
Abstract
We propose a mixed methods approach to digital ethnographic research. Treating online conversational environments as communities that ethnographers engage with as in traditional fieldwork, we represent those conversations and the codes made by researchers thereon in network form. We call these networks “semantic social networks” (SSNs), as they incorporate information on social interaction and their meaning as perceived by informants as a group and use methods from network science to visualize these ethnographic data. We present an application of this method to a large online conversation about community provision of health and social care and discuss its potential for mobilizing collective intelligence.
Treating conversation platforms as communities in which humans engage in communication and meaning-making (Rheingold 2000), we perform ethnography that generates codes that can be analyzed in network form. We define a special type of network representation of ethnographic data, SSNs, and argue that a methodology based on them is accountable to ethnography as a discipline. Its steps, save for the final quantitative analysis layer, carry naturally over from traditional field research to the digital domain. So does ethnography’s focus on human communities.
SSNs can help discover collective worldviews, address open-ended questions, and scale reasonably well. They show promise as tools to harness collective intelligence, the production, and processing of meaningful information by connected human groups (Lèvy 1997).
We first situate our contribution in digital ethnography and network science literature (see Related Work section). Then, we introduce a data model for SSNs (see A Data Model for Digital Ethnography section). Next, we present data in SSN form from a study on community-provided health and social care services (see An Application: The OpenCare Data subsection). We then illustrate how we used SSNs to aggregate and navigate a large corpus of ethnographic data (see Results and Discussion section). Finally, we reflect on their potential and possible extensions (see Conclusions and Future Improvements section).
Related Work
Digital Ethnographic Methods
Responding to calls for multimodal and network ethnography integrating anthropological participant observation with digital research methods, our ethnographic method maps online conversations to analyze community meaning-making practices (Dicks et al. 2006; Howard 2002; Murthy 2008). Following Rheingold (2000, pp. xx), we define online communities as “social aggregations that emerge from the Net when enough people carry on those public discussions long enough, with sufficient human feeling, to form webs of personal relationships.” SSNs encode these webs of relationships.
We treat online conversational environments (such as digital fora) as communities (Beaulieu 2004; Miller and Slater 2000). We visualize informant contributions in a semantic network, like approaches outlined by Bernard et al. (2016), but with significant differences: Codes are generated through direct ethnographic coding on an online platform and automatically visualized in network form, in contrast to manual construction of the social network (Howard 2002). The semantic network is therefore not generated from key words but from sustained ethnographic engagement with user contributions. This approach integrates benefits from qualitative data analysis (QDA) software (Bernard et al. 2016), iterative meaning-mapping approaches (Dressler et al. 2005), anthropological participant observation, and social network analysis to display a map expressing what community members are talking about and who is talking to whom about what concepts (as interpreted by the researcher). It provides a rich visualization, derived from grounded theory (Bernard 2011; Bernard et al. 2016), to aid in anthropological theorization.
Anthropologists have suggested that network images enhance qualitative understandings of social processes (Burrell 2009; Hannerz 1992; Strathern 1996). Several mixed methods approaches combine qualitative research with social network mapping. Snodgrass et al. (2017) utilize psychometric measurement techniques and interviews to generate measurable qualitative data sensitive to socioculturally specific meaning. Dengah et al. (2018) use survey data and “egocentric social network interviews” to theorize the relationship between social support and online gaming involvement. We employ online ethnographic participant observation rather than off-line interviews and construct social networks from observed, rather than reported, online interaction.
Dressler et al. (2005) share our aim: retaining sensitivity to informants’ contextual, interactional, and socioculturally specific understandings of concepts while also introducing systematic means of visualizing (and measuring) them. We, however, do not attempt to measure a prehypothesized concept like cultural consonance. Instead, we visualize ethnographic research reflecting the contributions of community members, through codes, in a social network and compute indicators on that network.
SSNs
The notions of semantic network and SSN have been used in different contexts to denote different concepts. Sowa (1983) introduced conceptual graphs as encoding the logical structure of statements also called “semantic networks” (Sowa 1992). His theory focuses on mathematical patterns and rules, and transformations operated on the graph structure emulating human reasoning (Sowa 1983, 2000), mathematically representing knowledge in a manner suitable for deduction (Shapiro 1977; Woods 1975).
Statistics-based approaches known as text mining competed with Sowa’s, focusing on co-occurrence patterns of words in documents. Other computational approaches (like unsupervised learning) suggest how groups of terms reflect the semantic structure of documents, often representing documents as weight vectors (Salton and Buckley 1988; Salton et al. 1975). Graphs are utilized when using document vectors to compute similarities between documents (fragments of conversations). Nearest neighbor approaches (Fukunaga and Narendra 1975; Kramer 2013) are often used to induce links between similar documents. Structural characteristics of the graph are interpreted at the corpus level. Jiang et al. (2016) exemplifies the use of these statistical apparatuses to address problems involving large document collections.
We depart from this largely nonethnographic literature by constructing semantic data based on ethnographic coding of community members’ conversational themes, elucidated through on-platform interactions with participant–observer researchers. Unlike researchers like Roth and Cointet (2010), we do not use natural language processing techniques. We use SSNs to theorize how humans co-construct meaning through social interaction, rather than how individual behavior produces network structure, or how concepts in more static or single-authored documents like news media relate to each other.
Social networks are traditionally inferred from relations or interactions between people (Borgatti et al. 2009), represented as graphs where relations are embodied as links between nodes (persons; Wasserman and Faust 1994). Structural metrics (degree, distances, centralities, matrix eigenvalues, etc.) can be interpreted as socially meaningful (Burt 2000; Freeman 1997; Scott 2000).
We represent ethnographic data as a network. We choose its form so that it encodes information on both what each informant is talking about (as interpreted by the ethnographer) and who she is talking to. So, the network is a semantic and social one—an SSN. It stores the data in a structured form without compromising their rich, contextual character.
SSNs are for human consumption and therefore underpinned by a simple, intuitive ontology. Our representation has only two types of nodes, participants in the conversation and ethnographic codes, and three types of edges: comments-the-content-of (connects a participant to another), authored-posts-annotated-with (connects a participant to a code), and co-occurs-with (connects a code to another). By contrast, graph databases (proposed as early as the 1970s) can and do encode many types of relationships (Shapiro 1977).
A Data Model for Digital Ethnography
Ethics
OpenCare’s conversation was hosted on an instance of the forum software Discourse (Atwood et al. 2013–2019), where participants shared care experiences, discussed in-person events, and exchanged best practices. Participants passed through a “consent funnel” before posting, answering required questions to ensure they understood the project and risks associated. The forum conformed to the European Union’s General Data Protection Regulation.
We committed to radical methodological openness, discussing research and coding decisions on-platform with informants (Beaulieu 2004; Mortensen and Walker 2002).
Ethnographic Coding: Methods and Implications
We employed iterative, inductive, and reflexive coding processes (Auerbach and Silverstein 2003; Bernard 2011; Saldaña 2015; Sunstein and Chiseri-Strater 2011). An anthropologist (Hassoun) coded 28 hours a month over a one-year period. She performed three coding passes on the data set, with continuous updating of codes based on a detailed codebook with memos and analysis notes. She used both descriptive and in vivo codes.
Hassoun coded directly on-platform via an application we added to the platform’s code base. This process created a database of codes and automatically visualized it in network form.
We find ethnographic coding preferable to word count or key words because coding is not just a process of labeling but a clarifying, analytical process in which the ethnographer names and maps the concepts invoked by the community (Saldaña 2015). Informants use different words to mean similar concepts, making a word count less effective. The analytical process undertaken by the ethnographer produces codes that more richly reflect the community’s collective intelligence, encoding “summative, salient, essence-capturing, and/or evocative” attributes (Saldaña 2015).
We derive codes from ethnographic participant observation of community members’ long-term engagements with each other, analyzing meaning on different levels of analysis. One level is the subjects that community members consider most important and how they relate to each other (visible in the entire network of codes; see Figure 1). Another is a more granular focus on specific topics (manifest in a single code or subnetwork of codes). Yet another level is the focus on a selected group of community members (displayed as the network of codes discussed by a selected group; see Figure 2). As contributions and codes are time-stamped, the network of ethnographic codes also allows researchers to see what topics become interesting over time, to whom, and through what kinds of interactions.
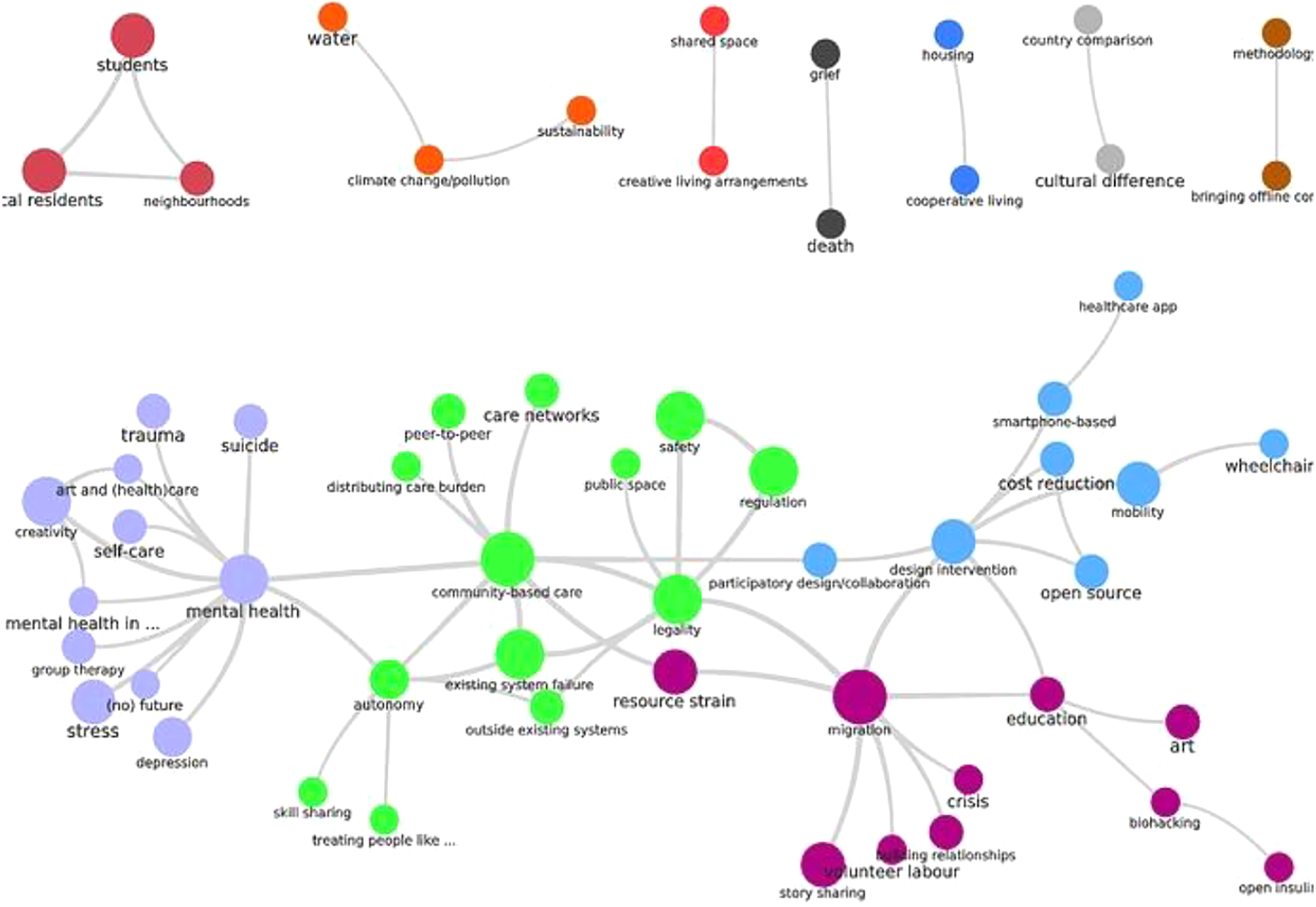
The OpenCare code co-occurrence network (filtered for k ≥ 6).
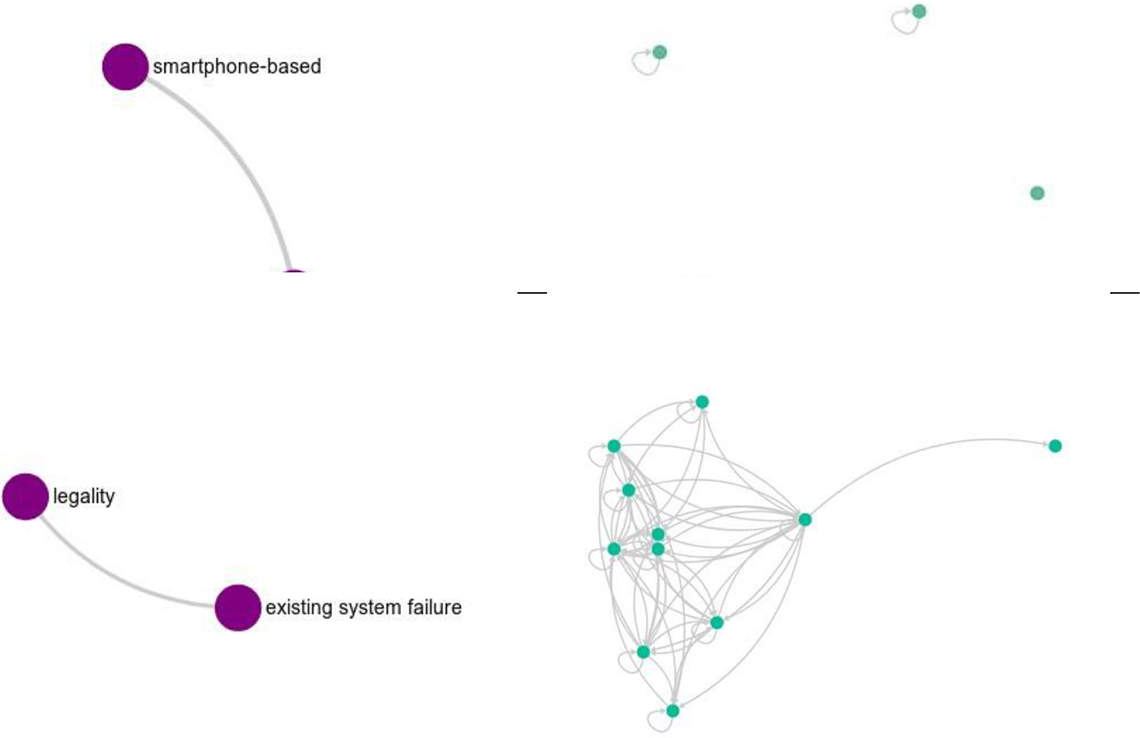
Two edges in the OpenCare semantic network (left) and their associated social networks (right). Structural differences in the latter hint to different degrees of convergence in how the online conversation interprets the former.
Hassoun did not artificially limit the amount of codes assigned (in part so the codes and corpus could be expanded on in the future), instead mapping codes as accurately as possible onto informants’ categories of analysis. Because we employ grounded theory and had community members participating from a wide range of cultural and institutional contexts, we did not predefine any codes based on existing theories.
On-platform coding produces a digital codebook, making coding decisions transparent and codes easily editable. Visualizing the semantic network enables iterative coding processes, illuminating which codes might be redundant or need forking. Both elements enable multiple researchers to work on the same large corpus in a coherent way, with unique identifiers separating each researcher’s codes. This makes our method partially scalable. It offers a clear benefit over existing computer-assisted qualitative data analysis software, which are closed, mostly proprietary, and notoriously difficult for multiple researchers to use.
These methods also make the ethnographer’s interpretive process more visible. Coding is a process of reflexive interpretation that requires moving between the positionality of the researcher and the worldviews of informants (Rosaldo 1992). Keeping a detailed, open codebook and memos makes this more transparent than in traditional ethnographic studies. These coding practices and visualizations utilize ethnography’s ability to tease out collective beliefs and practices while rendering the researcher’s situatedness and partiality visible. Future studies employing multiple ethnographers will enable comparison of semantic social networks (SSNs) generated by different researchers, further shedding light on this interpretive process.
Contributions
SSN-based ethnographies start with posts/comments on the social networking platform. We call contribution a testimony in written form (interview transcript, post on an online forum, etc.). A minimum viable structure for encoding a contribution as primary data includes: Contribution ID: The contribution’s unique identifier. Text: The contribution’s complete text. Author ID: A unique identifier for the informant that contributed the text. Target ID: A unique identifier for the informant that the text is addressed to. Date and time.
Annotations
Ethnographers associate snippets of texts in contributions to key words called codes. This generates an ontology representative of the corpus. We call annotation the atomic result of this activity. A minimum viable structure for annotations includes: Annotation ID: The annotation’s unique identifier. Contribution ID: The unique identifier of the post or comment that this annotation refers to. Snippet: The part of the text in the contribution that the researcher wishes to associate with the code. Code: The ethnographic code associated with the snippet. Author ID: Unique identifier for the researcher that produced the annotation. Date and time.
This representation induces a network where the nodes are informants and edges represent interactions. Codes—associated with the interaction via annotations—encode the semantics of that interaction. We call this an SSN. We propose it is general enough to fit evidence from most ethnographies, while structured enough to be encoded into a data set.
An Application: The OpenCare Data
The OpenCare project explores how communities provide health and social care when neither states nor businesses can or will serve them. We began with the research question: What do people do when existing health and social care systems no longer provide care? Data were gathered from an online forum where individuals discuss their care experiences. We used the method described in the A Data Model for Digital Ethnography section to code them and build the corresponding SSN. We then built a social and a semantic network from the coded data.
The OpenCare Social Network
Online conversation induces a social network where nodes are community members and edges encode interaction. For users A and B, we induce a connection A → B if A has commented B’s content at least once. This network is directed (A → B /= B → A) and weighted (the edge A → B has a weight of k if A has commented B’s content k times). The OpenCare corpus has 332 nodes and 1,265 edges.
The main feature of this network is a clear core–periphery structure. Almost all participants are connected to the giant component, so information can flow freely across the network. The giant component itself is not obviously resolved into distinct subcommunities (its modularity value is 0.38) (Newman and Girvan 2004). These structural features allow us to infer that most opinions expressed in the forum have been expressed in a public space that everybody participates in. There are no signs of isolation of individuals, nor of balkanization of the conversation.
SSNs can also be represented in ways that emphasize the semantics of the online conversation. The representation that proved most useful to ethnographic research is what we call the co-occurrence network. Its nodes are codes. Whenever two codes occur in annotations that refer to the same post, they are said to co-occur in the same post, and an edge is induced between them. This network is undirected (A → B ≡ B → A) and weighted (the edge has a weight of k if A co-occurs with B on k different posts or comments). We can think of the co-occurrence network as an association map between the concepts expressed by the codes. A higher edge weight k indicates a stronger group-level association between the two codes connected by the edge.
The annotations on the OpenCare corpus induce a co-occurrence network with 1,248 nodes and 16,727 edges. The main component is formed of 1,234 nodes and 16,702 edges and shows a small-world structure (Watts and Strogatz 1998) with a high average clustering coefficient
Results and Discussion
Filtering the Co-occurrence Network for a High-level View
Rather than representing the point of view of an individual, the co-occurrence network encodes contributions from informants as a group in conversation as interpreted by an ethnographer. The resulting concept map, therefore, does not simply aggregate the association patterns of individuals like a survey; it is the product of the interaction across participants. Edge weight k, then, represents the strength with which the conversation associates the codes connected by that edge.
Filtering the graph by higher value of k allows the researcher to see the strongest associations between codes made by informants as a group. She can experiment with different values of k, starting from a low value and increasing until the graph simplifies enough to be interpretable. For the OpenCare data set, filtering edges by k ≥ 6 yields a co-occurrence network with 60 codes and 72 edges, which lends itself well to visual inspection (Figure 1).
From it, one can see the structure of community members’ concerns. Consider the cluster with legality (in green): We find existing system failure and regulation, reflecting the preoccupation of some informants that community health-care initiatives and technological innovations outside of existing systems (much needed when systems fail) turn out to be illegal and therefore difficult to implement. We also find safety, reflecting the acknowledgment that regulation is often there for a reason.
We can also see isolated but intense conversations visualized as islands in the high co-occurrence network: The network death, grief, and online memorials (visible at a lower co-occurrence level) appear unconnected to the rest of the network, indicating a deeply discussed single issue. In this case, community members intensively discussed this issue on one highly active thread, but the topic was not discussed more widely across the platform. In the next section, we describe how to tell whether a discussion is driven by a small number of community members or a larger group.
A researcher can choose to look at the network of associations around a topic of interest at a more granular level by clicking on the link between two codes to view all community contributions containing both codes (like design intervention and cost reduction) to see what specific innovations the community has devised.
The method allows for rich analysis on multiple levels, retaining the granularity that makes ethnographic research so powerful. High co-occurrence edges in the semantic network illuminate connections that might be invisible at a smaller scale of analysis, allowing the ethnographer to visualize and understand her informants’ concerns and how they relate to each other. Without the co-occurrence network, vital interconnections made by informants would have been missed; without the detailed ethnographic data, the meaning behind those connections would be lost.
A detailed discussion is out of scope of this methods-focused article, but in the OpenCare project, this method led to key insights into informants’ beliefs, desires, innovations, and concerns. Centrally, people, facing the collapse of existing health and social care institutions, reach for what we term “collective autonomy”: feeling empowered to solve their own problems while in a community-based framework (Hassoun 2017). This finding has clear implications for states and nongovernmental organizations trying to help people in crisis. Care solutions that treat people as helpless or remove them from a community context will likely fail. Refugees wanted the tools to collaboratively build their own temporary living spaces and markets rather than being infanalized by states or non-governmental organizations; mental health patients found helping others in their community therapeutic. Solutions that connected people with others with compatible skills gave them tools and space to experiment, or strengthened care networks in communities were most useful to people seeking care outside of existing health and social care systems.
Some of the network’s properties have straightforward interpretations and can be used to validate or extend the researcher’s conclusion. A researcher can use edge weight to get a precise idea of how strong the association between any two codes is. She can also use community detection algorithms to get a quantitative indicator of how neatly a problem resolves into subissues. We applied to the network in Figure 1 the Louvain community detection algorithm (Blondel et al. 2008): It is highly modular (with a modularity of 0.64) and presents clearly distinguishable communities of codes identified by color.
Enriching Semantic Information with Social Network Structure Information
The OpenCare social and semantic networks, as described in The OpenCare Social Network and SSNs subsections, are interlinked by the data structure defined in A Data Model for Digital Ethnography. This enriches semantic information with information on the structure of the social network. For example, we can check that the social network underpinning any one edge in the semantic network is connected. A connected social network signals that they who have made the connection between those two codes are in conversation with each other: informants are aware of each other’s existence and have had the opportunity to interact around that particular connection to arrive at an interpretation of its nature and importance for the problem at hand. A disconnected one signals that they never conversed at all: They agree the two codes are connected but might have different interpretations of that connection unimpacted by each other’s views. In Figure 2, there are four informants who have mentioned both smartphone-based and health-care app (six co-occurrences), and they are not interacting directly with each other. There are 11 who have mentioned both legality and existing system failure (nine co-occurrences), and they are all connected in a dense network of direct interaction. The latter association has the potential for being supported by a consensus resulting from the conversation, not unlike what happens in Wikipedia (Laniado et al. 2011), whereas the former does not.
Conclusions and Future Improvements
SSNs show promise as a digital social science research method aimed at capturing collective intelligence and making ethnography a more collaborative discipline. They deal well with open questions and novelty (like traditional ethnography) and handle hundreds of informants (like quantitative surveys). When combined with open standards and open data, they could attempt to handle thousands of informants.
SSNs pave the way for replication, reuse; and extension of ethnographic studies as well as larger-scale studies. An ethnographer can pull a colleague’s annotations and codebook, increasing the clarity and accountability of the research process. She can add her own coded corpus and use the combination of annotated corpora to produce a new study. Accurate documentation of the code ontology allows ethnographers to work on projects that would be too large for a single ethnographer to tackle. Finally, SSNs help enable longitudinal online ethnography, as an online conversation could be revamped yearly to keep track of how its collective point of view evolves.
These practices require a cultural shift from practitioners. Ethnographers tend to work alone and seldom disclose access to coded interviews and field notes. The process of coding in ethnography follows standards that are project specific and often not made public. There are few naming conventions for codes followed by all ethnographers, few codebooks published in electronic form, no accepted specifications for data files, and so on. We suggest that ethnographers embrace the practice of using and publishing open data. Open data are data that are (1) machine-readable; (2) published under licenses that allow their reuse; and (3) documented with appropriate metadata. 1
The payoff of such a shift is substantial. We could imagine a version of Eurobarometer based on an open online conversation. Instead of answering multiple-choice questions, vulnerable to framing biases (Tversky and Kahneman 1981), informants would discuss their perception of Europe, allowing researchers to discover novel patterns of association and detect the fading of old ones.
Our method could be further improved along the following lines:
Develop the idea, introduced in enriching semantic information with social network structure information, of applying existing social theory on the social network topology to derive “interest scores” on individual informants and connections in the semantic network.
Apply alternative ways to measure edge (association) strength k in the co-occurrence network. For example, k(A → B) could encode the number of informants who have authored contributions coded with both codes A and B or the number of separate threads that contain at least one contribution with it. Different measures of edge strength have different interpretations, so they allow different perspectives on the data corpus.
Observe and model the online conversation as a dynamic system. Stochastic actor-oriented models might be a good place to start despite known limitations (Snijders 1996).
Multilingual studies: The code ontology can be structured as a hierarchy so that codes with the same meaning in different languages are entered in the secondary data as children of the same parent code. The code co-occurrence network would be drawn between parent nodes, allowing both an all-languages view on data and across-languages comparisons. This work would allow for analysis of generalizability of codes across languages and potentially different cultural understandings of concepts, although cultural difference would need to be explicitly theorized as an object of analysis.
Ethnographic coding as compression: Empirically, in OpenCare, the rate at which new codes are produced declined, approaching zero. This suggests that, after a certain number of iterations, the online conversation produced an ontology (nearly) sufficient to code all future contributions. This phenomenon is reminiscent of file compression in computer science. If the analogy holds, a dynamic analysis of the conversation could identify moments of significant evolution by spikes in the growth rate of the codes dictionary as new ideas are suddenly generated. We could estimate the overall relatedness and novelty of conversations. We intend to refine and test this hypothesis on more corpora of similar size and scope.
Supplemental Material
Supplemental Material, Re_Page_Proofs_for_Journal_of_Sports_Economics_JSE_913102 - Semantic Social Networks: A Mixed Methods Approach to Digital Ethnography
Supplemental Material, Re_Page_Proofs_for_Journal_of_Sports_Economics_JSE_913102 for Semantic Social Networks: A Mixed Methods Approach to Digital Ethnography by Alberto Cottica, Amelia Hassoun, Marco Manca, Jason Vallet and Guy Melançon in Field Methods
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The OpenCare project received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant agreement 688670).
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.