
Abstract
This work contributes to the evolving discourse on biodigital architecture by examining how generative artificial intelligence (AI) and extended reality (XR) systems can be combined to create immersive urban environments. Focusing on the case study of “Osmosis”, a series of large-scale public installations, this work proposes a methodological framework for real-time architectural composition in XR using diffusion models and interaction. The project reframes the architectural façade as a semi permeable membrane, through which digital content diffuses in response to environmental and user inputs. By integrating natural language prompts, multimodal input, and AI-generated visual synthesis with projection mapping, Osmosis advances a vision for urban architecture that is interactive, data-driven, and sensorially rich. The work explores new design territories where stochastic form-making and real-time responsiveness intersect, and positions AI as an augmentation of architectural creativity rather than its replacement.
Keywords
Introduction & literature review
The rise of mediated urban environments has transformed contemporary cityscapes. From iconic locations like Times Square to emerging LED-clad architectural façades worldwide, large scale public displays are reshaping how cities communicate, engage, and perform. High tech interactive façades, projection mapped buildings, and immersive museums with LED walls are shaping the future of augmented cities. As media architecture expands into immersive and interactive realms, it becomes a powerful interface between physical structures and digital expression. Parallel to this evolution, generative artificial intelligence (AI)—particularly diffusion-based models—has become increasingly influential in the design fields, offering novel ways of producing, transforming, and interpreting visual content in response to contextual input.1,2
This convergence between AI and urban media opens new possibilities for architectural computing that move beyond pre-rendered content. Most existing urban installations operate on deterministic frameworks with little room for adaptation or collaborative input. This paper addresses that limitation by proposing an alternative: a real time pipeline in which AI generated content can respond dynamically to user presence, environmental signals, or other forms of input. The goal is not to replace traditional design processes but to extend them with AI driven responsiveness and transmodal interaction.
We pose two guiding questions: - How can a real time AI driven content pipeline be developed for immersive architectural façades using generative AI models? - How can real time collaboration be achieved to produce transmodal XR layers tailored to the architectural and spatial logic of buildings?
We present Osmosis, 3 a series of practice led installations exploring a computational framework that integrates generative AI -specifically Diffusion Models (DMs)- with XR technologies. Taking inspiration from the biological principle of osmosis, the framework introduces a conceptual model of permeable exchange - where machine learning systems, media content, and architectural surfaces interact continuously. This analogy is intended as a guiding metaphor for exploring gradients of transformation across digital and physical layers. Osmosis, as an artistic research, does not involve empirical evaluation such as user surveys or biometric tracking. Instead, it is grounded in speculative prototyping and experiential design to propose new trajectories in biodigital architecture and real time urban computation with AI and XR.
Evolution of urban media façades and urban media architectures
Times Square’s evolution, as described by Samuel R. Delany4,5 represents an early example of the integration of large-scale urban media, with electrified advertisements appearing as early as 1907 and now featuring over 55 LED displays that convert content into digital property within urban space. Other notable examples include Shibuya Crossing (Tokyo), COEX K-Pop Square (Seoul), Fremont Street Experience (Las Vegas), and Piccadilly Circus (London). More recently, structures like the “Sphere” in Las Vegas define the growing global trend of integrating architectural forms with digital media. 6
Urban spaces increasingly become canvases for creative and experimental media displays. 7 This is also observed at International Light Festivals. The Fête des Lumières festival in Lyon, which has been running since 1852, began incorporating projection mapping in the early 2000s. Other prominent festivals that showcase engaging light installations and projection mapping in urban settings include the Festival of Lights in Berlin, Light Night Leeds in the UK, Tokyo Lights in Japan, and the Amsterdam Light Festival in the Netherlands. Newer events such as the Llum BCN Festival in Barcelona continue to expand this dialogue by foregrounding experimental urban media art and festivals highlight the artistic potential of media in public spaces.
However, there is a disparity between temporary light installations and permanent, non-permeable structures on building façades. In Times Square, for example, the architectural charm of historic buildings is often overshadowed by black LED displays that rely on electricity. While these displays are captivating when operational, they can be alienating when not powered. The key challenge is integrating modern display technologies into existing structures in a way that complements their architectural integrity and also addresses the concern about what happens when the display technology becomes obsolete. Newly constructed buildings can seamlessly incorporate displays, but the long term impact of this integration needs to be considered.
From a content perspective, urban centers often function as advertising platforms controlled by private companies focused on profit. This contrasts with cultural events and museums that showcase artistic content, emphasizing aesthetics, and creativity. Although advertisements can be compelling, scaling material produced for personal displays devices such as smartphones to building-sized screens often overlooks the medium’s scale and location. This lack of choice in spatial aesthetics and coherence can disconnect users from the architectural integrity and identity of space.
This leads to the need for a more balanced approach that integrates display technologies into the design process, respecting the architectural context and offering diverse, engaging content that goes beyond mere advertising. Unlike commercial displays focused on spectacle or advertising, and unlike temporary artistic projections that often remain isolated interventions, the Osmosis framework proposes an architectural composition model in which the media façade itself becomes an interface for real time, collaborative content generation. This shifts the emphasis from content consumption to content co creation, and from passive spectacle to dynamic mediation and active engagement. While inspired by the aesthetic and participatory qualities of international light festivals, Osmosis differs by embedding generative AI and XR technologies into the structural logic of the architectural surface, enabling the continuous reconfiguration of spatial media in response to evolving user and environmental inputs. This approach reconsiders authorship and agency in architectural computing, positioning the façade as a living interface rather than a static screen. The temporary nature of some installations contrasts with the permanent impact of others, suggesting a need for architects, engineers, artists, and media designers to work together to create more seamlessly integrated solutions. Integrating AI and XR technologies could offer new ways of mediating this relationship.
Artificial intelligence and extended reality in architecture
Over the past few years, digital content creation has progressed through several stages to today’s generative AI-enhanced aesthetics. Image machines have progressed from basic object recognition to generative systems capable of “seeing” and “creating” with human-like sophistication.
8
This evolution, from passive processing to active creation, opens new possibilities for architectural design and urban media (Figure 1). Current technologies employ deep learning to generate and manipulate images with human-like sophistication, marking a shift from passive image processing to active “seeing” and “creating” by machines. The ability of machines to generate high-resolution images and videos from textual descriptions has opened new possibilities in architecture and other design fields. Photograph from the Greek Parliament building. “Desire for Freedom” was one of the most widespread projection mapping events in Europe, running simultaneously across 18 cities and buildings in Greece in June 2021. Led by the TUC TIE Lab, at TUC’s School of Architecture. Source: Authors, TUC Transformable Intelligent Environments Lab, 2021.
Generative AI now plays an increasingly prominent role across the architectural design pipeline, from ideation to immersive environment creation.9–11 Generative AI models translate natural language prompts into visual concepts and are proving to be very useful in the early phases of design. 12 In a pedagogical setting study, students used a “Double-Layered Model” to generate images based on different prompts, facilitating explorations of possibilities that might not have been considered otherwise. 13
In speculative design, Generative Adversarial Networks (GANs) such as CycleGAN and StyleGAN, 14 and more recently Diffusion Models (DMs), have been employed to investigate architectural form and typology through machine learning.2,15 As of 2020, DMs have emerged as a new generative paradigm that uses noise removal techniques. DMs operate on a different logic than GANs, relying on a probabilistic model of noise addition and removal to simulate entropy reversal. These techniques allow for granular control over visual output and often produce more consistent results than adversarial approaches.16,17 Sora, Stable Diffusion, Midjourney, Leonardo, and DALL-E are among the most popular DMs, due to their comprehensive interfaces, output control, and ability to rapidly translate natural language prompts into detailed conceptual images and videos. Platforms such as Hugging Face provide downloadable open source AI models that can be trained, fine-tuned, and run locally on a single computer.
AI also enables speculation and prediction of new architectural styles based on training with existing ones. The Deep Himmelblau project exemplifies using AI to explore potential new designs based on existing works by Coop Himmelblau. 18 Such strategies reveal how generative systems can serve both as speculative tools and critical lenses through which design legacies are extended.
Simultaneously, the fusion of Generative AI and Extended Reality (XR) environments is reshaping speculative and virtual architecture, creating novel possibilities for design, interaction immersive urban computation. Projects like Refik Anadol Studio’s Living Architecture: Casa Batlló project. 19 illustrate how XR, environmental data, and generative systems can converge into site-specific visual storytelling. This project merges XR with physical architectural compositions by utilizing the intricate relationship between the building’s façade, the surrounding urban environment, and real-time weather data. Artists such as Sofia Crespo and Quayola also deployed two urban projection mapping installations on Antoni Gaudí’s Casa Batlló and created hybrid façades of physical, computational, and complex organic forms.20,21 This line of experimentation correlates with Osmosis by layering projection mapping and hybrid AI-generated organic textures onto architectural surfaces. These practices demonstrate how XR and generative AI can operate beyond aesthetic augmentation, contributing to temporally dynamic, environmentally responsive, and digitally mediated architecture.
While these projects contribute significantly to media arts and cultural installation, Osmosis builds on this lineage by developing a practice-led architectural computing framework. Our approach differentiates itself by integrating real-time generative AI systems into the structural behavior of urban facades. Rather than pre-rendered compositions, the Osmosis framework positions the facade as a perceptive membrane and an interface through which architectural experience is shaped in open collaboration between users, artists, and data.
Core methodological approach
Our research follows a practice-based methodology situated at the intersection of computational design and real-time XR environments. As discussed previously, the integration of AI-driven form-finding processes with immersive urban media signifies a shift in architectural computing, moving from deterministic models toward emergent, probabilistic systems. 22 In this transition, synthesis becomes a core structural principle, organizing generative outputs beyond formal replication.
Diffusion Models (DMs) and Large Language Models (LLMs) are inherently probabilistic and are capable of interpolating new structures within latent space rather than merely referencing known typologies. 23 Unlike traditional parametric models, which rely on explicit mathematical constraints, DMs introduce noise into an image and systematically remove it, creating intricate and evolving compositions that parallel natural complex systems. 24 Such models are rooted in principles of non-equilibrium thermodynamics, mirroring self-organizing behaviors found in biological and physical systems, while also aligning with concepts of latent space structuring and computational representation explored in AI-driven generative synthesis.25,26 As Somaini and Manovich have noted, recent AI text-to-image models resonate with avant-garde artistic movements that embraced chance as a creative strategy, such as Dadaism and Surrealism, and also draw parallels to contemporary algorithmic aesthetics that redefine visual culture through deep-learning image synthesis.
This methodological orientation builds upon our previous large-scale immersive installations, including the olfactory-driven installation Alloplex BioAffective Worlds XR: Hydnum
27
and the Synaptic Time Tunnel, a 130 × 15 ft XR installation deployed at the Los Angeles Convention Center during ACM SIGGRAPH 2023 (Figure 2). These projects explored real-time multi-layered systems where algorithmic processes and user interaction shaped evolving spatial compositions through datasets and live, adaptive input modulation. “Synaptic Time Tunnel”, an example of a perforated system with multiple collaborative interconnected layers. Siggraph 2023, Los Angeles Convention Center. Source: Weihao Qiu, 2023.
Within this framework, we articulate the concept of perforated systems. Perforated systems, a term coined by Marcos Novak, embrace a dynamic interplay between multiple compositional layers of deterministic and stochastic elements, enabling digital and material interfaces to co-evolve through user interaction. 28 A perforated system can be defined as a composite structure consisting of multiple interconnected layers that function synergistically, resulting in an integrated whole that transcends the mere summation of its individual components. Osmosis extends this methodology by embedding generative AI within the architectural interface itself, creating a feedback-rich design environment where real-time media and form composition converge.
Practical application - the “osmosis” research project
The Osmosis project investigates the intersection of generative AI-driven content creation and immersive urban environments through a biomimetic conceptual framework. Drawing abstract inspiration from the biological process of osmosis -where solvent molecules move across a semi-permeable membrane due to differential concentration gradients 29 - this research conceptualizes the urban façade as a dynamic interface that mediates between digital and physical layers. In this metaphorical model, AI-generated visuals act as the ‘solute,’ the built environment as the ‘solvent,’ and the architectural surface as the semipermeable membrane. The ‘osmotic pressure’ refers to algorithmically modulated input intensity, such as prompt weights or visual coherence. This conceptual translation does not aim to replicate the biological mechanism but rather to provide a guiding logic for generative exchange in hybrid architectural systems.
We present four urban projection mapping installations, realized between 2023 and 2024. The first three were presented at the Santa Barbara Center for Arts, Science, and Technology (SBCAST), and the fourth spanned dual water towers across the Santa Barbara Community Arts Workshop. All installations were executed as components of art exhibitions and engaged approximately 150 to 300 participants. Each iteration deployed variations of diffusion-based generative models -specifically text-to-video, image-to-video, and video-to video systems- along with customized projection mapping workflows and interactive pipelines.
These installations highlight how generative synthesis can produce dynamic architectural experiences, evolving in response to environmental cues and user-driven input. While some modalities, such as biosignal integration, are part of the evolving pipeline and not yet activated in public exhibitions, other forms of user interaction, including real-time parameter control and natural language prompts, were deployed. The outputs functioned as public media artworks, revealing the architectural potential of diffusion models when scaled to urban surfaces.
This work positions Osmosis at the intersection of Artificial Intelligence, Architectural Computation, and Media Arts. The primary focus was on using Diffusion-based AI models for immersive content generation in urban spaces. Diffusion Models were selected for their ability to operate with natural language, making them more accessible than lower-level programming languages. His methodological and conceptual model offers a foundation for future extensions of real-time AI-driven urban computing systems.
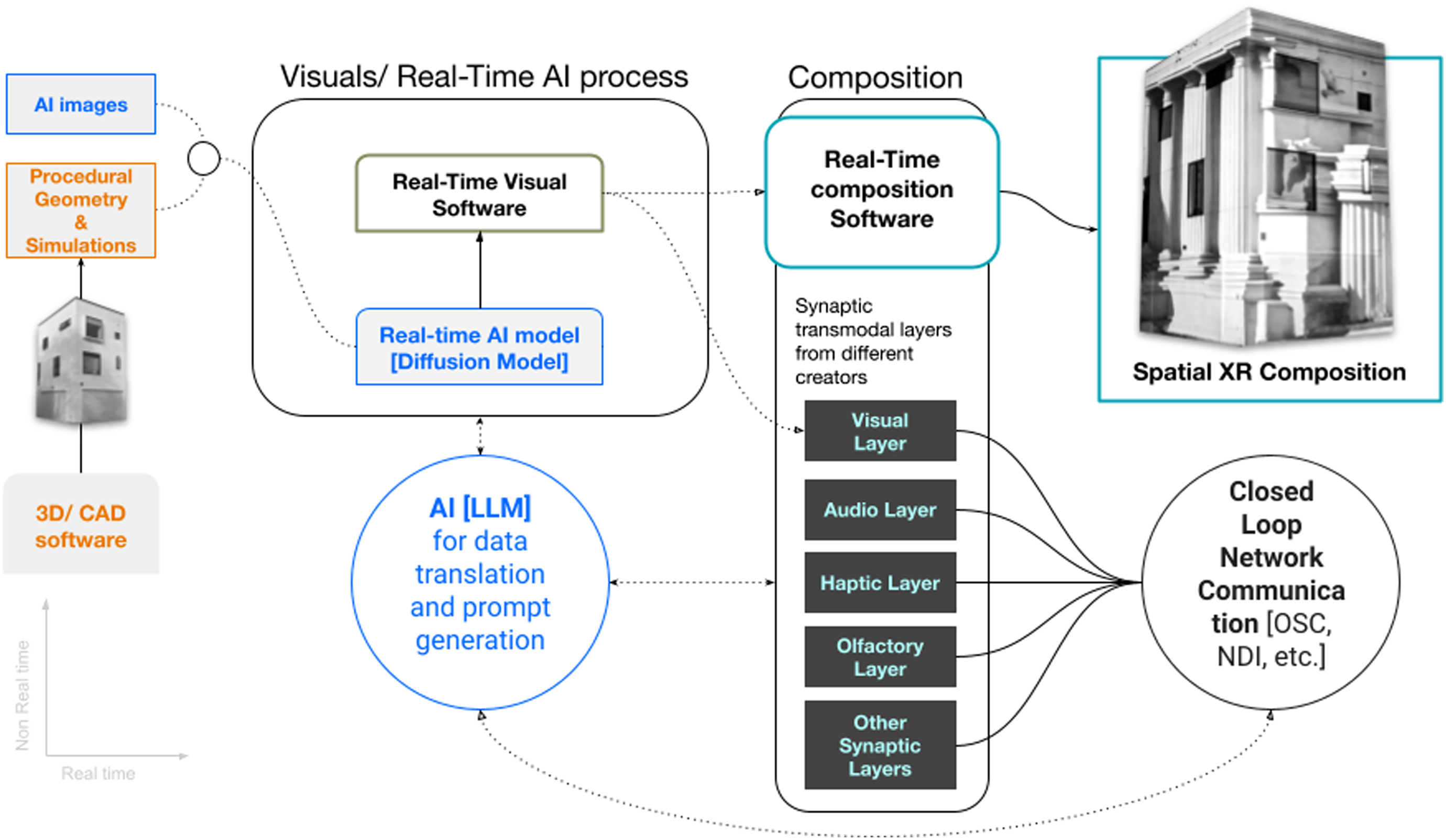
AI hybrid content generation pipeline
In Osmosis, diffusion models (DMs) enable non-deterministic real-time architectural compositions that evolve through feedback. By interpolating across latent space, these models generate imagery that reflects organic-like complexity rather than rigid formalism. The workflow for producing content in each installation followed a structured multi-step sequence (Figure 3): • Developing high-fidelity 3D scans or manual models of target buildings or facades • Designing generative and procedural effects mapped to architectural features and projection layouts • Importing architectural renders into AI diffusion models for transformation (used in all but the fourth iteration) • Layering procedural and AI-generated imagery to create hybrid architectural compositions • Rendering outputs as AI-generated videos, with real-time rendering capabilities tested in final iteration • Using projection mapping software to align content with building surfaces and enable interactive input The proposed pipeline of the process for real-time AI-generated transmodal immersive façades. Source: Authors, 2024.
Across multiple iterations, we explored and refined the use of various AI models based on visual complexity, system responsiveness, and interactivity. Each of the four installations utilized AI models that received text, image, or video inputs to generate dynamic outputs. The first two installations employed a pre-rendered pipeline in which procedurally generated building videos and AI generated imagery were input into the system. In contrast, the final two installations marked a significant development with the use of a real-time diffusion model capable of handling multimodal input. This shift allowed for live adjustment of inputs, weights, and generation parameters during performance.
Projection mapping required precise adaptation of AI-generated content to match the unique physical characteristics of the building. Since video-to-video models rely on source input characteristics -including contours, motion, and form- we created accurate digital representations of the buildings. A 3D model of the building was produced in Blender, allowing us to simulate effects within the building’s volumes using Blender’s geometry and simulation nodes, along with Python scripting. Each structure was modeled with an outline frame and included architectural elements such as windows, doors, and recessed planes. These volumes served as scaffolds for embedded visual effects.
We integrated fluid dynamics, particle systems, and virtual lighting within each building volume to enhance spatial depth and simulate internal illumination. Render cameras were positioned to match the physical projector placements on site, ensuring alignment and reducing distortion during projection. Each camera output was mapped to a corresponding projector to maintain perspective fidelity.
Following the simulation stage, AI-generated images were exported to be utilized as input. The AI image synthesis process utilized DALL-E and MidJourney, which generated images that embodied themes of complexity and biological processes. These images showcased abstract and intricate visual structures, cosmic formations, biomorphic designs, and speculative architectural spaces. The AI images were then input into video-to-video synthesis models, merging them with Blender-generated simulations to form dynamic architectural façade compositions.
For the first two installations at SBCAST, we employed RunwayML’s Gen-1 image-to-video model, which proved effective due to its ability to maintain structural coherence while generating dynamic content. It allowed precise control over key features such as edge definition, spatial alignment, and temporal consistency, which are critical for projection mapping onto complex surfaces without compromising the geometric integrity (Figure 4). Although Runway’s later text-to-video models offered enhanced creative capabilities, their reduced spatial control based on video inputs made them less suitable for architectural projection mapping. Osmosis process. A collection of AI-generated façades overlaying the building’s form with text-image, image-video, and video-to-video generations. Source: Authors, 2024.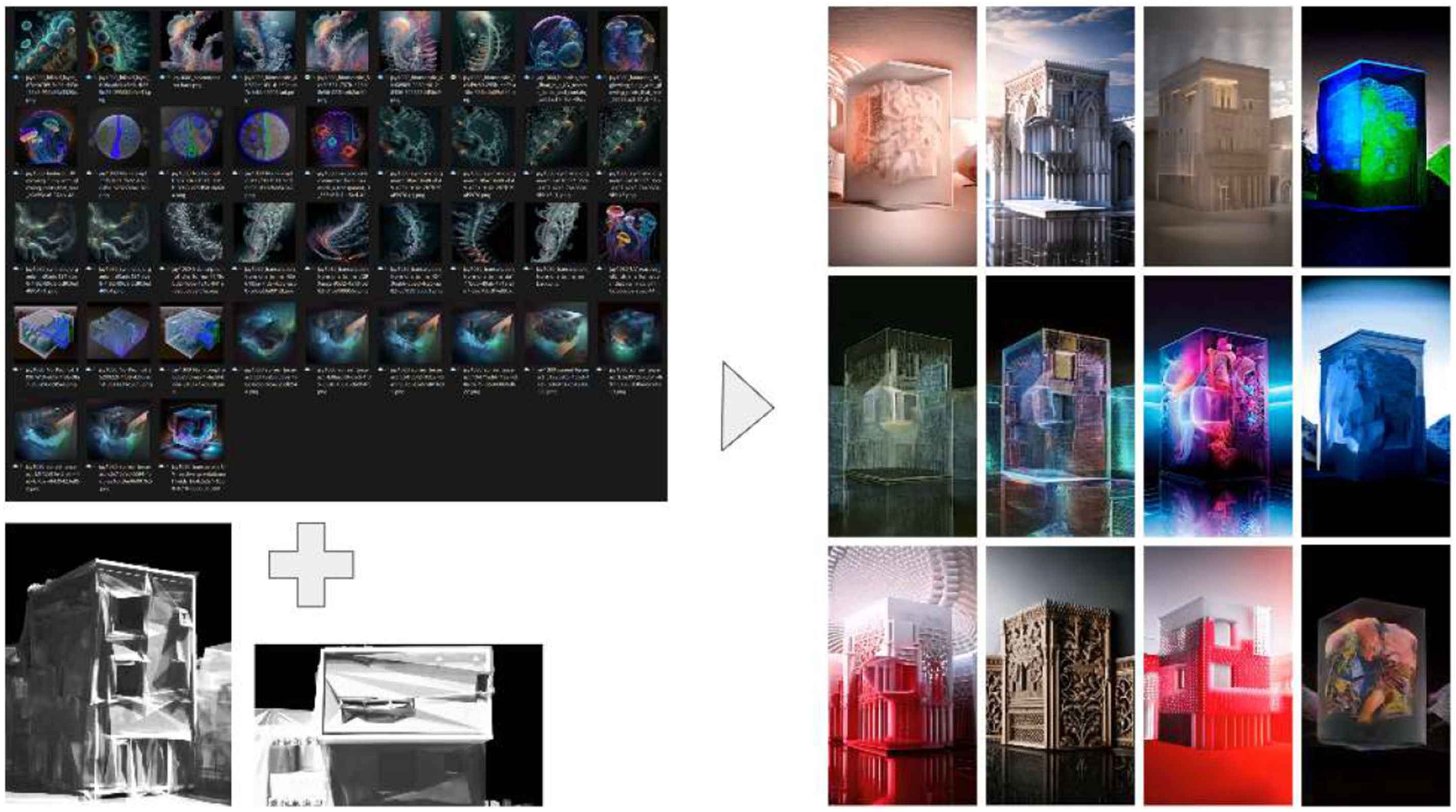
A key limitation of the Gen-1 approach was its reliance on pre-rendered video sequences of fixed duration, which resulted in perceptible repetition. To address this constraint and introduce real-time interactivity, we implemented a multi-layered composition in TouchDesigner. The system consisted of four core components: • Base layer: AI-generated simulations of architectural effects • Dynamic layer: Procedural Perlin noise introducing organic motion • Blend layer: Real-time opacity and composition modulation • Interaction layer: Live user input integration for parameter control.
TouchDesigner’s node-based visual programming environment allowed us to create a responsive system that could seamlessly blend the pre-rendered AI content with real-time generative elements. TouchDesigner partially masked the temporal limitations of the source material and enabled interaction with the Dynamic and Blend layers.
For the third and fourth installations, we made a significant shift by integrating StreamDiffusion 30 directly into TouchDesigner. StreamDiffusion achieves real-time performance by using an optimized guidance method that reduces the number of steps needed to transform noise into a clear image, increasing generation speed compared to traditional DMs. StreamDiffusion’s architecture, optimized for real-time inference, allowed us to generate AI content on-the-fly, fundamentally changing our pipeline from a pre-rendered to a live-generative approach. This integration offered several advantages, such as real-time AI content generation, dynamic response to user input and environmental conditions, direct manipulation of generation parameters, and more seamless integration with projection mapping systems.
Initially, we maintained our Blender-generated architectural simulations as reference inputs, ensuring the AI-generated content remained coherent with the physical structure. However, this real-time approach presented performance challenges especially due to StreamDiffusion’s GPU utilization load regularly exceeding 80%. This limited our ability to compute additional non-AI real-time effects. To maintain visual complexity while working within these computational constraints, we incorporated Perlin noise as a pre-processed input to StreamDiffusion, effectively guiding the generative process to create more intricate and organic results without additional post-processing overhead.
The fourth installation at the Santa Barbara water tanks represented a significant evolution in our pipeline, prioritizing portability and efficiency while maintaining high-resolution output. Building volumes were generated directly in TouchDesigner, eliminating the dependency on Blender and allowing real-time manipulation of lighting, shadows, and volumetric framing in response to live inputs.
We developed a more efficient rendering strategy where StreamDiffusion generated a single high-resolution texture containing all building components. This texture was then segmented and routed to multiple projectors through MadMapper. This optimized pipeline enabled us to run the entire installation from a single computer, eliminating the need for distributed rendering across multiple machines. The benefit of using multiple rendering nodes remains, especially when scaling up an urban installation; however, the fourth Osmosis installation proved the viability of a single AI rendering node.
Fine-tuning and optimization
After integrating real-time diffusion models into the Osmosis pipeline, we implemented fine-tuning for guiding the AI’s compositional output. We utilized two optimization technologies: Low-Rank Adaptation (LoRA) and ControlNet conditioning.31,32 Fine-tuning DMs with LoRAs in architectural XR compositions offers multiple possibilities, from training on specific building elements to influencing compositions through thematically relevant datasets. Instead of training on building features, we used LoRAs trained on biological microscopy imagery to maintain conceptual alignment with Osmosis’s bio-inspired framework. This influence surfaced in the resulting visuals as layered cellular motifs, morphogenetic forms, and interwoven organic textures.
ControlNet was integrated directly within TouchDesigner to introduce depth aware conditioning into StreamDiffusion. Depth maps were computed in real time from our 3D building simulations and matched to the live camera viewport. These maps were then passed to StreamDiffusion as secondary input, providing structure-aware generative constraints. The combination of LoRA and ControlNet enabled simultaneous creative guidance and structural consistency with LoRA steering the aesthetic direction while ControlNet maintained architectural integrity.
These enhancements also introduced new performance considerations. A StreamDiffusion instance with TensorRT acceleration running on a desktop with an Nvidia RTX 4090 GPU and an Intel i9 13900K CPU, could exceed 30 frames per second at 800 × 800 resolution. Performance was highly dependent on the Diffusion Model and the number of denoising steps. Stable Diffusion (SD) 2.1, for example, was faster than SD 1.5 since it required fewer denoising steps. However, adding LoRA and ControlNet optimizations caused frame rates to drop below 16 fps and, in some instances, reach 12 fps at the same resolution since ControlNet disabled the TensorRT acceleration. Artists and researchers working with real-time generative AI in projection-based environments may benefit from adjusting system priorities based on context. In high-interaction scenarios, we recommend optimizing for faster inference by reducing compositional layers. For larger displays or installations that prioritize visual density and duration, visual richness may take precedence over frame rate. These trade-offs highlight the importance of designing flexible system architectures capable of balancing performance and aesthetic complexity.
Extended reality integration
In the first three installations of Osmosis, we utilized two distinct volumes within the SBCAST complex: a three-story and a two-story structure positioned at a 90-degree angle from each other (Figure 4). The positioning of projected surfaces relative to audience location around the central courtyard was essential for depth perception and immersion (Figures 5–7). Performers controlling the real-time projection mapping were stationed adjacent to the courtyard’s center, facing the audience. Each performance lasted approximately 20 minutes. Axonometric diagram of the installation layout of “Osmosis” SBCAST. Source: Authors, 2024. A photograph taken from the performer's perspective during the third installation of “Osmosis” at SBCAST. Source: Authors, 2024. A photograph from the third installation of “Osmosis”. SBCAST. Source: Authors, 2024.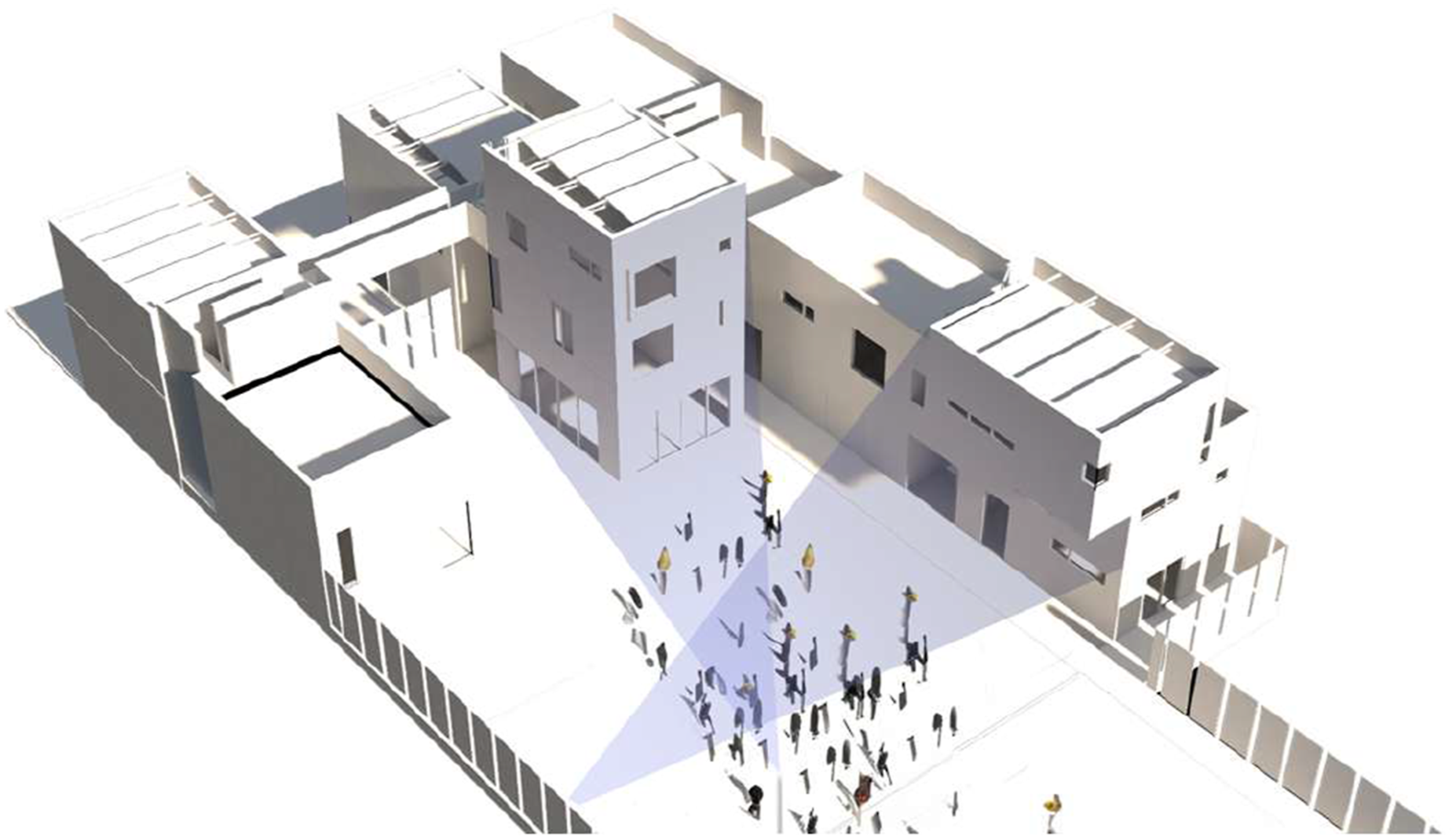


The technical infrastructure included a laptop with an Nvidia RTX 4090 GPU connected to two large venue projectors, handling projection mapping through MadMapper. Real-time AI content was generated on a desktop with another RTX 4090 GPU and streamed to the laptop over IP using the Network Device Interface (NDI) protocol. Each computer handled a distinct building volume processed through the Osmosis pipeline, and the outputs were blended in MadMapper. Additional communication between devices was facilitated through Open Sound Control (OSC), a protocol originally designed for musical contexts, now widely used for transmitting control data across interactive media systems.
A fourth iteration of Osmosis was demonstrated at the Santa Barbara Community Arts Workshop (CAW) during the Unite to Light the Night philanthropic event in October 2024 (Figure 8). This installation introduced new architectural challenges, as projections spanned two cylindrical water tanks, requiring a different technical and software strategy. We developed a cylindrical composition with simulations directly within TouchDesigner, eliminating the previously required Blender simulation phase. This modification resulted in a more computationally efficient integration, with AI generation and distribution occurring within a single machine. The larger video texture was subsequently cropped and distributed to individual projectors via MadMapper, as detailed in previous sections. Despite operating with constrained computational resources, we achieved 9-10 frames per second on a laptop with an Nvidia RTX 4090 GPU, generating an AI texture that covered both cylindrical water tanks and an adjacent flat wall. This iteration also included a custom LoRA model, with generation parameters (e.g., prompts, noise frequency, color mapping) dynamically controlled via a MIDI controller and a custom haptic interface developed by a collaborator. A photograph from the fourth installation of “Osmosis”. CAW, Santa Barbara, California. Source: Authors, 2024.
Comparison
Across the four installations, we observed substantial evolution in the generative pipeline driven by advancements in AI diffusion models. Earlier iterations relied on non-real-time models like Runway Gen-1, which produced pre-rendered videos requiring additional compositional layers to simulate interactivity and maintain architectural features. In contrast, later installations incorporated StreamDiffusion, enabling real-time AI-video generation. This allowed for dynamic prompt and seed modification during live performance, removing the need for layered augmentation and fundamentally shifting the pipeline toward a generative feedback model.
Furthermore, these AI models are still in an early stage of development. StreamDiffusion is considered one of the fastest models and can produce more than 30 frames per second at lower resolutions, although it is claimed to be capable of exceeding 90 fps in general. Output resolution is a limitation and requires additional high-resolution layers and effects overlaid for users to perceive an overall sharper composition. The distance between the observer and the building also plays a role. It is important to note that the resolution of the generated image impacts the complexity of the result. Overlaying additional Perlin noise with the input videos provides a more complex result. The limitation of the resolution and the computationally expensive generations will be overcome shortly with the introduction of more efficient algorithms and faster GPUs with more memory. Currently, for content requiring engagement and architectural fidelity, hybrid pipelines that blend real-time AI with procedural overlays remain a practical solution.
Discussion
AI as augmentation, not replacement
The integration of AI systems into architectural practice invites critical reflection on their role within established and emerging design methodologies. Vision machines and AI systems are not intended to replace traditional architectural practices such as hand drawing, physical ideation, collaborative fieldwork, and conventional design techniques. As emphasized by critical scholars in the fields of technological studies and critical AI, these systems must be approached with an awareness of their limitations and embedded values.33,34 AI models can produce “dump meaning” by abstracting content from its cultural and contextual origins, potentially reinforcing biases and problematic patterns. Any critical engagement with AI in architecture must acknowledge these concerns while exploring the technology’s productive potential. 35
This research positions AI as an extension of compositional practice, an augmentation layer that enhances rather than replaces the architect’s process. The immediacy and responsiveness of diffusion models enable designers to iterate and experiment dynamically, forming a bridge between analog and digital environments. This real-time adaptability encourages the development of continuous, fluid pipelines that operate across disciplines and media. In this context, AI functions as a “second creative brain” which, generates speculative iterations based on its training data. While the abstraction inherent in diffusion models distances outputs from meaning-making traditions rooted in cultural authorship, it also provides fertile ground for architectural speculation. Our approach proposes moving beyond superficial prompt-based design and toward deeper engagement with the architecture of AI models and their latent spaces. By participating in training and fine-tuning processes, designers reclaim agency, shaping not only the outputs but the generative potential of the tools themselves.
This evolution parallels a return to polymathic thinking in architecture. 36 Throughout history, influential architects often operated across disciplines, integrating science, philosophy, engineering, and art. While 20th-century specialization fragmented this approach, AI offers new tools for interdisciplinary synthesis. With accessible interfaces and open-source models, architects can now integrate knowledge from domains they may not formally be trained in, whether that be biology, meteorology, or linguistics. AI in this framework becomes an instrument for transdisciplinary creativity, enabling the convergence of data-driven analysis with speculative vision.
Bio-digital complexity
Commercial interests have played a central role in shaping the visual language of urban environments, often emphasizing consistency and brand visibility over adaptive or experimental design strategies. In contrast, Osmosis engages AI to cultivate bio-digital complexity—dynamic compositions that evolve in response to both contextual input and system indeterminacy. Rather than referencing natural forms directly, the project leverages stochastic design logic and layered generative processes to evoke organic richness without replicating nature. 37
This approach offers an opportunity to reintroduce complex, organic formal languages that characterized architectural expression before the modernist turn of the early 20th century. The intricate, nature-inspired forms of Art Nouveau, exemplified in works like Victor Horta’s Tassel House in Brussels, provide exemplary historical paradigms for computational complexity in contemporary design. When applied to building digital façades, as in the case of Osmosis, whether at the scale of individual structures or entire urban districts similar data driven approaches can generate emergent patterns and forms that integrate with traditional generative methods, all processed through AI models to produce diverse, responsive outcomes.
Looking ahead, the convergence of generative AI and fabrication technologies suggests a future in which biodigital compositions move seamlessly from screen to structure. The emergence of “text-to-mesh” models capable of translating language prompts into three-dimensional geometries opens new territory for direct materialization. These systems offer a speculative roadmap for transforming AI-generated visual logic into digitally fabricated architectural components, extending the XR aesthetic into the domain of built form. 38
Bio-digital futures
Future research in biodigital architecture will likely expand through multimodal sensing systems, including olfactory, haptic, and physiological data, to further personalize and localize generative design. The Osmosis framework points toward a distributed design ecosystem, where real-time communication across machines enables remote participation and intellectual property exchange through live computational media. Computation and data communication over the network is crucial, allowing artists to share their intellectual property and transmit data in real time. This system offers numerous potential for extension.
An emerging trajectory in this domain builds on the concept of “NeuroNanoBioTectonics,” which imagines adaptive architectures that fuse biological signals, nanotechnology, and machine learning. 39 Our most recent research project, “Organoid_Protonoesis 1”, demonstrates the potential for integrating real-time generative AI and DMs with biological systems. This project introduces a real-time interface that connects spontaneous brain organoid activity between UCSB’s transLAB and the Ken Kosik neurobiology lab with external stimuli, enabling unique interactions between human intellect and emerging self-organizing neural connectivity. The project introduces an interface that translates spontaneous neural activity from brain organoids into AI-driven XR compositions, using the same generative architecture -diffusion models, real-time synthesis, and spatial mapping strategies- initially established in Osmosis. This procedural integration demonstrates how the Osmosis pipeline can accommodate biological data streams as real-time compositional inputs.
Osmosis 2.0 is already being programmed for June 2025 and involves real time reading and translation of biodata. For the new implementation we are developing a framework based on the Source, a biophysical sensing acquisition system by bioMECI 40 to capture physiological measures from the performers, such as Electrocardiography (ECG) and Electroencephalography (EEG) data. The advantage of the Source is portability and accessibility, compared to purely research devices and software. By translating live biodata into AI-driven XR compositions, the system enables immersive experiences that are co-authored by human physiology and machine synthesis. 41 This direction positions AI not only as a tool for generative speculation but also as an interface for sensing and relational design. As these systems mature, architectural experiences may emerge that are choreographed in real-time by cognitive, emotional, and environmental feedback, producing built environments responsive to cognitive and emotional cues.
Footnotes
Acknowledgments
This work was co-authored by Iason Paterakis and Nefeli Manoudaki. The authors extend their sincere gratitude to the Santa Barbara Center for Art, Science & Technology (SBCAST), and to SBCAST director and external collaborator Alan Macy, for their generous support throughout this series of studies. Appreciation is also due to the transLAB and the Media Arts and Technology (MAT) program at UCSB, as well as to Professor Marcos Novak, director of the transLAB and chair of MAT. We also acknowledge the contributions of external collaborators: Stejara Iulia Dinulescu, for designing and integrating a haptic interface to control Osmosis during the Unite to Light event; and Ryan Millett, whose sound composition accompanied the first three Osmosis performances at the SBCAST. Osmosis is fundamentally built on AI diffusion models and large language models (LLMs). No generative AI tools were utilized in producing original research content, analysis, or interpretations. However, AI-assisted tools were employed for text editing, reference formatting, and organizational enhancements. The final manuscript was reviewed and approved by the authors to ensure accuracy and originality.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the fourth iteration of Osmosis received a grant from the David Bermant Foundation to support its presentation at the Unite to Light the Night Art Exhibition & Fundraiser, held in Santa Barbara, California, in October 2024.
Awards
Osmosis was awarded first place in the Visual Art category of UCSB’s AI + Human Creativity Contest, organized by the Mellichamp Initiative in Mind and Machine Intelligence.