
Abstract
The growing work on causal modeling has produced as one key insight that we should not give a causal interpretation to estimates of controls. We should only interpret the treatment effect of interest. I show that this guidance that is valid for treatment effects is not necessarily valid for case selection in mixed-methods research when cases are selected based on their residuals. The effect of a control variable needed to identify the treatment effect may not itself be identified. While unproblematic for treatment effect interpretation, the resulting bias undermines the role that residuals are supposed to play for case selection. Guided by the distinction between good, bad, and neutral controls, I explain what identification assumptions must be met in mixed-methods research to use residuals for case selection. I present practical guidance on how to perform residual-based case selection in mixed-methods studies.
Introduction
Work on causal modeling has significantly contributed to an enhanced understanding of the assumptions that must be met to identify a causal effect (Hernán and Robins 2025: ch. 7; Pearl and Mackenzie 2019: ch. 1). The distinction between mediators, confounders, and colliders has highlighted the importance of building causal models and making the correct choices about including variables in a regression model (Elwert 2013; Keele 2015). Two related insights are: (1) we should not give a causal interpretation to the estimates of control variables; and (2) the identification strategy should focus on the treatment of theoretical interest (Keele et al. 2020). In this article, I extend the discussion to identification challenges in mixed-methods research that meets two criteria: (1) it integrates a quantitative analysis with case studies and chooses cases based on residuals; and (2) it allows us to make causal inferences about effects and mechanisms. This neither implies that all mixed-methods research is of this type, nor that all research should be of this kind.
The article is aimed at mixed-methods researchers who want to use such a design because it is the best strategy for answering their research questions and researchers with a methods-driven interest in mixed-methods studies. The goal of this extension is two-fold. First, I want to raise awareness for the extra identification challenges that residual-based case selection faces in mixed-methods research. Second, I propose steps that empirical researchers can follow to enhance case selection in their work.
My focus is on designs in which control variables are used in the quantitative analysis to prevent confounding, which is the rule in observational research and not uncommon in quasi-experimental work (Dunning 2008:45, 263). I use the familiar terminology of “control variable” or “control” as one subtype of adjustment strategy for identification purposes (Keele et al. 2020). For residual-based case selection, the requirement is that they do not absorb bias originating from the quantitative analysis. I argue that guidance available for the identification of treatment effects and avoidance of bias is unlikely to guarantee that the residuals do not reflect a bias. What is a good or neutral control for effect estimation (Cinelli et al. 2022) may be a bad control for case selection. The choice of cases based on their residuals is more complex and demanding than the current guidance on case selection indicates.
In the following, I first discuss residual-based case selection in MMR and the types of cases that I focus on. Types of Controls and an Empirical Example introduces the necessary causal-modeling terminology for a discussion of identification challenges of residual-based case selection in the subsequent sections. The final section concludes.
Case Selection Based on Residuals
In residual-based case selection, the size of a residual is assumed to be informative about the type of research that we can perform on a case and the insights that we can derive from it (Lieberman 2005). Typical cases have a sufficiently small residual. It does not matter here how we define and operationalize sufficiently small (see Rohlfing and Starke 2013). They are assumed to be useful for testing hypotheses about the causal mechanisms that produce the causal effect and for generalizing the results if the test is passed. Deviant cases have a large residual. They are assumed to offer insights about how the analysis can be improved, including evidence for the omission of a confounder from the statistical model.
There is no guarantee that small-residual and large-residual cases are suitable for what they are chosen for because of case-specific factors that are likely to feed into the residuals (Hertog 2023). With the available information, it is the best guess that we can make in the case selection stage. A review of 25 mixed-methods studies with regard to the chosen types of cases indicates that typical and deviant cases are dominant (Appendix section A Types of cases in mixed-method articles). The pathway case is a third type of case that appears to be selected less often, but is discussed in detail in work on mixed-methods designs (Gerring 2007; Weller and Barnes 2016). The pathway case is determined by comparing the residuals between a full and a reduced regression model. The reduced model omits the treatment variable from the full model that is used to estimate the treatment effect. The differences between a case’s residual in the full model and the reduced model is interpreted as a case-specific estimate of the treatment effect, the pathway case being the case with the largest difference. Multiple proposals have been made for the calculation of the difference, which is irrelevant here (Gerring 2007; Weller and Barnes 2016).
One requirement for residual-guided case selection is that the residuals only represent the effects of non-systematic variables (noise) that can be ignored and do not absorb a bias, for example because of omitted confounders (Hertog 2023; Rohlfing 2008). If bias was present and reflected in the residuals in addition to noise, it would cease to be informative for case selection. For a case with a small residual, we would not be able to tell whether it is well predicted because the causal and statistical models are well constructed, or because the bias accounts for a small residual that would be large if there was no bias in the analysis (a false-typical case).
Hertog (2023) speaks of false-positives/false-negatives and type-I/type-II errors in relation with the potentially wrong choice of cases for case-specific reasons that account for small or large residuals. For illustration, suppose we select a false-typical case and assume that it is useful for collecting evidence on a mechanism connecting cause and effect. We will be able to find evidence for some mechanism that produced the outcome, which is naturally present because of intentionally choosing a case with the expected outcome in place (Lieberman 2005), and generalize it to other typical cases (Seawright and Gerring 2008). When the case is a false-typical case, we would incorrectly generalize a case-specific mechanism to other cases for which the false-typical case is not representative. In an empirical analysis, we cannot know whether a typical or deviant case is a false-positive or true-positive. The goal of a study must be to minimize the chances that a bias undermines the interpretation of the residuals, which requires a discussion of causal models and types of controls.
Types of Controls and an Empirical Example
The quantitative analysis in a mixed-methods study can follow a design-based or a model-based approach to causal inference (Keele 2015). For the case selection discussion, the question that cuts across these distinctions is whether the statistical model includes control variables for which one estimates effects that are used to compute residuals. In a model-based approach relying on a regression model and selection on observables (Keele 2015), it is very likely that we work with control variables. In a design-based approach, we include covariates when there is reason to believe that as-if random assignment to the treatment is unlikely to be fulfilled based on the research design alone (Dunning 2008:ch. 8). In the following, I focus on model-based mixed-methods research because it usually involves controls that are the core of the problem for case selection. A second reason is that the argument not to interpret effects for controls variables has been made for model-based research.
The discussion of the challenges of residual-based case selection is anchored in two triple distinctions of terms familiar from causal modeling. The first one is the established distinction between confounders, mediators and colliders (Rohrer 2018). A confounder is a variable that is a cause of the treatment and outcome of interest. A mediator lies on the path from the treatment to the outcome. A collider is a variable that has two causes—i.e., their effects collide in this variable. Understanding the role of these types for case selection requires the second distinction between good, bad, and neutral controls (Cinelli et al. 2022). The three terms have been used to determine whether the use of a control is needed for a variable to identify a treatment effect (good); introduces a bias (bad); or neither removes nor introduces a bias (neutral), but may increase the efficiency of the estimator when being included. In an empirical analysis, the task is to designate variables as good, bad, and neutral controls based on causal models (directed acyclic graphs, DAGs) to decide whether a variable should be included in a statistical model to identify the treatment effect (assuming the absence of other potential problems).
A review of 25 articles that implement residual-based case selection shows that “confounder,” “mediator,” and “collider” are rarely explicitly used (Appendix Section B). None of the articles presents a DAG as the easiest way to decide about controls. Seven of 25 articles address confounding, or mediation, or both. No article mentions the concept of a collider. The lack of a transparent causal modeling framework in the reviewed mixed-methods studies indicates an increased likelihood that the identification requirements for neither the treatment effect nor the residual-based case selection are met, and that there is much room for improvement in this regard. The results are similar to the review of standalone quantitative research reported in Keele et al. (2020).
In the following, I use a study on the effect of education on communal violence and the underlying mechanisms to illustrate identification requirements for residual-based case selection (Lange 2012). The interest is in the total effect of education on communal violence. It is hypothesized to work via four mediators, each associated with a distinct mechanism. I designate one of the nine variables as a confounder and eight as neutral controls (for details on the theory and variables, see Appendix Section C). Each of the following sections addresses a different type of control—good, bad, neutral—and starts with a brief discussion of identification challenges for effect estimation. This is the template for extending the discussion to case selection.
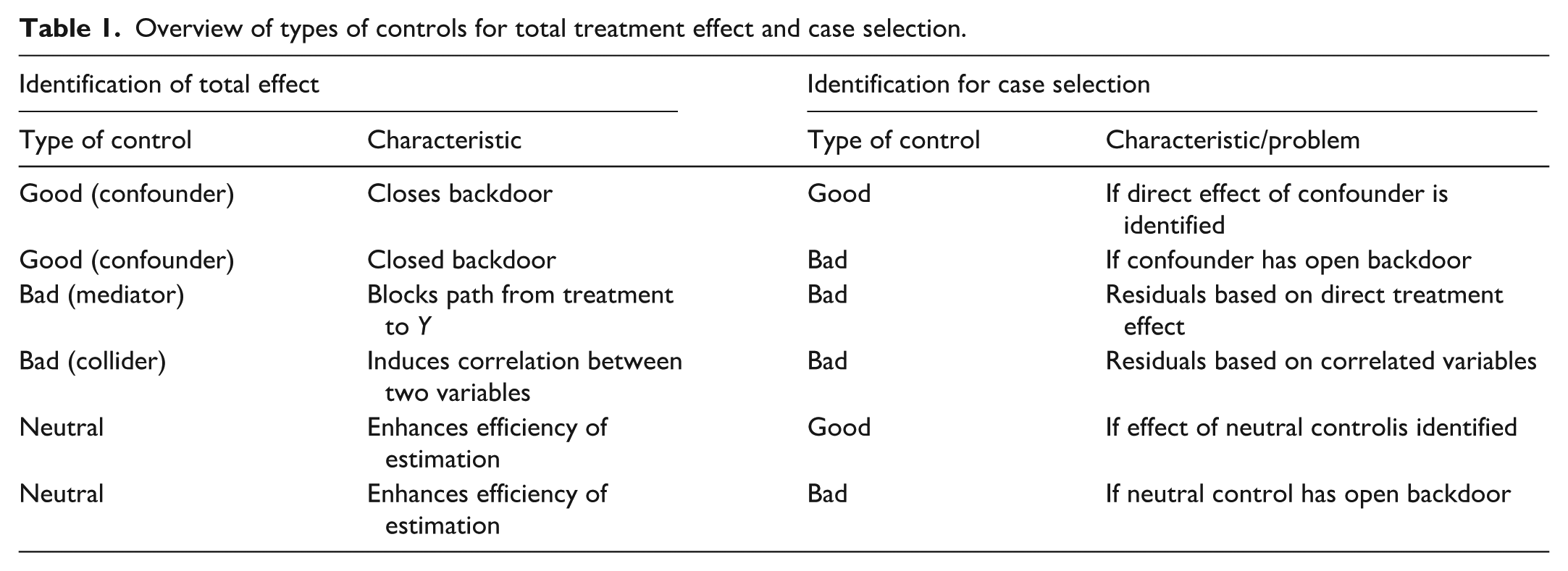
The main arguments are summarized in Table 1. The left half of the table presents the distinction between good, bad, and neutral controls for effect identification and their characteristics. In the right half, I summarize the arguments about the conditions under which a certain control for effect identification is a good or bad control for the choice of cases. Figure A.1 in the appendix blends the empirical example that is used in the following sections with the general arguments presented in Table 1.
Overview of types of controls for total treatment effect and case selection.
Good Controls for Effect Identification
A Good Control That Is Identified
A prerequisite for the identification of the total effect of education is the absence of open backdoor paths from the treatment to the outcome. Let’s assume that communism is a common cause of education and communal violence. One explanation could be that “communist regimes generally have relatively high rates of education” (Lange 2012:41). The effect of communism on violence could be explained with communism suppressing local conflicts (Cornell 2002) and democratic movements, potentially causing backlash. The control for communism closes the backdoor path and allows one to identify the effect of education, making it a good control (Cinelli et al. 2022; Rohrer 2018).
The interpretation of the confounder in the regression model is complicated by the fact that the treatment education lies on a path from communism to violence. Based on the assumption that researchers are usually not interested in the direct effect of a control, it has been argued that the effects of controls should not be interpreted causally (Keele et al. 2020). For case selection, the implication is that the treatment effect and the direct effect of the confounder are unbiased. A good control for treatment effect estimation would then also be a good control for case selection if no other identification challenge exists for communism. The calculation of the residuals based on the confounder’s direct effect is not a problem for case selection. We choose cases to gain insights about the mechanisms that underlie the total treatment effect, not the total effect of the confounder.
This feature of confounders is related to an additional problem that only pathway cases have and that distinguishes them from typical and deviant cases. The choice of pathway cases is problematic because different types of confounder effects are identified in the full and reduced models. The confounder’s total effect is not identified in the full model because the treatment variable is on a path from the confounder to the outcome. This is a direct implication of being a confounder that is included to close a backdoor for the treatment. In contrast, the total effect is identified in the reduced model that lacks the treatment and opens the previously blocked path. This makes any available measure of the residuals’ differences between the full and reduced models a composite of the treatment effect plus the confounder’s indirect effect. This composite measure is invalid for the choice of pathway cases because their residuals are supposed to only reflect the case-specific total treatment effect.
A Good Control That Is Not Identified
The strategy of closing all backdoor paths from the treatment to the outcome is not automatically sufficient for meeting the requirements of residual-based case selection. The direct effect of a confounder is not identified when it has an open backdoor path of its own. For example, we could argue that social and economic inequality and associated class cleavages are causal for the occurrence of a communist regime and the outbreak of communal violence. Communism would still be a good control for treatment-effect identification, but a bad control for case selection because the resulting bias would be reflected in the residuals. The backdoor from the confounder communism to the outcome communal violence must be closed by what can be referred to as a second-order confounder. In Appendix Section D, I present simulation results illustrating that open backdoor paths of second-order confounders have consequences for the identification of first-order confounders, and that this can have sizable consequences for case classification as a prerequisite for case selection.
The identification challenges for case selection do not stop with second-order confounders because any open backdoor path induces bias and undermines the interpretation of residuals. A second-order confounder would have to be reevaluated with regard to open backdoor paths that we may need to close with a third-order confounder. How often this step must be repeated depends on the causal relationship and theory of interest. Taken together, this shows that even if the effects of confounders are substantively and theoretically irrelevant, we must ensure that the direct effects are identified for case selection.
Bad Controls for Effect Identification
Controlling for a Mediator
A mediator is a bad control if the research interest is in the total effect of education on communal violence because it blocks a path from the treatment to the outcome. This interest is in the total effect in the illustrative study, which takes a broad perspective on the effect of education and four mechanisms that connect it to the outcome (Lange 2012:ch. 1). If the interest is in the total effect of education, residuals must be calculated based on the total treatment effect and not just the direct effect that is identified when a path is blocked. This implies that a bad control for the identification of the treatment effect is also bad for case selection. If the interest is in a specific direct effect and the associated mechanisms instead of the total effect and all mechanisms, it follows that we need to add mediators to the regression model because now they are good controls. This illustrates the general point that the status of any variable as a good, bad, or neutral control for effects estimation and case selection depends on the research interest and the variable’s place in the causal model (Cinelli et al. 2022).
Imagine, for example, that the interest is in the mediator identities. We would have to determine a mediator for each of the other three paths that have been theorized and use them as control variables. If the four theorized paths cover all possible paths between education and communal violence, we would be able to identify the indirect effect of education that runs through identities. The estimate for the direct effect would indicate the quantitative importance of this path (Acharya et al. 2016:517–18). The residuals would be calculated using the direct effect, which is now intended, and would indicate which cases are typical or deviant with regard to this path.
Controlling for a Collider
A collider induces an association between two causally unrelated variables that are causal for the collider (Elwert and Winship 2014). The fact that a collider opens a path between two causally unrelated variables makes it a bad control for treatment effect identification. By implication, a collider is also a bad control for case selection because the calculation of residuals would be based on non-identified effects. Treatment effect identification and case selection can be enhanced by one of two means. First, we do not control for the collider. Second, if there is a reason for conditioning on a collider, we have to close the path again that the collider opened. This can be achieved by controlling for two variables for which the collider induces a non-causal association (Pearl and Mackenzie 2019:ch. 9). Based on my reading of the theory in Lange (2012), there is no collider involved in the analysis.
Neutral Controls for Effect Identification
A variable is a neutral control if its inclusion in the regression model neither induces a bias nor helps in preventing it. One added value of a neutral control is to increase the precision of the estimate for the treatment effect (Cinelli et al. 2022). Another reason for adding neutral controls is to perform a comparative hypothesis test. A neutral control for the identification of the treatment effect undermines case selection when the effect of the control is not identified because of an open backdoor path. In the substantive example, for the neutral control total population a backdoor path could run through country size. The size of a country is causal for its population size and can plausibly have an effect on the outcome. Smaller countries tend to be ethnically more homogeneous and have a reduced risk of violence. When a neutral control has an open backdoor path, we need to add second-order and, possibly, higher-order controls, as may also be necessary for good controls.
The potential need for higher-order controls begs the question of whether a neutral control is worth the extra effort. When we include a neutral control to increase the precision of the estimate, we may first consider alternative steps that will achieve the same goal. When the research interest is in comparative hypothesis testing, we may not include the variables representing alternative theories in one model. Instead of dealing with the identification challenges of the treatment and neutral controls in a single analysis, we may create separate causal models per theory and examine the identification assumptions separately.
Conclusion
In the presence of identification challenges, residual-based case selection can be enhanced and made more transparent by going through the following steps. First, we should be transparent about the identification strategy (Keele 2015:section 3), and develop a causal model. Second, we should decide whether we are interested in the total treatment effect and, potentially, all mechanisms linking cause and effect, or the indirect effect working through a subset of mechanisms. Given this decision and the causal model, the third step is to derive the assumptions that must be met for unbiased case selection. For first-order confounders that are necessary to identify the treatment effect, this requires asking whether they have open backdoors that need to be closed. These are the minimum requirements for integrated case selection. Fourth, we may consider adding a neutral control to the analysis for theoretical or statistical reasons. The comparative analysis of theories has its virtues, but we should consider whether the theoretical value added outweighs the potential drawbacks, since any neutral control may pose additional identification challenges. Fifth, we need to decide which types of cases to select for qualitative analysis. Both typical and deviant cases share the requirement that all variables must be identified. Pathway cases have the additional, currently unresolved problem of estimating different types of effects for full-model confounders in the full and reduced models.
Theoretical uncertainty or data limitations may make it unlikely, or outright impossible, to satisfy all identification assumptions for residual-based case selection. Empirical researchers have multiple strategies for addressing the identification challenges. They can embrace the uncertainty about the interpretability of the residuals. It is acknowledged in mixed-methods work that the quantitative analysis can be imperfect, with consequences for the next steps of the analysis (Lieberman 2005:442).
The issue that remains is a circularity problem (Rohlfing 2008): We select cases with residuals that are of uncertain value for model-testing or improvement because they are calculated based on at least one non-identified effect. In response to this problem, we can implement a multistage mixed-methods design with several iterations of the quantitative and qualitative analysis that possibly offers a gradual improvement of the causal model (Galvin and Seawright 2023).
A multistage analysis and iterative improvements have been originally suggested for mixed-methods designs using typical and deviant cases (Lieberman 2005:437). This indicates that iteration is available for all types of cases and selection strategies, not only propensity-adjusted case selection (Galvin and Seawright 2023). The better the causal model is at the outset, the fewer iterations are needed to determine all the identification assumptions that must be made and met for case selection. A causal model can guide iterative improvement by making transparent the uncertain elements of the theory that may introduce bias. For example, we may be uncertain about whether a variable is a confounder or a neutral control and focus on that element. In addition, a causal model can indicate the nature of the bias that may exist and whether it is likely to lead to overestimation or underestimation of the treatment effect.
In a formalized version of the “embrace uncertainty” strategy, we can try to assess the direction of the bias and perform a sensitivity analysis for unmeasured confounding (Cinelli and Hazlett 2020). In principle, an assessment of the direction of the bias is valuable because the bias, or biases in the case of multiple confounders, may be negligible or cancel each other out, on average. Except for simple settings, it seems difficult to derive analytically how confounding affects case selection. A complementary strategy is to implement a sensitivity analysis that would simulate the degree of confounding that would be necessary to overturn the case selection based on the estimated model. In contrast to a sensitivity analysis for the treatment effect, a robustness assessment for case classifications is likely to be more complex because, given a DAG, we may have to take multiple and different sources of confounding into account.
An alternative to embracing uncertainty is a case selection protocol that does not rely on residuals. At the design level, this would require the substitution of interactive for the independent choice of cases and case selection criteria that do not necessitate unbiased effects for variables other than the treatment. This could be the extreme-case strategy (Seawright 2016), or any other criterion such as substantive or theoretical importance (Koivu and Hinze 2017). Although this strategy would come at the expense of a less tightly integrated quantitative and qualitative analysis, it would put case selection for the case studies on safer ground from an identification perspective.
Supplemental Material
sj-docx-1-fmx-10.1177_1525822X261437572 – Supplemental material for Identification Requirements for Residual-based Case Selection in Mixed-methods Research
Supplemental material, sj-docx-1-fmx-10.1177_1525822X261437572 for Identification Requirements for Residual-based Case Selection in Mixed-methods Research by Ingo Rohlfing in Field Methods
Footnotes
Acknowledgements
I am grateful for the comments of three reviewers. Nancy Deyo provided valuable editorial assistance.
Ethical considerations
This article does not report any studies involving human participants, human data, or human tissue. Ethical approval was therefore not required.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.