
Abstract
Cracks in tunnel linings might cause a lack of water tightness, directly affecting the overall stability and durability using an increased risk of corrosion of the rebar. Hence, automatic, timely and accurate detection of cracks is significant to safe operation and maintenance for tunnels. In recent years, Convolution Neural Network (CNN) has achieved success in the field of computer vision. However, the large storage requirement and high computational consumption of the model limit its application. Aiming to overcome these challenges, this study proposes a lightweight target detector YOLOV5-lite, which utilizes transfer learning to construct the YOLO single-stage target detection model and uses the Efficient Intersection over Union (EIoU) in the loss function to optimize its convergence speed. To improve the model efficiency, a Network Pruning algorithm is performed in order to reduce the number of parameters in the model. To compensate for the loss of accuracy caused by the Network Pruning algorithm compressing the network, knowledge distillation algorithm is implemented in this study and fused with the Network Pruning algorithm. This results in a new lightweight modelling framework which has a high computational efficiency enabling deployment in mobile devices as well as high accuracy leading to good detection performance. To illustrate the advantages of the proposed method, two experiments using an extensive evaluation of the YOLOV5 series of models and a comparison with different model tests were made to validate it. In the evaluation of the YOLOv5 series, key findings include: (a) The optimized YOLOV5-loss model, incorporating the EIoU loss function, achieved an impressive crack recognition accuracy of 0.97. This model demonstrated superior capability in detecting fine cracks, particularly in corner regions, with an accuracy exceeding 0.85. The EIoU loss function offers enhanced sensitivity to overlapping regions and more precise boundary localization, which are critical in identifying minute or boundary-ambiguous cracks. (b) The YOLOV5-finetuned model, which underwent network pruning alone, achieved an accuracy of 0.74 but was hindered by significant detection gaps, despite achieving a 50.9% reduction in model size. In contrast, the YOLOV5-lite model, refined using a combination of network pruning and knowledge distillation, maintained a high recognition accuracy of 0.96, with only a negligible 0.01 difference from the optimal YOLOV5-loss model. When compared with five different models, the YOLOv5-lite model demonstrated significant advantages: A substantial reduction in the size of the proposed YOLOV5-lite by 184.1 MB, 659.4 MB and an increase in the number of the transmitted Frames Per Second (FPS) by 6.69 f/s, 13.24 f/s compared with that of YOLOV3, Faster R-CNN, respectively. Overall, the proposed new method consistently achieves high detection performance as well as substantially reducing computational demands, making it well-suited for real-time applications, particularly in mobile and embedded systems.
Keywords
Introduction
Related work
Tunnels can expand limited ground space and effectively relieve traffic pressure. However, with long-term use of tunnels, the internal lining may begin to suffer from deterioration and defects. One of the early phenomena of tunnel infrastructure degradation is lining cracks. Lining cracks in the lining structure reduces the local stiffness and may also affect the safety and stability of the structure with evolved crack expansion. If early cracks can be detected and repaired in a timely manner, the associated risks can be mitigated, and the service life of the tunnel can be significantly increased. Therefore, regular tunnel inspections to detect early cracks without disrupting traffic operations have practical significance in preventing tunnel damage.
Various computer vision-based methods have been proposed to detect surface cracks in infrastructures, including house surfaces, bridges,1,2 sewer pipes and tunnels, 3 and others.4–6 These methods are divided into two main categories: traditional machine learning methods and deep learning methods. Traditional machine learning methods require the creation of manually labelled crack features and use them in training classifiers; in general, BP neural networks, 7 Bayesian networks, 8 and SVMs 9 are often used as classifiers in machine learning for pixel-level crack recognition. However, the results obtained by machine learning algorithms often tend to be dominated by some regions of images based on the training and classification of low-level features within sub-images. When it comes to cracks with low contrast or poor continuity relative to the background, these methods may encounter challenges in locating the complete crack curves.
Deep Convolutional Neural Networks (DCNNs) can extract advanced features from a large number of crack images from a variety of aspects such as edges, textures, and shapes, and the recognition results can be greatly improved than traditional machine learning algorithms.10–13 Dorafshan et al. 14 compared the performance of an edge detector and a DCNN for detecting cracks in concrete structures and illustrated the advantages of DCNN in detecting concrete cracks. Subsequently, scholars extensively applied DCNNs in various domains. Man et al. 13 established a ResNet model relying on the TensorFlow deep learning framework to detect tunnel diseases (water seepage and cracks) from interferences (pipe splices and tunnel tubes). Applications in detecting cracks on the surface of concrete can be found in Silva et al. 15 in which an image classification algorithm was developed based on the VGG16 architecture. The recognition accuracy of this application was improved using a Faster R-CNN-based defect inspection method, 16 which can detect five types of damages including cracks. Another improvement was made by Tabernik et al. 17 who proposed a two-stage deep learning algorithm based on a segmentation model to address the issues with scarce samples. The new model only needs 25–30 training samples to obtain a well-performing crack detection model. Other attempts have been made to optimize the model structures to improve feature extraction capabilities, such as the Atrous Spatial Pyramid Pooling and BatchNorm (BN) modules used in crack detection in steel structures, 18 and the extended the PANet model 19 to solve the crack disconnection problem.
Current studies on detecting cracks are mainly focused on improving the detection accuracy; therefore, most of the models use network structures with deeper layers, such as segmentation models and two-stage detection models. However, these models require a large amount of computational resources. In some cases, measured data on-site can be transmitted to a Cloud, which could trigger the alarm system according to the system settings.20–22 However, signal propagation is affected by factors such as tunnel length and curvature in the complex environment of underground tunnels, leading to problems such as slow data uploading and data loss during transmission. Therefore, there is significant potential for crack detection algorithms deployed to edge mobile devices by using and improving small-frame neural network models, such as single-stage detection models.
YOLO, as a single-stage target detection algorithm in DCNN, is widely used in many fields due to its much higher detection speed than other target detectors.21–23 Park et al. 24 combined YOLOV3 with a laser sensor to accomplish the detection and quantification of surface cracks on concrete structures. Zheng et al. 25 embedded the non-parametric attention mechanism of SimAM (Simple, Parameter-Free Attention Module) into the YOLO model for pavement crack detection, which improved the accuracy by 4.5% over the original YOLOV5 with more prominent crack features. Liu et al. 26 defined a new loss function to optimize the YOLOV5 model and integrated PSA-Neck and ECA-Layer attention mechanism modules into the network architecture for concrete bridge maintenance and management. Zhu et al. 27 established the MFF-YOLO model for crack identification in urban metro tunnel lining with a re-weighted screening method in the prediction stage to solve the problem of repeated frame detection. Besides metro tunnels, the YOLO model is also often used in hydraulic tunnels, road tunnels, etc. to identify tunnel damage.3,28
Several studies have attempted to simplify the network structure by strategies such as network compression and compact network design, aiming to deploy the models in mobile devices. Chen et al. 29 introduced an attention mechanism based on the YOLOV5 model and deployed the model on Raspberry Pi to detect helmet-wearing of construction site workers. Kumar et al., 20 based on the YOLOV3 and TYOLO-V3 models, used transfer learning to classify and localize cracks and spallings that appeared on the surface of high-rise civil buildings in real time with the open-source hexacopter Unmanned Aerial Vehicle (UAV). Wang et al. 30 proposed a lightweight model based on YOLOV5 for identifying road vehicles. The number of network layers and channels was reduced drastically after the optimization of the model, which improved the model’s inference speed. Zhu et al. 31 trained a lightweight model based on a multidimensional knowledge distillation method on both features and outputs, and the MobileNetv3 lightweight network was embedded into the student model to reduce the number of model parameters and volume. Zhou et al. 32 compressed the YOLOv4 based on a Network Pruning algorithm and introduced an efficient channel attention module, which improves its performance compared with those before pruning for the pruned YOLOv4, but still fails to meet the requirement for real-time detection.
Through the literature review above, it can be revealed that there are difficulties in balancing accuracy and network size when using single-stage models for further model compression. Most existing studies have focused on optimizing models to achieve high precision and recall in detecting structural defects, particularly cracks, in tunnels. However, these approaches face several limitations. For instance, models like Faster R-CNN, despite their high accuracy, have a considerable number of parameters and large model sizes, rendering them unsuitable for resource-constrained environments. This is a critical limitation for applications that require real-time detection on mobile or embedded devices with limited computational capabilities. Furthermore, lightweight modelling methods, such as knowledge distillation and network pruning, have not yet been explored for tunnel defect detection, despite their successful application in fields like medicine and agronomy. Additionally, significant accuracy degradation resulting from network pruning remains an unsolved issue.
Contributions of our work
Considering the limitations of traditional target detection and inspired by the previous research, this study relies on the PyTorch Deep Learning framework and optimizes the YOLOV5 model by replacing the Complete Intersection over Union (CIoU) loss function with the Efficient Intersection over Union (EIoU) loss function to improve the convergence speed of the crack detection model. To reduce the number of parameters in the model, the Network Pruning algorithm is employed to prune the redundant channel numbers in the YOLOV5 network convolution. To compensate for the possible accuracy loss caused by Network Pruning, this paper combines the knowledge distillation algorithm with the Network Pruning algorithm. This makes the pruned model able to learn from a more accurate model and improves the model accuracy under the premise of simplifying the model structure, leading to rapid and accurate crack identification.
Image acquisition and dataset generation
Image acquisition
The capacity of neural networks to extract high-level and abstract features from raw data is complex, making image quality vital for optimal model training. This study utilized a dataset collected from various tunnel projects (subway tunnels, highway tunnels and pedestrian tunnels) to enhance the adaptability of the model to deal with diverse tunnels. However, obstacles such as dim lighting and auxiliary facilities like anti-drainage systems often interfere with capturing clear images of lining cracks. Figure 1 illustrates various obstacles disrupting the tunnel crack detection, including stains, ancillary pipes, bolt anchors and cables. Stains, as shown in Figure 1(a), create significant visual noise during the detection process, often causing the model to confuse stains with actual structural cracks. Additionally, obstructions such as those depicted in Figure 1(b) and (c) can obscure cracks, increasing the complexity of the detection task. Consequently, the model must be trained to effectively filter out these extraneous elements. Understanding these factors is crucial for effective tunnel crack recognition and underscores the need for sophisticated neural networks to achieve accurate detection.

Crack detection obstacles in the field: (a) stains; (b) ancillary pipes; (c) bolt anchors; (d) cable.
From a vast array of tunnel lining photos, a number of 148 photos containing cracks were selected to make a dataset, which is not insufficient for training a robust model.
Training dataset generation
To optimize the feature information extraction from this limited lining crack dataset and mitigate overfitting risks that could halt feature learning progress, this study employed a comprehensive dataset augmentation strategy. For dataset augmentation, we employed random image transformations to eliminate highly similar samples. Geometric transformation techniques, colour temperature transformations, and image enhancement methods were specifically applied to diversify the dataset, contributing to improved model robustness. Among these strategies, three image change renderings —brightness adjustment; 90° rotation; colour temperature transformation—are illustrated in Figure 2. Each original image was expanded 18-fold resulting in an augmented dataset comprising of 2664 sample images, which were divided into training set, validation set and test set at a ratio of 3:1:1, respectively.

Sample dataset enhancement results.
The images need to be annotated after data augmentation in supervised learning in this study. The annotation process automatically generates information such as the target category, centre coordinates of the annotation box (x_center, y_center) and dimensions of the annotation box (width, height), and this information is saved in a designated folder in text (TXT) format. Here, we define the label storage form for cracks as 0 with annotated samples shown in Figure 3.

Crack labelling diagram.
In the process of manual labelling, various challenges may arise, such as inaccuracies in the positioning of target rectangular boxes (either too large, too small or misaligned). These labelling issues hold the potential to exert a significant impact on the training outcomes of the final model. To enhance the interpretability of the detection outcomes from the model, we employed a moderately dense annotation method specifically tailored for longer cracks. To underscore the effectiveness of this method, we conducted a comparison and analysis of results obtained through different annotation methods. Figure 4 provides valuable insights, indicating that in scenarios where cracks lack breakpoints or exhibit minimal horizontal/vertical angle changes, a solitary target box suffices to meet localization requirements, as shown in Figure 4(a). Consequently, the recognition results manifest as a singular target box to circumvent the challenges associated with an excess of target boxes, which may lead to occlusion issues and compromise visibility. However, when cracks are dispersed across a substantial area as shown in Figure 4(b) and (c), relying on a sole target box for labelling may inadvertently incorporate interferences or overlook crack discontinuities. In such instances, employing multiple target boxes for labelling proves advantageous, facilitating enhanced feature extraction by the model.
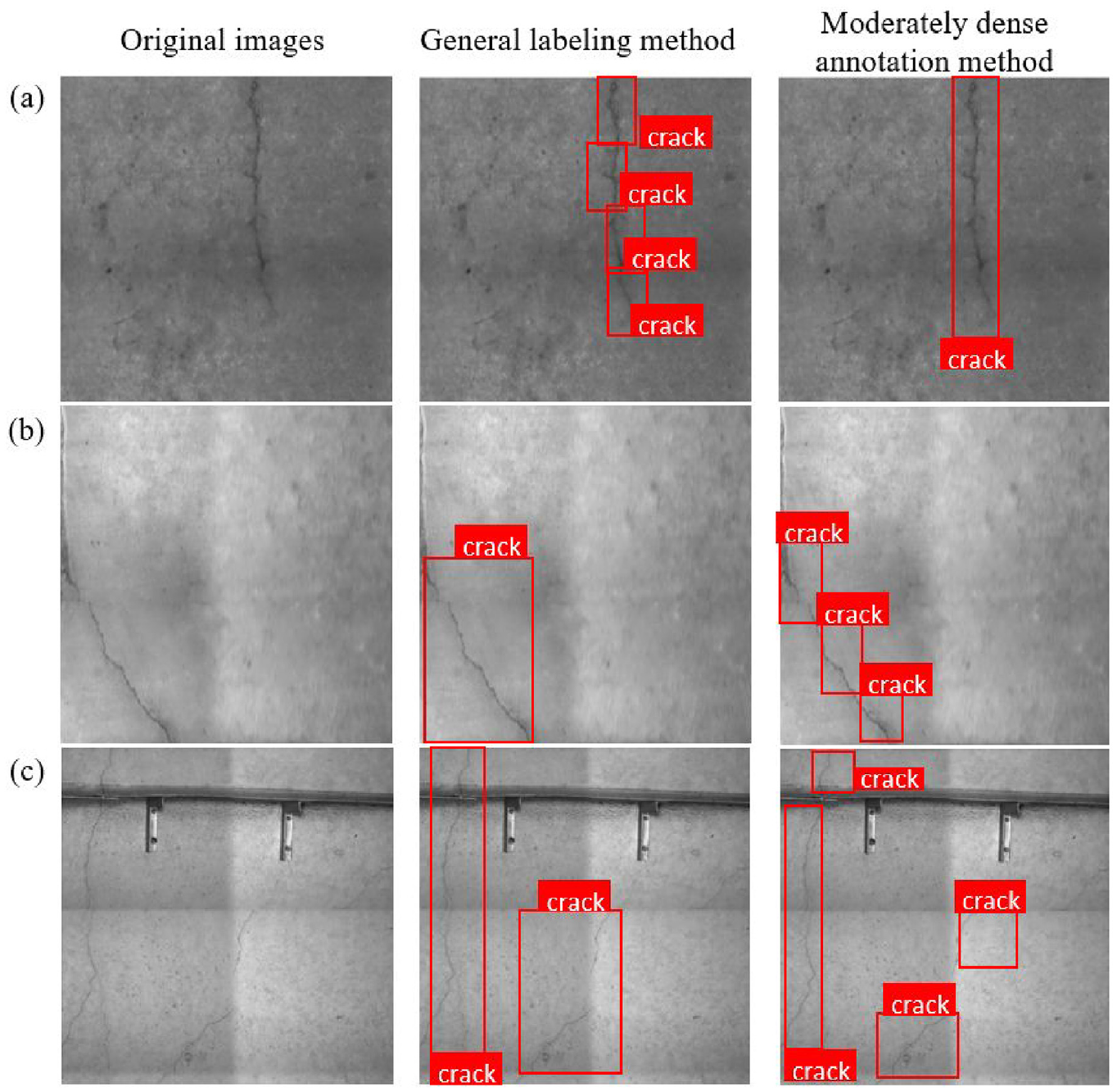
Comparison of different labelling methods: (a) cracks with continuous and minimal change in horizontal/vertical angle; (b) cracks with large horizontal/vertical angle; (c) cracks with discontinuous and extensive distribution.
The proposed moderately dense annotation method maximizes the content of the target and minimizes the interferences in the labelled boxes. In addition, the method leads to a reasonable number of target boxes to avoid overly dense labelling that may lead to problems such as results confusing and model overfitting. Figure 5 displays a segment of the labelled samples, the application of this technique contributes to the overall quality and coherence of the dataset with annotated images, which makes the model easier to learn the features.

A portion of the labelled samples.
YOLOV5-lite model and principle
Baseline model YOLOV5
Basic components
YOLOV5, a single-stage object detection algorithm, is primarily composed of three main components: the Backbone network, the Neck section and the Head section. The basic architecture of these components is illustrated in Figure 6.
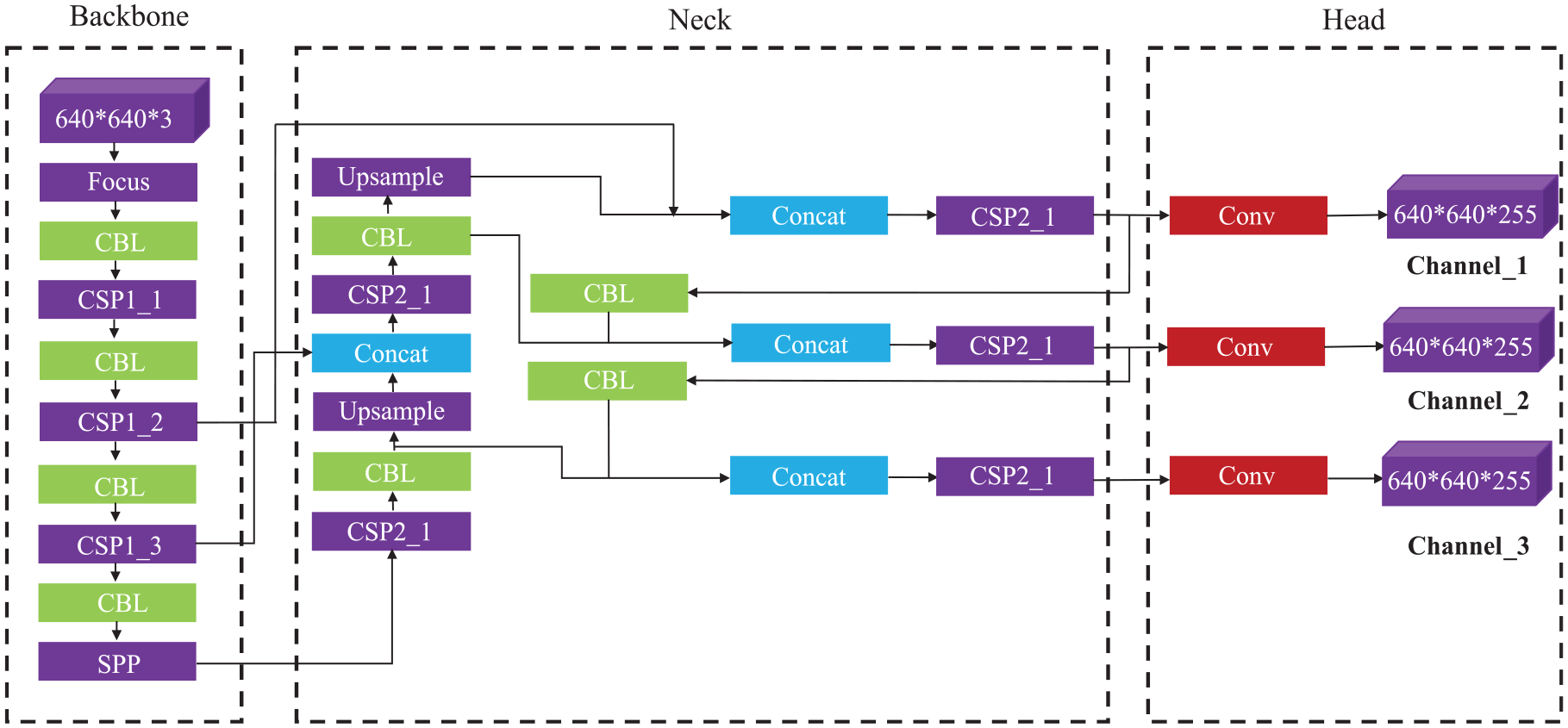
Basic structural framework of YOLOV5 used in this study.
The Backbone network includes CSPNet and Focus modules whose primary function is to extract critical features from input images. 33 The CSPNet structure employs bottleneck blocks of residual structure, which enhance gradient propagation capacity and at the same time reduce the number of network parameters to boost neural network learning capability. The Focus module enhances computational efficiency by expanding input channels while preserving information integrity. These elements provide robust feature extraction capabilities for subsequent improvement methods. In the Neck section, YOLOV5 utilizes a CSP2 structure and constructs a feature pyramid to achieve target crack scaling and generalization. This makes the model easier to recognize cracks across different sizes and scales. Unlike the traditional feature layer aggregation, which typically involves combining feature maps from different layers or stages of a neural network, the Neck part of YOLOv5 reprocesses and uses feature mappings from various stages of Backbone, implementing up-sampling and down-sampling settings. The use of both up-sampling and down-sampling settings implies a dynamic adjustment of spatial resolutions at different stages, allowing the model to efficiently process features across various scales. This method ensures an adaptive and resource-efficient mechanism for handling diverse scales in the feature space, thus helping conserve computational resources. The Head part undertakes final detection procedures by applying anchor boxes to collected feature maps from backbone networks and then generating final output vectors that include class probabilities as well as bounding boxes to determine object position and confidence. 34 Additionally, YOLOV5 integrates several data augmentation techniques such as Mosaic data augmentation, 11 adaptive anchor box computation, 35 adaptive image scaling 36 among others aimed at enhancing dataset diversity along with model performance. These data augmentation strategies work coherently with the core components of YOLOV5, enabling object recognition on images varying in size or scale without resorting to traditional anchor boxes and thus providing an ideal platform for future improvement methods.
Optimization loss function
In the context of object detection, the refinement of bounding boxes through regression is a pivotal step, profoundly influencing the accuracy of target localization. This process entails adjusting the anchor boxes. Crucial to this endeavour is the choice of an appropriate loss function, serving as a critical metric for evaluating regression and classification tasks. By default, YOLOV5 employs the CIoU metric to compute bounding box loss, characterized by equations (1)–(3). 34
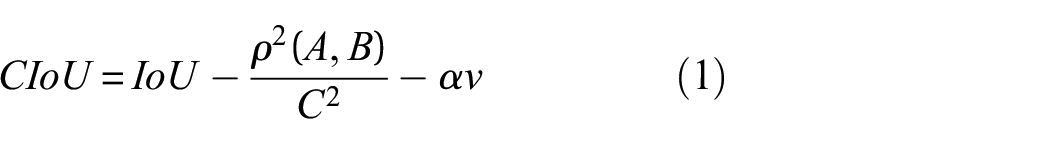
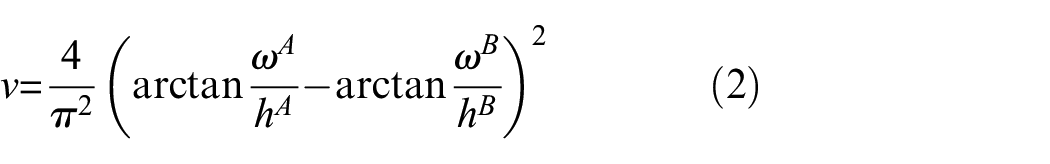

In these equations, “IoU” represents the Intersection over Union, quantifying the overlap between a true box “A” and a predicted box “B.” The definition of IoU is provided in Figure 7. In equation (2), the parameters
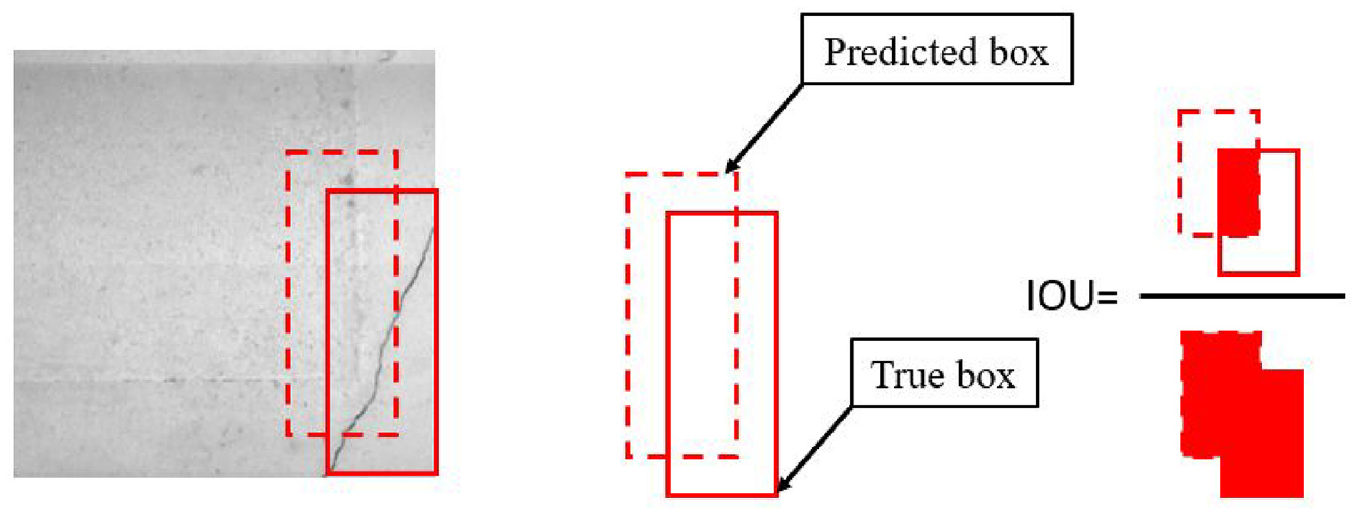
Diagram of the definition of IOU.
Examining equation (1) shows that CIoU accounts for the overlap area, centre point distance, and aspect ratio

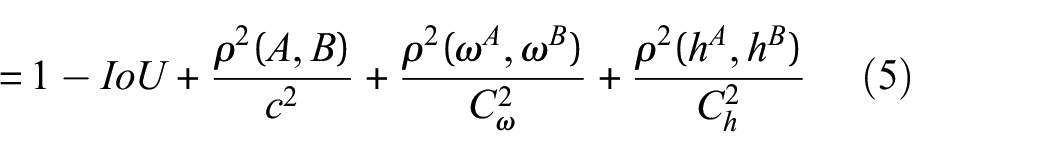
where
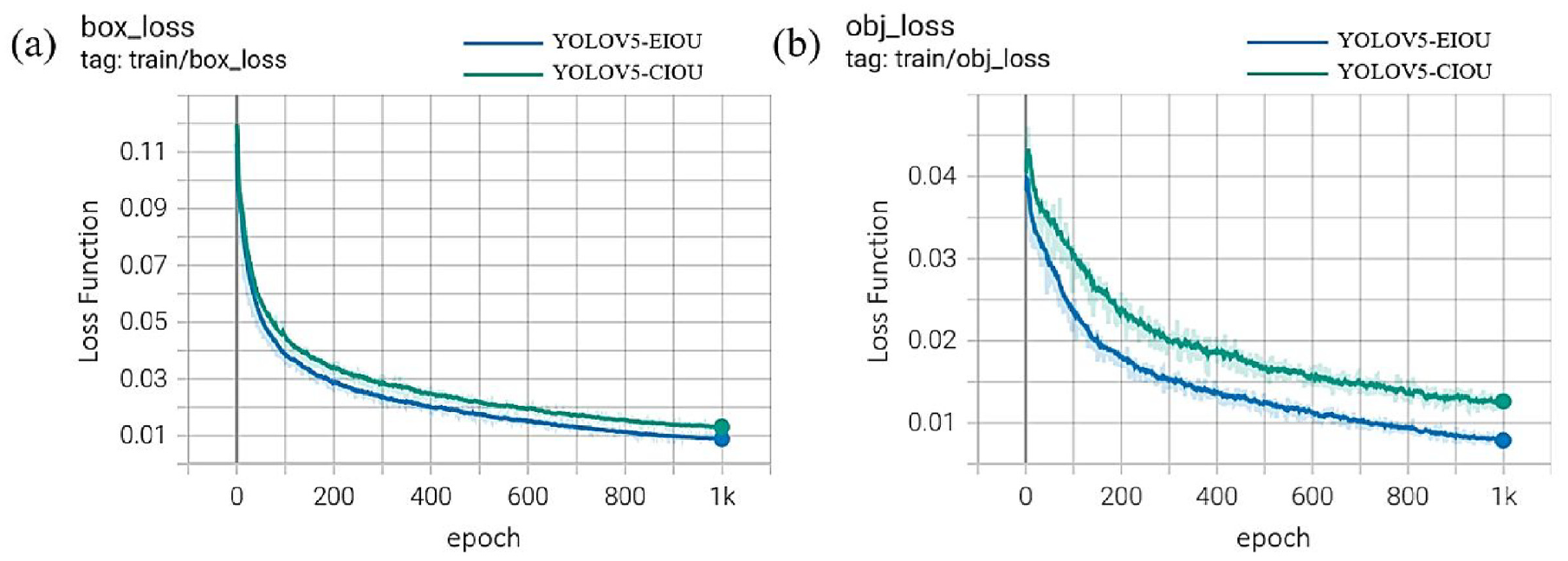
Comparison of the performance using different loss functions: (a) target bounding box loss curve, (b) target kind loss curve.
From Figure 8(a) and (b), it becomes evident that adopting EIoU as a loss function results in a steeper slope in the curve representing losses for the YOLOV5 model. This suggests a faster decline in losses, indicating that incorporating length and width information regarding objective and prediction boxes into the EIoU-based loss function facilitates a more rapid reduction of disparities. This, in turn, enhances the precision of object localization and detection by the models. Moreover, the comparison against optimizing objective box losses underscores the notably superior performance in optimizing type-of-objective losses.
A novel model light-weighting framework
Network pruning
In the realm of deep learning, Network Pruning serves as a fundamental technique aimed at diminishing the complexity of network models. 36 The Network Pruning algorithm necessitates the sparsity training of normalized (Batch Normalization or BN) layers within the network. In this intricate process, a scale factor denoted as γ is introduced for each channel, and it is multiplicatively applied to the output of each channel. Subsequently, layers exhibiting sparsity and smallness are systematically excised based on the distribution of γ and the Network Pruning rate during the concurrent training of weight parameters and the scale factor γ. Notably, the observation stands out that as the central value of the γ scale factor distribution gradually converges toward 0, the corresponding output has a diminishing impact on the overall results of the model. Consequently, model compression is achieved through the removal of these layers, with the specific calculation process elaborated in equation (6).
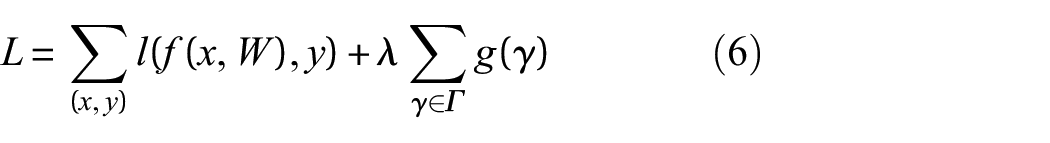
In equation (6), “x” and “y” represent the training inputs and targets, respectively. “W” signifies the trainable weights, and the first summation term embodies the conventional training loss of YOLOV5. The function “g(·)” captures the penalty attributed to the sparsity of the scale factor, and “λ” is the balance loss coefficient. Figure 9 illustrates the BN layer γ coefficient at different sparsity rates (Sr), where Sr represents the sparsity rate. The units of Sr are expressed in percentages, indicating the proportion of layers that undergo sparsity training. Notably, as Sr is incrementally adjusted, the central distribution of the γ coefficients across all BN layers progressively approaches 0, signifying a gradual sparsity in the γ coefficients. At the 84th epoch, the alteration in the sparsity of γ shows only a marginal shift, implying that sparse training has attained a certain level of stability.
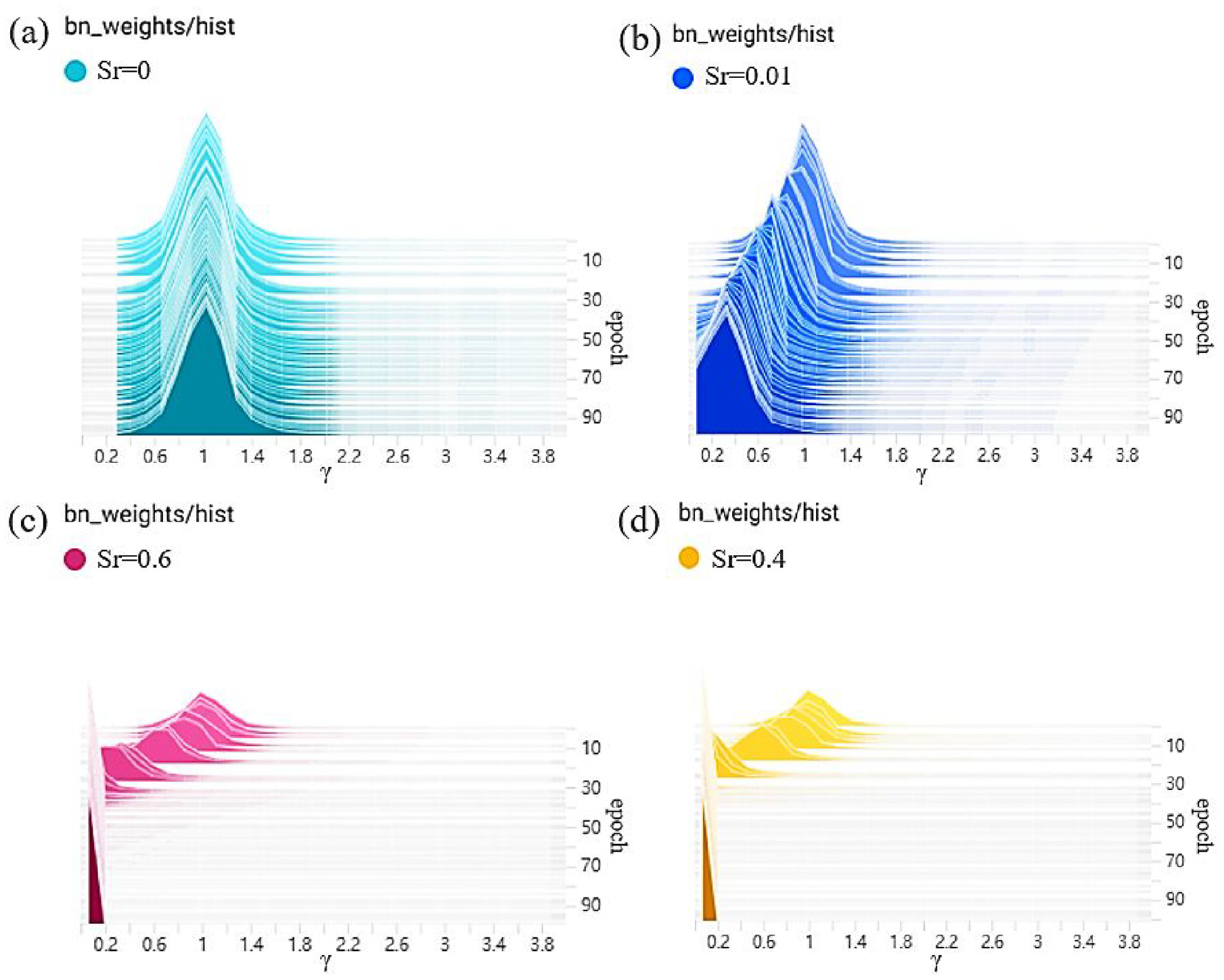
BN layer γ coefficient at different Sr during sparse training: (a) Sr = 0; (b) Sr = 0.01; (c) Sr = 0.6; (d) Sr = 0.4.
While network pruning is effective in reducing the complexity of models, it inevitably leads to a loss of accuracy. Subsequently, a meticulous retraining and fine-tuning process becomes imperative to adapt the model to the new network structure and restore its performance. The comparative analysis of channel counts of the YOLOV5-finetuned model before and after Network Pruning is presented in Figure 10.
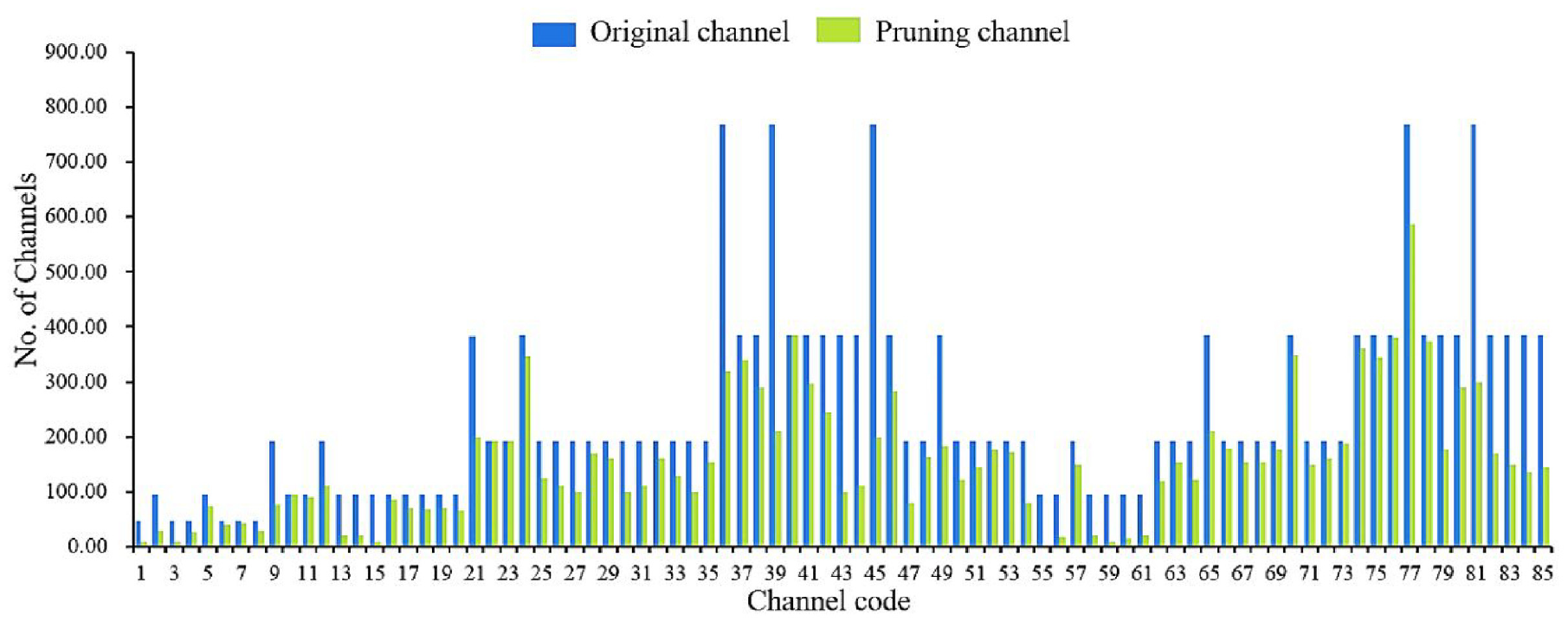
Comparison of the number of channels before and after pruning.
Knowledge distillation
In the context of Network Pruning experiments, fine-tuning can only partially compensate for the performance loss caused by pruning. To further enhance the detection performance of the YOLOV5-finetuned model, this study proposes a method that combines knowledge distillation with Network Pruning. This approach allows the pruned model to learn from a more robust teacher model. Specifically, the original complex backbone detector, YOLOV5-loss, is defined as the teacher model, while the smaller backbone obtained through Network Pruning, YOLOV5-finetuned, is used as the student model. Knowledge distillation, a concept originally introduced by Gou et al., 37 involves transferring knowledge from the teacher model to the student model during training. This is achieved with soft labels and multi-task learning, enabling the student model to maintain performance like that of the larger teacher model while operating at a relatively smaller scale. Figure 11 illustrates the knowledge distillation framework derived from the relationships between features. In this framework, YOLOV5-lite represents the result of distilling YOLOV5-finetuned under the guidance of YOLOV5-loss.
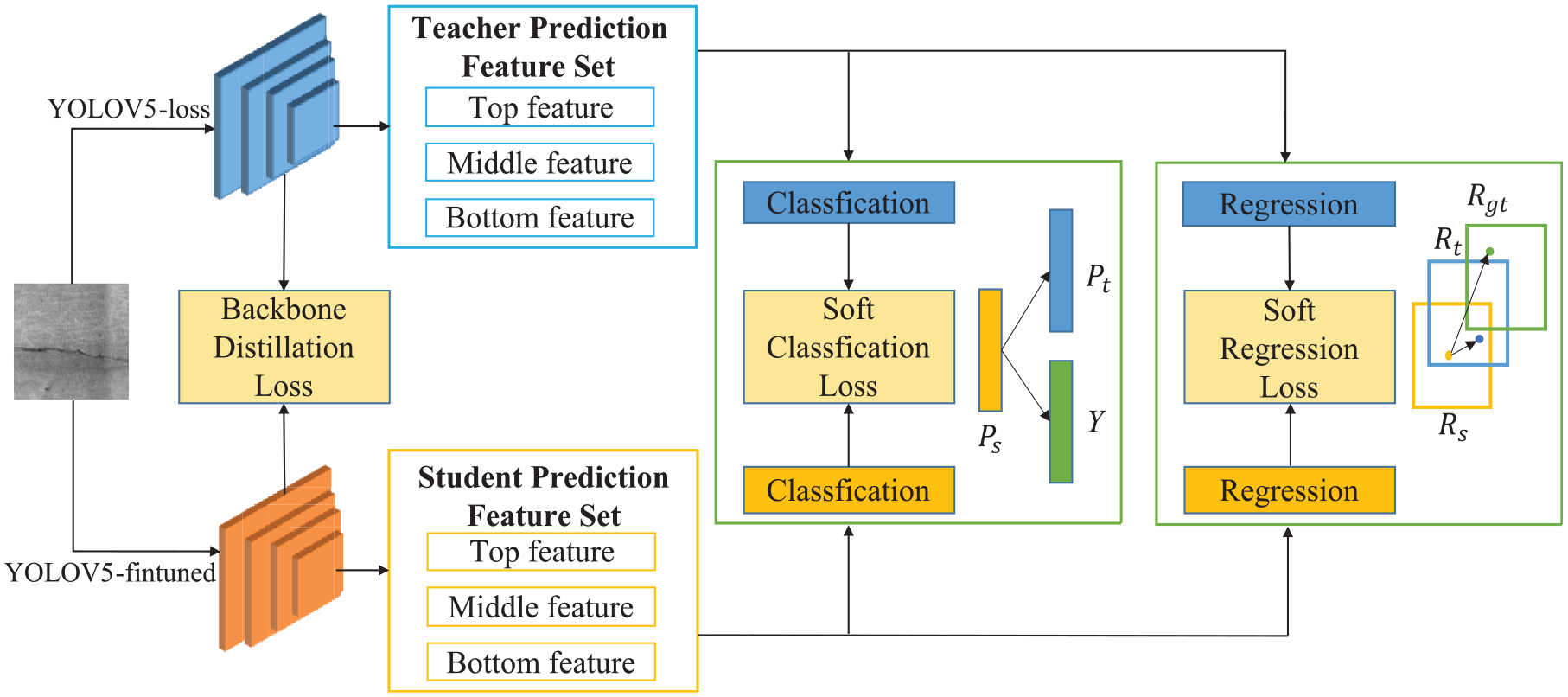
Technology flow of knowledge distillation.
During the distillation process, a function

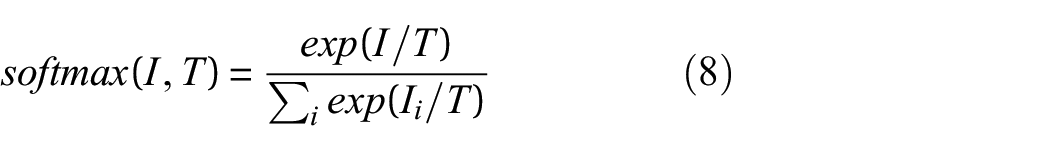
In this equation, “

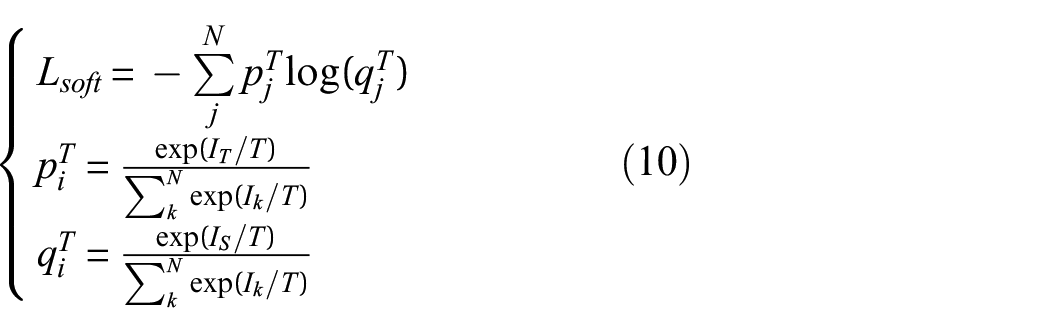
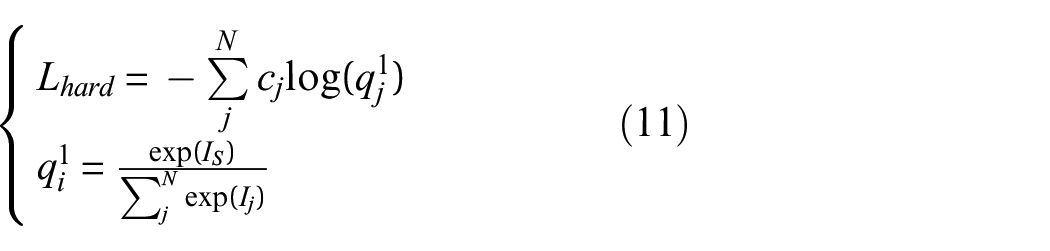
The coefficients α and β in equation (9) represent the balancing coefficients. These coefficients play a crucial role in determining the contribution of soft label distillation loss (
Experiments and results
Evaluation criteria
In the evaluation of the model performance, we consider the presence of two distinct label types in the images: background and object labels. The prediction boxes are categorized as either correct or incorrect, resulting in four sample types for evaluation: true positive (TP), false positive (FP), false negative (FN), and true negative (TN). To assess the effectiveness of the model, we employ three key performance indicators: precision rate, recall rate, and the
The Precision Rate (P), as defined in equation (12), quantifies the accuracy of the model to correctly identify positive samples for tunnel defects. It represents the ratio of samples predicted as positive by the model to those that are indeed positive. A higher precision rate indicates a stronger capability of the model to distinguish negative samples.
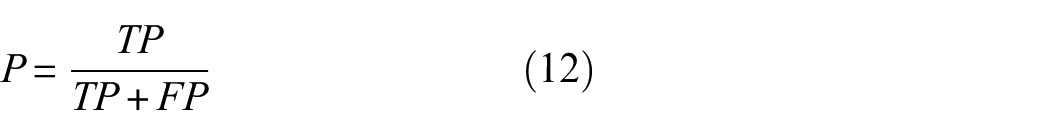
The Recall Rate (R), as defined in equation (13), measures the proportion of actual positive samples correctly predicted as positive. A higher recall rate signifies the proficiency of the model in identifying positive samples:
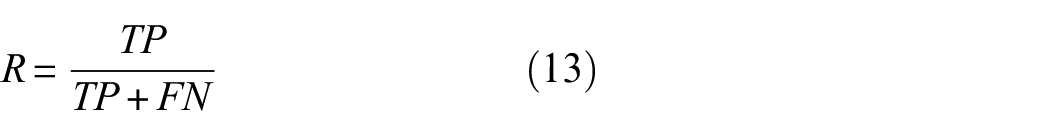
The
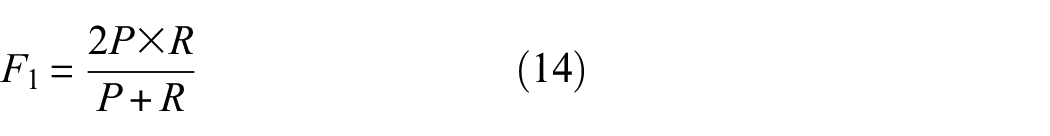
For crack samples in the dataset, TP signifies correct predictions where the predicted box aligns accurately with the actual box, with an IOU greater than a specified threshold. FP indicates instances where background information is erroneously identified as a lining crack. FN accounts for real cracks missed by the detection with the actual box not selected. TN corresponds to cases where the model does not detect any crack. The distinction between lining cracks and other samples is illustrated in Figure 12.
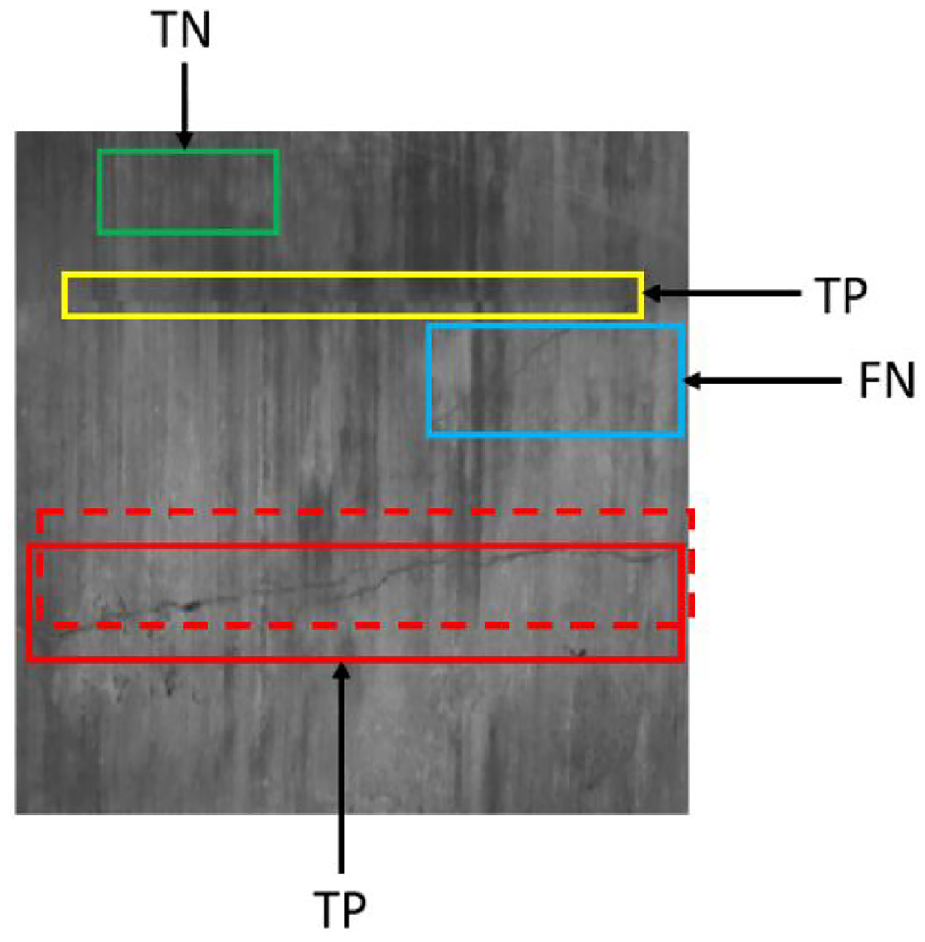
Schematic diagram of positive and negative sample identification.
Apart from the above metric, we employ additional metrics such as the parameter count of the model, its size, and the Frames Per Second (FPS) as indicators to holistically assess its performance. These metrics allow us to optimize accuracy and execution time when considering deployment into mobile devices.
Experiments environment
In order to effectively visualize the impact of Network Pruning and knowledge distillation algorithms on model recognition, we conducted training with four distinct models: the original YOLOV5, the YOLO-loss model with an enhanced loss function, the trimmed and fine-tuned YOLOV5-finetuned model, and the YOLOV5-Lite model with knowledge distillation. All models were configured with a fixed input image size of 640 × 640, a learning rate of 0.001, a momentum of 0.87, and a weight decay of 0.0005. The training process was conducted over 980 iterations, with a batch size of 35. Details of the experimental environment are outlined in Table 1.
Experimental platform.
YOLOV5-lite model recognition results
Considering the varying environmental conditions of cracks within the test set, we selected five distinct interference scenarios, encompassing strong light, similar background, Pipe Joint interference, stain occlusion, and crack discontinuity. The test results of the four models were comprehensively compared, as presented in Table 2. In this table, regions where the model successfully detects cracks are highlighted with red boxes, which are accompanied by numerical values representing the confidence level in target determination.
Detection results of the test set for different models.


Upon a meticulous examination of the presented results, it is evident that the YOLOV5 model adeptly mitigates interference caused by factors such as similar backgrounds, strong lighting, and segment splicing. It consistently and accurately identifies crack locations, confidently exceeding the confidence threshold of 0.8. In contrast, YOLOV5-loss and YOLOV5-lite exhibit superior performance when it comes to detecting smaller targets, particularly tiny and discontinuous cracks. However, it should be noted that the model YOLOV5-finetuned after Network Pruning displays instances of missed detections, particularly in the context of small and discontinuous cracks. This observation suggests that the removal of feature channels with limited information during Network Pruning in the convolutional layers results in incomplete learning of target features by the model. This deficiency explains the observed decline in network accuracy after post-pruning.
There is a risk of misidentifying Pipe Joint as targets due to the challenges of overfitting and underfitting by deep learning algorithms. In our detection results, all four YOLO models demonstrate robust feature differentiation between Pipe Joint and target cracks, effectively avoiding any misdetection anomalies. In particular, YOLOV5-loss achieves an impressive recognition accuracy of 0.97. Even with a 18.7% reduction in accuracy following fine-tuning, YOLOV5-finetuned after distillation maintains a high recognition accuracy of 0.96, with a negligible 0.1 difference from the recognition accuracy of the teacher network (YOLOV5-loss). This underscores the effectiveness of the proposed knowledge distillation framework, enabling YOLOV5-finetuned to acquire diverse object knowledge from YOLOV5-loss and rectify the decrease in model detection accuracy observed during the pruning process.
To visualize the model performance, the Precision-Recall (P-R) curve, widely used for assessing models in binary classification, is introduced in this study. Generally, the model performance is considered better when the P-R curve is closer to the upper right corner of the coordinate system. This implies a high recall rate and high precision simultaneously. As illustrated in Figure 13, YOLOV5-loss, post the replacement of the loss function, exhibits superior performance. In contrast, YOLOV5-finetuned, subjected to channel reduction through the Network Pruning algorithm, experiences a significant degradation in performance, characterized by poor precision and recall. Furthermore, a noteworthy observation is the similarity in performance between YOLOV5 and YOLOV5-lite. This observation indicates that the proposed framework for knowledge distillation can effectively ameliorate the loss in YOLOV5-finetuned models.
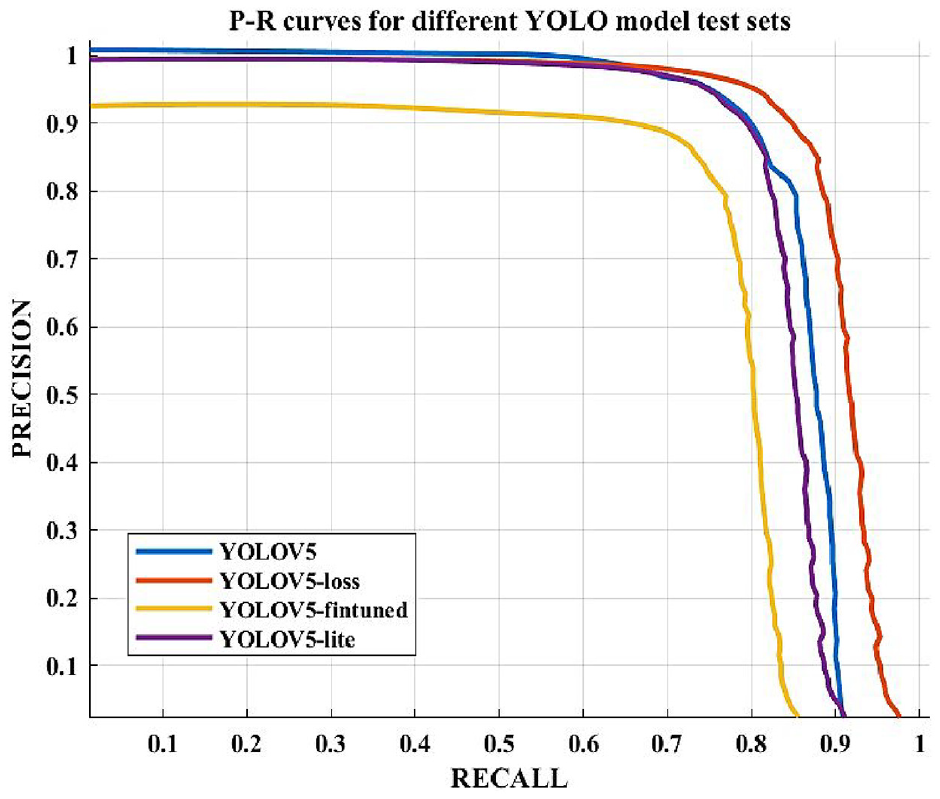
P-R curves for different YOLO models.
Different models comparative analysis
To substantiate the superiority of the proposed YOLOV5-Lite model in tunnel lining crack detection, this study conducts a comprehensive comparison of parameters and detection results between several models, including YOLOV5, the Network pruned model YOLOV5-finetuned, YOLOV3, and the two-stage detection model Faster R-CNN.
The expanded sample dataset was utilized to train five different network models, and their performance was subsequently validated using the test set. The comparative outcomes are presented in Table 3.
Comparison of parameters before and after pruning of model channels.
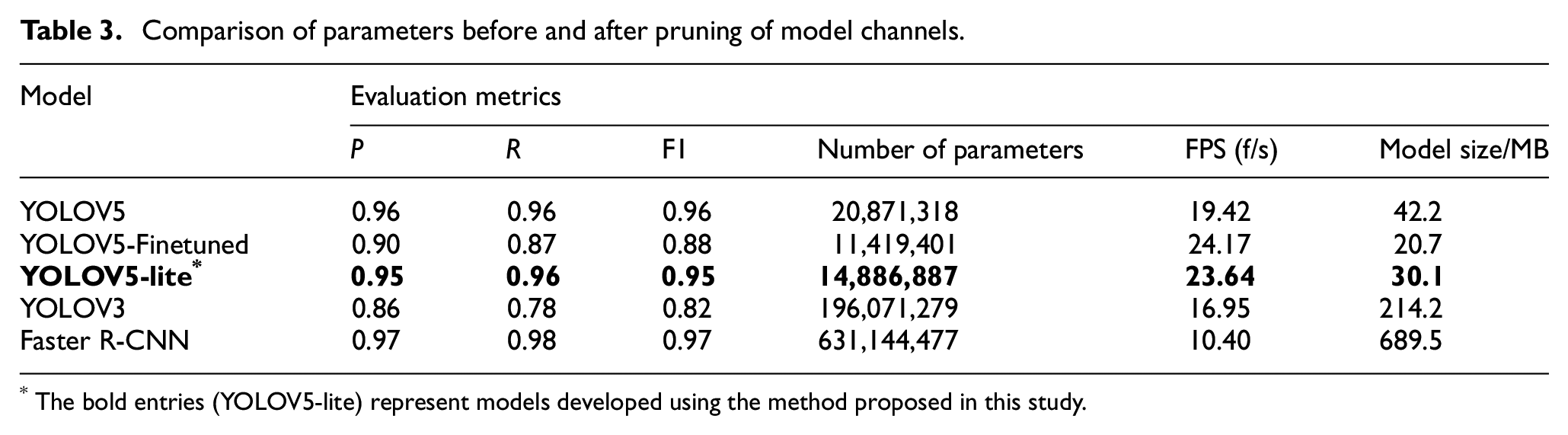
The bold entries (YOLOV5-lite) represent models developed using the method proposed in this study.
The comparison as shown in Table 3 and Figure 14 shows that YOLOV3 exhibits the weakest performance in identifying genuine positive samples in the dataset, with a recall rate of only 78%. In contrast, Faster R-CNN excels in precision (P), recall (R), and
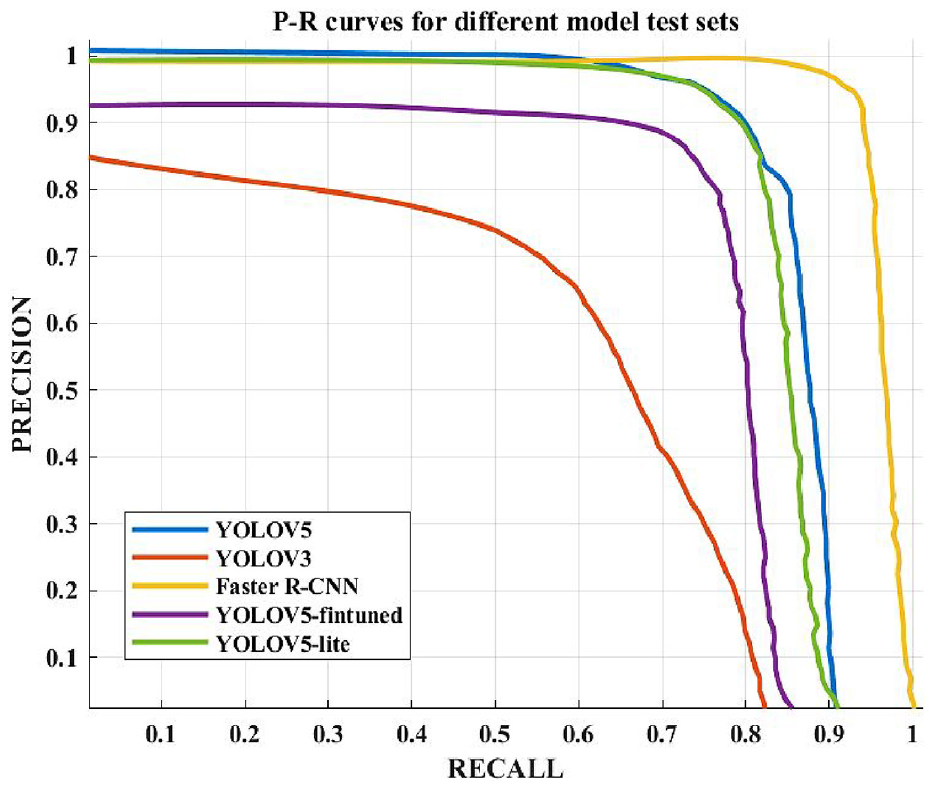
P-R curves for different models.
In terms of detection speed reflected by the detection FPS, Faster R-CNN lags behind the other four models due to its reliance on two networks for feature extraction and candidate box classification. In contrast, YOLOV5-Lite achieves a commendable crack recognition speed of 23.64 f/s, which is only marginally lower than the FPS of the YOLOV5-finetuned model, with a minimal gap of 0.53 f/s. Regarding model size, Faster R-CNN stands out as the largest, with a size of up to 689.5 MB, clearly unsuitable for deployment in lightweight models. In contrast, the lightweight approach proposed in this paper significantly reduces the size of the YOLOV5-Lite model, making it 184.1 MB smaller than YOLOV3 and 12.1 MB smaller than YOLOV5, rendering it far more suitable for resource-efficient deployment.
Taking all these aspects into consideration, YOLOV5-Lite emerges as an optimal choice capable of delivering high-precision recognition performance within resource-constrained environments.
Discussion
Effectiveness
The tunnel crack detection model must achieve a balance between precision and model size to meet the real-time processing demands, particularly in environments with limited computational resources. By integrating EIoU, network pruning, and knowledge distillation, our YOLOV5-Lite model significantly enhances crack detection performance while optimizing computational efficiency. Specifically, the combination of network pruning and knowledge distillation results in a notable reduction in parameters and model size by 42.9% and 50.9%, respectively, while increasing the detection FPS by 24.4%. These improvements ensure that the model is capable of real-time crack detection. Furthermore, the innovative knowledge distillation framework leverages learning from YOLOV5-loss, elevating the accuracy and recall rates of YOLOV5-Lite to 95% and 96%, respectively. This approach mitigates the performance degradation typically associated with the pruning process and ensures versatility across various modern detectors. As a result, YOLOV5-Lite achieves a substantial reduction in model size, being 184.1 MB smaller than YOLOV3 and 12.1 MB smaller than the original YOLOV5. These enhancements make it highly suitable for deployment in environments with stringent computational constraints without compromising detection performance.
Shortcomings and future works
Despite the proposed method demonstrated exemplary performance in tunnel crack detection, it had some shortcomings. Firstly, despite achieving significant reductions in model size and parameter count, YOLOV5-Lite faces challenges in real-time detection within highly dynamic environments. To overcome this, more aggressive pruning techniques or alternative lightweight architectures, such as MobileNets or SqueezeNets, should be explored. Additionally, incorporating real-time optimization methods, such as TensorRT or FPGA acceleration, can further enhance processing speed without compromising accuracy.
Moreover, the YOLOV5-Lite model, although effective under various interference scenarios such as strong light and similar backgrounds, shows limitations in complex environments. Specifically, it struggles with severe occlusions and highly discontinuous cracks, leading to false negatives and false positives. To mitigate these issues, future work should investigate preprocessing techniques like multi-scale processing and super-resolution. Additionally, augmenting the training dataset with more diverse and representative samples will enhance the model’s robustness in challenging conditions.
Conclusions
The integration of deep learning-based crack detectors into hardware devices with limited computational resources faces challenges associated with the substantial size of the detection model. This study addresses this concern through the synergistic application of the Network Pruning algorithm and knowledge distillation technology, culminating in the refinement of the YOLOV5 model. The key conclusions derived from this investigation are presented as follows:
Refinement of Loss Function and Network Pruning: The substitution of the EIoU for the CIoU in refining the loss function is pivotal, particularly given the small size of cracks as detection targets. This adaptation minimizes height and width loss between the target box and the prediction box, expediting model convergence. Besides, the incorporation of the Network Pruning algorithm significantly reduces model parameters and size by 42.9% and 50.9%, respectively. Specifically, the model size was reduced from 70.8 to 34.7 MB, and the number of parameters decreased from 7.1 to 4.05 million. This reduction is coupled with a commendable 24.4% increase in FPS, enhancing the capacity of the model for real-time crack detection, with FPS improving from 19.0 to 23.64. This substantial reduction in size without compromising performance demonstrates the effectiveness of Network Pruning in optimizing deep learning models for deployment in resource-constrained environments.
Innovative Knowledge Distillation Framework: Departing from traditional approaches that append fine-tuning stages to mitigate performance degradation in Network Pruning, this study proposes a novel knowledge distillation framework that amalgamates knowledge distillation and Network Pruning. The collaborative learning from YOLOV5-loss improved the accuracy of YOLOV5-Lite to 95.8% and recall to 96.3%, compared to the original YOLOV5 model’s accuracy and recall of 87.3% and 87.0%, respectively. This adaptation also results in a substantial 28.67% reduction in model size compared to the original YOLOV5 model. The introduced knowledge distillation framework presents a versatile approach applicable to a wide array of modern detectors, showcasing adaptability and efficiency.
Efficient YOLOV5-Lite Model for Resource-Constrained Environments: The research findings underscore the efficiency of the proposed YOLOV5-Lite model in facilitating automated tunnel lining crack identification, even in resource-constrained computing environments. The seamless deployment of the model on mobile platforms with limited computational capabilities positions it as a promising solution for practical applications. The introduced feature extraction framework, demonstrating effectiveness in emulating information function while suppressing non-informative feature interrelationships enhances the versatility of the model. This feature extraction framework presents an avenue for broader applications across diverse detectors.
Future Research Directions: The YOLOV5-Lite model, tailored for resource-constrained environments, holds promise for deployment on mobile platforms. Future research endeavours may explore the incorporation of an image acquisition module, enabling real-time crack detection and subsequent data transmission to clients. The challenges and focal points identified in this study pave the way for continued exploration and refinement of detection models in the context of hardware limitations, contributing to the evolution of efficient, deployable solutions for crack identification.
In conclusion, the amalgamation of innovative methodologies, such as EIoU-based loss refinement, Network Pruning, and knowledge distillation, presents a comprehensive approach to enhance the efficiency and applicability of crack detection models. This study not only provides a reference and guidance for the monitoring and management decisions of tunnel structures but also lays a foundation for future research endeavours in real-time detection on resource-limited devices.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.