
Abstract
While numerical bipolar rating scales may evoke positivity bias, little is known about the corresponding bias in verbal bipolar rating scales. The choice of verbalization of the middle category may lead to response bias, particularly if it is not in line with the scale polarity. Unipolar and bipolar seven-category rating scales in which the verbalizations of the middle categories matched or did not match the implemented polarity were investigated in randomized experiments using a non-probabilistic online access panel in Germany. Bipolar rating scales exhibited higher positivity bias and acquiescence than unipolar rating scales. Reliability, validity, and equidistance tended to be violated if the verbalizations of the middle category did not match scale polarity. The results provide a rationale for rating scale verbalization.
Introduction
Surveys are one of the main data collection methods, and survey questions are often presented along ordered response options referred to as rating scales. Multiple indicators (items, questions) with rating scales have the promising property of enabling a theoretical concept to be measured within the frame of Latent Variable Modeling (LVM, Mellenbergh 1994). Empirical research on rating scales has provided many instances of their undesired effects on data (e.g., Krosnick and Presser 2010). When designing rating scales, researchers must make numerous decisions on matters such as number of categories, category labeling, use of middle category, or scale orientation. More research has been undertaken on some of these characteristics than on others (Menold and Bogner 2016).
The number of categories and use of verbal labels are both well researched. Research based on randomized experiments has consistently shown that a moderate number of response categories (five–seven), which are all verbalized, is associated with higher reliability and validity than other realizations (e.g., Gummer and Kunz 2021; Maitland 2009a, 2009b). Researchers have also addressed the effect of rating scales on results in the context of LVM (e.g., Menold and Tausch 2016), demonstrating that seven fully verbalized categories are consistently associated with tenable or high data quality.
When it comes to verbalization, researchers must make a number of other decisions, such as on kind of quantity, scale polarity, and verbalization of the middle category. There is little empirical evidence on which to base these decisions. Researchers need to develop rating scales to measure intensity, frequency, probability, or evaluations, and different possibilities are available for each of these factors (Casper et al. 2020; Rohrmann 1978). Evaluation can be realized as a disagree–agree, false–true or bad–good continuum. Disagree–agree ratings (DA) are very common in questionnaires because they can be used with many different indicators, although their use may lead to acquiescent responding (e.g., Saris et al. 2010). Acquiescence means agreement regardless of the item content (Paulhus 1991). Hence, we would like to provide and evaluate the argument in this article that it is not the choice of agreement rating per se, but its bipolar realization that evokes acquiescence (or similar biases) and that this can be avoided by using alternative unipolar verbalizations. Bipolar rating scales comprise two opposite quantities, such as disagreement and agreement in DA ratings, whereas unipolar rating scales contain only one single quantity, such as agreement ranging from “do not agree” to “agree” (e.g., Krosnick and Presser 2010). Initially, polarity was researched within the frame of numeric rating scales. Bipolar numeric rating scales combine negative numbers “-3”, “-2”, “-1,” the middle “0” and the positive numbers “+1”, “+2”, “+3.” Unipolar ratings, in contrast, contain numbers from “1” to “7” or “0” to “6`” (see Online Appendix A). Bipolar numeric rating scales were found to evoke an acquiescence-similar positivity bias, which is a tendency to avoid choices marked by negative numbers resulting in more positive evaluations (e.g., O’Muircheartaigh et al. 1995; Schwarz et al. 1991). An alternative explanation for the higher acquiescence associated with verbal DA rating scales could therefore be their bipolarity. Respondents might avoid using the disagree part of the scale in a similar way to which they avoid negative numbers. Higher acquiescence or higher positivity bias would be particularly pronounced in bipolar DA scales and not in unipolar alternatives that use do not agree instead of disagree.
Positivity bias and acquiescence are lower in unipolar than in bipolar rating scales. Bipolarity can also negatively affect psychometric measurement quality. Reliability has been addressed by previous research with mixed results. Krebs (2012) found higher Cronbach’s Alpha in bipolar rating scales, while Menold and Raykov (2016) found higher reliability in a unipolar application dimension than in bipolar DA ratings. Researchers also addressed bimodality in bipolar rating scales (Batyrshin et al. 2017), which can additionally affect measurement quality. In the present research, besides reliability, we expect bipolar rating scales to negatively affect validity and equidistance:
Reliability and validity are higher, and equidistance is given in unipolar as compared to bipolar rating scales. Another relevant decision in bipolar and unipolar rating scales concerns how the middle category is verbalized (Höhne and Krebs 2021; Menold 2021). A middle category is frequently used by respondents when it is provided in the questionnaire (referred to middle responding, e.g., Krosnick and Presser 2010), and it has therefore been suggested the explicit middle be omitted (see Menold and Bogner 2016). However, according to Sturgis et al. (2014), respondents use the middle category to express their true opinions. Omitting a middle category can also violate equidistance (Casper et al. 2020). The frequently used labels for the middle category in DA rating scales are “moderately,” “neutral,” “neither–nor,” or “partly–partly.” Are these alternatives exchangeable? Taking polarity and opinion theory into account, some verbalizations have a unipolar, while others have a bipolar meaning. The middle category can be thought of as an expression of indifference or ambivalence (e.g., Kaplan 1972; Yoo 2010). Indifference refers to uncertainty about the decision to agree or to disagree, which is verbally expressed with neutral, or neither disagree/nor agree (short: neither–nor, Kaplan 1972). Ambivalence reflects unstable attitudes or judgments, meaning that respondents would disagree with some aspects, but agree with others. Ambivalence can be verbally expressed with “partly disagree/partly agree” (short: “partly/partly”; Kaplan 1972). Hence, ambivalence and indifference as decisions between two alternatives are compatible with bipolar attitude measurement and are therefore rather more applicable in bipolar rating scales. In a unipolar rating scale, a decision midway between two alternatives is not made. The response decision alters along a continuum ranging from non-existent intensity to an extreme degree of intensity (Kaplan 1972; see Online Appendix A). The corresponding meaning of the middle category is a moderate position or medium intensity. Suitable unipolar verbal expressions for the middle category would be moderately, fairly, somewhat (see e.g., Casper et al. 2020; Rohrmann 1978). This means that neither–nor or partly/partly rather correspond to the meaning “0” (which is present in the middle of a bipolar, but not in a unipolar scale), while moderately or somewhat are hard to associate with “0.” Placing a neither–nor in a do not agree–agree continuum would be tantamount to having a 0 between the numbers 1 to 7. However, researchers are often not aware of the polarity and displace the middle category. Menold (2021) introduced the term mismatching, if a middle category with a unipolar meaning is placed into a bipolar rating scale and vice versa. Examples of mismatched polarity can be easily found in existing surveys, textbooks, or publications of empirical research. The German General Social Survey (GESIS 2019) uses a unipolar rating scale ranging from fully agree to do not agree at all with the bipolar middle neither–nor for different content. In international surveys, mismatching may be due to translation, if, for example, a source bipolar DA scale is translated as unipolar, but the middle category remains bipolar (e.g., ISSP Research Group 2019). We might expect a middle category that stands apart from the remaining continuum to be more strongly attended to by respondents and to result in higher middle responding.
Middle responding is higher in the case of mismatched than matched use of the middle category. Previous research has shown that mismatching reduces reliability (Höhne and Krebs 2021; Menold 2021). The expectation is that the negative impact of mismatching on reliability will be replicated in the present study. In addition, this study evaluates validity and equidistance.
Mismatching leads to a decrease in reliability and validity and violates equidistance as compared with matched rating scales. To summarize, the present research investigates the effect of bipolarity and mismatching in verbalized rating scales with seven categories on response bias and quality of latent variable measurement to help researchers make more qualified decisions with respect to the verbalization of rating scales.
Methods
Experimental Design
To vary the content of questions and the kind of the unipolar dimension, four established multiple indicator instruments were used (Online Appendix B, C). Taken from a Gender Role inventory (Braun 2014), “Parenting” was implemented in experiment 1 and “General Ideologies” in experiment 2. Internal Locus of Control (ILC) and External Locus of Control (ELC) from a German inventory (Bornmann and Daniel 2000) were used in experiments 3 and 4. Data on known correlates (criterions) of Gender Roles and Locus of Control (LC) were collected (Online Appendix F, Table 1) to obtain validity scores.
In each experiment, we varied polarity and matching of rating scales (Online Appendix B, D). All bipolar rating scales were on a DA continuum and ranged from fully disagree to fully agree. For the unipolar versions, an agreement continuum with the range do not agree at all–fully agree was realized in experiments one and three. An application dimension ranging from “does not apply at all” to “fully applies” was used in experiments two and four. Both unipolar realizations are popular counterparts to the DA rating scales and allow more generalizable results.
A limitation of previous research (Höhne and Krebs 2021; Menold 2021) has been that only moderately and partly/partly were compared as middles with unipolar versus bipolar meaning. To extend previous research, we included unipolar moderately and somewhat and bipolar partly/partly and neither–nor (Online Appendix B, D). Moderately (“mittelmäßig”) and somewhat (“einigermaßen”) were evaluated by Rohrmann (1978) as suitable verbalizations of the middle categories for unipolar rating scales. The remaining labels for the bipolar rating scales are incorporated as typically used in surveys (compare, e.g., ISSP Research Group 2019). The remaining labels for the unipolar rating scales were taken from the unipolar intensity dimension developed by Rohrmann (1978). The aim in selection was to comply with the requirements on rating scales to be exhaustive and symmetric around the middle (Dillman et al. 2014) and with the theoretical definition of polarity.
Matched unipolar rating scales contained unipolar labels and middle category with unipolar meaning: do not agree at all, do not agree, slightly agree,
Study Participants
The data were collected in December 2016 with a commercial online access panel with a quota sample for the German adult population aged 18 years or older (N = 1293, ca. 150 persons per experimental group, see Fig. 1 in Appendix E). The participants used only a PC or laptop, as mobile device use was not the focus of the present study and use of different devices would confound study results. Of the participants, 49.6% were men, 30.6% were younger than 40 years, 38.1% were between 40 and 60 years, and 31.1% were older than 60 years. Almost 30% (29.7%) had a university entry education grade. The experimental groups did not significantly differ with respect to these variables in any of the experiments (p > 0.10).
Data Analysis
Frequency in choice of the middle category described middle responding. The positivity bias score counted disagreement versus lack of or low agreement resulting in higher scores for a lower positivity bias (see Schwarz et al. 1991). The acquiescence score described how often respondents provided agreement or application. Poisson Regressions with SPSS 23 (Coxe et al. 2009) were conducted to analyze the impact of experimental manipulations on these count variables, accounting for the non-normality and heteroscedasticity, while data of all four experiments were pooled together. The first regression evaluated the effects of polarity, matching and their interaction. The second regression compared eight groups. The type of unipolar dimension (“Agreement” vs. “Application”) and the topic of items (Gender Roles vs. LC) along their interactions with polarity and matching were included as predictors to control for potential differences between the four experiments.
A Multi-Group Confirmatory Factor Analysis (MGCFA) was conducted to evaluate reliability in each experiment separately. Composite reliability (
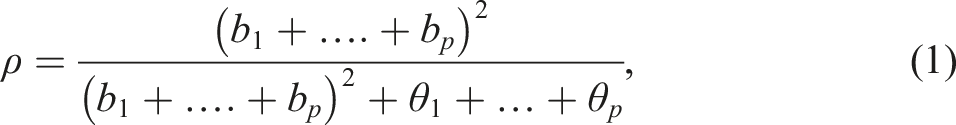
In experiment 1, a correlated error term between the items 1 and 3 (Online Appendix C) was included in the MGCFA model due to the reverse-keying of these items (Weijters et al. 2013b). This correlation was treated as a part of the error term when calculating reliability. In experiment 4, a correlated error term was included between items 1 and 2 (Online Appendix C). This correlation seems to be theoretically sound due to the similarity in meaning between the two items. It was held constant among the groups and was not considered in the equation (1). All models provided tenable goodness of fit according to RMSEA (range 0.00–0.08) and CFI (range1.00–0.95). To analyze validity, latent correlations between the test and criterion measures were obtained and compared among experimental groups by means of Multi-Group Structural Equation Modeling (MGSEM, see Menold and Raykov 2022 for methodology). All models provided sufficient model fit (RMSEA between 0.06 and 0.00; CFI between 0.95 and 1.00).
MGCFA and MGSEM were conducted with Mplus software using an estimator robust to non-normality (MLR), because none of the items in any group was normally distributed (assessed with the Kolmogorov-Smirnov-Test). Box Plots for the summarized mean scores are provided in Online Appendix E. MLR has been proven to provide stable results for ordinal data with five and more categories and small sample sizes
Results
Polarity
Results of Poisson Regressions for Response Bias by Eight Experimental Groups.
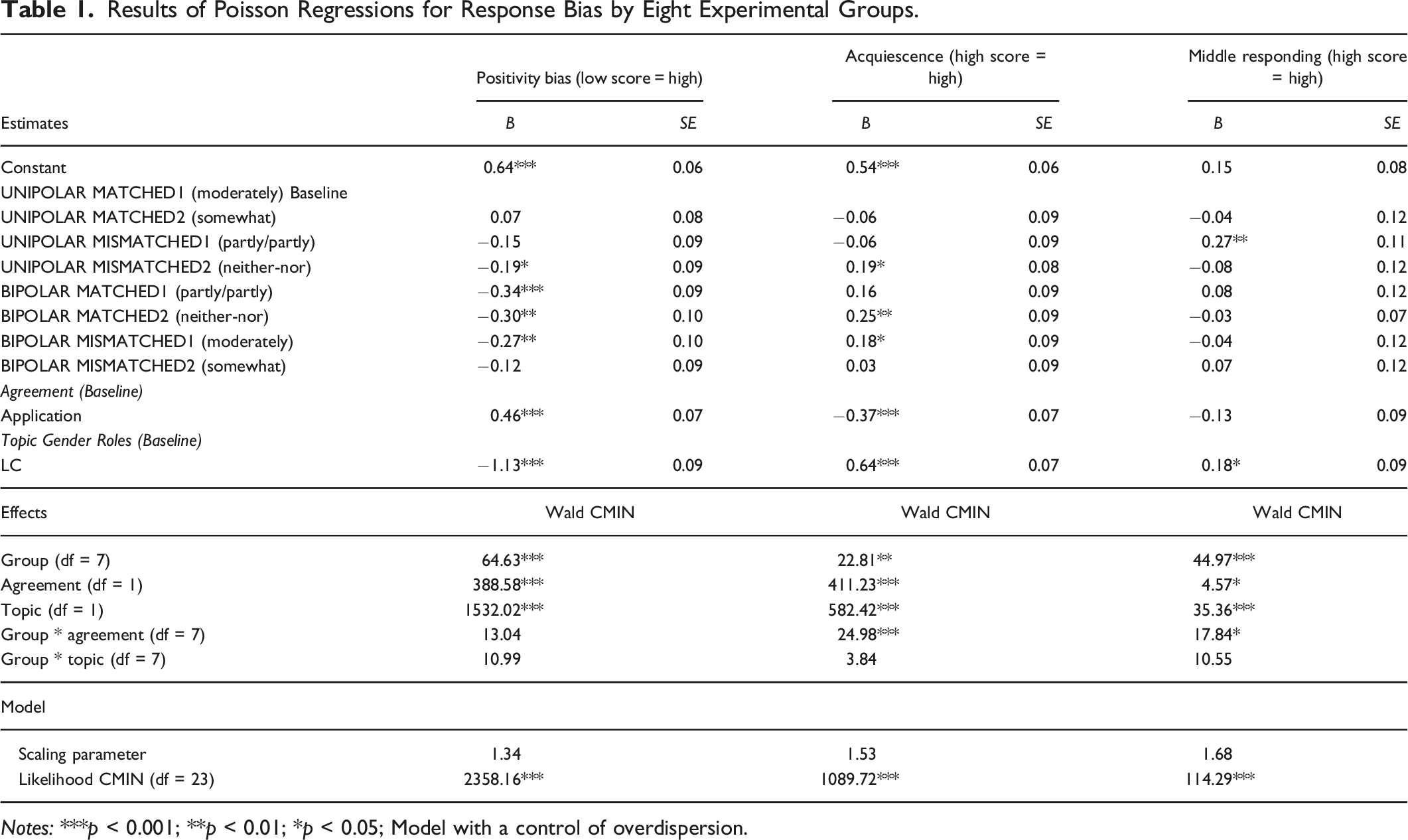
Notes: ***p < 0.001; **p < 0.01; *p < 0.05; Model with a control of overdispersion.
Composite Reliability (ρ) and Their Pairwise Differences (D) with Standard Errors (SE) by Experimental Group.
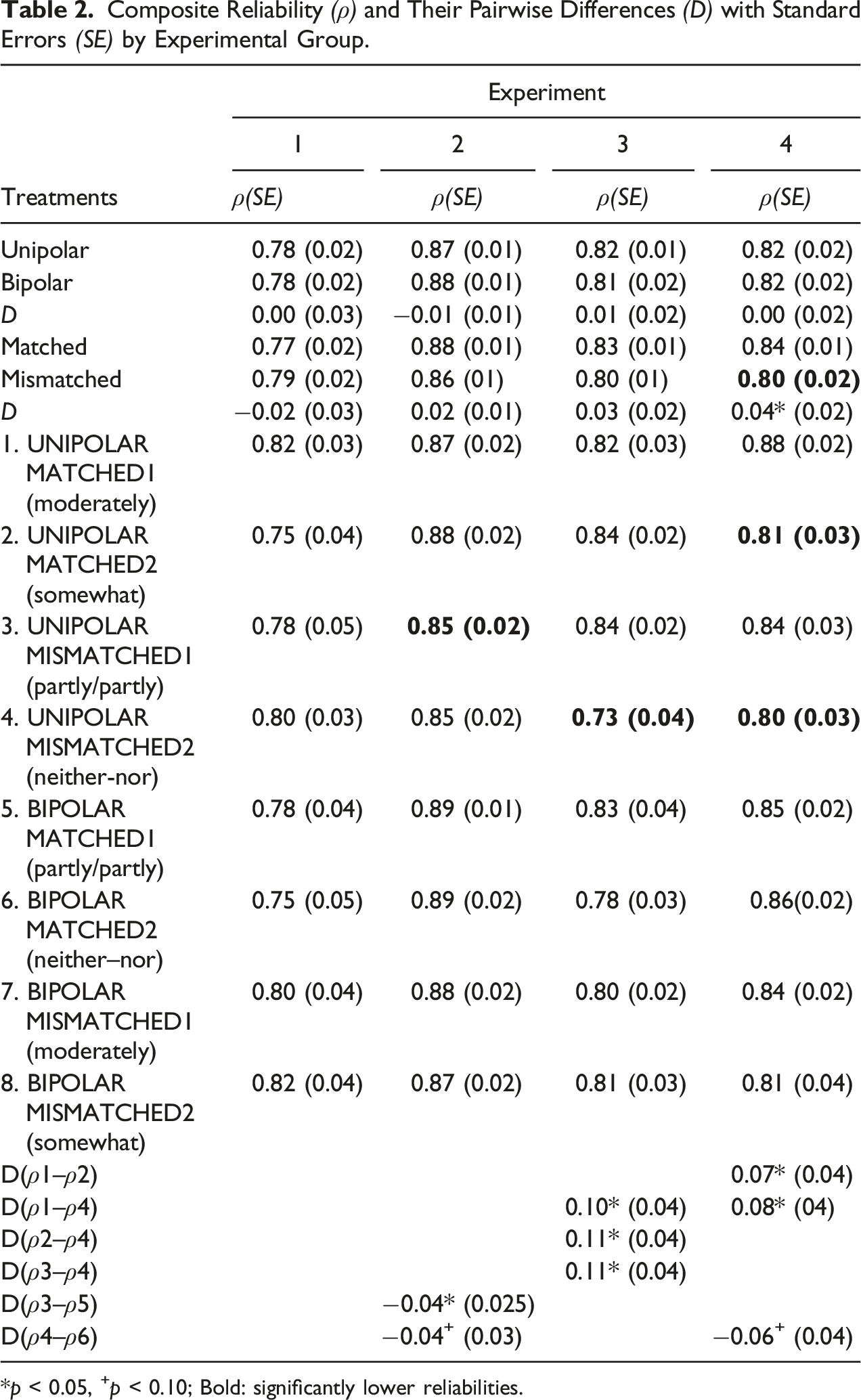
*p < 0.05, +p < 0.10; Bold: significantly lower reliabilities.
For the differences between the experiments, the positivity bias and acquiescence were lower for the unipolar application than agreement dimensions. The overall disagreement was also higher in the case of Gender Role instruments as compared with the LC (Table 1).
The Hypothesis H1 that anticipated higher positivity bias and acquiescence in bipolar rating scales was mainly supported. Positivity bias and acquiescence for several realizations also depended on matching.
The reliability coefficients were of middle or high magnitude (Table 2). There were no significant differences between unipolar and bipolar rating scales in any of the experiments. Validity scores did not markedly differ between unipolar and bipolar rating scales either (Table 2 in Appendix E). Only one validity score (for Neuroticism) in experiment 4 was significantly higher in unipolar than in bipolar rating scales. A violation of equidistance is given in experiment 4 for the matched bipolar rating scale with partly/partly (Online Appendix G).
The Hypothesis H2 found no empirical support with respect to reliability. In some single cases, however, bipolarity reduced validity and violated equidistance.
Matching
There was no significant main effect of matching on middle responding, but there was a significant interaction effect between the polarity and matching (Online Appendix E, Table 2). Differences between the eight groups (Table 1) demonstrate that mismatched partly/partly was associated with higher middle responding than other realizations. Middle responding was also higher for LC than for Gender Roles (Table 1). Hypothesis H3 that expected higher middle responding in the case of mismatching could be supported for a single case meaning the use of the bipolar partly/partly in a unipolar rating scale.
In experiments 2–4, matched verbalizations obtained slightly higher reliabilities than mismatched verbalizations, while the overall effect of matching was significant in experiment 4 (Table 2). Significant pairwise reliability differences were found in experiments 2, 3, and 4 showing lower reliabilities for mismatching partly/partly or neither–nor to unipolar rating scales. So, in experiment 2, the bipolar matched use of partly/partly was associated with higher reliability than its mismatched use (difference between the groups 3 and 5, Table 2). In experiments 3 and 4, displacing neither–nor provided significantly decreased reliability as compared to other matched realizations.
Validity scores for matched verbalizations were higher than for mismatched verbalizations in all experiments (except the correlations with Openness in experiment 3, Online Appendix F, Table 2). The overall effect was significant in experiment 2 for one criterion (Tradition). The pairwise comparisons between eight groups point to an effect of matching due to significantly lower validity for several unipolar and bipolar mismatched scales in experiments 1, 3, and 4. In addition, mismatching was often associated with the risk of obtaining a non-significant correlation with a criterion, which is summarized in Online Appendix F, Table 2.
Equidistance was not given for the unipolar rating scale with mismatched partly/partly in experiment 1 and for the unipolar rating scale with mismatched neither–nor in experiment 2 (Online Appendix G).
Hypothesis H4 could be supported for reliability in the case of the mismatching partly–partly and neither–nor into a unipolar rating scale. Equidistance was violated in some such cases as well. Validity was reduced for mismatching in all experiments.
Discussion
The question addressed was how verbal polarity and mismatching middle categories in verbal rating scales affect response bias and measurement quality. As expected, positivity bias and acquiescence were higher in bipolar than in unipolar rating scales, which is in line with previous findings on numeric polarity (e.g., Schwarz et al. 1991). The results provide evidence that acquiescence can be reduced by using unipolar rating scales rather than the typically used bipolar DA scales. The positivity bias and acquiescence were also higher in some mismatched rating scales, which is in line with previous findings (Menold 2021). To reduce acquiescence, unipolar rating scales with matched middle category would therefore present an alternative to so-called item specific format (Saris et al. 2010), which should be addressed by further research, however. Mismatched use of partly–partly, but not other mismatched middle categories, attracted respondents and increased middle responding (see Menold 2021). The result is nevertheless relevant, because mismatching partly/partly frequently occurs. It also demonstrates that middle responding may depend on the middle category verbalization.
Polarity did not affect reliability for the most part, whereas mismatching did. This is in line with previous research (Menold 2021). The mismatched use of bipolar neither–nor or partly–partly in unipolar rating scales decreased reliability and validity and violated equidistance. Implausibly low or even non-significant relationships with the criterion variables were also observed with the mismatching unipolar moderately and somewhat as well.
The results were comparable across different topics and point to the context dependency of verbalizations, which affects the understanding and use of rating scales by respondents. The labels for the middle categories may matter owing to their different denotative (lexical) meaning (see Rohrmann 1978). Verbalizations can have different emotional coloring (Friedman and Amoo 1999), intensity with respect to the denotative meaning and familiarity to the respondents (Weijters et al. 2013b). The alternatives used for unipolar or bipolar middle categories can therefore differ with respect to these characteristics. The author used existing verbalizations taken from surveys and survey literature and varied them to implement polarity and matching. A detailed analysis of their linguistic properties and optimized realization for rating scales is left to further research.
The present research was conducted by means of a web survey on desktop PCs or laptops, with Internet users only in a non-probability sample. Research is needed to investigate the use of verbal rating scales with mobile devices and modes other than web surveys. The results are applicable to the German language only and verbalizations in different languages should be addressed in future research.
Taking the presented results into account, researchers should avoid the bipolar disagree–agree scales. More attention should also be given to the matched use of middle categories and to avoiding using bipolar neither–nor and partly–partly in unipolar rating scales.
Supplemental Material
Supplemental Material - Verbalization of Rating Scales Taking Account of Their Polarity
Supplemental Material for Verbalization of Rating Scales Taking Account of Their Polarity by Natalja Menold in Field Methods
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.