
Abstract
In recent years, advances in generative AI have enabled the direct generation of 3D models from sketches or images, offering new possibilities in architectural design. However, most current AI-driven modeling approaches still operate as “black boxes,” exhibiting issues such as opaque modeling processes, non-editable outputs, and a lack of semantic depth. In the field of architectural design, ideal tools should not only support structured component generation and spatial reasoning but also facilitate iterative workflows and collaborative creation. To address these challenges, inspired by the iterative design processes of human architects, we propose an agentic vision-action framework to assist architects in reasoning controllable and explainable 3D models from simple sketches. The framework involves the collaboration of multiple AI agents—including a Vision Agent, a 3D Reasoning Agent, a Reflection Agent, and a Data-Driven 3D Layout Agent—that collectively support sketch interpretation, spatial reasoning, and the generation of editable, structured 3D models. By integrating vision-language models (VLMs) with data-driven techniques, the system predicts detailed 3D spatial layouts and enables intuitive modifications through both visual and language inputs. Experimental results show that our approach surpasses existing methods in sketch interpretation, spatial reasoning, and structured 3D model generation. The outputs are not only editable and semantically rich but also composed of interpretable and traceable modeling steps, highlighting the potential of AI to assist architects in explainable and controllable design workflows. Instead of replicating human cognition, the framework is designed to augment it by enabling iterative feedback loops that interpret ambiguity, co-evolve design intent, and support co-constructive human–AI collaboration.
Keywords
• Propose a vision-agent framework that generates editable 3D models from sketches. • Develop a multi-agent system combining perception, reasoning, and action to assist architects in early-stage spatial design. • Enable an explainable and interactive generation process through natural language and sketch-based inputs.Highlights
Introduction
In the fields of architectural design and game development, the creation of 3D models has traditionally begun with sketches. Human architects rely on these initial drawings, combined with their extensive professional knowledge, to reason about spatial relationships and progressively develop complete 3D models with complex interior layouts. 1 Sketches and textual annotations have long served as intuitive means for expressing design concepts and have remained central to architectural conception and documentation for centuries. With the advancement of computer-aided design (CAD) tools, architects have been able to more efficiently translate their ideas into visualized outcomes, facilitating the transition from sketches to precise models. However, CAD fundamentally remains a tool for enhancing operational efficiency; it depends on explicit user commands and inputs, lacking autonomous understanding and reasoning capabilities. 2 In contrast, the rise of generative artificial intelligence (AI) technologies in recent years—particularly cross-modal models—has demonstrated more “active” capabilities: these systems can automatically generate complete 3D model shapes based on sketches or language prompts, seemingly participating in the design thinking process.
Nevertheless, most purely data-driven 3D generative models still operate in a black-box manner, lacking interpretable structural modeling logic, intermediate feedback mechanisms, and semantic control capabilities.3–5 In practice, such opacity and uncontrollability conflict with the openness, reasoning, and interactivity required during the early stages of architectural conceptual design. Designers often find it difficult to understand how AI generates these models and struggle to meaningfully modify or iterate upon them. AI systems still fall short of effectively collaborating with human architects in reasoning about and completing 3D designs. Addressing these challenges requires not only interpreting two-dimensional visual inputs but also developing a profound understanding and reasoning capability regarding spatial relationships.
To address these issues, we propose a vision-action-driven framework that integrates multiple AI agents responsible for visual understanding, modeling action execution, data-driven prediction, and reflective correction, aiming to achieve structured, editable, and semantically rich 3D architectural generation. Unlike previous static end-to-end approaches, our framework aligns with the iterative design workflows of human architects, enabling AI to actively operate modeling tools and execute spatial logic based on visual cues, thereby generating more controllable and explainable 3D outputs. The system also integrates data-driven methods to predict detailed spatial structures, generating complex hierarchical models with clear semantic organization and improving the overall architectural logic and usability of the generated designs.
Our goal is not to have AI simply mimic human architects’ design processes, but rather to build a collaborative modeling system characterized by reflection, generation transparency, and operational controllability. As scholars such as Bratton and Hayles have emphasized, human and machine reasoning are fundamentally different: human thinking is deeply rooted in intuition, embodied experience, and cultural context, whereas AI relies predominantly on data statistics and probabilistic inference. Therefore, we emphasize that AI should act as a collaborative agent embedded within the design process, supporting rather than replacing human judgment.
By emphasizing process transparency and controllable structure generation, our framework enables AI to actively execute modeling commands based on sketch inputs and supports interactive adjustments through both visual and language inputs. The integration of a Reflection Agent and data-driven reasoning mechanisms ensures that generated models possess clear spatial semantics and can be dynamically refined based on user feedback. Experimental results demonstrate that our method outperforms existing approaches in sketch understanding, spatial reasoning, and structured expression, exhibiting broad applicability and scalability.
The framework is primarily intended for use in the early stages of conceptual design, enabling intuitive transformation from sketches to three-dimensional spatial models. It serves not only architects and designers but also non-expert users, such as clients or stakeholders, supporting open-ended design exploration. The framework highlights the significant potential for shifting from CAD-based automation tools toward intelligent systems that assist humans in 3D reasoning and creative spatial design processes.
Related works
Our exploration of visual-based 3D generation techniques encompasses four key areas: visual input, spatial understanding and reasoning, agent frameworks, and data-driven prediction of 3D details.
Visual input for 3D modelling
The ability to interpret and reconstruct 3D models from visual inputs is fundamental to both biological systems and AI applications. Animals use their visual systems to comprehend and navigate the 3D world, 6 a capability that human architects emulate by observing and analyzing images to reason and construct 3D models. However, replicating this process in AI poses significant challenges, particularly when attempting to infer a complete 3D structure from single or limited visual inputs, akin to the expertise of professional architects.
Current end-to-end AI approaches mainly rely on visual inputs from multiple viewpoints to guide the generation of 3D implicit fields. These fields use sophisticated mathematical representations to describe object geometries in space. For example, Signed Distance Functions (SDFs) define object shapes by calculating the distance from each spatial point to the object’s surface, distinguishing between interior and exterior regions. 7 Neural Radiance Fields (NeRF) use neural networks to infer scene geometry, lighting, and other properties from multi-view 2D images, achieving high-quality 3D reconstructions. 8 Gaussian-based methods model objects using Gaussian distributions to capture fuzzy boundaries and volumetric properties, enabling precise scene detail representation. 9
Advanced techniques like Rodin and VAST use multi-view visual inputs and deep learning to optimize 3D field parameters, thereby enhancing the accuracy of geometric shapes and illumination properties.10,11 OpenLRM uses scalable transformer frameworks trained on extensive datasets to predict high-quality 3D object reconstructions from single images rapidly. 12 Get3D introduces generative models that produce high-quality, textured 3D meshes with complex topology and geometric details, improving diversity and handling arbitrary mesh topologies. 13 Visual-driven methodologies employ various techniques, including rendering and isosurface extraction, to translate 2D visual information into comprehensive 3D representations while maintaining geometric and photometric fidelity.14–17
Despite these advancements, a fundamental limitation persists in the architectural domain: these methods typically produce 3D shells resembling 2D images without fully accounting for the complex processes and intricate details involved in human architectural design. While they excel at generating artistic resources, they fail to emulate the reasoning steps inherent in the design processes of human architects. Unlike human architects, who engage in visual comprehension, execute modeling actions sequentially, predict details based on experience, and iteratively refine 3D spatial models through reflection and adjustment, AI systems do not perform these tasks. Therefore, enhancing machine visual understanding and spatial reasoning is crucial for advancing AI-driven 3D model generation in architecture.
Spatial understanding and reasoning
The iterative and reflective nature of architectural design has been explored through Schön’s concept of the “Reflective Practitioner”, 18 which emphasizes how designers continually assess and refine their work through cycles of reasoning and reflection. This reflective practice is central to understanding spatial relationships and informs the iterative processes required for effective architectural design. Both large language models (LLMs) and visual language models (VLMs) have shown the capability in processing natural language and visual inputs. These models can interpret image information similarly to humans and provide structured summaries of that information. Spatial relationships are fundamental to human cognition, but their expression in natural language can vary significantly. Although VLMs have made progress in understanding spatial relationships, they still struggle with capturing complex spatial arrangements involving object orientation, leading to performance gaps compared to human capabilities.
Visual chain-of-thought prompting has been proposed to enhance knowledge-based visual reasoning by enabling iterative interactions between visual content and natural language. 19 This method consists of three stages: see, think, and confirm, which enhance the reasoning process and improve performance on open-world questions. Additionally, visual spatial reasoning datasets, containing thousands of text-image pairs with diverse spatial relations, highlight the challenges current VLMs encounter in accurately capturing relational information. 20 The idea of “digital cousins” offers a promising method for enhancing 3D training environments. It provides cost-effective virtual assets that retain similar geometric and semantic features. This method improves robustness in sim-to-real domain transfer for robot policy training, making it a valuable reference for creating 3D environments. 21
These studies reveal a significant cognitive-performance gap between human architects and AI systems in interpreting and reasoning about complex spatial relationships. Existing methods primarily rely on retrieving pre-modeled 3D elements from libraries, leading to rigid and non-editable assets. In contrast, human professionals systematically model digital buildings using sequential modeling commands in specialized software. To bridge this gap, both an agentic action library and a multi-agent framework are necessary. The agentic action library requires a repository containing hierarchical instructions for volumetric configurations, elements, and detailing features, which will support AI-driven modeling operations. Additionally, the multi-agent framework must combine advanced visual comprehension with procedural modeling capabilities. This framework should go beyond conventional pattern recognition to achieve improved design-generation intelligence. By adopting this integrated approach, we can transform AI’s role from a passive visual interpreter into an active spatial composer in architectural design.
Agent based frameworks
AI agents function as active entities capable of solving diverse simulation problems based on specific needs.22,23 This is reflected in Bratton’s concept of “The Stack”, 24 which illustrates how computational systems, including AI, serve as layered frameworks that transform interactions between humans and non-human agents. Existing language agents can control shape generation, such as Building Agent. 25 However, effectively coupling visual information with 3D understanding and reasoning generation remains a significant challenge. To address this, several innovative AI agent frameworks have been developed. Positioned as a comprehensive and visionary embodied agent within the Minecraft virtual environment, STEVE integrates vision perception, language instruction, and code actions. This integration enhances performance in tasks like continuous block searches and knowledge-based question answering, achieving significant speed improvements in unlocking key technological advancements and completing block search tasks. 26 GALA3D focuses on effective compositional text-to-3D generation. 27 By using layout-guided control and large language models, GALA3D produces realistic 3D scenes with consistent geometry, accurate interactions among multiple objects, and enhanced controllable editing capabilities. VARP addresses the limitations of traditional methods in action-oriented tasks within action role-playing games. 28 Leveraging VLMs for enhanced visual understanding and interaction using only visual inputs, VARP demonstrates significant success in complex combat scenarios.
Cognitive-related agents have been introduced to navigate virtual environments using a predictive coding framework. This agent constructs an internal representation of the environment that quantitatively reflects spatial distances based solely on visual inputs. DreamControl employs a visual agent framework to optimize coarse NeRF scenes and generates fine-grained objects to ensure consistency in geometry and texture fidelity. 29 The General Computer Control setting, along with the Cradle agent framework, aims to enable foundation agents to master any computer task through multimodal inputs and produce keyboard and mouse operations as outputs, addressing challenges in generalization and self-improvement within complex environments. 30 For generating geometries for conceptual design in the third dimension, a prototype is proposed that integrates a diffusion network to create 3D datasets using parametric design, addressing the current lack of available architectural 3D data suitable for training neural networks. 31
Despite 3D modeling tools offering APIs, there lacks an agent-based command library to model editable results for architectural applications. These existing AI agent frameworks inspire our visual framework, but they fall short in modifying spatial details based on experience illustrated in sketches. Thus, a data-driven mechanism is essential to extend agent capabilities, enabling experience-based spatial modifications.
Data-driven prediction of 3D details
Human architects, through extensive training, can derive complete 3D models and internal layouts from simple visual cues. Shape grammar forms the historical foundation of computational design methodologies and establish a formal, rule-based approach to architectural design. 32 This has paved the way for algorithmic and procedural techniques used to generate complex structures. Recently, data-driven approaches in 3D modeling like GAN, have gained significance by enhancing design innovation through advanced statistical geometry processing. 33 These methods allow for the integration of suggestion generation into traditional geometric modeling tools, helping architects during the conceptual design phase. As data-driven approaches become increasingly vital in 3D generation, they are transforming how 3D models are created and manipulated. 34 They tackle challenges in 3D content creation by providing significant benefits, such as reducing the time and effort required for both experts and beginners, supporting creativity, and optimizing designs for 3D printing.
To provide a comprehensive overview of data-driven techniques for architectural design generation, several innovative frameworks based on graph representations are presented. Building-GNN integrates Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs) to facilitate controllable 3D voxel building model generation, which enables architects and AI to collaboratively explore spatial planning, allowing for dynamic and interactive design processes. 35 As a generative agent framework, Building-Agent combines the decision-making capabilities of LLMs with GNNs to autonomously process design tasks. 36 It iteratively refines 3D layouts based on natural language instructions, enhancing the collaborative potential between human architects and AI. BuildingVGAE employs Variational Graph Autoencoders (VGAEs), a neural network architecture, to encode Building Information Modeling (BIM) data into graph-structured representations. 37 It enables low-cost, self-supervised learning of complex architectural relationships, thereby enhancing the generation of detailed and controllable 3D models.
Despite these advancements, a significant research gap exists in generating comprehensive 3D building models that seamlessly integrate both exterior appearances and interior layouts. Current studies primarily focus on either external geometries or isolated internal structures, lacking a unified approach that encapsulates the full architectural complexity. Future research will explore the application of these emerging representation methods in architectural generation, aiming to bridge this gap and further promote AI’s capabilities in the field of architectural design.
Methodology
The transformation from conceptual sketches to comprehensive 3D models in architectural design presents a complex and multifaceted challenge. Like how human architects progressively refine building designs from initial drafts, our objective is to develop a methodology capable of generating complete architectural 3D models from visual inputs. These models must not only faithfully represent the conceptual shape of the sketch but also rationalize interior layouts. However, achieving this goal involves addressing several technical challenges.
Challenges in sketch interpretation
The primary challenge lies in the inherent ambiguity of human sketches. Architectural sketches are often highly abstract, lacking explicit details; they may outline only the building’s silhouette without specifying internal layouts or detailed features. This ambiguity complicates the extraction of precise spatial and stylistic information. Additionally, the limitations of VLMs in interpreting sketches must be acknowledged. Existing VLMs are typically trained on structured datasets, while architectural sketches are unstructured and often ambiguous. Thus, effectively interpreting these sketches and extracting meaningful design information remains a significant challenge.
Moreover, sketches typically express only the exterior of buildings, resulting in unclear interior layouts. Therefore, the system must not only interpret the external shapes but also create logical internal spatial layouts from limited information. To convert sketches into functional building models, establishing the interior layout is crucial, as it requires transforming vague sketch data into complete, hierarchical building representations.
Architectural design inherently demands the consideration of external shape and internal layout. The design must balance architectural aesthetics with structural rationality while ensuring functional interior spaces and spatial organization. Consequently, the system must simultaneously generate both external shapes and internal layouts, maintaining consistency and coherence in design intent.
Finally, compositional modeling and iterative editing are key characteristics of the architectural design process. Architecture is inherently iterative, requiring frequent adjustments to various building components. However, many automated modeling systems generate 3D models as singular, indivisible entities, making it difficult to edit specific components without affecting the entire structure. This limitation is particularly pronounced in architectural design, where architects continuously experiment with different massing, facade, and interior layout configurations.
While human reasoning in architectural design is intuitive and experiential, AI reasoning is data-driven and procedural. Our framework does not aim to replicate human reasoning entirely but emulates specific processes, such as resolving sketch ambiguity and iteratively refining designs. This approach complements human creativity by automating repetitive tasks and enabling architects to focus on higher-level design decisions. By replicating human reasoning, our framework enhances sketch interpretation, enabling accurate and contextually relevant 3D model generation. This capability supports iterative design processes and improves communication between architects and non-experts, bridging gaps in understanding design intentions. Ultimately, integrating machine reasoning with human-like capabilities improves the usability and flexibility of AI-driven design tools.
Agent-based framework
To effectively address these challenges, we propose an innovative agent-based architecture aimed at automating the generation of complete 3D architectural models, encompassing both exterior and interior elements from sketch inputs. The architecture comprises four core agents: the Vision Agent, 3D Reasoning Agent, Data-Driven 3D Agent, and Reflection Agent (Figure 1 and Table 1). The framework of our proposed approach: Comprising vision agent, 3D reasoning agent, data-driven 3D agent, and reflection agent. LLM-based text adjustment is optional. System prompt for vision, reasoning, and reflection agents.

The Vision Agent serves as the entry point, interpreting hand-drawn sketches provided as input images (e.g., PNG files). Using VLMs, specifically GPT-4o, the Vision Agent extracts essential design features and converts them into a structured JSON format. This JSON data encapsulates hierarchical information, such as building volumes, spatial relationships, and stylistic attributes, which is then passed to the 3D Reasoning Agent.
The 3D Reasoning Agent utilizes the structured JSON data to execute modeling actions within a virtual environment (e.g., Unreal Engine). These actions are implemented using an action function library written in C++, which interfaces with Unreal Engine’s APIs to perform operations like volume adjustments, element modifications, and architectural detailing. The output of the 3D Reasoning Agent is a set of 3D models in Unreal Engine format, which serve as constraints for subsequent processes.
The Reflection Agent evaluates the integrity and coherence of the generated 3D models by comparing their spatial and stylistic attributes against the target specifications encoded in the JSON data. This comparison guides iterative improvements by identifying discrepancies at the building, volume, and element levels. The Reflection Agent then provides feedback to the 3D Reasoning Agent, enabling dynamic refinement of the models.
Finally, the Data-Driven 3D Agent leverages the refined 3D data from Unreal Engine as constraints to generate detailed interior layouts. Using pre-trained models, this agent predicts functional zones, walls, doors, and windows, ensuring that the interior layouts align with the exterior geometry and maintain architectural coherence.
Figure 2 illustrates the interactive user interface of the proposed framework designed for a vision-agent modeling method. It features various components operated by multiple agents, including sketch and text inputs, VLM-parsed results, AI reasoning steps, and user dialogs, which facilitate smooth interaction between the user and the AI. This interface enables users to submit sketches and receive AI responses, allowing for the automated execution of building modeling. Interactive user interface for our framework: Multimodal inputs and reasoning process.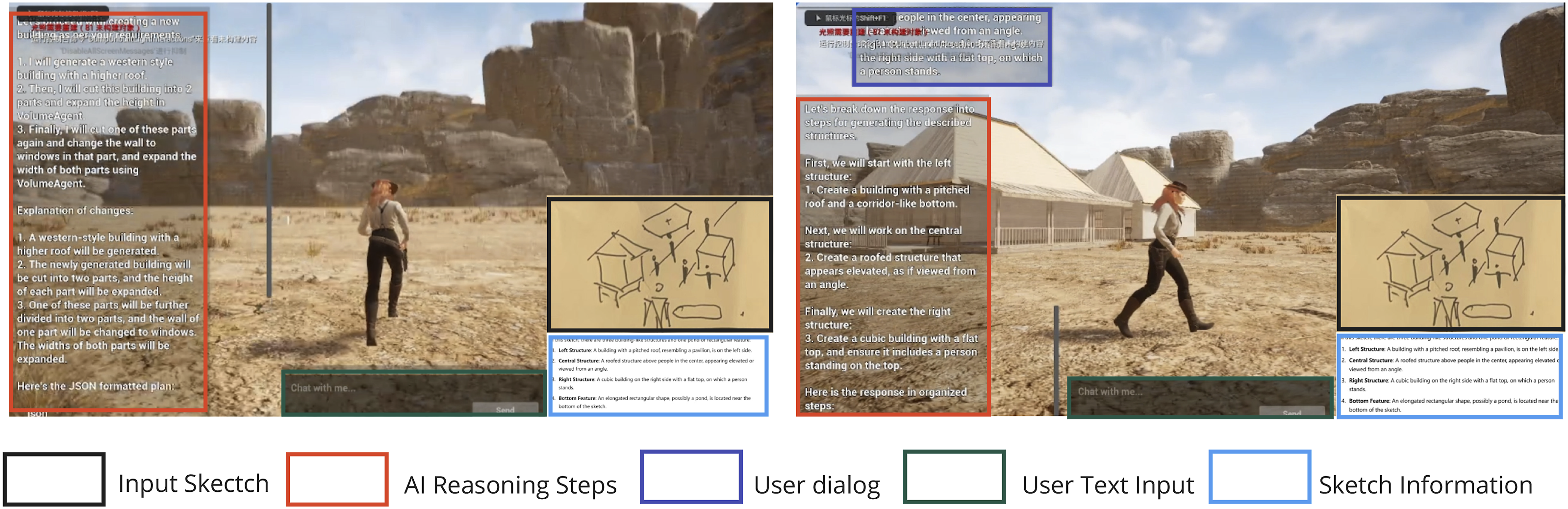
Vision agent: parsing hand-drawn sketches
The Vision Agent is designed to bridge the gap between abstract architectural sketches and structured data of corresponding 3D models. Using the capabilities of VLMs, specifically GPT-4o as a visual encoder, this agent is tasked with parsing hand-drawn architectural sketches and extracting essential data for subsequent 3D shape modeling (Figure 3). The process is systematically organized into two distinct stages: feature extraction and data storage. The vision agent processing: Parsing features from sketches and producing structured data.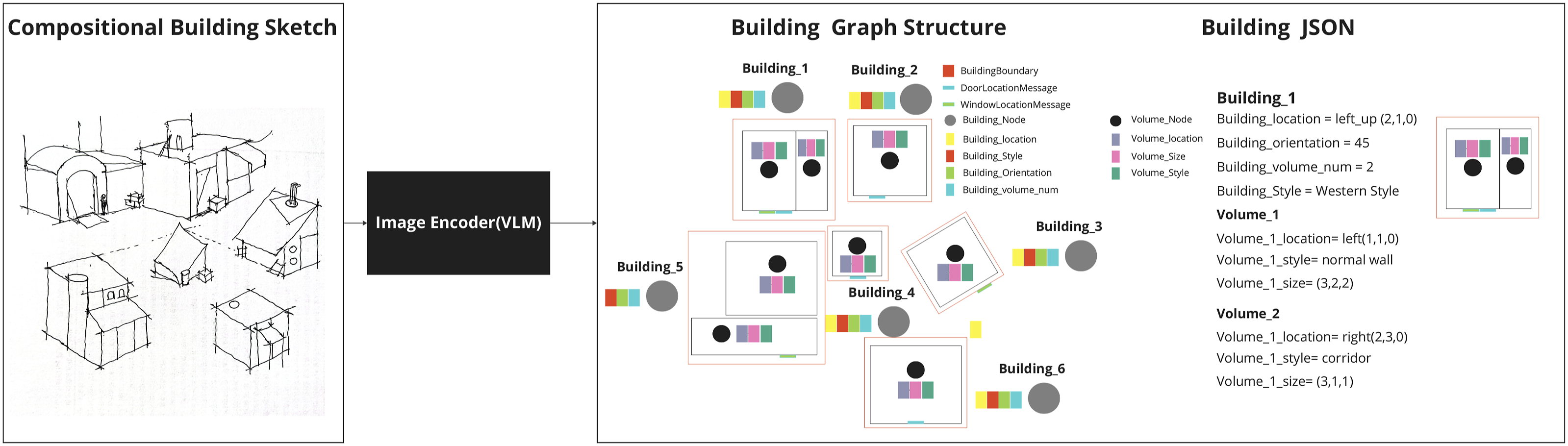
Feature extraction constitutes the initial stage. The Vision Agent analyzes the hand-drawn sketch to identify and interpret key design elements. Carefully crafted prompts are employed to elicit specific details related to the building design, addressing challenges such as ambiguous layouts and the inherent limitations of VLM parsing. The details extracted include the number of buildings depicted, the overall architectural style, the orientation of the structures, and for each building, the count of volumetric elements, their relative positions, dimensions, and stylistic attributes. Rather than presenting this information as a flat list, the Vision Agent structures it into a graph representation. In this graph, nodes represent individual architectural entities, which may be entire buildings or specific volumes within a building. The features associated with each node encapsulate characteristics such as location, style, and size, while edges define the relationships between these entities, such as adjacency or connectivity. To achieve accurate spatial information, the Vision Agent employs carefully designed prompts that guide the VLM to perform building segmentation to isolate footprints, assign grid - based coordinates via centroid points, and implement collision prevention during training to avoid overlaps, thereby ensuring coherent layouts. This approach effectively transforms vague sketches into quantifiable, structured data, balancing visual interpretation with architectural constraints.
Following feature extraction, the graph-based data is processed and transformed into a structured text format. This conversion serves a dual purpose: it generates a machine-readable format suitable for downstream processes, such as task planning and action parsing required by 3D modeling software, and it provides a human-readable format that allows for precise data adjustments through LLM-based text input, facilitating an optional text-based intervention mechanism. While LLMs can produce diverse structured outputs such as HTML, Markdown, and LaTeX, we have selected JSON (JavaScript Object Notation) for data storage due to its standardized and lightweight nature. JSON is inherently machine-readable and structured, easily parsed by most programming languages, ensuring interoperability with various software systems. Its hierarchical structure accommodates the nested arrangement of architectural designs, efficiently representing buildings, volumes, and elements in a clear and organized manner. This structured format facilitates seamless integration with software actions, allowing direct consumption of JSON data by modeling tools to automate object creation and parameter adjustments. Furthermore, JSON’s structured nature enhances LLM-based text modifications, providing a consistent input format that enables LLMs to understand architectural context and generate accurate text-based modifications or additions. The consistent JSON schema ensures data uniformity, reducing ambiguity and improving the quality of text generation (Figure 4). A simple example of a sketch input (left), VLMs parsing process (middle), and the transformation into JSON format (right).
3D reasoning agent: Modeling shapes
The 3D Reasoning Agent autonomously performs modeling actions for architectural for generating and refining architectural forms. It converts JSON data from the Vision Agent into executable modeling operations, addressing AI actions for building modifications, volume adjustments, and element changes through an action agent library. To implement this functionality, a virtual modeling environment in Unreal Engine integrates agent logic with the engine’s capabilities. Sub-agent actions act as modular interfaces that invoke Unreal Engine APIs and custom code for core operations at the building, volume, and element levels. Although the proposed agentic modeling framework is demonstrated using game engine environments, it holds significant potential for use in architectural software, offering broad compatibility with industry-standard platforms like Rhinoceros and Revit to enhance AI-driven workflows.
Dynamic modeling is facilitated through the 3D Reasoning Agent’s task hierarchy and multi-agent collaboration (Figure 5). Complex tasks are decomposed into subtasks and distributed to specialized sub-agents: BuildingAgent, VolumeAgent, and ElementAgent. Each sub-agent operates at different hierarchical levels, ensuring logical consistency and adaptability. The agent action coding library serves as the action space for sub-agents engaged in 3D modeling operations. This modular library offers operations tailored to modeling tasks. For example: BuildingAgent executes high-level operations such as “Add Building,” “Adjust Overall Style,” and “Modify Orientation.” VolumeAgent handles intermediate tasks like “Cut Volume,” “Adjust Volume Size,” and “Change Volume Style.” ElementAgent manages fine-grained modifications, including “Create Opening,” “Set Material,” and “Add Doors and Windows.” The 3D reasoning agent processing: Modeling using sub-agent in the action agent library.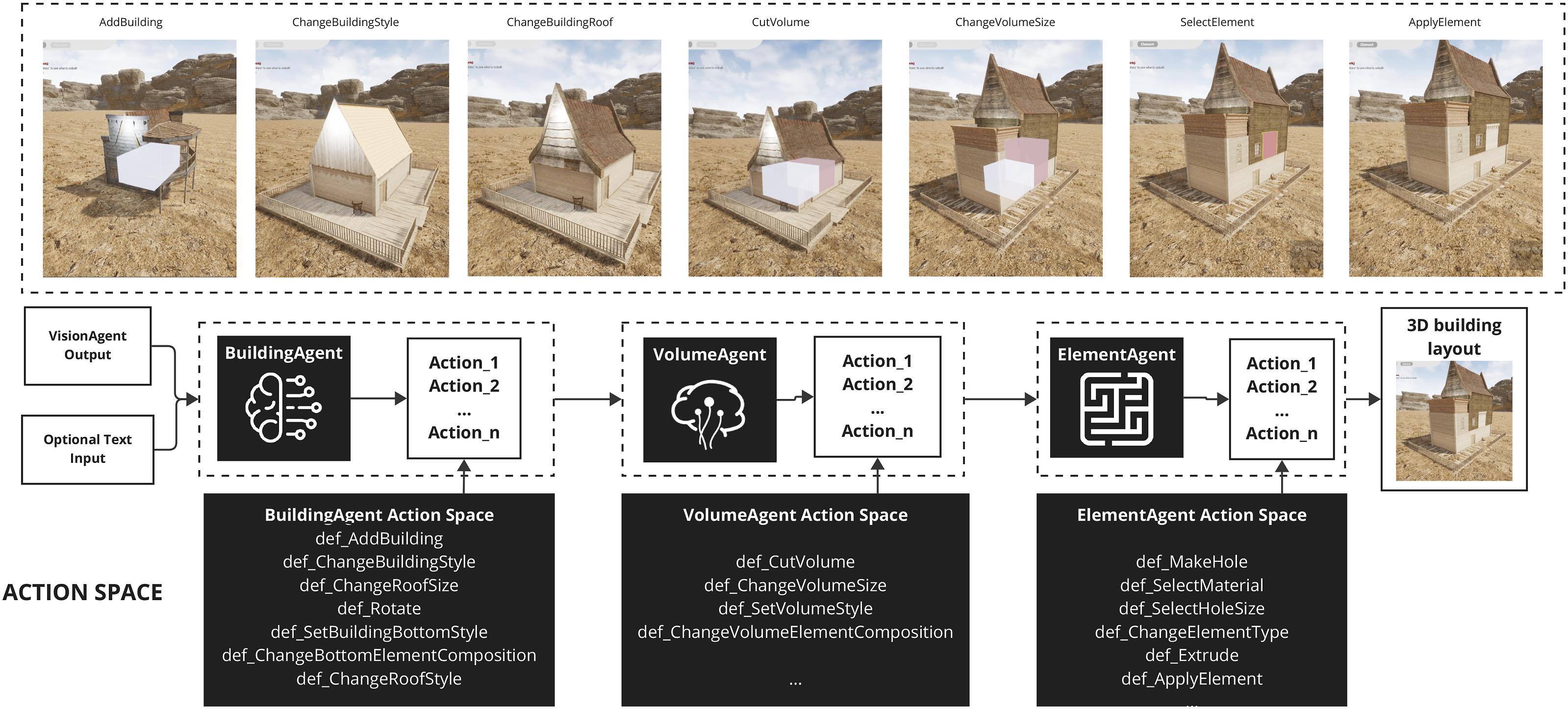
Action execution involves two steps: identifying actions in the action agent library based on task content from natural language instructions, and parsing parameters like location, style, and size to generate concrete operations. This systematic approach enables flexible task accommodation and ensures logical and architectural consistency in the shape generation.
A key advantage of the 3D Reasoning Agent is its capacity for compositional modeling and iterative editing, challenges mentioned before. Conventional methods struggle with coherence during iterative modifications, leading to inconsistencies and inflexibility, which lack effective handling of compositional structures, hindering individual component modification without impacting the entire model. In contrast, the 3D Reasoning Agent’s hierarchical and modular design enables independent component editing while preserving structural integrity. Specialized sub-agents and the action agent library allow targeted modifications at various granularities, from buildings to elements. This facilitates intuitive, flexible, and seamless iterative edits without compromising model coherence.
Reflection agent: Optimizing models
The primary role of the Reflection Agent is to ensure that the generated 3D model aligns with the target design specified by the Vision Agent. It achieves this by systematically comparing the current model against the target data and generating feedback to iteratively improve model quality.
The module conducts comparisons across three hierarchical levels: Building Level, Volume Level and Element Level.
Each level outputs a discrepancy score, calculated based on the structured JSON data representing both the target and generated models. The system determines whether significant differences exist by comparing these scores against predefined thresholds. If the discrepancies exceed the thresholds, the Reflection Agent generates new optimization instructions and transmits them to the 3D Reasoning Agent. This triggers a closed-loop refinement process that continues until the model sufficiently matches the target design, as illustrated in Figure 6. Closed-loop workflow of the reflection agent with multi-level difference analysis.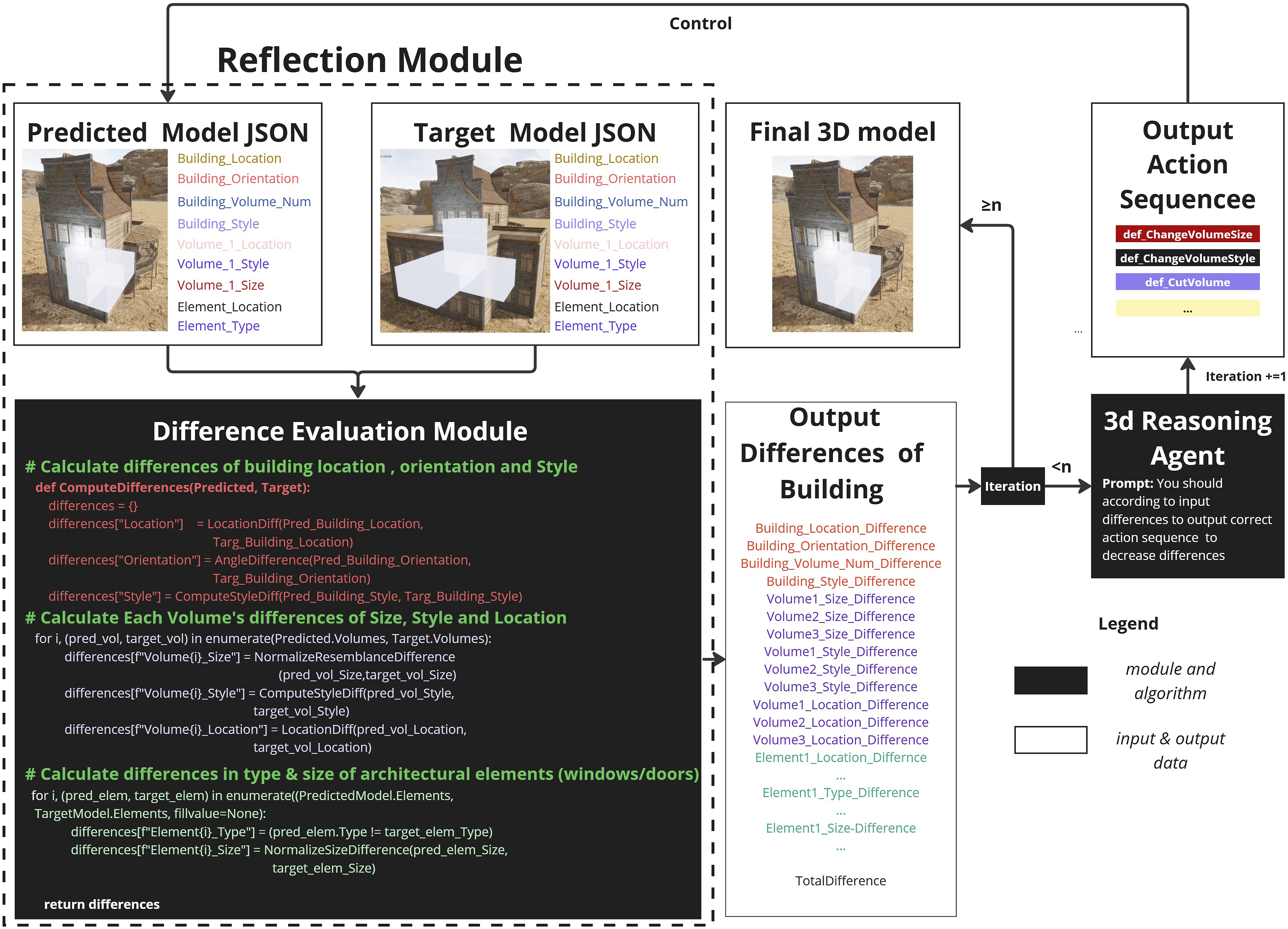
Building level comparison involves assessing various attributes between the predicted and target models, including location (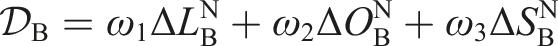
In the volume level comparison, the volume 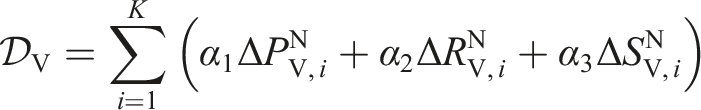
The
The element difference function 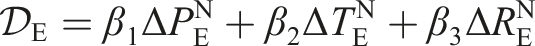
If the number of iterations exceeds a user-configured maximum threshold, the Reflection Agent stops the optimization process. Otherwise, the agent continues to generate optimization tasks based on the current discrepancies and sends them to the 3D Reasoning Agent for further model refinement.
This hierarchical feedback system enables precise corrections at multiple levels while maintaining the overall structural integrity of the model. By leveraging structured JSON outputs and weighted metrics, the system provides transparent, traceable, and goal-oriented feedback, allowing design priorities such as geometric accuracy or stylistic consistency to be flexibly adjusted.
Data-driven 3D module: Generating interior layouts
The Data-Driven 3D Layout Module is responsible for inferring detailed interior spatial layouts based on the generated building volumes. This module applies a data-driven approach, transforming the volumetric outputs from the 3D Reasoning Agent into functionally complete, structurally coherent interior layouts enriched with architectural components. It leverages a pretrained graph neural network (GNN) model to predict the distribution of interior elements such as walls, doors, and windows, ensuring that the generated layouts are both realistic and consistent with the external building form.
To address key challenges in deriving interior layouts from sketch-based external volumes, the module implements the following strategies: Sketch Ambiguity: Architectural sketches often lack explicit interior details. The module compensates for missing information by learning spatial organization patterns from large-scale datasets, enabling plausible and functional layout predictions. Complex Spatial Relationships: By adopting a graph-structured representation, the model captures intricate functional and spatial dependencies among building components. Volume Alignment: Spatial constraints are embedded within the graph structure to ensure that the predicted layouts align coherently with the external geometry of the building.
Our system utilizes the BuildingVGAE framework, specifically a Variational Graph Autoencoder (VGAE) model trained with a Graph-BIM encoding strategy (Figure 7). Building volumes are partitioned into a 3D spatial grid, where nodes represent spatial points (e.g., wall intersections) and edges represent architectural components (e.g., walls, doors, windows). This structured graph data serves as input to the pretrained GNN model. The data-driven 3D agent processing: Predicting interior layouts and details via a pretrained model.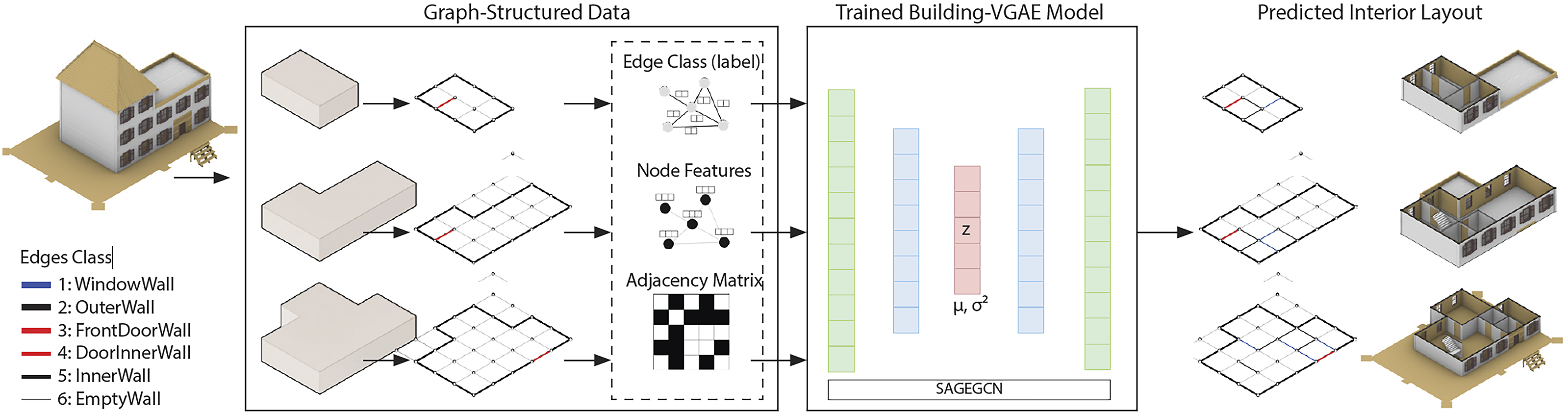
The model is trained on a modified HouseGAN dataset, which includes over 27,000 annotated building samples. These samples are converted into 3D BIM models aligned with a 3D spatial grid, ensuring consistency in the training data. Through this process, the module learns realistic interior spatial structures and component relationships.
The VGAE model adopts a three-layer SAGEConv encoder that reduces feature dimensions from 256 to 128 and 64, and finally projects into a 32-dimensional latent space. The decoder reconstructs detailed interior layouts by predicting the classes of edges corresponding to different architectural components.
The BuildingVGAE framework demonstrates strong generalization capability, accurately reconstructing realistic and accessible interior layouts from new building volumes. The module is pretrained without altering original network parameters, ensuring reproducibility and stability.
By employing a transparent architecture, open-source datasets, and a reproducible training pipeline, the Data-Driven 3D Layout Module provides robust and reliable support for automated architectural modeling, enabling the generation of functional and coherent interior spaces from abstract volumetric inputs.
Experiments and result analysis
The performance of our approach was evaluated through experiments focusing on 3D model generation from architectural sketches and dynamic interaction capabilities. This section presents three experiments designed to validate the approach’s interpretability, controllability, modifiability, and adaptability across various design scenarios. These scenarios include individual sketches, group building sketches, and interactions that combine multiple modes of communication, such as natural language.
The first experiment, as illustrated in Figure 8, confirms that our proposed approach effectively generates final 3D models while dynamically engaging a 3D engine to produce a sequence that aligns with human design logic. This process vividly demonstrates the transition from initial sketches to complete 3D models, significantly enhancing the interpretability, controllability, and modifiability of the 3D modeling workflow. Stepwise generation using the proposed approach for diverse requirements: Volume-composed buildings and building groups.
In this experiment, the approach successfully processed three single-building sketches, each characterized by distinct volume compositions and architectural styles, as well as a composite sketch representing a group of buildings. This versatility showcases the approach’s adaptability and logical consistency across a variety of design scenarios.
When presented with hand-drawn sketches of single buildings, our approach incrementally adds structural details—such as roofs, windows, and door frames—beginning with basic geometric forms and culminating in realistic final 3D representations. Each step of the generation process transparently reveals the approach’s dynamic reasoning, enabling users to intuitively grasp the underlying design logic and facilitating adjustments and optimizations at every stage.
For sketches depicting building groups, our method, although the generated 3D models do not perfectly match the sketches, captures the relative layouts and spatial relationships among multiple structures, reproducing these relationships within the 3D scene. This capability, while not fully replicating the 3D forms in the sketch, underscores the approach’s robust logical reasoning and generative proficiency in complex scenarios, thereby broadening its applicability in architectural design. The results of the first experiment demonstrate that our approach not only achieves clear hierarchical 3D model generation but also fosters a transparent and interactive design process.
The second systematically evaluates the performance of our proposed method in sketch understanding and 3D reasoning, comparing it with leading 3D generation models, including TripoSR, Rodin, and OpenLRM. Due to the lack of standardized benchmark datasets for architectural sketch inputs, conventional evaluation metrics such as F1 scores and IoU are not directly applicable. Therefore, we designed a comprehensive evaluation framework based on the core requirements of architectural design and modeling. This framework includes five key metrics: ClipValue, BVE Difference, Editability, Generation Time, and Stepwise Interpretability.
The ClipValue (0–1) measures the visual-semantic similarity between the input sketch and the generated 3D model, with higher values indicating better semantic preservation. BVE Difference (0–1) quantifies the structural discrepancy between the generated model and the intended sketch across three hierarchical levels—Building (B), Volume (V), and Element (E)—with lower scores indicating higher structural fidelity. Editability (0–5) is assessed through five binary sub-criteria: Component Independence, Local Editability, Mesh Cleanliness, Parameterizable Editing, and Editing Overhead, reflecting the practical usability of the generated models. Generation Time (measured in seconds) captures the time elapsed from sketch input to model output, representing system responsiveness. Stepwise Interpretability evaluates whether the generation process supports stage-by-stage construction and user intervention, assessing the transparency and controllability of the modeling process.
Figure 9 and Table 2 present the comparative performance results across four experimental scenarios (EXP_1–EXP_4). The results demonstrate that our approach consistently outperforms existing methods in terms of sketch comprehension, spatial reasoning, and controllability. Specifically, our method achieves higher ClipValue and lower BVE Difference scores compared to Rodin and OpenLRM, while maintaining comparable or slightly lower performance relative to TripoSR, which primarily outputs wireframe models. Through a stepwise reasoning process, our model effectively captures both global massing relationships and local architectural features from the sketches. Comparisons of the directly generated results among our approach, TripoSR, rodin, and OpenLRM. Comprehensive performance comparison of different methods on sketch-to-3D generation tasks.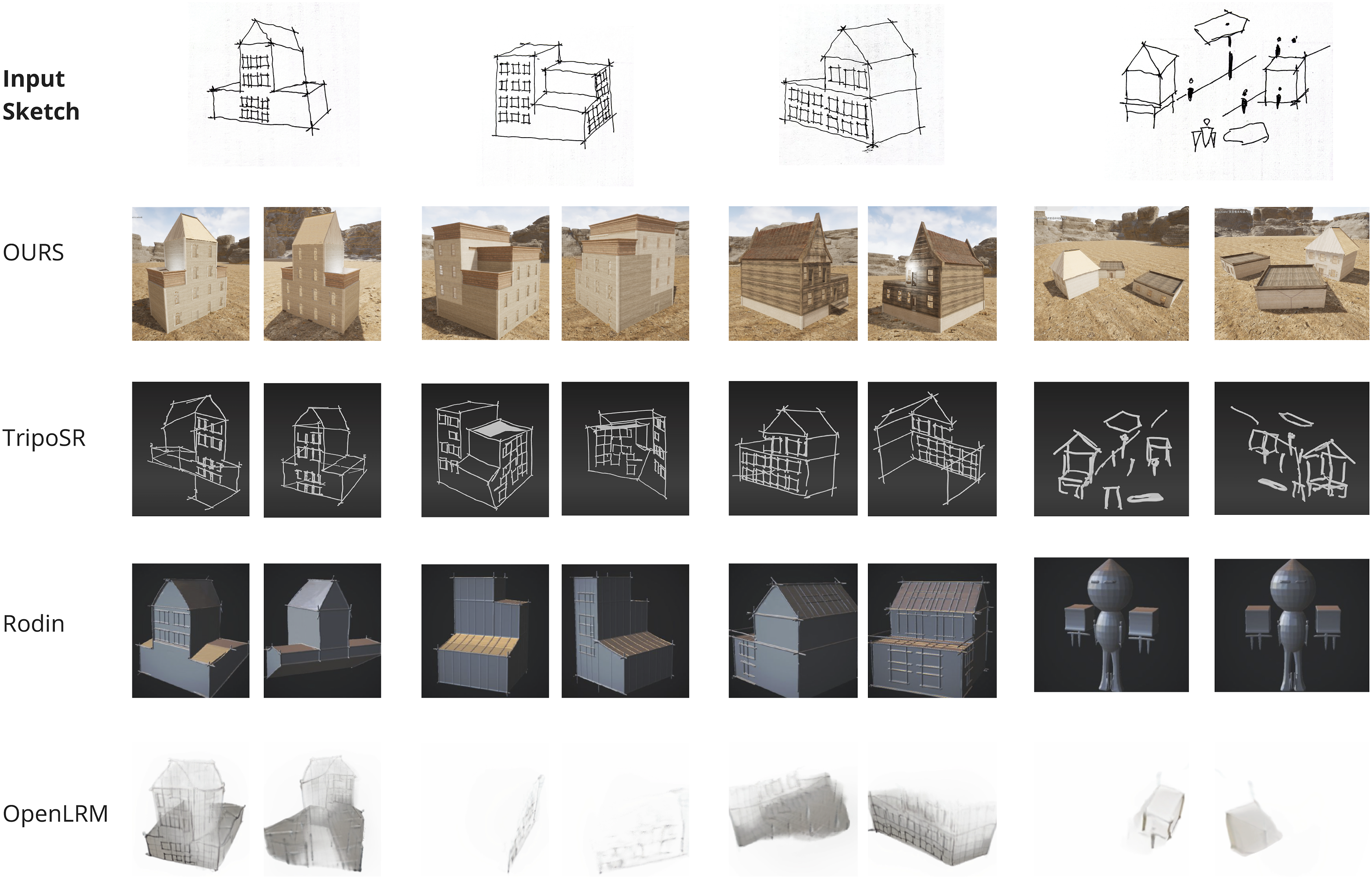
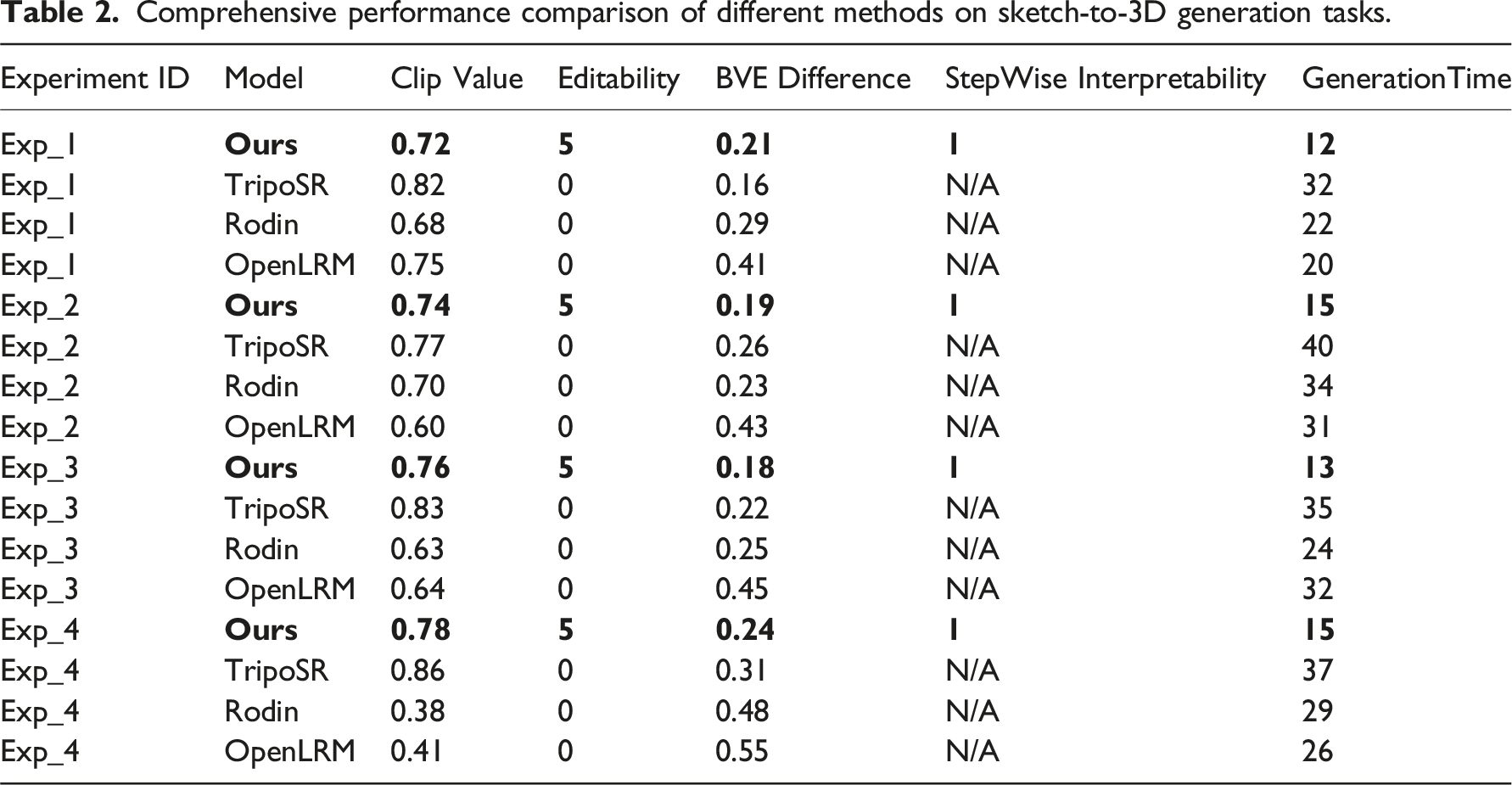
In terms of editability and modeling quality, our method achieves full scores across all five editability sub-criteria, significantly outperforming other methods. The generated models allow independent manipulation of components, support local modifications without structural disruption, maintain clean and well-formed meshes, enable parametric transformations, and require minimal post-processing. These properties greatly enhance the ease of subsequent design editing and optimization.
Regarding generation time and system responsiveness, our method leverages vision-language models (VLMs) to parse sketches into structured JSON representations and incrementally constructs models through modular functions. This design avoids the heavy inference overhead typically associated with end-to-end 3D networks. As a result, the generation time of our method is comparable to or faster than that of Rodin, TripoSR, and OpenLRM.
Our method also demonstrates significant advantages in process transparency and user controllability. By supporting stepwise generation and real-time user intervention, it enhances the interpretability and transparency of the modeling process, effectively overcoming the limitations of conventional “black-box” generation approaches.
Although our method exhibits slightly lower fidelity in restoring fine geometric details compared to Rodin, particularly in certain viewpoint-specific geometric fittings, it demonstrates clear advantages in spatial relationship construction, overall structural rationality, component independence, and dynamic reasoning capabilities. Rodin, which is primarily trained on multi-view images, excels at local geometric restoration but lacks the capacity to generate interior structures or support dynamic and editable generation processes. In contrast, TripoSR produces only line-based structures, resulting in poor spatial completeness, while OpenLRM tends to overfit local details and fails to reconstruct complete architectural forms.
In summary, our method exhibits significant advantages in sketch interpretation, detail construction, dynamic generation mechanisms, and interactive controllability. It provides a more efficient, logically consistent, and user-controllable solution for automated 3D architectural modeling, enabling the rapid generation of high-quality building models from diverse and abstract sketch inputs in alignment with architectural design logic.
The third experiment (Figure 10) shows the capabilities of our proposed visual reasoning and generation framework for creating 3D models from sketches with dynamic interactions. We validate the approach’s performance in multimodal interactions, combining visual sketches and natural language instructions, emphasizing its interpretability, flexibility, and precision. Multimodal inputs in our approach for flexible decision-making.
Results demonstrate that the model accurately extracts design intentions from sketches, producing logically consistent 3D architectural models. Our approach’s natural language interaction enables users to modify geometric structures and details through verbal commands, with real-time, precise adjustments. For example, when instructed to “Add a volume along the Y-axis to make it the tallest part of the building,” the model promptly generated and positioned the new volume accordingly. Similarly, commands such as “Increase the number of windows on the ground floor, modify the roof to be flat, and rotate it 45 degrees,” were executed simultaneously, reflecting complex modifications. The experimental figures illustrate that our framework facilitates flexible and precise multimodal interactions: sketches establish the global geometry, while natural language instructions refine details and overall structure.
Overall, the experiments demonstrated the efficiency of the proposed approach, enhancing the design process’s flexibility and usability. This allows non-experts to effectively participate in generating 3D models through handy ways.
Limitation
To further assess the performance of our proposed approach, we conducted a standalone experiment using given descriptions of 3D buildings, as shown in Figure 11. The experimental evaluation highlights both its strengths and limitations in generating structured 3D models from sketches. We began by using structured natural language descriptions that included geometric shapes, materials, element types, spatial layouts, and rotation angles to generate corresponding 3D models. These models were then captured as screenshots and processed by a visual model to extract structured data. This extracted data was meticulously compared to the original target data to calculate difference values, thereby assessing the visual model’s proficiency in spatial semantic understanding (e.g., materials, colors, element types) and spatial scale quantification (e.g., positions, volumes, angles). Comparison of difference values between specified structured data and VLM-Parsed data from 3D models generated using the given data.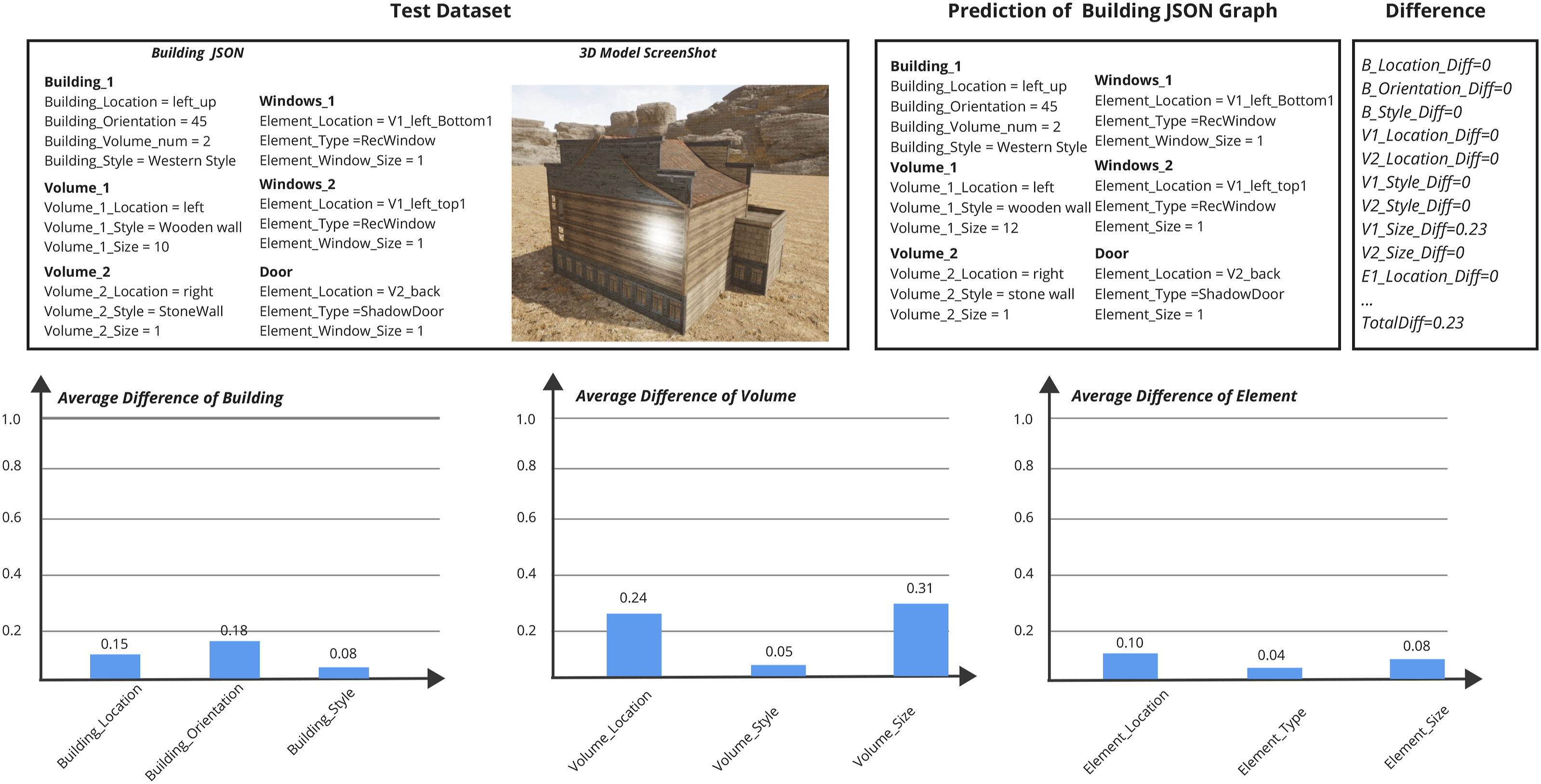
The results indicate that the approach excels in extracting spatial semantics. Specifically, it shows a notable difference in certain attributes, such as building orientation with an average difference of 0.18, reflecting the model’s challenges in accurately capturing this aspect. Building style demonstrates a minimal difference of 0.08, suggesting closer alignment with the target data. The approach struggles with volume attributes, particularly volume size, which has the highest difference of 0.31, indicating substantial inaccuracies. Additionally, the differences in element attributes, including an average difference of 0.10 for location and 0.08 for size, demonstrate a strong ability to understand complex element relationships. Overall, these findings underscore the model’s strengths in some areas but also reveal shortcomings in quantifying spatial features and accurately estimating geometric relationships, which can affect the effectiveness of semantic feature extraction and agentic modeling.
These shortcomings arise from our approach’s reliance solely on image features, which limits its ability to understand spatial depth and accurately capture 3D geometric measurements. Consequently, although the visual model excels in semantic extraction, it requires the integration of additional spatial understanding mechanisms to address challenges in spatial scale and geometric relationships.
Conclusion and future work
This study proposes a vision-action-driven multi-agent framework for generative 3D architectural modeling from sketches, aiming to bridge the gap between static AI generation pipelines and the dynamic, reflective processes of human architects. By structuring the system around observation, reasoning, feedback, and correction loops, the framework enables AI not merely to automate modeling tasks, but to engage in an iterative and semantically structured generation process.
The experimental results validate the system’s ability to accurately interpret sketch inputs, extract semantic information, and produce editable, hierarchically organized 3D outputs. Compared to conventional end-to-end methods, our framework achieves significant improvements in model explainability, controllability, and adaptability to design iteration workflows. These outcomes demonstrate that, by aligning AI processes with the structural logic of human design activities, it is possible to enhance both the usability and creative applicability of AI-generated models.
However, the study also reveals fundamental limitations that stem from deeper differences between AI modeling and human architectural cognition. While the proposed system effectively captures spatial syntax and compositional logic, it remains limited in understanding contextual, experiential, and value-driven aspects of design. Controlled experiments highlight challenges in spatial scale quantification, indicating the need for more sophisticated spatial reasoning beyond purely visual feature extraction. Moreover, the current framework operates primarily on static sketch inputs, lacking temporal design evolution and broader multimodal integration, which are essential in real-world creative processes.
To address these limitations and move closer to human-aligned design intelligence, future research will focus on three strategic directions: Enhancing Spatial Reasoning: Integrating depth estimation models, geometric constraint learning, and spatial simulation capabilities to improve the precision and realism of generated structures. Expanding Contextual and Multimodal Understanding: Incorporating textual descriptions, user intents, functional narratives, and other contextual data into the modeling process to enable richer and more situationally aware design reasoning. Fostering Human-AI Collaborative Design: Moving beyond AI as a passive generator toward systems that can dynamically negotiate, adapt, and co-create with human designers through iterative feedback, scenario exploration, and proactive design suggestions.
Ultimately, this research suggests that the future of AI-assisted architectural design lies not in replicating human cognition, but in structurally aligning with human workflows, supporting reflective, explainable, and value-driven design processes. We believe that this system offers a promising path toward building collaborative, interpretable, and semantically aligned design support tools. It is not intended to fully automate the design process, but rather to provide a mechanism for “co-constructive” human–AI collaboration, where human intent and AI suggestions iteratively shape the design outcome. This perspective also reflects a broader shift in computational design—from automation toward augmentation.
Supplemental Material
Supplemental Material
Footnotes
Declaration of conflicting interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical statement
Data Availability Statement
The datasets and model generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.