
Abstract
In qualitative comparative analysis, as with all methods, there is a question about how many cases are needed to make an analysis robust. In deciding on the number of cases, a key consideration is the number of conditions to be analyzed. I suggest that adding cases is preferable to dropping conditions if there are too many conditions relative to the number of cases. I first consider the relationship of low n and limited diversity, followed by an exploration of two scenarios: (1) cases in the study are the universe; (2) more cases could exist. I suggest that a simple rule or benchmark on how many cases to include in relation to the number of conditions is unlikely to be helpful since this depends at least in part on the goals and circumstances of the research. Finally, this issue is not confined to QCA but affects all types of research.
Introduction
In qualitative comparative analysis (QCA) (Ragin 1987, 2000, 2008), as with all methods, the question arises of how many cases are needed to make an analysis robust (on robustness, see Skaaning 2011). A key consideration is the number of factors (or conditions, as they are usually called in QCA) to be analyzed. (Throughout this article, I use both terms: “factors” to make general points and “conditions” in the QCA context. Thiem and Mkrtchyan (2023a) (hereafter TM) use “factors,” Marx and Dușa (2011) (hereafter MD) use “conditions.”
The question of how many cases are needed is not often put explicitly by QCA researchers in their published work (see, e.g., Ide and Mello 2022; Wagemann et al. 2016, for critical reviews of published QCA studies). Instead, in small n research, the set of cases to be analyzed is often taken as a given by the particular circumstances of the research, whereas in large n research, the question does not appear to arise at all, since it is simply assumed that hundreds or thousands of cases will be enough (though sampling is a key issue). Small n QCA analyses, in the tradition of case study research, sometimes include the universe of cases. While deciding which cases form the universe (i.e., defining the population) is a difficult question in its own right (Ragin 2000:chap. 2, 2006), once it is settled, there is no further question of whether the cases included are typical or representative in some way for the population since they already form the population. In many other (small and large n) analyses, however, the cases included in the study are not obviously the population. Instead, they are a sample taken from some underlying population, and there will have been reasons for including them in the study. These may include the attempt to make the sample representative in some sense, restricted resources, or simply convenience. As with cases, the question of which and how many conditions to include in one’s study is one for which there cannot be any fixed rules. Instead, the theoretical background to the research, previous studies, putative causal mechanisms, and the researcher’s judgment as well as practical considerations and constraints all play a part.
Questions concerning sample size, case-to-factor ratios, case selection, and selection of factors are not unique to QCA. Quantitative researchers deal with them by, for example, considering sampling techniques and undertaking power analyses, whereas qualitative researchers—again, unless they study a population, however defined—also must decide on the number as well as the type of cases to be included in their analyses (e.g., Small 2009).
Decisions concerning the number of cases and of factors to be included in one’s study are related: It seems intuitively plausible that the more factors are to be analyzed, the larger the number of cases should be, and, indeed, for QCA, MD have proposed benchmark tables as guidance on the number of cases in relation to the number of conditions. Thus, they suggest that the number of cases is not to be decided in isolation, but that the number of conditions to be studied needs to be taken into account. The question can take two forms: (1) how many cases are needed in relation to the number of conditions; or (2) how many conditions can be used given the number of cases. While these two appear to come down to the same thing—and of course they do in numerical terms—there is a difference: Phrasing the question as pertaining to the number of cases suggests that there is a pool of possible cases to include in a study and, given a fixed number of conditions, a decision must be made about how many of them (and which ones) to study. Asking about the number of conditions given a fixed number of cases suggests that the number of cases is constrained somehow, for example, because the cases we want to study constitute the universe, or because data have already been gathered and it is not possible to collect data on more cases, so there may be limits on the number of conditions that can be included in the analysis. In this article, I largely focus on the former scenario, where the number of conditions is fixed but the number of cases is potentially variable.
To my knowledge, there has been no systematic attempt, either before or since MD’s article was published, to provide guidance on this issue. However, I suggest that it may not be helpful to provide fixed benchmark tables for case-to-conditions ratios. How many cases and how many conditions may be included depends on a number of characterics of the study, among them the question of whether the cases studied are the universe or a sample from a population, and theoretical considerations. I will argue that some numerical analyses and considerations are helpful, but that, ultimately, judgment is required to make the decision. Concerning MD’s (2011) benchmark tables, TM have demonstrated a number of serious flaws with MD’s approach.
To summarize TM’s argument, one of their key criticisms is that MD base their benchmark tables on whether the data producing a putatively causal model could have been generated by a random process. But whether data could have been generated randomly is not a suitable criterion for assessing whether any pattern found in these data is causal. “First, every set of data generated by any proper causal structure can always be duplicated by an identical set of data generated by a purely random process. Demanding that a method abstain from inferences when the data could be non-causal is, therefore, futile” (Thiem and Mkrtchyan 2023a:2). See also Lieberson (1985:93): “[I]t is always possible to generate an equation—a complicated one, to be sure—that can completely and totally fit any function whatsoever. In other words, if pairs of X and Y values are obtained through a series of random numbers, Taylor’s theorem in differential calculus states that it will be possible to generate a function that will fit this set except under certain specified conditions” (but see Dușa and Marx 2023, for a response, and Thiem and Mkrtchyan 2023b, for a reply to the response).
However, my concern is not merely with MD’s specific approach, nor with TM’s criticism of it. The latter have focused on dropping conditions from a study with a fixed number of cases, a potentially problematic course of action that may result in underspecified models, whereas my concern is largely with changing the number of cases given a fixed number of conditions (being aware that it will not always be possible to add cases to an existing study). By choosing this focus, I privilege obtaining a model less likely to be underspecified (provided all relevant conditions were included in the first place). Thus, the challenge is finding a sufficient number of appropriate cases given the number of conditions. Accordingly, instead of providing a critique of either MD or TM, I wish to encourage a wider debate on how to think about the number of cases needed in a study, merely taking these authors' work as my starting point. To do so, I first discuss the relationship of the case-to-conditions ratio and limited diversity, the latter being a topic which has received much more attention to date than case-to-conditions ratios, before working through two scenarios: (1) the cases included in the study comprise the universe of cases (i.e., no more cases could exist); and (2) more cases could and do exist. Throughout, I illustrate my discussion with examples. I close with a discussion of the key points.
Case Numbers and Limited Diversity
While I am largely in agreement with TM’s criticism of MD, there is one point that, in my view, does not maybe receive enough attention from them. Having demonstrated the flaws with MD’s approach, they appear to suggest that a low number of cases in relation to the number of conditions is not a problem. (For example, in their conclusion they note that “we have demonstrated that there is nothing in the algorithmic machinery of QCA that puts an upper limit on the number of exogenous factors given a certain number of cases” (Thiem and Mkrtchyan 2023a:12). While this technically true, it is practically true only if the cases to be studied constitute the universe of cases, or if any other cases within the scope of the study do not differ in relevant ways from the cases already in the study, as I will show). I discuss two reasons why this may be overly dismissive since, on the contrary, low n can indeed pose a problem for the analysis. One reason is the relationship of low n to limited diversity (this section), the other is that, I argue, their argument applies only to situations where the cases included in the study constitute the universe (a situation I discuss in the next section). By contrast, if more cases could and do exist than have been included in the study (two sections ahead), things are more complicated.
Limited diversity is when some of the possible configurations that result from the combination of conditions in a study have no cases (i.e., there are some empty truth table rows). There is no agreement as to the best approach in this situation, but limited diversity cannot simply be ignored since a choice has to be made on how to proceed with the analysis to obtain a Boolean solution (e.g., Dușa 2019; Glaesser 2022; Haesebrouck 2022; Ragin and Sonnett 2005; Thiem 2019). Cooper and Glaesser (2016) and Thomann and Maggetti (2020), among others, note the connection between limited diversity and low n: Reducing the number of conditions and/or increasing the number of cases in a study are remedies that alleviate or resolve limited diversity as well as improving case-to-condition ratios.
Thomann and Maggetti (2020) suggest it might be better to think of the cases-to-conditions ratio problem as a cases-to-configurations problem. Of course, the two are just two ways of looking at the same problem since number of conditions and number of configurations are perfectly related, with number of configurations = 2number of conditions for binary and fuzzy conditions. But it may help researchers, as part of exploring their data, to work out the number of possible configurations resulting from the number of conditions they wish to analyze to get a sense of the possible extent of limited diversity. Five or six conditions may seem like a modest number, but the resulting numbers of configurations are 25 = 32 and 26 = 64, respectively. So, if there were, say, 20 cases—a not unusual number seen in published QCA studies—this will leave 12 or 44 empty rows even if all cases were spread evenly across the configurations which usually they are not, given that conditions are often interrelated. Even using 64 cases in such a situation would be likely to result in limited diversity for that reason. Given this exponential rise in configurations as a result of added conditions, it is important regardless of the number of cases to limit the number of conditions even with large n. Solutions can become overly complex and difficult to interpret if there are too many conditions, and limited diversity will arise even with thousands of cases.
Thus, in many ways, the problem of low n in relation to conditions is one of limited diversity and the question of to what extent low n is a problem depends largely on whether limited diversity is perceived as a problem. If there are no cases for some configurations, this means that there is no empirical evidence concerning whether such cases would experience the outcome or not (though of course if it is logically or empirically impossible for cases with such configurations to exist, then the lack of such evidence is irrelevant). Interpretability is therefore one of the ways in which this matters: If there is secure evidence from other sources or theoretical knowledge, then this may matter less. If there is little such knowledge, does this affect the validity of the conclusions on the basis of the cases that do exist? To what extent can the results be generalized to cases not in the study? These are the questions researchers could ask themselves in deciding whether low n and the associated limited diversity pose a threat to their research. In Glaesser (2022), I work through some of the possible consequences of limited diversity. In that article, I consider several scenarios, the key difference between them being whether more cases than are included in the study could exist in principle. This is linked to the question of generalizability: If no more cases exist, then this question does not arise since there are no cases to which the conclusions can be generalized. Given the link between low n and limited diversity, I employ the same two broad scenarios again in this article.
No More Cases Could Exist
If the cases included in a study constitute the universe of cases, then a QCA analysis will not produce an erroneous model, since any QCA model based on the universe of cases will represent faithfully the empirical evidence provided by these cases (in situations of limited diversity, this is true regardless of whether a parsimonious, intermediate, or complex solution is chosen). TM employ an example where two cases with different outcomes differ on just one of 30 conditions. To conclude that this condition is causal in producing the outcome is thus supported (though not proven because a regularity view of causation is too narrow, in my view. Put differently, finding an empirical regularity is evidence but not proof of causation) by the empirical evidence, and, what is more, we can assume that no evidence contradicting this conclusion can or will exist, as long as the two cases constitute the universe.
This does not mean, however, that the 29 remaining conditions were all causally irrelevant: The data alone do not tell us what role they played. Consider, for example, striking a match to produce a flame: In two otherwise identical situations, only distinguished by whether a match was struck, we will assign the striking of the match as the flame’s cause. But one of the other factors needed to produce a flame is oxygen. The fact that it is constant across the two situations does not mean it was not causally relevant for producing the flame, but given that oxygen is ubiquitous, we could not have observed its causal role simply by comparing any number of situations (see also Lieberson’s [1985:99] example of gravity). This possibility of a constant cause is not unique to QCA, but it is an important consideration for anyone looking for causal explanations. It is thus a matter of interpretation whether a factor is causal, part of a “causal field” or context factor (like oxygen in the match example), or causally irrelevant. This cannot be decided on the basis of QCA—or any form of empirical analysis—alone.
The example with which I started this paragraph, with two cases differing on just one variable, is the simplest but not the only one to which this applies. If the two cases differ on more than one factor, interpretation becomes more complex: If two factors are identified as potentially causal, we cannot be sure, on the basis of just two cases, whether both were indeed necessary to produce the outcome or whether one would have sufficed (because two binary factors can be combined in four ways, two too many for our two cases). The data are compatible with both interpretations, so theoretical knowledge and knowledge about causal mechanisms is required.
I stress again that the QCA model itself will be correct (as a summary of the truth table, if not necessarily as a causal model), regardless of the number of conditions and cases. However, if the cases are just a sample from some larger population, any model based on the empirical evidence provided by the sample may not just be refined or extended, but it may actually be contradicted by further empirical evidence once the analysis is extended to other cases from the population. This is because the cases in the original analysis may have been unusual in some way, or there may have been measurement error, for example. In the next section, I discuss the possibility that more cases could exist, which is probably more common than the cases constituting the universe.
More Cases Could Exist
As TM, I employ just two cases to begin with, though for simplicity’s sake I consider just three conditions rather than 30. My cases share the absence of condition A, the presence of condition B, and they differ on C: case 1 has both it and the outcome O, case 2 has neither C nor O. The model identified is then simply

Eight Cases.
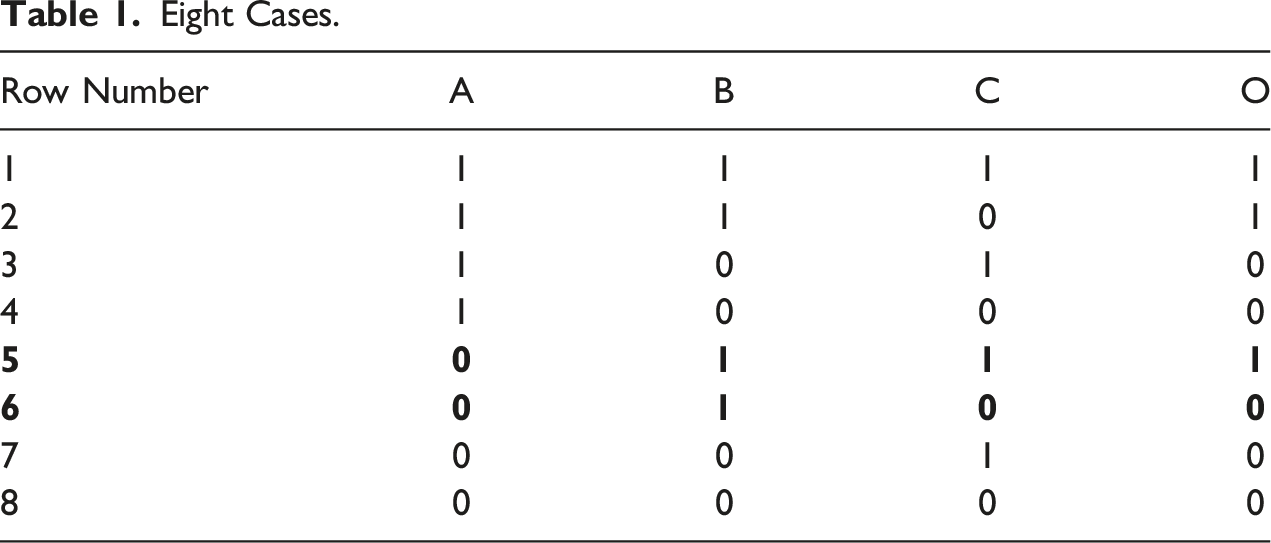
The resulting model is Model 2: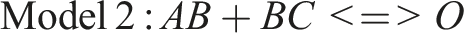
As we can see, it differs from Model 1, but still includes C as part of the solution. Thus, it might be said, using TM’s term (p. 7), to “complete” the original, simpler model (where “complete” only refers to the possibility of adding or dropping conditions, not of adding cases. TM do not comment on the latter.) C, instead of being necessary and sufficient on its own, is now an INUS condition.
Merely having eliminated limited diversity does not mean that the model is now robust. Instead, this depends on the new cases' outcomes. If I were simply to multiply the cases in each row in Table 1, with all new cases showing the same outcomes as the original ones given the same configuration of conditions, the resulting model would always be Model 2, regardless of the factor by which the cases are multiplied, though the confidence in the results presumably would grow with larger n. Consider, however, a scenario where 10 cases are added to each configuration set out in Table 1, with the configurations and outcomes in rows 1 to 4 and 6 to 8 identical to the existing cases but with the 10 new cases in row 5 not having the outcome, unlike the original case. The resulting model is Model 3, with a consistency of 1 and near-perfect coverage. Even keeping the original two cases unchanged, obtaining new information has the potential of changing the resulting causal model completely.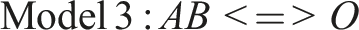
C is no longer part of the model. The original case with the configuration a*B*C was recorded as having the outcome. This may have been due to measurement or recording error, or it may have been a case that was unusual in some way, with some compensatory condition D that led to its having the outcome without having the configuration identified in Model 3. Whatever the reason, we would not consider C as a potentially causal condition based on the 88 cases analyzed in this imagined situation. The eight cases on which Model 2 is based constitute a fourfold increase compared to the original sample of two and there is no limited diversity, but the analysis based on 88 cases suggests that eight cases was not enough to find the “true” model (assuming the 88 do now provide it). Clearly, both the number of cases and their specific combinations of conditions have the potential to alter a putatively causal model. This illustrates the importance of choosing one’s cases well, and of being clear about their scope (i.e., to which other types of cases they are thought to be generalizable).
Up to now, I have focused on eliminating limited diversity by adding cases. Depending on the new cases' outcomes, the resulting models may or may not include the original model as part of their solutions. I now explore what happens if more cases are added but limited diversity is not eliminated. If, as before, I add 86 cases to the original two but, unlike before, all with the same configurations, then Model 1 would remain unchanged. However, we would have greater confidence in it, given the larger number of cases on which it rests (especially if the new cases were spread fairly evenly across the two configurations), even though the extent of limited diversity is unchanged. Presumably, for the same reason, we would also have greater confidence in it than in the model generated by eight cases (Model 2), even though Model 2 is based on data without limited diversity.
To keep things simple, I have used just three conditions in these scenarios. In principle, my points apply to situations with more conditions, but more cases are needed to achieve the sense of confidence in the resulting models, given that so many more possibilities of combining the conditions exist. So far, I have not explained why greater numbers of cases should give us more confidence. To many, this may be intuitively appealing, but it is not necessarily the case that there is a linear relationship between number of cases and degree of justified confidence in the results. The reason why large samples are appealing is that, with random samples, the larger the sample, the more likely it is that the results found in an analysis for the sample would also be found for the population from which it is drawn. However, samples frequently are not random samples of a population. Either the population is not defined in the first place, or, if it is, in many studies the sample employed was not randomly drawn from the population. Depending on how the sample is obtained, biases can exist regardless of sample size, potentially limiting the applicability of the results. Having said that, adding one case can make much more of a difference to the resulting models if the original sample was small compared to adding one to a sample that was already large. From that point of view, results based on large n are more stable, but the problem of biased samples and potentially limited applicability remains.
Discussion and Conclusion
While the issue of low n in relation to the number of conditions is clearly connected to the issue of limited diversity, I have shown that they are not identical. Even if there is no limited diversity, models based on low n may be unstable if the cases they are based on are unusual. This becomes evident when cases are added. Obviously, this only applies if the cases in the original analysis do not already constitute the universe of cases. If they do, then the number of cases is not an issue since any conclusions drawn from the analysis are not intended to—indeed, cannot—be applied to any other cases. Thus, they will be valid (assuming no measurement error or other flaws in the analysis) whatever the number of cases.
Matters are different if the cases studied are a sample of some larger population. Here, a model may be invalidated when more cases are added to the original analysis. It is therefore important to be clear about which kind of situation applies to the study, and, obviously, it is important to consider both how many cases to include and how to choose them. Marx and Dușa (2011) and Thiem and Mkrtchyan (2023a, 2023b) all address the first point, number of cases, and this has also been my main focus. However, it is important at least to note that the second point, the type of case, also matters crucially.
If the solution to the problem of having few cases in relation to the number of conditions is to add more cases, then the same careful attention must be given to how to choose these as when the original cases were selected for inclusion in the study. In large n research, samples are often (rightly or wrongly) taken to be representative of some population from which they are drawn and thus assumed to be appropriate, regardless of the specific goal of the research (as long as the population from which the sample was drawn was identified correctly). By contrast, small and medium n researchers must take greater care in selecting cases in accordance with the goal of their research. Small’s (2009) discussion, while it is concerned with qualitative research and not QCA specifically, is relevant here (see also George and Bennett 2005; Seawright and Gerring 2008). Thus, I recommend making the criteria for case selection explicit, in situations where the cases included do not constitute the universe, since this would strengthen QCA-based research (and any other research).
The next step is to assess whether the number of cases appears adequate given the number of conditions to be studied. If it isn’t, researchers should add more relevant cases to their sample wherever possible, having made explicit what constitutes relevant cases. These steps should inform the scope and limits of the analysis: If more relevant cases cannot be added to the analysis, then researchers must be clear that their conclusions only apply to cases like those in their analysis. Similarly, at the very least, researchers employing QCA should be explicit as to whether the cases included in their research constitute the universe of all possible cases. If so, they should explain how the universe was defined and delineated, also noting the scope and any limits of their analysis.
In this article, I have concentrated on the issue of case numbers to supplement TM’s focus on conditions. Clearly, the two issues are equally important: How many and which conditions to include is one of the key considerations in the design of a study. Theoretical considerations, potential mechanisms, and previous empirical evidence all need to be taken into account. I have argued here that the same is true of cases: How many and which ones to include is relevant for the robustness of the study. TM discuss the dangers of dropping conditions, but of course it is equally possible that, in the course of the research, a researcher is faced with the need to add one or more conditions to refine an existing model. This then again requires an assessment of whether the number of cases already in the study is sufficiently large and, if not, whether more can be added, though it can be impossible to add cases because relevant data are not available and it is not feasible to collect more. It is also worth noting that the greater the number of cases, the harder it is to bring in-depth case knowledge to bear.
In conclusion, I suggest that a simple rule or benchmark as to how many cases to include in relation to the number of conditions is unlikely to be helpful. Depending on the goals and circumstances of the research, a handful of cases may well be all that is needed, whether or not there is limited diversity. This applies especially in situations where all the cases from the universe have been included in the study. In other situations, limited diversity may indicate a problem because not all possible types of cases have been sought for the study. Yet in others, limited diversity in itself is not a problem, for example because certain types of cases do not exist or because they are so unusual that they are not of interest in the particular research context.
Thus, the researcher’s judgment, as ever, plays a key part: The researcher has to understand his or her particular research situation, reasons for any limited diversity, and whether the cases he or she has included constitute the universe or a sample from a population. Judgment is also crucial in deciding how many and which conditions to include. While in some ways this is the flipside of the same coin, it is a different issue that should be considered separately from the case selection issue, though the interplay between the two matters. In addition, pragmatic considerations will always be involved, such as whether it is even possible to add cases, or whether data on additional conditions can be obtained. I hope that some of the issues I have suggested here for consideration will help researchers in their decision-making.
Finally, I want to reiterate that this issue is not confined to QCA. Even in the age of “big data,” researchers must consider carefully not just how many cases they can study—this can be a very large number—but also what these cases' characteristics are. Large samples are often tacitly assumed to be representative of some underlying population, or at least to contain cases of any kind of interest, (see, e.g., Yarkoni and Westfall [2017:1108], who suggest that “The larger a sample, the more representative it is of the population from which it is drawn”), but this assumption may well be too optimistic. Yarkoni and Westfall’s discussion is interesting for our context for a different (though related) reason, however: They suggest large samples as a remedy for “overfitting” (i.e., the danger of obtaining models containing a large number of parameters that fit one data set well but not any other). Yarkoni and Westfall (2017:1119) say: “The critical element in reducing overfitting is the number of observations relative to the number of predictors. Datasets that include thousands of variables but have relatively few cases are, if anything, even more susceptible to overfitting.” This is, of course, exactly the situation MD worry about. To reiterate, this issue clearly is not confined to QCA. It concerns the question more generally of how to deal with the world’s complexity, as expressed through the large number of factors of potential interest, in relation to the number of cases we are able to study.
Footnotes
Acknowledgments
I would like to thank Barry Cooper for his immensely valuable comments on this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.