
Abstract
Data use is becoming a prominent strategy for educational innovation and improvement across countries. However, the fragmentation of data collection often hinders the capacity of policymakers, researchers and practitioners to access and analyse the wealth of data routinely generated in educational institutions. A critical step towards realising the potential of education data is thus to set up a strong data infrastructure at the national/state level. Longitudinal data systems represent a promising solution to this challenge. We discuss the capabilities and limitations of current education data systems, drawing on a survey of 64 systems in 30 countries. We argue that the next generation of education data systems should integrate longitudinal, individual-level administrative records with learning management platforms, and incorporate an extended repertoire of analysis and reporting tools in order to support richer types of diagnosis and provide enhanced feedback to stakeholders. The potential of longitudinal data systems to foster innovation and improvement in education is illustrated by a discussion of how these tools can support educational research.
Introduction
Education information systems have evolved to meet increasing demands for data use in the education sector. Schools, universities and education agencies have always been data-rich environments. Historically, however, much of these data would not be easily retrievable and usable beyond a restricted time and institutional context. Over the last decades, a variety of technological solutions, from school-based information systems to historical data repositories, have emerged to support the collection, storage and use of education data. But it is only recently that national/state education agencies have begun to develop comprehensive, longitudinal education information systems to maintain high-quality information about the inputs, resources, operations and outcomes of their education systems and serve as one-stop shops that facilitate the use of education data to a range of stakeholders.
The purpose of this article is to report on the state of education data systems internationally, including their coverage, data models and major functionalities. Identifying the key features of longitudinal information systems and their prevalence across an international sample of current systems is a first step towards exploring how these systems could (and could not) be used. This analysis provides a reference point for our discussion about the desirable data models and features of ‘next-generation systems’ – the kinds of systems that could accelerate innovation and improvement in education.
Background
Big (administrative) data in education
A wealth of data are routinely generated in the education sector, and increasingly in a digital format. As an illustration, consider the amount of data that an average school in an Organisation for Economic Co-operation and Development (OECD) country can produce and maintain on a regular basis. In the process of enrolment, the school will typically gather detailed demographic information about incoming students, including their age, sex or area of residence. Student data files will also contain past and current course-taking records, attendance patterns and class placement. In turn, periodic assessments will yield multiple types of academic performance data, from interim marks to final course grades to progress across levels of schooling. Less commonly, the data footprint may further include samples of student work, notes on behaviour or information on transitions between schools and into higher education. In addition, the school will normally maintain and update extensive data about its teachers, relating, among other aspects, to qualifications, seniority, subjects and classes taught or professional development. Importantly, the school will collect these and other data elements multiple times throughout and across years, hence opening up the possibility of creating longitudinal data series. However, until recently, much of this information would be kept in paper-based formats that complicated its retrieval and analysis. And even when digitalised, these data would most often remain within school-based information systems, hence rarely flowing out of their local context.
The magnitude of the data generation activity in the education sector and the benefits of leveraging improvements in data management capacity become more visible when considered at a national or regional level. As an example, the amount of data collected every year from the nearly 5000 elementary and secondary public schools serving over 2 million students in Ontario (Canada) increased from about 8 million records in 2005 to about 110 million records in 2014 following the introduction of the Ontario School Information System (OnSIS). By enabling highly granular statistical modelling and a rich contextualisation of student achievement patterns over time, OnSIS has improved the capacity of the ministry to monitor key indicators about policy priorities and base its strategic planning on timely and consistent evidence (OECD, 2015). The case of OnSIS and other publicly administered information systems also serves to emphasise that the huge and growing volume of data maintained by education agencies pertains essentially to “conventional”, administrative school and student records rather than to the unstructured data streams generated in digital environments that discussions about big data in education commonly allude to (e.g. Long and Siemens, 2011).
In 2012, an average of 85% of students across OECD countries attended schools where data are recorded systematically for quality assurance and improvement purposes, including student attendance and assessment results, and teacher professional development data (OECD, 2013a). The use of student assessment data for monitoring progress through comparisons with district or national benchmarks increased throughout the 2000s in most countries for which the information is available (OECD, 2014). While indicators of student achievement remain the most visible type of education data, a wider array of elements reflecting the quality of teaching and learning are also frequently collected as the result of evaluation and assessment practices (OECD, 2013a).
The growing scope and frequency of education data is related to the central role that evaluation and assessment policies have gained in national education agendas, and which respond to a climate of public sector accountability and increasing demands for effectiveness and quality in education (OECD, 2013b). As data-driven decision-making is increasingly advocated as a strategy for educational improvement across countries (e.g. Coburn and Turner, 2012; Mandinach, 2012; Schildkamp et al., 2013), it is important for education systems to develop a knowledge-supporting infrastructure that can promote more efficient uses of data among a range of stakeholders.
A fragmented data ecosystem
Education ministries and agencies across countries have adopted a variety of information systems to manage their student and school registries and the information generated by national evaluation and assessment frameworks. In their most basic configuration, the original systems consisted of repeated cross-sections of data that served to produce aggregate indicators at the system level. More recently, more advanced systems have incorporated individual-level unique identifiers and thus the possibility of following students (and sometimes teachers) over time. Regardless of their specific functionalities, data in these platforms are conventionally used to inform policymaking and support statistical reporting at the regional or national level, including the international databases managed by United Nations Educational, Scientific and Cultural Organization (UNESCO), the OECD or Eurostat. In parallel to national information systems, a wide array of information technology solutions exist at the school level to support the storage, retrieval and analysis of data required for school management and school improvement policies. Examples of these tools include student monitoring systems and performance feedback systems enabling comparisons vis-a-vis national standards and other schools (Selwood and Visscher, 2008).
While improvements in information technology have greatly facilitated the large-scale collection and management of education data, the lack of framework policies for the development of education information systems has resulted in a fragmented architecture of data silos. This remains one of the biggest impediments to exploiting education data for effective decision-making. The main problem with education data silos is the difficulty of linking student-level data longitudinally, as when data from different years or levels of schooling are stored separately or in an inconsistent format, thus making it difficult to match records and analyse individual pathways over time (e.g. how early performance influences later achievement, how course-taking patterns are associated with field of study in higher education). This arises when independent systems designed to meet different needs cannot communicate with each other easily. A recurrent example in schools and large education agencies alike is the concurrent use of warehousing and transactional systems to manage past and current data, respectively (NFES, 2010; Wayman, 2005). Data warehouses provide efficient storage for historic data but tend to lack turnaround and linkage functionalities for data from different sources and years. Transactional or operational systems, in turn, are designed to enable queries on recent data but can rarely support long-term data storage and retrieval. As a result, the linkage of data from different time points and entities is often costly and time-consuming.
Longitudinal information systems in education
A baseline definition
An increasing number of countries in the OECD area and beyond are establishing longitudinal information systems as an attempt to improve the conditions for the use of education data. In order to describe the baseline functionalities of these tools, here we follow the National Forum for Education Statistics in the US and define a longitudinal system as: a data system that collects and maintains detailed, high quality, student- and staff-level data that are linked across entities and over time, providing a complete academic and performance history for each student; and makes these data accessible through reporting and analysis tools. (NFES, 2010: 7)
The first critical feature of a longitudinal data system is thus the ability to link student-level data collected at different points in time and/or by different agencies, institutions or schools, and which may thus be stored in different repositories or sub-systems. This relies on the availability of unique individual identifiers which remain with each student across data collections. Being able to link student data over time distinguishes longitudinal systems from systems maintaining repeated cross-sections of data, which can nonetheless include unique school identifiers to enable school monitoring and evaluation over time. Longitudinal information systems may additionally include individual teacher identifiers that support analysis of variance at the class or teacher level. However, we see student-level data as the core of longitudinal information systems as it remains the basis for assessing the impact of policies and practices on learners’ achievement and outcomes. Information systems with teacher-level data only may also be longitudinal, but in the absence of student-level information the range of policy-relevant questions that can be examined with a system is greatly reduced.
The second baseline feature of longitudinal systems is the capacity to combine data elements reflecting student achievement and learning outcomes with data on enrolment, attendance, demographic backgrounds and other factors that serve to contextualise student outcomes. The ability to provide a comprehensive picture of student experiences and performance differentiates longitudinal systems from systems with a more restricted focus such as computer-based assessment tools or virtual learning environments.
Lastly, longitudinal systems are defined, as opposed, for instance, to data repositories, by the integration of tools that allow a range of stakeholders, including policymakers, researchers, practitioners and families, to easily query the system in ways that speak to their specific needs and interests.
These functionalities bring about significant improvements in the capacity to use education data to make better-informed decisions. Most importantly, longitudinal systems make it possible to transform the static view on student outcomes provided by cross-sectional data into a moving picture of each student’s progression. This opens the door to compare students with different development trajectories and investigate, beyond correlational analysis, how these pathways are associated with schooling contexts and classroom practices. The availability of repeated measurements is central to the greater capacity of longitudinal research, as compared to cross-sectional research, to establish temporal order, measure growth and support causal interpretations, and thus to adequately describe and analyse change processes. Inferences from longitudinal data are more (though not always fully) robust to the problems of self-selection and reverse causality that plague cross-sectional analysis (Menard, 2002; Saw and Schneider, 2016).
Having access to longitudinal information can thus help educators and researchers to better identify and monitor students who are not progressing towards the desired goals, estimate the effectiveness of various programmes and practices, and gain insights to better support student needs. Longitudinal information systems can also support the work of education policymakers by putting in their hands data of greater accuracy and reliability than the aggregate indicators traditionally used in evaluating school or system performance. For instance, by linking student-level and school-level data longitudinally, policymakers can more reliably gauge the impact that school policies and programmes have on students. Assessing with greater accuracy what is working and what is not for different types of students can then lead to more efficient and effective allocation of resources across schools.
And a vision for the future
Setting up an information system with the baseline functionalities described above can be taken to represent a first step towards establishing an efficient data infrastructure in the education sector. However, new approaches to data use in education, including, most notably, learning analytics, will likely require enhanced solutions for data collection, linkage and analysis (e.g. Baker and Siemens, 2014; Bienkowski et al., 2012). Higher-order capabilities of information systems may involve, for instance, the ability to collect data of greater granularity, the provision of real-time feedback, linkages to digital learning resources or the integration of recommendation engines and predictive modelling solutions.
Since 2010, the OECD Centre for Educational Research and Innovation (CERI) has been analysing how the next generation of education information can meet the imperatives of educational improvement and innovation (OECD, 2010, 2015). This work has identified a series of advanced features that exemplify innovative and promising solutions for the evolution of longitudinal information systems over the next 5 to 10 years, and which could set the horizon for education agencies working towards building an enhanced data infrastructure. In addition to the ability to track students and teachers longitudinally, these features include the use of interoperability standards; the possibility of customising analysis and reporting tools; the integration of banks of educational resources; and the capacity to provide educational stakeholders with timely feedback, including automated diagnostics and suggested solutions to help personalise teaching and learning practices.
Current information systems in education could incorporate these features in a gradual manner. An initial step would be to ensure that longitudinal data systems are able to establish a student–teacher data link and thus enable a closer examination of instructional practices. Secondly, next-generation systems would be characterised by the ability to integrate data from virtual learning environments used in schools and higher education institutions to provide access to digital teaching and learning resources. This would likely require the adoption of interoperability standards for data mining and linkage across platforms. Data integration does not necessarily involve transferring data from multiple sources into a single system. Instead, integration can more easily be achieved by making systems interoperable, that is, able to read, mine and link data from one another. Open technical standards and definitions pave the way for this type of integration, so that data from multiple feeding databases can be accessed, visualised and analysed through a single system or interface.
Relying on the combination of administrative and assessment data from multiple sources, next-generation systems would then be powered by learning analytics to make customised recommendations and provide links to specific instructional and learning materials. The application of learning analytics would enable systems to organise the navigation of banks of resources through techniques such as knowledge domain modelling, which uses personal data to compare a learner’s knowledge with the mapping of knowledge in a discipline and provide personalised content and tasks to support progress in learning (Siemens, 2013).
Another essential feature of next-generation systems would be a greater integration of analysis and reporting tools to facilitate feedback and knowledge flows. Rapid feedback loops that keep pace with data generation cycles can enable more dynamic learning environments for students and teachers, as well as the faster evaluation of interventions by educational researchers and policymakers. At the school levels, enhanced analysis and reporting tools would include automated reports, flexible data visualisation interfaces such as customisable dashboards, and discussion tools. For researchers and administrators, enhanced analytical capacity would stem from reduced delays in the turnaround of data and a greater ability to make relevant comparisons between schools and programs.
Next-generation systems should, therefore, be thought of as ‘learning systems’ or ‘expert systems’ with the potential to foster a culture of learning and of continuous improvement. Building on prior waves of systems designed to provide an overview of student and school performance at the system level, the main aim of future systems should be to foster improvement by giving quick feedback and supportive tools to teachers, schools and students. The enhanced capabilities of next-generation information systems would thus open the door for a forward-looking re-orientation of the use of data and information technologies in education, away from a traditional focus on reporting and accountability purposes and towards informing concrete practices in teaching and learning (NFES, 2011; OECD, 2010, 2015).
Method
We bring an international perspective to the analysis of education data systems by presenting results from a survey of 64 systems in 30 countries carried out by the OECD CERI. 1 The survey was undertaken as part of the CERI project Innovation Strategy for Education and Training, which explores the role of technology in facilitating self-sustained improvement and experimentation alongside other innovation levers in education. It was administered online between 2010 and 2015 to staff responsible for national, regional or city-wide education information systems, whose profiles ranged from chief data officers with responsibilities in the design and governance of the systems to technical staff involved in daily operations. The survey collected a total of 46 responses from 30 OECD and partner countries/regions. This information was supplemented with data from 18 state-wide systems in the US collected by the non-profit organisation Data Quality Campaign (DQC) for its 2013 Data for Action survey (DQC, 2013). 2
The survey questionnaire consisted of 42 items combining closed-ended and open-ended formats and included a set of notes clarifying technical terms. It collected information according to 10 main sections: main goals of the system; data model (i.e. data elements at the individual, school and region/country level); coverage and frequency of collection; data linkages; data quality processes; access rights and restrictions, and speed of access; comparison possibilities offered by the interface; instructional materials, communities of practice and professional development; accountability usage; and other features related to third-party uses (e.g. interoperability).
Responses were screened for inconsistencies and incompleteness, and when those occurred, verification checks were carried out with respondents. Some respondents also consulted with the authors when filling in the survey. A small number of questionnaires were answered through interviews. Overall, less than 5% of the original answers were recoded based on open-ended questions and follow-up clarifications. In addition, equivalences between the CERI and the Data for Action survey instruments were established in consultation with DQC and submitted for validation to the 18 states. The incidence of missing data was low (about 20% of cases missing in about 5% of items) and stemmed mainly from the lack of equivalent items in the US state-level survey. All the data in the reported analyses are actual responses, as there was no imputation of missing data. Actual sample sizes are indicated below each figure in this paper.
By yielding the first international mapping of longitudinal information systems in education, the CERI survey fills important gaps in our knowledge about the current features and capabilities of education information systems, which currently suffer from a dearth of international comparative analyses. The scant literature describing systems tends to adopt a national focus, cover a single level of education or rely on case studies without a unifying framework (e.g. DQC (2013); Gaebel et al., 2012; Hordosy, 2014; Passey et al., 2013).
The current state of education information systems internationally
Responses to the CERI survey reveal that education agencies across OECD and partner countries have developed systems with a wide array of approaches and significant variation in their data models and functionalities. We first present some general findings before examining in greater detail the results for major features related to the capacity of the systems to support innovative uses of education data.
The majority of the systems in the CERI survey are recent, publicly administered, and include data from national or state jurisdictions. About two thirds of the systems have been in use for less than a decade, including five that have been running for five years or less. In terms of coverage, most systems cover primary and secondary stages of education but four of them relate to tertiary education only. In addition, more than half of the systems (35) maintain pre-school education data, and almost another half (31) include information on post-secondary education. Most notably, about a third of the systems (21) provide comprehensive coverage from early childhood to higher education.
The survey also enquired about the areas where stakeholder needs could be better addressed thanks to the system. Most respondents listed support for managerial and accountability tasks as well as performance evaluation as the main goals of their systems. Improving conditions for educational research appears as the third most important objective, while only a minority of respondents listed the provision of personalised feedback and support for instruction as priority goals. This ranking can be seen as reflecting the statistical reporting approach that has traditionally governed the use of education data.
Key features of education information systems
Longitudinal identifiers and linkage possibilities
Unique, permanent identifiers that remain with students, teachers and schools across data collections are essential elements of longitudinal information systems. These longitudinal identifiers make it possible to connect data from different points in time and thus trace sequences of events and individual performance trajectories. Unique identifiers are also required to match data entities into nested structures, for instance students within classes or schools. Information systems may rely on identifiers that are specific to a single database or shared with other agencies or registries. Examples of the latter include unique learner numbers, social security numbers or personal identification numbers from digital ID cards. Shared identifiers facilitate the merging of data from different sources and can thus reduce the burdens of collecting again information that is already available. Further, collating data from different points in time reduces the risk of recollection bias and measurement errors when information must be collected retrospectively. Shared identifiers may, however, increase identification risks in the event of a security breach concerning one of the linked databases.
Figure 1 presents the percentage of systems providing different types of longitudinal identifiers, as well as linkages between student and teacher data. Unsurprisingly, all systems in the survey are able to identify specific schools and track them over time, which suggests that schools remain the most common unit of analysis for comparisons carried out using these information systems. However, only 72% of the systems covered by our survey are in fact able to follow students over time and can thus be said to be longitudinal. As discussed in the previous section, the longitudinal tracking of students represents the most important axis of differentiation between education information systems. Those with a longitudinal design can link student data over time and thus document progression in learning at the individual level and sustain robust analyses of the impact of different school environments and specific instructional practices. In contrast, systems maintaining cross-sectional data are only able to provide snapshot views of the experiences of different student cohorts, sustain correlational analyses and describe trends at the aggregate level. Additionally, Figure 1 reveals that 54% of the systems contain individual teacher identifiers and that 37% provide a student–teacher data link necessary to match teachers to students by classroom and subject. These systems are heavily concentrated in the US, where a greater emphasis has been placed on the effectiveness of teaching through teacher-level value-added models. Teacher accountability based on value-added measures remains highly controversial and there is yet little evidence about its effects on teaching and learning (e.g. Harris and Herrington, 2015). Attempts to estimate the contribution of a given teacher or classroom environment are a complex undertaking with very high requirements in terms of data quality, which go beyond the features that most education data systems were originally designed for (Thorn, 2013). While longitudinal information systems can eventually support teacher-level value-added models, some countries have deliberately chosen not to make a high-stakes use of teacher data and to forgo teacher–student data links in their education information systems.
Availability of longitudinal, unique identifiers (N = 64).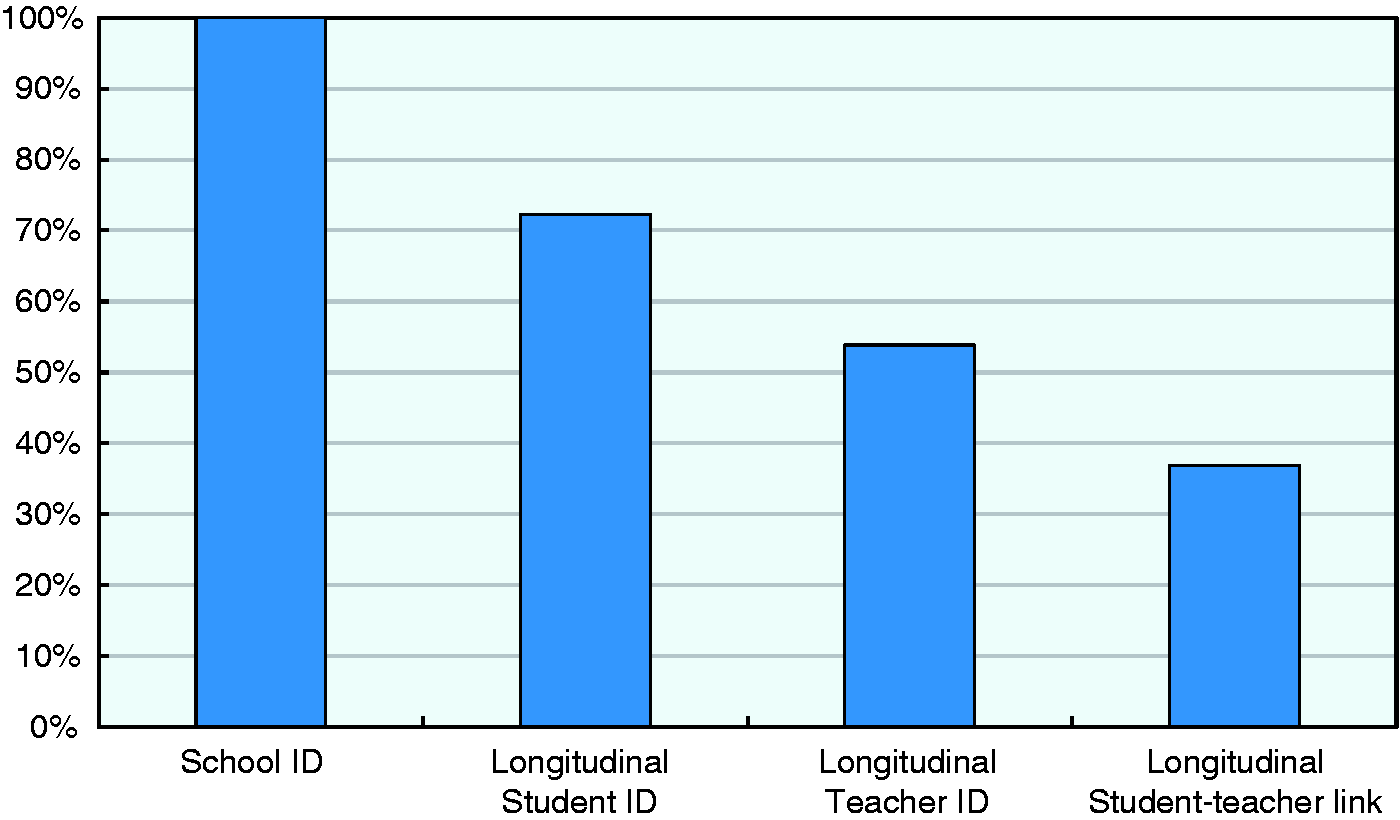
Data elements
The variety and granularity of data elements is another critical determinant of the ability of information systems to provide teachers and learners with useful feedback and to shed new light on the dynamics and determinants of effective teaching and learning. Figure 2 shows the percentage of systems providing different types of student data. Results suggest that information on student performance is still largely focused on conventional, summative attainment indicators such as graduation status and final course grades, which about 80% of systems maintain in one form or another. Information on other aspects of student experiences and outcomes is less common. Daily attendance records at the class or school level are maintained by 43% of systems in the survey, while only about 20% maintain data that can be used to diagnose learning needs; for instance, item- or task-level answers in tests and exercises that have been used in a formative way. The same holds for information on student high-order skills such as critical thinking or creativity, or social and behavioural skills such as perseverance or collaboration.
Student data elements (N = 64).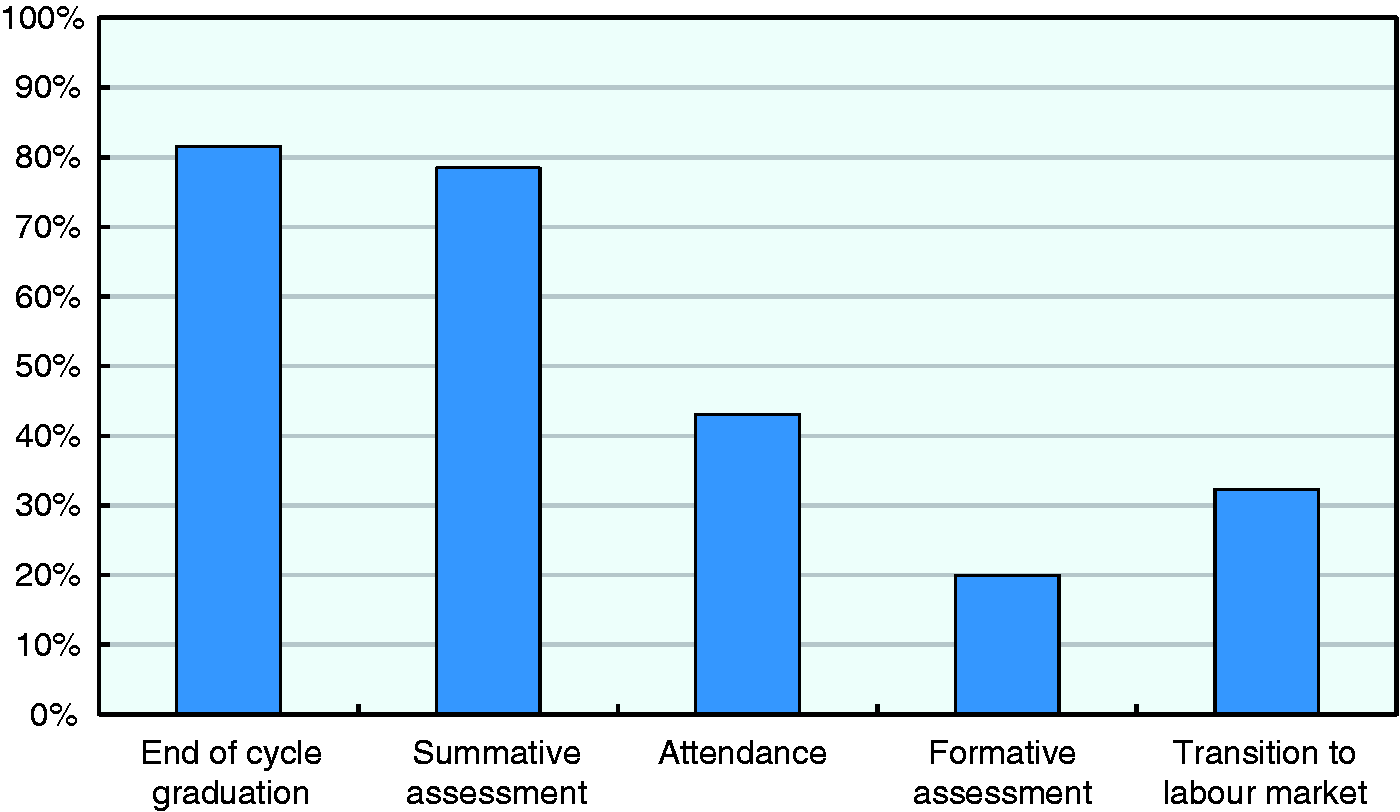
The focus on summative achievement in a limited number of subjects and the relative dearth of other types of student data reflecting the learning process and a broader set of skills has implications for the ability of information systems to inform discussions about how to better support student needs. Formative assessment data can play a crucial role in supporting learning when conveying information about students’ thought processes and misconceptions that teachers could use to make adjustments in instruction. Collecting and making available to educators and researchers a wider range of measurements of student learning and competences could also provide valuable input on the effectiveness of innovative educational practices. By including a broad range of student performance data, information systems could enrich discussions among practitioners and open new avenues for educational research.
Another way in which longitudinal information systems could sustain innovative uses of education data is by providing linkages to labour market data or data from other agencies such as healthcare or social services. These data can be used to extend the scope of analyses on the outcomes associated with educational attainment. The survey suggests, however, that the possibilities that these linkages open up are underexploited, with only 32% of systems providing, for instance, data on students’ transition to the labour market.
As for information relating to teachers, Figure 3 shows some of the most common teacher data elements available, maintained by the systems in the survey. This information, present in more than half of the systems, tends to focus on teacher credentials, seniority and assigned subjects. By contrast, information that may speak more directly about teacher performance or training needs is more rarely available, as, for instance, only 23% and 34% of systems in the survey maintain records of teacher evaluations or participation in professional development, respectively.
Teacher data elements (N = 64).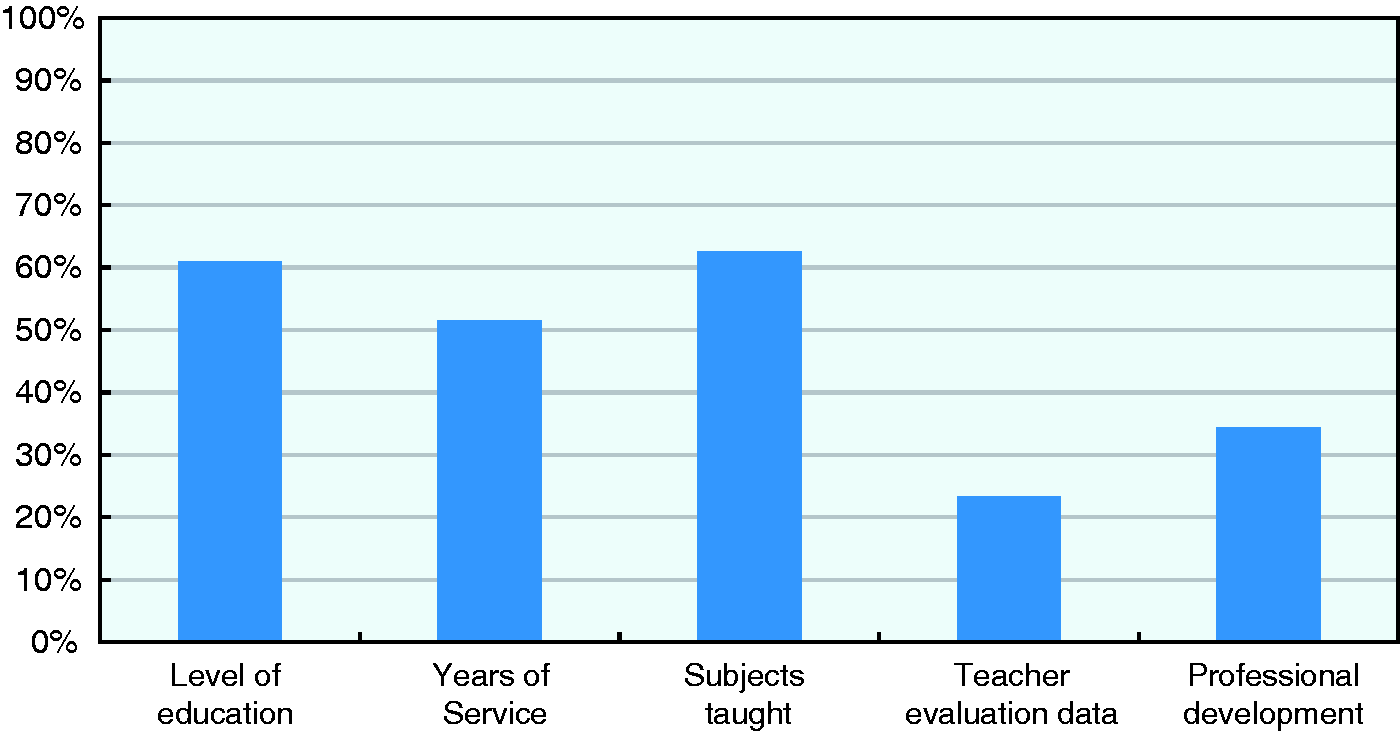
Overall, the survey results suggest that most systems could make progress in incorporating more diverse forms of student assessment records beyond traditional summative indicators; for instance, data on creative and critical thinking skills and more granular assessment data that could be used in a formative way. Systems could also extend the scope of teacher-level data, for instance, by maintaining records of classroom observations, and give teachers opportunities to input information in the system.
Speed of feedback
Complementary to the diversity and granularity of data that they maintain, the speed at which information systems provide feedback to different stakeholders is crucial to their potential to be used to improve student and school outcomes. Feedback needs to be timely in order to effectively support improvement efforts. If the information emerging from a system refers to processes and outcomes too distant in time, its value is likely to diminish. The extent to which delays in the provision of feedback affects the value of data will of course vary across data elements and stakeholders. Only quick feedback allows teachers to identify learning gaps and adjust instruction for the students for which the data are collected. Similarly, daily updates of class attendance records can support more effective action to prevent student absenteeism than end-of-year summaries of school attendance patterns. On the other hand, valuable feedback to inform school- or system-wide policies may require less immediacy, as when aggregate information on school performance trends flows to principals and education authorities on a semestrial or yearly basis.
Figure 4 shows the time lags that information systems impose between data collection and the moment when data are made available to different systems users. The responses reveal that administrators and school principals tend to enjoy the quickest access to data, while students, families and researchers have to wait the longest and teachers occupy an intermediate position. About 43% of the systems in the survey make information flow to administrators and school principals in real time, but only 33% provide such rapid feedback to teachers. One third to half of the systems in the survey take more than four months to make their data accessible to different stakeholders, a timeframe which can be at odds with the aim of supporting timely and effective interventions, especially regarding instructional practices. Commonly cited reasons for these delays include data cleaning and anonymisation procedures, but also suboptimal technical integration between the information systems and their feeding databases.
Speed of feedback (N = 46).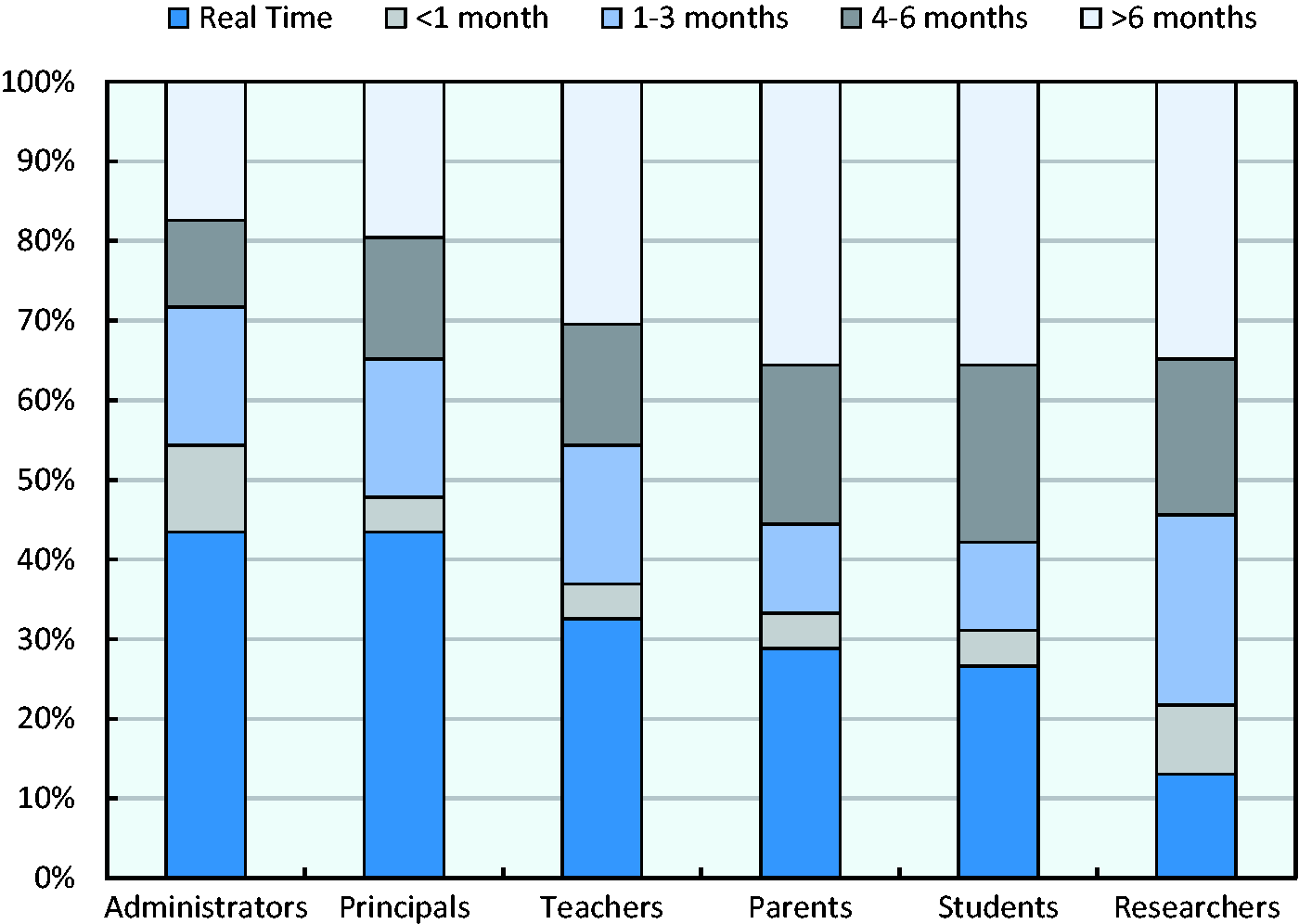
Analysis and comparison tools
One of the features distinguishing advanced longitudinal information systems from data warehouses is the integration of data visualisation and analysis functionalities that enable users to engage in data mining; for instance, selecting indicators of their interest, visualising trends and carrying out comparisons across student cohorts or schools. These functionalities may be available either through pre-defined reports or user-friendly tools to perform custom queries. These tools can facilitate comparisons at multiple levels and help contextualise their results; for instance, by referring to benchmarks or peer-groups (e.g. schools with a similar demographic intake). Dashboards for the visualisation of key metrics are the most common example of this type of tools. Ideally, dashboards would have the capacity to aggregate information from multiple underlying sources, present up-to-date information and be customisable for users with different data access rights, and are needed to address different questions at the classroom, school or central agency levels.
Figure 5 shows that 62% of systems in the CERI survey integrate visualisation and analysis tools, and that the majority of those systems enable comparisons between schools and students. When available, the tools normally permit to carry out peer comparisons, such as between schools or classes with students of similar socio-economic or gender composition (not shown). A smaller proportion of systems (32%) incorporate the enhanced functionality of enabling estimations and predictive analyses of student performance based on existing data. However, the fact that almost one in four systems does not yet integrate any kind of visualisation and analytical functionalities suggests an untapped potential of information systems in many countries to work not only as tools for collecting and managing raw data but also for supporting education stakeholders in turning such data into valuable information.
Integrated analysis tools and enabled comparisons (N = 64).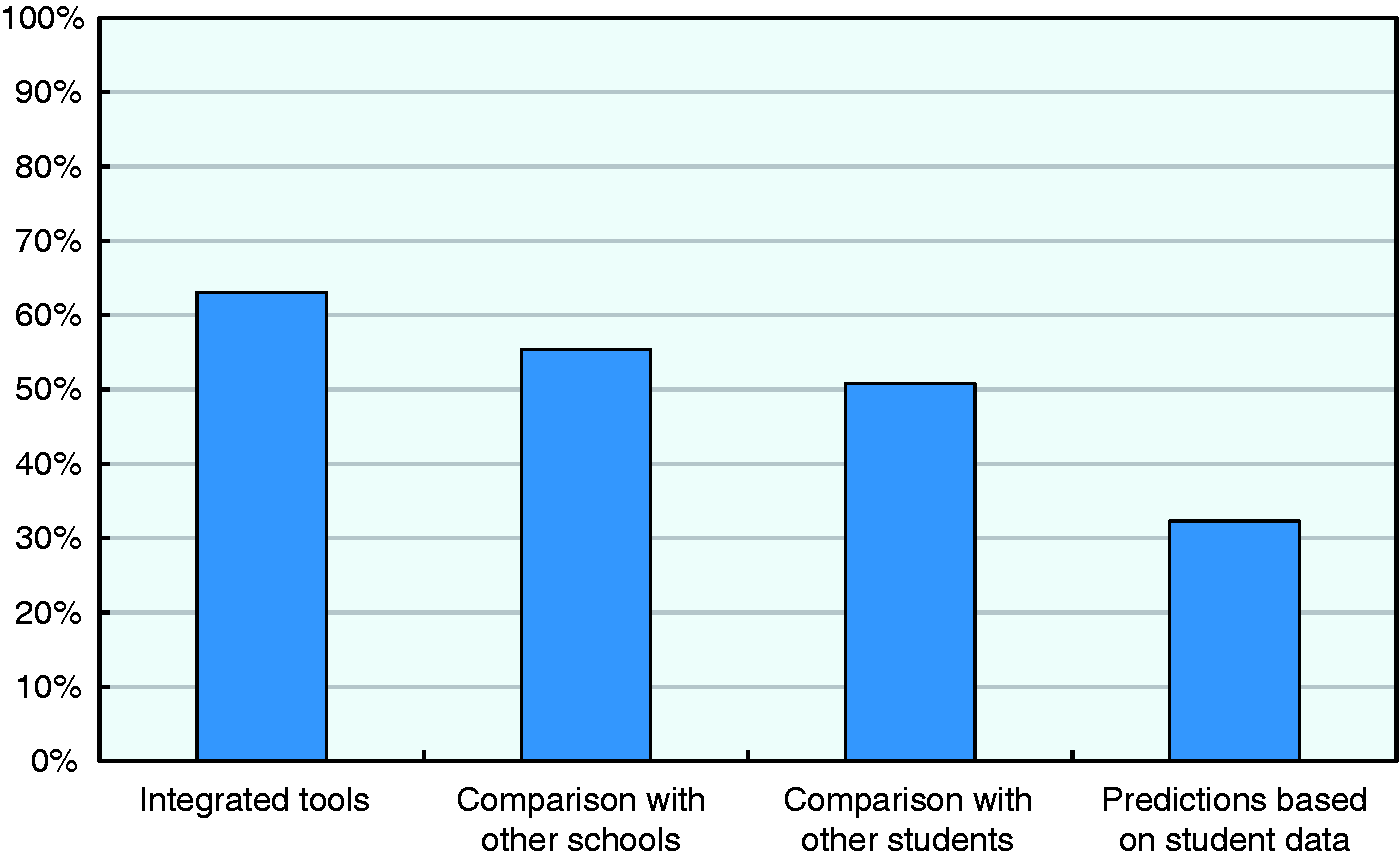
Access to digital learning resources, knowledge networks and training on data use
The next generation of longitudinal information systems in education could also move beyond the collection and reporting of data by developing functionalities that help inform instructional practices in more direct ways. A key step in this direction would be the integration of statistical data systems with virtual learning platforms that provide access to digital materials for teaching and learning, typically through school learning management systems or through independent, affiliated content repositories. These platforms are designed to support classroom instruction or work on self-directed learning by giving access to content and assessment tools in a variety of formats, from digital textbooks to video and tutorials, educational games, etc. Their integration with data systems could be an opportunity to set up direct links for teachers and learners to access these digital materials, but also to use the data in the systems to inform recommendations of specific materials.
Another potential functionality of next-generation information systems would be to support the development of communities of practice for teachers and decision makers alike. Virtual networking functionalities such as blogs, wikis, mailing lists or social media groups would, for instance, allow educators to share practical knowledge across subjects and schools, and to create networks of teachers and schools facing similar challenges. Information systems could further support practitioners by providing training to help them use data and derive actionable insights for instruction. Systems could facilitate this through guides, video tutorials or webinars that may complement face-to-face training opportunities.
Figure 6 shows that only a small proportion of systems incorporate some of these advanced functionalities. Training programmes to use data in classroom settings exist for about 50% of the systems, most commonly in the US. Links to banks of educational resources are rare, with only 25% and 14% of systems providing access to such materials for teachers and students, respectively. Present in only 16% of systems, tools to support communities or practice are also the exception rather than the norm. Survey results, therefore, suggest that most current education information systems do not yet operate as hubs to transform data into personalised advice and support for teaching and learning practices.
Availability of instructional materials and support for data use (N = 64).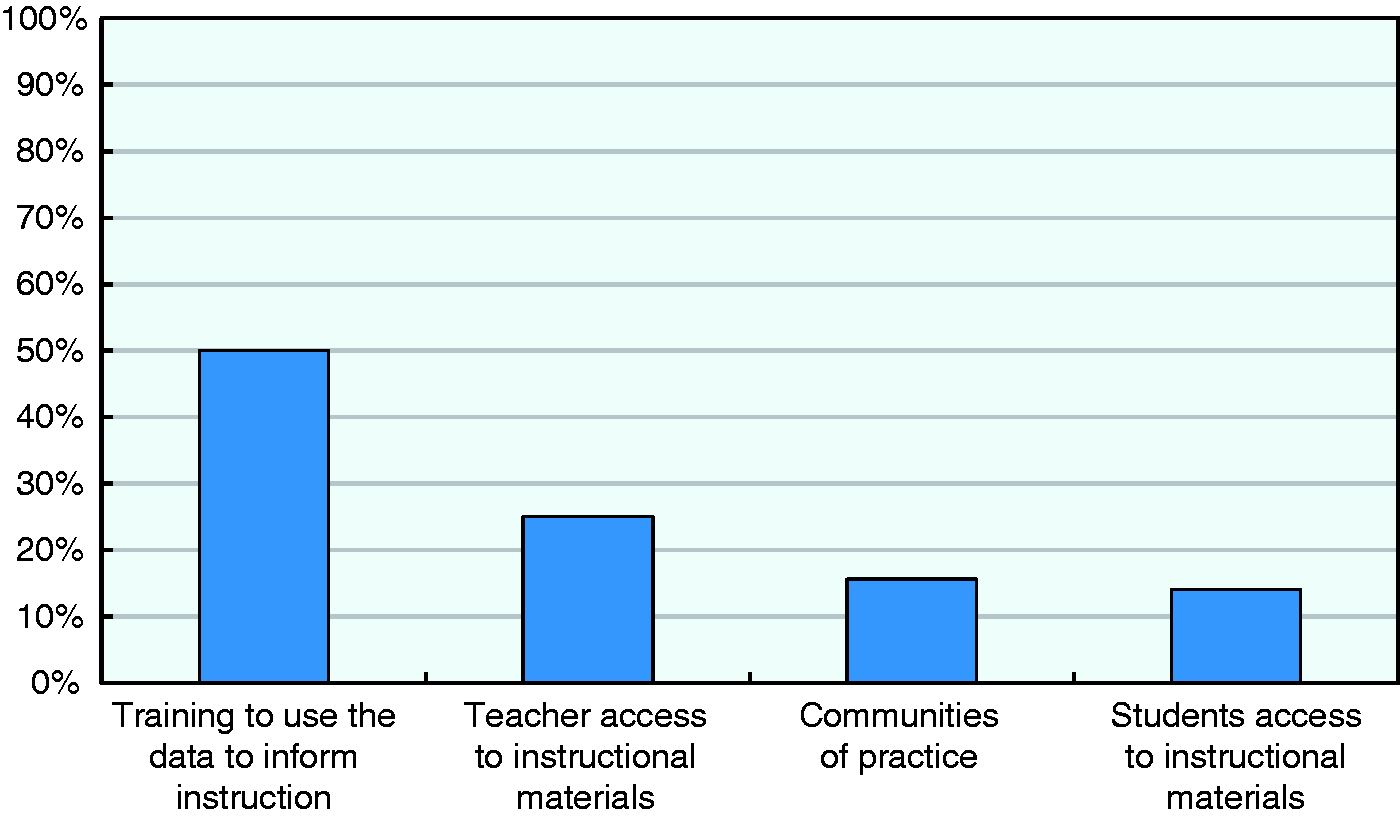
Concluding remarks
Results from the CERI survey of education information systems suggests that many countries across the OECD area and beyond are building the infrastructure that will allow them to move from a culture of statistical reporting to more promising models of education data use. However, many national and state information systems do not yet possess the design features to fully exploit the wealth of education data they routinely maintain. Rather than a paucity of data on learning and achievement outcomes, it is the longitudinal linkage of student-level data with other records that remains the key area for improvement. A second dimension where these systems could improve is the integration of flexible analysis and reporting tools that speed up the provision of feedback, provide suggestions and resources to take action and put data in the hands of a larger number of stakeholders.
Massive administrative data collection combined with other types of data could indeed lead to the emergence of a host of innovative social practices and power a more personalised teaching and learning in education. While many of the possible transformations are just possible, there is one that is almost certain: a positive impact on educational research and on the creation and use of knowledge in education (OECD, 2007). If all else failed, new longitudinal information systems would indeed at least represent an improved solution to collecting, managing and making data available for educational research. Our concluding remarks will highlight the transformative potential of longitudinal information systems in this specific area.
First and foremost, longitudinal information systems generally give the opportunity to track entire student populations on a continuous basis. Working with data on the whole student population makes educational research findings much more robust, with questions of statistical power becoming irrelevant. The impact of changing policies and their variation across subgroups of students or schools could, for example, be analysed more easily and with more confidence (Dynarski and Berends, 2015).
Data collected in longitudinal information systems can also strengthen educational research by allowing one to address more confidently causality questions. They provide a more solid basis to interpret relationships between assumed causes and effects compared to repeated cross-sectional data (Menard, 2002; Saw and Schneider, 2016). They can also facilitate the adoption of more complex research strategies, including the application of techniques that permit researchers to approximate experimental settings such as the construction of control groups through matched designs or instrumental variable approaches.
An improved data infrastructure would benefit qualitative research as well. The baseline and contextual information provided by data systems can be used to inform the design of ethnographic studies; for instance, to identify cases that field work will explore, or to triangulate findings.
High-quality longitudinal data are, in particular, essential to enable rigorous evaluations of innovative programmes. Researchers make important contributions to the innovation process by testing the impact of new initiatives and the conditions under which they are most and least effective. This is particularly relevant for programmes with incremental approaches, where lessons from early implementation stages can inform subsequent programme iterations and, ultimately, scaling up.
Finally, the linkage of data from multiple sources that longitudinal information systems can bring about can enable researchers to examine a greater number of variables and expand the scope of their analyses. For example, in the UK, matched data from a wide range of sources using shared identifiers feeds the National Pupil Database, a longitudinal census containing extensive information about students, teachers and schools in England.
In spite of all these promises, the challenges to building an effective data infrastructure to support educational research are multiple. They include building sustainable partnerships for data sharing, developing common understandings and objectives for data use and addressing mounting concerns about data security and student privacy. Partnerships should build on and reinforce institutional trust and help overcome potential tensions between the use of data for knowledge building through research and their use for policymaking and management. These frictions typically stem from different time horizons between researchers and policymakers, different emphasis on rigour versus relevance and different audiences and constituencies. National education agencies may be unwilling to share data that reveal unsatisfactory outcomes, but compromises can be found by incorporating more policy-relevant questions to research agendas or by “no surprise” rules whereby researchers inform policymakers prior to the publication of their results. Data sharing partnerships also call for effective data governance structures that regulate data ownership and help ensure continuity through policy shifts. In some countries changes in regulatory frameworks may be in order to permit more effective data matching across different public datasets. Striking a balance between the privacy of subjects and the analytical value of data appears as a major challenge for regulating the use of education data for research purposes.
The potential benefits for educational research outlined above require that researchers have access to the data included in the longitudinal information system. Access to these data by researchers is difficult in the majority of systems, even after data anonymisation. As public authorities do generally not have the resources, the time or the competences to exploit all the data collected and maintained through their information systems, the knowledge that could be generated from education data is rarely leveraged to the full. The adoption of secure data access arrangements is, therefore, an area for improvement for the next generation of longitudinal education information systems.
While the development and use of a new generation of longitudinal information systems has the potential to transform the education sector into a strategic sector that can experiment and learn from its innovations, there are many hurdles for this future policy to materialise. A challenge lies in equipping information systems with the right features and functionalities. But this may be the easiest compared to the social, organisational and institutional innovations that will allow all educational stakeholders to make a positive and responsible use of all these data to support continuous improvement and innovation in education.
Footnotes
Acknowledgement
The authors wish to thank anonymous reviewers for helpful comments and suggestions.
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The analyses presented and the opinions expressed in this paper are those of the authors and do not necessarily reflect the views of the OECD.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.