
Abstract
Adopting toxicity scores produced by Google’s Perspective API has become perhaps the most popular approach to estimating the prevalence of incivility and toxicity in online communication. However, existing scholarship has often overlooked the imbalanced nature of incivility when evaluating the performance of Perspective scores, leading to an overestimation of their effectiveness. In this research note, we demonstrate that once this imbalance is considered, Perspective scores perform poorly in accurately identifying incivility. We then propose a method that leverages Perspective scores to reduce the manual coding needed for developing a high-performing supervised learning classification model. Our findings indicate that combining Perspective scores with supervised learning approaches yields significantly better results for identifying incivility.
A burgeoning literature has sought to classify incivility in large-n studies, often focused on gauging the presence and frequency of incivility in the social media posts of political elites (Ballard et al., 2022; Petkevic and Nai, 2022; Skytte, 2022). Scholars have relied on several different measurement strategies to accomplish this (Muddiman et al., 2019). 1 Adopting toxicity scores produced by Google’s Perspective API has become perhaps the most popular approach to estimating the prevalence of incivility and toxicity in online communication (Calvo et al., 2023; Chang et al., 2023; Frimer et al., 2023; Hansen, 2023; Hopp et al., 2018; Kim et al., 2021; Stevens et al., 2022; Theocharis et al., 2020; Votta et al., 2023). The preceding list of citations is not comprehensive and will likely grow.
That so many studies have made use of this tool in recent years is not without good reason: Google’s Perspective API is an established, thoroughly tested model for analyzing digital communication, which scores text for toxicity. For each comment, Perspective provides a probability, which can be interpreted as the likelihood that a comment makes someone leave a discussion. However, the question as to whether raw Perspective API scores are a valid measure of political incivility is unclear. Given the number of studies utilizing Perspective API (e.g., Frimer et al., 2023; Kim et al., 2021) and the high-profile coverage of some of this work (e.g., Mason, 2022), an assessment of the validity of the scores is warranted and necessary.
Our research note has two main goals. First, we aim to highlight the limitations of using raw Perspective scores to measure political incivility in the American context. Perspective was originally designed to detect toxicity, which differs from incivility. Applying toxicity scores to measure incivility is problematic because these scores may misclassify strong language aimed at non-political targets as toxic. Additionally, the rarity of incivility in social media posts can lead to misleadingly high accuracy and low false positive rates that don’t accurately reflect the score’s ability to identify uncivil discourse. Through our analysis of congressional tweets using metrics like precision, recall, and F1-scores, we show that Perspective’s performance is flawed in capturing incivility. Therefore, we advise against relying solely on Perspective scores and suggest a more nuanced approach to measuring incivility in political communication.
Second, we propose a method that leverages Perspective scores to enhance the performance of custom classification models in identifying incivility. Custom classification models typically struggle with this task due to the infrequent occurrence of incivility in social media posts, which results in an imbalanced dataset. We argue that scholars can use Perspective scores to create a more balanced dataset, which can then be used to train a custom classification model. We demonstrate that this method outperforms both dictionary-based techniques for identifying incivility and traditional modeling strategies for handling data imbalance.
Identifying Political Incivility with Google Perspective API
Google’s Perspective API is an “out-of-box” classifier specifically designed to score text for toxicity 2 . Its 3 algorithm is trained via supervised machine learning using many thousands of individuals. The model’s specification of toxicity defines a “toxic” comment as any “rude, disrespectful, or unreasonable comment” (Google, nd). We think leveraging Perspective scores to measure political incivility, which can be defined as violations of interpersonal norms that govern political conflict (Mutz, 2015), has utility. For instance, they may be sufficient in detecting incivility in campaign ads (Hopp et al., 2018; Votta et al., 2023). However, the scores have also been used to measure political incivility in social media posts (Frimer et al., 2023; Kim et al., 2021), and the way in which the scores have been employed, we think, may lead to likely measurement error for several reasons.
First, we will emphasize that Perspective scores are a probability that a comment qualifies as toxic, not a measure of intensity. Using raw Perspective scores as a gauge of the level of incivility is a misuse of the scores. Nonetheless, scholars have treated Perspective scores as a continuous measure (e.g., Frimer et al., 2023; Kim et al., 2021). This practice extends the application of Perspective scores beyond their intended purpose, potentially leading to conclusions that do not accurately reflect the nuanced nature of incivility.
Second, it is unclear whether perspective scores produce a valid measure of incivility. Many of the studies that employ Perspective scores to gauge incivility aim to assess partisan warfare in the context of American politics, using elected officials’ use of uncivil discourse to reflect on the state of partisan polarization (Chang et al., 2023; Frimer et al., 2023; Kim et al., 2021). However, a comment that receives a high toxicity score may have little to do with domestic partisan dynamics; it may be strong language aimed at an international adversary, or condemnation of some criminal or unethical act by a non-political actor. This is particularly likely to be the case with social media communication, which, unlike campaign advertisements, feature messages on topics outside the scope of election battles and American politics.
Whether toxicity scores can be extended to measure incivility is ultimately an empirical question, but current scholarship offers an unclear answer. Existing studies primarily assess the effectiveness of toxicity scores by focusing on the false positive rate, which measures the proportion of non-toxic instances that are incorrectly classified as toxic (Frimer et al., 2023; Muddiman et al., 2019). However, relying on the false positive rate to evaluate Perspective API’s performance is problematic when studying incivility because incivility is a rare phenomenon within the broader spectrum of social interactions. The rarity of incivility allows a classifier to achieve a low false positive rate simply because civil interactions are far more common. 4 Consequently, the validity of using Perspective scores remains uncertain. Even with a low false positive rate, Perspective scores may still rarely identify true instances of incivility accurately.
We reassess the validity of Perspective scores by focusing on their effectiveness in correctly categorizing the minority class of incivility, particularly in terms of precision, recall, and the F1-score. Precision measures the proportion of true positive (correctly identified uncivil) instances out of all tweets classified as uncivil. In scenarios where uncivil discourse is rare, a high precision indicates that when the classifier predicts incivility, it is likely correct. Recall, on the other hand, measures the proportion of actual uncivil tweets that the classifier successfully identifies. A high recall means that the model is capturing most instances of incivility, while a low recall suggests that many true cases of incivility are being missed and classified as civil. The F1-score, which is the harmonic mean of precision and recall, balances the need to minimize false positives (addressed by precision) with the need to maximize the correct identification of uncivil tweets (addressed by recall). In rare event scenarios like uncivil discourse, the F1-score is particularly valuable because it provides a comprehensive measure of both the accuracy and completeness of the classifier’s positive predictions.
Defining and Operationalizing the Concept
Drawing from Mutz (2015), we conceptualize political incivility as the violation of interpersonal norms that govern political conflict. 5 We define it as norm-violating rhetoric or discursive behavior meant to demonstrate contempt for opposing individual, groups, or viewpoints in a political context. By political context, we mean the person or group targeted by incivility is done so for political reasons. In addition, the person or group targeted should have a political nature. These standards can weed out behavior and rhetoric that is apolitical. For instance, failing to hold the door for the person behind you is rude, it would not be political incivility—unless you did it because the person was wearing a MAGA hat. Likewise, insulting a steaming company (e.g., Netflix) on social media because their services are down does not have any obvious political implications.
What qualifies as a norm violation can vary across time and space (Sapiro, 1999). However, given our primary concern is the measurement of political incivility in contemporary American society (which is also largely the concern of the studies we cite above that have leveraged Perspective API), that there is broad agreement among the American public as to what qualifies as uncivil, norm-violating behavior (Massaro & Stryker, 2012), and there is broad agreement among scholars that types of discursive behaviors qualify as uncivil in modern American politics (see categories below) , operationalizing political incivility into a clear set of discursive behaviors that fits this definition is a feasible task. We qualify the following type of behaviors, when occurring in contemporary American political context, as examples of political incivility (additional discussion of each is included in the Appendix): (1) Invectives and ridicule: ad hominem attacks, character assassinations, mockery, name calling, and other insults) (Berry & Sobieraj, 2013; Brooks & Geer, 2007; Coe et al., 2014; Fridkin & Kenney, 2008; Gervais, 2014; Massaro & Stryker, 2012; Mutz, 2015; Thorson et al., 2010). (2) Hyperbole and distortion (or “spin”), in which individual misrepresents a target’s views or behavior with the intention of making them seem more radical, immoral, or corrupt. This is done by leveraging extremizing and inflammatory words or phrases (Berry & Sobieraj, 2013; Gervais, 2014, 2019, 2021; Gervais & Morris, 2018; Massaro & Stryker, 2012). (3) Negative-emotion attribution, such as stating that a political figure or group is a source of national sadness, fear, or embarrassment (Berry & Sobieraj, 2013; Gervais, 2014; Gervais & Morris, 2018; Muddiman, 2017). (4) Conspiracy theories, or (baseless) accusations of very sinister motives/actions/background, promoted as fact (Berry & Sobieraj, 2013; Gervais, 2014; Gervais & Morris, 2018, 10, 13).
Assessing the Performance of Google’s Perspective API
We collected tweets from congressional Twitter (now known as X) accounts at two different periods, using two different types of accounts: official congressional accounts and congressional campaign accounts. The two types of accounts each have an advantage: whereas a collection of official accounts will be more representative (nearly every member of Congress has an official account), we expect that campaign accounts are more likely to feature incivility. Incorporating both allows for a more nuanced evaluation of Perspective API’s performance in identifying incivility across different contexts of elite tweets.
The first dataset consisted of tweets issued by the official accounts of 418 members of the 115th U.S. House of Representative during a three-month period (from March 2017 through June 2017). The initial collection consisted of about 100,000 tweets. Like previous work (e.g., Frimer et al., 2023), tweets that were not original to the account of a legislator—i.e., retweets of other users’ posts—were then removed from the dataset. After the removal, about 84,000 tweets remained. Our second dataset consisted of tweets from congressional campaign Twitter accounts active during the 2020 general election. We collected a dataset of 116,086 tweets from 775 campaign accounts of 2020 general election House candidates. 6
To code for incivility, we select a random sample of tweets from both datasets for human coding. From the 2017 official tweet dataset, 3% were selected (2184 tweets). For the 2020 campaign tweet dataset, we realized a slightly smaller training set would suffice and sampled 1% of the dataset (1000 tweets). After undergoing training, teams of research assistants were tasked with independently coding the training set (for this stage, the team consisted of three coders for the 2017 data and two coders for the 2020 data). 7 These coders were tasked with identifying the forms of discursive behavior commonly identified as uncivil in the political incivility literature, described above.
We include the complete coding scheme used by coders in the appendix, but will note several key rules of thumb coders were provided with here: If you are not sure about whether a comment/post contains incivility or not, give the benefit of the doubt to civility. Avoid marking mild rebukes as uncivil. Treat criticism as civil unless it features one of the incivility types listed [in the coding scheme]. Avoid marking comments as uncivil when they are bipartisan in their criticism or target a group the member is a part of (e.g., “elected officials have failed to get the job done”) Always, ask “who’s the target?” If no person or group is explicitly targeted, don’t mark it as uncivil. However, if someone is referenced, but we aren’t sure who (e.g., “he is an idiot and is destroying the country.”) this ought to be marked uncivil. Use your best judgment as to whether you think it is targeting an individual person/group.
Intercoder reliability was strong in both cases: the 2017 team agreed on about 96% of the cases (Brennan and Prediger’s kappa = 0.92), and there was 94% agreement among the 2020 team (Brennan and Prediger’s kappa = 0.89). To demonstrate the types of tweets the coders identified as uncivil, we include a table in the appendix that includes tweets randomly selected from the student coded sets that were coded as uncivil.
To assess the validity of Perspective toxicity scores, we used Google’s Perspective API to code both datasets for toxicity. For the 2017 corpus, the average toxicity score was 0.14 (SD = 0.11) with a median toxicity score of 0.11. The distribution was similar for the campaign tweets: the average toxicity score was 0.14 (SD = 0.11) and the median toxicity score was 0.09. Next, we compare their performance to the human coded dataset across different thresholds. Since Perspective scores generate a probability that a comment is toxic, we calculate precision, recall, and F1-scores at various thresholds ranging from zero to 1, in intervals of 0.1. This approach allows us to identify the threshold that maximizes the accuracy and reliability of the Perspective scores in categorizing uncivil discourse, ensuring that we provide a comprehensive evaluation of perspective scores across the range of thresholds that practitioners might use.
Perspective API Performance Across Thresholds.
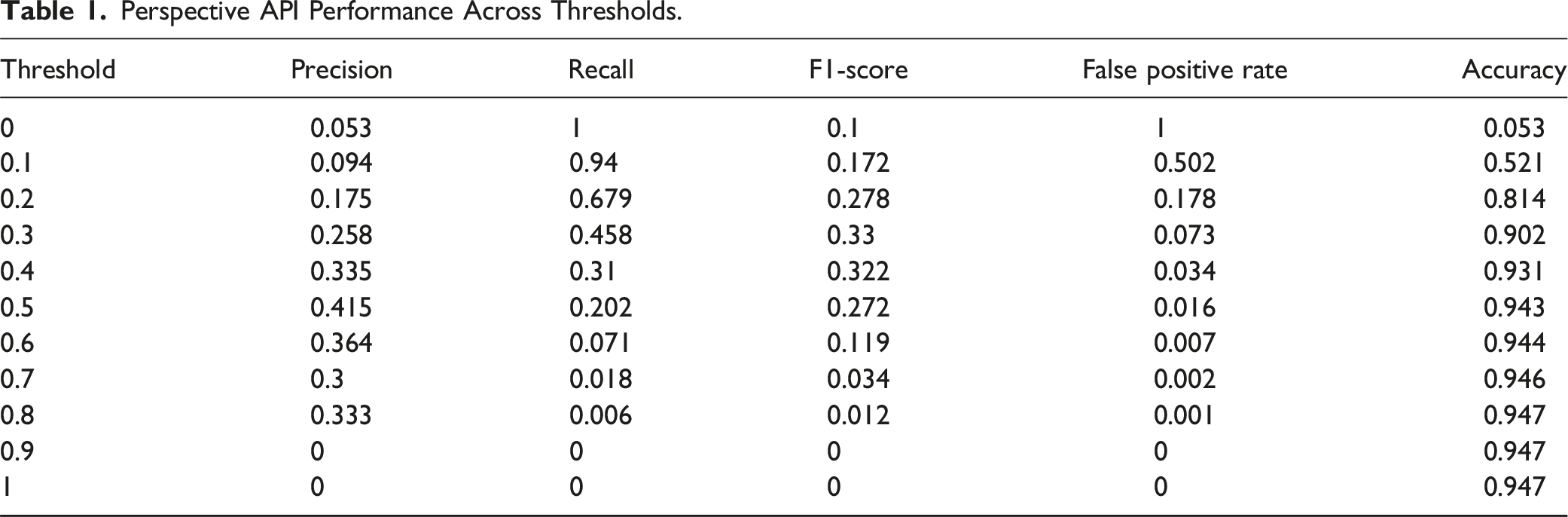
The high accuracy and low false positive rate at higher toxicity thresholds, despite the model’s poor ability to identify incivility, show that these metrics can be misleading. The inflated accuracy is driven primarily by the imbalanced nature of the dataset where civil comments vastly outnumber uncivil ones. This imbalance allows the toxicity scores to achieve a high accuracy score by correctly predicting civil comments, without having to correctly identify incivility. Similarly, the low false positive rate at higher thresholds, which might initially appear as a positive outcome, is indicative of the inadequacy of toxicity scores. The sharp decline in recall at thresholds where the false positive rate is high indicates that toxicity scores fail to identify most true uncivil comments. As a result, the reduction in false positives stems not from the model’s ability to accurately differentiate between uncivil and non-uncivil comments, but rather from its failure to detect the majority of uncivil comments altogether. Consequently, the Perspective API’s performance across all thresholds is fundamentally flawed, as it fails to strike a balance between precision and recall, leading to poor overall model efficacy.
A Hybrid Approach to Classifying Incivility
While Perspective scores are unreliable in identifying incivility, we argue that they can be used to improve the performance of custom classification models. Custom classification models differ from Perspective API, because they are based on a sample of the data being analyzed. In the case of custom supervised learning classification models, they are developed by using a small set of data to train a model over the features of the text that are associated with each category. The advantage of custom models is that they can be trained to classify specific concepts. At the same time, custom models perform poorly when developed to identify rare events. Rare events create imbalanced datasets, which lead custom classification models to overemphasize the more dominant class.
While techniques such as oversampling from the minority class, under sampling from the majority class, or weighting observations from the minority class higher in the training process mitigate the performance issues resulting from imbalanced data (Chawla et al., 2002; Megahed et al., 2021), the most effective strategy to address data imbalance is to incorporate more unique observations from the minority class. However, gathering more observations of rare events is inherently time-consuming, as it requires collecting a large amount of data to identify a small number of instances in the minority class. In the context of our Tweet data, researchers would have to manually code 100 comments just to find 5 uncivil comments that can be incorporated into the training process. 8
We propose that scholars use Perspective API to locate comments that are most likely to be classified as uncivil. While toxicity and incivility do not perfectly overlap, comments that are assigned a higher toxicity score are also more likely to be uncivil. Indeed, comments that were identified as uncivil by human coders had an average toxicity score of 0.32, while comments that were classified as not uncivil had an average toxicity score of 0.13. By filtering observations that are unlikely to be uncivil, Perspective API can reduce the manual coding associated with developing a high performing classification model.
To test our approach, we develop a training dataset for Tweets whose scores were above the median threshold. The 2017 official tweet review set contained about 7115 tweets—or 11.2% of the total sample. For the 2020 data, this process left us with over 10,485 tweets above the cutoff for further review or 9% of the total sample. 9 Teams of human coders independently reviewed the tweets above the median cutoffs, identifying tweets they believed to not qualify as uncivil. Two coders assessed the 2017 review set, coding 500 tweets in common so that intercoder reliability could be assessed. There was 88% agreement (Brennan and Prediger = 0.75). Five coders reviewed the 2020 review set. About 4% of tweets were coded in common. Among the commonly coded tweets, there was about 84% agreement (Brennan and Prediger’s = 0.67). Disagreements were resolved through discussion.
We begin by evaluating how effectively Perspective scores reduce the manual coding required to build a high-performing classification model. We compare the proportion of tweets characterized by incivility in the dataset used to assess the performance of the toxicity scores with the dataset consisting of all tweets above the median threshold (Figure 1). In both cases, the dataset filtered by Perspective had a higher proportion of tweets characterized by incivility. For the 2017 tweets, the proportion of uncivil tweets increased from 4% to 12%, meaning scholars would need to manually code only one-third as many tweets to obtain the same number of uncivil examples. The reduction in manual coding was even more pronounced with the 2020 tweets, where the proportion of uncivil tweets jumped from 8% in the original dataset to 40% in the Perspective-filtered dataset. Proportion of tweets Labeled uncivil in pre- and post-perspective data.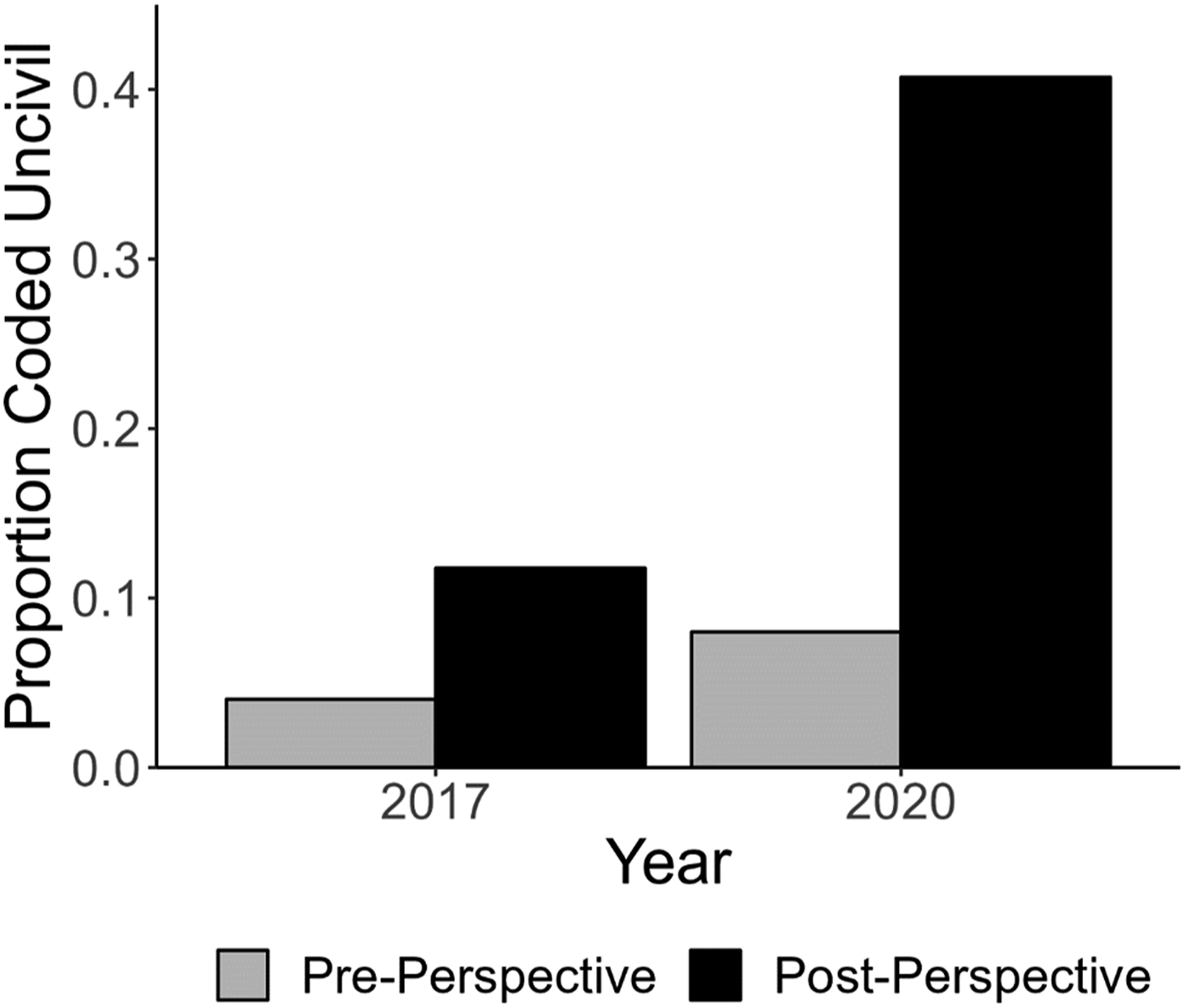
Next, we examine how altering the balance of the dataset influences the performance of a custom classification model in identifying incivility. We combine both the 2017 and 2020 datasets to increase the size of the training dataset. Since our goal is to create a classification model that can identify incivility in all tweets, we create a test dataset of tweets that consists of 15% of all tweets in the student coded dataset used to assess the effectiveness of toxicity scores (478 tweets). We then created two different training datasets. The first dataset, which we refer to as the benchmark dataset, consists of all remaining tweets used to assess the performance of toxicity scores (2706 tweets). The second dataset, which we call the perspective supplemented dataset, consists of all tweets in the benchmark dataset and all tweets with a toxicity score above the median values in the 2017 and 2020 datasets labelled as uncivil (9193 tweets).
To assess how variation in the underlying data influences the model’s performance, we use the same architecture to create our classification models. For both datasets, we employ a transformer-based approach to developing a custom classifier, which has been shown to outperform existing bag of words and word embedding approaches in classification tasks (Wang, 2023; Widmann & Wich, 2023). 10 As with the perspective scores, the transformer-based classification models output a probability that a comment is characterized by incivility. To compare each model’s performance, we generate precision-recall curves, which provide a comprehensive view of how each model balances precision and recall across different thresholds. Across each threshold, the model trained on the Perspective supplemented dataset outperforms the model trained on the benchmark dataset. To evaluate the improvement in model performance using the Perspective-supplemented dataset, we calculate the area under the precision-recall curve (AUC-PR) for each model. The model trained on the Perspective-supplemented dataset achieved an AUC-PR of 0.86, compared to 0.29 for the benchmark model, indicating better balance between precision and recall across different thresholds.
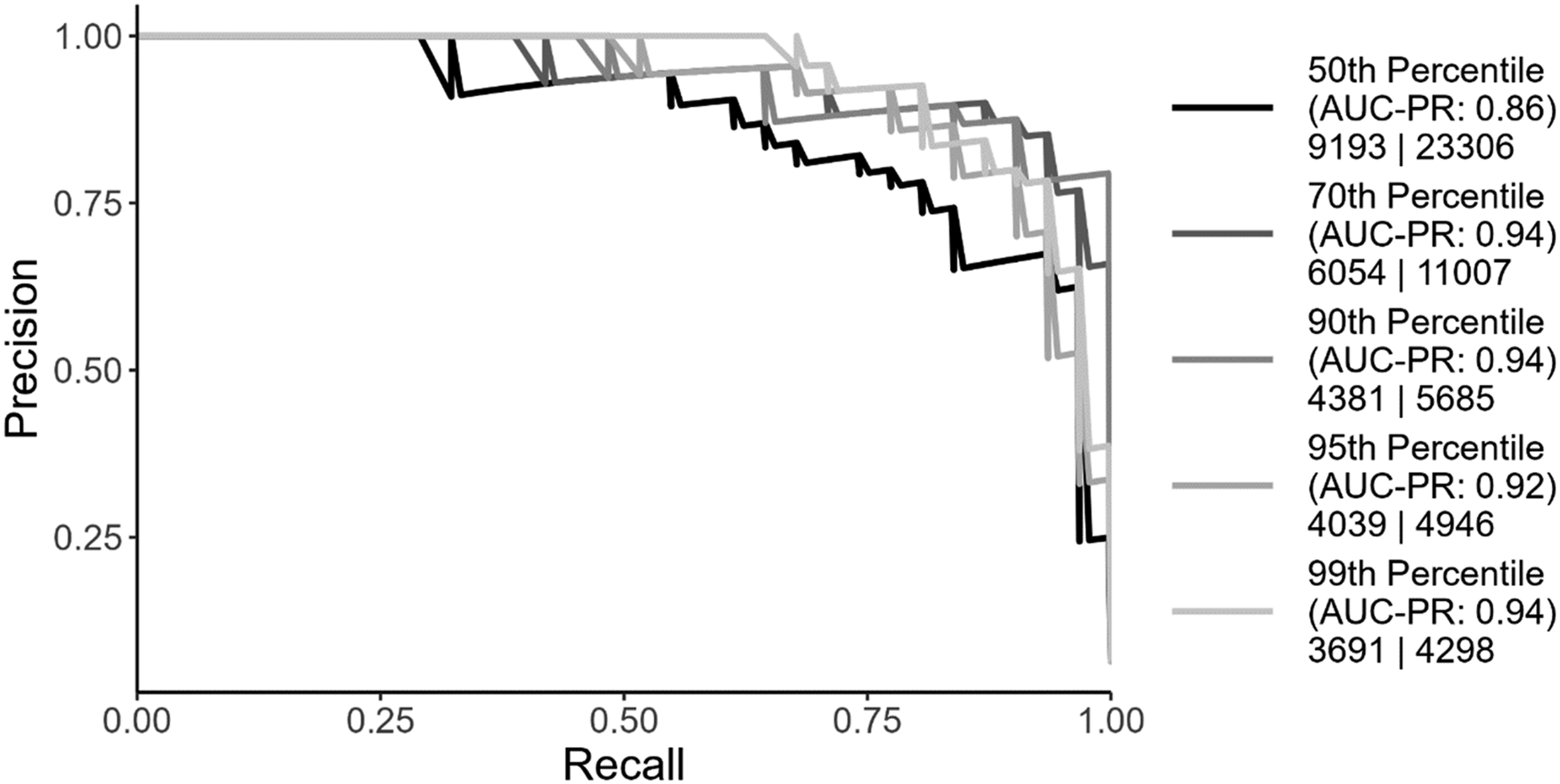
While Figure 2 demonstrates how the hybrid approach significantly improves performance over existing methods for handling imbalanced data, developing the training dataset required considerable effort, with students manually coding 23,306 tweets. To explore how reducing the manual coding workload impacts model performance, we retrained the model using datasets filtered at various thresholds of Perspective toxicity scores. Specifically, we trained models using datasets that included only tweets with Perspective scores in the 50th, 70th, 90th, 95th, and 99th percentiles of toxicity.
11
We then compared each model’s performance using precision-recall curves (Figure 3). Reducing the size of the training dataset did not significantly affect model performance. In fact, the model trained on tweets in the 90th percentile of toxicity achieved the highest AUC-PR of .94. Notably, this model required only 5685 manually coded tweets, compared to the 23,306 tweets required for the model trained on the median threshold. Model performance on benchmark and perspective supplemented datasets. Model performance trained on supplemented datasets by toxicity thresholds.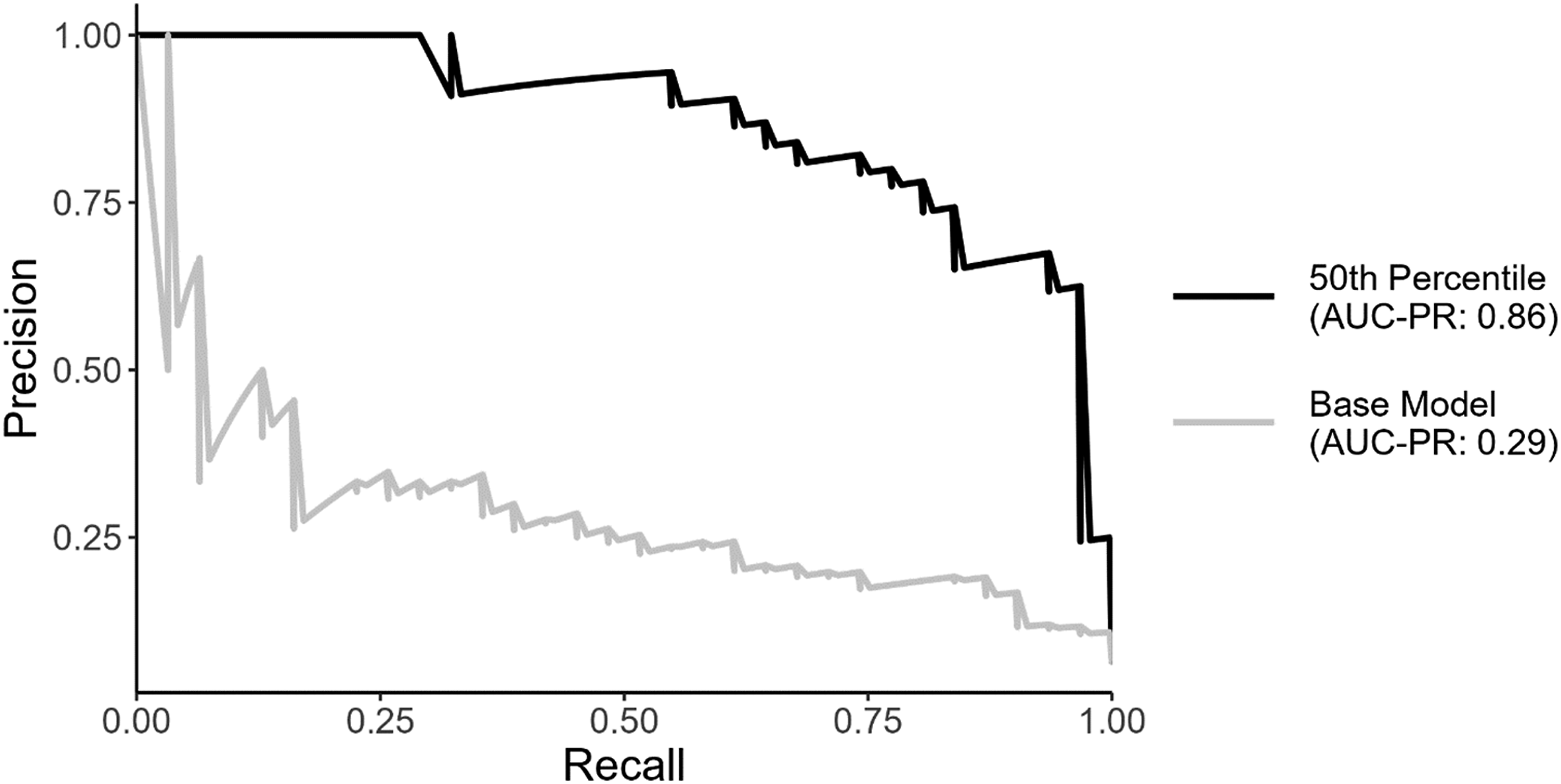
Dictionary and Hybrid Performance Comparison.
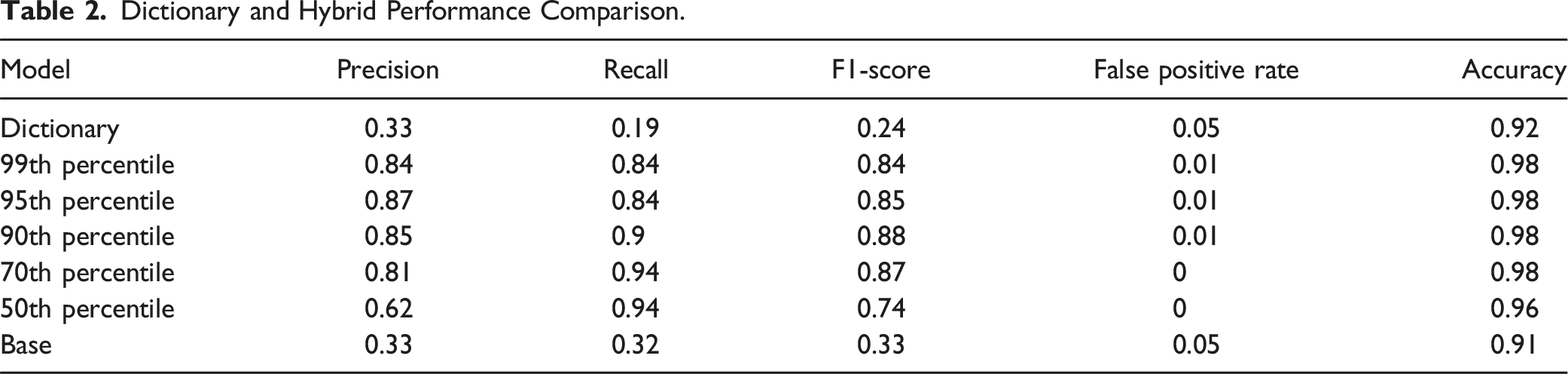
Summary and Recommendations
Our analyses indicate that relying on raw toxicity scores generated by Perspective API to measure political incivility is not appropriate, particularly when they are used to comment on American partisan polarization. As our analysis of congressional tweets show, using perspective toxicity scores in isolation will produce a dataset where many of the tweets identified as toxic in the dataset are not uncivil. Additionally, a dataset on uncivil tweets developed from toxicity scores may miss instances where the politician was being uncivil, but comparatively less toxic. Therefore, datasets relying on perspective toxicity scores in isolation will fail to effectively capture the concept of incivility, making it an unreliable foundation for analysis.
Despite the inability of Perspective toxicity scores to create a reliable dataset of incivility, we argue that the Google’s Perspective API still has utility in assisting scholars in developing a more robust custom model to identify incivility. We introduced a hybrid approach that uses perspective toxicity scores to mitigate the challenges associated with developing a custom classifier on imbalanced data. By using toxicity scores to filter out comments that are unlikely to contain uncivil language, scholars can develop a model that is more effective at identifying incivility than existing approaches to mitigating problems caused by imbalanced data. Moreover, the amount of additional data that requires human review can be further minimized by the manual coding on the highest percentile of toxic comments.
In light of our findings, we recommend researchers who wish to use Perspective to measure incivility do the following: (1) randomly select a benchmark set of comments for human coding; (2) if satisfactory intercoder reliability is achieved, generate toxicity scores for the entire corpus; (3) using the benchmark set, identify comments that have the highest probability of being uncivil based on their toxicity score; (4) train a custom classification model using the benchmark dataset supplemented with the additional positive instances of incivility identified during review (5) repeat steps 3 and 4 moving to lower thresholds of toxicity scores in step 3 until the researcher is satisfied with the model’s performance.
While out-of-the-box models like Google’s Perspective toxicity scores may not perfectly align with political science concepts, our results provide evidence that they can greatly reduce the effort needed to create accurate and comprehensive datasets. Emerging tools like Jigsaw’s Detoxify, Pysentimiento, and Hugging Face’s Toxic-BERT are becoming more sophisticated and accessible for analyzing toxicity, incivility, and negative sentiment. By combining these tools with custom approaches, researchers can streamline data collection and annotation, allowing them to focus more on refining their analysis and less on manual coding. This advancement in NLP tools has the potential to significantly improve the quality and efficiency of research, particularly in areas of political science dealing with imbalanced data.
We offer one final, broader, recommendation. While we have laid out a strategy for leveraging existing tools to measure political incivility, it is worthwhile for scholars to consider the importance of this concept relative to the measure of toxicity. While a good deal of theory concerns incivility, the latter may be just as (or more important) in the study of digital communication. We encourage conversation among political communication scholars on the advantages of favoring incivility over toxicity as a focus of research.
Supplemental Material
Supplemental Material - Incivility or Invalidity? Evaluating Perspective API Scores as a Measure of Political Incivility
Supplemental Material for Incivility or Invalidity? Evaluating Perspective API Scores as a Measure of Political Incivility by Bryan T. Gervais, Connor Dye and Amber Chin in American Politics Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.