
Abstract
The creep behavior of concrete, a critical long-term property in construction, significantly impacts material selection and structural design in civil engineering. Conventional methods for predicting creep usually require many parameters, presenting two significant challenges: substantial consumption of sensor resources and the inability of limited static parameters to capture the material’s complexity. This study introduces a groundbreaking parameterless approach namely Creepformer to predict long-term creep using only early concrete creep data and proposes a simple but effective hybrid model combining convolutional neural networks (CNN) and Transformers within an encoder–decoder framework. The encoder part of the model is composed of the residual neural network, which is responsible for noise reduction, local correlation learning, and embedding feature compression. The decoder consists of a transformer decoder to capture the long-distance dependencies of the time series and global features. Our model achieved impressive performance, with a root mean squared error (RMSE) of 8.28, a mean absolute error (MAE) of 6.85 on the Northwestern University database, an RMSE of 10.09, and an MAE of 7.10 on the real-world Yihui dataset. In addition, we proposed a data completion tool based on random forest to ensure the consistency of data intervals and enrich data samples in different environments and situations compared with other studies. The data completion tool has been tested with RMSE 3.2 and MAE 2.4. Furthermore, the model was subjected to an ablation experiment to prove the effectiveness of the encoder. Finally, the model is applied as two case studies in real-world ordinary concrete and ultrahigh-performance concrete experiments.
Keywords
Introduction
Concrete creep is the time-dependent deformation of concrete under sustained load. Unlike instantaneous elastic deformation, creep occurs gradually and can continue for years, significantly affecting the long-term performance and stability of concrete structures.1–6 This phenomenon is influenced by several factors, including the composition of the concrete, environmental conditions, and the magnitude and duration of the applied load.2,5–7,8 Concrete creep can lead to various hazards; one of the primary concerns is the potential for excessive deformation, which can lead to structural instability and, in severe cases, collapse. 9 Over time, creep can cause concrete to sag or distort, leading to misalignment and uneven settling of structures. This can compromise the functionality and safety of bridges, buildings, and other infrastructure elements.3,5,10,11 Additionally, creep-induced stress can result in cracking, which not only weakens the structure but also allows ingress of harmful substances like water and chemicals, accelerating deterioration and reducing the lifespan of the concrete.4,11 These issues will not only occur in ordinary concrete, high-performance concrete, and ultrahigh-performance concrete (UHPC) also suffer from these problems.12,13
Predicting concrete creep is essential for the planning, designing, and maintaining infrastructure. Accurate predictions make engineers account for long-term deformations in their designs, ensuring that structures can withstand sustained loads without compromising safety and functionality.14,15 In engineering practice, infrastructure is subject to various complex environments and load conditions. By incorporating creep predictions into their designs, engineers can improve the durability and resilience of infrastructure, reducing maintenance costs and extending service life. Conventional methods for predicting concrete creep include empirical, statistical machine learning, and deep learning methods.
Empirical methods rely on physical and empirical models to predict concrete creep. These models are typically based on established theories of material behavior and use parameters such as stress, temperature, humidity, and age of the concrete to make predictions. One of the earlier models is CEB-FIP Model Code 1990 16 ; it laid the foundation for subsequent research by providing detailed equations for creep and shrinkage deformations. It is fundamental, so it may not accurately capture the effects of various factors in some unusual environment. To handle the lack of comprehensiveness of CEB-FIP Model Code 1990, FIB Model Code 2010, developed by the International Federation for Structural Concrete, analyzes more data while taking into account the influence of environmental conditions and material properties to improve performance. 17 Motivated by CEB-FIP Model Code 1990, Bazant provides a more scientific approach, named the B3 model, addressing limitations in capturing both basic and drying creep and incorporating a more comprehensive range of influencing factors. 18 Based on the success of B3, B4 was developed further. B4 uses a larger database of experimental results to refine predictions and better explain the influence of environmental conditions and material properties. 19 Unfortunately, although B3 and B4 have quite a considerable accuracy, mathematical calculation, and material knowledge are required, making them less accessible for actual design work without specialized software. In addition, while these models are widely used in industry for now, their accuracy is limited by the complexity of concrete material behavior. 20
Machine learning methods use statistical techniques to develop predictive models based on historical data. These methods can capture complex relationships between variables without relying on explicit physical models and has been used in many fields of civil engineering.21–24 Yunze et al. 25 developed a model incorporating supplementary cementitious materials, which includes 17 different internal parameters for comprehensive analysis. The model also considers the impact of environmental temperature and humidity on concrete. Through Shapley Additive Explanations analysis, it was found that creep is negatively correlated with cement content and humidity, while factors such as age and water-cement ratio show a positive correlation. Minfei et al. 26 developed an ensemble machine learning model based on Bayesian optimization, achieving high accuracy while considering the impact of admixture dosage. However, the creep compliance curves were not smooth and lack of robustness because tree-based models are prone to overfitting. Additionally, significant data noise also affected the model’s accuracy and robustness. Furthermore, more studies further discussed the performance variations of creep under different conditions or environments and developed a series of models for specific scenarios, providing various solutions in this field.21,22,27–29 However, these methods are still limited by the quality and completeness of the input parameters, and their robustness and generalization require some improvements.
Deep learning methods, a subset of machine learning, utilize neural networks with multiple layers to model complex relationships in data. These methods can automatically learn features from raw data, reducing the need for manual feature engineering. Previously, many researchers developed various neural network models to provide new solutions and ideas for predicting concrete creep.30–36 However, these approaches were limited by the feature extraction capabilities of conventional neural networks and did not show significant advantages in accuracy compared to ensemble learning. In 2021, Jingsong et al. 37 were the first to apply convolutional neural networks (CNNs) to unify the tasks of predicting creep and shrinkage. This method greatly improved prediction performance because of the feature extraction advantages provided by convolutional downsampling. However, the approach had several shortcomings: first, it did not effectively filter noise caused by errors in data collection; second, it trained two separate models for the two tasks, preventing weight sharing and a deeper understanding of features. The denoising residual neural network (DRNN) 38 was proposed to address the noise errors in data collection. This model employs an encoder–decoder structure, where the encoder performs soft sorting of tabular features, denoising, and global feature sampling. This approach significantly improved generalization and accuracy, achieving state-of-the-art performance.
These approaches rely heavily on predefined parameters to make predictions. However, the parameter-based methods presents several significant challenges:
Many sensors are required to collect the necessary data, which can be impractical and costly in some scenarios.
The inherent complexity of concrete materials means that the limited parameters used in these models cannot study the high-dimensional information needed for accurate predictions.
Conventional methods depend on external factors such as temperature and humidity, which are difficult to predict accurately in advance, further complicating the prediction of concrete creep.
Except traditional creep prediction models, many methods such as Informer and Autoformer have been primarily developed to address the long sequence time-series forecasting problem, with a particular focus on enhancing long-range dependency modeling.39–42 For instance, Autoformer introduces a Seasonal-Trend decomposition mechanism that effectively captures long-term patterns, 40 while Informer proposes the ProbSparse self-attention mechanism to reduce the computational complexity typically encountered in ultralong time series handled by traditional Transformer architectures. 39
However, these advancements are not directly applicable to our task. Creep prediction data does not present the characteristics of extremely long sequences. In most cases, the observation period spans up to 3 years, with time steps recorded on a daily basis. Given the moderate sequence length and the scarcity of high-quality data in this domain, the application of overly complex architectures such as Informer or Autoformer may lead to overfitting and degraded generalization performance. Lastly, in scenarios with small datasets, overly complex models are prone to overfitting and may fail to generalize effectively. In contrast, many state-of-the-art time series forecasting models are developed and validated on large-scale benchmark datasets, making them less suitable for specialized tasks such as creep prediction, where data acquisition is costly and time-consuming. Our model strikes a balance between complexity and generalization, ensuring reliable performance under data-scarce conditions.
We propose a method to address these challenges by making predictions based solely on early creep data and observed trends without relying on any external and inner parameters namely Creepformer. This approach simplifies the prediction process and achieves state-of-the-art performance compared to existing methods. We use the Northwestern University (NU) creep database 43 to train and validate our model, and the experiments show that its performance has reached 6.85 in mean absolute error (MAE) and 8.28 in root mean squared error (RMSE). In addition to using experimental dataset for validation, this study also utilized industrial data collected by Yihui New Materials Co., Ltd. during the concrete mix ratio and quality inspection experiment in three provinces of China, including Shandong, Sichuan, and Yunnan, from 2013 to 2018. The performance in Yihui dataset is 7.10 in MAE and 10.09 in RMSE. These experimental results demonstrate that the model can effectively solve the problem of concrete creep prediction in real-world environments with lack of sensors to collect material parameters.
Our model is built upon a CNN-transformer encoder–decoder architecture and is specifically designed to exclude the use of material-specific parameters entirely. Which focuses on capturing the creep behavior of ordinary concrete and UHPC, relying solely on early-age creep data for prediction. It consists of a residual encoder for feature compression and noise reduction and a decoder composed of a transformer encoder for learning global features. Given the need to simultaneously perform creep prediction and feature noise reduction, our model employs a multiobjective learning approach through a designed objective function and backpropagation to learn two tasks under the same framework. We designed a random forest (RF)-based data completion method to address missing data and inconsistent data collection standards to ensure consistency in time series data during the preprocessing stage. In addition, we conducted ablation experiments on the encoder to validate its effectiveness by removing it and observing the resultant increase in model complexity. Finally, two case studies with real-world scenarios and UHPC samples showed that Creepformer outperformed the baseline models and predictive ability in UHPC. Figure 1 shows the process of the proposed method. Table 1 illustrated all the definitions of symbols where this paper used.
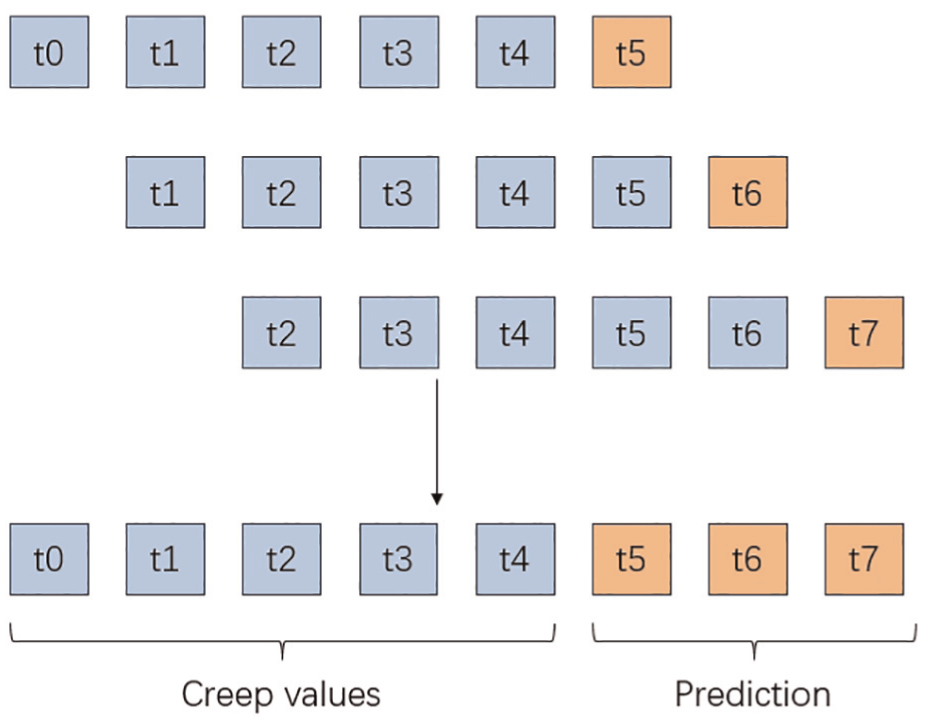
Concrete creep prediction process. The figure illustrates that the model uses the creep values from previous time steps to predict future creep values. The sequence of blue items represents the historical creep values used as input data. The orange items indicate the predicted future values.
Symbol notations in this article.
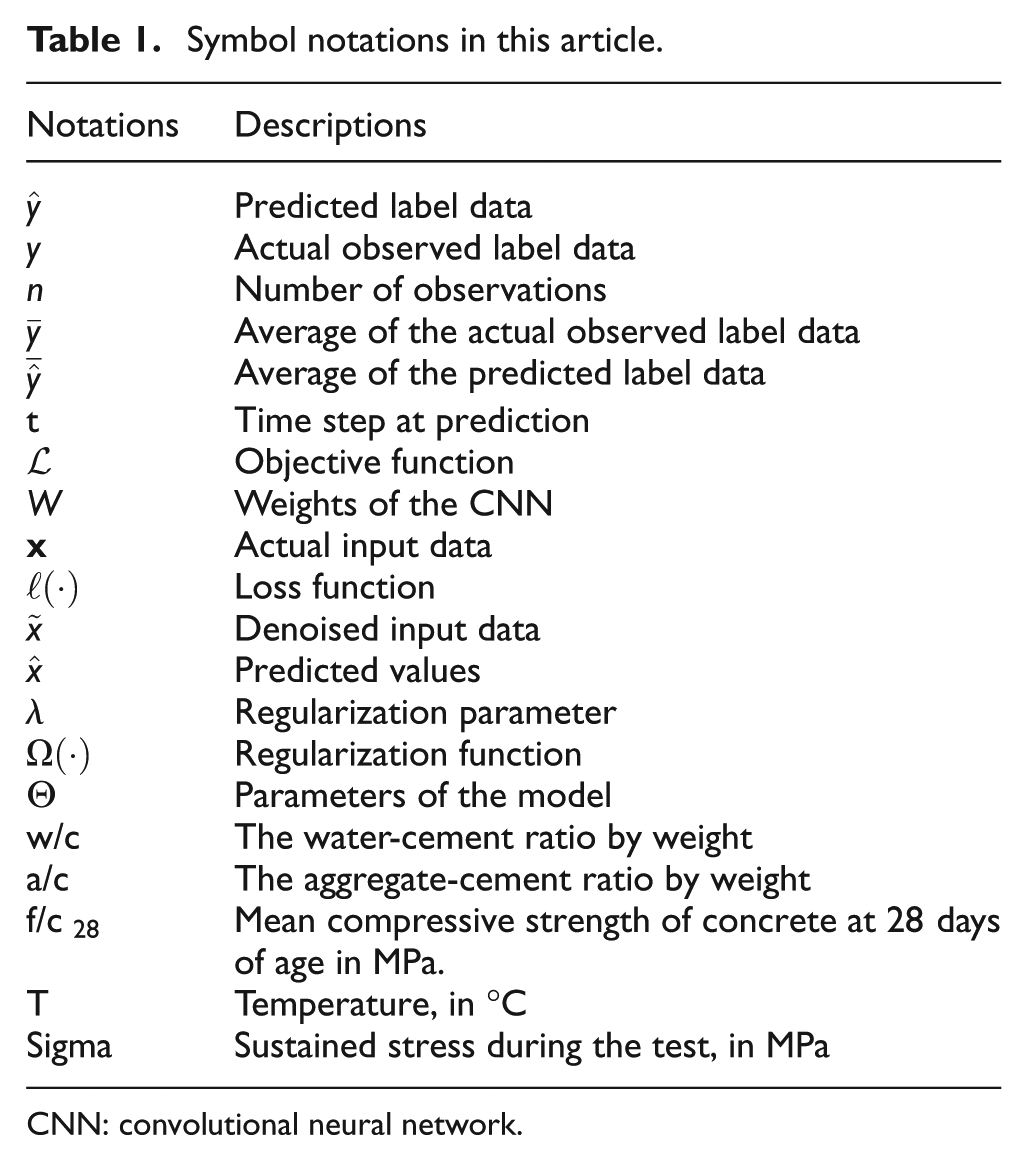
CNN: convolutional neural network.
In summary, the contribution of this experiment is as follows:
For the first time, long-term creep is predicted by only its early stage without any other parameters namely Creepformer.
The encoder achieves effective noise reduction, local feature extraction, and feature compression.
Proposed new data completion method to overcome consistency of data intervals.
Proves the effectiveness of the method in real scenarios.
Demonstrates the method’s predictive ability in UHPC and adaptability in dynamic environments and stress levels.
Methodology
In order to solve the problem of conventional concrete prediction models, CNN-transformer-based hybrid model architecture is proposed for this work. Specifically, it is mainly divided into three modules: First, residual CNN is used for preliminary feature processing of data and noise reduction due to changes in uncontrollable external environmental factors; second, the Transformer is used as the core architecture to understand and abstract time series data; finally, the fully connected network is used to generalize the model and obtain the final creep prediction value. The model framework is shown in Figure 2, and the pipeline is shown in Figure 3.
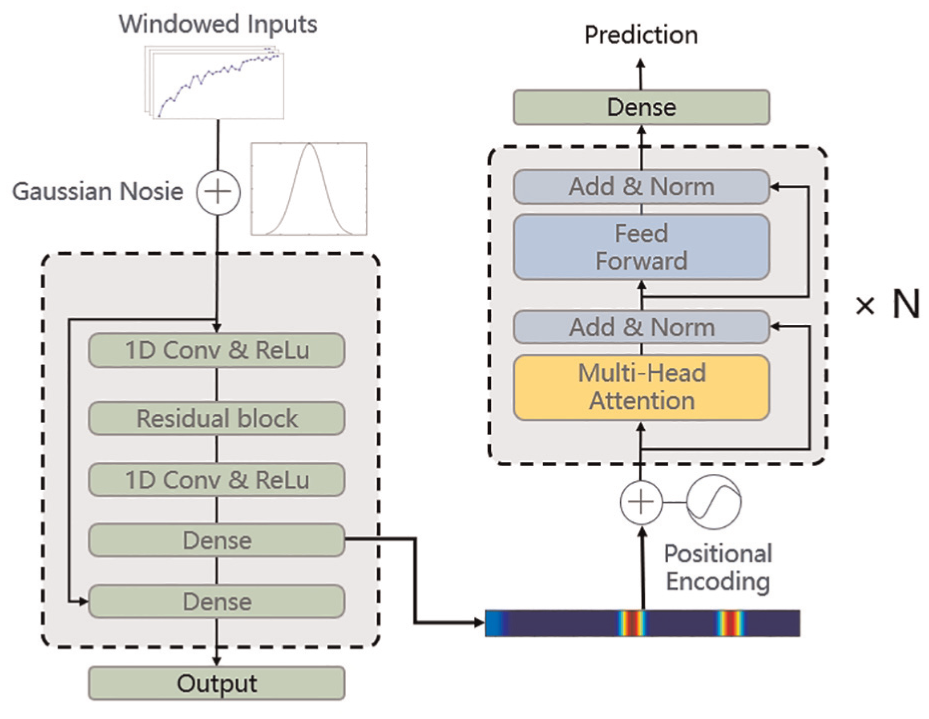
Model structure. The model structure consists of an encoder–decoder architecture for parameter-free concrete creep prediction. The raw data are windowed, and Gaussian noise is added to improve robustness. The left side is a CNN-based encoder designed to reduce noise, learn local correlations, and reduce feature dimensionality. The right side is a Transformer-based decoder that captures the time series’ long-distance dependencies and global features. CNN: convolutional neural network.
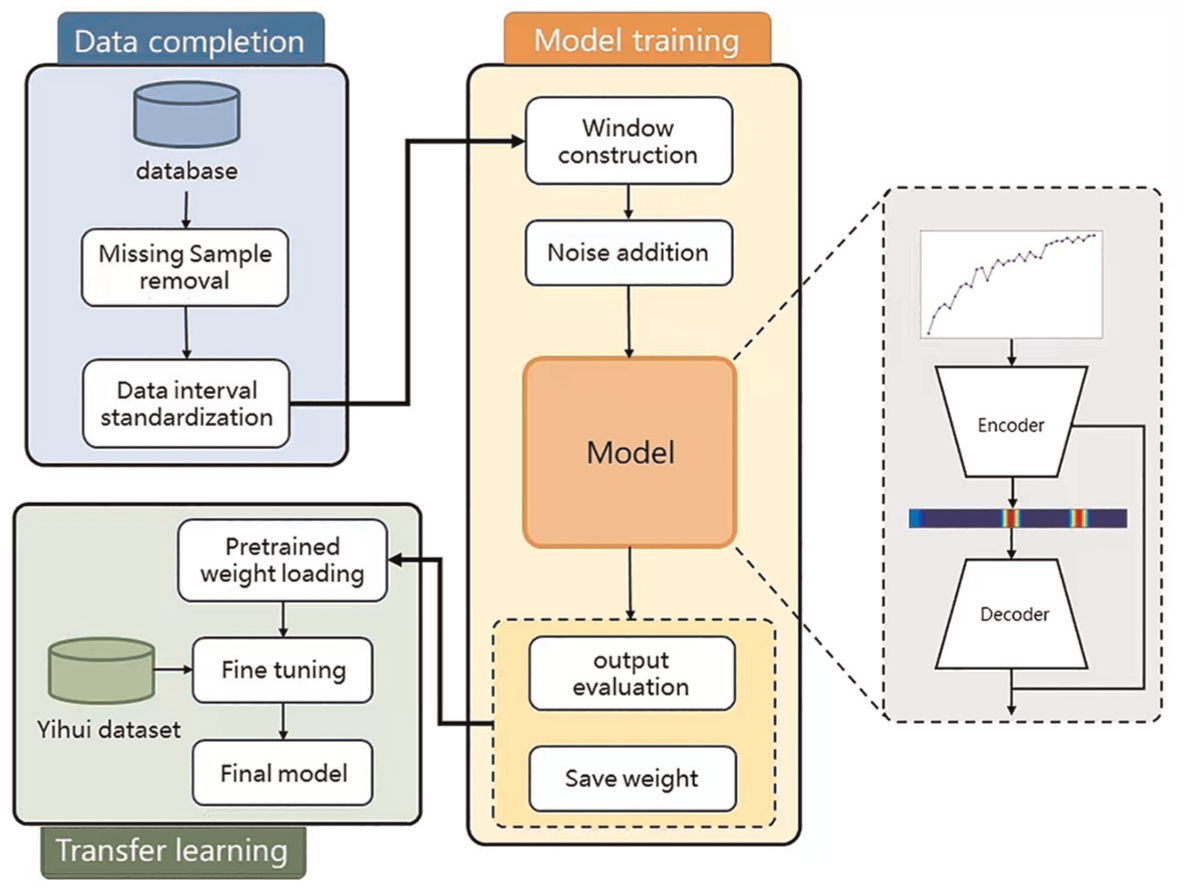
Method pipeline. The pipeline includes three main stages: data completion, model training, and transfer learning. First, the data are processed by removing missing samples and standardizing intervals to ensure consistency. The model training phase involves constructing data windows, adding Gaussian noise and training, and evaluating the model. In the transfer learning stage, pretrained weights are loaded and fine-tuned by the Yihui dataset to optimize the model’s accuracy.
Due to the irregularity of data sampling in time series, we used the data completion method to fill in the data in the data preprocessing stage. As we do not consider data loss and distortion of different sensors, we can use 1061 experiments with 14,024 data points in the NU database and 137 experiments with 2205 data points in the Yihui dataset. Each experiment represents a complete creep experiment cycle with dozens to hundreds of data points. Compared with other works, through the adaptation of more experiments in various environments, our model has better robustness.
The encoder in the Creepformer is mainly responsible for feature extraction, local correlation learning, feature dimensionality reduction, and noise reduction. Specifically, the encoder sets up multiobjective learning and uses residual connections for noise reduction. A more compact sequence can be obtained through the learning of the CNN encoder, which effectively shortens the sequence length and reduces the difficulty of the decoder expression. The data dimension ratio of decoder input and encoder input is 1:2. Moreover, in this model, the encoder is used to capture local patterns and correlations in the data, while the decoder is used to capture global factors as well as long-distance dependencies, which complement each other.
In the decoder part, due to the application of the attention mechanism, the model is susceptible to small changes in the time series data, so in the encoder, we add the Gaussian noise in training data and use the residual neural network and the objective function to reduce noise and improve the generalization ability of the model. The objective function includes the loss function of the predicted creep value, the actual value, and the noise value. This method realizes the multiobjective optimization of these two objectives simultaneously.
As the backbone of this approach, the Transformer has three layers of multilayer attention coding. In the input part of the component, we set the fixed position code instead of the floating position code because of the fixed window. Because of Transformer’s long-distance dependencies, our model can easily capture the relationship between the creep values of concrete over long distances in time.
In our structure, the size of one-dimensional convolution kernel is uniformly set to 3, because it can capture the local change pattern (such as change trend, mutation point) in the sequence, especially for short sequence data (such as length = 32). Residual blocks are mainly used to introduce more complex feature expressions. In the transformer part, because the dimension of the input is 32, we set the embedding size to only 16 for feature compression, and set 8 attention heads, so that each attention head is assigned with smaller moral dimension, and the attention can capture the more fine-grained changes in the time series data. Model’s setting can be found at Table 2.
Network architecture details.
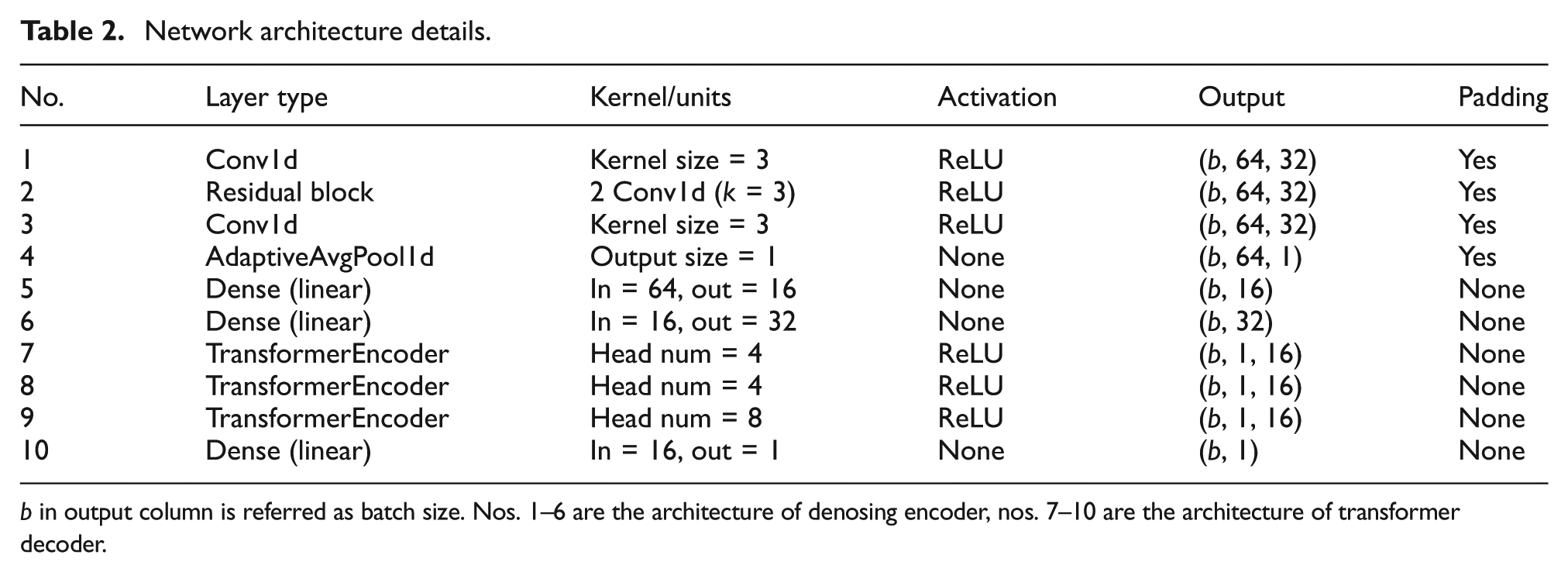
b in output column is referred as batch size. Nos. 1–6 are the architecture of denosing encoder, nos. 7–10 are the architecture of transformer decoder.
Prediction process
The whole prediction process uses the concept of sliding Windows. The concept of a rolling window is to always use the latest window data of size
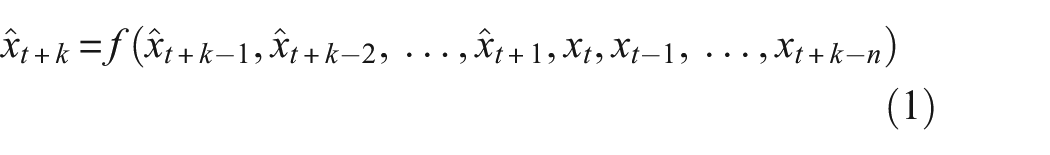
where
Denosing encoder
In actual construction and experimental scenarios, the measurement of concrete creep is not always accurate, and various reasons can produce random changes or fluctuations in the measured data, which can distort the actual underlying behavior of the data. 38 The behaviors that cause noise are varied, such as differences in the proficiency of the experimentalists, imperfect accuracy of experimental equipment, differences in measurement methods, and so on. At the same time, attention mechanisms are very good at capturing different types of dependencies in the data. In other words, it is susceptible to small changes in the time series data, and even small noises can impact long-term creep predictions. Therefore, after data entry, our first task is to reduce the noise in the data.
According to DRNN, residual networks have significantly succeeded in noise reduction of concrete creep data. 38 We use a five-layer residual neural network with the objective of noise reduction. Residual neural networks can alleviate the problem of disappearing gradients through simple skip connections, allowing the network to learn more efficiently and retain more raw, noise-free information. The equation can prove the validity of the skip connection:

In this equation,
Another benefit of CNN encoder utilization is embedding feature dimensionality reduction. By utilizing a CNN encoder, we can obtain a more compact sequence that effectively shortens the sequence length and simplifies the task for the decoder. The data dimension ratio of the decoder input to the encoder input is 1:2. This reduction in sequence length is crucial as it lowers the complexity and computational burden on the decoder, allowing it to focus on generating more accurate outputs. In addition, CNNs are particularly adept at capturing local patterns and correlations within the data due to their convolutional filters. 44 In contrast, Transformer decoders are proficient at capturing global features and long-distance dependencies through self-attention mechanisms. This complementary relationship between CNNs and Transformer decoders enhances the model’s overall performance.
The advantage of capturing local patterns and correlations is primarily from the local receptive field and weight-sharing mechanisms inherent in convolutional layers. By applying convolutional filters over small and contiguous time windows, CNNs can efficiently learn short-term trends, abrupt changes, or local oscillations that are common in temporal data. 44 Because the same filters are applied across all positions in the sequence, the model becomes adept at detecting similar patterns regardless of their position in time, which enhances generalization.
Objective function
In the processing pipeline, we add Gaussian noise to input data and apply a multiobjective function to give the encoder noise reduction capability.
In order to make the model realize multiobjective learning of noise reduction and creep prediction simultaneously, mean squared error (MSE) is applied to the objective function. The function design is as follows:
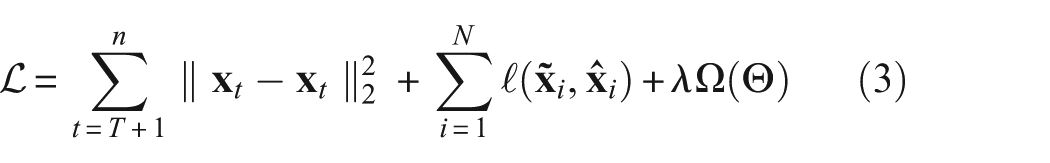
This objective function are constituted by three terms. Data fidelity measures the squared difference between the actual values
Transformer
Transformers initially introduced in natural language processing. It has revolutionized many areas of machine learning due to their ability to model complex patterns in data. 45 The main idea of the Transformer is the self-attention mechanism, which allows the model to measure the importance of different inputs. Conventional methods for predicting long-term creep require large amounts of empirical data and often fail to capture the nonlinear, time-dependent nature of the process accurately. Transformer offers an alternative with its ability to model time dependencies. 46 By training on early creep data, we can use self-attention mechanisms to identify the most relevant factors affecting long-term creep. The Transformer can then use this information to predict future creep behavior accurately. As shown in Figure 2, the decoder mainly consists of a position encoding, a multi-head attention layer, and a feedforward network (FFN).
The Transformer uses a combination of sine and cosine functions of varying frequencies to generate positional encodings that capture the relative positions in the input data sequence. The positional encoding is added to the creep embeddings before they are processed by the encoder, making the model understand the relationships within the time series. Each position is mapped to a vector, resulting in a matrix where each row represents a coded sequence element and its positional information.
The multihead self-attention mechanism enables the Transformer to focus on different sequence parts. For creep prediction, this means weighing the importance of different sub-sequences of creep to improve long-term creep forecasts. The multihead attention mechanism helps the model capture complex, time-varying patterns in early creep data, enhancing prediction accuracy.
The FFN in the Transformer model introduces nonlinearity, allowing it to learn complex patterns and handle the intricate nature of concrete creep influenced by various factors. The FFN processes each position independently, which is advantageous for analyzing time-series data where each time point can be affected by different factors. The FFN consists of two linear transformations with a Rectified Linear Unit activation function in between, further transforming features learned by the attention mechanism into higher-level abstract features for better prediction accuracy.
Experiment
Datasets
The experiment consists of two databases: the NU database and the Yihui dataset.
The NU database is a comprehensive resource for concrete creep and shrinkage testing. 43 It covers a long measurement period and includes the effects of admixtures in modern concrete mixtures. The database contains approximately 1400 creep and 1800 shrinkage curves, with significant effects of admixtures on creep and shrinkage behavior observed. It provides information on various concrete compositions, including different cement types, aggregate sizes, admixtures, and various environmental conditions, such as temperature and humidity levels, which affect creep behavior. The data in this dataset were obtained through experiments using standardized testing methods, ensuring the consistency and reliability of the data.
The Yihui dataset was collected during the infrastructure construction phase by Shandong Yihui New Materials Co., Ltd. from 2013 to 2018 for keeping test samples and providing product reports. This dataset contains commercial data on infrastructure projects in three Chinese provinces: Shandong, Sichuan, and Yunnan, including projects such as the Yibi Expressway, Xubi Railway, and Qinglan Expressway. It comprises 197 creep experiments from mainly expressway projects but still covers a wide range of conditions and scenarios, including tunnels, high-speed railways, roads, and other infrastructures. However, due to the lack of uniformity in data collection standards, many data points are missing key internal parameters of concrete, making them not directly comparable. Additionally, inconsistent collection intervals cause a challenge, as consistent intervals are essential for understanding trends and patterns over time in time series data forecasting. Despite these issues, the real-world sampling of the data makes it highly instructive for the training and evaluation of the model.
Data preprocessing
In the study of concrete creep, field data collection is a critical component. However, it is often observed that the data collection process does not adhere to a fixed time interval. This irregularity can be attributed to factors such as project-specific requirements or constraints inherent to the experimental sites. Consequently, the datasets obtained from different projects or locations may exhibit inconsistencies in their temporal resolution.
To address this challenge and ensure the uniformity of the data input into our model’s sliding window, we standardize the data interval to one sample per day across all experimental scenes by a RF-based data completion method.
The RF algorithm operates by constructing multiple decision trees during the training phase and outputting the mode of the classes or mean prediction of the individual trees. 47 It is particularly well suited for our purpose due to its ability to handle large datasets with numerous input variables and its inherent mechanism for estimating missing data. By utilizing this method, we can impute the missing values based on the patterns learned from the available data, thereby preserving the integrity of the dataset and maintaining the consistency required for accurate creep analysis. We also compared other popular data completion algorithms. To refer the Table 3, the RF achieves the best performance.
Performance comparison of data completion method.
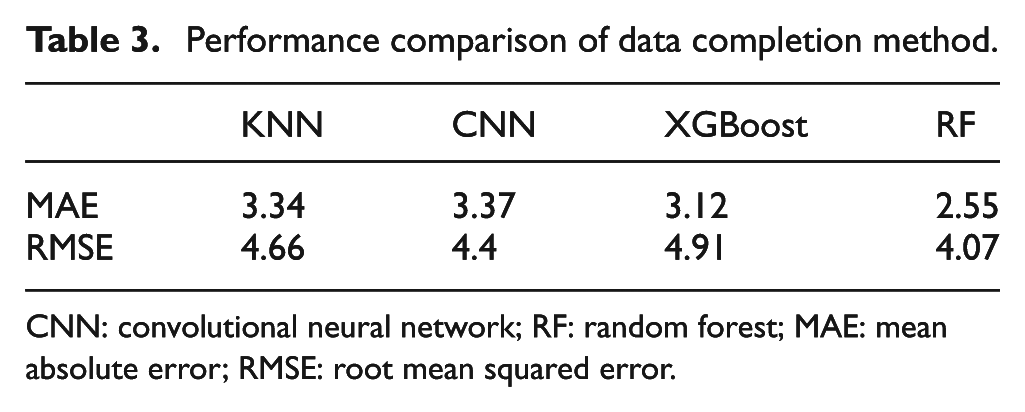
CNN: convolutional neural network; RF: random forest; MAE: mean absolute error; RMSE: root mean squared error.
Although RF is not inherently designed for sequential data, it can effectively capture temporal patterns when appropriate features are engineered. Since our data are time series with fixed intervals, we explicitly incorporated temporal information into the input features by encoding the timestamp associated with the loading time. This approach allows the RF to learn correlations that are implicitly related to temporal progression, thereby enhancing the quality of the imputation. Empirical results at Table 3 indicate that this time-aware feature encoding enables RF to produce relatively accurate imputations, demonstrating its viability as a data supplementation strategy for structured time series data.
The data completion method presented at Algorithm 1 is designed to process creep dataset
Dataset completion algorithm.

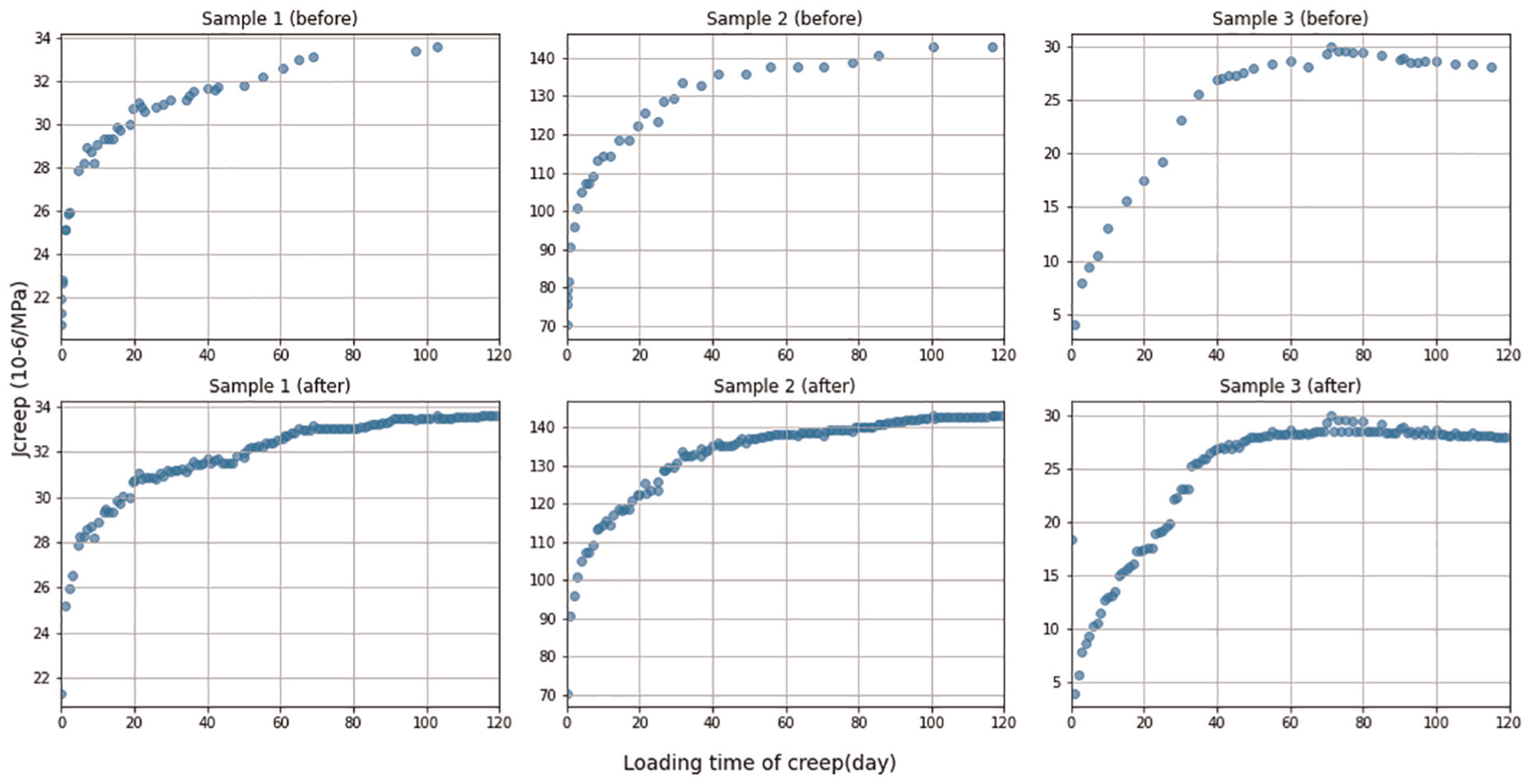
Completion samples by RF. RF: random forest.
It is important to note that our data completion method utilizes both preceding and future context to predict and fill the gap. However, in the scenario of concrete creep, where future trends are unknown at the time; therefore, the proposed data completion method is not applicable to creep prediction. The process of data completion can be referred to as Figure 5.
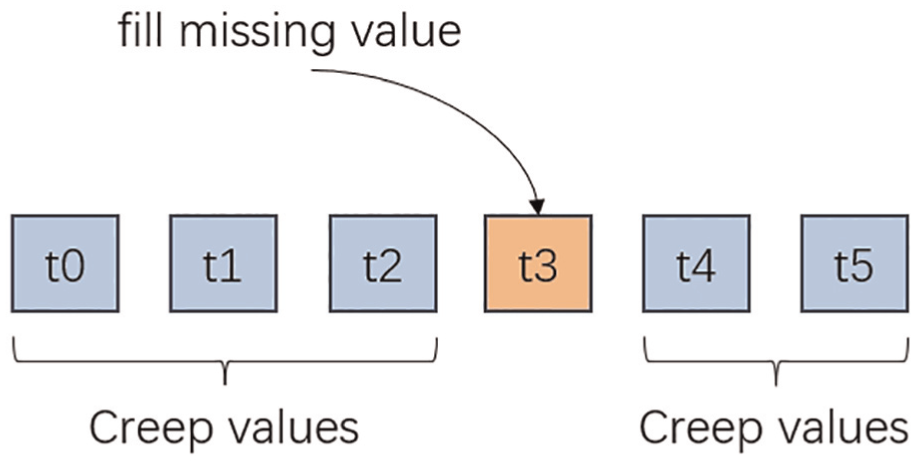
Data completion. The diagram illustrates predicting and filling the missing value using the surrounding values. The example consists of known values (t0, t1, t2, t4, and t5) and a missing value at t3.
Evaluation metrics
To assess the performance of our concrete creep prediction model, we use three evaluation metrics: R-squared (
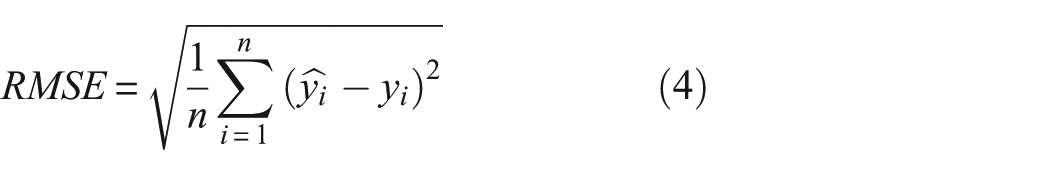

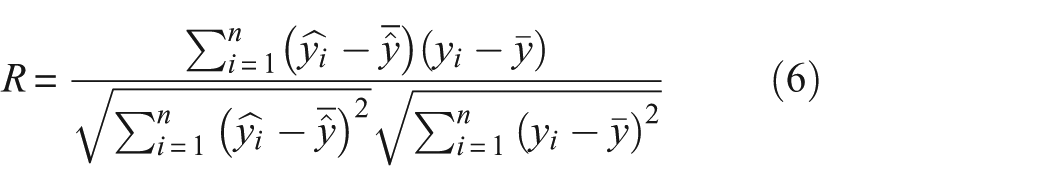
where
Parameter selection
In order to improve the generalization ability and model performance of the model, the model needs to apply the optimal hyperparameters. Therefore, the method deploys grid search to optimize the model’s hyperparameters. Grid search is an important technique in machine learning hyperparameter optimization. 49 It performs an exhaustive search within a specified range of hyperparameter values to find a combination that optimizes model performance. By systematically working through multiple combinations, grid search ensures the best possible results are found. This process improves the model’s accuracy, reduces the error, and dramatically enhances the model’s generalization ability. Our hyperparameters for using grid search include learning rate, multihead attention layers, level of Gaussian’s noise, and weight decay. The model is trained using the Adam optimization algorithm with MSE as the loss function.
The final parameter is chosen as the learning rate: 0.001, multihead attention layer: 3, noise level: 0.1, dropout: 0, weight decay: 5e-5.
Transfer learning
In the task of concrete creep data collection, continuous observation over the load time is a very long-term and complex task. In addition, the reporting and evaluation of creep tests require heavy labors. Because of these problems, the Yihui dataset from the real industrial environment has a very limited data size compared to the NU database. Using the Yihui dataset to train the model from scratch may lead to reduced accuracy, overfitting, and other problems. To solve these problems, we introduce the concept of transfer learning in this study.
Transfer learning solves the most critical challenge in machine learning: it allows one to take advantage of pretrained models when there is not enough labeled data to train on, thereby reducing the need for large amounts of labeled data. 50 Specifically, in this study, the NU database was trained as the pretrained dataset of the creep prediction model. After the training, the Yihui dataset was used to fine-tune the pretrained model, which improved the model’s performance on the Yihui dataset. The performance of the fine-tuned model can be referred to Table 4.
Performance metrics for different models on two datasets.
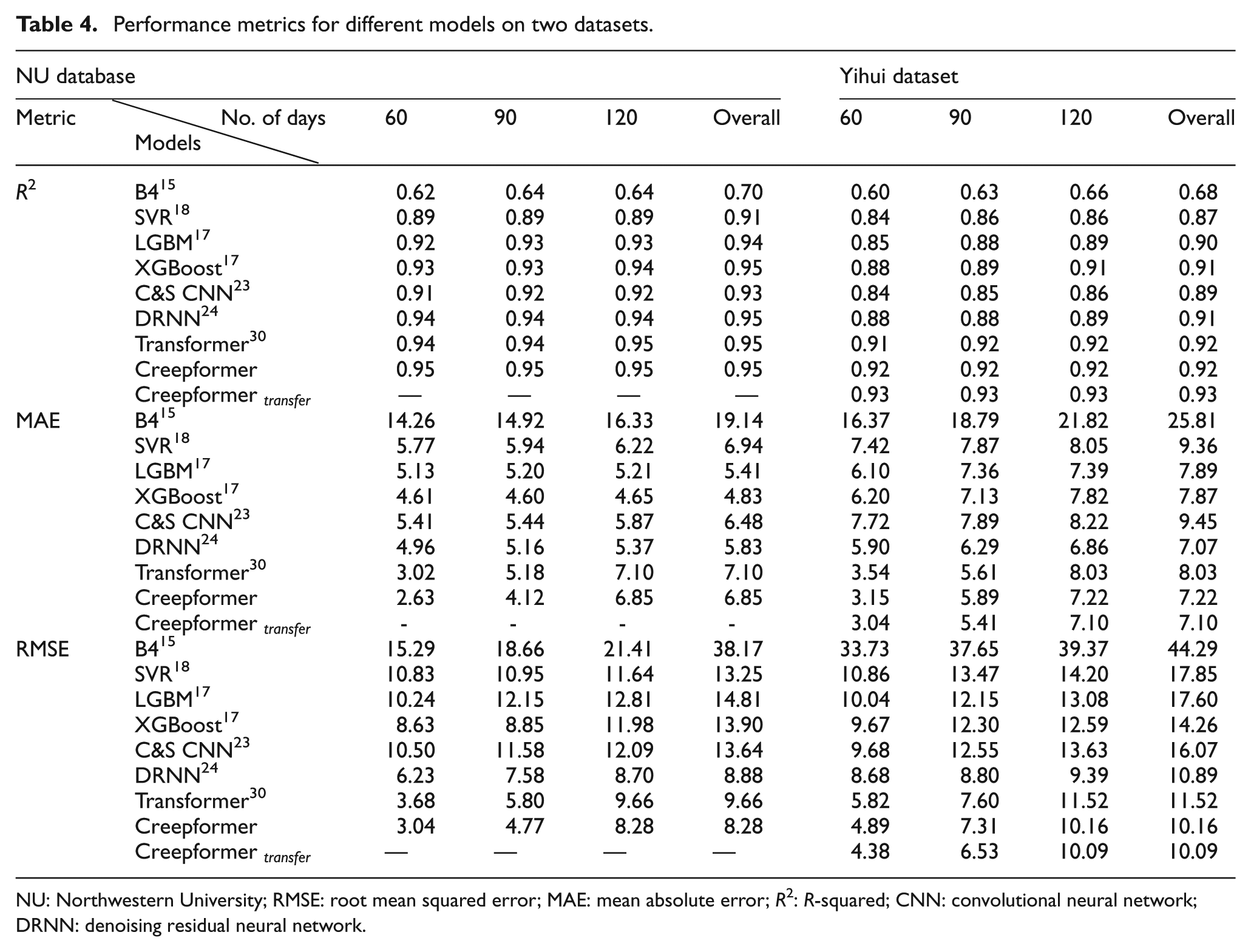
NU: Northwestern University; RMSE: root mean squared error; MAE: mean absolute error; R2: R-squared; CNN: convolutional neural network; DRNN: denoising residual neural network.
Result analysis
Overall result
The experimental results of our proposed method and baseline models are shown in Table 5. The method was verified on two datasets: the NU database and the Yihui dataset. Validation on the NU database provides convincing evidence of the Creepformer, while validation on the Yihui dataset demonstrates the method’s practical significance for real-world creep prediction.
Performance metrics for baselines at long sequence time-series forecasting task on NU database.
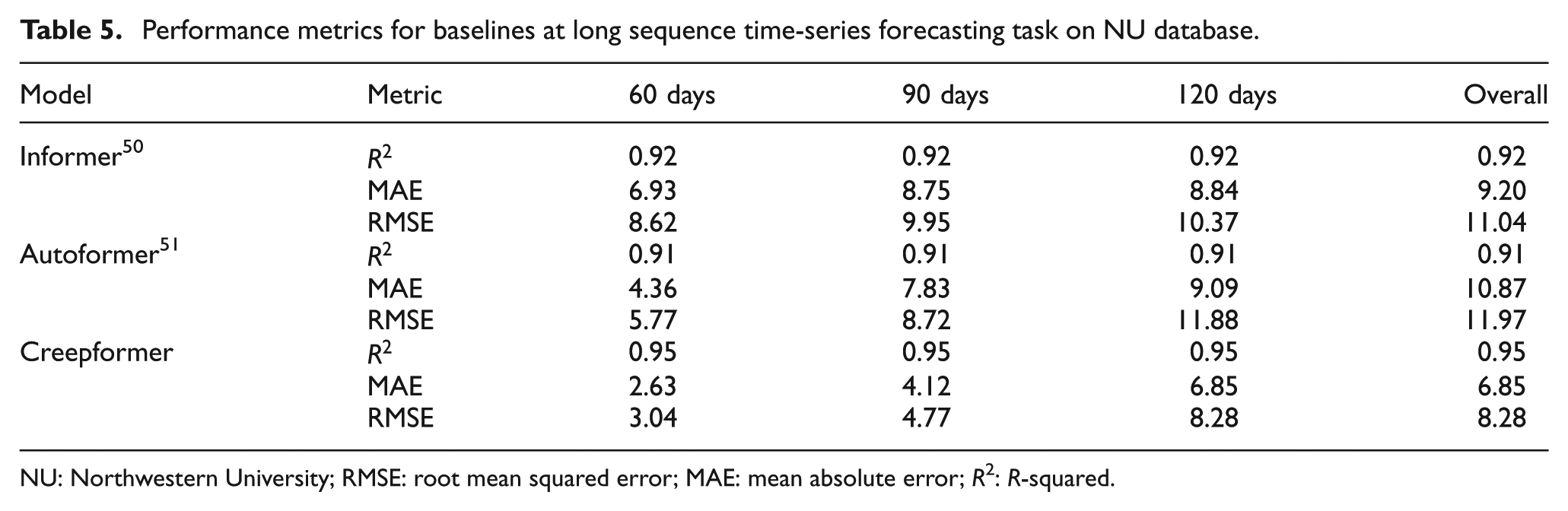
NU: Northwestern University; RMSE: root mean squared error; MAE: mean absolute error; R2: R-squared.
We examined the performance of the baseline and proposed models over different periods, dividing the experiments into 30–60, 90, and 120-day creep predictions. The overall performance indicates the models’ performances in the entire experimental cycle. For the parameter-free approach that utilizes time series, the duration of each experiment is settled at 120 days. According to Table 5, the Creepformer and Transformer initially exhibit very high performance, but their performance decreases significantly over time. This phenomenon occurs due to the accumulation of errors inherent in time series predictions. In time series prediction, each prediction step depends on the previous ones. This dependency means that any error in earlier predictions can propagate and amplify in subsequent predictions, leading to a cumulative effect. 51
In contrast, parameter-based models have high errors initially, and the experimental results slowly decrease as the test data increases. This is because, along with the increase of data volume, more different creep states in the test data bring complexity which the model cannot identify. These phenomenons from parameter-based methods suggest that parameter-based models do not effectively leverage the time series characteristics of the creep process. Despite this, the Creepformer consistently shows SOTA performance compared to other baseline methods on both benchmarks, especially on the Yihui dataset.
The Yihui dataset, collected from an actual experimental scene, contains more noise than the standardized samples of the NU dataset. Consequently, models usually perform worse on this dataset due to the increased noise. However, the Creepformer and the DRNN demonstrate strong antinoise capabilities, which can reduce the impact of noise to a certain extent. This noise resistance highlights the encoder’s role in noise reduction, which enhances the model’s robustness and noise resistance, improving overall predictive accuracy.
Comparison with time series baseline
As shown in Table 5, our model achieves the best overall performance. Although Informer and Autoformer are specifically designed for time series forecasting, their relatively complex architectures are not well-suited to the characteristics of creep prediction data. In particular, the limited sequence length and small dataset size reduce the effectiveness of such models, which are typically optimized for large-scale, long-sequence scenarios. In contrast, our model demonstrates better adaptability and accuracy under these constraints.
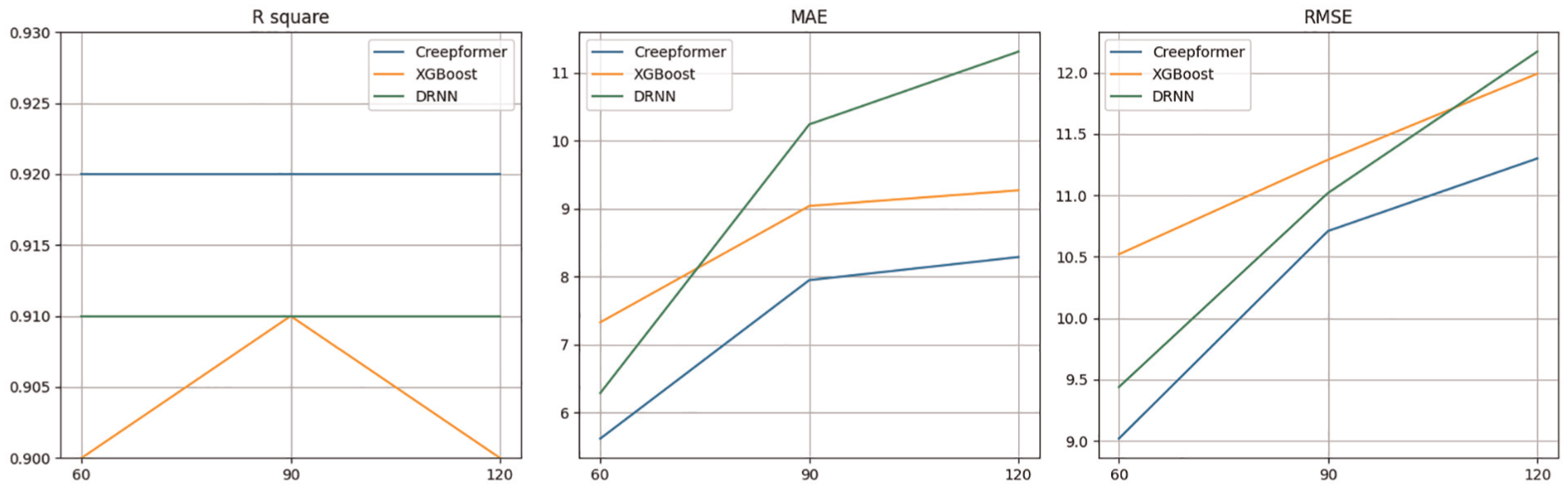
Tenfold cross validation
Tenfold cross validation can usually have more reliable performance in small dataset. 23 As such, we selected DRNN and XGBoost as baselines, which have high performance in random train-test splits, to apply a 10-fold CV for comparison. The result is shown in Figure 6. Compared to random train-test splits, 10-fold CV led to a notable performance drop, suggesting that it is a more rigorous and reliable evaluation method. Additionally, as illustrated in the figure, our model consistently outperforms the baselines across all folds, unlike in random splits. This further reinforces the robustness and effectiveness of proposed model.
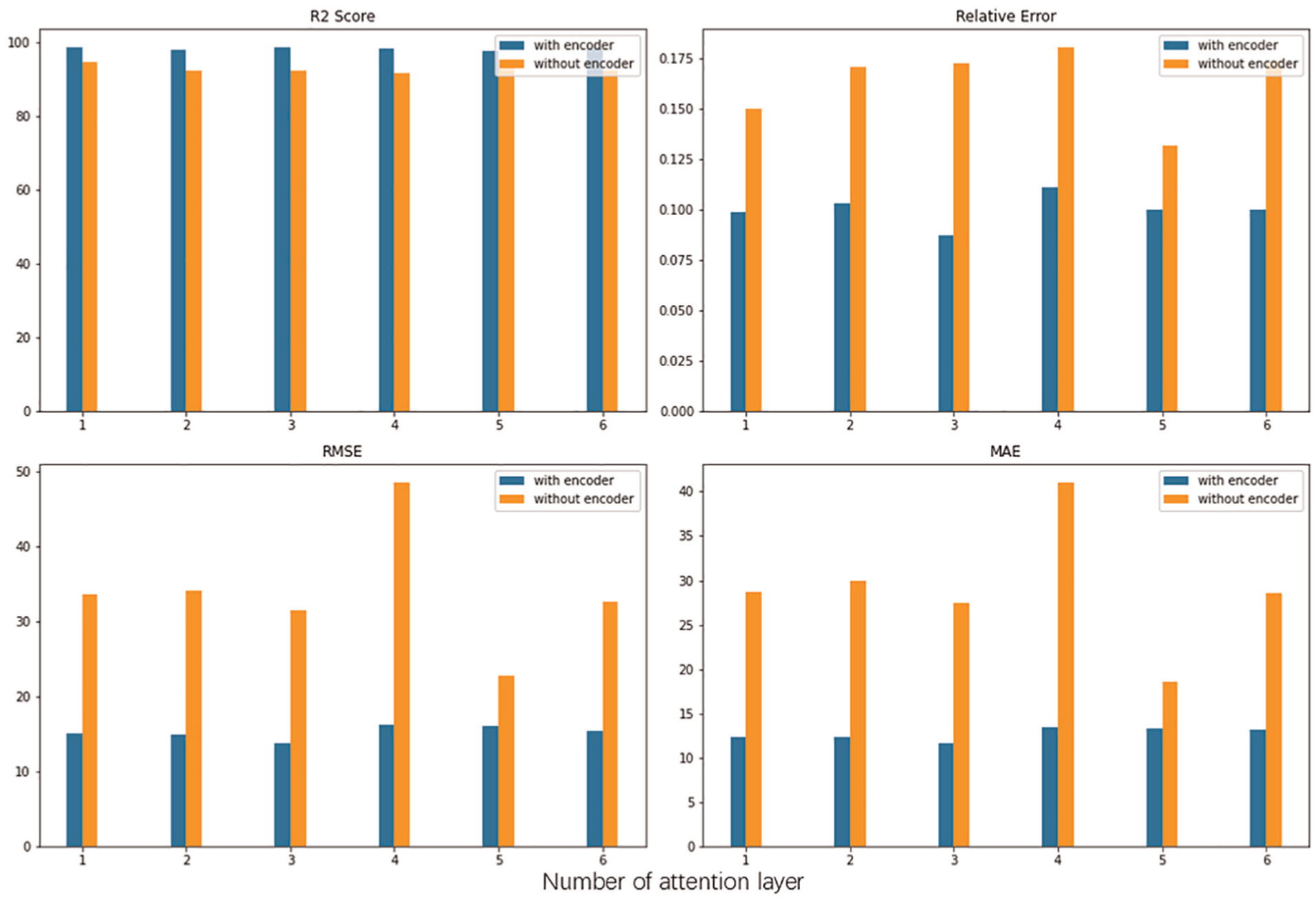
Tenfold experimental performance for baselines.
Ablation experiment
In the ablation experiments, we systematically evaluated the role of the encoder in improving performance in the model. We evaluated the impact on the model’s predictive power by removing the encoder from the model’s structure. The results in Figure 7 show that the performance significantly decreases when the encoder is removed. The experiment demonstrated the critical role of the encoder in feature compression and noise reduction; thus, allowing the decoder to learn highly abstract temporal features.
Effect of encoder.
In addition, model complexity may also affect the results of ablation experiments. We assume that when we remove the encoder, the complexity of the model decreases, so the model may cause underfitting to reduce performance. Therefore, to further demonstrate the effectiveness of the encoder, we removed the encoder in the ablation experiment and increased the number of multiple attention layers to eliminate the effect of complexity. The experiment results are shown in Figure 7, which shows that increasing model’s complexity does not have a regular positive effect on the experimental results. The experimental results further demonstrate the encoder’s effectiveness in the model’s overall structure.
Case study
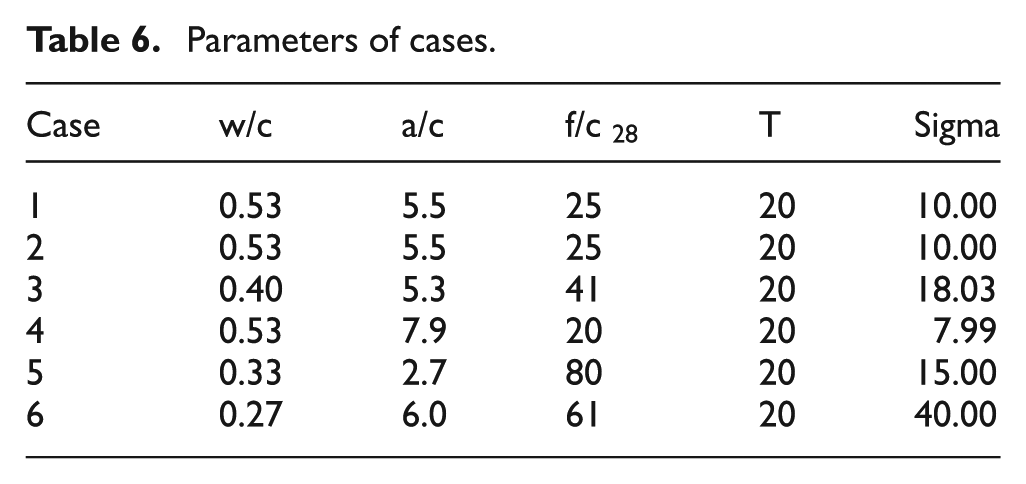
In the case study, we comprehensively evaluated the proposed model’s performance in predicting the creep behavior of concrete using real-world samples. Specifically, we selected six concrete samples from the Yihui dataset, each with dimensions of 150 ×400 mm, and subjected them to testing under constant temperature and humidity conditions. The parameters of these cases are shown in Table 6, and the parameter symbol explanation can refer to Table 1.
Parameters of cases.
The proposed model and baselines are evaluated as shown in Figure 8. Particularly during the early prediction phase, our model shows consistency with the observed creep behavior. However, as the observation period extended, deviations between the model predictions and the actual creep behavior gradually emerged. Despite encountering these challenges in the later stages, our model consistently shows robust performance in predicting the overall creep trend across all six cases.
Case study for baselines. The red dashed line on the left is the input 32-day creep data, and the Ground truth data along with the prediction results of different baselines are shown on the right.
Compared with parameter-based baselines, our model illustrates advantages in accuracy and robustness. They are difficult to understand the time series features, leading to unstable deviations between predicted values and actual creep trends. While a naive Transformer shows considerable capabilities in learning time series information, Figure 8 revealed that this model is easy to noise interference by analyzing case 3. In contrast, in case 3, our model shows excellent noise resistance, which means it can accurately predict concrete creep behavior in the real world.
In addition, it can be observed that the proposed model generally exhibits better noise resistance than other models. Several ensemble learning-based baselines demonstrate significant overfitting. This overfitting occurs because these models’ Regression in high-dimensional feature space is not smooth enough; as such, they closely fit the training data, including noise and outliers. In contrast, the proposed model incorporates noise during the training stage, and the encoder learns to handle this noise, significantly enhancing the model’s robustness.
Application in UHPC
UHPC represents a breakthrough advance in concrete technology, adding considerable strength, durability, and longevity compared to conventional concrete materials.52,53 Because of its dense microstructure, high compressive strength, and low permeability, UHPC is increasingly being used in some critical infrastructure projects, including bridges, high-rise buildings, and defense facilities. Nevertheless, as a concrete material, UHPC is still vulnerable to creep, which can compromise its long-term performance and structural integrity. Therefore, accurately predicting the creep behavior of UHPC is critical to ensuring the durability and reliability of the structures that use it.
The UHPC case study employed the University of Adelaide’s UHPC test dataset, which includes primary and dry compression creep and shrinkage data, to conduct creep experiments on 16 concrete samples over 1 year. 54 It is important to note that the dataset measures compressive strain under specific load conditions, whereas our measurements focus on creep compliance. To align the data, we use the following conversions:
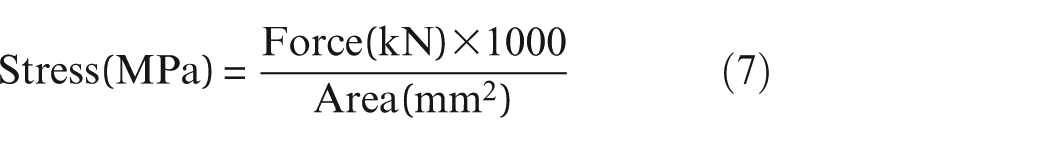
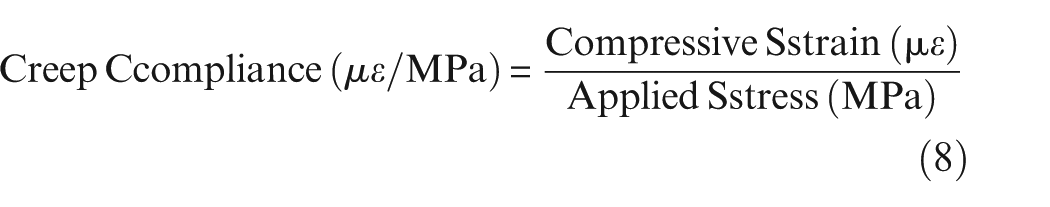
Creep compliance, expressed as
After fine-tuning, the final results from these tests are illustrated in Figure 9. We compared four different UHPC samples, with each sample’s name indicating different sizes and stress levels, as detailed in Table 7. All samples tested in the same laboratory environment, with dynamic temperatures between 16 and 24°C and humidity levels from 45 to 70%. Due to the data missing, we only take first 280 days data for experiment.
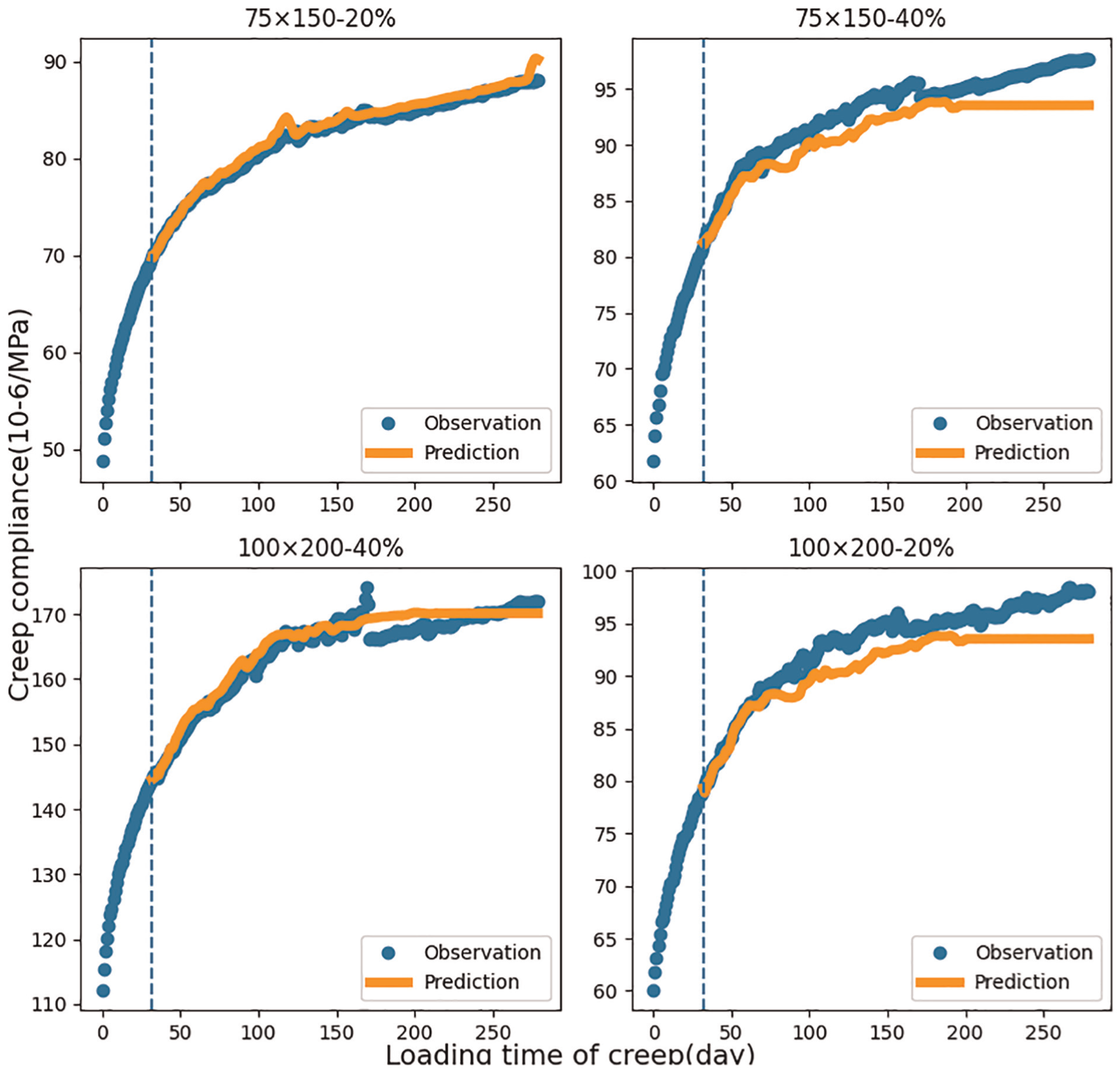
Case prediction for UHPC samples. UHPC: ultra-high-performance concrete.
UHPC samples and their parameters.
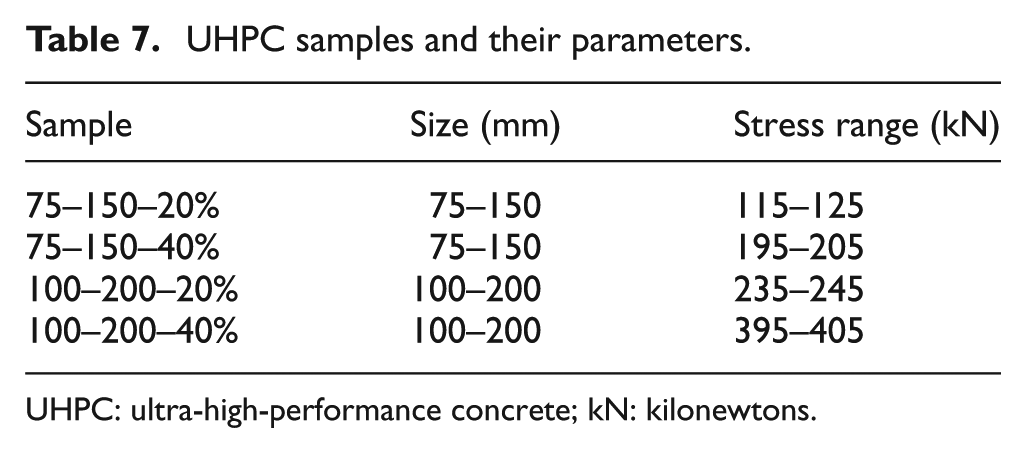
UHPC: ultra-high-performance concrete; kN: kilonewtons.
As shown in the reference Figure 9, the results prove that the proposed method not only has good prediction ability for ordinary concrete but also has high accuracy and robustness for UHPC. In addition, the experiment also demonstrated its adaptability to UHPC under dynamic environmental conditions and stress levels due to continuous changes in ambient temperature, humidity, and stress levels. This adaptability is essential for practical applications, as materials must often function under dynamic stresses and environmental influences.
Conclusion
In this study, we proposed a novel CNN-transformer hybrid model namely Creepformer. We applied it for the first time to the parameterless prediction of concrete creep, complemented by a RF-based data completion tool. Our model achieved impressive prediction results on the NU and Yihui datasets. Additionally, we performed ablation experiments to verify the effectiveness of the encoder and conducted predictions and analyses on a set of real-world creep experiments. Eventually, we applied our model in the UHPC experiment and evaluated the performance, showing outstanding accuracy and adaptability to dynamic environments and stress levels.
However, our work still has several disadvantages:
Cumulative errors with increased prediction time: Our model tends to accumulate errors as the prediction time horizon extends. This is a common issue in long-term time series prediction, where initial inaccuracies can propagate and magnify over time, leading to significant deviations from actual values. This cumulative error effect can undermine the reliability of long-term creep predictions. One possible solution is to conduct multimodal prediction model using a small number of key static parameters of the concrete material.
Inaccuracies in data completion: While effective to a degree, the RF-based data completion tool introduces errors that prevent a perfect representation of actual creep changes. Incomplete or unevenly spaced data points are a challenge, and our current method does not fully capture the intricate variations of the actual creep behavior. These inaccuracies can lead to less precise predictions, especially in sparse or highly variable data scenarios. An adaptive data completion method may solve the related problems well.
Exclusion of key static parameters: Our model currently excludes some key static parameters, such as the water-cement ratio and aggregate-to-cement ratio, which are crucial for accurately characterizing the material properties of concrete. This omission can result in large prediction variances, particularly in cases where these static parameters significantly influence the creep behavior. The absence of these parameters limits the model’s ability to fully capture the material’s complexity and variability.
Based on these shortcomings, we plan to conduct the following research in the future:
Use multimodal models for prediction: To address the issue of cumulative errors and enhance prediction accuracy, our next aim is to develop multimodal models that integrate internal static parameters (such as water-cement ratio, aggregate-to-cement ratio) with early creep data. By combining these diverse sources of information, we hope to improve the consistency and reliability of our predictions over both time and space, providing a more holistic understanding of the material behavior.
Develop adaptive data completion models: To overcome the inaccuracies in data completion, we plan to develop a new adaptive model that can handle varying data intervals. This model will be designed to function effectively even when the time intervals in the data are not uniformly equal to 1 day. By accommodating floating intervals, we aim to ensure that our predictions remain robust and accurate and overcome the irregularities in the data sampling process.
Footnotes
Acknowledgements
The authors would like to express their sincere gratitude to Shandong Yihui New Material Co., Ltd. for providing access to the data used in this study.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Ministry of Higher Education, Malaysia, under the Fundamental Research Grant Scheme (ref: FRGS/1/2020/ICT02/MUSM/03/1).