
Abstract
Understanding the importance of data is crucial for realizing the full potential of AI in architectural design. Satellite images are extremely numerous, continuous, high resolution, and accessible, allowing nuanced experimentation through dataset curation. Combining deep learning with remote-sensing technologies, this study poses the following questions. Do newly available datasets uncover ideas about the city previously hidden because urban theory is predominantly Eurocentric? Do extensive and continuous datasets promise a more refined examination of datasets’ effects on outcomes? Generative adversarial networks can endlessly generate new designs based on a curated dataset, but architectural evaluation has been questionable. We employ quantitative and qualitative assessment metrics to investigate human collaboration with AI, producing results that contribute to understanding AI-based urban design models and the significance of dataset curation.

Keywords
Introduction
Currently, more than half of the world’s population lives in cities. By 2050, it is expected that two-thirds of the world’s population will be urban dwellers, making urbanization a huge challenge.1,2 The impact of rapid urban development on land use and climate change and changes in surrounding rural areas are central issues, forcing us to face how differently we will have to think, conceptualize, and design our urban habitations. 3 This also challenges our methods, which rely on modernist approaches that developed during industrialization and require an understanding of the city that no longer locates it in a single site but takes into account all the sites scattered across the world that are implicated in its creation. 4 Therefore, we must understand the city within a complex network condition and understand what it means to intervene in a planetary-scale structure that describes our modern world—the city as a distributed object. How can these complex planetary networks be pictured in a way that does not generalize or flatten them, or in a way that attends to the hyper-local while keeping larger geopolitical and Earth systems in view?
Remote sensing technologies now enable us to survey urban landscapes and map their changing conditions across vast areas and time scales with great precision. Observations from the ground or airplanes cannot create such precise and continuous records of the entire earth’s surface over the period of four decades. 5 Thus, never have we had so much continuously generated data about urban developments on a planetary scale, data that are beyond the limits of our senses let alone the human capacity to process them. This raises the following question: Can we develop a completely new understanding of the city by coupling these planetary datasets with AI technology? When Benjamin Bratton states that knowledge about climate change is an epistemological achievement of planetary-scale computation, 6 further questions arise: Can we do the same for the complex interlocking systems of urbanization? How can human and AI be combined to create a collective architectural mind capable of hybridizing artificial and natural environments, various urban structures across different geographical areas, and climatic zones to explore new ways of generating, inhabiting, and preserving cityscapes?
Until recently, the majority of research on urban form and morphology has been limited to a small number of observations (datasets based on a single city and urban models that had been produced within a Western knowledge system and exported all-over the globe); however, global availability of massive urban data opens new avenues for studying the city and its hinterlands. Now, through the continuous data produced by remote sensing technology we have unprecedented ability to include historically underrepresented urban precedents and areas around the globe in order to promote data-justice in AI-aided urban planning. Thus, we consider the constantly increasing urban and cartographic data, which flows around us daily, to be a complex cultural entity with collective, institutional, individual, and artificial memories for imagining a different dimension of urbanization. We use this ubiquitous visual data and transform it into urban speculations that represent our collective planetary sapience of cities, which far exceeds a Western canon of urban design references/history as well as the narrow city. Such data also consider the wide array of local and global landscapes that condition and are conditioned by what we call the city. The central approach is to use deep learning (DL) methods and remote sensing to reveal, on the one hand, our limited perspective on the city and its landscapes and, on the other hand, our truncated view of complex systems.
Satellite imagery also offers an interesting aspect in terms of data justice, as it is in line with Mariana Mazzucato’s argument. The economist argues that public ownership of technological innovation is crucial for driving economic growth and promoting innovation that benefits society as a whole. She contends that governments should play an active role in shaping the direction of technological change and ensuring that the benefits of innovation are shared equitably.7,8
This study explores the nature of possible new urban environments and observes a machine’s creation of an unknown city by including data from geographical and climatic regions or cultural backgrounds that have been excluded, left out, or disadvantaged in and around urban design. The premise is, therefore, fairly straightforward: any of the cities on the planet represent only a fraction of the conceivable and imaginable urban environments. DL makes it possible to begin visualizing and synthesizing the diversity and complexity of urban creation that exists latently in the global urban fabric and that has been materialized over centuries.
The study contributes to understanding generative adversarial networks (GANs) in urban design by examining GAN models (deep convolutional generative adversarial networks [DCGAN] and StyleGAN) for creating new urban designs and suggesting a design workflow that merges machine and human intelligence. In doing so, the research emphasizes the importance of the dataset curation within the context of DL design methodologies.
State of the art
Overview of GANs
Interest in GANs and growth in their use as DL algorithms for generative and analytical tasks have increased rapidly. Image-based datasets are still the most common form of samples used to train GANs. Unlike architectural datasets, satellite images of urban areas and their conditioning landscapes are available in vast quantities with continuity, high resolution, precision, and unlimited access. Surprisingly, this enormous, openly accessible dataset has not yet been extensively exploited for architectural and urban design speculation (with a few exceptions). For the most part, other disciplines have successfully used these data, combined with GANs, to augment original data as prediction models or to generate more accurate maps from real-time satellite imagery. Satellite image datasets and GANs contribute broadly to scientific and interdisciplinary research, including predicting coastal flooding during hurricanes to develop global visualization tools for climate impacts. 9 Other approaches focus on automatically generating digital maps and segmented layers from satellite imagery 10 to detect objects, 11 classify land use and land cover in satellite images, 12 or predict food production through remote sensing technology. 13
GANs in urban design and architecture
In the field of architecture, where image datasets are also still the dominant sample form for GANs, remote sensing technology offers tremendous benefits as it provides an enormous amount of accessible and open-source data for conducting research with DL. Regarding GANs and satellite imagery as it is used in architecture and, most notably, urban design, extant research has focused primarily on the reconstructions of existing conditions or predictions of future conditions by working predominantly with paired datasets or mapping data onto a target; they are less frequently employed as a speculative medium. Consequently, few studies have conducted in-depth, qualitative analyses of how machines perceive urban and architectural satellite data.
David Newton used remote-sensing image datasets to analyze the relationship between urban layouts and mental health issues. Whereas GANs are primarily deployed as an analytical tool, Newton employed multiple maps with varying data to crystalize the correlation between mental health and the built environment.14,15 GANs are also disseminated as a generative vehicle for speculative urban fiction, which uses urban satellite images as style images and uses abstract renderings and patterns as target images. These speculative depictions of fictional urban environments, however, ignore the scale and correlation between different datasets and architectural elements. 16 Other studies using satellite images explore the mapping of urban structures onto biological and small-scale growth patterns using CycleGAN, 17 or they explore how to further extract detailed architectural information from satellite images to automate the generation of urban plans, 18 analyzing and generating morphologies of urban contexts, 19 or generating non-planned urban patterns using GANs that inherently promote local practices, traditional knowledge, and cultural sustainability. 20 Additionally, satellite images are combined with GANs to dissect how GANs learn and subsequently generate formal architectural features from urban datasets. 21 While such research contributes to the application of GANs in architecture and urban design, the question remains of how the results can be evaluated from an architectural or urban design perspective.
Methodology
To address the aforementioned research topics, we implemented a methodology that consists of analytical interpretation and a generative process. The generative process includes data collection and curation, GAN training, and comparison of two GAN models (DCGAN and StyleGAN) with the objective of obtaining a collection of visual images with highly diverse urban characteristics. The analytical process entails critical interpretation of GAN imagery using well-established techniques in the field of urban design, such as figure-ground analysis. The qualitative evaluation is followed by a quantitative validation process, which uses convolutional neural networks (CNNs) like feature visualization and depth estimation models. 22 The machine-based interpretation is used to validate the urban design potential by translating 2D-generated GAN images into 3D geometric shapes and comparing them with the qualitative analysis. This workflow was then implemented in a seminar where 33 students generated their own dataset according to their design thesis. This allowed to test very diverse datasets within the same experimental setup and methodological approach.
GANs
23
are an established model to generate (image) data. In principle, GANs represent an unsupervised learning method. Unsupervised learning is a method in which the algorithm independently learns to identify patterns and relationships in data in an exploratory manner. Unsupervised learning deals with unlabeled data; therefore, results might be stochastic and completely unknown. GANs broadly consist of two neural networks: generator and discriminator. The two networks are trained iteratively against each other. During this process, the generator tries to generate a realistic data point while the discriminator learns to distinguish between real and synthetic data points. In this minimax game, the generator improves its performance until the generated data points are indistinguishable from real ones. This means that, in the case of GANs, neural networks are used to analyze and classify data and learn the underlying distribution of a dataset to generate new, realistic sample data. Through their application, it is possible to generate synthetic data samples that have the same statistical properties as the underlying training data. In the following experiments, we deploy two different unsupervised DL algorithms: DCGAN and StyleGAN (Figure 1). The diagram illustrates the relevant aspects of the workflow in GAN-based designs, thereby indicating what is the generative versus the analytic part. Whereas the generative part (b,c) describes a more sequential alternation of human and machine roles, the analytical part (d) is more intertwined. Human-machine collaboration is taken to the next level with continuous feedback from the analysis into the generative part starting with data set adjustment (b). The image shows an extract of the results of formal analysis performed by the participants. Starting with the generated GAN image, the following analyses display; (a) urban organizational structures based on circulation systems; (b) classical figure-ground analysis where all the grey patches are not quite figures or ground; and (c) comparative analysis of artificial/built to natural features, extracting their hybridization. Example of a feature visualization performed on a DCGAN image. Leveraging guided backpropagation for CNN urban feature classification. The comparison illustrates the higher degree of hybridization of urban features in the DCGAN results. Overview of results of the various methods of depth estimation. Comparison of height evolution and information resulting from the two different analysis methods (figure-ground, above vs. depth map estimation, below). Rose diagrams from GAN generated urban images sorted by greatest entropy of street network orientation. Diagrammatic evaluation builds on the research of Geoff Boing. Excerpt from the DCGAN and StyleGAN latent space showing hybridized urban speculations. The 3D articulation is introduced trough deep learning depth map analysis.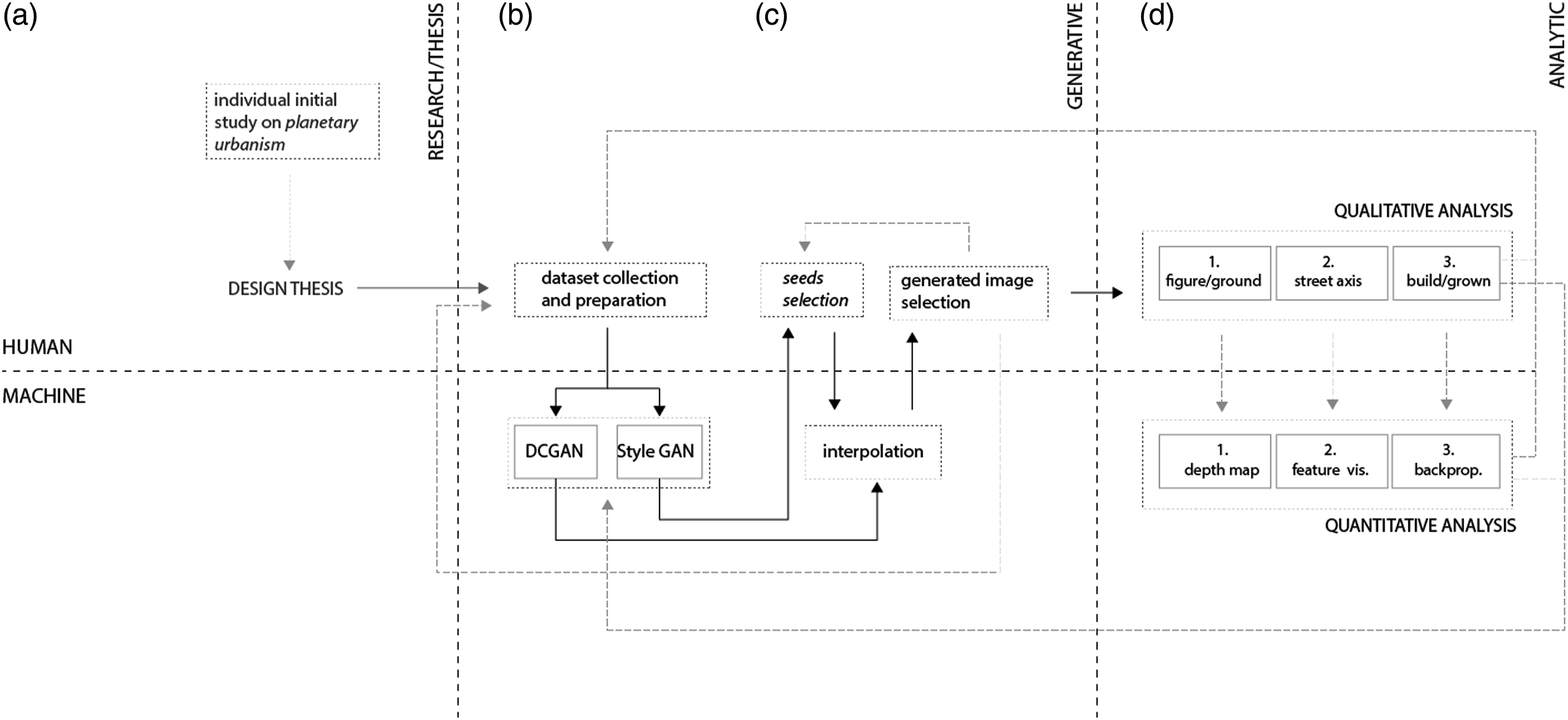






The Architecture of DCGAN, Style-GAN
In DCGANs, CNNs are introduced into traditional GAN architecture as both discriminator and generator and replace fully connected layers. This makes them more stable during training and output and improves their ability to extract features from images. DCGANs can learn hierarchies of features in the full scene and subsequently visualize them through the integration of CNNs.24,25 Nevertheless, this GAN architecture does not distinguish between high-level and low-level features and so composes and hybridizes them more equally than StyleGAN. Training starts at zero without relying on pre-trained models.
StyleGAN, developed by NVidia, introduced a new generator architecture after DCGAN that has increased the fidelity and consistent feature extraction of parts and scene hierarchies in images. 26 This GAN system utilizes developments from style-transfer research to distinguish between high- and low-level features, yielding increased variation and realism in the results. Through this novel generator architecture, scale-specific features are better trained, perceived, and controlled at different scales. Features that are considered style features are differently weighted compared to overlaying high-level features. This results in more curated compositions that are true to the scene compositions and hierarchies of the dataset. Additionally, stochastic variations and variation control are promoted because of increased access to interpolation and latent space parameters. StyleGAN relies on pre-trained models to train custom datasets. In our research, we used StyleGAN2 ADA, which can succeed with relatively small datasets of a few thousand samples instead of tens of thousands. 27
Results
Dataset preparation
In the first stage of the research, the necessary satellite data were generated through either SASPlanet Nightly or Google Earth Studio. The first has the advantage of being able to select entire regions in a controlled manner without producing image overlays. On the contrary, Google Earth Studio allows for more targeted data curation and the extraction of carefully selected parts of a city according to the individual thesis of the participants, such as only high-rise regions of a city or along a coastline, to include both urban and natural elements in the dataset. However, geographic distances and temporal progression must be well aligned to avoid creating image overlays, which can create unwanted weighting in the datasets. Furthermore, it is crucial that each image within the dataset have the same resolution and ratio and be taken from the same altitude to preserve the consistency of scale, detail, and resolution during training and thereby be comparable. To test the influence of the data set on the results, each of the 33 participants created their own data set and implemented it in both models. For both DCGAN and StyleGAN, it is always crucial that the dataset have sufficient similarities in its features that these can be extracted and compared. At the same time, a successful dataset avoids repetition of the same image or feature to promote diversity and better training, which can lead to overfitting.
Overall, we collected 171 different cities and regions, each containing about 400 images, for a total of 68,400 processed images. Based on the individual thesis, the images were curated into different-sized datasets consisting of 1200 to 8000 images to test specific features and investigate how results can be controlled.
Training and experiments
StyleGAN and DCGAN were applied to various curated datasets to compare how the respective models affected the results. DCGAN training was performed on a stand-alone machine, but the StyleGAN was implemented on a Google Colab Notebook, a cloud-based notebook environment. Each DCGAN model was trained in Tensorflow GPU 1.14 for 300–500 epochs over a 24–48-h period. Over time, we tested various datasets, changing the number of samples and height level from which the images were extracted. Our research determined that a capture height of 500 m and at least 3000 samples were ideal for DCGAN training. Otherwise, there were multiple issues with the results: inconclusive rendering, distorted scale, overfit, loss of features, or stagnation after only 80–100 training epochs.
Both models were first tested on identical datasets to compare the results. While both produced unusual interpolations, different reactions were found for the dataset and learning outcomes. Based on this first experimental setup of identical datasets, we tested different datasets to further examine the identified capacities and specifics.
StyleGANs required well-curated datasets, which in turn could be significantly smaller (900–1200 images), and already showed respectable results within a relatively short training time of approximately 8 hours. Neither larger datasets nor longer training times (around 24 h) showed a higher degree of interpolation of features but rather successively reproduced the input data. To achieve the most the most synthesized results, an additional process was necessary for the StyleGAN, which entailed interpolating between different latent space seeds. In contrast, by simply extracting particular seeds without interpolation, the results were too close to the input samples and showed almost no hybrid qualities. The DCGAN, in comparison, already showed high degrees of hybridization through random samples from the latent space at large. The StyleGAN was trained on Google Colab Pro with Pytorch 1.9.0 using the SG2-ADA-PyTorch library.
We observed that the DCGAN was able to learn better from the high diversity in large datasets. It should be noted that after we applied DCGANs on a local GPU system, it could also process relatively large datasets (8000). In contrast, StyleGANs could generalize larger urban circulation patterns like gridded or laddered street patterns while tending toward a higher degree of diversity in smaller details. The GAN architecture may account for the discrepancy between the results and the dataset.
Critical interpretation: Qualitative analysis
In this key part of the research, the chosen GAN images were evaluated by the participants by conducting a conventional figure-ground analysis of the generated urban depictions to reflect upon the typo-morphological urban fabric and patterning of the urban space. As one of the “primary principles of visual perception and visual communication,” 28 its straightforward black and white drawing typically permits rapid (though shallow) comprehension of an urban fabric and yields an idea of possible density. This analysis revealed that the machine produces unprecedented urban models where, for instance, a classic binary figure-ground analysis is untenable because too many undecidable and ambiguous moments are detected. We identified cases where there was no clear distinction between what was ground and what was figure as they dissolved into each other, or they could be read as multiple grounds or figures on/in figures. This was more often the case in DCGAN examples than in StyleGAN images. Thus, we concluded that a binary reading of urban structures was suspended (Figure 2).
Another analysis stream explored the nature of the urban street networks attempting to characterize spatial order and disorder tendencies in the urban circulation system. With this analysis, we intended a process of reverse engineering because the spatial logic and geometric order that emerge through the street network provide insight into and are influenced by design paradigms and certain eras as well as the underlying terrain, culture, or local socio-economic conditions of an urban area.29–32 The analysis showed that certain circulation patterns are adopted but often do not ensure continuous movement, even when we used datasets composed exclusively of grid cities. The results made us wonder about and consider the circulation of different forms and how the land might be subdivided because the buildings did not yield any clear conclusions on this issue (at least none that we know of). In fact, the results open a field of questions about how they could be read and whether the machine generates a more complex three-dimensional urban idea than our known urban analysis methods allow to identify. In particular, the DCGAN model produces an unconventional compilation that mingles forms from all over the world, revealing no clear genealogical order from which specific urban patterns and models can be deduced.
The third analysis investigated the relationship between natural and artificial (built) environments, particularly their hybridization. Did the machine reveal an idea for designing, creating, and producing habitations on a planetary scale, buildings for which this natural/artificial binary no longer exists?
Feature visualization: Quantitative analysis
Quantitative approaches were further used to investigate the scope of critical interpretation. To analyze and understand how the machine detects features in urban datasets, we used image-features-embedding-visualization algorithms, in the cnn-visualization-keras-tf2 library, to visualize the similarities between features. These quantitative methodologies were a necessary in-between step to develop a further understanding of how the machine sees. In particular, we used depth maps, feature maps, and guided backpropagation visualization. All these feature visualization techniques are pre-trained models based on the VGG-19 CNN and supervised learning algorithms (Figure 3). The depth-map visualization allowed us to trace the spatial height of our results. With common CAD applications, the depth can be visualized and compared to data inputs to visualize the factor of hybridization. The feature maps extract features from the output through multiple convolutional layers. This visualizes what architectural elements are being detected, trained, and subsequently composed in the hybridized outputs. Guided backpropagation provides valuable insight about how impactfully features are being trained and perceived by the DL systems. More precisely, guided backpropagation visualizes the features from the feature maps that activate the artificial neurons and subsequently outlines their impact. Furthermore, this helps determine which features in a dataset do not contribute to the final output composition (Figure 4). 33
Investigating the “Urbanness” of GAN images
To interpret an urban scene, information on depth estimation is important, not only for a 3D reconstruction but also to gain some understanding of density, morphology, etc. In recent years, some approaches have shown that it is possible to estimate depth directly from just one image using DL. This technique has received more and more interest, especially through text-to-image applications such as Midjourney or Dall-E, but it has been important in application areas like robotics and autonomous driving for several years. Research has progressed to the point where tolerance ranges or relative information about individual pixels is now sufficient to estimate respective depth and generate high-quality depth maps. The results go beyond a conventional two-dimensional figure ground analysis and grant additional information that, although not fully 3D, allows for a reconstruction that includes both the 2.5-dimensional built structures and the topography at the same time.
To translate the GAN-generated images into three-dimensional urban depictions, we used several different algorithms on a Google Colab notebook application. To verify their correctness and accuracy, we tested the same procedures on existing cities and then applied them to a selection of generated images. The results and comparison with existing cities illustrate that the HighResDepth model (LeiaPix) produces the most truthful depth maps with high resolution and boundary accuracy. 20 This is due to the fact that it performs a double estimation and combines a low-resolution depth range with high-frequency details in the resolution of the neural network. Therefore, this model was predominantly used to evaluate and interpret the generated images.
As was the case previously with the feature visualization, hybridization of the input data appeared to be evident in this process and suggested a higher diversity in the height development of the buildings as well as a stronger development of the topography.
While some GAN images suggested a more conventional 3D urbanscape (primarily in StyleGAN results), thereby mostly confirming the qualitative (figure-ground) analysis, other GAN images (particularly DCGAN images), which showed ambiguities or uncertainties, provoked a rethinking of urban structures that went beyond a 2D (or 2.5D) reading. An interesting result of the process was that the depth map translations of the GAN images also showed unexpected topographic developments than we would have suspected from the 2D images. From further research on GANs and conversations with remote sensing experts, we conclude that, in this case, each pixel contains more information than a human eye can perceive. However, the machine is able to recognize and interpret these subtle nuances, noises that the human eye eliminates and abstracts whereas the machine perceives pixel information in higher detail (Figure 5 and 6).
The feature visualization introduces an alternative data source that allow a comparable evaluation of the urban spatial logic and order as normally granted by the orientation of the street network. It can be used, for instance, to investigate whether the street network is oriented to the geometric ordering logic of a single grid, the measure of connectivity, or entropy. The comparison with existing cities and OpenStreetMap as its data source reveals that even if a single orientation is dominating, any symmetries in connectivity and uniform distribution of streets in every direction that characterize existing structures seem to be cancelled. 34 Moreover StyleGAN images have shown higher connectedness of the street patterns than DCGAN results. This confirms the results of the qualitative analysis, where a more fragmented road network could be identified in the DCGAN images. Compared to previous research on existing cities conducted by Goeff Boeing the results indicate a higher entropy which would make them more akin to European, Middle East, and Asian cities. The decisive factor here is the inscribed terrain information in the satellite images, which remains invisible to the human eye (Figure 7).
Discussion
Concerning the generation of new urban designs, this paper explores the collaboration of human visual perception and data curation with the analytical and generative intelligence of the machine. The study primarily investigated the importance of the curation of datasets and measured the nuances of GAN models. The number of 35 experiments allows to make the following conclusions.
The ambiguity elicited from figure-ground analysis casts doubt on its suitability as an analytical tool, in the context of machine cognition. Needless to say, that the extreme reductive ichnographic representation of figure-ground has certain limitations as it excludes all information other than the buildings footprints in relation to the unbuild voids, including terrain and building height. This is a result, of course, of this tool being invented in the 18th century for analysis at a time when real aerial photography was unavailable and the various information on urban structures were treated and displayed separately. In contrast, even if still two-dimensional, satellite images have an inherently higher degree of information recorded in their color pixels, which can be perceived and processed by a machine, as the depth estimation models prove. Since both building heights and topography are processed simultaneously with the 2D information of satellite images, the results are more nuanced and grant a 2.5-dimensional perception of the urban situation. This additional information leads to divergences between human figure-ground analysis that has hitherto dominated urban design and machine interpretation based on depth estimation. This leads us to two conclusions: on the one hand that the figure-ground technique is being replaced by more human-machine analysis methods in the context of AI-aided design methods for the simple reason that the satellite images already contain information on depth that goes beyond a 2D plan reading. On the other hand, it can also be understood as a provocative indication that, figure-ground, as a Eurocentric method, it is no longer an adequate means once cities and regions of a non-Western canon are integrated and considered in the data.
Feature visualization as a quantitative method of analysis has revealed hidden correlations between input data and output samples. Although we use supervised and pre-trained algorithms to quantitative evaluate the results, human evaluation must play a part in the end, and so, the process underlines the human-machine collaboration. Furthermore, feature visualization processes give relatively small output samples compared to high-resolution GAN results. This can be circumvented by tiling the GAN outputs and processing the smaller fragments before stitching them back into high-res images.
The premise of the research is to include and diversify datasets in urban design through the use of remote sensing technology like satellites. Although the same satellites and technology cover multiple areas, the images may differ in resolution and availability. We have encountered issues when trying to include areas and urban regions in Asia or North Africa in our datasets, but the resolution at the defined height we needed for our dataset was insufficient. This is due to certain countries’ restrictions and laws concerning the protection of privacy and military or nuclear information, which means a limitation of certain geographical regions we could include in our study. Such geopolitical differences can have significant consequences resulting in data gaps and biases that can limit the usefulness and accuracy of collective datasets. Overall, geopolitical differences can make it challenging to create collective datasets that are comprehensive, accurate, and useful. Addressing these challenges will require collaboration, coordination, and trust-building among countries and organizations that are involved in collecting, sharing, and using the data.
That being said, the study has shown the critical importance of consciously curating datasets when incorporating deep learning algorithms into a generative design process. In particular, since the writing and coding of GAN models is usually beyond the knowledge of an architect, a conscious influence on the designs is limited to the curation of datasets and the choice of algorithmic model. Furthermore, the various iterations of case studies have illustrated the influence of the datasets on the results, even though by minimal changes within the data (Figure 8).
Therefore, results from applications like diffusion model, midjourney, or similar whose datasets remains hidden and are beyond our control are to be questioned even more critically, since the bias cannot be elicited and clarified. It needs to be clear that biases in AI applications cannot be prevented—“there is no view from nowhere”—but that positioning of authors whether of the dataset or algorithmic model needs to be transparent. This also applies to satellite images, as there are not only state but also private providers, and the raw data from Landsat, Sentinel, or similar are made accessible to the human eye through algorithmic processes by companies such as Google. Even though DL offers the possibility of process unprecedented amount of data it is a misconception that this could lead to de-biases the data. 35
Conclusion
Our investigation of how the machine perceives, analyzes, and generates a built environment has led us to consider DL to be a collaborator in the design process as it makes the invisible visible and reveals design possibilities we had not considered. DL can, therefore, support architects and stimulate new ideas in the performance of creative tasks. However, one must keep in mind that the results are strongly constrained by the training data. In this sense, the research could be expanded both by significantly higher participatory dataset generation (of various stakeholders from different sectors and regions that ensures an impactful and equitable research) and a crowdsourced evaluation of GAN-generated designs than has been carried out in this test series.
By combining GAN’s generative potential with the analytic abilities of quantitative approaches such as feature visualization and depth estimation algorithms, this investigation highlights future design and analysis procedures that incorporate human-machine intelligence. The quantitative methodologies utilized in the experiment enabled a systematic investigation of human interpretation of machine-generated images, providing a more comprehensive assessment of the application of GANs in urban design and architecture. Combining the generative and analytical capacities of neural networks in conjunction with human perceptual intelligence to form a collective architectural mind is promising in terms of a new approach to designing future cities and techniques to be included in pedagogical models. We suggest a design process in which not only are the boundaries between human and machine agency increasingly blurred but also the urban design knowledge stored in cities 36 across the planet is activated and enabled by space-based data and systems. The benefits of government investment in research and development of remote sensing technologies, which are critical to driving innovation as Mazzucato demonstrates, can thus support societal needs. We see a lot of potential in utilizing space technology as a means of creating a more just and inclusive future, where all communities and nations have access to affordable and efficient space-based solutions to address both local and global urban issues.
Footnotes
Acknowledgements
Special thanks go to the students of the Advanced Urban Design seminar at the University of Innsbruck in the fall term 2022 (in alphabetical order) Hanna Albrecht, Vera Blasbichler, Henning Jasper Dörfler, Nicola Kollreider, Can Öztunc, Sarah Rieder, Clemens Unterlechner, Elisa Venir.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.