
Abstract
The free-list method has enjoyed a remarkably productive history, yet most free-list research is limited to informal comparisons that are heavily reliant on point estimates such as item or cultural salience. Here, we demonstrate a range of methods to incorporate uncertainty into such group-level estimates. This approach involves: (1) resampling individual-level data (via bootstrapping or Bayesian regression) to create a range of hypothetical alternative samples; (2) generating group-level estimates (e.g., Smith’s S) in each sample; and (3) using the variation in these estimates as uncertainty intervals. While we focus predominantly on cultural salience, this approach can be applied to other free-list metrics. We also present some extensions to this approach, such as comparing estimates between items and between groups. We provide open data and code to help readers gain familiarity with these methods. Ultimately, we encourage researchers using free-list data to move beyond simply reporting point estimates.
Introduction
As socially transmitted representational content stored in human minds (Boyd and Richerson 1988; D’Andrade 1981; Sperber 1996), culture and cultural data are central to the social sciences. Ethnographic free-listing is a common method for soliciting naturalistic, content-rich, ecologically valid cultural data about a target domain (Quinlan 2005). Many metrics exist that reveal and examine the important properties of culture that free-list data contain, but few applications incorporate uncertainty into their analyses (Purzycki 2025).
In a nutshell, free-listing entails that participants list things they associate with some topic (e.g., features of heavy metal music, ideal partner qualities, or all the teas they know; see Table 1). While the content and frequency of items tells us a lot about what people think, as the items individuals list are ordered, free-list data also contain important structural properties (i.e., how people think). As such, free-listing can bridge between qualitative and quantitative data and is uniquely catered to examine the content and structure of cultural models.
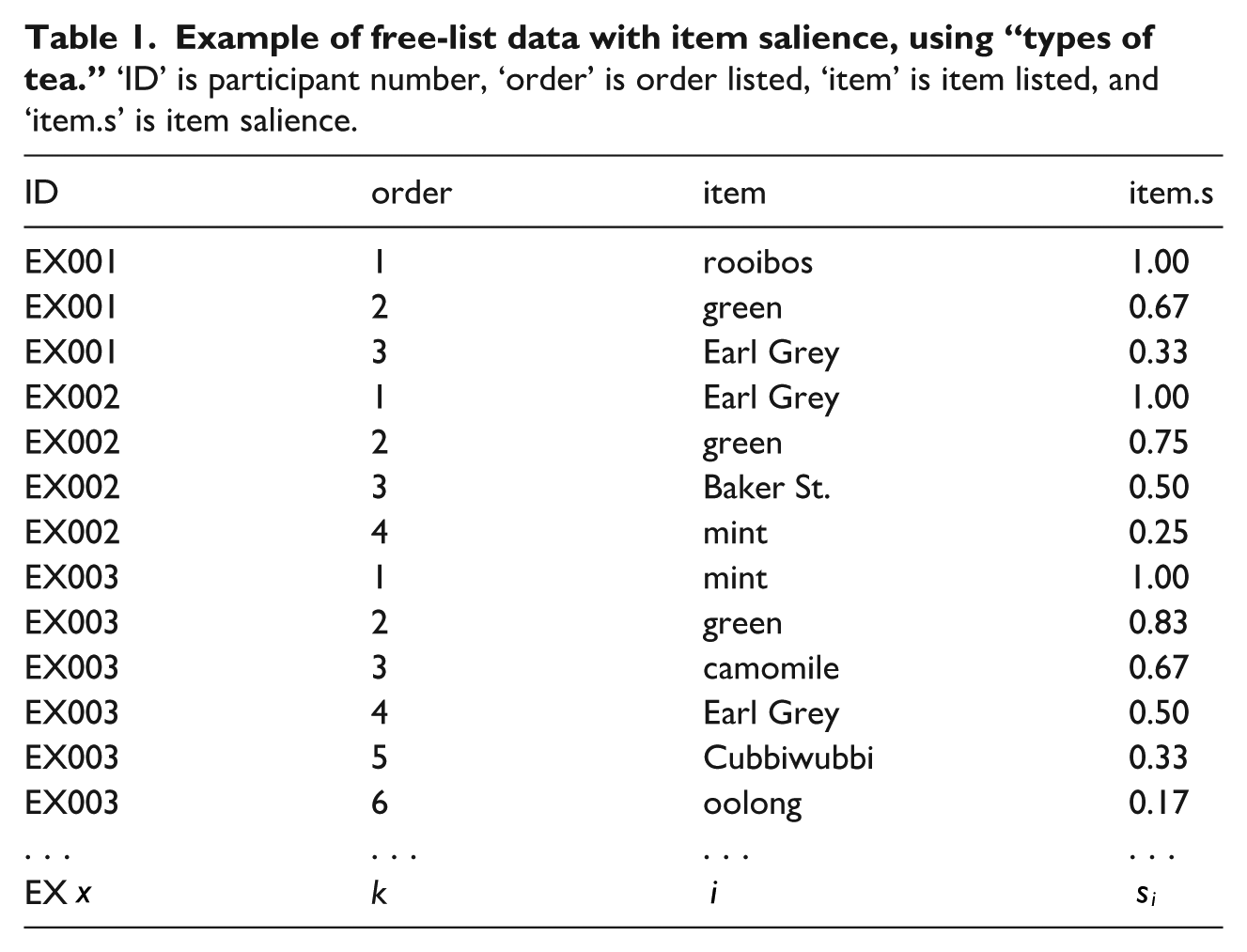
A key metric in free-list data is item salience,
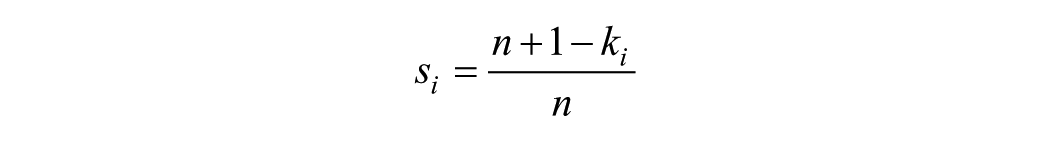
Here, the first-listed items always have an
These item saliences scores can then be used to examine cultural salience. Cultural salience (Smith and Borgatti 1997) bridges the gap between individual cognition and cultural distribution. A common way to calculate this is Smith’s S (see Sutrop 2001):
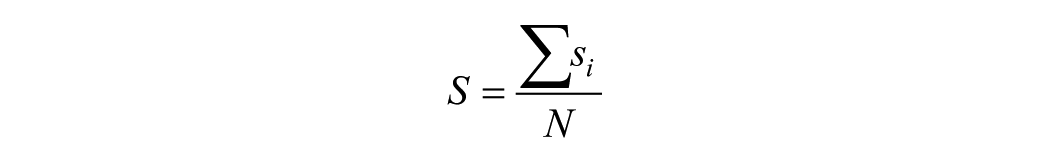
where
Researchers tend to report salience scores descriptively, and make informal comparisons with them (e.g., “This item is more salient than that one” or “Item X is more culturally salient for Group A than for Group B”). Yet analyses and interpretations that rely on point estimates can be unreliable and potentially misleading in a few key ways.
First, such analyses lack formality and rely on researcher intuitions and biases (however reasonable and correct they might be), rather than some principled and reproducible method. If an item, for example, had a salience score of 0.7 and another was 0.6, we must rely on our own hopes and interpretations to render a judgment about how different these items’ salience scores are.
Second, point estimates do not tell us how likely we are to get similar results if we repeated the study, providing a false sense of precision. A Smith’s S score of 0.30 from one sample could change to, say, 0.21, 0.17, 0.32, or 0.38 with other samples from the same population. Relatedly, point estimates do not provide any information regarding uncertainty; for instance, a Smith’s S of 0.5 in a large sample would be estimated with greater certainty than the same value in a smaller sample. Statistics like confidence or credibility intervals give us a better sense of how replicable and uncertain our point estimates are (Gelman and Greenland 2019).
Given these issues, making comparisons, contrasts, predictions, and causal estimates are severely hampered without embedding these salience scores into some principled approach that incorporates uncertainty into these estimates. Despite this, studies using free-list data frequently only report point estimates. Although recent case studies (Bendixen and Purzycki 2025; Purzycki et al. 2020) bring free-list data and their properties to bear in a probabilistic regression framework as outcome (i.e., dependent) variables, there remains a dearth of uncertainty estimates in purely descriptive and comparative studies. This article offers a few methods to address this lacuna.
Propagating Uncertainty
To make more principled descriptions and comparisons, then, we need uncertainty intervals (Gelman and Greenland 2019) around indices like Smith’s S. There are a few ways to do this.
One common way to generate uncertainty is to bootstrap (Efron and Tibshirani 1994). This involves randomly sampling a set number of observations with replacement from a sample (i.e., each observation is returned to the sample for potential resampling), then reporting the desired quantile values (e.g., 0.025 and 0.975 for the conventional 95% interval). This approach is simple and does not require declaring any particular distribution. Hence, it works regardless of the observed values. However, because it makes no distributional assumptions, the approach lacks any generativity that allows us to make inferences beyond our sample. In sum, while bootstrapping might be the simplest approach, it lacks principle and may be somewhat limited in use.
Another way is to calculate uncertainty intervals using a regression framework. Regression requires us to model the estimate using a particular distribution. While one could use either frequentist or Bayesian approaches, here we focus on Bayesian methods for three main reasons: (1) the interpretation of Bayesian credible intervals is more intuitive than frequentist confidence intervals; (2) many of the relevant distributions and situations we may wish to model are currently only available in a Bayesian framework (e.g., zero–one inflated Beta and ordered Beta models; discussed below); and (3) Bayesian models allow us to incorporate information regarding our knowledge and/or assumptions about the data (i.e., priors). For introductions to Bayesian regression, including best practice guidelines, exploring the assumptions of priors and convergence diagnostics, see Gelman et al. (2020) and McElreath (2020).
In the next section, we briefly introduce some options for propagating uncertainty around item and cultural salience scores. We then turn to an application and discussion with real data. To help readers replicate, understand and adapt these methods, full data and analysis code are available on our accompanying
Methods
Because it has dedicated software for both processing free-list data and statistically modeling estimates like salience, the following analyses are conducted exclusively using R software (R Core Team 2023). To illustrate our steps and analyses, we use a public data set (used in Purzycki and Bendixen 2020) collected in the Tyva Republic, the southernmost Russian republic in Siberia. In this example, we analyze free-list data of what it means to be a “good Tyvan person” (n = 86) using the AnthroTools package (Purzycki and Jamieson-Lane 2017). To propagate uncertainty around salience scores, we first need to prepare the data and perform salience analyses.
Salience Analysis
First, we calculate item salience (similar to Table 1), then generate a participant-by-item table using the maximum item salience values for all items listed by participants, with values of 0 for items not listed. Steps to prepare this are shown in the companion code and associated preprint (Major-Smith and Purzycki 2025).
Methods for Propagating Uncertainty
To generate uncertainty around such indices, we can: (1) resample the individual-level item salience data to create a range of hypothetical alternative samples; (2) generate the group-level estimate (i.e., Smith’s S) in each sample; and (3) use the variation in these estimates as uncertainty intervals. For step 1, this can be achieved either via bootstrapping, or modeling the data distribution via intercept-only Bayesian regression models.
A key consideration when modeling data, especially when the aim is prediction, is to use a distribution that (broadly) matches the observed data and the data-generating process. Many of these will be familiar to most readers: Gaussian/linear models for normally distributed data, logit/logistic models for binary data, Poisson models for count data, and the like. Many outcome variables fall into these familiar groups, but for free-list item salience data it is less clear. For instance, in our example dataset, the raw data for the item “hard-working” clearly has a nonstandard distribution (see Supplementary Figure S1). The bulk of the data are at zero (i.e., people who did not list hard-working in their free lists), with a range of item salience values above zero and up to one. Given these nonstandard distributions, we focus on three methods for modeling such free-list data: bootstrapping, zero-one inflated Beta, and ordered Beta.
As discussed above, bootstrapping randomly samples with replacement from the observed data a specified number of times. By randomly sampling participants’ salience values for a given item (including 0s for items not listed), we can then calculate cultural salience in each sampled dataset (which we denote as
Two such generative methods are the “zero-one inflated Beta” (ZOIB) distribution (Bendixen and Purzycki 2025; Liu et al. 2020; Ospina and Ferrari 2012) and the “ordered Beta” distribution (Kubinec 2022), both of which are mixture-models (i.e., models that include multiple generalised linear regression sub-models bundled together) which allow us to model such data with values between 0 and 1 (inclusive).
Briefly, the ZOIB has four parameters that describe its shape. Two parameters (the “mean” and “precision”) define the “Beta” function, which model the distribution of values in the range
The ordered Beta distribution is somewhat simpler and potentially more intuitive than the ZOIB model, as there are fewer parameters to estimate (Kubinec 2022). Rather than four independent processes operating at once, the ordered Beta only has two main parameters corresponding to the mean and precision terms of a standard Beta model. However, rather than model the 0 and 1 processes independently (as per the ZOIB), the ordered Beta combines these together in an ordinal model, with cut-points denoting the boundaries at 0 and 1.
Both distributions are suitable for modeling item salience data, although the ordered Beta model contains fewer parameters, so is somewhat more parsimonious. Both models can also be adapted to handle situations where no 0s and/or 1s appear in the data (see companion code).
Once we have our posterior predicted samples of our ZOIB or ordered Beta distribution, we can simply create the Smith’s S value in each posterior sample (again, denoted as
Worked Example
In this section, we take the modeling approaches outlined above and show how they can work to propagate uncertainty in cultural salience estimates. We focus first on simply describing single free-list items with uncertainty, followed by describing multiple items, then making comparisons between free-list items, and finally incorporating these approaches in a regression framework to compare items between groups (e.g., whether cultural salience differs by sex). Given space constraints, R code to follow along and replicate these analyses can be found in the companion code and associated preprint (Major-Smith and Purzycki 2025). The companion code demonstrates how to calculate these manually, along with functions in AnthroTools (Purzycki and Jamieson-Lane 2017) that automate many of these processes.
Description of Single Items
First, we continue with the example above of Tyvan hard-working values, comparing results using bootstrapping, ZOIB, and ordered Beta. For reference, in our dataset, the Smith’s S for this item is 0.31. For the Bayesian models, we use the default non-/weakly-informative priors (using more informative priors does not alter these results). For bootstrapping, the median
Description of Multiple Items
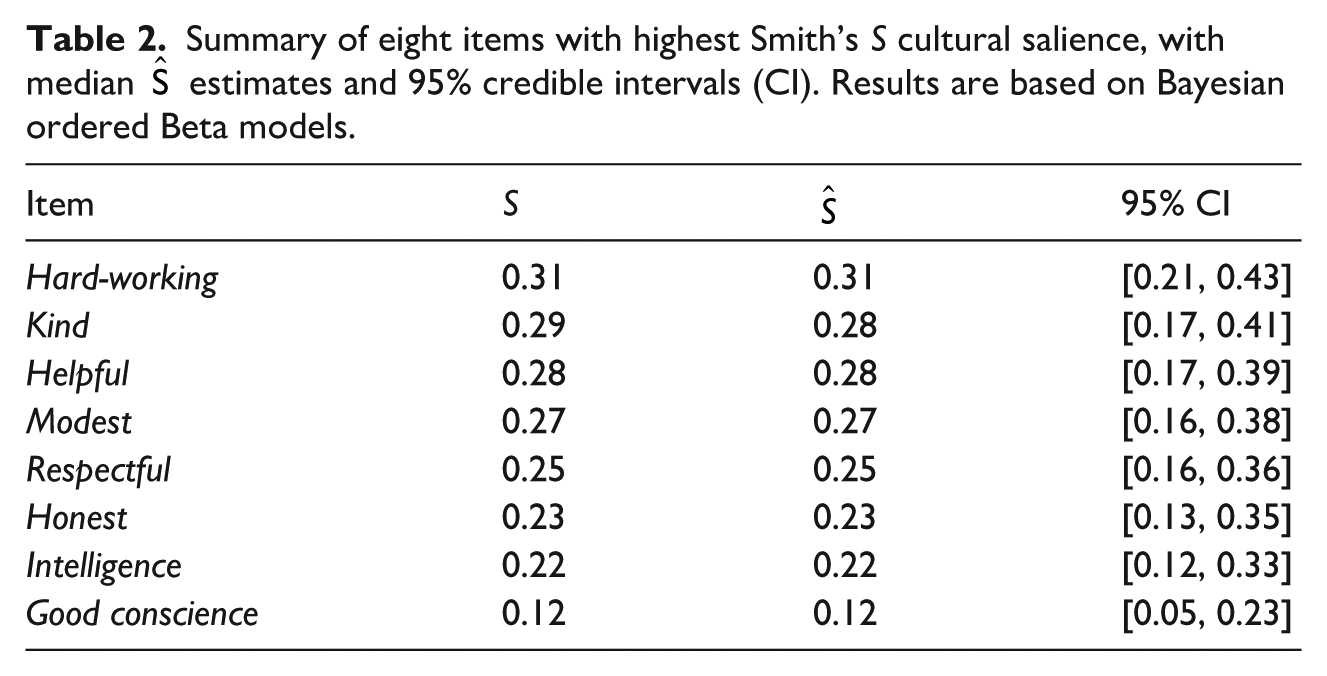
Of course, most salience analyses consist of assessing multiple items. To do this, we can simply repeat the steps above to calculate
Summary of eight items with highest Smith’s S cultural salience, with median
In addition to numerical tabular results, we can present this uncertainty graphically. We could use “flower plots” (often used for summarizing free-list cultural salience data), with the uncertainty intervals displayed in the text of the “petals” (Figure 1). Alternatively, we could plot the posterior distributions of
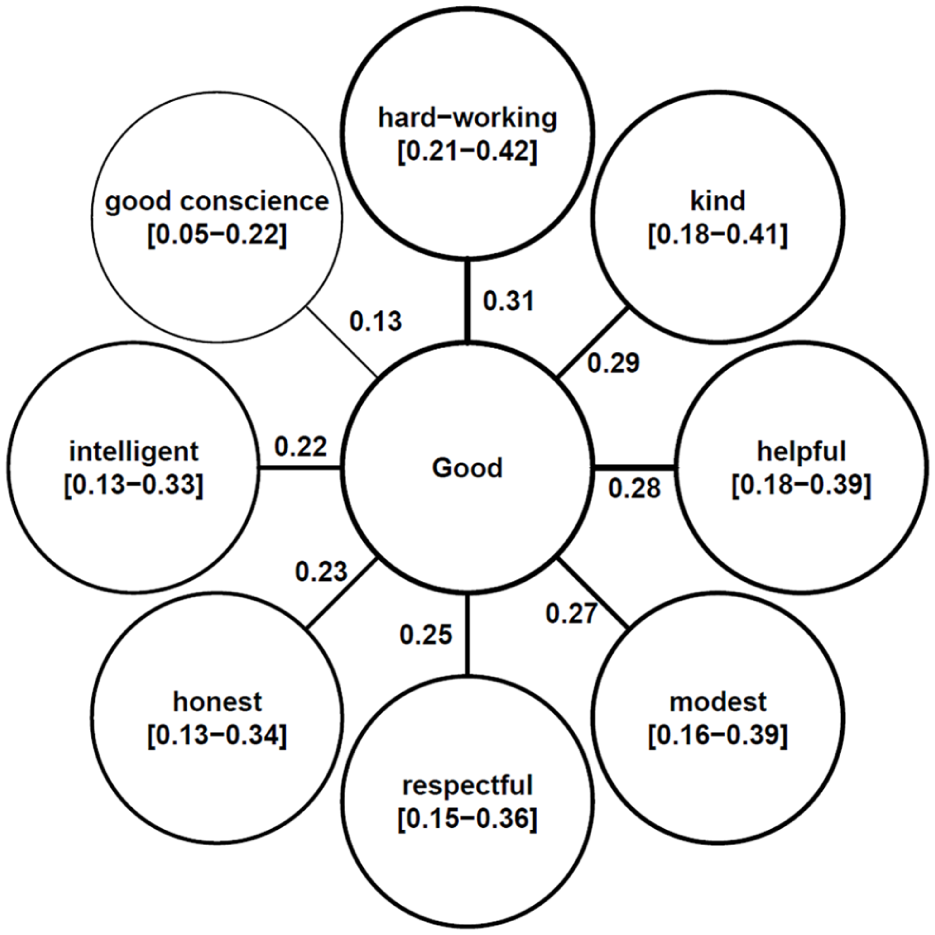
Flower plot of
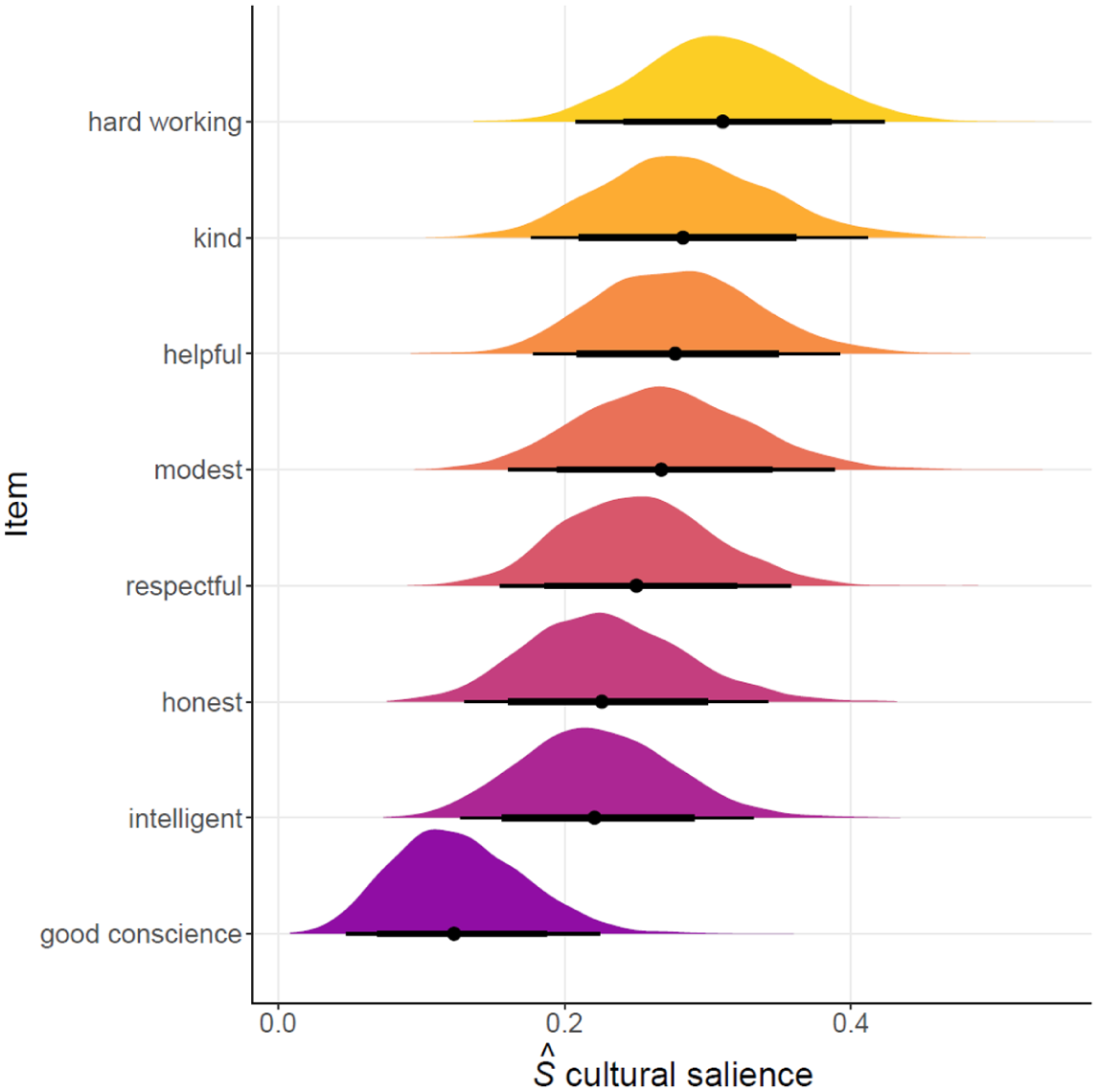
Posterior probabilities with 95% (thin) and 80% (thick) credible intervals of
Regardless of the presentation method, we can thus say, for instance, that hard-working is more likely to be listed sooner and more often than good conscience as the bulk of their probability masses do not overlap. We might even suggest that these seven most salient items constitute the core cultural model here by virtue of a strong overlap in the cultural salience intervals across these item types.
Comparison across Items
The above is definitely an improvement over ignoring uncertainty intervals but still leaves comparisons of cultural salience between items somewhat subjective. A simple extension to the method above would allow us to model these differences more formally. In other words, rather than simply presenting the predicted
Say we wanted to assess whether hardworking differed in cultural salience from the other items. Results of this with 95% credible intervals are shown in Table 3 (again focusing on ordered Beta models, with bootstrap and ZOIB contrasts in Supplementary Table S2), with the full distributions of contrasts summarized in Supplementary Figure S3. Based on these results, despite differences in
Contrasts in

Comparisons across Groups
In this section, we compare whether Smith’s S differs across groups. This can be done one of two ways: (1) using the intercept-only (or bootstrapping) approach above, split by group; or (2) including the group as a covariate in a regression framework. As the latter approach is more flexible (e.g., we can incorporate continuous predictors, not just categorical ones), this is the approach we focus on here (both approaches are demonstrated in the companion code).
As an illustrative example, we explore whether Tyvan good character traits differ by sex (n = 84; males = 33), focusing on kindness. From previous research, we know that this does differ (Purzycki and Bendixen 2020), with its cultural salience higher among female Tyvans (
The companion code and preprint (Major-Smith and Purzycki 2025) demonstrate how to include sex as a predictor variable in an ordered Beta model (it is easy to adapt this to a ZOIB model). Based on this model, the median
Discussion
Researchers using free-list data in any way beyond describing the sample and data should consider calculating uncertainty, particularly for cultural salience estimates. Otherwise, they run the risk of getting a misleading picture of what people think. This article has shown a range of methods to do this, all of which give broadly similar results. Importantly, these tools facilitate bringing free-list data into a greater predictive, generative, and/or explanatory statistical framework (Purzycki 2025). While some of these models may appear rather complicated, we hope that this introduction—in conjunction with the companion code and the availability of associated software—will help encourage their use going forward.
We believe that the methods detailed in this article will greatly strengthen research using free-list data. However, they are not a panacea and there are a number of open avenues for further research. First, the focus here has been on Smith’s S cultural salience; while the overall approach of incorporating uncertainty into group-level estimates will be similar, this approach needs to be explored and extended to other useful metrics for free-list data analysis and beyond. We provide two examples of this in the companion code, first for calculating Jaccard’s similarity and conceptual overlap between domains, and second for cultural
Second, this approach of modeling uncertainty in group-level estimates can be extended beyond the simple demonstrations here when conducting cross-cultural work. For instance, researchers could incorporate this group-level uncertainty in cultural salience as a predictor in regression models (for similar approaches, see Koster et al. 2016; Purzycki 2025; Purzycki et al. 2018).
Third, as described in the introduction, a key benefit of Bayesian approaches is the ability to incorporate our prior knowledge (i.e., priors) into our models. However, throughout this article we have predominantly focused on default weakly-informative priors for simplicity. While these often suffice, they may not do so in all circumstances (especially for more complex models), and if researchers have strong background information, this knowledge ought to be used (for guidance on selecting, testing, and exploring priors, see Gelman et al. 2017; Lemoine 2019; McElreath 2020).
Finally, we modeled cultural salience for each item independently. This overlooks the reality that a change in the ordering of kindness (say) will impact the item salience—and hence cultural salience—of other free-list items. Although a more principled approach, it is much more conceptually and computationally demanding but it may be an area to explore in the future (e.g., modeling each person’s original free-list data, including the items, order, and number of items listed, then deriving item salience and cultural salience from this, factoring in the uncertainty throughout the entire process). A further future development could entail modeling uncertainty of item co-occurrence (e.g., a la social network analysis; Borgatti et al. 2018) to understand the conceptual relationships between cultural items (see Purzycki 2025).
In sum, we strongly encourage researchers using free-list data to include uncertainty estimates in their studies. This will improve the kinds of inferences we can draw about human cultural models. We hope approaches such as those demonstrated here encourage researchers to incorporate uncertainty when analyzing free-list data as a matter of course, as well as develop future extensions to the approach outlined here.
Supplemental Material
sj-docx-1-fmx-10.1177_1525822X251379224 – Supplemental material for Modeling Uncertainty around Free-list Cultural Salience Scores
Supplemental material, sj-docx-1-fmx-10.1177_1525822X251379224 for Modeling Uncertainty around Free-list Cultural Salience Scores by Daniel Major-Smith and Benjamin Grant Purzycki in Field Methods
Footnotes
Ethical Considerations
This submission only uses previously collected, openly available data.
Consent for Publication
Not applicable.
Author Contributions
Both DM-S and BGP contributed to all stages of this submission, including conceptualizing, analysis, visualization, project management, and writing/revising.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was made possible by a grant from the Templeton Religion Trust (#TRT-2022-31107). DM-S is also supported by the John Templeton Foundation (grant ref 61917).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.