
Abstract
Generative artificial intelligence has swept into design research and practice, with popular image generators and language model interfaces now being used across disciplines and design stages. The multimodal language models exhibit fundamentally different characteristics from earlier machine learning approaches, and present unique challenges and opportunities for designers. A key question for design research arises: How can the capabilities of these large multimodal models become part of our design tools? This work investigates how the recent development of reasoning language models in particular can be utilized for early stage exploratory design. We outline a set of principles to build effective tools with these models by drawing from research in artificial intelligence. Specifically, we explore the application of the new reasoning model paradigm in computational design scripting. We present a system which successfully generates computer-aided design (CAD) scripts in Grasshopper. The system is compared to existing CAD AI approaches for its capabilities and characteristics. High latency and the absence of a user-model feedback loop still restrict real-time exploration in our system. Our developed principles can further inform broad exploratory tools and motivate inquiries into multimodal reasoning for design. By demonstrating a new CAD approach, we show large models’ utility as creative tools. Future research should address latency, enhance interactivity, and address other design tasks beyond CAD.
Keywords
Introduction
We propose large language models (LLMs) as powerful tools for enabling exploratory design processes in architecture. This paper outlines guiding principles to build such tools, and details our implementation of a generative computer-aided design (CAD) system within Grasshopper. By drawing on recent developments in multimodal “reasoning” models, we show how these emerging capabilities can help bridge the gap between early conceptual sketching and precise parametric design.
Design always occurs within context, both explicitly and implicitly. Tools that employ large, multimodal language models provide an opportunity to make explicit interactions with the large data learned by models. To build such tools, the design research community needs to understand the characteristics and capabilities of these models, and reevaluate how machine learning can contribute to design. In this paper, we develop a set of principles for creating exploratory tools using large models by drawing from contemporary research on their behavior. Our aim is to create broad, open systems as tools for designers. We implement such a system for the task of computational design scripting using reasoning models, and compare the output of our system to existing text-to-CAD approaches.
Computational designing
Integrating computational tools has reshaped the design disciplines, profoundly altering the way architects conceptualize, develop, and realize their designs. In architecture, designs are now formed in a continuous exchange with digital technologies, encompassing digital plans, renderings, 3D-printed models, and immersive virtual environments. These digital tools have transformed the discipline, automating repetitive and labor-intensive tasks and enabling the design and execution of projects at unprecedented complexity and precision. The analog tools of the past have been largely supplanted by digital systems, upending past traditions and shaping new practices.
A key characteristic of this digital shift is the requirement for explicit decision-making, particularly in the early stages of design. While traditional sketching provides an open-ended and iterative medium for exploration, digital tools often require architects to specify exact parameters from the outset. This is most pronounced in computational design, where the focus moves from direct manipulation of form to the abstraction of architectural algorithms. The peak of this digitized architectural practise is design scripting; generating explicit geometry through algorithmic logic. Initially confined to specialist circles, computational design has now become a central methodology in architectural education and practice to explore vast design spaces, 1 with tools like Grasshopper enabling architects to engage with algorithmic workflows through more accessible, visual scripting interfaces. The resulting scripting culture and accompanying style is perhaps the most significant trend of the past two decades in architecture, turning architects into digital tool makers. 2
These computational tools, while powerful, are limited. They rely on well-defined constraints and parameters, making it difficult to use them for the early, exploratory stages of design, where ambiguity and open-ended thinking dominate. Creating geometric algorithms for computational tools demands a level of precision and structure that is incompatible with the fluid and iterative nature of conceptual design. As a result, architects frequently revert to freehand sketching, collaging or other traditional techniques to explore initial ideas, moving to computational tools at later stages in design, when concrete decisions have already been made. Bridging the gap between free modes of exploratory design and the structured logic of algorithmic systems would empower designers to effectively leverage computational tools across all stages of the design process, creating new opportunities for creative exploration through algorithms.
Custom models and designer-like thinking
Machine learning models introduced a new paradigm to computational tools, shifting capabilities from deterministic logic to probabilistic modeling. Unlike traditional software, these systems learn from data, observe patterns and generate new data. With the advent of generative artificial intelligence, machine learning models moved from classifying to creating data, combining what they’ve learned with provided context. This makes them more similar to how designers think, 3 as they too draw from prior experience to produce solutions to new contexts.
The discipline quickly embraced this new capability, training custom models on design-specific datasets to generate images of buildings, cityscapes, and other architectural forms, often capturing the mood, style, or essence of a place. 4 Experimental explorations highlighted how machine learning could serve both as a design tool and a reflective mechanism, revealing inherent structures and distilled “knowledge” encoded within data. This marked a stark departure from decades of deterministic computational approaches and the design tools that were produced. The first period of generative artificial intelligence was driven by bespoke, narrowly focused models and a spirit of experimentation that sought to understand how these systems might augment or transform the design process.
Generative models and mainstream adoption
The public release of MidJourney in 2022 made very large generative image models available to the public, and marked the beginning of a new era of generative design tools. Architects and designers quickly integrated it into their workflows, sparking vibrant discussions about potential and limitations, while the models capabilities quickly advanced. By 2024, generative image models have become familiar tools across many design disciplines, integrated into widely used software such as Photoshop and displayed on the pin up boards of student projects around the world. This broad adoption was driven by the easy to use natural language interface, and the existing familiarity with modifying and editing the image medium. Generative models transformed explorative design phases, offering new ways to rapidly visualize ideas, explore creative directions, and produce high-quality results. Accessibility and the quick speed of iteration made them instantly popular for exploring visual design spaces. The shift from self-trained to massive pretrained models, which absorb vast web-scale visual data, obscures their contextual references and capability limits, raising unresolved questions of authorship and dataset ethics—yet machine learning continues to integrate into design
Adapting to New Models
The emergence of large language models (LLMs) alongside early generative image systems sparked a global phenomenon. ChatGPT reached a million users in record time, fueled by its astonishing adaptability and training on unprecedented scales of textual—and now multimodal—data. Newer iterations are trained on both text and images, operating in a unified “idea space” and breaking down traditional notions of separate mediums. These models exhibit emergent behaviors that go far beyond the capabilities of earlier models, and clearly offer fascinating potential for design research. Design research cannot map previous practices and intuitions to these tools, but must develop new approaches alongside the new technology. 5
In earlier machine learning workflows, clean, proprietary datasets were prerequisites for generating intelligible results. But LLMs flip this paradigm on its head. Straight out of the box, they excel at tasks guided solely by prompts or minimal examples, bypassing the painstaking dataset preparation and model-specific training of the past. In architecture, LLM’s most prominent application has been limited to surfacing code compliance information 6 by being paired with retrieval systems—a valuable subset of their capabilities that ignores their potential as exploratory design tools. The models’ capacity to write about every architectural style in history or generate matching images has been only lightly explored, and a wealth of potential remains untapped.
The intuitions developed in previous machine learning design research suggests extensive teaching of the model through fine tuning and contextual examples. While it may enhance performance in narrow tasks, this clearly constrains its broader, emergent capabilities. For exploratory design, where tools must remain open-ended and flexible, such restrictions undermine the very breadth that makes these models powerful tools. Approaches that employ fine tuning succeeded in generating CAD models, 7 but are so rigid and narrow that they become useless to the exploratory, boundary-pushing needs of designers. For a discipline that requires open tools, and explicit interactions with the learned language model idea space, fine tuning and too many contextual examples will always guide the model output to be restrained and create tools with marginal utility and affordances.
Principles for large language models in design tools
In this work, we propose a set of principles for employing large, multimodal language models (LLMs) as creative and exploratory design tools. In stark contrast to previous systems, LLMs offer the flexibility to address open-ended tasks by operating in a broad “idea space” that spans text, images, and other data. This adaptability matches the ambiguous and evolving nature of early-stage design, where problems and solutions are discovered in tandem. Reasoning-oriented LLMs, in particular, excel at translating loosely defined constraints into executable design outputs—such as CAD scripts—and empower designers to focus on higher-level goals rather than programming exact logic.
We propose using these models in their general and multimodal capacity, rather than restricting them to automating constrained, predefined tasks. Embracing uncertainty and the emergent reasoning of LLMs can better support the multifaceted needs of designers and enable their iterative processes with computational design tools. We detail our principles in a dedicated section later in the paper, illustrating how they inform the design of our CAD scripting prototype.
Our prototyped system
We demonstrate these principles through a prototyped system that employs large “reasoning” language models for computational design scripting. Our approach adapts to diverse constraints and yields editable outputs, making it well suited for exploratory design tasks. To situate its capabilities, we compare its performance with existing AI-driven CAD solutions: • Code Generators (e.g., zoo.dev) often rely on curated examples (and likely fine-tuning) for high accuracy in a narrow domain. While their code outputs can be edited, relying on traditional coding formats can make it hard for architects to use them, and requires switching to new CAD programs. • Mesh Generators (e.g., Meshy.ai) often prioritize aesthetics over precision, producing dimensionally imprecise meshes with limited interactivity. This approach does not support iterative refinement and exploration.
Our system leverages the adaptability of reasoning LLMs and node-based parametric design to generate and refine scripts dynamically. Unlike our earlier, more rigid task-decomposition work 3 , these new reasoning capabilities handle varied user prompts with greater accuracy and creativity. By embracing generality, multimodality, and flexibility, the system supports open-ended exploration—vital to early-stage and iterative design processes.
State of the art
Our approach relies on the recent advancements in pretrained, large language models and the more recent reasoning model paradigm. The work is set in the context of generative geometry, a field that has been explored both before and since the advent of large language models.
Logic and reasoning in large language models
Generating computational design scripts requires constructing sound algorithmic logic. Initially, language models were discarded as stochastic parrots incapable of reasoning or constructing logic, and shown to be unable to correct false reasoning. 8 Recent advancements address these shortcomings, with much better performance on relevant benchmarks such as MATH. 9 A key development are models specifically trained to expend thinking tokens before providing a final response, called ‘reasoning models’. This new paradigm of large language models is a very recent development, with some of their architecture still unpublished.
Chain of thought and search
Chain of thought prompting (CoT) improves reasoning by having models produce ‘thinking’ text output before reaching a conclusion, effectively breaking tasks into smaller steps, and can be as simple as asking a model to ‘think step by step’.10,11 This method boosts performance on problems that require intermediate reasoning or planning. A new approach called Chain of Continuous Thought 12 refines CoT further by feeding the model’s hidden embeddings back into the system before converting them to explicit tokens. This allows the model to reason in continuous latent space instead of language, so it can consider multiple next steps simultaneously and improve its flexibility and accuracy in reasoning for some tasks. The same team has trained a small model to inherently perform a search of the solution space before answering, 13 and it retains impressive capabilities even when the explicit search is suppressed at inference. OpenAI trained a model to specifically produce such text chains of thought; their reasoning model “o1” 14 released in September 2024 improved scores significantly on tasks involving formal logic (+17.2%), mathematical reasoning (+34.5%), and physics reasoning (+32.2%). The results are especially impressive on tasks that require logical steps and following constraints, similar to constructing CAD logic.
Neurosymbolic approaches
Machine learning models that rely on neural networks are good at providing likely solutions but cannot guarantee correctness. Symbolic systems on the other hand, such as the automated theorem prover Lean or the Prolog language, 15 are deterministic, algorithmic tools enforcing strict rules and consistency with constraints. Neurosymbolic methods combine these two strategies for intelligent systems by using neural models to propose symbolic definitions and steps, and symbolic solvers to verify or refine them.
For example, GPT-f 16 deduces mathematical proofs by proposing next steps, which are then checked for correctness by formal methods. Alpha Geometry 17 extends this idea to geometric proofs. It employs a symbolic solver to find a solution based on the given elements in a math olympiad geometry problem. If no solution exists, the neural model suggests new elements to be constructed, like drawing a circle to create new intersection points, which are then added to the symbolic solver. This process repeats until the symbolic system constructs a successful proof, and its performance approaches the average IMO gold medalist for geometry problems.
Generative AI CAD
Various approaches have been explored to integrate generative AI into computer-aided design (CAD). These methods range from adapting diffusion models for 3D content to implementing neurosymbolic systems and executable CAD scripts. Each approach comes with unique capabilities and limitations that point to its broader applicability in existing and future CAD workflows.
Mesh diffusion
A popular way to generate 3D objects is through mesh diffusion models. Early work repurposed image diffusion models by generating 2D images from various viewpoints and then reconstructing meshes through photogrammetry, an approach pioneered by DreamFusion. 18 Commercial tools 19 have already shown the viability of text-to-mesh pipelines. While these models yield visually recognizable 3D assets, they trade impressive appearance over dimensional precision. The generated Polygonal meshes are suitable mostly for animation and rendering but can be problematic for workflows that require exact dimensions, such as design for fabrication.
Brep and other diffusion
Recent projects aim to mitigate the precision gap by adapting diffusion to other geometric representations. For instance, 20 from NVIDIA extracts a point cloud from a common, imprecise mesh diffusion model and then recomputes its geometry by tokenizing the point coordinates rather than relying on pixel-based features, and produces high fidelity outputs. Meanwhile, a team at Fraser University and Autodesk 21 has extended diffusion to boundary representation models, enabling more dimensionally accurate forms of CAD data. These methods show promise for integrating precise CAD requirements with the generative flexibility of neural networks.
Programmatic CAD
Language models have been applied to generate executable code for 3D models in common CAD environments. Such systems generate CADQuery code, 22 or python scripts 23 for models in blender, and the code offers parameter control. A commercial system 24 generates scripts in the proprietary KittyCAD language. These systems sometimes rely on in-context examples and fine tuning to adapt large language models to the specific, uncommon, programming languages and their syntax. While programmatic CAD allows precise parameter-driven control, to most designers it is less accessible than graphical interfaces. Both approaches highlight how language models can integrate into CAD workflows, balancing flexibility, usability, and precision.
Neurosymbolic CAD
Neurosymbolic CAD combines learning-based generation with symbolic logic. Models generate symbolic programs like Grasshopper scripts, and symbolic systems execute them. This approach is inherently data-efficient since models only need to combine lists of geometric operations and constraints, rather than raw 3D coordinates. An added benefit of the lightweight representation is how it allows users to modify or extend the generated programs to meet their requirements. This approach has been explored extensively in computer graphics. 25 Early research on computer aided design 26 introduced custom-trained models, while more recent methods use large language models to create parametric modeling scripts.
Immediate precursor
The system presented here builds on an earlier method described in Mediating Modes of Thought, 27 which generated visual Grasshopper scripts from short text inputs. Our work extends this idea by incorporating the latest reasoning-focused models, aiming to provide a more intuitive and flexible design workflow for computational design, and by expanding to image inputs. Both the previous work and this project make use of the open source project GHPT 28 as the logic to translate a list of Grasshopper components and connections to the user’s canvas.
System design principles
In this section, we outline our four principles for designing with large language models. Specifically, we are focusing on the implementation of creativity tools to support exploratory design processes, especially in our sub problem for CAD scripts. We draw from other disciplines to motivate our ideas, and discuss how they relate to design research specifically, providing the background to the choices made in designing our prototyped system.
Generality and utility
When designing systems around large models, we must decide if the system should remain general or become narrow in focus. The utility of foundation models lies in their extensive encoding of knowledge with incredible breadth, and the emergent intelligence that arises from it. For instance, a multimodal model can take input from many world languages, interpret sketches or images, draw on real world knowledge such as the dimensions of the golden gate bridge - and produce a Grasshopper script logic from all of this. Their breadth equips these systems with a vast reservoir of knowledge, and makes them flexible enough to be employed by different disciplines such as engineering and jewellery design.
Their generality also has specific drawbacks. The internet scale training set produces ‘common-sense’ results for given context, reflecting the most likely results from across the ingested dataset. The more unique and rare an idea or approach, the less likely such a system is to reproduce it. In writing, language models will reproduce the most common text patterns observed. In our system, this tendency recreates common programming constructs, such as loops, that align with its broader training data but are incompatible with the specific linear logic of Grasshopper. The broad training can also introduce assumptions or pseudo-knowledge that are conflicting within the tools current context. When the user is looking for exact task execution, data can leak into the model’s response that ends up directing it away from the user’s specific goals. The same interaction can also be interpreted as an explicit interaction of the user’s inputs with the model’s learned context and become deliberate.
Fine tuning and contextual examples
To address these issues, systems that employ large models for creative tasks must carefully navigate the tradeoff between their expansive generality and the precision required for narrow, well-defined problems. While the strategies of fine-tuning and contextual examples offer solutions for tailoring models to specific tasks, they are suboptimal for the broad, exploratory goals of design tools.
Fine-tuning adjusts a model’s weights based on examples of provided solutions, 29 and can be thought of as adjusting a model to a custom dataset. This makes it an effective strategy for solving well defined, narrow tasks where examples exist, or teaching specific output syntax such as a new programming language. But models fine tune over multiple dimensions, not just one. In the context of programmatic CAD, fine tuning can teach a model a new programming language but will also incline it to reproduce the models and structure of provided examples, causing it to reproduce not just syntax but also similar models. Solving the problems introduced by generality risks constraining the model’s emergent creativity - a key asset for exploratory design tools.
Similarly, contextual examples, or “few-shot learning”, can guide a model to adhere to specific structures or patterns, and require a robust library of relevant examples to avoid introducing irrelevant or distracting context. Such systems select matching examples from a database and append them to the user prompt. LLMs are very good at adhering to structures and patterns introduced using this method. 30 But for tools with broad applications, supplying relevant examples is challenging. If contextually irrelevant, examples are especially confusing to models like o1, and this was also shown for similar other systems. 31 Reasoning models have become much better at adhering to outlined formats and schemas, but are easily distracted by wrong context, so we recommend no contextual examples be used. Additionally, in-context examples can introduce the same challenges as fine tuning, where the system is inclined to reproduce the content of the examples and therefore constrain its response.
Given these tradeoffs, we propose emphasizing the generality of large models to maximize their utility for design tools, prioritizing their flexibility and emergent behavior over the accuracy of results. Fine-tuning and contextual examples should be reserved for narrow, well-defined subtasks where creative freedom is less critical, and a high degree of automation is needed. By embracing generality, design tools can maintain their broad affordances and serve as powerful, adaptable machines for creativity, supporting users across early and dynamic design challenges with benign failure modes and no absolute requirements for accuracy.
Making models ‘think’
Design tasks don’t have straight forward solutions. They require deliberation of context and constraints, a step-by-step exploration of design space by weighing up if-then scenarios, what can be thought of as “thinking time.” For generating a CAD script, this requires understanding the intended geometric outcome, then identifying relevant parameters for it, and constructing a sequence of logical commands which map from these inputs to the desired geometry. Generative AI models, by their nature as next-token predictors, are not inherently designed for such tasks. They generate output incrementally, without planning ahead or trying out different scenarios. Overcoming this linear prediction constraint is central to advancing their utility in design.
Single and multi model strategies
One of the earliest breakthroughs in this domain was to prompt models to “think step by step” 11 to improve their performance on tasks requiring logical inference. By encouraging the model to produce additional reasoning tokens before arriving at an answer, this approach helped enhance accuracy on benchmarks that involve multi-step problems. While this strategy was transformative in improving reasoning performance for individual models, it does not fundamentally change the token-by-token generation process. Building on this insight, researchers introduced approaches involving multiple models working collaboratively. These “mixture of agents” 32 strategies prompt one model to construct a detailed plan, then one or more models to execute that plan, and yet another to check the output for logical consistency. This method divides a problem into discrete subtasks, with different models handling each component. This is an effective strategy for problems with consistent structures, but it relies heavily on the predetermined division of tasks and is less suited to adapt dynamically.
Inference time compute models
In September 2024, OpenAI introduced o1-preview, a model in a new class of large models that are specifically trained for inference time compute, and excel at logical inference and reasoning in comparison to previous models. Similar to the thinking step by step prompt, these models expend many more tokens before arriving at an answer, being trained specifically to decompose problems. Though the precise architecture of OpenAI’s o model series is not public, similar systems 33 produce a stream of consciousness output where the model ‘thinks’ about different approaches to solve a task, and sometimes backtrack their reasoning. They arrive at their final output after much more compute effort than previous models, as a final conclusion of such a thought process. Conceptually, the inference time compute models can be thought of as a dynamic thinking architecture, similar to the explicitly programmed ensemble of expert systems. But instead of dissecting a problem along predefined lines, it learneed to do sodynamically, and match the expended effort to the problems complexity. For design researchers, these models take over the task of dissecting and delegating subproblems for logic operations.
While thinking architectures such as the inference-time compute models are not universally optimal, they offer clear advantages for addressing the dynamic and exploratory nature of design problems, especially those that rely on logic and constraints solving. Their adaptability makes them well suited for design tools that prioritize broad affordances and flexibility, dynamically adapting the system to different design challenges. As these models continue to evolve, they present a promising foundation for next-generation design tools.
Modality collapse
Large models learn visual concepts by training on images paired with captions, 34 integrating data from multiple modalities into a unified embedding space. Instructions, context, and tasks can be communicated through text descriptions, photos, sketches, or screen captures. Eventually, the medium through which an idea is conveyed becomes less important, and the concept that is communicated becomes central. The model can translate and respond using any medium, effectively collapsing modalities into a single representation. For designers, conveying their intentions and constraints to the model is essential, but the method of instruction becomes flexible. A pencil sketch and a detailed text description, for example, can both communicate the same idea to the model, just as they might to a human collaborator. The model distills the instructions to their informational content.
This shift aligns with Schmidhuber’s notion of compression 35 : only unexpected, non-redundant input holds value. Where no specification is provided, the model fills in the blanks with an expected solution. Generating excessive, predictable information has little value; instead, the focus shifts to conveying and interpreting concise, meaningful data. This principle represents a fundamental departure from the interfaces of conventional computational design tools, which often require users to adhere to rigid input formats and commands.
Neurosymbolic 3D models
Machine learning models can generate complex digital data types, from 3D meshes to CAD models, but the underlying informational content could often be reduced. For instance, describing a cube with an edge length of 10 requires only a few words, and no additional information is gained from modeling its mesh vertices. Language models can leverage this efficiency by generating symbolic representations rather than producing detailed geometry directly.
Our CAD generation system implements this by using large models to generate sequences of CAD operations, such as Grasshopper scripts, that define a desired object. Grasshopper scripts abstract underlying CAD operations, offering a symbolic representation that simplifies modeling and modification compared to engaging directly with underlying vector mathematics. This lightweight modeling strategy allows large models to focus on higher-level logic and relationships and let traditional CAD engines handle computationally intensive calculations. Parametric modeling is widely used in architecture, construction, and engineering for precisely this reason. The streamlined, abstracted approach allows easy modeling of complex geometries, controlling complex computations at an abstracted layer.
Tools and agency
We advocate for broad, exploratory tools because the design process is inherently iterative and requires discovery. Automation, by contrast, is typically narrow, working towards known solutions. Artificial intelligence will reduce much of the menial work currently performed by designers, and beyond that, image generation models are already more than automators, akin to active co-designers. The capabilities of large models are increasing across domains and will likely continue to expand in the future. For design research, engaging with these technologies beyond their automation potential is critical in understanding how human designers can retain agency when wielding such intelligent, powerful tools.
Already, working with these models risks diminishing the designer’s own intent and ideas, and learned context can drown out or skew instructions or inputs from the designer. The model’s ability to ‘fill in the gaps’ of provided constraints—a useful characteristic in most contexts—can become overwhelming in the design process, leading to decisions that were once made with explicit design intent being automated into generic, average solutions.
It is crucial to develop tools that emphasize the design process, allow users to make mistakes, backtrack, iterate, and experiment. This is the opposite of rigid automation and central to the act of designing. Keeping tools broad and open-ended allows designers to explore and discover their most effective applications individually. Parametric representations empower users to iteratively refine and modify models, making them a natural fit for the dynamic and exploratory nature of design work.
Implementation
We have outlined four principles for designing LLM-based AI systems as exploratory design tools: maximizing affordances and maintaining generality, employing flexible reasoning models, utilizing lean symbolic representations, and supporting non-linear design processes. This section details the implementation of these principles in our prototyped system, including model configuration, prompting methodology, context provision, goal definition, and structured output generation. The flow of our system is detailed in Image 1. This diagram outlines the flow of our System: The user query is sent to the model alongside the system prompt, the o1 model computes a json result which is then parsed into the users canvas through the plugin in Grasshopper.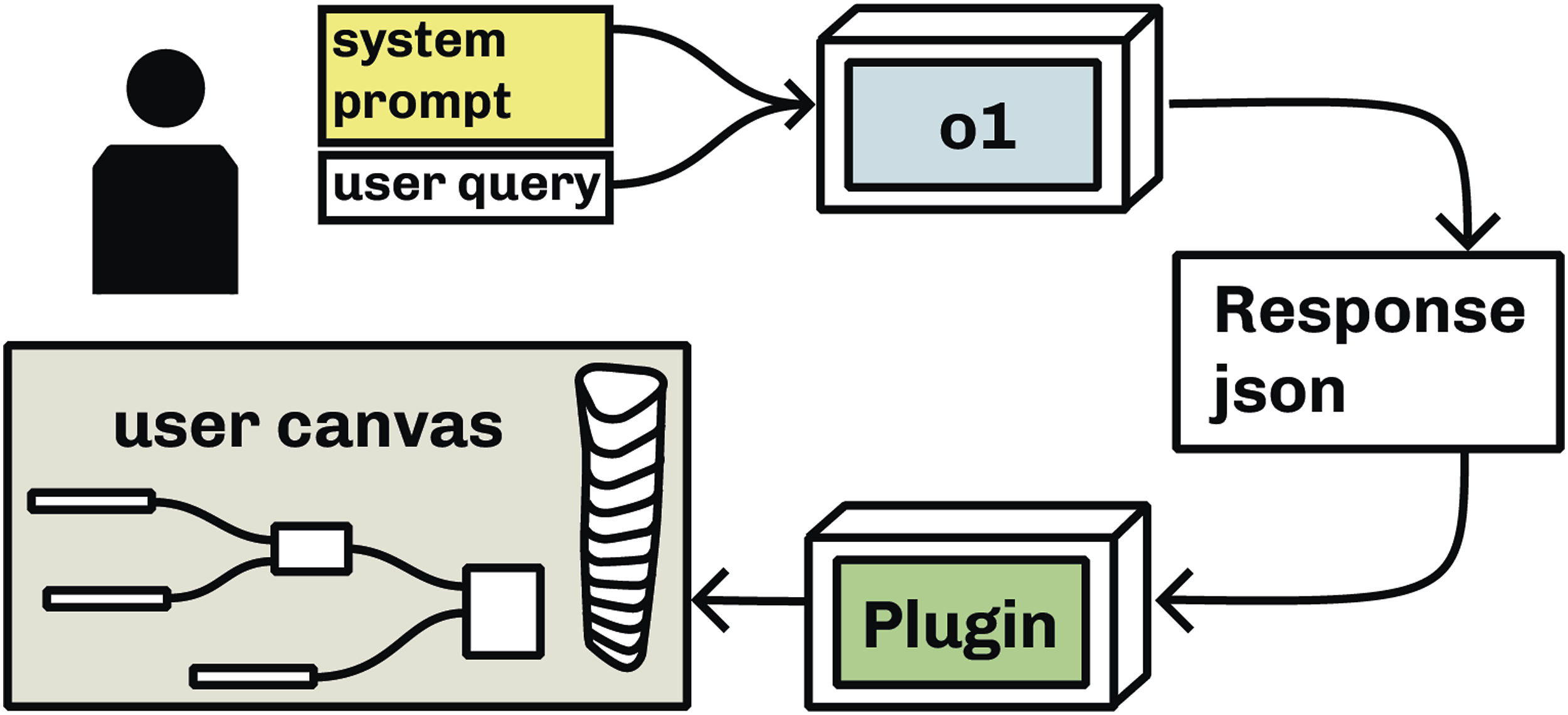
Model configuration
To ensure flexibility and broad affordances, the system is designed to generate Grasshopper definitions from diverse user inputs of varying complexity. We employ OpenAI’s o1 model, accessed via the OpenAI API, due to its multimodal capabilities, structured response enforcement, and variability in reasoning effort.
The model is configured with high reasoning effort to enhance logical coherence and adaptability. Its output adheres to a predefined JSON schema (see Online Appendix), which is enforced at inference time by the OpenAI API. This ensures structured, reliable responses, significantly improving on prior Grasshopper script generation approaches such as the original GHPT.
Prompting
Our prompting follows the outlined principles, establishing clear constraints while maintaining flexibility where useful. The prompt is structured into key sections: system goal definition, response format, warnings, and a comprehensive component list.
System goal
This section defines the purpose of the system—to generate Grasshopper script logic—and describes how it is represented as a structured list of components and connections. It introduces component roles, distinguishing between inputs and operations, and explicitly states the system constraints, including adherence to standard CAD operations and Euclidean geometry. The model is instructed to construct logic that “maps from useful input parameters through components to the final output,” ensuring it follows the logic of Grasshopper scripting without rigidly prescribing task decomposition.
Response format specification
The model’s output is structured according to a predefined JSON schema, enforced during inference. This schema consists of: • A textual summary to communicate results to the user. • A list of Grasshopper components, including IDs, names, values, and an automatically generated “nickname” field to facilitate readability. • A list of connections, detailing originating and receiving component IDs and their corresponding parameter names.
Explicitly defining this format within the prompt directs the model towards structured and interpretable responses.
Component reference list
A detailed list of Grasshopper components is appended to the prompt, these are the symbolic elements for constructing responses. Each component is listed alongside its input and output parameter names, guiding the model to construct compatible connections. Instead of explicitly specifying all data types, the list describes each component’s function, striking a balance between conciseness and informativeness.
Given the tradeoff between prompt length and clarity, we selected only essential components while ensuring their input and output names remain clear (see Online Appendix). This prevents overwhelming the model with unnecessary information while ensuring it has access to a robust set of tools for varied design tasks.
Parsing to grasshopper
The parsing logic is built upon the open-source GHPT project, which utilizes the Grasshopper SDK to instantiate components and establish connections based on the provided JSON structure. The system iterates through the component list, placing elements on the Grasshopper canvas, and subsequently applies the specified connections.
This system aligns with our principles: it avoids excessively guiding the model, and instead maintains generality with open-ended prompting, leverages flexible reasoning models, and ensures a lightweight, symbolic approach to computational design scripting. Errors in the Grasshopper logic are easily mitigated by the user, and the output format is easy to iterate and append to. The result is a flexible and interactive tool capable of supporting exploratory design workflows within Grasshopper.
Results
This section presents the results of our system and compares its performance with existing state-of-the-art generative CAD systems. We evaluate the system’s outputs against our outlined principles and assess its effectiveness in generating computational geometry. To provide a comparative perspective, we contrast our system’s results with two commercially available text-to-geometry systems. The selected prompts showcase the system’s generality, ability to handle algorithmic geometry, and overall adaptability.
All results were generated through an API call using the previously outlined prompt structure provided in the Online Appendix. The raw API responses were then processed using the GHPT logic, which instantiates the generated scripts on the user’s Grasshopper canvas.
Our system
Text-based generation
The API response in json format to the query ‘A Double Howe Roof Truss.’ This response format is enforced for each API reply through the json schema functionality of the OpenAI API.
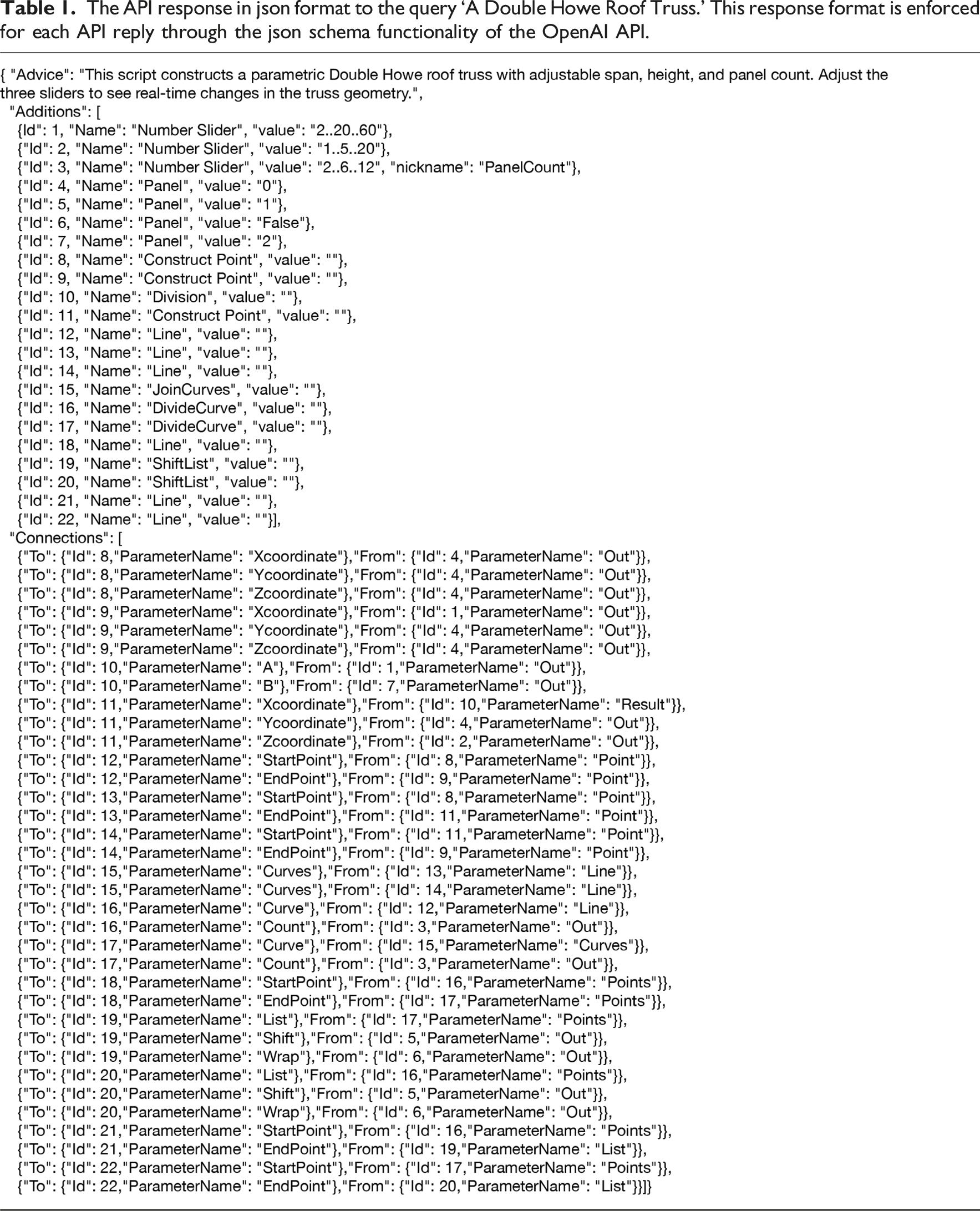
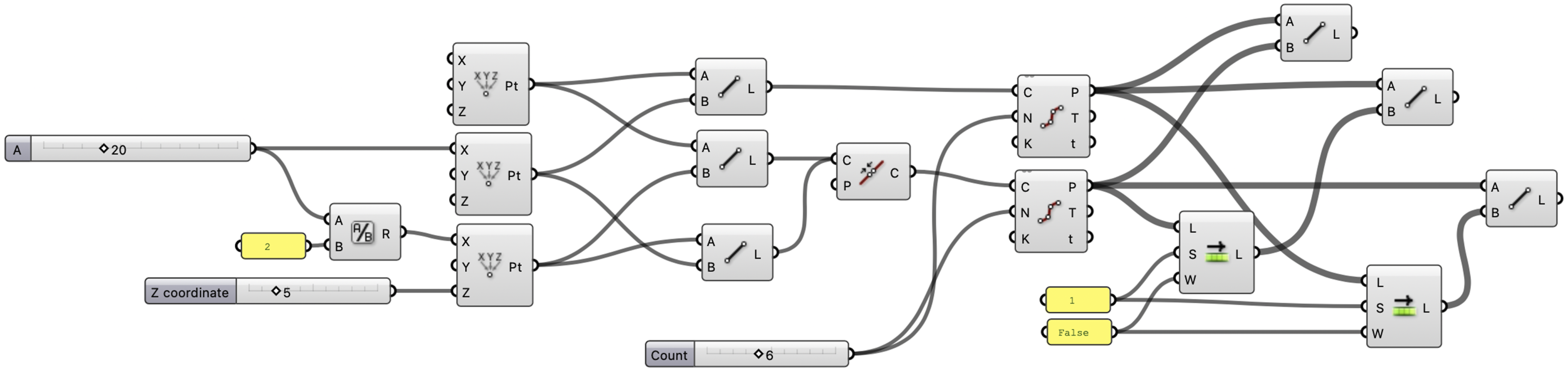
This Grasshopper script is the direct result of parsing the Json response from Table 1 through the Grasshopper plugin to the users canvas.
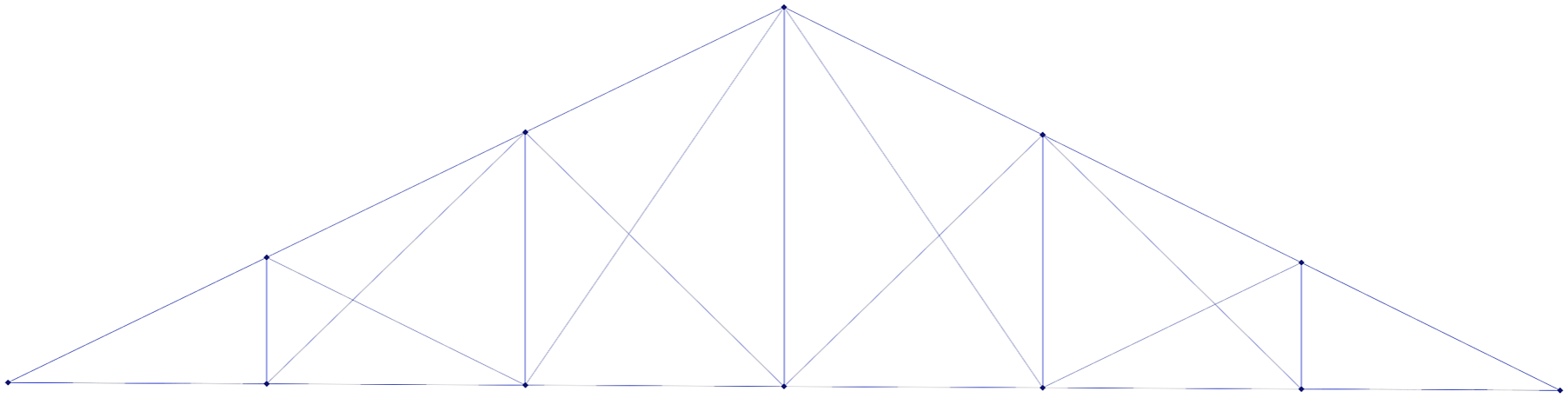
This image shows the Grasshopper render preview of the “A Double Howe Roof Truss” script as generated by our system.
The Double Howe roof truss model successfully reconstructs the essential structural elements of the truss: the model shows a solid understanding of its underlying geometric logic. However, the output includes additional cross-bracing elements not present in a standard Double Howe truss. While the system accurately captures the core design principles, it introduces unexpected variations or additions.
The Golden Gate Bridge model (Image 4) successfully incorporates the primary catenary cables and support towers, but with notable simplifications. The two towers are represented as rectangular volumes rather than H-shaped structures, and the roadway is depicted as a single line with no width. While the script maintains the correct suspension logic, the output is a highly reduced abstraction of the geometry described in the prompt. The geometry preview of the result for the prompt “a parametric model of the golden gate bridge, including its two double-H towers, the two catenary cables that run from the start of the bridge to each tower and then to its end, and the suspender cables” constructed by our system.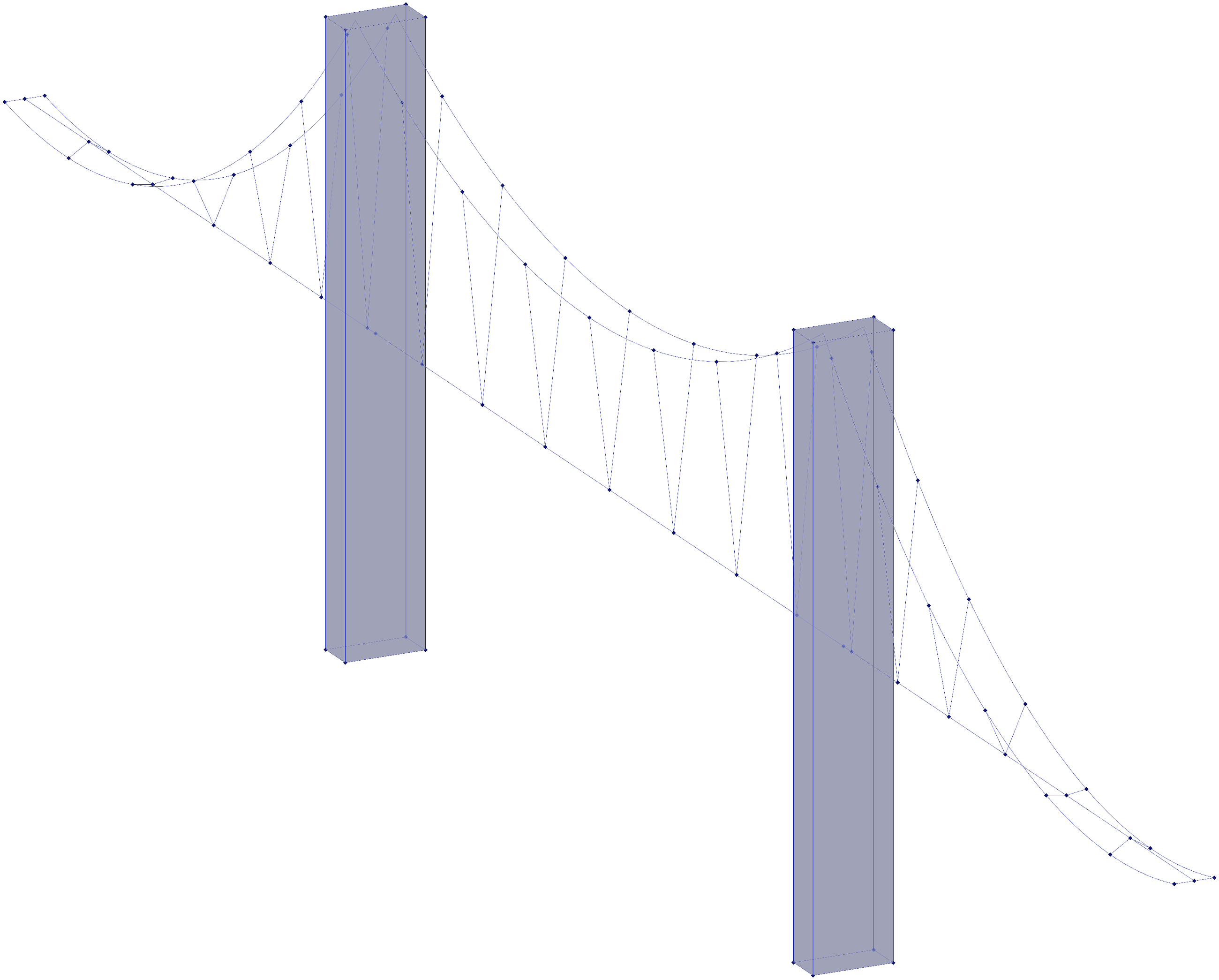
In contrast to the previous two results, the script generated for the “Sydney Opera House”(Image 5) prompt failed to produce a recognizable architectural form. The output contains wedge-like structures arranged in a circular pattern, suggesting that the system attempted to construct the curved shell elements but struggled with their placement and orientation in 3D space. This result highlights a common limitation: the system encounters challenges in handling shape and logic that do not have a single, linear direction, and struggles with complex orientations in coordinate space. The render result for the prompt “the wedged roof of For Peer Review the sydney opera house” clearly shows issues wiht orientation in 3D space.
The Framed Timber Wall script (Image 6) is a geometry with a clear linear directionality, and successfully generates a logically structured parametric frame. The Facade with Dynamic Shading script (Image 7) has misalignment in rotation axes. While the script attempts to create dynamic shading panels, the panels rotate in the YZ plane instead of the XY plane, and result in an interlocking pattern rather than the intended shading effect. Similarly, in the Parametric Brick Wall script, the bricks do not follow the expected orientation, and the script only produces the first layers of bricks (see Image 8). The system successfully captures essential geometric principles outlined in the queries, but it tends to limit the complexity of its solutions, often failing to combine all elements from a query within a single model. The result for “a parametric model of the golden gate bridge, including its two double-H towers, the two catenary cables that run from the start of the bridge to each tower and then to its end, and the suspender cables” shows the systems success in producing clearly oriented, directional geometry along one main axis. The prompt “a facade with dynamic shading panels” output has panels that are cleary rotating in an unintended direction, interlocking instead of shading. “A brick wall flowing along a sine curve” produced a script which orients the bricks vertically and fails to build the multiple layers of a wall, but does follow a sine curve.
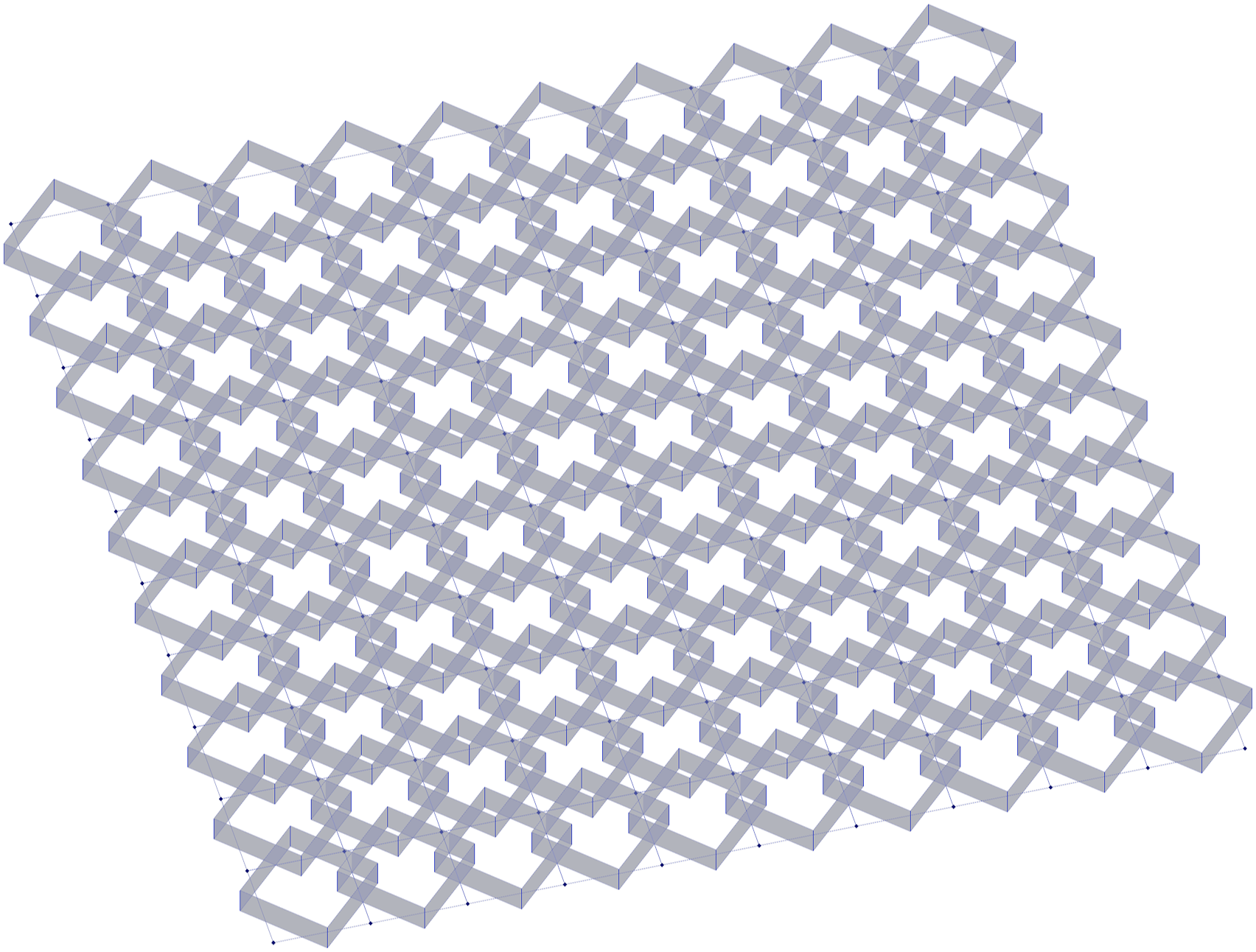
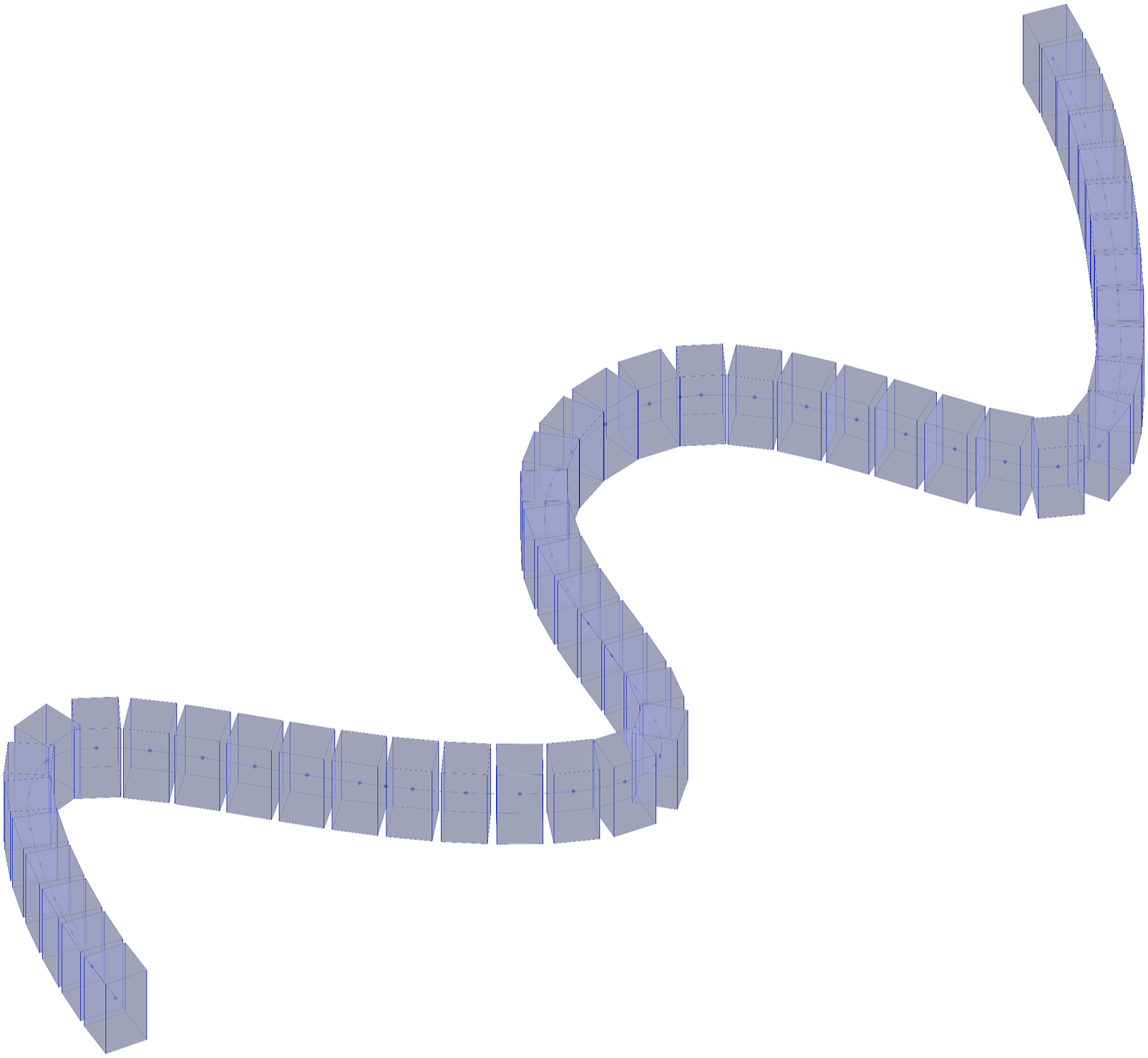
Image-based generation
The following results were obtained using image inputs, processed through the OpenAI API by encoding images in Base64. The system interprets the structure from the provided image, constructs relevant geometric logic, and generates a script to approximate the depicted form.
Our results indicate that the system tends to generate abstracted and simplified versions of the original images. While key geometric principles are retained, finer architectural details are often omitted.
For instance, in the Ribbed Vault (Image 9) example, the system successfully reconstructs the primary vault structure, including the domed geometry and overarching roof beams. But significant features such as pointed arches and intermediary vault ribs are absent. Additionally, the scripted geometry extends beyond the expected floor level, pointing to limitations to anticipate and constrain spatial boundaries. Despite this, the generated script maintains a recognizable vaulted structure, albeit in a simplified form. This image was the input to our system to create the rib vault logic seen on the right. No additional text prompts are necessary, and the system clearly succeeds in translating relevant characteristics from the image to the script output.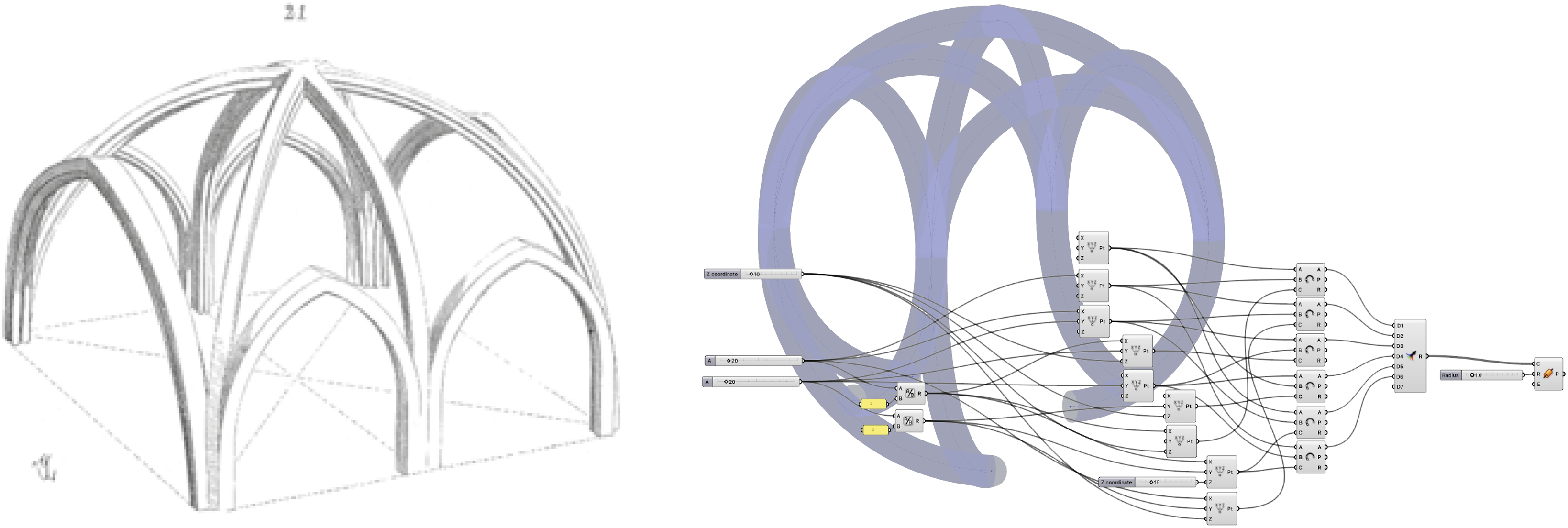
In the case of the Zaha Hadid Building (Image 10) input, the system demonstrates a more conceptual approach. Rather than attempting a faithful reconstruction of the building’s geometry, the model extracts a dominant geometric theme—an extruded wave-like pattern—and reproduces it with its script. This result clearly shows the model’s multimodal reasoning process: instead of replicating precise architectural features, it picks a design motif or concept and translates it via language reasoning to a script. This building photograph was the input to our system which resulted in the extruded curve script. While the building itself was clearly not recreated, the concept of a slender curve is transported to the output script.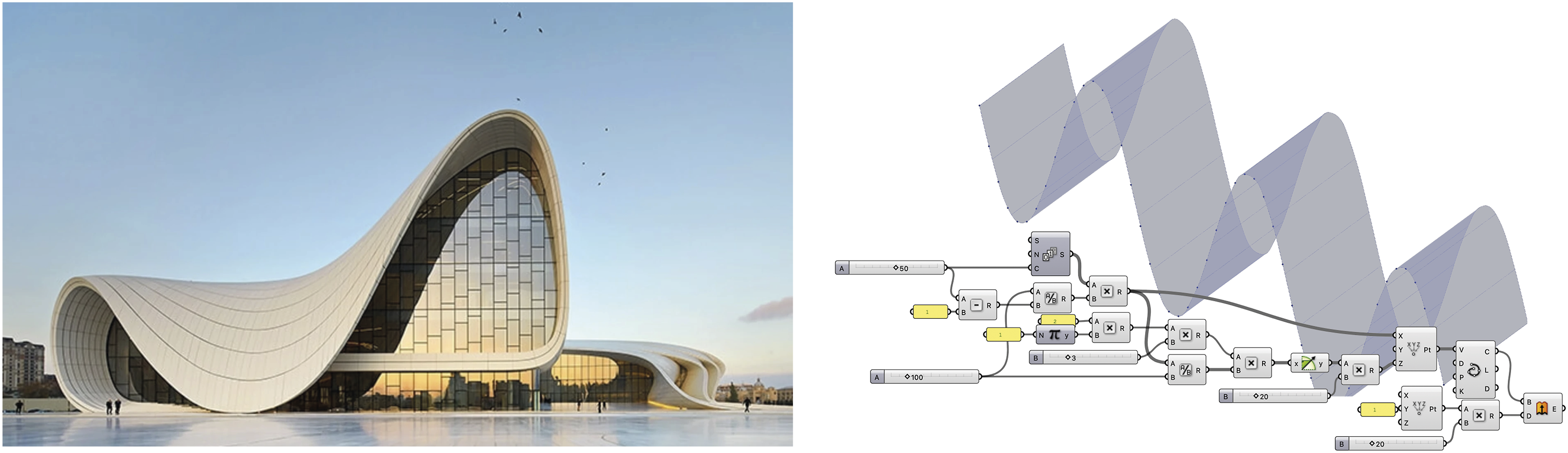
The Shanghai Tower (Image 11) input produces a more successful integration of geometric elements. The reference image provided to the system includes multiple views—perspective, section, and plan—clearly articulating the building’s twisting, sloping form and triangular base. The system effectively constructs a coherent geometry from these distinct elements, generating a Grasshopper script that correctly applies a twisted extrusion logic to approximate the tower’s shape. This result highlights the advantage of structured, information-rich image inputs, where geometric relationships are explicitly presented rather than shown implicitly through photography. The schematic to the left includes detailed, multi view drawings for the Shanghai Tower, and the system successfully combines these for his model of the parametric, twisting tower.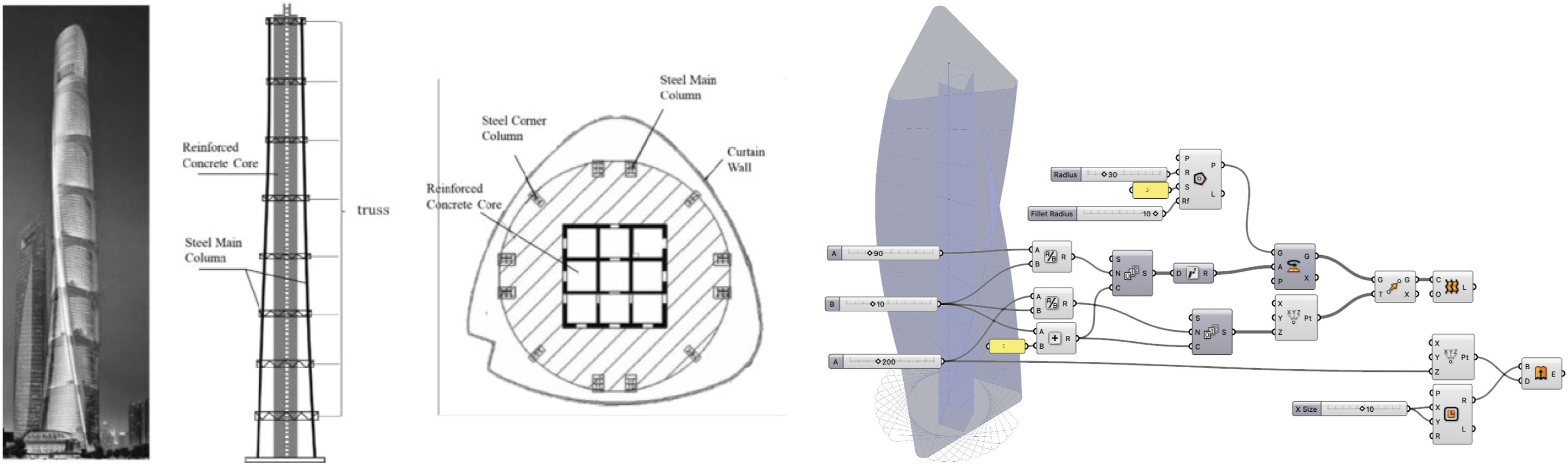
Comparisons to other CAD AI approaches
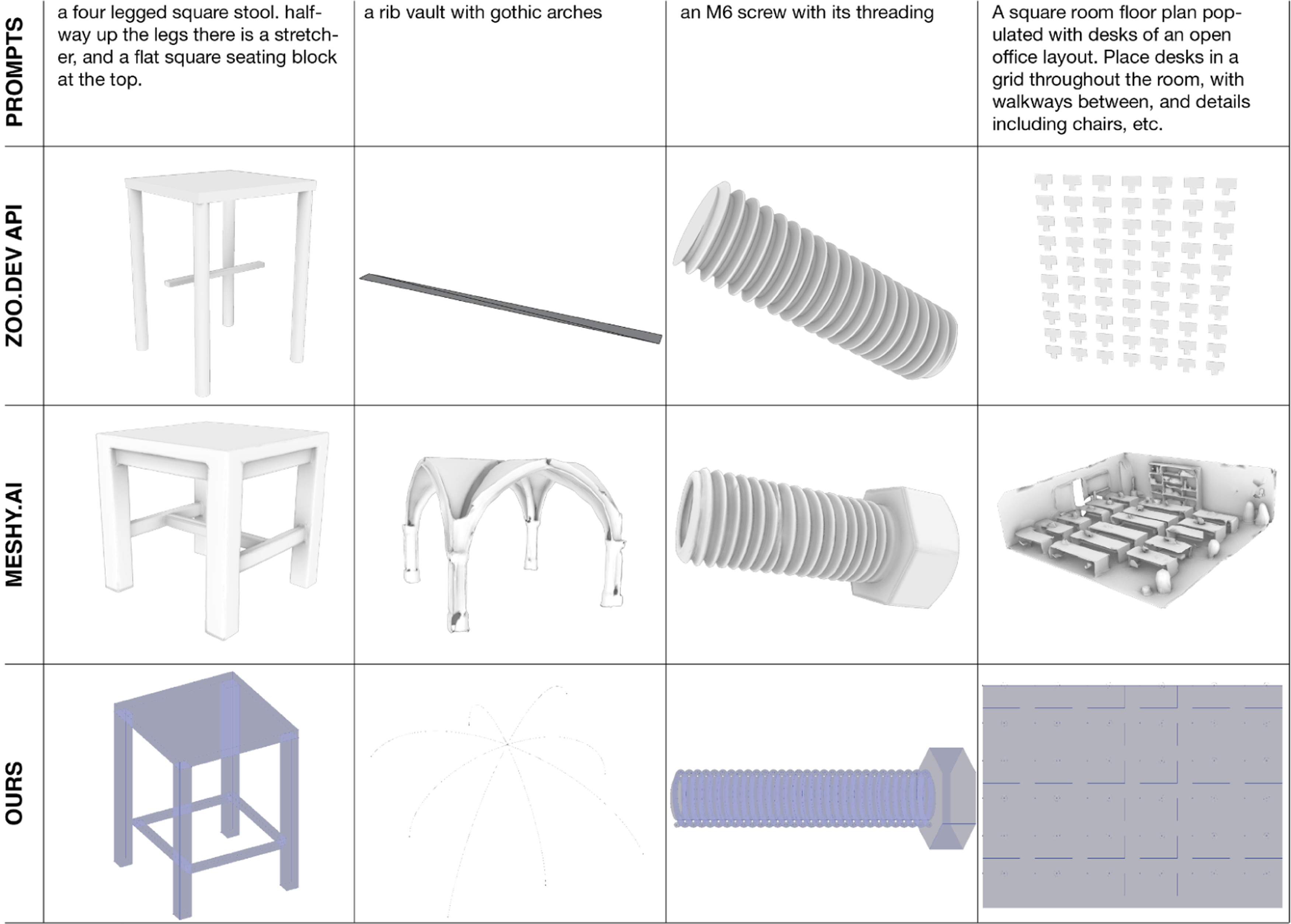
Comparison of four text-based prompts and their resulting 3D models generated using three distinct AI-driven CAD approaches: programmatic CAD (Zoo.dev API), mesh diffusion (Meshy.ai), and our proposed system.
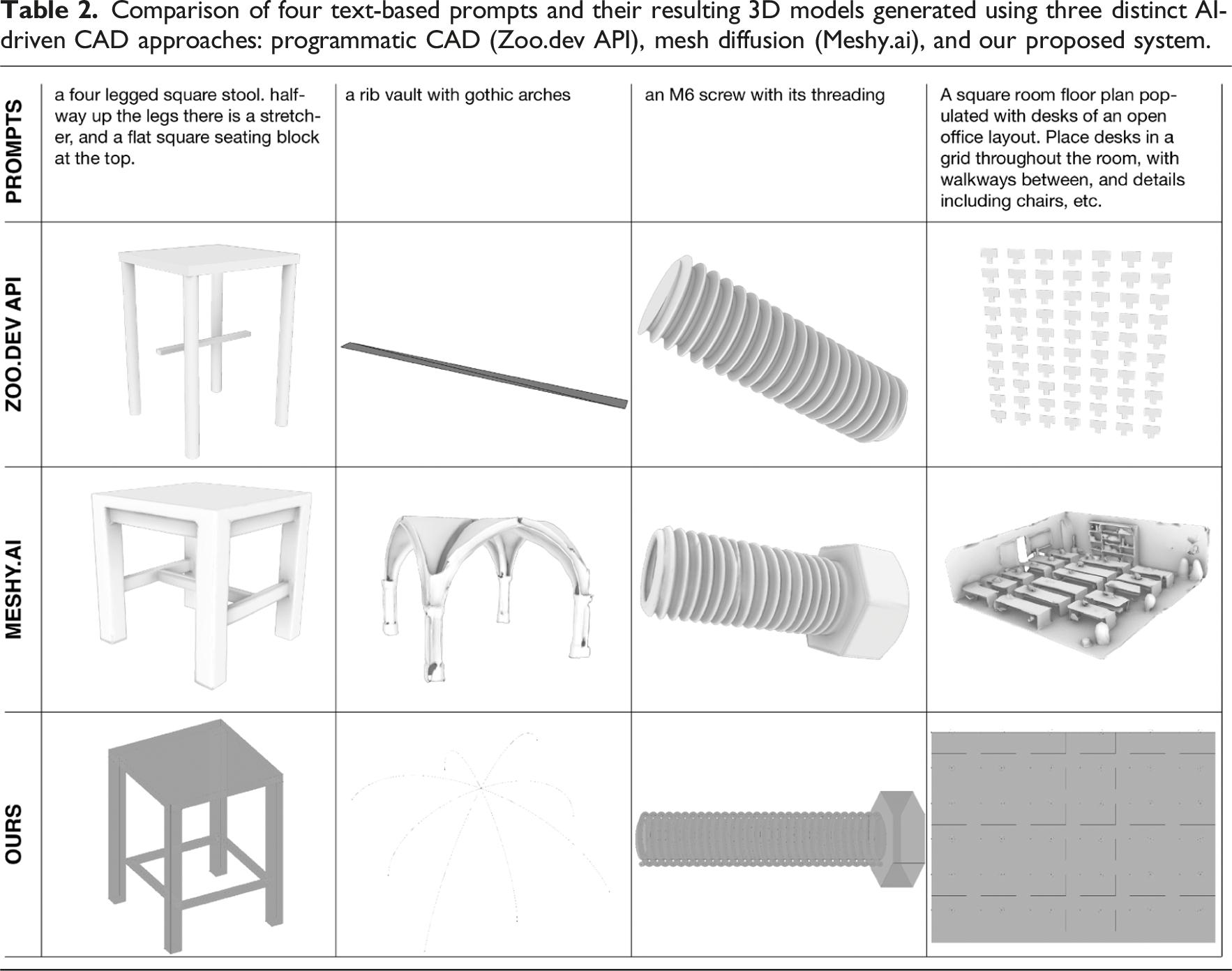
Programmatic CAD – Zoo.dev
Programmatic CAD generation directs large language models to produce executable programming code that defines a geometric structure. Zoo.dev’s text-to-CAD API, which employs the proprietary KittyCAD scripting language, generates precise and parameterized models, much like our system’s use of Grasshopper components.
When tasked with generating structured geometries such as helices or regular desk distributions in a floor plan, both Zoo.dev and our system perform well. Challenges emerge when dealing with less explicitly defined shapes, such as arched vaults, where spatial planning is more complex. Because the system constructs an executable program, unexpected and loosely defined structures like the vault can result in missing geometries or errors in the generated code.
Language models also struggle with spatial planning. For instance, in generating a stool model, Zoo.dev correctly produces a stretcher element between the legs but fails to accurately attach it to the structure—it floats independently in space. These limitations highlight the challenges inherent to abstracted symbolic CAD generation, where it becomes difficult for the model to anticipate the resulting geometries and their spatial relationships.
Mesh generation – Meshy.ai
Meshy.ai, a mesh diffusion-based model, excels in generating high-resolution, visually realistic 3D models, particularly for applications in game design and animation. Trained primarily on extensive datasets from these industries, it demonstrates a strong understanding of form, allowing it to generate complex structures such as gothic vaults with high fidelity.
However, when prompted to generate a floor plan—an uncommon request for a mesh-based system—Meshy.ai misinterpreted the task and instead produced a complete office interior, as it is geared to produce objects rather than structured architectural logic. This reflects a fundamental limitation of diffusion-based models in computational design: they prioritize visual representation over geometric reasoning or precise dimensions.
A significant drawback of mesh-based AI generation in architectural workflows is the rigid nature of its output. Unlike parametric or script-based systems, Meshy.ai does not allow for direct modification of design logic post-generation. Users are limited to editing the final mesh using external software, as the underlying generative process is inaccessible. In the case of the generated screw, users cannot easily adjust its length or thread parameters without manual rework. Similarly, while the gothic vault generated by Meshy.ai visually resembles historical examples, it is a faulty and incomplete model and would require extensive reprocessing to become usable.
Reasoning models – comparison to previous publication
Our system builds upon the prior research outlined in (previous publication, anonymized), replacing rigid task decomposition with dynamic reasoning models. This shift significantly improves performance in computational design tasks, particularly in the complexity of generated scripts and avoiding mismatches of components.
By directly comparing results using the same prompts from (previous publication), we observe a clear improvement in geometric accuracy and logical coherence. Prompted to generate a simple suspension bridge (Image 12), both (previous publication) and our system produced relatively simple outputs. However, our system demonstrated a much clearer structural logic, correctly implementing a catenary curve with suspension cables connecting to a horizontal roadway. The (previous publication) result, by contrast, lacked a distinct suspension logic, and created an ambiguous structure. The upper bridge model is the result of the current system which employs reasoning models, while the lower bridge is the result from our previous work with hard coded problem dissection.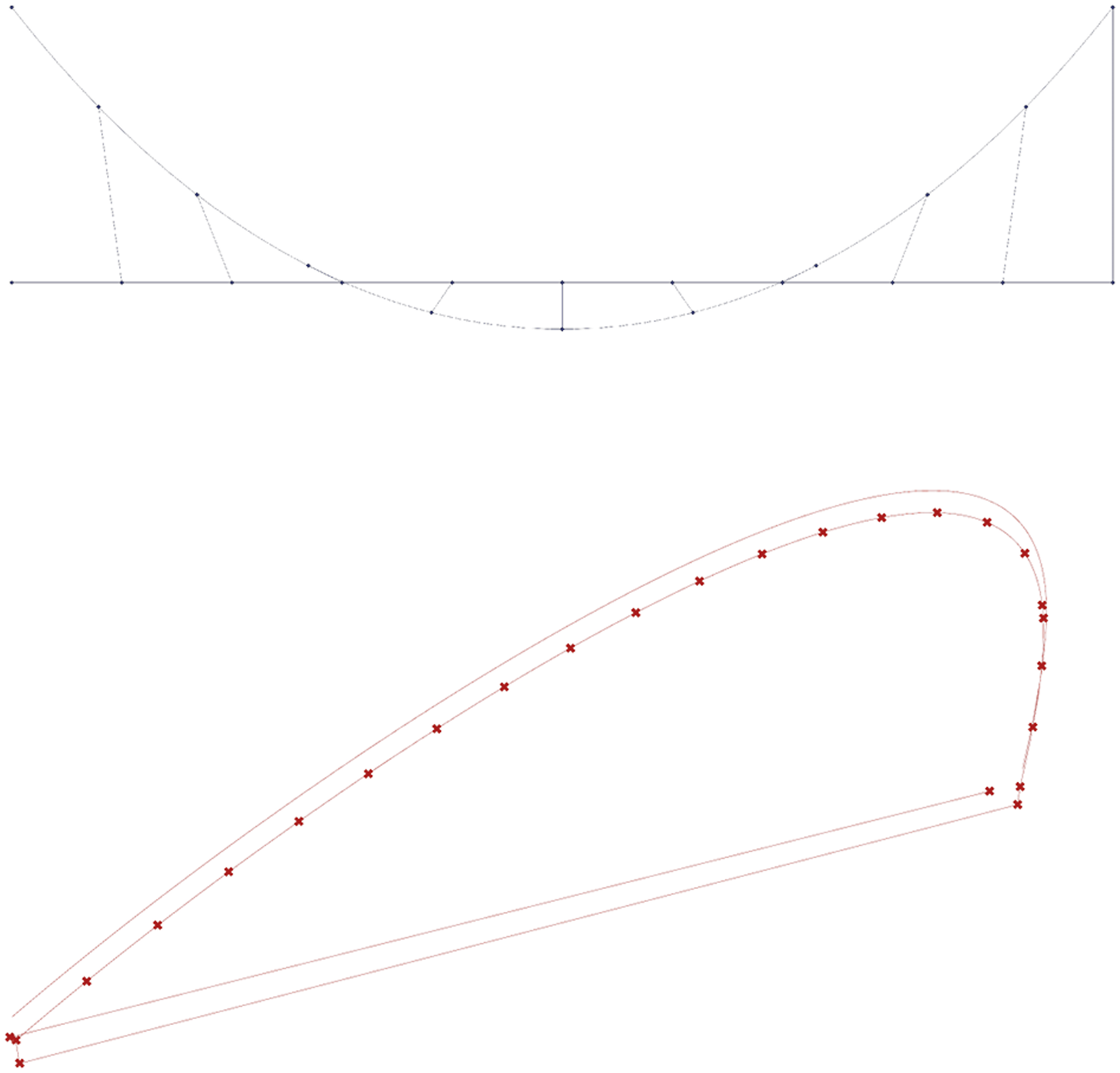
The ability of reasoning models to expend more computation during inference time directly translates to more robust geometric reasoning. Comparison for the query an umbrella (Image 13) clearly shows the sound construction logic of the new system, where the previous one failed in the final assembly steps. In the Mediating Modes of Thought system, the generated canopy was incorrectly placed due to logical errors—specifically, it connected an incorrect data type, mapping a numerical value where a vector input was required. Our system, by contrast, achieves higher accuracy in combining components, ensuring compatibility and avoiding such failures. The improved handling of parametric constraints demonstrates how reasoning models enhance computational design workflows, making them significantly more reliable for generative CAD applications. The model on the left is the result of the previous system, and clearly fails to place the canopy at an appropriate position, while the result of the new system on the right succeeds.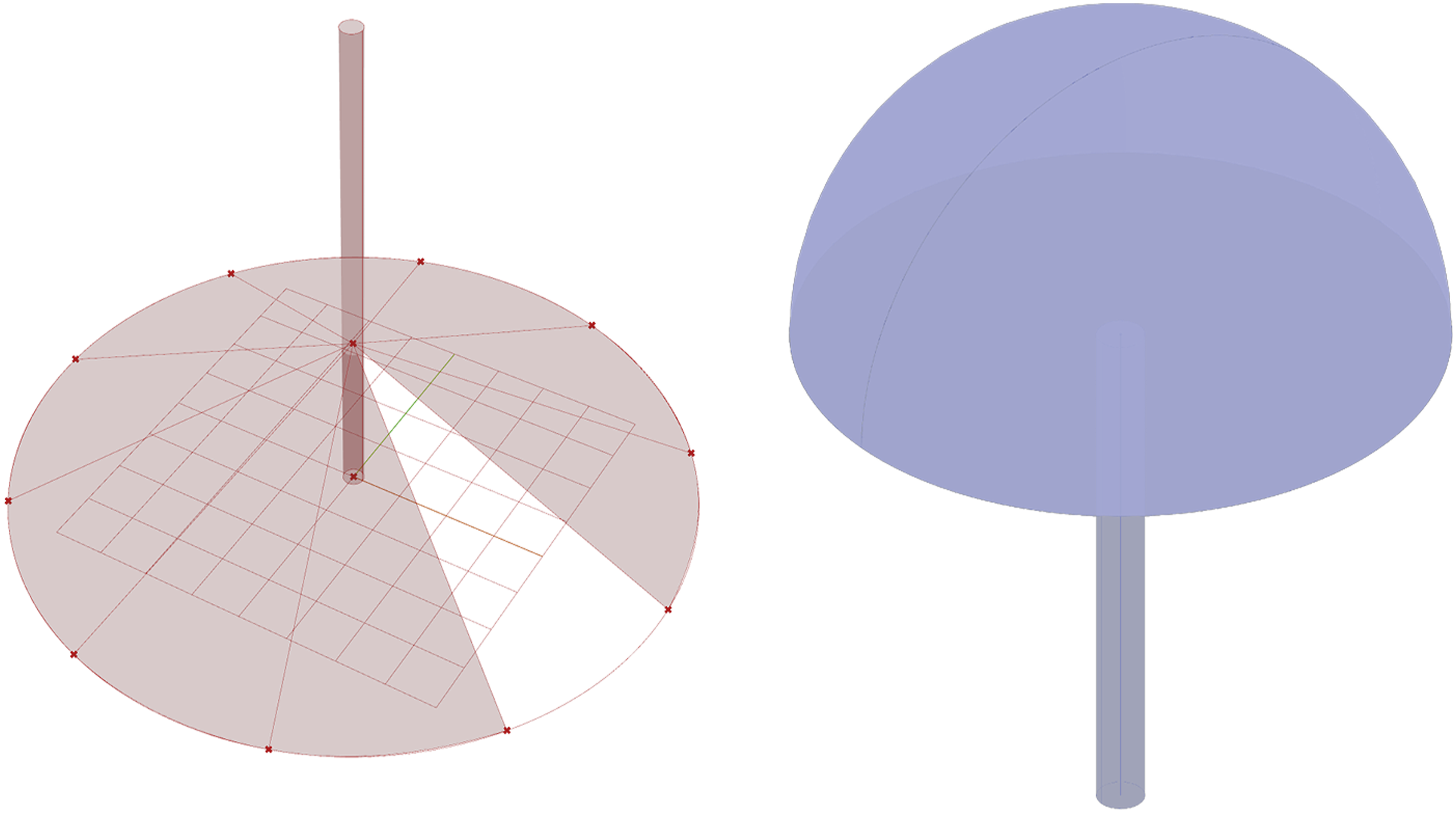
Summary of comparisons
Each AI-driven CAD approach presents unique advantages and constraints. Programmatic CAD (Zoo.dev) offers precision and editability but struggles with spatial placing and non mechanical queries. Mesh Diffusion (Meshy.ai) generates highly detailed and visually compelling models but lacks editability and logical structure, making it less suitable for architecture. Our system dynamically adapts to task complexity, producing robust and editable Grasshopper scripts while maintaining flexibility across diverse design scenarios. While mesh diffusion models cater to aesthetic-driven applications, parametric CAD scripting provides structured, modifiable outputs ideal for iterative architectural workflows.
Conclusions
We outlined three principles for creating tools with large language models in design research and demonstrated their application through a system that generates parametric design scripts using reasoning models. Our system was compared to state-of-the-art AI-driven CAD approaches, revealing how reasoning models enable flexible and interpretable design tools rather than rigid automation.
Creativity tools
Large models are most useful as creative tools when they prioritize exploration over automation. Designing is an iterative and contextual process, where solutions are found alongside evolving problems. Automation is suited to known, repeatable tasks, but exploratory tools must allow for ambiguity and discovery.
Perfect task adherence is neither possible nor desirable in design tools that employ large models. These models excel in generalization and inference, but their ability to fill in gaps can lead to undesired outputs if not properly constrained. The balance between interpretability and constraint is critical in designing AI-driven tools for computational design.
Large multimodal models encode knowledge across different data types, enabling a collapse of modalities into a shared embedding space. This shift means the most effective interactions with these models focus on essential abstractions rather than rigidly structured data. Architectural design relies on distilling complex information into plans and models, and AI tools benefit from similarly abstracted representations. Textual interfaces, rather than direct image-to-image processes, enable reasoning models to navigate the conceptual space of design rather than merely reproducing visual patterns.
Symbolic systems, such as parametric design scripting, allow designers to intervene in the generative process rather than passively receiving completed outputs. The ability to modify, iterate, and correct results is crucial for design workflows, making symbolic approaches preferable to opaque generative methods.
Latent space surfing
As first suggested in(previous publication), large models act as intermediaries between different modes of thought in the design process. Their broad knowledge and reasoning capabilities make them powerful exploratory tools to construct geometric logic from sketches or prompts. Maintaining generality in large models enables designers to engage with both specific task contexts and the vast encoded knowledge of the model, creating opportunities for novel interactions and emergent discoveries. Images and text descriptions given to the model are interpreted by its data trained eye, and the output will be an explicit interaction between the provided and learned data. Architects and designers work with context, either implicitly or explicitly. Large models externalize this context, making interactions with internet-scale data explicit, and enabling designers to surf and iterate through these interactions. This remains difficult to intuitively grasp but enables new forms of computational exploration.
Limitations and future work
While our system demonstrates promising capabilities, it also presents several limitations. One significant challenge is its struggle with complex hierarchical reasoning and highly interdependent components. Although it successfully generates structured Grasshopper scripts, performance deteriorates as task complexity increases. Additionally, the computational demands of reasoning models result in high inference costs and response latency, limiting real-time usability in interactive workflows.
The system also lacks iterative interaction, preventing users from refining outputs dynamically. Implementing conversational feedback loops could improve usability and allow designers to guide generative outcomes more effectively. Furthermore, the absence of empirical user studies limits our understanding of how these tools impact creative workflows. Future research should examine expressivity, usability, and the effectiveness of reasoning models in supporting design exploration.
Another limitation is the monolithic nature of our task modeling. The system currently processes each design script as a monolithic task, which restricts the possible complexity. A more modular approach, subdividing tasks into interconnected subgraphs, could enhance its capacity to handle complex models. Additionally, the token-based sequential nature of language models inherently processes linearly even through non-linear graph structures. Finally, our system primarily focuses on algorithmic design, which represents only a subset of broader architectural workflows. Future work should extend these methodologies to other phases of design practice.
Addressing these challenges will require several key developments. Conducting user studies will provide insights into the system’s effectiveness in real-world scenarios. Modularizing task decomposition can improve efficiency, allowing the model to generate and assemble subcomponents dynamically. Exploring alternative system architectures, such as integrating Graph Neural Networks alongside large language models, could enable explicit representation of graph-based logic. Additionally, incorporating interactive, iterative interfaces will allow designers to refine outputs in real time, enhancing both control and expressivity.
By advancing in these directions, AI-driven design tools can move beyond rigid automation systems, evolving into adaptive and expressive tools that meaningfully augment creative workflows.
Supplemental Material
Supplemental Material - Intelligent tools on the loose: Reasoning models for exploratory computational design
Supplemental Material for Intelligent tools on the loose: Reasoning models for exploratory computational design by Moritz Rietschel and Kyle Steinfeld in International Journal of Architectural Computing

Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.