you upset? Yes/No.” Thus, the longlist group would have answered the key item twice. With this design, Aronow et al. (2015) propose using the answers to the direct question as auxiliary information to increase the statistical efficiency of the item-count estimation.
Formally, let Ai be respondent i’s answer to the direct question, where Ai = 1 for the affirmative answer and Ai = 0 otherwise. Aronow et al. (2015) make two assumptions about this variable: 1) Ai is independent of Ti , and 2) Ai is monotonically related to Si . As illustrated in table 2, positive monotonicity means that respondents do not answer the key item affirmatively to the item-count question while answering the direct question negatively; that is, P (Si = 1, Ai = 0) = 0; by contrast, negative monotonicity means P (Si = 0, Ai = 1) = 0.
Assumptions about the relationship between S and A

Under the negative monotonicity assumption, Aronow et al. (2015) modify the difference-in-means estimator as (7) for using Ai to aid the estimation of Si .

NOTES: Additional assumptions:
Ai
is independent of Ti
.
Ai
is related to Si
in a negatively monotonic manner.
Equation (8) is the counterpart under the positive monotonicity assumption:

NOTES: Additional assumptions:
Ai
is independent of Ti
.
Ai
is related to Si
in a positively monotonic manner.
Eady (2017) uses the same type of auxiliary information to improve Imai’s (2011) maximum likelihood estimator. Like Aronow et al. (2015), Eady also assumes that Ai is monotonically related to Si . This assumption—though simplifying estimation— severely restricts the choice of auxiliary information. Except for a direct question on the sensitive issue of interest, it is hard to see another source of auxiliary information that could possibly satisfy the monotonicity assumption. This is a major limitation of Aronow et al.’s and Eady’s methods because surveys cannot afford to adopt both a direct and an indirect approach for the same question.
Nonetheless, Tsai (2017, in part Not just unbiased but precise: How auxiliary information can improve modeling based on the item-count technique) shows that the monotonicity assumption is not essential. In fact, any individual-level information that is predictive of but extraneous to the sensitive issue of interest has the potential to improve the item-count estimation. “Extraneity” means that Ai is not a regressor for modeling Si . (Eady also implicitly makes this assumption.) “Predictivity” requires Ai to be statistically correlated with Si ; this assumption is weaker than monotonicity and thus places fewer restrictions on the choice of auxiliary information. (Besides, Ai still has to be independent of Ti , but this assumption is statistically testable.)
Consider the 1991 National Race and Politics Survey again. Actually, it did not include a direct question on the sensitive issue of interest, but there were other sources of auxiliary information. For example, a question in that survey asked respondents: “How do you feel about blacks buying houses in white suburbs? Strongly in favor/Somewhat in favor/Somewhat opposed/Strongly opposed.” This house-buying question and the key item of the item-count question (that is, “a black family moving in next door [makes you upset]”) are largely tautological, so it is reasonable to expect some correlation between respondents’ answers to these questions (predictivity). Also because of tautology, it is unnecessary to include that house-buying variable as a regressor to model the key item (extraneity). If the independence assumption holds too, then it is legitimate to dichotomize that variable and use it to improve the item-count estimation. (Note that the monotonicity assumption is not an essential concern.)
Equation (9) shows the likelihood function of Tsai’s (2017) estimator, where
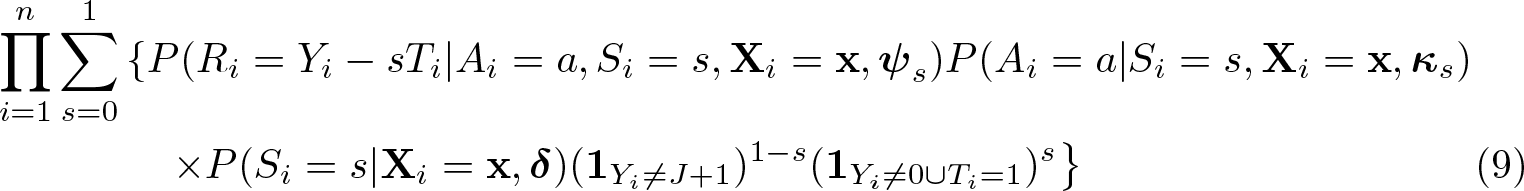
NOTES:
Additional assumptions:
Ai
is independent of Ti
.
Ai
is predictive of Si
.
Ai
is extraneous to Si
. Distributional assumptions of Ri
.
This estimator models the factorized joint probability of Ri
, Ai
, and Si
. As always, the coefficient
Equation (9) is specific for the standard design of the item-count technique, but its idea applies to nonstandard designs too. In the appendix, I extend that estimator to Corstange’s (2009) partial item-count technique.
3 Commands
3.1 Syntax

indepvar specifies an independent variable of the active
depvar specifies a variable that records respondents’ answers to an item-count question (Yi
). For the dual-list design, depvar and depvar2 specify variables that record respondents’ answers to the first and second item-count questions, respectively (that is,
3.2 Options for kict deff
By definition, probabilities cannot be negative. If some of the estimated joint probabilities are negative,
[
3.3 Options for kict ls
gmm_options; see
3.4 Options for kict ml
Consider a vector
ml_options; see
Options specific to estimator(corstange)
The approximate likelihood function assumes that the number of affirmative answers to the key and nonkey items (Si
+Ri
) is binomially distributed (
Options specific to estimator(imai)
Options specific to estimator(tsaieady)
If a recoded version of the dummy is also specified after the original dummy,
3.5 Options for kict pfci
4 Examples and technical details
In this section, I demonstrate the use of
4.1 The standard item-count technique
I first revisit the item-count question in the 1991 American National Race and Politics Survey. The data contain an indicator variable (

Diagnostics
The validity of the item-count technique rests on at least three assumptions (footnote 3). A common practice to check the first assumption—treatment randomization—is to test for differences between the shortlist and longlist groups’ responses to important variables in the survey. No significant difference between groups indicates an effective randomization of treatment.

The second assumption—no liar—requires respondents in the longlist group to answer the key item truthfully. It is not statistically feasible to check this assumption, not only because respondents’ answers to the key item are by design unobserved but also because their truthful answers are unknown (otherwise there is no point in using the item-count technique).
The third assumption—no design effect—requires respondents not to change their answers to nonkey items depending on whether the key item appears in the list. Suppose that a respondent in the shortlist group answers one nonkey item affirmatively. If he or she were assigned to the longlist group, his or her answer must be either “one” or “two” (that is, he or she either answers one nonkey item affirmatively or answers one nonkey item plus the key item affirmatively). Blair and Imai (2012, 64) propose a statistical test for the no-design-effect assumption.
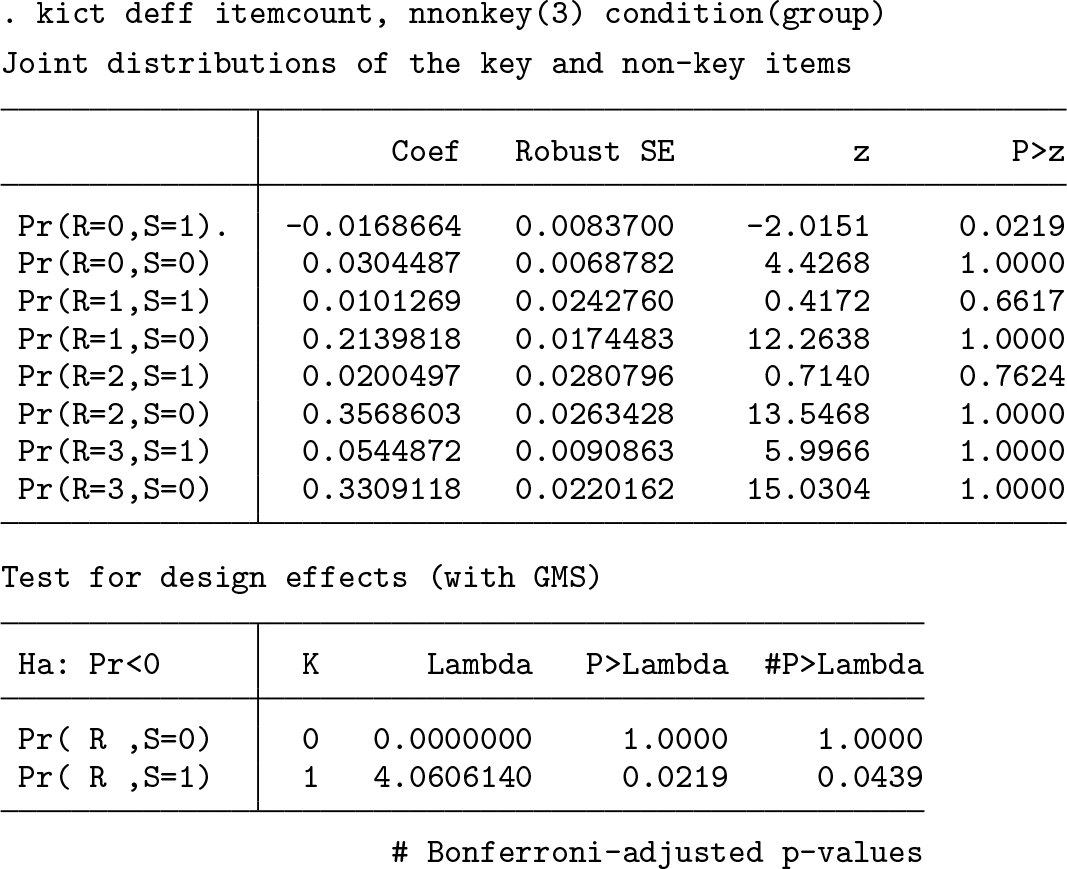
The first table lists estimated probabilities of all possible types of item-count responses. For example,
When either of these tests is statistically significant, researchers should conclude that the no-design-effect assumption does not hold. 6
The difference-in-means estimator
Let us assume for a moment that the 1991 American National Race and Politics Survey satisfies all three fundamental assumptions of the item-count technique. Then a basic analysis is to estimate the proportion of people who answer the key item affirmatively.

In this output, the central focus is
Note that, regardless of estimators,
The linear least-squares estimator
Kuklinski, Cobb, and Gilens (1997) analyze whether whites in the Southern United States have a higher level of racial prejudice than other white Americans do. They answer this question by applying the differences-in-means estimator to the subsample of Southern whites and the other whites in the survey and then testing for the difference between two estimates.
Taking a more sophistic approach, Imai (2011, 412) estimates the regional difference in racial prejudice while controlling for other sociodemographic characteristics. The output below replicates his analysis by a linear least-squares regression [similar to (2)].
8
The coefficient of interest is

One disadvantage of the linear least-squares estimation is unreasonable prediction. For example, a 21-year-old college-educated female non-Southern white’s probability of feeling anger over a black family moving in next door is estimated at −0.17(= 0.20×0+ 0.73×0.21+0.18×0+0.11×1−0.43). This is nonsensical because a probability cannot be a negative value. We can avoid this problem by using the nonlinear least-squares estimator. 9
The nonlinear least-squares estimator

Because of the logistic parameterization,
Imai’s maximum likelihood estimator
Imai’s maximum likelihood estimator (4) is an alternative to the nonlinear least-squares estimator. By default,


Furthermore, the
These assumptions do not always hold true. For example, a commonly used strategy to prevent respondents from answering all items affirmatively or negatively is to include an extremely low or high prevalent nonkey item into the list. This strategy jeopardizes assumption 2. Another strategy is to use negatively correlated nonkey items (Glynn 2013, 163). However, this risks violating assumption 1.
A way to relax these two assumptions is to use other distributions to model Ri
.
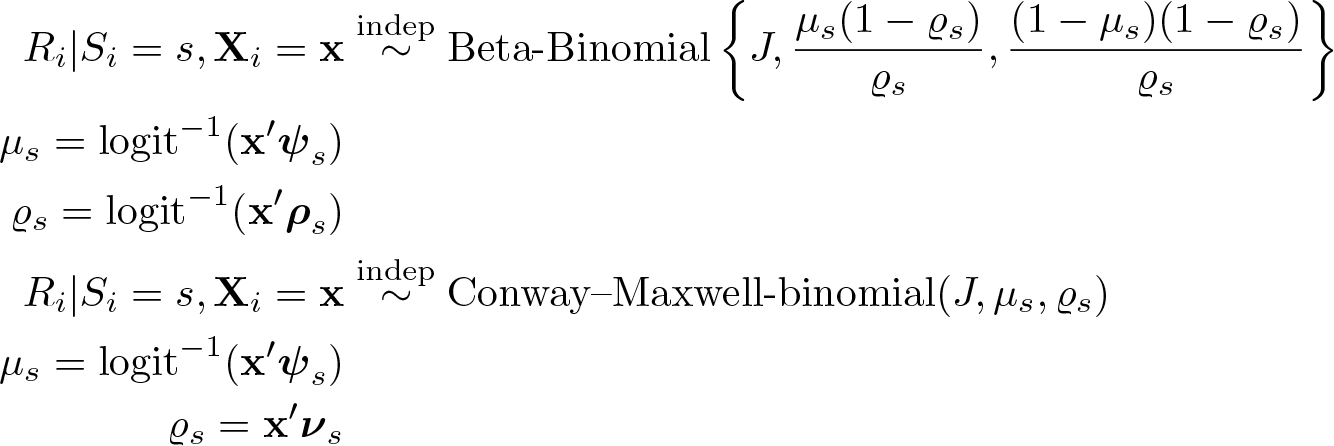
Nonetheless, both alternative distributions require
Another significant aspect of Imai’s estimator is regarding the relationship between responses to the key and nonkey items. By default,

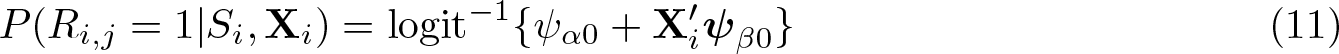
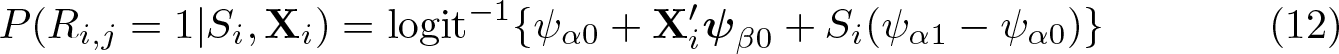


Imai (2011, 412) proposes a simpler specification. He assumes that Ri,j
and Si
are independent after controlling
Advanced issues for maximum likelihood estimators
Imai’s maximum likelihood estimator is complex and hence potentially difficult to optimize (so are the other maximum likelihood estimators demonstrated later). None of Stata’s built-in optimization algorithms guarantee finding the global maximum. A trick to handle this issue is to optimize a model from different random initial values.
For example, the syntax below requires

Furthermore, because of its complexity, Imai’s estimator is also prone to the problems of complete separation and boundary values. The quasi-Bayesian approach is a possible solution to these problems. Following Gelman et al. (2008),

The next step is to decide which coefficients need priors and how informative their priors should be. For illustrative purposes, I impose a prior with a scale parameter 2.5 on every slope coefficient in the

No matter whether the quasi-Bayesian approach is adopted,
CI does not rest on the normality assumption (Royston 2007) and is hence more robust than the normal-based CI when the sample size is small or when nonnormal priors are used.
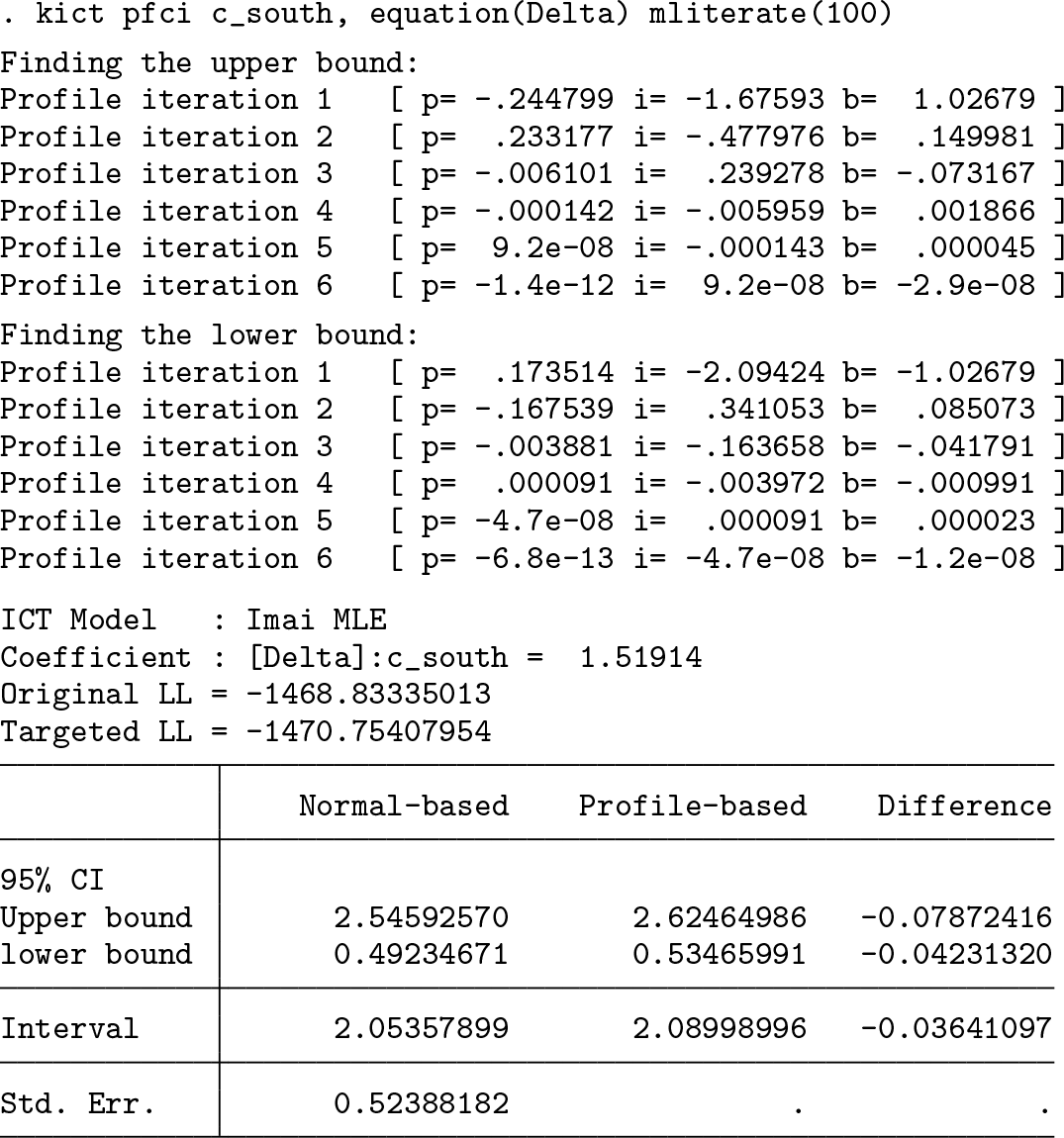
All the commands, options, and discussions above apply to the other maximum likelihood estimators demonstrated later in this section.
4.2 The partial item-count technique
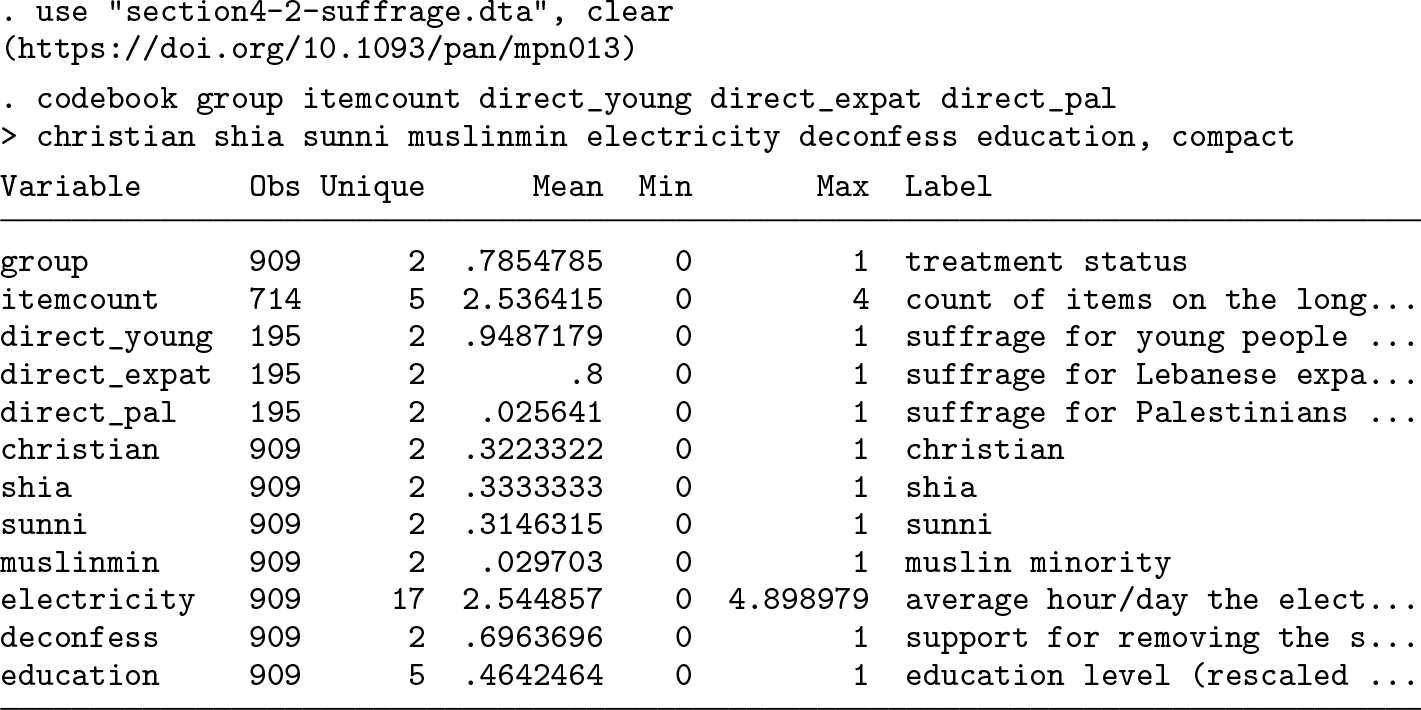
To gauge Lebanese attitudes toward voting rights for illiterates, Corstange (2009) uses the partial item-count technique in a Lebanese nationwide face-to-face survey. He requires a quarter of randomly selected respondents to answer each of the following items separately and directly: “There has been some debate recently over who should have the right to vote in Lebanese elections. I’ll read you some different groups of people: please tell me if they should be allowed to vote or not.
Young people between the ages of 18 to 21; Lebanese expatriates living abroad; Palestinians without Lebanese citizenship.”
The rest of respondents answer to the question below in the item-count format, where the third item in the list is the key item: “There has been some debate recently over who should have the right to vote in Lebanese elections. I’m going to read you the whole list, and then I want you to tell me how many of the different groups you think should be allowed to vote. Don’t tell me which ones, just tell me how many.
Young people between the ages of 18 to 21; Lebanese expatriates living abroad; Illiterate people; Palestinians without Lebanese citizenship.”
After casewise deletion, the sample size for analysis is 909 (see the
Corstange (2009) conducts an analysis by using a maximum likelihood estimator (6) that assumes that each respondent’s item count approximately follows a binomial distribution.

The output below replicates table 1 of Corstange (2009, 59). The

Blair and Imai (2012) improve Corstange’s estimator by using a Poisson-binomial distribution to model respondents’ item counts.
Blair and Imai’s estimator generally outperforms Corstange’s when the probability of answering an item in the affirmative varies greatly from one item to another. Nonetheless, note that both estimators assume that items are conditionally independent. It remains unclear about which estimator is more robust to the violation of that assumption.
4.3 Item-count techniques with auxiliary information
Eady (2017, 252–257) investigates Canadians’ attitudes toward gender equality through an Internet survey by using both the standard item-count technique and a direct question. A random half of respondents (the longlist group) are prompted with the following item-count question: “How many of the following do you agree with?
There should be more funding for the arts The government should raise taxes on gasoline Corporations are taxed too much Women are as competent as men in politics Unions have too much power”
The other half of respondents (the shortlist group) are prompted by the same question without the sensitive item (the fourth one). Later in the same survey, all respondents are required to answer the sensitive question directly. In other words, those in the longlist group answer the key item twice: “Do you agree or disagree with the following statement? ‘Women are as competent as men in politics.’ ”
The sample size for analysis is 22,372 (see the

Aronow et al.’s (2015) difference-in-means estimator
Eady (2017) argues that, while respondents who deny gender equality may misreport their attitudes for avoiding social disapproval, those who agree with the norm should have no incentive to give a false answer. In this regard, Aronow et al.’s difference-inmeans estimator with the positive monotonicity assumption (8) is suitable to estimate the prevalence of the belief in gender equality in Canada.

In the output above,
This difference-in-means estimator rests on two assumptions. First, Ai
is independent of Ti
. We may test this assumption with
Eady–Tsai’s maximum likelihood estimator
Besides the overall prevalence of the belief in gender equality, Eady is also interested in whether that belief varies along ideological lines. He conducts a regression analysis using the maximum likelihood estimator shown in (9) (hereafter “Eady–Tsai’s estimator”).

The option
The output below replicates the second model in table 4 of Eady (2017, 256). Two coefficients are particularly of interest. First,

Several technical points are noteworthy. First, the model above does not estimate the
4.4 The dual-list item-count technique
Consider the dual-list design presented in table 1: two item-count questions having the same key item but different nonkey items—three nonkey items for QA and two for QB . To demonstrate this design, I construct an artificial dataset as follows:

The output below demonstrates that each item-count variable is sufficient to produce an estimate of the population average response to the key item (

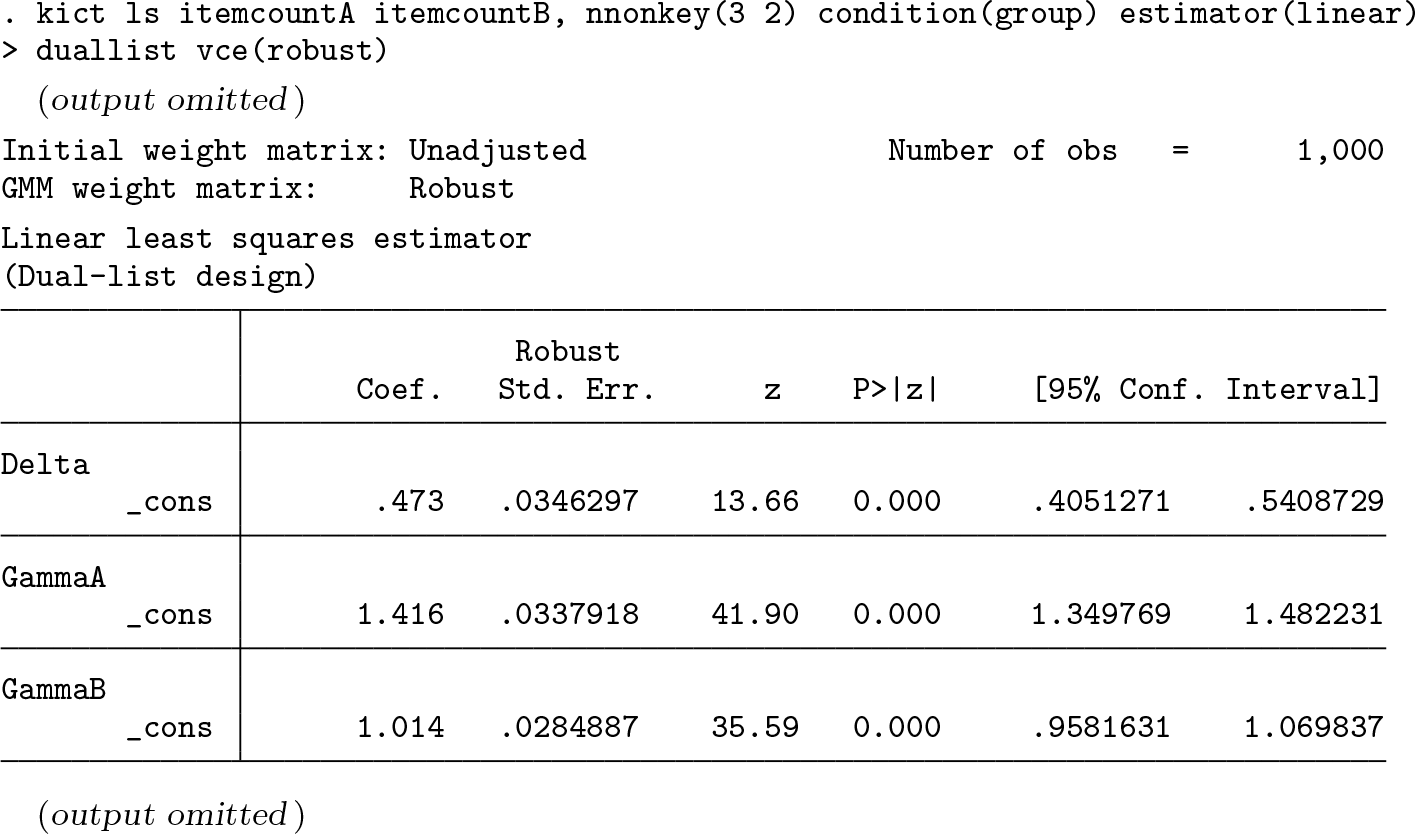

Regarding maximum likelihood estimation,

4.5 The item-sum technique
To demonstrate the item-sum design illustrated in The item-sum technique on page 397, I construct an artificial dataset as follows:


On multivariate analysis, the interpretation of the

5 Concluding remarks
In this article, I reviewed recent developments of the item-count technique and introduced a package,
The
The development of the item-count technique is still ongoing. There are more and more interesting variant designs and new methods for data analysis (for example, Chaudhuri and Christofides [2013, 115–150]; Blair, Imai, and Lyall [2014]; Chou, Imai, and Rosenfeld [Forthcoming]; Ibrahim [2016]; Tsai [2018]). I will continue to update the
Supplemental Material
Supplemental Material, st0559 - Statistical analysis of the item-count technique using Stata
Supplemental Material, st0559 for Statistical analysis of the item-count technique using Stata by Chi-lin Tsai in The Stata Journal
Footnotes
Notes
Appendix
I first modify Imai’s least-squares estimators [(2) and (3)] to accommodate to the duallist design of the item-count technique. I continue to use the notations introduced in The dual-list item-count technique on page 394 and additionally define
NOTES:
g(
f(
h( Additional assumptions:
In the linear least-squares estimation, g(·), f(·), and h(·) are identity-link functions. For nonlinear estimation,
Computationally,
Second, I attempt to modify Imai’s maximum likelihood estimator (4) for the dual-list item-count technique. Equation (16) shows the likelihood function of one possible modification:
NOTES:
Additional assumptions: the distributions of RiA and RiB. Third, I apply Eady and Tsai’s idea about auxiliary information to Corstange’s partial item-count technique. Equation (17) is the likelihood function:
NOTES:
UYi−s
is a set of combinations of Ri,j
that satisfy Ri
= Yi
− s.
u is one of the combinations in U
Yi−s
.
ru,j
= 1 if Ri,j
= 1 in u; ru,j
= 0 otherwise. Additional assumptions:
Ai
is independent of Ti
.
Ai
is predictive of Si
.
Ai
is extraneous to Si
.
Si
, Ri,j
, and Ri,k
(j ≠ k) are independent after controlling for

References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.