
Abstract
Recent advancements in Machine Learning (ML) have significantly enhanced the capability to generate 3D objects from textual descriptions, offering significant potential for design and fabrication workflows. However, these models typically fail to meet practical requirements like printability or manufacturability. In addition, current approaches often cannot accurately control the dimensions and the interrelations of elements within the generated 3D models. This presents a major challenge in utilizing ML-generated designs in real-world applications. To address this gap, we introduce a novel method for translating natural language descriptions into parametric 3D objects using Large Language Models (LLMs). Our approach employs multiple agents, each agent is LLM pre-trained for a specific task. The first agent deconstructs textual prompts into design elements and describes their geometry and spatial relations. The second agent translates the description into code using the Rhino.Geometry coding library in the Rhino3D-Grasshopper modeling environment. A final agent reassembles the models and adds parametric control interfaces, enabling customizable outputs. In this paper, we describe the method’s architecture and the training methodologies, including in-context learning and fine-tuning. The results demonstrate that the suggested method successfully generates code for variations of familiar objects. However, it still struggles with more complex designs that deviate significantly from the training data. We outline future directions for improvement, including expanding the training dataset and exploring advanced LLM models. This work is a step towards making 3D modeling accessible to a broader audience, using everyday language to simplify design processes.
Introduction
The recent advent of text-to-image ML models has revolutionized the creation of 2D images, showcasing design abilities once thought to be uniquely human. However, the act of generating 3D shapes is more challenging than its 2D counterpart due to the lack of training data and the difficulty of representing the 3D information. 1 Current text to 3D methods rely on a process of translation from 2D images into 3D representations and often produce results lacking in geometric precision. More importantly, these generation methods do not allow their user numeric control over the physical parameters of the generated result. 2
Traditionally, this type of customization and control is achieved through parametric design, where shapes are defined by algorithmic processes rather than by direct 3D manipulation. Platforms like Grasshopper for Rhino3D use parameter-based algorithms to generate geometry, which enables the creation of a wide range of designs. Moreover, the slider-based user interface allows users to rapidly modify the design to fit their specific needs or requirements.
In this work, we present an alternative approach to the conventional text-to-3D methods, which is based on using Large Language Models (LLMs) to generate the code required to create parametric 3D models. LLMs have recently made significant progress in generating code from a natural language description. They excel at various simple coding tasks and can solve challenging Python programming problems created by humans. 3 Generating an entire program for a complicated task is more difficult, but recent work has suggested that this can be solved by dividing the task into several separate agents and establishing heuristic communication between them.
Hence, our approach utilizes multiple LLM agents that work together to generate the parametric models employing the Rhino Geometry 3D coding library. The resulting output is a Python program that operates within the Rhino-Grasshopper environment to materialize the specified object. Input sliders are automatically generated to give users control over various aspects of the model, such as geometry and the relationships between its elements. The proposed method was evaluated by designing and testing multiple training approaches, including fine-tuned models, few-shot in-context examples, and diverse object context groups to assess the impact of training methods on the generated outputs. The resulting designs were evaluated based on their object definition correctness, error-free code, geometric accuracy, and proper parametrization. This comparative analysis provided insights into the strengths and limitations of each training approach in handling varying levels of object complexity.
This work aims to simplify the 3D modeling creation process, making it more accessible while empowering users to control and customize the generated designs through parametric adjustments, thereby enhancing their practicality and usability.
Related work
Our work spans several fields related to ML: ML for 3D printing, text-to-3D methods, code generation using LLMs, and ML in parametric design. In this section, we review the state-of-the-art in those fields.
Machine learning for 3D printing
3D printers, once confined to industrial, university, or maker-space environments, are now becoming increasingly prevalent in domestic settings. The trend towards personal fabrication is set to grow in the coming years, with 3D printing playing a pivotal role. Thanks to advancements in technology and more accessible pricing, 3D printers are steadily gaining popularity among casual home users. 4 However, despite this increased adoption, numerous challenges remain, such as the complexity of design software and the need for technical expertise in 3D modeling. 5 To address these difficulties ML has been applied to various aspects of 3D printing, in an attempt to improve the whole design and manufacturing workflow. In this context, ML has been applied to composite design, process planning, design feature recommendation, optimized build orientation, manufacturability, and stress prediction. 6 All these methods contribute to simplifying the design and printing processes. However, there aren’t comprehensive methods that allow users to transform textual descriptions into parametric, printable 3D objects.
Text-to-3D
Text-to-image models can understand and bridge the gap between natural language and images. 7 The task of generating 3D shapes from text is more challenging due to problems related to data availability and representation format. The largest text-to-3D dataset proposed by Fu et al. 8 contained only 369K text-3D pairs and was limited to a few object categories. This is significantly lower than the datasets that contain 5.85 B text-image pairs. 9
There are several different representation formats for representing 3D shapes in the current text-to-3D research: Voxels: “volumetric pixels” represent 3D space as a grid of small cubic elements. CLIP-Sculptor 10 uses an unlabeled voxel dataset and a pre-trained image-text network such as Contrastive Language-Image Pretraining (CLIP). Point clouds represent 3D space by capturing individual points and can also include attributes like color or intensity for each point. Point-E 11 first generates a single synthetic view using a text-to-image diffusion model, then produces a 3D point cloud using a second diffusion model, which generates an image. A Mesh is a 3D object represented as lists of vertices and faces, where each face is constructed from several vertices. CLIP-Mesh 12 is a technique for generating a 3D model using a target text prompt. Neural radiance fields (NeRF) 13 are an implicit function method for synthesizing views of complex scenes by optimizing a continuous volumetric scene function using a sparse set of input views. Shap-E 14 uses a latent diffusion model over a space of 3D implicit functions that can be rendered as both NeRFs and textured meshes. Magic3D 15 uses text prompts to optimize a coarse neural field in two stages, refining mesh representations with diffusion priors at high resolutions. NeRFs are considered state-of-the-art and have the advantage of high-quality and realistic 3D model generation.
While these innovative methods have achieved impressive results, the resolution of the produced objects often falls short, especially for physical applications. The complexity of processing 3D objects stems from their extensive information content and the irregularity of the data. Our hypothesis is that we can conceptualize 3D objects as assemblages of interconnected basic shapes, subject to various manipulations. This conceptualization can make the representation of complex objects more feasible and effective for an LLM.
Additionally, current methods that do produce relatively high-quality models lack the capability for users to control specific parameters. This limitation reduces their practicality, especially for physical implementations. This challenge is not exclusive to text-to-3D methods but is also common in other generative AI fields, such as text-to-image models, where users struggle to produce outcomes that align precisely with their vision.16,17 To overcome these limitations, a parameter-based approach to object creation is necessary. This approach would allow for precise model control, leading to the generation of highly useful objects that can be customized to meet the specific requirements of users.
These insights prompted us to approach 3D object generation from a different perspective: viewing the object as the output of a textual description. In this method, an LLM decomposes the object into its constituent components. It then generates functions to create these parametrically controlled components and connects them to form the complete object. This process leverages the advanced capabilities of LLMs to interpret and translate textual descriptions into detailed 3D models.
Code generation using LLM
The task of generating code from a natural language description, or NL2Code, is considered a significant challenge in ML. The Generative Pre-Trained Transformer (GPT) is an AI-powered LLM capable of generating human-like text based on context and past conversations. Specialized versions of GPT, such as Codex, have demonstrated remarkable effectiveness in this area. 18 Codex operates based on 12 billion parameters and has demonstrated the ability to solve 72.31% of challenging Python programming problems crafted by humans. 3 A major drawback of NL2Code LLMs is that they can generate mostly simple task descriptions with short solutions. Generating a complex program starting from a long natural language task description has remained an open problem. Recent work has suggested that this can be solved by dividing complex tasks into several separate agents, each performing simple tasks and establishing heuristic communication between them. This collaborative approach was effectively employed in studies by Dong et al, 19 where multiple LLM agents, each trained on specific tasks, were used to generate code. Each agent was trained for a specific task, and by integrating the work of all agents together, the combined model successfully generated more complex programs. Inspired by these methodologies, we deployed similar agents to facilitate the generation of comprehensive Python programs capable of creating controllable 3D models with a high-quality finish.
Parametric design and LLMs
Parametric design is a method in which shapes are constructed using coded algorithms rather than by direct 3D manipulation. Parametric design offers significant advantages by enabling dynamic customization and flexibility; it allows for the easy modification and adaptation of designs to meet specific requirements, leading to a wide range of variations from a single model. A key player in this domain is Grasshopper, a visual programming environment for parametric modeling that runs within the Rhinoceros 3D computer-aided design (CAD) application. The usefulness of Parametric design in architecture and design has been repeatedly demonstrated, and Grasshopper has achieved widespread penetration into academia and industry. 20 However, acquiring parametric design skills often requires significant time and effort, even for design students. 21
With the advancements in LLMs, there has been a trend towards integrating them with Grasshopper to enhance their capabilities. Several methods that combine Grasshopper with GPT by OpenAI API were demonstrated.22,23 These methods integrate GPT as part of the Grasshopper workflow and are mainly used for manipulating images. More related to our work are projects such as GHPT, 24 a project which leverages GPT to create Grasshopper definitions. Using the GHPT Grasshopper component, users can send a prompt describing a Grasshopper program, and then the suitable components are automatically generated. However, this project is still in its early stages. To our knowledge, none of these methods currently harness GPT’s full potential for generating code that can directly translate user prompts into parametric design scripts.
Methods
In our research, we developed a method for creating 3D parametric models based on user prompts. The method comprises several key platforms. The Grasshopper platform is constructed on the foundation of the Hops plugin.
25
Hops is a Grasshopper library that enables the integration of external Python libraries within the Grasshopper environment. Through the Hops platform, we communicate with the API of the pre-trained GPT-LLM. We use the OpenAI GPT API
26
platform, which offers the option to fine-tune the base models on specific datasets, enabling more personalized and domain-specific applications. Our method pre-trains the GPT model using custom code examples. In the suggested workflow (Figure 1), the user inputs a text prompt describing an object into a Grasshopper interface. This prompt is then relayed to the Hops platform, which sends the prompt to a Python program that processes the prompt through the pre-trained LLM using OpenAI API. The LLM is comprised of several individual pre-trained agents. These agents collaboratively process the prompt and generate a complete Python script for an object using the Rhino.Geometry library. This script is then sent back through the Hops platform and into Grasshopper, which converts the code into a 3D model and displays it in the Rhino interface. Project architecture: Grasshopper, Hops, OpenAI API.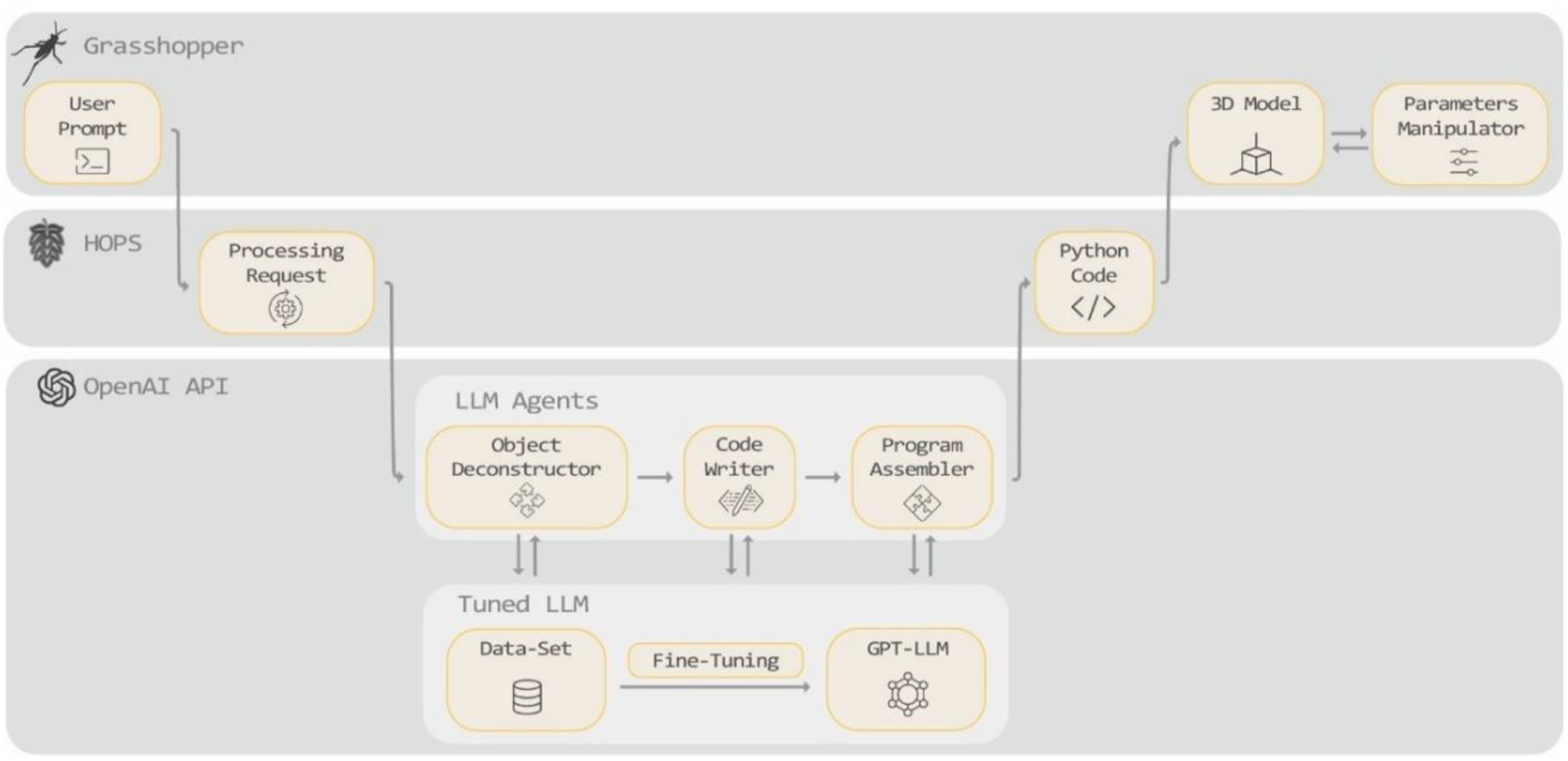
LLM agents
The suggested LLM architecture is composed of three individually pre-trained agents (Figure 2): the Object-Deconstructor agent breaks down the objects into simple components, the Code-Writer agent receives each component description as an input and builds a function to generate the component’s 3D geometry, and the Program-Assembler agent receives all the functions from the previous agents and constructs the full program for generating the object. The LLM agent’s flowchart - demonstrates the process of generating a kettle.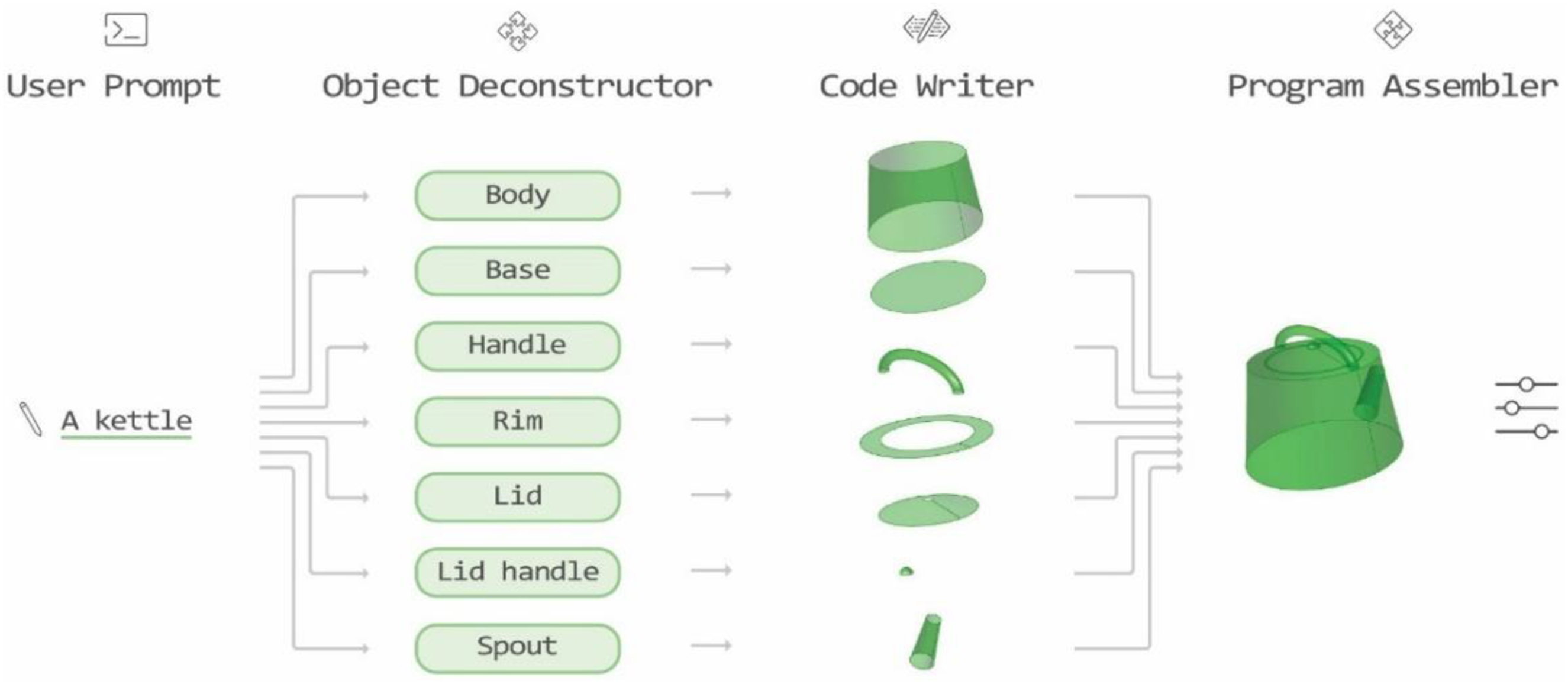
The Object-Deconstructor agent processes the user’s prompt, which entails describing an object and deconstructing it into its basic geometric shapes (Figure 3). This agent is trained to accept an input prompt describing an object, identify all its components, and then generate output text for each component. Object-Deconstructor agent Input-Output example.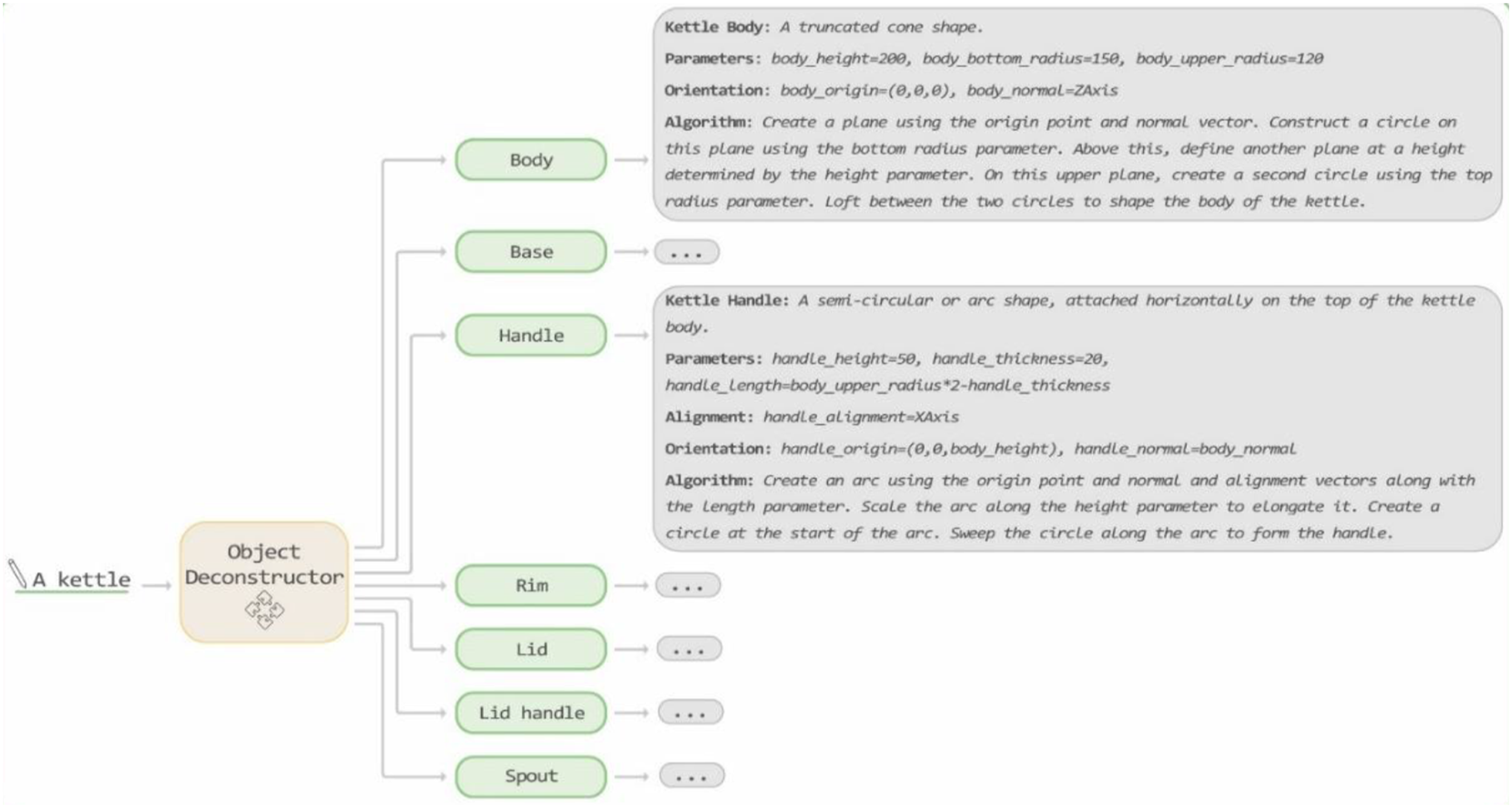
Initially, the Object-Deconstructor provides a description of the components as 3D geometric shapes. Then, it enumerates the parameters each part relies on, along with their initial values in millimeters. The orientation of each component is described next, involving a combination of two parameters: the origin point and the normal vector, which together define the plane on which the part is constructed. Additionally, the agent specifies the alignment of components that are not symmetrically built around their central vector. Finally, it describes a short basic algorithm for generating the component.
The Code-Writer agent is called iteratively for each object’s components generated by the Object-Deconstructor. It receives two inputs: the user-written prompt describing the full object and a text describing one of the object’s components. The agent creates a detailed Python script which sets all the parameters, orientation, and alignment according to the component description and creates a function to generate the component as described in the input text. This function accepts as inputs all the values provided by the Object-Deconstructor. It outputs a Boundary Representation (BREP) that represents the 3D shape (Figure 4). The modeling process is built upon the functionalities of the Rhino.Geometry Python library,
27
which offers a range of geometric types used in Rhino and functions for manipulating these geometries. Code-Writer agent Input-Output example.
The Program-Assembler agent takes all the functions implementing the object’s different components and compiles them into a comprehensive Python program that constructs the entire object (Figure 5). Initially, it aggregates all the import statements from the different component programs. Then, it creates the functions to generate each object component precisely as received from the Code-Writer agent. Following this, the Program Assembler consolidates all the parameters from the different components, dividing them into two categories. The first category includes external parameters, which are potentially relevant for user manipulation to alter the final shape, which is subsequently used by the Hops component to create sliders that can adjust the final appearance of the object. The second category comprises internal parameters not intended for user manipulation, such as parameters related to orientation and alignment. Finally, the program assembles an array containing all the BREPs of the different components and returns this array as the output of the Python script. Program-Assembler agent Input-Output example.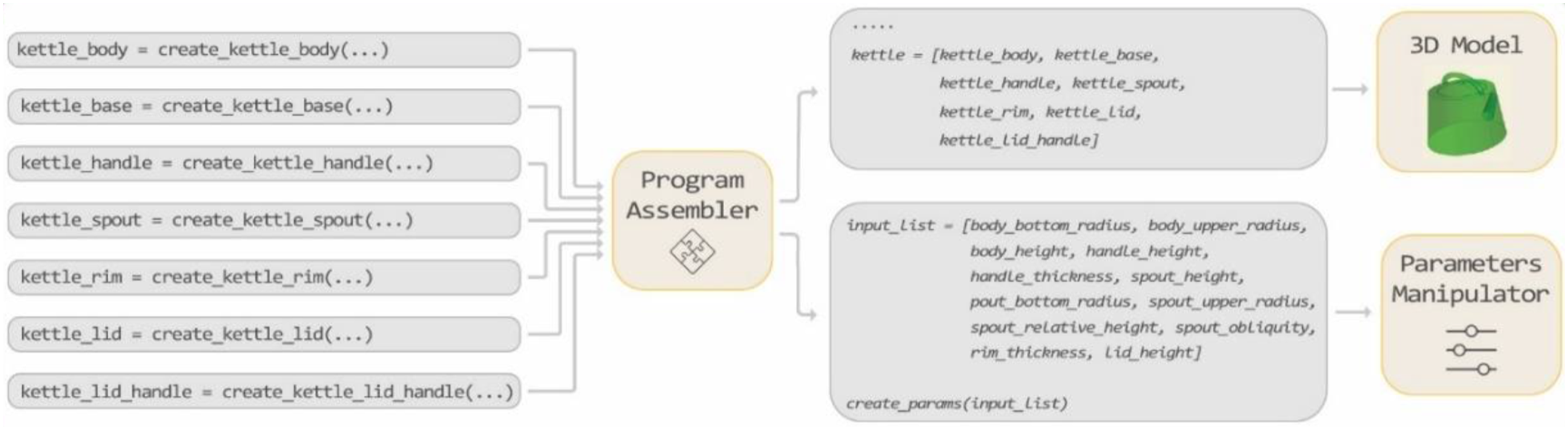
Model training
Our method is based on OpenAI’s GPT model, with agents leveraging both in-context learning and fine-tuning as core processes. For in-context learning, we used GPT-4o as the base model. For fine-tuning, we instantiated each agent multiple times, utilizing different model versions: GPT-3.5-turbo-0125, GPT-4o-2024-08-06, and GPT-4o-mini-2024-07-18. Each agent’s capability in our setup depends on the chosen training approach and is influenced by both the quality of the initial model and the precision of subsequent fine-tuning. GPT is recognized for its nuanced understanding, improved accuracy across diverse tasks, and sophisticated language generation and comprehension. 28
We employed two methods to improve the performance of the LLM agents: in-context learning with few-shot examples and fine-tuning. We first used in-context learning, where the agents were provided with a set of example inputs and outputs during the inference process to guide their performance. For this method, we designed two distinct groups of examples (Figure 6): one focused on household items (‘a bowl,’ ‘a mug,’ and ‘a cooking pot’) and another on furniture-architectural elements (‘a chair,’ ‘a door,’ and ‘a staircase’). These examples were dynamically selected and varied in each run to analyze their influence on the results. We discuss the differing results generated by each group in the Results section. In-context learning: 3D models from two groups of examples— furniture-architectural elements and household items.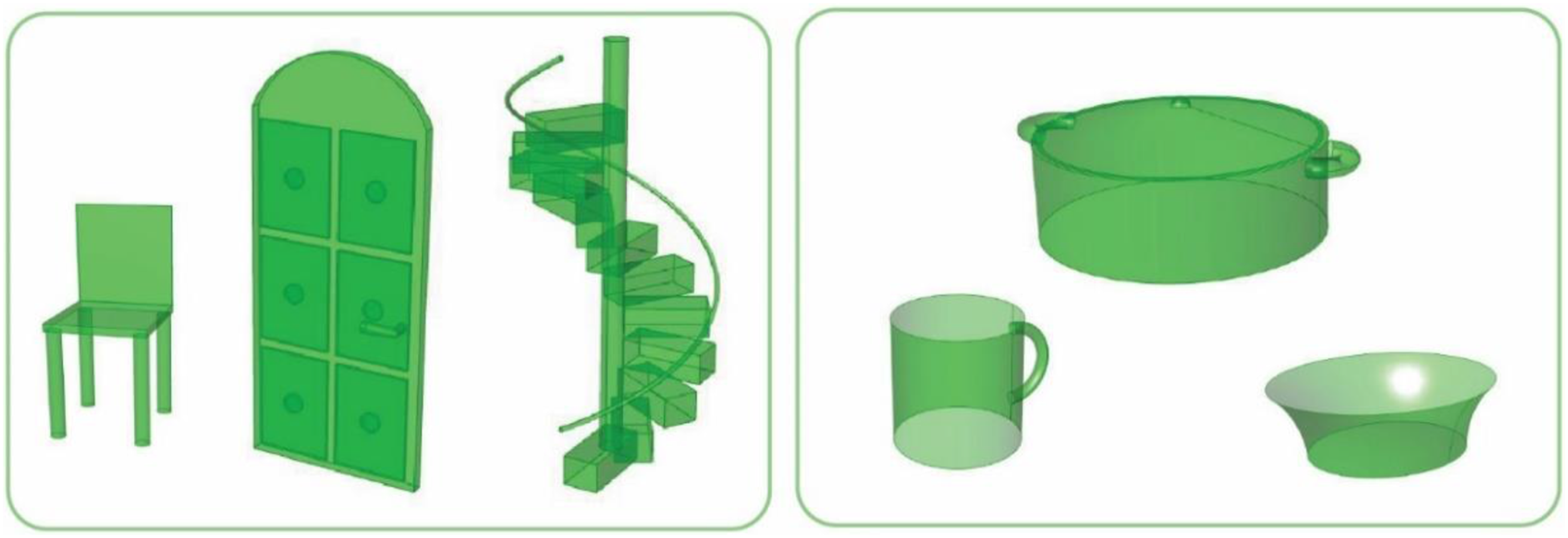
In addition to in-context learning, we used fine-tuning, which involved crafting a dataset of 23 prompt-response examples to train the agents. Each full object was decomposed into parts, resulting in a total of 62 training examples for the Code-Writer agent. The dataset focused on household items and included both simple objects, such as “a glass” and “a bowl,” and more complex designs composed of multiple primitives, such as “a cooking pot” and “a kettle.” Each example followed the structured input-output format detailed in Section LLM Agents, to ensure reliably parseable outputs that could be automatically processed. During dataset creation, initial outputs were manually refined to correct errors and enhance accuracy before being included in the training set. Figure 7 presents a visual overview of the full dataset used for fine-tuning. Finetuning training dataset: 3D models created by the code examples from the dataset.
Training parameters
All three agents are based on the OpenAI GPT model. Each agent is configured with unique parameters, particularly focusing on Temperature and Top-P. The Temperature parameter, adjustable from 0 to 2, affects output consistency, with lower values producing more consistent results and higher values encouraging creativity. The Top-P parameter, varying from 0 to 1, controls the balance between diversity and coherence in text generation by filtering potential next words into a subset that meets a cumulative probability threshold, thus introducing a level of controlled randomness. 29 We determined the best settings for each model through experimentation with different Temperature and Top-P values. For the Object-Deconstructor agent, we set the Temperature value to 1.7, allowing for creative interpretation of the shape description. However, to ensure consistency in defining parameters and orientation, we use a Top p value of 0.32. This combination fosters a balance between innovative shape conceptualization and structured parameter detailing. In the case of the Code-Writer agent, we employ a Temperature of 1.8. While a lower Temperature value, like 0, is typically preferred for code-writing tasks to guarantee accuracy, our project’s unique creativity and correctness requirement justifies a higher Temperature setting. To counterbalance this and enhance precision in code generation, we set the Top-P value at 0.05. For the Program-Assembler, the Temperature and Top p values are set at 0.5. This setting ensures high consistency in the program’s structure, which is crucial for the agent’s functionality. This configuration’s moderate level of creativity helps determine which parameters should be user accessible as external parameters, adding a subtle yet important layer of flexibility to the final program assembly.
Code output
The output of the codes in the example dataset is a Python code describing a BREP geometry. This code is then transmitted back to the Grasshopper environment, which realizes the geometry via the Hops components. In addition to geometry, the process automatically generates input sliders through an interface invoked by the Python scripts and executed by the Hops components. These sliders enable users to tailor the final object precisely. An illustrative example demonstrates a kettle produced by this method (Figure 8). The output parameters allow for extensive manipulation to achieve the desired design and functionality of the kettle. The final output of the sequence of agents shows that the physical parameters of the object can be modified using the grasshopper sliders.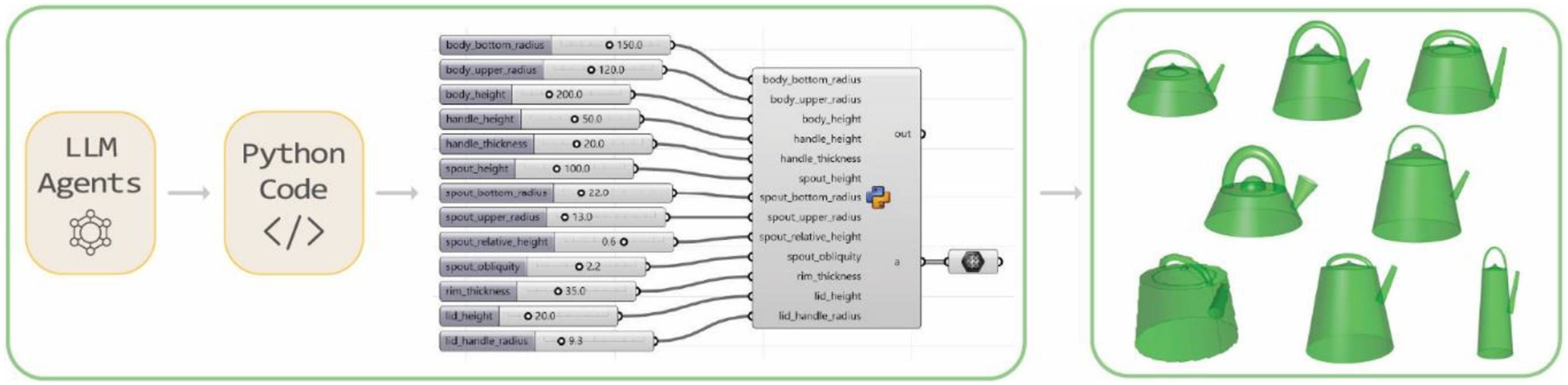
Results
We evaluated our method for generating 3D objects using two different training approaches, both implemented in the described multi-agent system: (1) GPT-4o using a few-shot, in-context example setting, and (2) fine-tuned GPT-4o and GPT-3.5. Each approach was assessed based on its ability to generate objects with varying levels of familiarity, structure, and complexity.
Result comparison with existing text-to-3D methods
To evaluate the performance of our system, we compared it against cutting edge state-of-the-art text-to-3D methods. We selected three different state-of-the-art methods, each employing a distinct approach and offering accessible infrastructure; Magic3D, 15 CLIP-Mesh 12 and Shap-E. 14 In comparison we use our system with finetuned GPT-4o model. A range of prompts were employed using all methods to generate 3D models. The prompts varied in complexity, beginning with a basic object like ’a kettle’ and progressing to more nuanced control of the object parameters and function, such as ‘a kettle with two handles,’ ‘a kettle without a lid,’ and ‘a kettle 200 cm high and 20 cm wide’. We conducted a visual assessment of the resulting 3D models, focusing on the correlation between the descriptive text in the prompt and the features of the resulting model, as well as the quality of the models. Subsequently, we 3D printed these models to test their practicality as tangible objects. This section presents a detailed review of the outcomes derived from these methods compared to our method.
Technical characteristics comparison of Magic3D, CLIP-Mesh, Shap-E and LLMto3D.

Functionality comparison of Magic3D, CLIP-Mesh, Shap-E and LLMto3D.


Printability comparison of Magic3D, CLIP-Mesh Shap-E and LLMto3D.


Comparing vanilla ChatGPT-4o, in-context Learning and finetuning
Comparison of GPT-4o model results: vanilla ChatGPT (amount of error iteration mentioned below each image), Fine-tuned with dozens of household items, In-context learning using three household items and In-context learning using three furniture-architectural elements.
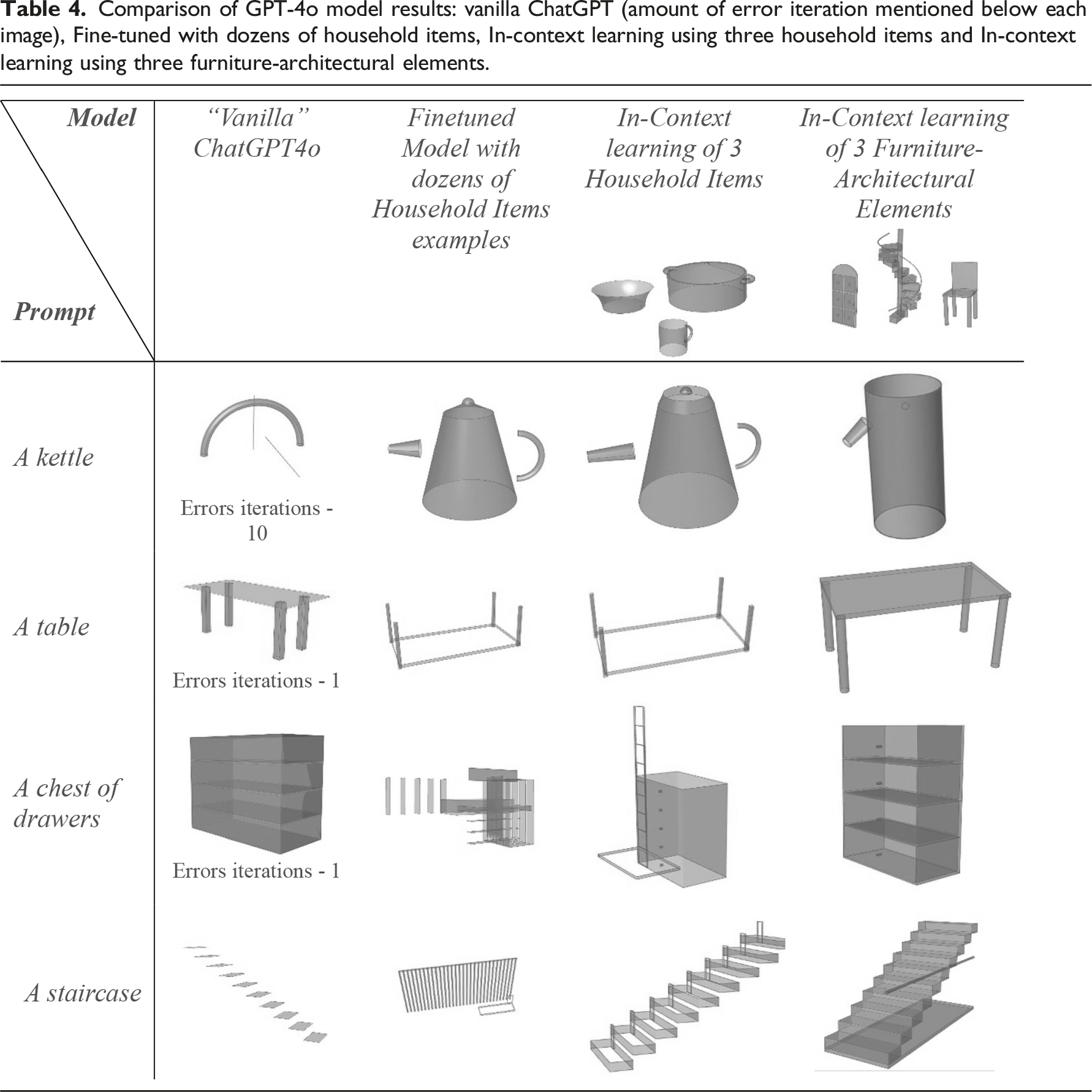
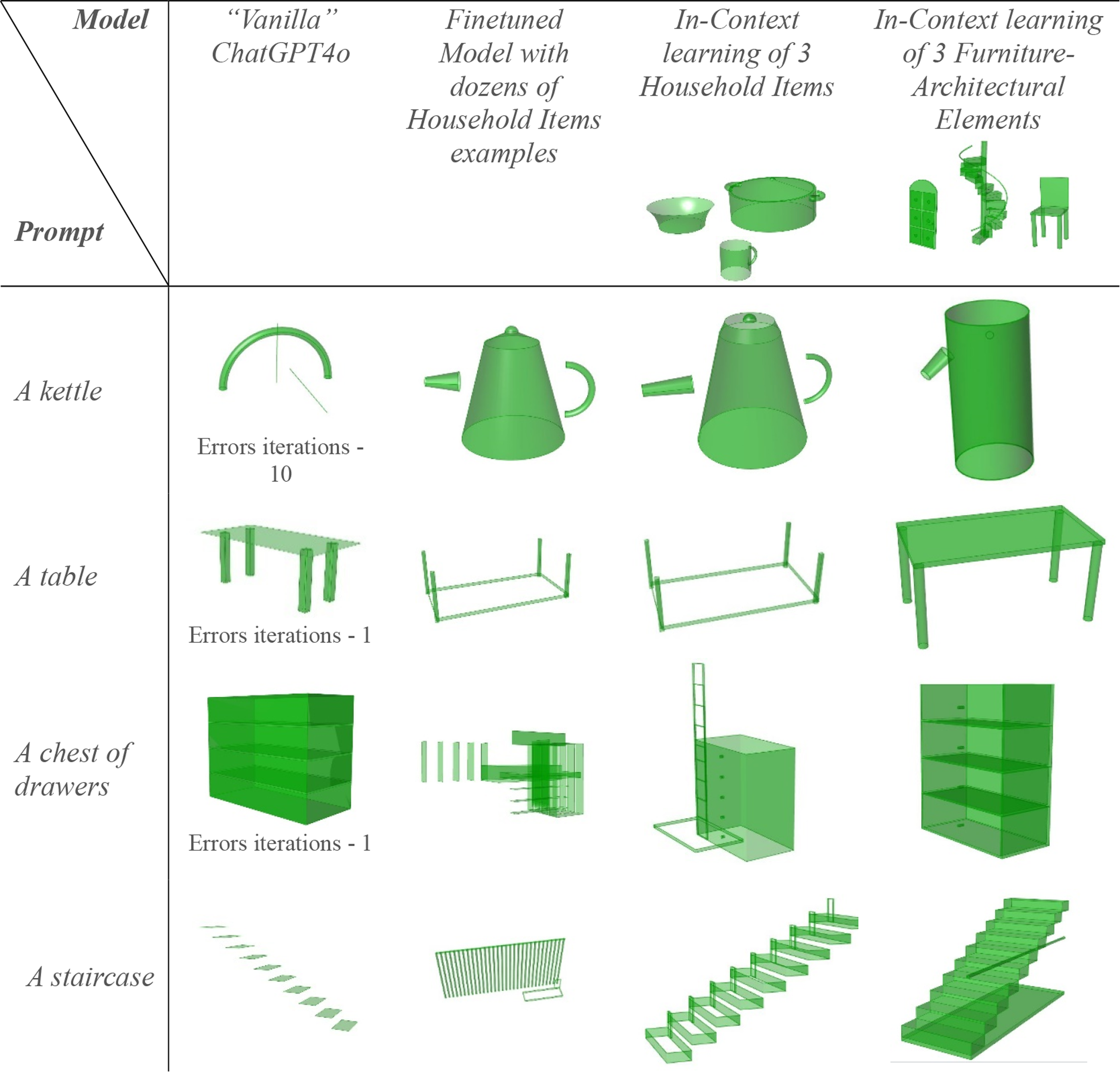
Our findings show a clear alignment between the provided examples and the quality of generated objects. The model trained on the Household Items group produced superior results for objects such as kettles, which shared structural similarities with the training examples. Conversely, the model trained on the Furniture-Architectural Elements group performed better when generating tables and a chest of drawers.
Surprisingly, the model trained using three household items as in-context examples outperformed the fine-tuned model. This was particularly evident for objects outside the training set (e.g., a chest of drawers). This suggests that the fine-tuned model may have been overfitted to the training examples, limiting its adaptability to unfamiliar contexts. Overall, our findings indicate that while fine-tuning enhances consistency for familiar objects, the variety of the dataset plays an important role in the success of the training. A smaller but more relevant dataset, provided to the model as in-context learning, provides greater flexibility for generating novel objects.
As illustrated in Figure 9, our method automatically generated sliders to control model parameters, a feature absent in the baseline ChatGPT-generated outputs. Additionally, the in-context example approach consistently produced higher-quality models, even for objects not explicitly included in the dataset. However, in the table example, which significantly diverged from the examples in the household items, the results were markedly inferior to the vanilla ChatGPT code. This highlighted the importance of providing a varied set of examples to the LLM. Results include generated sliders to control the generated 3D model.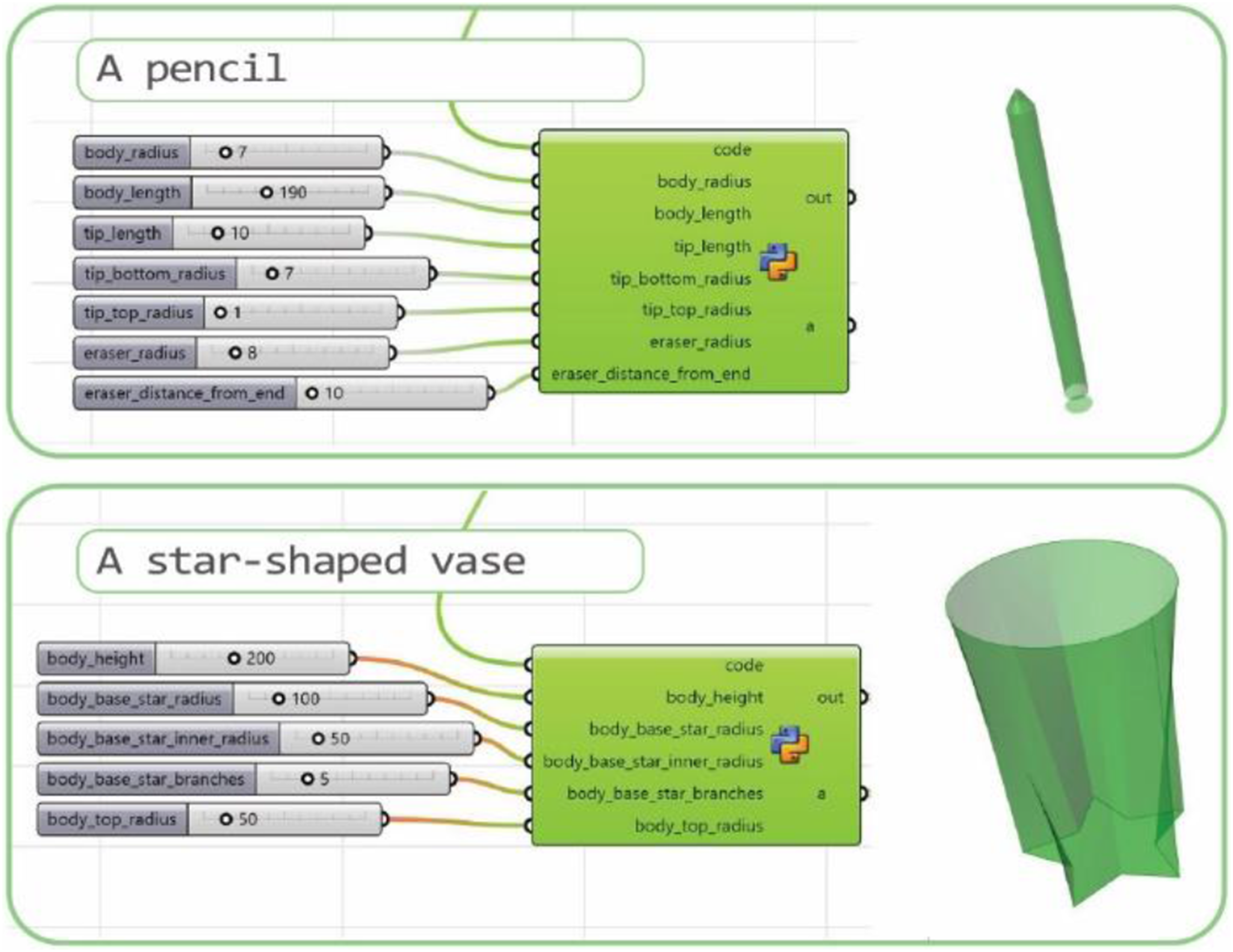
Finetuned model success rate
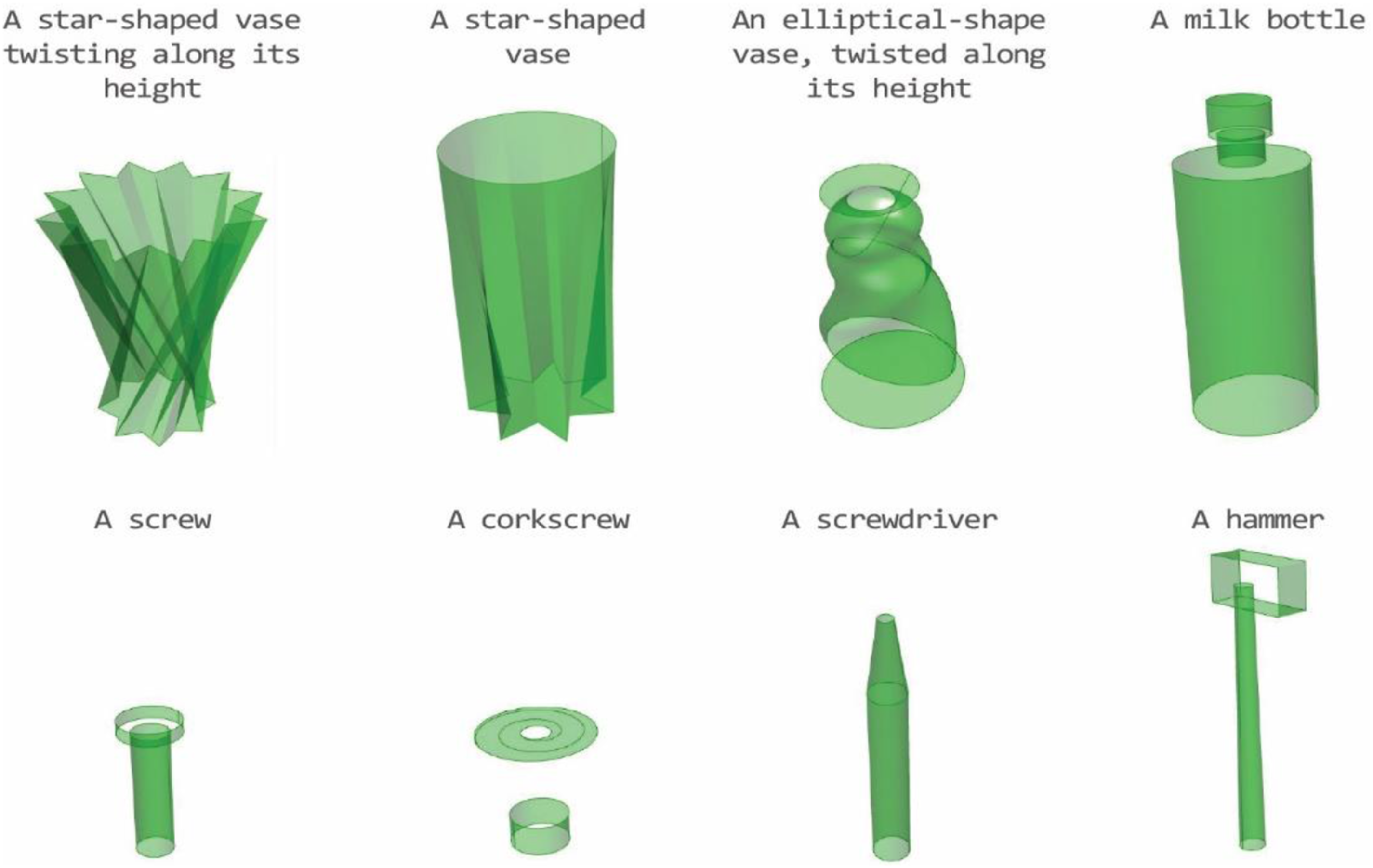
The fine-tuned model was tested on 40 examples with a similar level of difficulty to previously trained objects. This included prompts that were variations of ones the model had already encountered, as well as prompts for completely new objects. For both categories, we employed different levels of complexity, ranging from simple objects such as a ‘rounded bowl’ to more complex ones composed of multiple primitives such as ‘a cooking pot with two side handles.’ For some prompts, we ran the method multiple times and presented the best result. Figure 10 shows results for objects similar to those on which the model has already been trained. Figure 11 shows results for objects with highly diverging structures from the elements in the dataset. Results of running the method on objects similar to the ones the model was trained on. Results for complex objects whose structure was entirely new to the model.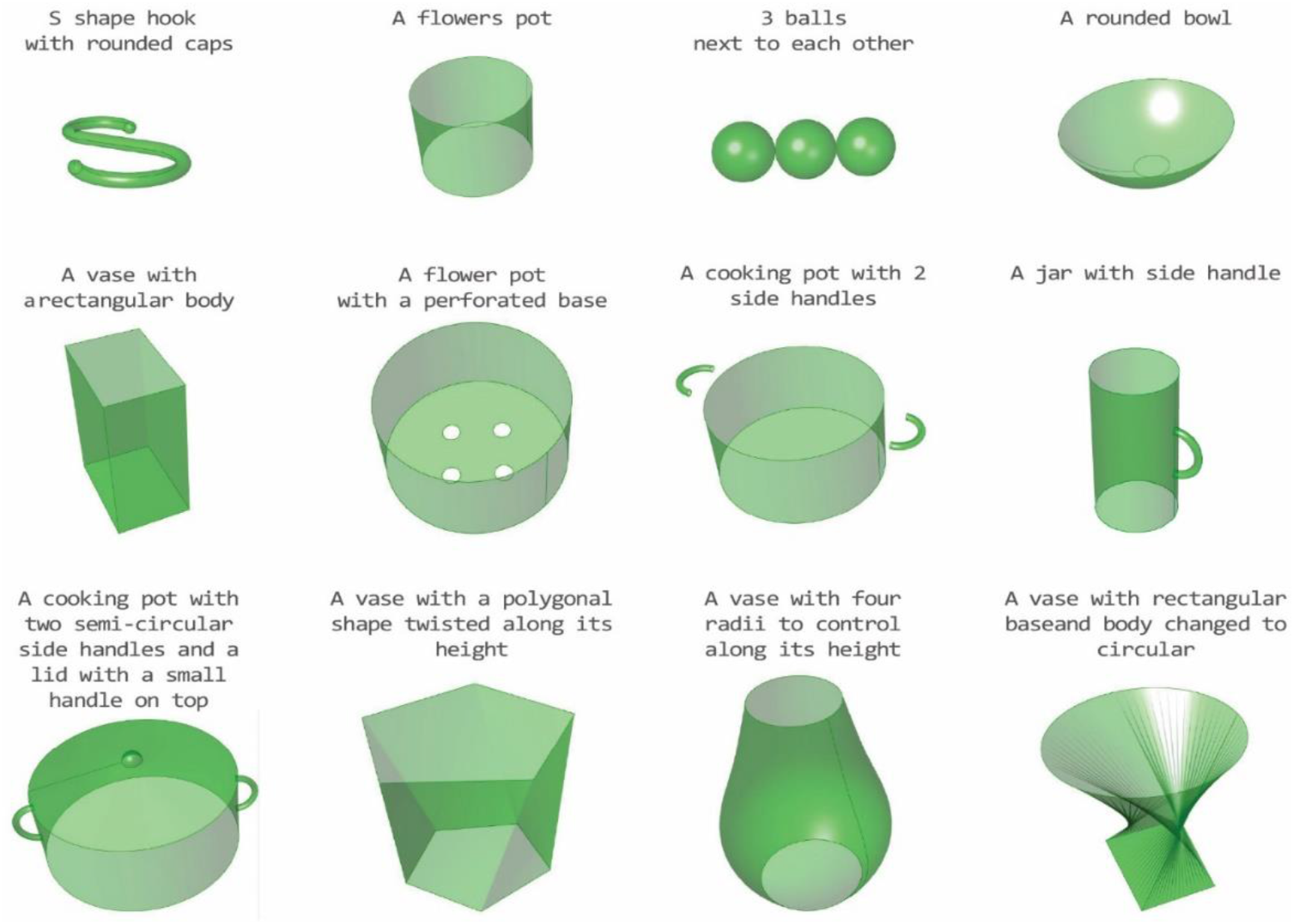
The success of the generation process depends on the performance of the individual agents. If the Object-Deconstructor accurately identifies the components of an object, isolates the variables each component depends on, and effectively defines the algorithm, there’s a higher likelihood that the Code-Writer will successfully generate the correct code. Similarly, the success of the Program-Assembler hinges on the Code-Writer’s ability to produce error-free code, define parameters accurately, and create a program structure that meets our expectations.
We determine the success rate of each agent differently. For the Object-Deconstructor, success hinges on accurately identifying the required components, defining the shape correctly for each component, creating all anticipated parameters, and correctly describing the generative algorithm. We measured the Code-Writer’s performance based on its ability to generate code without errors, adhere to the provided algorithm, and produce shapes that align with the given input. Finally, we measured the success of the Program-Assembler by its capability to produce error-free code and to allow access to all the parameters expected to be controllable by the user.
Since no automated validator currently exists for this multi-step process, all outputs were qualitatively reviewed and scored according to these consistent criteria. The goal was not to apply a binary pass/fail outcome, but rather to evaluate how effectively each agent fulfilled its role in the system. For each run, every agent received a score between 0 and 1, allowing us to capture both technical correctness and practical usability in a structured and repeatable way.
The fine-tuned model successfully generated objects that were similar to those it was trained on, such as simple vases, bowls, mugs, kettles, and cooking pots (Figure 10). Yet, it still encountered challenges with intricate, unfamiliar objects. We prompted the model to design objects outside of the training set, like boxes, chairs, snowmen, pencils, and corkscrews (Figure 11). The model generally succeeded with simpler objects, like pencils and boxes, but struggled with more complex shapes with unfamiliar alignment definitions between the primitives. For certain prompts, we ran the model multiple times because failures occurred at different stages within the agents, either preventing the generation of final results or producing only partial components. Figure 11 presents the best results for each prompt after these repeated attempts.
The average success rates across all model versions for partially familiar objects were as follows: the Object-Deconstructor achieved a 73% success rate, the Code-Writer 79%, and the Program-Assembler 95%. For completely new objects, the system showed greater variability. The Object- Deconstructor averaged 60% success rate. Often, the Deconstructor made errors in parameter estimations, such as omitting the leg height parameter when tasked with generating a chair. Additionally, the agent occasionally misaligned orientation parameters, like defining Z-axis alignment instead of the expected X-axis. The Code-Writer with average 66% success rate generally performed well with straightforward shapes, such as basic surfaces, lofts, sweeps, or twisted surfaces. However, it faced challenges with more complex and unfamiliar designs, like accurately modeling the head of a hammer or sweeping along unfamiliar rails. The Program-Assembler usually successfully compiled the complete program, including all necessary code and accurately defined external parameters. It achieved a success rate of 96%.
Analyzing model-specific performance (Figure 12), we found that Agent performance by model version and prompt.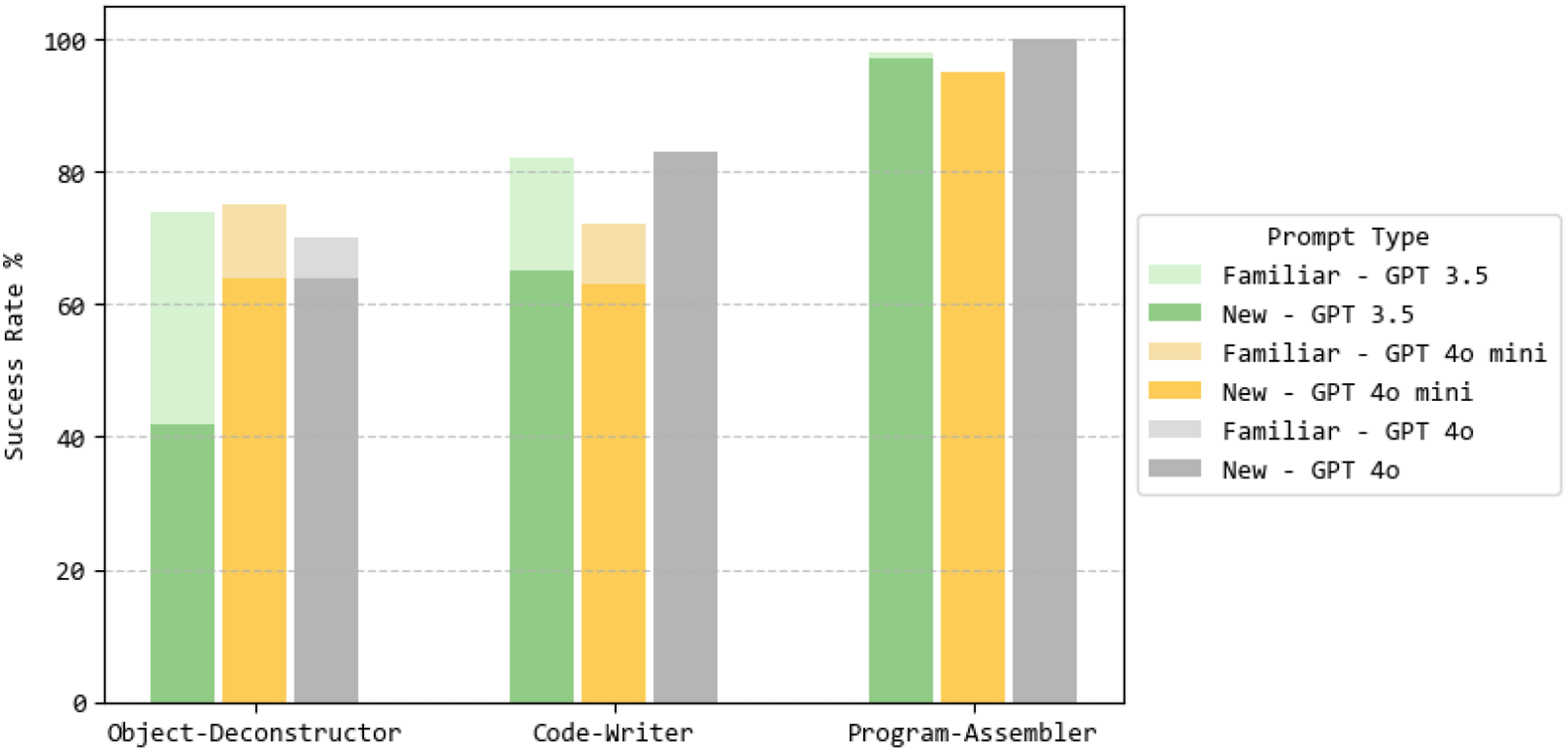
Discussion and future work
The results described in the previous section demonstrate the potential of our method to generate 3D parametric models using LLM. The suggested method produced simple shapes and illustrated the potential of the text-to-code approach for the field of text-to-3D. However, on complex shapes markedly different from the ones in the dataset, the method faced difficulties in deconstructing separate elements, providing parameter definition, defining element relations and orientation, and correctly defining the algorithm. Given the difficulty of understanding 3D geometric relations and the research’s initial stage, we believe these issues can still be improved. Possible reasons for the current limitations include dataset size and variety, the version of the LLM used, and the lack of a model to correct inaccuracies in the generated code.
The choice of GPT-4o as the base model was guided by practical constraints encountered during system development. The system was originally built using GPT-3.5 and subsequently transitioned to GPT-4o upon its release via the OpenAI API. At the time of integration, advanced features such as structured output and function calling were not yet incorporated into the pipeline. GPT-4o was selected because it produced reliably structured responses that aligned well with the required input-output format of the agents. In contrast, preliminary experiments with newer versions, such as GPT-4.1, resulted in outputs that were less predictable and often diverged from the expected format, limiting their immediate usability within the current framework. Future iterations of the system will aim to incorporate more robust integration mechanisms, including structured output and function calling, to support compatibility with more advanced language models.
The in-context learning approach revealed the adaptability of LLM models when guided by relevant examples, producing coherent outputs even without prior fine-tuning. Notably, the in-context learning method outperformed the fine-tuned model in some cases, particularly for unfamiliar prompts, as seen in Table 4 for cases such as ‘a staircase’. The fine-tuned model often struggled with prompts that significantly diverged from its training data, producing suboptimal or incomplete designs. This indicates potential overfitting to the training examples, limiting its ability to generalize to novel prompts. However, the fine-tuned model performed better when generating household items, the category it was explicitly trained on—producing more consistent and structurally accurate results. In contrast, the in-context learning approach demonstrated greater flexibility, with carefully crafted examples enabling the generation of more sophisticated and contextually accurate designs.
To enhance our method’s performance, future work will focus on areas with space for improvement: refining and expanding our dataset and exploring new LLMs as they are developed and released. To decrease the frequency of code errors resulting from the method, we’re planning to introduce a system for real-time validation, a Code-Error-Fixer agent. This agent will be developed to execute and debug code, utilizing log outputs to identify and correct errors before they are passed upstream.
One of the current limitations of the method lies in problems related to disassembling complex geometries into their different components and then reassembling them in place. As this task cannot be validated by reviewing the code, we suggest a visual analysis of the results be used to improve this aspect. Hence, we intend to use an adversarial network, an ML framework consisting of a generator, and a discriminator model with a Visual Language Model (VLM) as a discriminator in the training process, ensuring that the final 3D models are faithful to the initial prompts.
Finally, in the process of developing our dataset, we found that providing an image to ChatGPT as a description was often more straightforward than writing a prompt. This insight has led us to consider a new approach where users can submit an image, which our system would then process to generate an accurate 3D model.
Conclusions
Our research outlines the basis for an innovative approach to using LLMs to bridge the gap between natural language descriptions and creating parametric 3D models. The multiple LLM agents we described collaborate to interpret user prompts and translate them into functional Python scripts displayed in the Grasshopper environment. The results are geometrically cleaner and more precise than those generated by other known methods, leading to improved results in 3D printing. The controllable nature of the generated parametric code lends itself well to functionality issues and adaptation to user requirements. These results serve as proof of concept for the system’s ability to generate various simple objects. While there are currently limitations in reassembling multiple parts to handle complex designs, the trends in the training results suggest a potential for future improvement by expanding the training dataset and exploring more advanced LLMs.
This research indicates that using language-based ML models can make 3D design accessible to a wider audience. We envision a future where creative expression and engineering precision merge seamlessly, enabling anyone, from artists to engineers, to bring their unique ideas to life effortlessly.
Footnotes
Acknowledgments
The authors would like to thank Abraham Shkolnik, Michael Weizmann, Or Litani, and Yonatan Belinkov for their insightful comments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.