
Abstract
The dynamic structural load identification capabilities of the gated recurrent unit, long short-term memory, and convolutional neural networks are examined herein. The examination is on realistic small dataset training conditions and on a comparative view to the physics-based residual Kalman filter (RKF). The dynamic load identification suffers from the uncertainty related to obtaining poor predictions when in civil engineering applications only a low number of tests are performed or are available, or when the structural model is unidentifiable. In considering the methods, first, a simulated structure is investigated under a shaker excitation at the top floor. Second, a building in California is investigated under seismic base excitation, which results in loading for all degrees of freedom. Finally, the International Association for Structural Control-American Society of Civil Engineers (IASC-ASCE) structural health monitoring benchmark problem is examined for impact and instant loading conditions. Importantly, the methods are shown to outperform each other on different loading scenarios, while the RKF is shown to outperform the networks in physically parametrized identifiable cases.
Keywords
Introduction
The four fundamental structural identification problems in civil structures 1 are (i) computing the dynamic responses with known structure parameters and loads,2–12 (ii) solving or recovering the structural parameters based on known responses and excitations,13–16 (iii) identifying or estimating the structure input loads using some structure parameters and responses,17–28 and (iv) identifying or estimating the structure input loads using only the structure responses.29–41 The first one is a forward problem, while the rest are inverse problems. While the forward problem has been researched extensively for a long time, the inverse ones, and in particular the load identification or estimation, attracted attention only recently.
The structural load, specifically, is an integral part of the system identification and monitoring process as the analytical or the numerical structural models, inevitably, are much better calibrated by input–output identification processes.42–44 It is particularly useful for civil engineering structures since the loading is difficult to be estimated or measured due to the stochastic environment. In the input–output identification scenario, though, the required input cannot always be measured, or the measurement of the input may be more unreliable than what is demanded. For instance, there is not a reliable means of accurately measuring the traffic and wind load on large structural systems.45–47
To this end, several methodologies have been created to provide the structural load identification, but often they are either refer to linear systems or the methodologies are examined only on systems with no input at some degrees of freedom (DOFs). This is not the case for all civil structures; for instance, the ones which are excited at the base. Furthermore, many works examine inputs which have zero mean value, that is, white noise or some seismic excitations, excluding cases such as a hammer dynamic test scenario. As a result, these methods do not always succeed on realistic complex civil structures and a need for further investigation arises.
The importance of the dynamic structural load identification, specifically, is highlighted by the fact that a more detailed model needs to fit the parameters with even greater accuracy. This requires proper parameter sensitivity in order for the parameters to be estimated correctly. Furthermore, the load identification is also beneficial for the optimal sensor placement.48–55 The philosophy behind those approaches is to minimize the information entropy after quantifying the uncertainty in the system parameters. This is used as a sensor configuration performance measure. The knowledge of the structural loading significantly improves the uncertainty quantification in the structural identification and, as a result, leads to a better estimation of the information gained during the model updating process.
Output-only system identification techniques, on the other hand, have also a long history of assessing the structural condition when performed during their normal operation with ambient vibration data. In this direction, the stochastic modal identification techniques are introduced from output-only data, combining high computational robustness efficiency with high estimation accuracy. To address the nonautomated identification issue in output-only procedures extensive research is performed, and it is still ongoing. Rainieri and Fabbrocino 56 presented a literature review for the most common automated output-only dynamic identification techniques. However, those methodologies are very sensitive to the noise level which often results in inaccurate estimates. This highlights the importance of identifying the loading.
To address the challenge of load identification, the deep learning architecture libraries are employed in this work. In the last few years, machine and deep learning resulted in a substantial impact on a variety of civil engineering problems,57–59 or other problems such as visual recognition, speech recognition, and natural language processing. Among different types of deep neural networks, convolutional neural networks are studied the most.60–74 The convolutional neural network (CNN) is a deep learning architecture inspired by the natural visual perception mechanism of the living creatures. Hubel and Wiesel 75 noticed that cells in animal visual cortex are responsible for detecting light in receptive fields. Based on this, Kunihiko Fukushima proposed the neocognitron, 76 which could be regarded as the predecessor of CNN. LeCun et al., 77 later, developed a multilayer artificial neural network called LeNet-5 which could classify handwritten digits. 77
To overcome the shortcoming of deep neural networks of being difficult to be trained78,79 due to the exploding-vanishing gradient issue when learning long-term dependencies, the long short-term memory (LSTM) architecture 80 is introduced. Importantly, the LSTM network is designed to capture long-range data dependencies on modeling sequential data such as the dynamic load, and shows a great potential in modeling structural loading time series, 81 or in other applications.6,82,83
In the same direction, the gated recurrent unit (GRU) neural networks 84 have shown success in several applications involving sequential or temporal data. 85 GRU success is attributed to the gating network signaling. This controls how the present input and previous memory is used to update the current activation and produce the current state. These gates have their own sets of weights which are adaptively updated in the learning phase.
Intelligent methods for dynamic load identification 86 currently focus on vehicle loads,87–89 component and mechanical structures loading,81,90–103 bridge cables loading, 104 and power loads. 105 They have been recently investigated in structural dynamics, but with pseudo-experimental data at the Pirelli Tower in Milan, Italy. 106
In this work which focuses on full scale building structures with real experimental data, the structural response and loading are employed to train the neural networks, and finally predict unseen loading data. In doing so, the work contributes to the dynamic load identification research assessing the networks in the uncertain outcome related to obtaining poor predictions when in civil engineering applications only a low number of tests are performed or are available, or when the structural system is unidentifiable with physical parameter-based modeling. The networks are compared when overcoming those issues, while Kalman filter physics-based alternatives, without assuming more information such as known system parameter of the model, 41 are also employed. A realistic small dataset scenario prone to outliers is investigated for civil engineering applications in contrast to hundred or even thousands of available data which are assumed for other applications. This problem is crucial since it potentially leads to overfitting the model when it is adjusted excessively to the training data, seeing patterns that do not exist, and consequently performing poorly in predicting new data.
The work is organized as follows: the LSTM network is overviewed in section “Dynamic load identification using the LSTM neural networks,” while in section “Dynamic load identification using the GRU neural networks,” the improved and faster GRU is presented. The standard CNN architecture is provided in section “Dynamic load identification using 1D CNNs,” as well as a discussion on the one-dimensional and the multidimensional CNN versions. The physics-based RKF is then presented in section “Dynamic load identification using physics-based residual Kalman filtering.” Importantly, sections “Structural loading identification in a 6-story building,”“Structural loading identification for a hotel in San Bernardino,” and “Structural loading identification in the IASC-ASCE structural health monitoring benchmark problem” investigate applications on both simulated and real structures, as well as on both continuous and impact loading cases. Subsequently, section “Discussion” presents a discussion and section “Future research” future research suggestions. Finally, the conclusions are provided in section “Conclusion.”
Dynamic load identification using the LSTM neural networks
The LSTM neural networks are a type of recurrent neural networks (RNNs) which are designed to handle the vanishing gradient problem in the traditional RNNs. The vanishing gradient problem occurs when the gradients of the error function with respect to the weights in the RNN become very small. This makes it difficult for the network to learn long-term dependencies.
The standard LSTM architecture consists of several memory cells that can store information for long periods of time, as well as several gates which regulate the flow of information into and out of the cells, seen in Figure 1. The gates are controlled by sigmoid activation functions and can either allow or prevent information from passing through. The LSTM cell has three gates: the forget gate, the input gate, and the output gate. The forget gate determines which information to discard from the previous cell state, the input gate determines which new information to add to the current cell state, and the output gate determines which information to output from the current cell state. The equations governing the LSTM cell are written as
where
Examined network architecture for all applications as described in section “Structural loading identification in a 6-story building.” The LSTM–GRU–Conv layer is replaced each time by each one of the three considered layers. The dropout layer is removed in the 1D-CNN case.
To train a LSTM neural network, the structural load and response set of input–output pairs are provided, also known as training data. During training, the network adjusts its weights and biases to minimize a loss function, which measures the difference between the predicted and actual output values. The loss function used to train the LSTM depends on the specific task. In the context of predicting structural loading based on the structure response, a common choice is the mean squared error between the predicted and actual loading values, mathematically written as

where
Dynamic load identification using the GRU neural networks
GRU neural networks, on the other hand, are another type of RNN which, similar to the LSTM case, are designed to handle the vanishing gradient problem in traditional RNNs. GRUs are similar to LSTMs in that they also use gating mechanisms to regulate the flow of information. They are simpler and more computationally efficient, though.
The GRU architecture also consists of memory cells that can store information for long periods of time, as well as several gates that regulate the flow of information into and out of the cells (Figure 1). The gates are controlled by sigmoid activation functions and can either allow or prevent information from passing through. The GRU cell has two gates: the reset gate and the update gate. The reset gate determines how much of the previous state to forget, while the update gate determines how much of the new state to add to the current state. The equations governing the GRU cell are written as
where
To train a GRU neural network, the structural load and response set of input–output pairs are also provided. It adjusts its weights and biases to minimize a loss function which measures the difference between the predicted and actual output values. The loss function used to train the GRU also depends on the specific task. In the context of predicting structural loading based on structural response, a common choice is the mean squared error between the predicted and actual loading signals. The GRU network is trained using backpropagation through time, similar to LSTMs, which involves computing the gradient of the loss function with respect to the weights and biases at each time step.
Dynamic load identification using 1D CNNs
Finally, the one-dimensional convolutional neural networks (1D CNNs) have been proven to be highly effective in a variety of signal processing tasks. The fundamental building block of a 1D CNN is the convolutional layer (Figure 1). A convolutional layer applies a set of filters to the input signal, producing a set of feature maps. The filters have a fixed size and slide over the input signal, computing a dot product at each location. The resulting feature maps capture different aspects of the input signal, such as local trends and patterns.
The applied 1D CNN compares to the multidimensional counterparts as follows: A one-dimensional configuration fuses the feature extraction and the learning phases of the dynamic states. One-dimensional arrays are used instead of two-dimensional matrices for both the kernels and the feature maps. Additionally, the network architecture has the hidden neurons of the convolution layers which perform both the convolution and the subsampling operations. Accordingly, the convolution and the lateral rotation are replaced by their one-dimensional counterparts, namely the convolution and the reverse operations. Finally, the parameters for the kernel size and the subsampling are scalars. Importantly, this simplified structure of the convolution neural network requires only one-dimensional convolutions and therefore, a mobile and low-cost hardware implementation for near real-time applications. The convolution operation is represented mathematically as

where
In practice, a 1D CNN may have multiple convolutional layers with different filter sizes and numbers of filters. Each layer can apply a different set of filters to the input signal, allowing the network to capture different aspects of the signal at different scales. No additional layers are assumed in this work for the 1D CNN (such as pooling layers) to compare fairly all networks.
To train the 1D CNN, the structural load and response set of input–output pairs are also provided. During training, the network adjusts its weights and biases to minimize the loss function, which measures the difference between the predicted and actual loading values. This is done using an optimization algorithm such as the stochastic gradient descent. This updates the weights and biases based on the gradient of the loss function.
For all three networks discussed in this work, in addition to the training data, it is important to have a separate set of validation data to monitor the training performance of the network to avoid overfitting. The validation data are used to evaluate the network’s performance on unseen data, and the training process can be stopped early if the performance on the validation data starts to deteriorate.
Dynamic load identification using physics-based residual Kalman filtering
For the mathematical implementation of the unknown input residual-based Kalman filter 41 consider the process equation in the continuous-time and the state-space format:
where
The discrete-time transformation of the system and the input matrices is provided by the zero-order hold assumption for the input in between the time instants
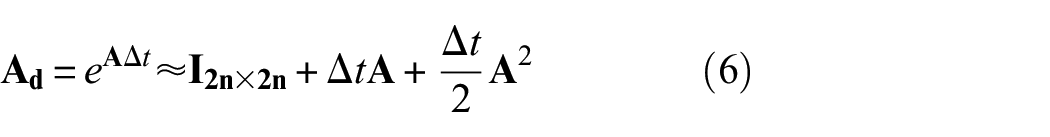
and
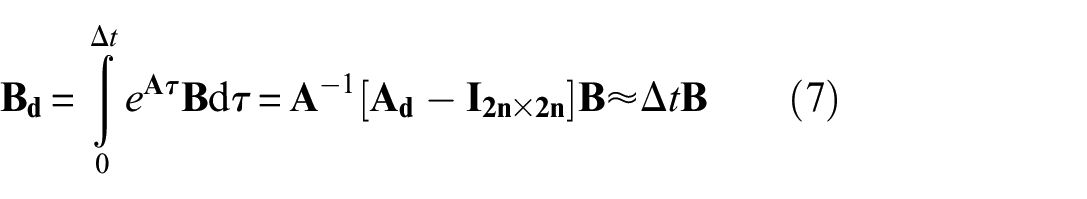
The state-space model of Equation (5) in the discrete-time, including the noise term

where
The equation which relates the measurements

where
It may seem here that the acceleration responses are not covered by the observation matrix. However, this is chosen intentionally since it addressees two problems. First, the unknown input and parameters have not yet been estimated for the step
More importantly, the presented observation model reflects the model for the pseudo-measurements rather than the actual measured quantities. In that case, the actual observation model, which relates the observed quantities to the state vector, is not defined. To clarify how different measurement scenarios are accommodated within this approach and at which step they weigh in, the reader is referred to Impraimakis and Smyth. 41
The predicted covariance matrix

where the discretized process and observation covariance matrices are
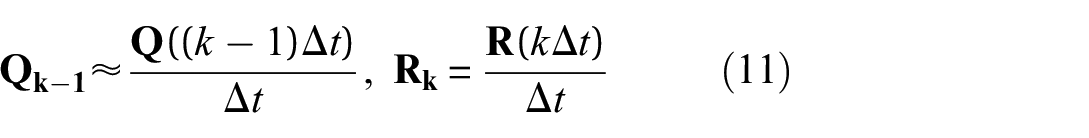
It is assumed, though, that the matrices are constant during the whole process, where being constant does not harm the estimation success. An investigation of their exact value, which importantly highly affects the success of the estimation, 107 is shown in Refs. 41 and 108.
Having provided the posterior prediction model for the dynamic states and their covariances, the update process starts according to the Kalman filter. The updated dynamic state estimate is specifically derived by a correction of the predicted dynamic states using the measurement pre-fit residual. This is multiplied and controlled by the optimal Kalman gain

where the pre-fit residual covariance

The final estimation of the posterior dynamic states is then given by
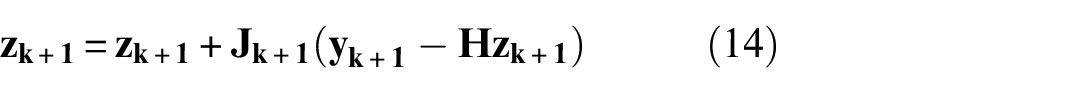
while the final estimation of the covariance of the dynamic states is given by

For Equations (14) and (15), the same quantity on the right and left hand side implies that they are re-calculated at the same time step. The a priori estimate of the right hand side is used for the calculation of the a posteriori estimate on the left hand side.
Once the dynamic states are filtered using the pseudo-measurements and with the use of the parameters of the prior step, the input at the current step is approximated by the system model at the time instant

where
For instance, the full expression of
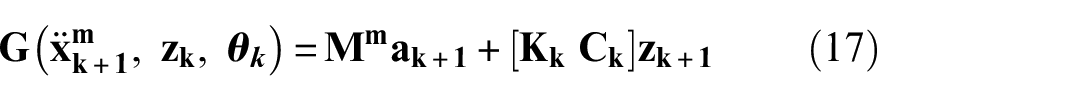
where
For the parameter estimation, a sensitivity analysis approach is implemented by the Taylor series expansion truncated after the linear term. To provide a real-time estimation specifically, the measured outputs are chosen to be accelerations instead of the modal parameters, written as
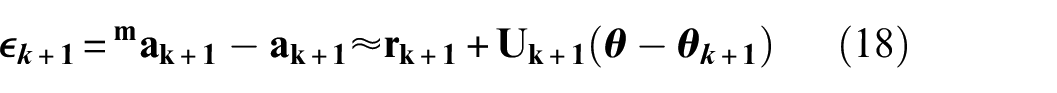
where

where the error
At each step, Equation (18) is solved by a Gauss–Newton gradient approach. The prior parameter estimates are corrected as

where
For Equation (20), the residual of the system model estimation is
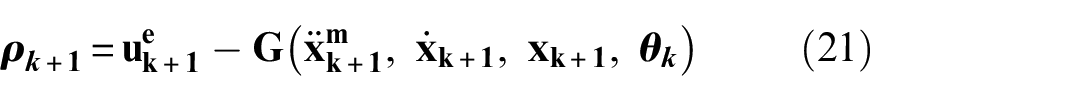
where
For the objective function, the least square approach is formulated based on an additional scaling parameter
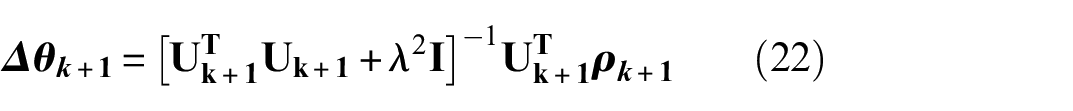
where
Regarding the derivation process of Equation (22), it is provided as the optimal solution of the objective function minimization. Here, the scaling parameter
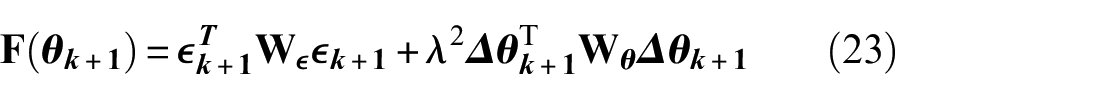
where a penalization exists for the differences between the estimated parameters and the output error. Further derivation details are provided in Impraimakis and Smyth. 41
Structural loading identification in a6-story building
For the numerical application of the GRU network, LSTM network, convolutional network, and residual-based Kalman filter for structural load identification with small datasets, consider the 6-story shear-type structure of Figure 2. The structure is described by the following equation:
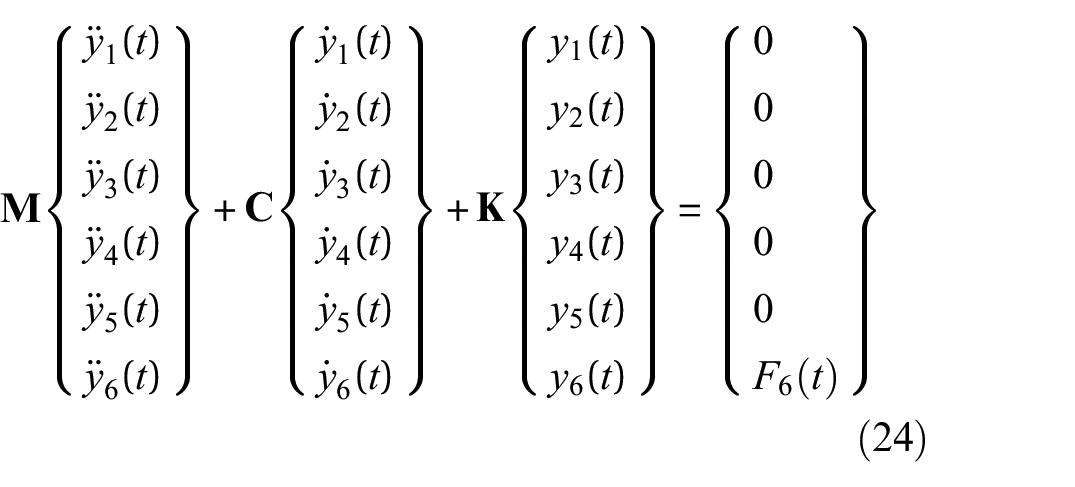
for a shaker-type load input

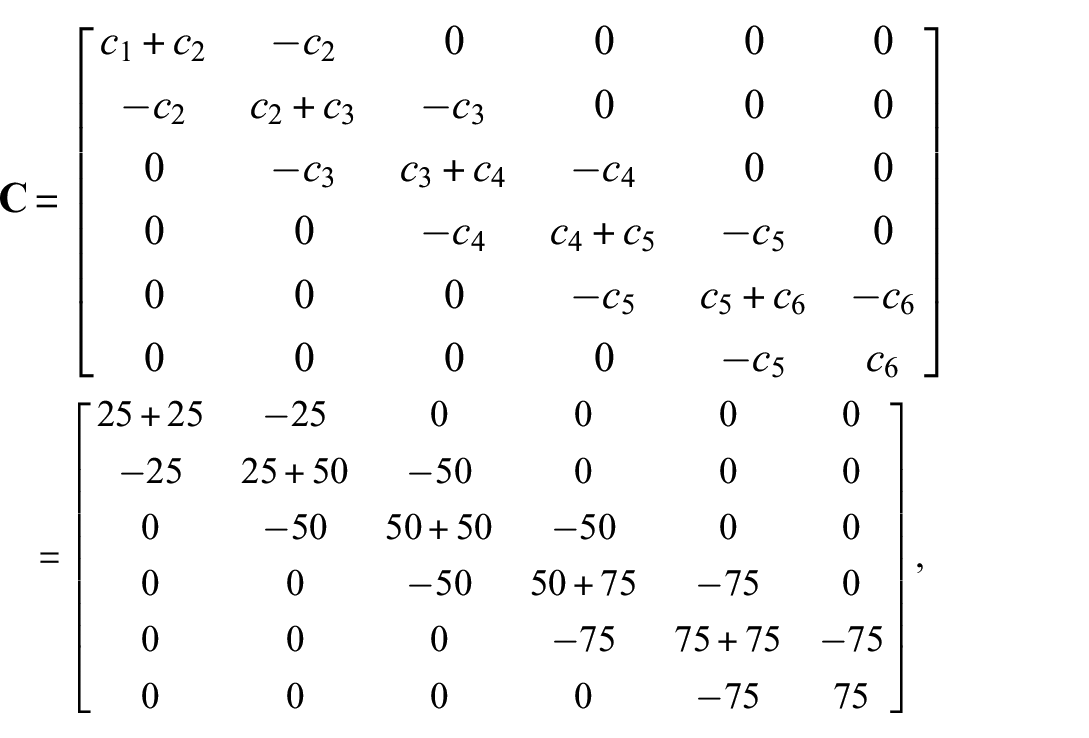
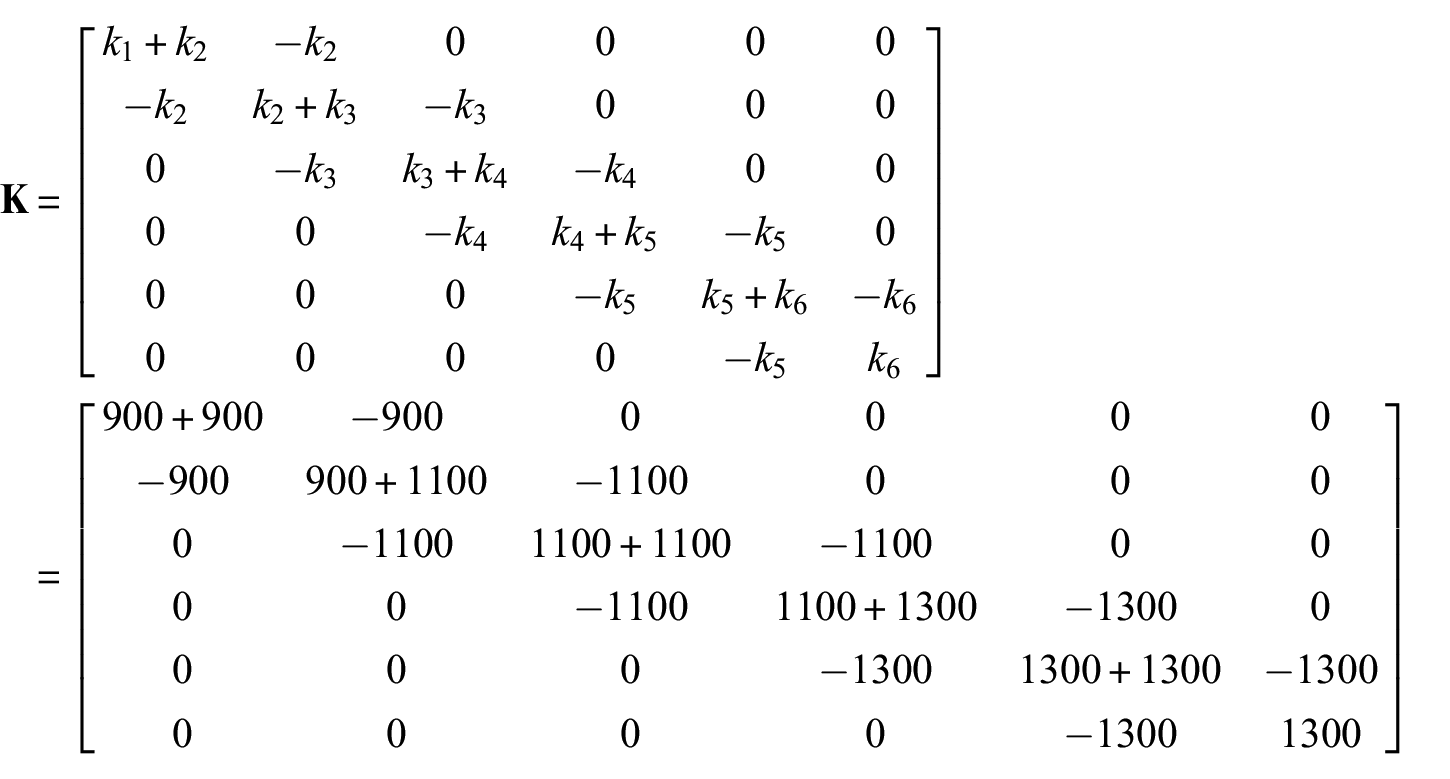
with initial conditions
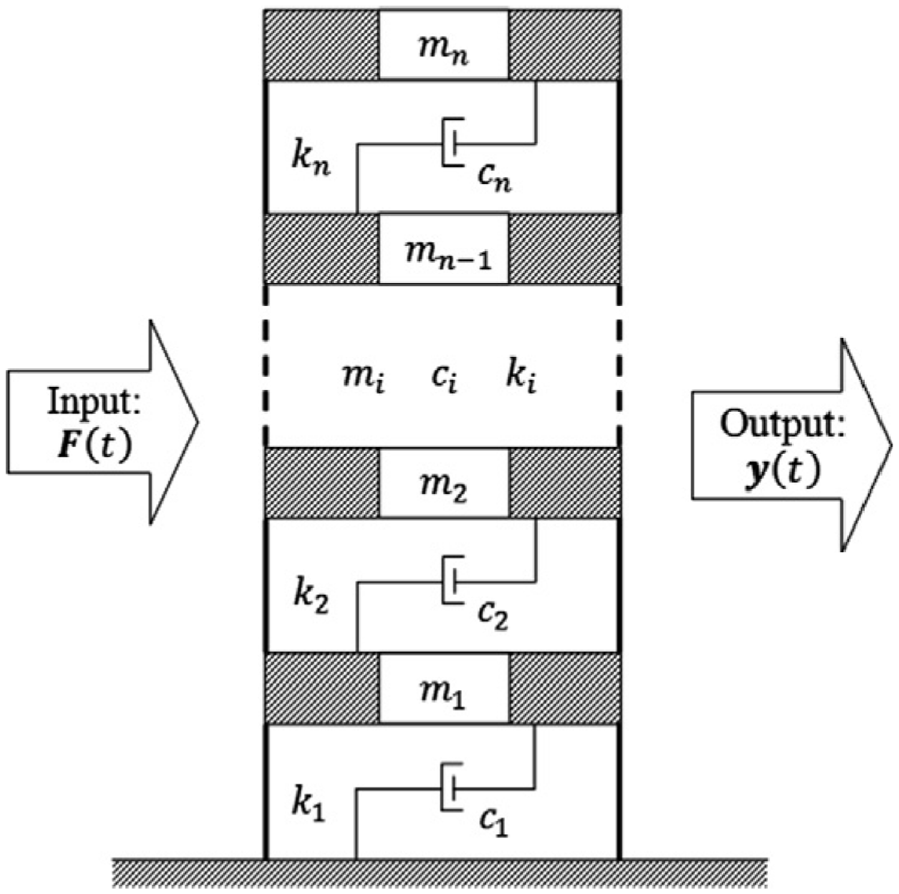
6-story shear-type building structure of section “Structural loading identification in a 6-story building.”
In order to create synthetic measurements, the Runge Kutta fourth order method of integration is utilized to compute the system response for 200 s. The sampling frequency for the dynamic state measurements is considered to be 100 Hz. Therefore, the time discretization
A total of 21 available datasets from the simulations are formatted and divided into three subsets, including 11 datasets for training, four datasets for validation, and six datasets for prediction of the structural loading. For the Kalman filter, the identification is performed in real time, without any training. Importantly, for the shear-type building study, despite being numerical, the datasets for training, validation and test are so small, for instance, only 11 datasets for training, to match and directly compare to section “Structural loading identification for a hotel in San Bernardino” case, where also 11 datasets for training are used.
The neural network architectures are defined as follows in Figure 1: An input layer with the 11 signals for each one of the three network types. A GRU, or a LSTM or a convolutional layer with 30 units. Therefore, the dimension of the output vector is 30, while the batch-size equals to 2. A rectifier layer, termed also as ReLu is also set, as well as a dropout layer of 0.3 for the first two networks. An additional GRU, or a LSTM or a convolutional layer with 30 units is set with an additional activation layer and dropout layer for the first two cases. Finally, 100 neural density is defined for all cases, along with activation and dense layers. The learning rate is defined as 0.0001. The Adaptive Momentum Estimation (Adam) algorithm is used for the network optimization 109 and the number of epochs is 10,000. It is generally known that the performance of deep neural network is overly dependent on the setting of hyperparameters. The author set the network parameters according to Kingma and Ba 109 without any special adjustments that would potentially favor the dynamic load identification problem. Importantly, this architecture and the number of hidden units were selected as they have been proven efficient in a number of structural engineering applications.6,110,111 Last but not least, investigation on the dropout layer hyperparameter, or the number of layers is shown in section “Discussion.”
For the RKF, the process covariance
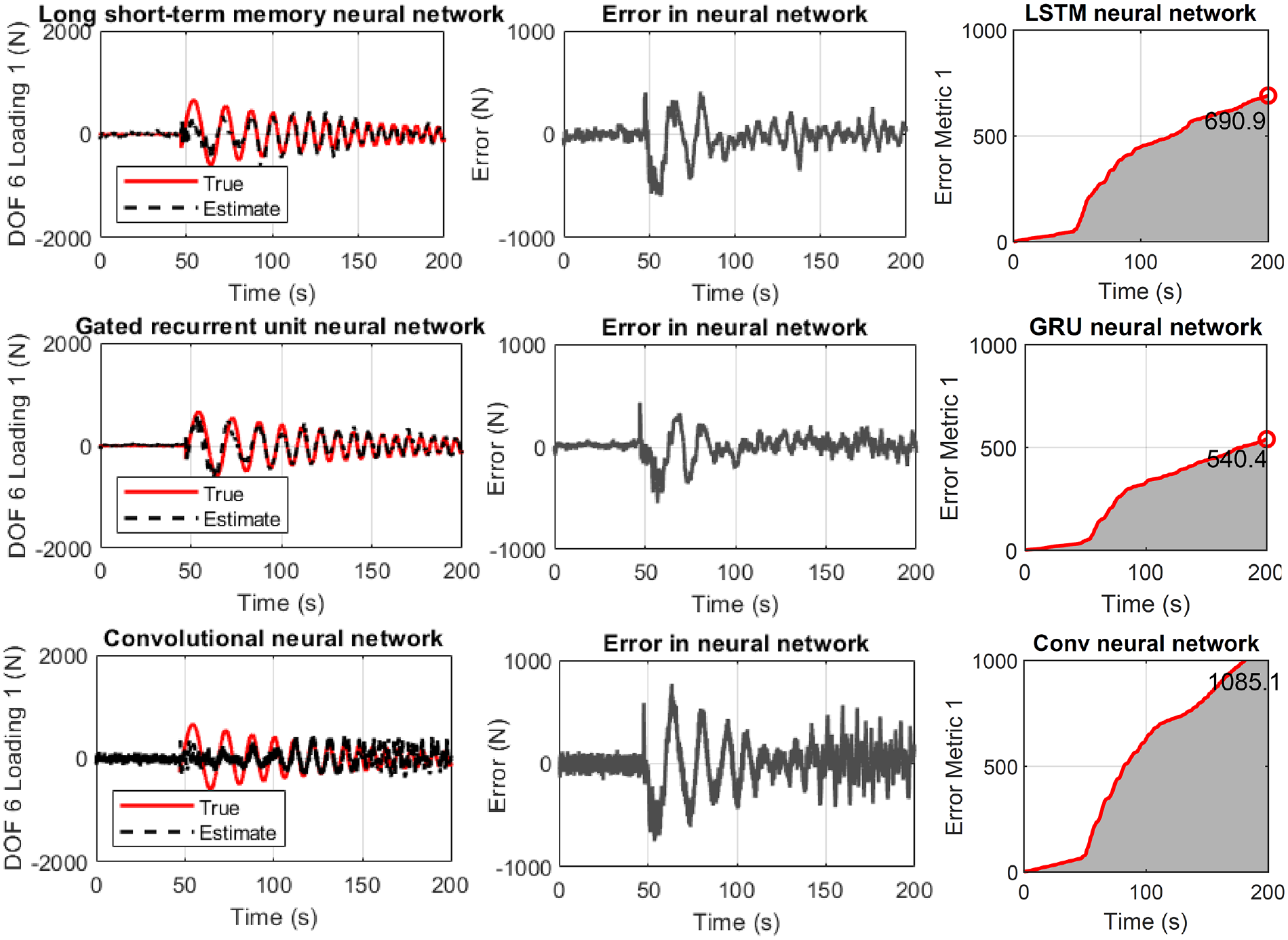
All three cases are examined on Figures 3 to 5. They show the true and identified structural load (first column) for the six unknown predicted datasets where the network never trained or validated. The load identification error is also seen at floor six (second column), as well as the comparison to the Kalman filter (third column). In all cases, acceleration measurement are only selected from story 3, 5, and 6. For a different combination or number of measurements, different convergence timing is observed.
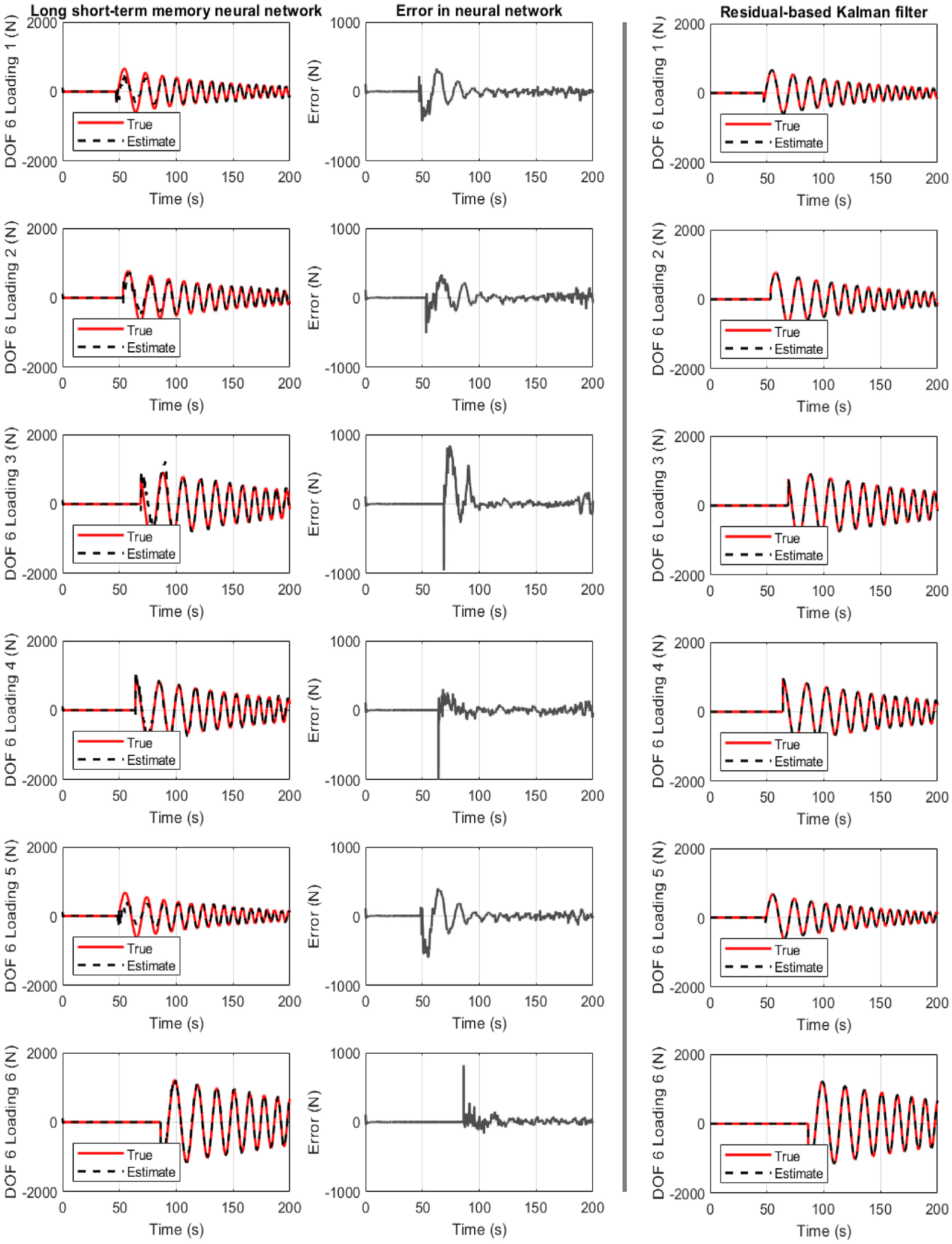
Structure of section “Structural loading identification in a 6-story building”: results for the 6-story shear-type building when the LSTM neural network is used. First column: true and estimated loading at floor 6. Second column: error at loading identification. Third column: Residual-based Kalman filter performance.
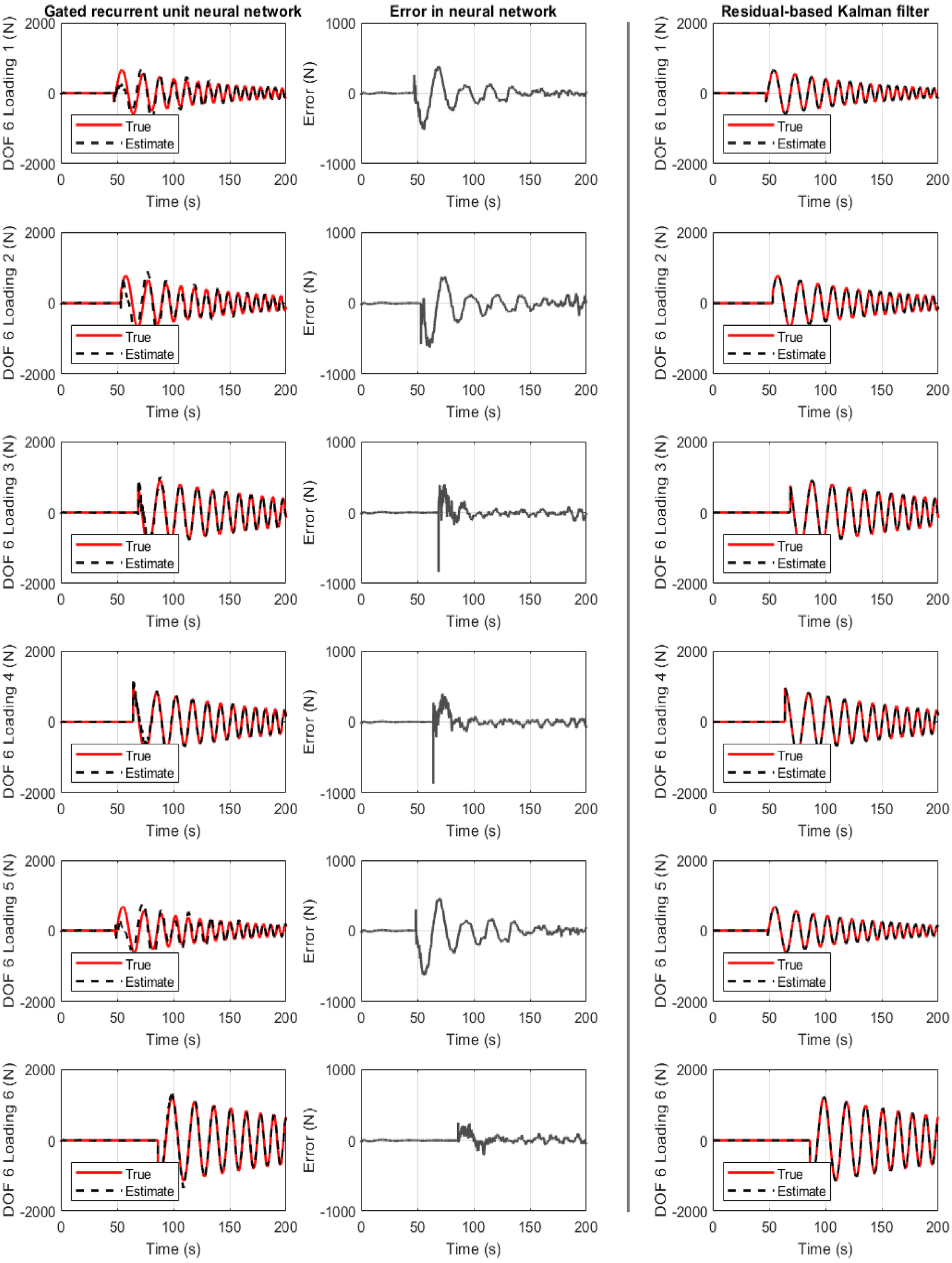
Structure of section “Structural loading identification in a 6-story building”: results for the 6-story shear-type building when the gated recurrent unit neural network is used. First column: true and estimated loading at floor 6. Second column: error at loading identification. Third column: Residual-based Kalman filter performance.
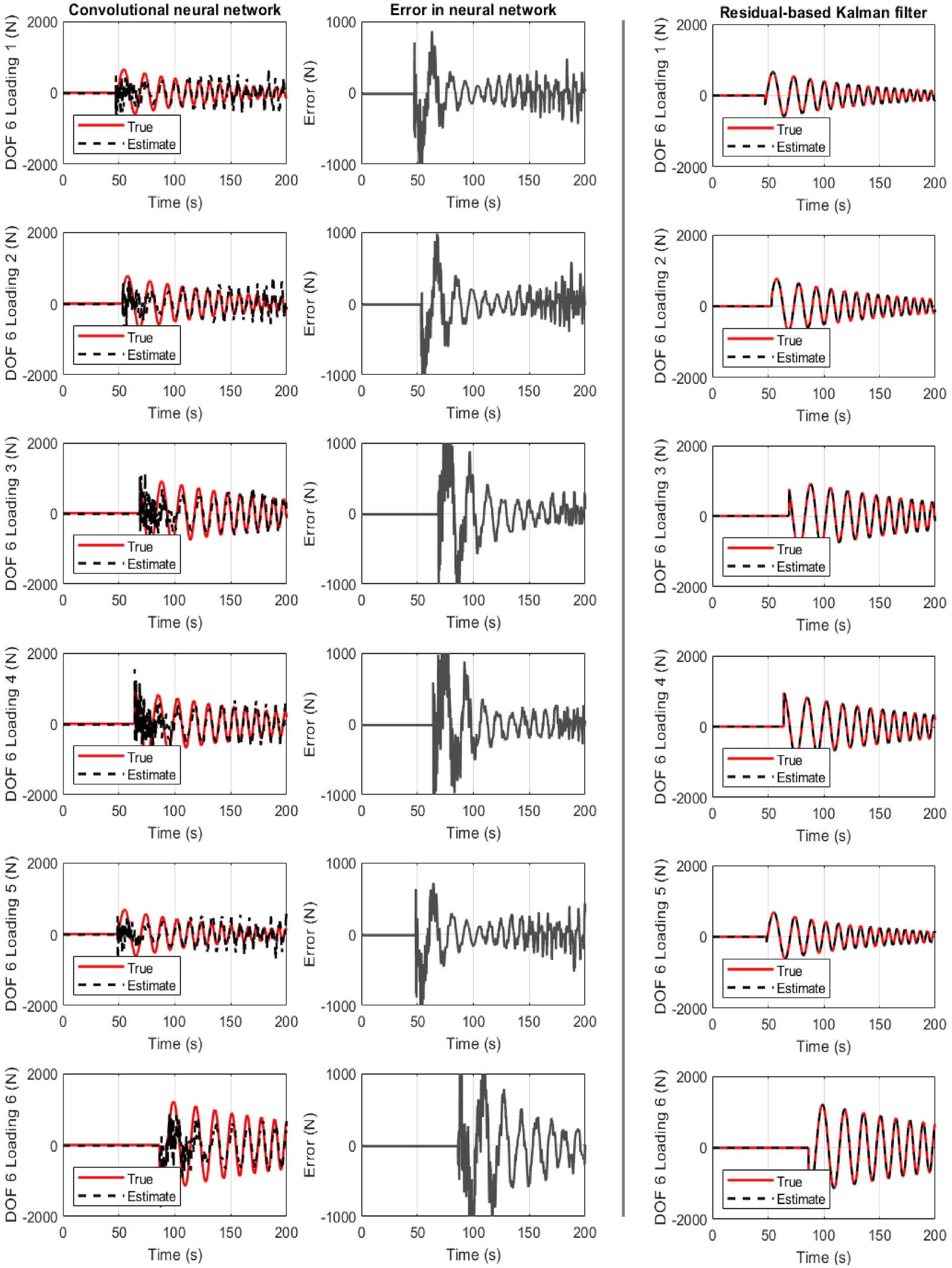
Structure of section “Structural loading identification in a 6-story building”: results for the 6-story shear-type building when the convolutional neural network is used. First column: true and estimated loading at floor 6. Second column: error at loading identification. Third column: Residual-based Kalman filter performance.
Figure 3 refers to the case where the LSTM neural network is used. The results are satisfactory for all six cases. The exemption of the first loading instances is related to the slightly wrong estimation of the load phase or amplitude.
Figure 4 refers to the case where the GRU neural network is used. The results are also satisfactory for all six cases. However, a convergence time improvement is seen compared to the LSTM neural network case, as discussed in Table 2 of section “Discussion.” Once more, but at a lower level, the first loading instances are not satisfactory for the same reasons as in Figuer 3.
Figure 5 refers to the case where the CNN is used. The results for all six cases are not as satisfactory as with the previous networks. However, a clear and significant convergence time reduction is observed. Importantly, for all cases, the Kalman filter approach provided a better accuracy.
So far, only time-historical error is provided to indicate the performance of presented approaches. To use a comprehensive evaluation metric, the accumulated error at each time instant is employed as
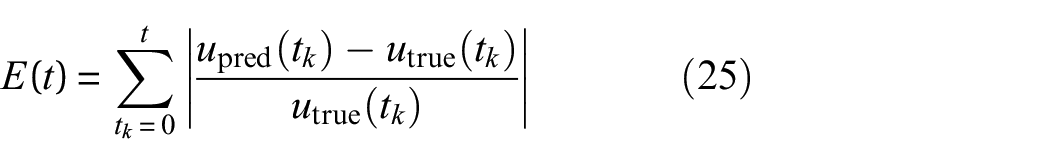
where
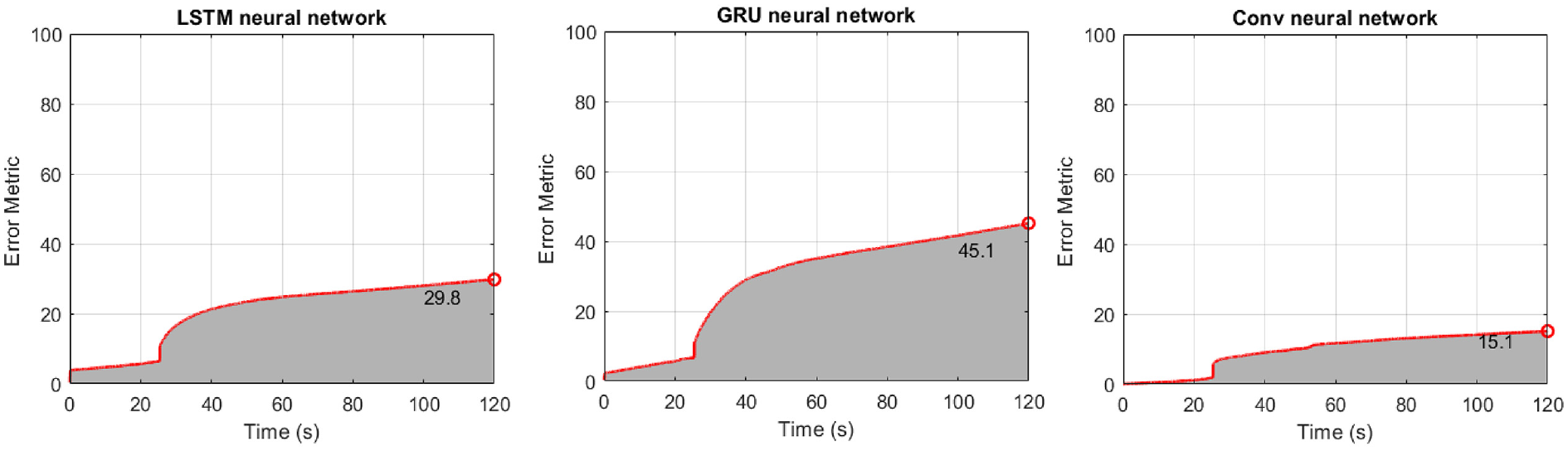
Figure 6 refers to the case where the error metric E(t) of Equation (25) is used. The results show that the LSTM network performs better but with higher computation cost, which is shown in Table 2 of section “Discussion.” The Kalman filter has the lower error, summarized also in Table 1.
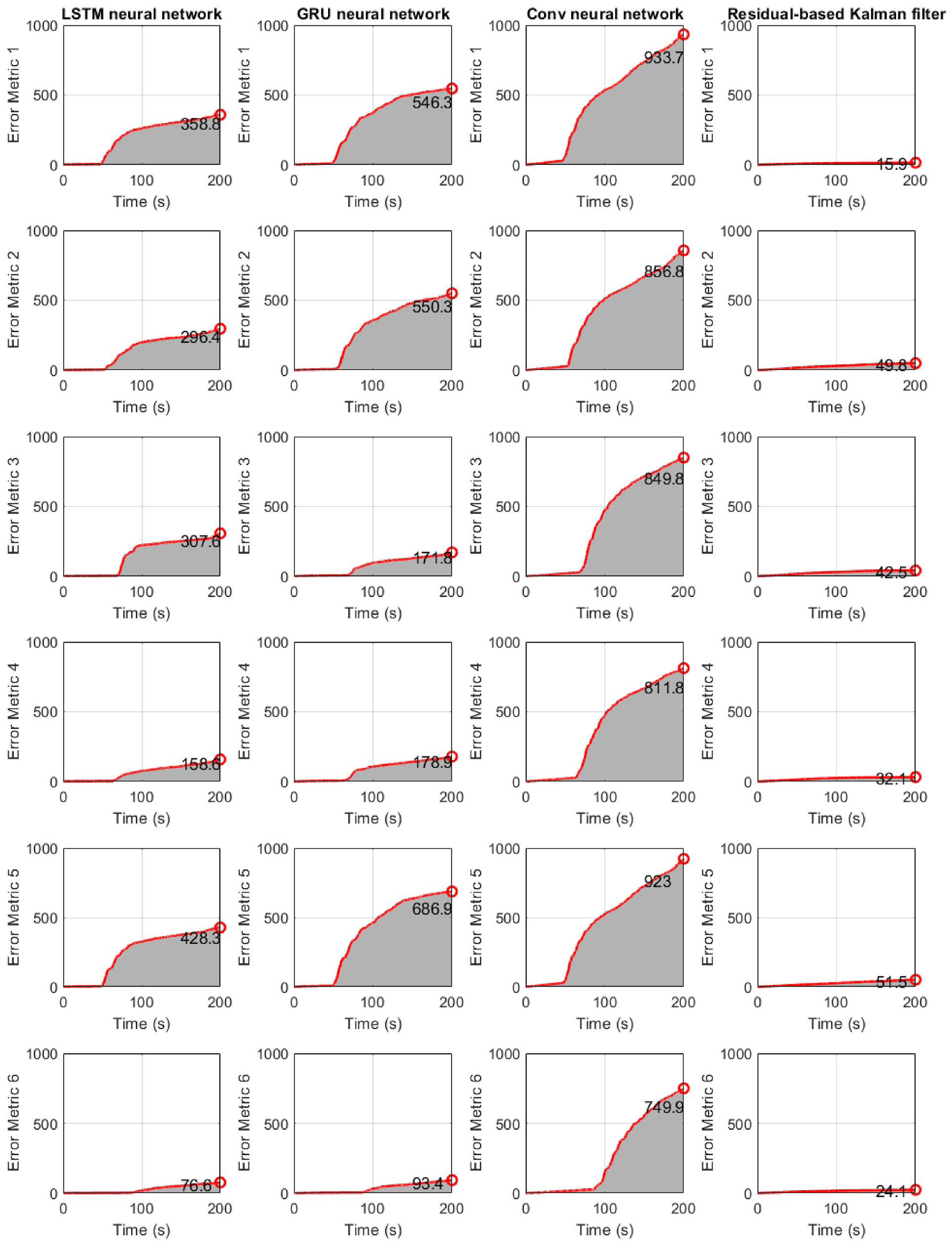
Structure of section “Structural loading identification in a 6-story building”: results for the 6-story shear-type building when the error metric E(t) of Equation (25) is used. First column: LSTM neural network. Second column: GRU neural network. Third column: CNN. Fourth column: Residual-based Kalman filtering.
Final value of error metric E(t) of Equation (25) for the 6-story building of section “Structural loading identification in a6-story building.”

LSTM: long short-term memory; DOF: degree of freedom; GRU: gated recurrent unit; KF: Kalman filter.
Structural loading identification for a hotel in San Bernardino
The methodologies are examined also in field sensing data. An examination is conducted on a 6-story hotel building in San Bernardino, California, sourced from the Center for Engineering Strong Motion Data. 112 The structure, a mid-rise concrete building designed in 1970, is equipped with nine accelerometers on the 1st floor, 3rd floor, and the roof level, as depicted in Figure 7. These sensors have captured seismic events from 1987 to 2018. The historical data serve as training inputs for the proposed neural network deep learning models, predicting the structural loading induced by the ground motions. In this scenario, methodologies such as the Kalman filter are vulnerable to identifiability issues, and they cannot be used efficiently to recover the input without assuming any known model parameter. 113 Assuming known parameters leads to unfair comparison with the network as more information is provided. For that case, the load estimation unsurprisingly is better as already demonstrated in Eftekhar Azam et al. 114
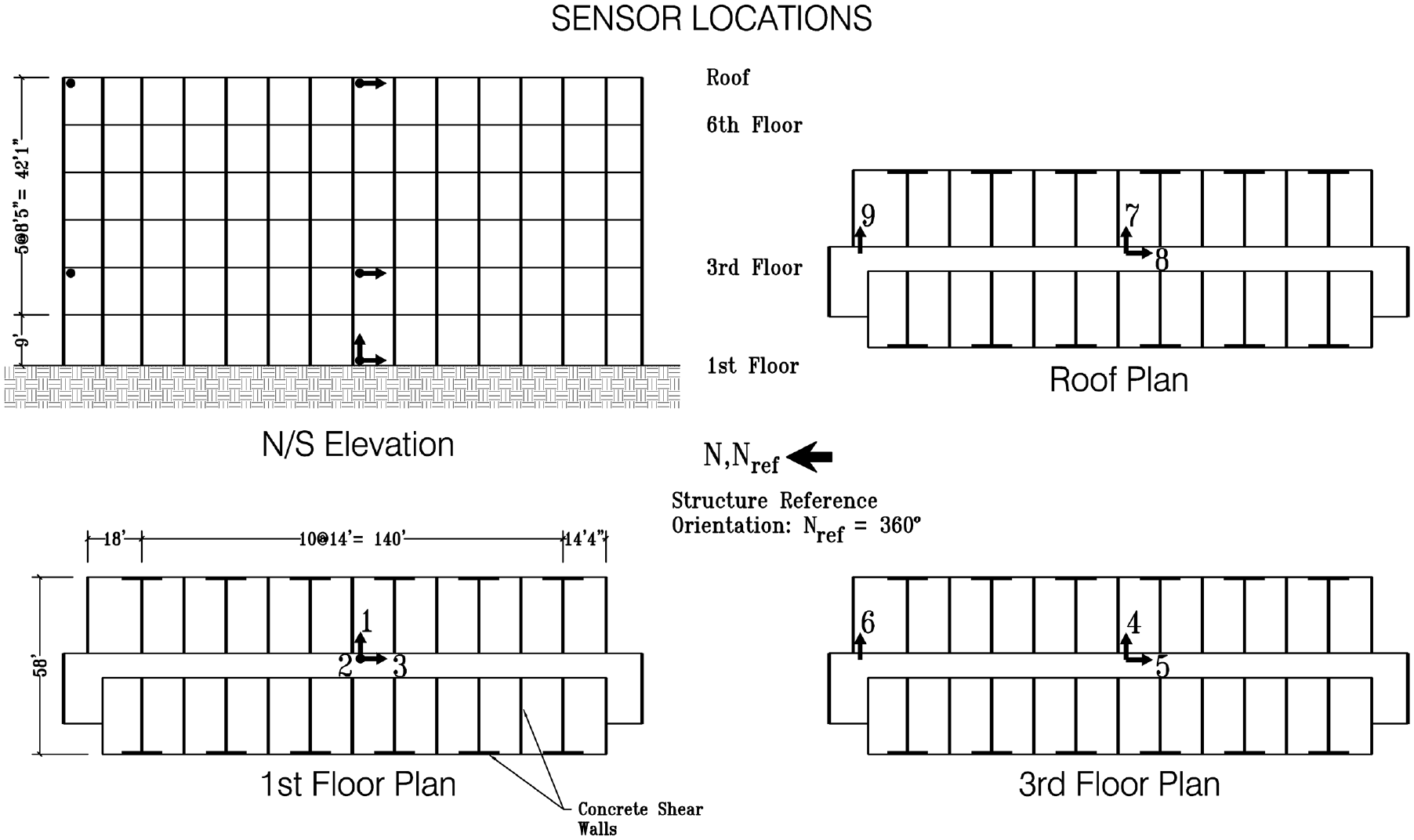
Sensor layout of the 6-story hotel in San Bernardino of section “Structural loading identification for a hotel in San Bernardino” (Station No. 23287).
In this examination, the field data, characterized by varying sampling rates and high-frequency noise, undergo initial preprocessing involving resampling at 100 Hz and filtering. A total of 21 datasets are organized into three subsets: 11 for training, 4 for validation, and 6 for prediction. The seismic loading at the building base is considered over a duration of 70 s. Importantly, the neural network architectures are structured in a manner consistent to the approach detailed in section “Structural loading identification in a 6-story building.”
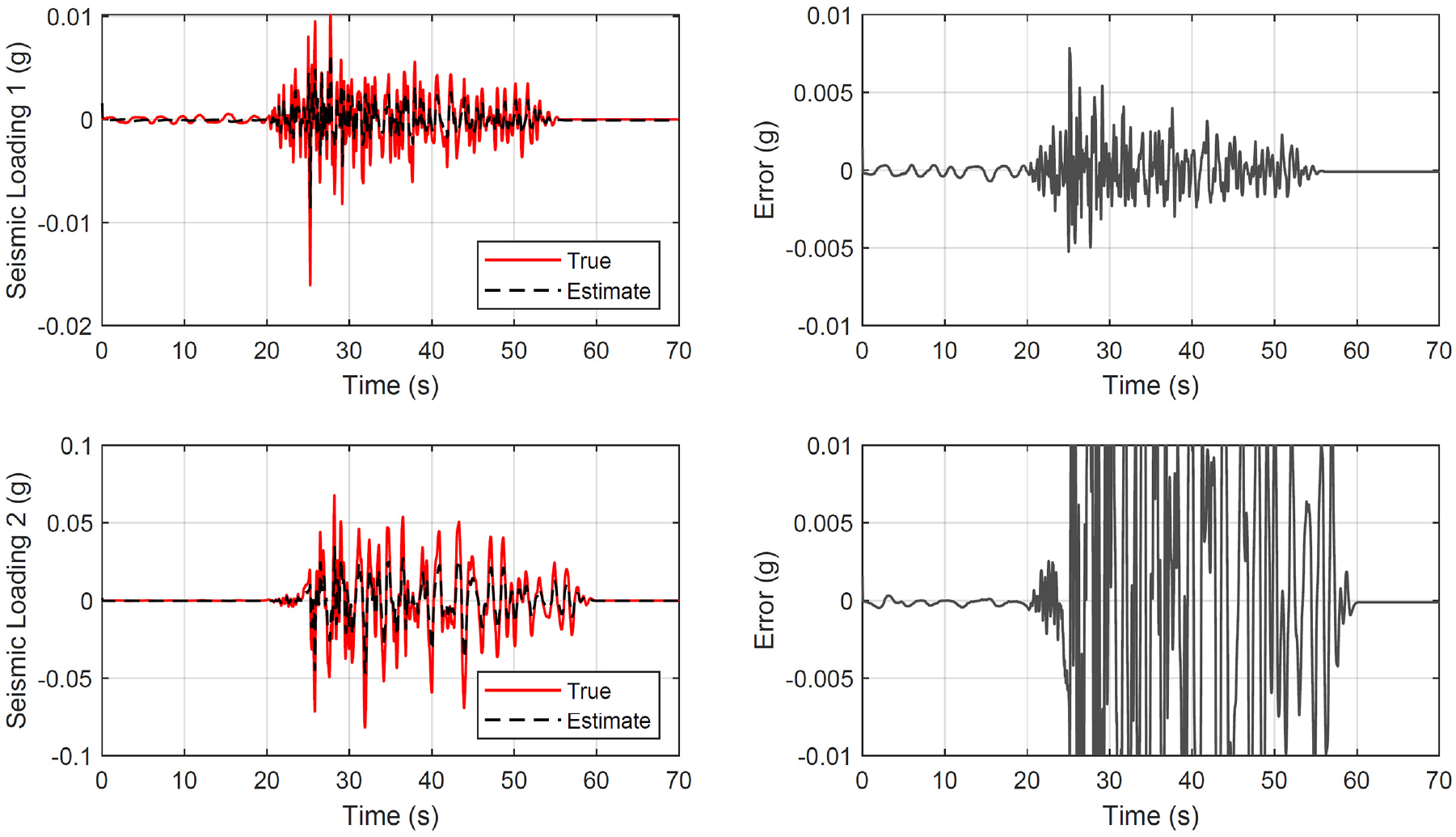
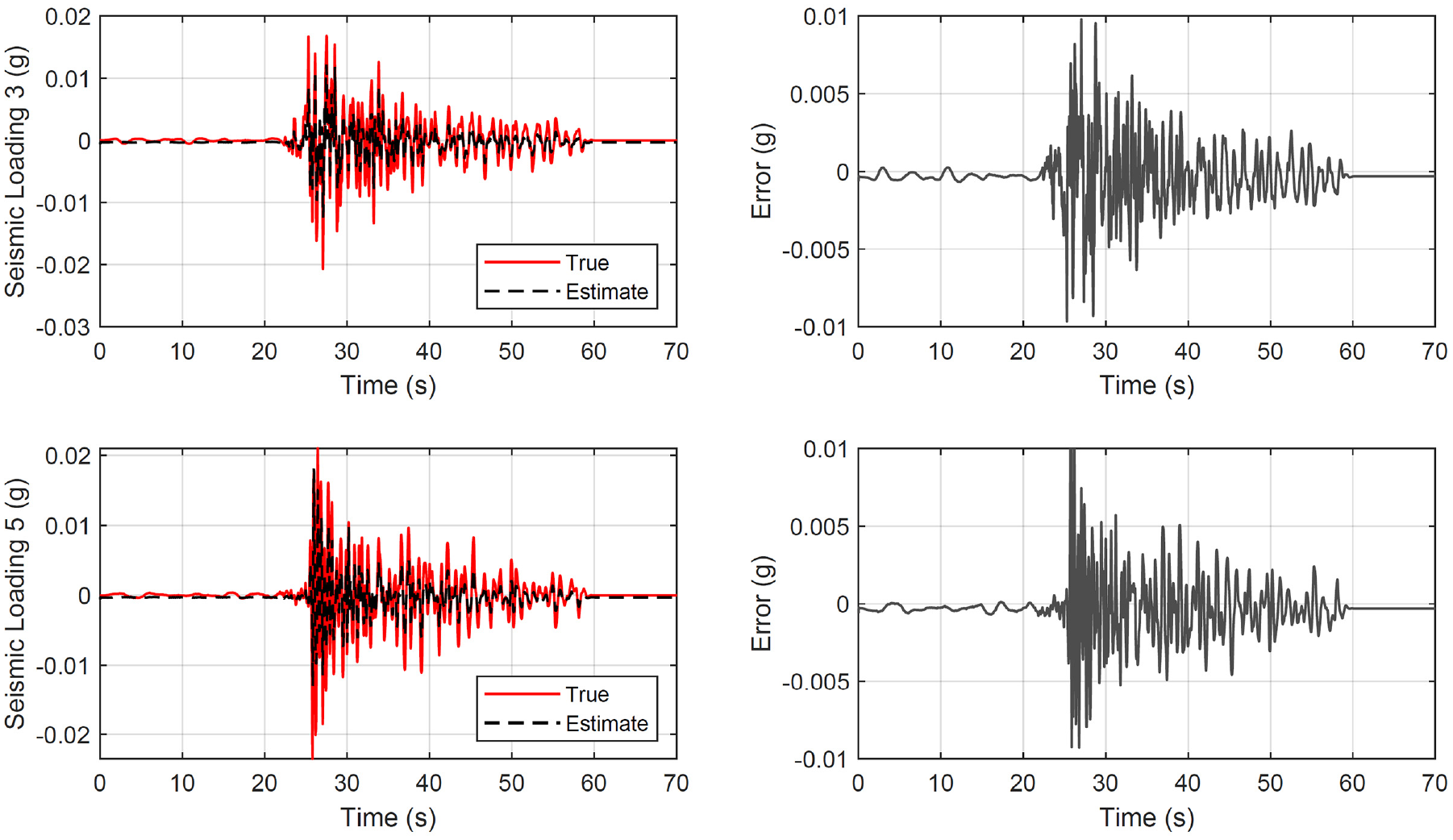
All three cases are examined on Figures 8 to 10. They show the true and identified structural load (first column) for the six unknown predicted datasets where the network never trained or validated. The load identification error at the building base is shown on the second figure column. In all cases, acceleration measurement are only selected from stories 3 and 6. For a different combination or number of measurements, different convergence timing is observed.
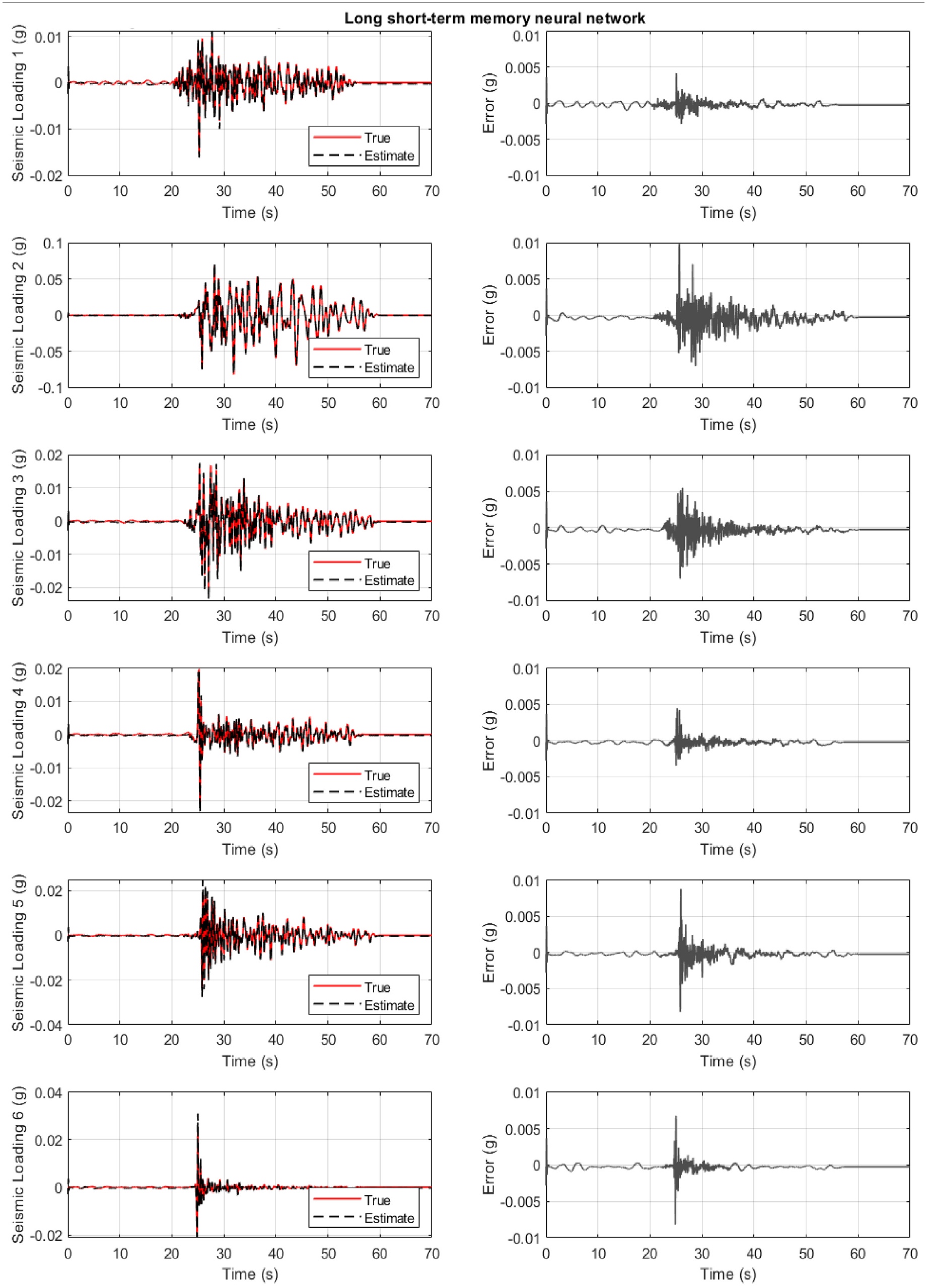
Structure of section “Structural loading identification for a hotel in San Bernardino”: results for the 6-story hotel in San Bernardino when the long short-term memory neural network is used. First column: true and estimated loading at the base. Second column: error at loading identification.
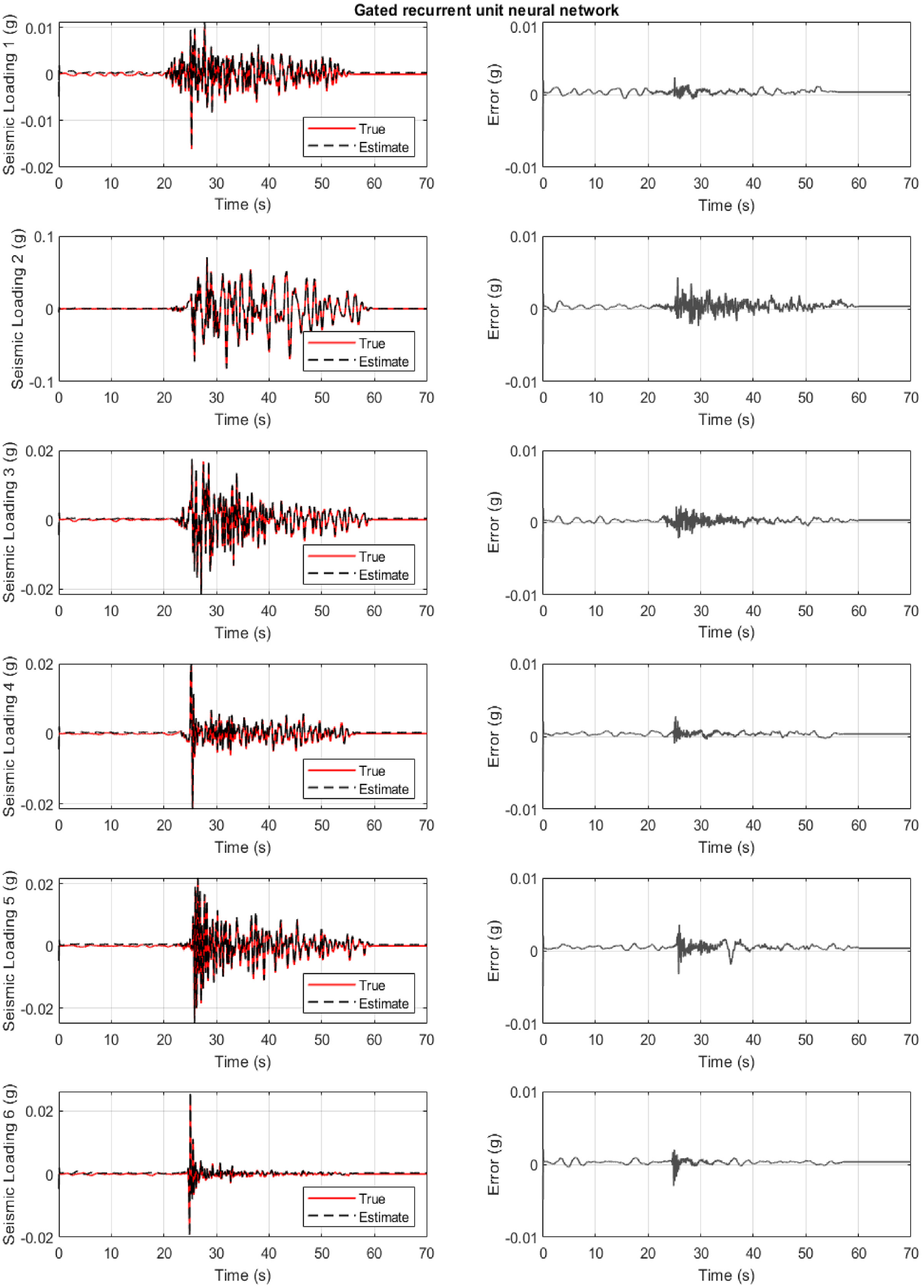
Structure of section “Structural loading identification for a hotel in San Bernardino”: results for the 6-story hotel in San Bernardino when the gated recurrent unit neural network is used. First column: true and estimated loading at the base. Second column: error at loading identification.
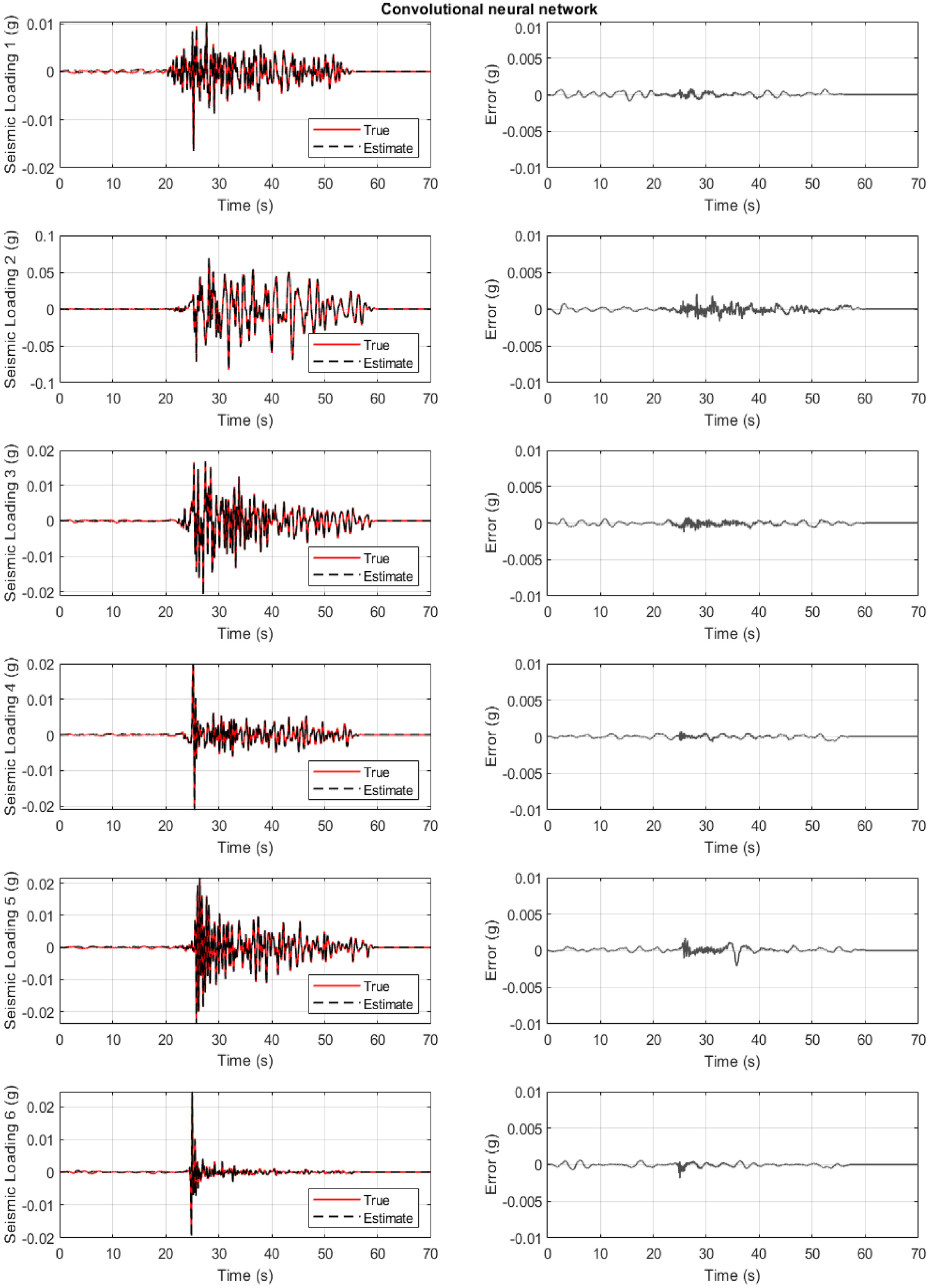
Structure of section “Structural loading identification for a hotel in San Bernardino”: results for the 6-story hotel in San Bernardino when the convolutional neural network is used. First column: true and estimated loading at the base. Second column: error at loading identification.
Figure 8 refers to the case where the LSTM neural network is used. The results are satisfactory for all six cases. On the other side, the LSTM neural network has the highest computation cost, and it is seen as the least favorable (Table 2).
Computational time for training the presented networks in minutes per 1000 epochs.

LSTM: long short-term memory; GRU: gated recurrent unit.
Figure 9 refers to the case where the GRU neural network is used. The results are often more satisfactory for all six cases, and with a convergence time reduction compared to the LSTM network (Table 2).
Figure 10 refers to the case where the 1D CNN is used. The results are the most satisfactory for all six cases compared to the previous networks. Along these lines, a clear and significant convergence time reduction is observed (Table 2). It can be then concluded that for the base excitation, the 1D CNN identifies and predicts the loading with better accuracy and with a less computation time. This result is not true for the top floor excitation of the previous investigation of section “Structural loading identification in a 6-story building.”
Finally, Figure 11 refers to the case where the error metric E(t) of Equation (25) is used. The results show that the LSTM network has (relatively) poor performance with higher computation cost, shown in section “Discussion.” In general, it seems that the performance of three neural networks is better compared to the building of section “Structural loading identification in a 6-story building.” This implies that base excitation results in a better learning for the networks when the responses are all related to the input, than exciting only a single DOF as in section “Structural loading identification in a 6-story building.”
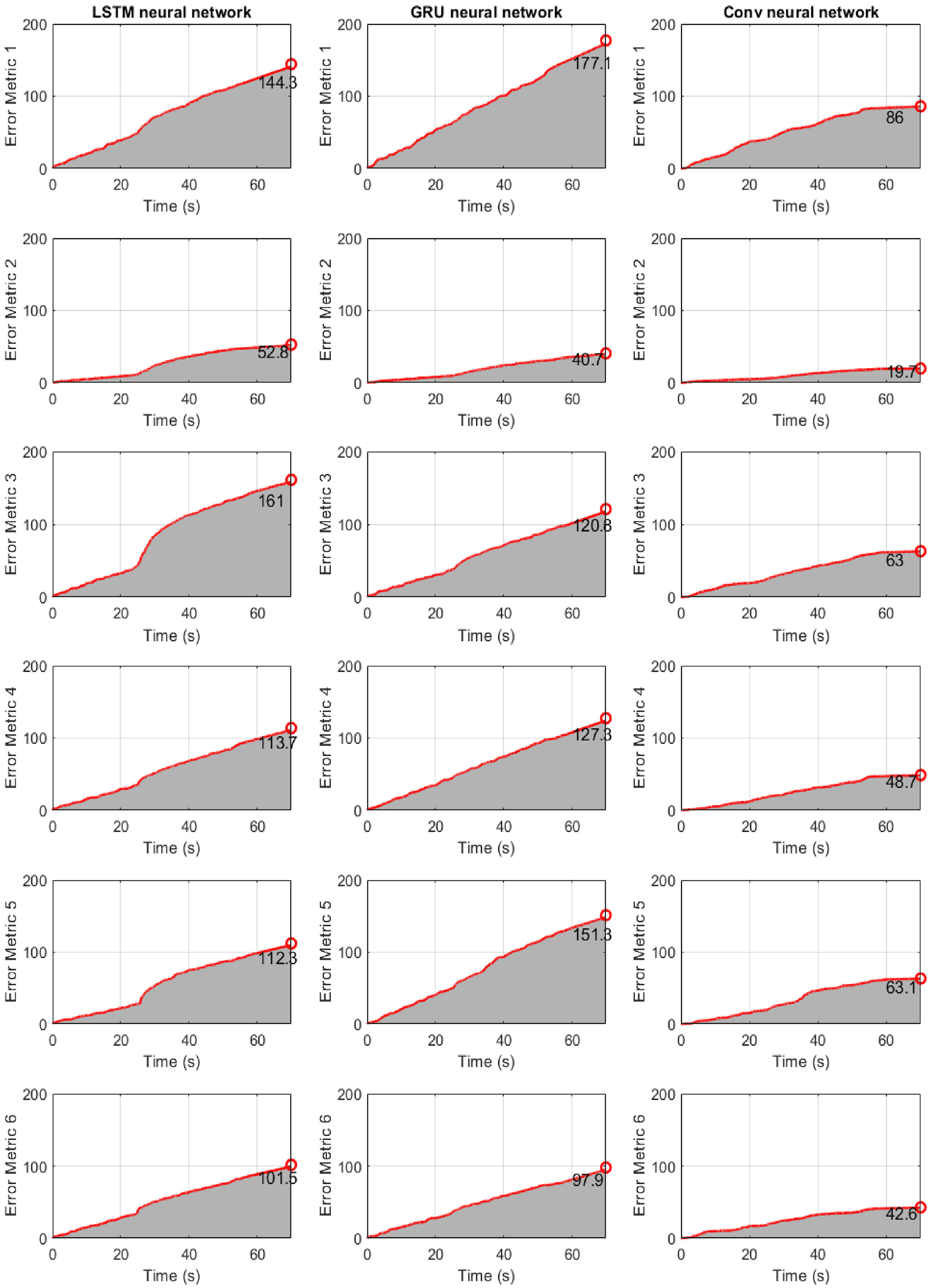
Structure of section “Structural loading identification for a hotel in San Bernardino”: results for the 6-story hotel in San Bernardino when the error metric E(t) of Equation (25) is used. First column: LSTM neural network. Second column: GRU neural network. Third column: CNN.
Structural loading identification in the IASC-ASCE structural health monitoring benchmark problem
The proposed methodologies are also examined in a hammer-type loading scenario. This examination corresponds to the second phase of experiments conducted by the IASC-ASCE Structural Health Monitoring Task Group, tested at the University of British Columbia.115–118 The study focuses on applying structural health monitoring techniques to data collected from a 4-story, 2-bay by 2-bay steel-frame structure, as shown in Figure 12. The structure, measuring 2.5 × 2.5 m in plan and 3.6 m tall, is mounted on a concrete slab outside the testing laboratory. To enhance realism, mass distribution was involved placing floor slabs in each bay per floor, with off-center masses on each floor. 115 The experimental setup included three types of excitation: electrodynamic shaker, impact hammer, and ambient vibration. Accelerometers strategically placed across the structure facilitated the measurement of structural responses.

IASC-ASCE structural health monitoring benchmark building of section “Structural loading identification in the IASC-ASCE structural health monitoring benchmark problem”, the Dynatron 5803A 12 lbf Impulse Hammer, and the monitor and console equipment. 115
Fifteen accelerometers were positioned throughout the frame and the base to capture the responses of the test structure. The placement included sensors for measuring northsouth and eastwest motion.
The excitation and impact hammer tests employed a Dynatron 5803A 12 lbf Impulse Hammer. This hammer, equipped with a force transducer, recorded measurements during tests involving 3–5 hits. Impact locations were chosen on the south and east faces of the first floor in the southeast corner. A force transducer on the hammer tip measured the force input during impact tests. A 16-channel DasyLab acquisition system recorded structural responses, with sampling rates of 250 Hz for shaker and ambient tests, and 1000 Hz for hammer tests. Anti-aliasing filters were applied selectively, and the data acquisition system commenced before the first impact, recording a series of hits within each test.
Since there was a very limited amount of data for the same damage scenario, namely the same structure, the signals of multiple hammer impact split into smaller (four) signals of a single hammer impact in them. Finally, the networks are trained with two signals, validated with one signal, and finally tested on a final signal. This approach examines the capability of the networks on extremely limited datasets. Importantly, the neural network architectures are defined similarly to section “Structural loading identification in a 6-story building.”
All three network cases are examined on Figure 13. They show the true and the identified structural load (first column) for the unknown load where the network never trained or validated, and the load identification error on the second figure column. In all cases, acceleration measurement are selected from all stories.
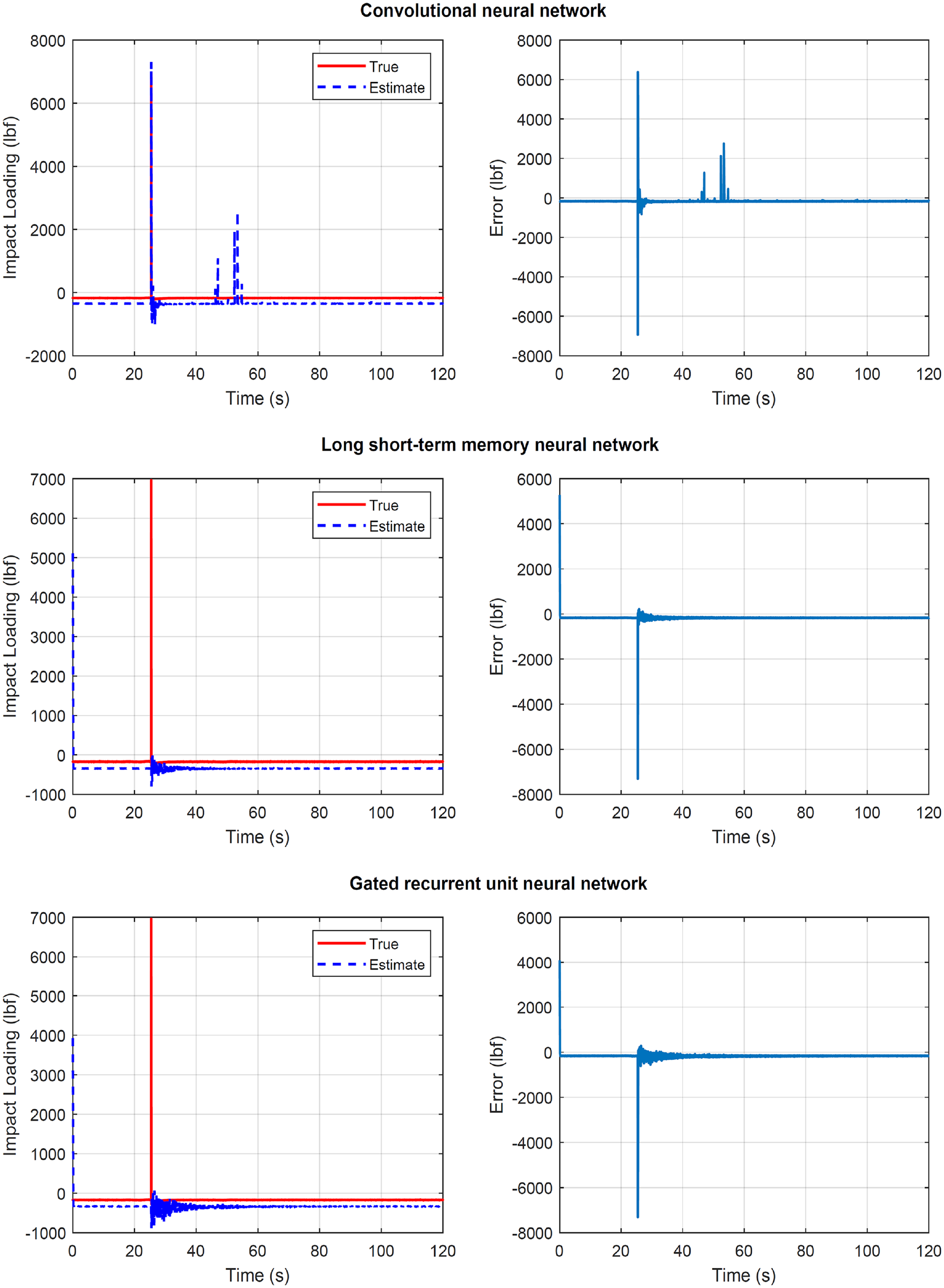
Structure of section “Structural loading identification in the IASC-ASCE structural health monitoring benchmark problem”: results for the IASC-ASCE structural health monitoring benchmark problem when the LSTM, GRU, and CNN are used. First column: true and estimated loading on the impact hammer scenario. Second column: error at loading identification.
Figure 13 top plots refer to the case where the CNN is used. The results are the most satisfactory compared to the other two models. At the same time, the CNN has the lowest computation cost, and it is seen as the most favorable. The error seen is attributed to the delay on the impact load time, and not to the wrong amplitude.
Figure 13 middle plots refer to the case where the LSTM neural network is used. The results are not satisfactory and with an additional convergence time compared to the previous case.
Figure 13 bottom plot refers to the case where the GRU neural network is used. The results are also not satisfactory, but with a shorter convergence time compared to the previous case.
Finally, Figure 14 refers to the case where the error metric E(t) of Equation (25) is used. The results show that the convolutional network performs better and with lower computation cost, shown in section “Discussion.”
Structure of section “Structural loading identification in the IASC-ASCE structural health monitoring benchmark problem”: Results for the IASC-ASCE structural health monitoring benchmark problem when the error metric E(t) of Equation (25) is used.
The poor performance on this investigation of the LSTM and GRU neural network is expected. The intuition behind them is to create an additional module in a neural network that learns when to remember and when to forget some characteristic of the provided signal. In other words, the network, effectively learns which patterns might be needed in the signal and when that information is no longer needed. This poses a disadvantage for structural load identification in a hammer impact case as it seen as an unexpected excitation in the structure. This is wrongly assumed to not be attributed to structure response or play an important role in the final prediction, and therefore it is neglected. In the hammer test scenario, this “unexpected” excitation is correct and the networks wrongly forget and neglect it.
Discussion
The presented work provided a simple, yet effective, way to identify the load in structural dynamics. It did not aim to present a machine learning algorithm advancement, rather than to apply the vast capabilities of such tools to the structural load identification problem. To this end, the efficiency and robustness of the methods were tested to both simulated and real data, and in different loading types.
This work provided an assessment for the GRU networks, LSTM networks, and CNN in the framework of limited datasets. For the structural health monitoring case of civil structures, this is realistic. All the presented tools can perform much better in a big data availability scenario, but this is often impractical. Despite the small dataset investigation, all the tools shown a great capability.
Regarding the network algorithm parameters, the examinations so far showed a recommendation of high values for the filter size and the number of neurons in the layers. The first one defines the kernel where the data are multiplied by, while the second one determines the number of feature maps. However, for the case of the dropout layer parameter, using a large number may lead to a poorer performance. This is illustrated in Figure 15, where the system of section “Structural loading identification for a hotel in San Bernardino” under seismic loading was modeled using the dropout layer value of 0.75.
Structure of section “Structural loading identification for a hotel in San Bernardino” in section “Discussion”: results for the 6-story hotel in San Bernardino when the gated recurrent unit neural network is used with dropout layer value of 0.75. First column: true and estimated loading at the base. Second column: error at loading identification.
The recommendation of high values for the filter size and the number of neurons in the layers sounds restrictive or suboptimal since it leads to higher weights for back-propagation, and ultimately to higher computational cost. Despite this, the computational cost of this approach is bearable. This is attributed to two main reasons: the one-dimensional nature of the data, and the small dataset training approach which was implemented. Future research is recommenced on the optimal value of them, or improved network architectures. The author investigated improving further the computational cost by removing layers from the architecture of section “Structural loading identification in a 6-story building.” Specifically a set of GRU, ReLu, and dropout layer is removed; however, this resulted in faster convergence but with a poorer performance (seen in Figure 16).
Structure of section “Structural loading identification for a hotel in San Bernardino” in section “Discussion”: Results for the 6-story hotel in San Bernardino when the gated recurrent unit neural network is used with less network layers. First column: true and estimated loading at the base. Second column: error at loading identification.
Regarding the concern about the robustness of proposed approaches against the noise effect, simulation are provided. Here, the data are contaminated by a Gaussian white noise sequence with a
Structure of section “Structural loading identification in a 6-story building” in section “Discussion”: results for the 6-story shear-type building when the data are contaminated by a Gaussian white noise sequence with a
The presented Kalman filter approach performs joint input-state-parameter estimation. The results for parameter estimation in the section “Structural loading identification in a 6-story building” building study are also shown in Figure 18 for the fourth floor parameter and for all noise levels. More parameter and noise results are shown in Impraimakis and Smyth.
41
The parameter estimation slowly convergences to the true values for
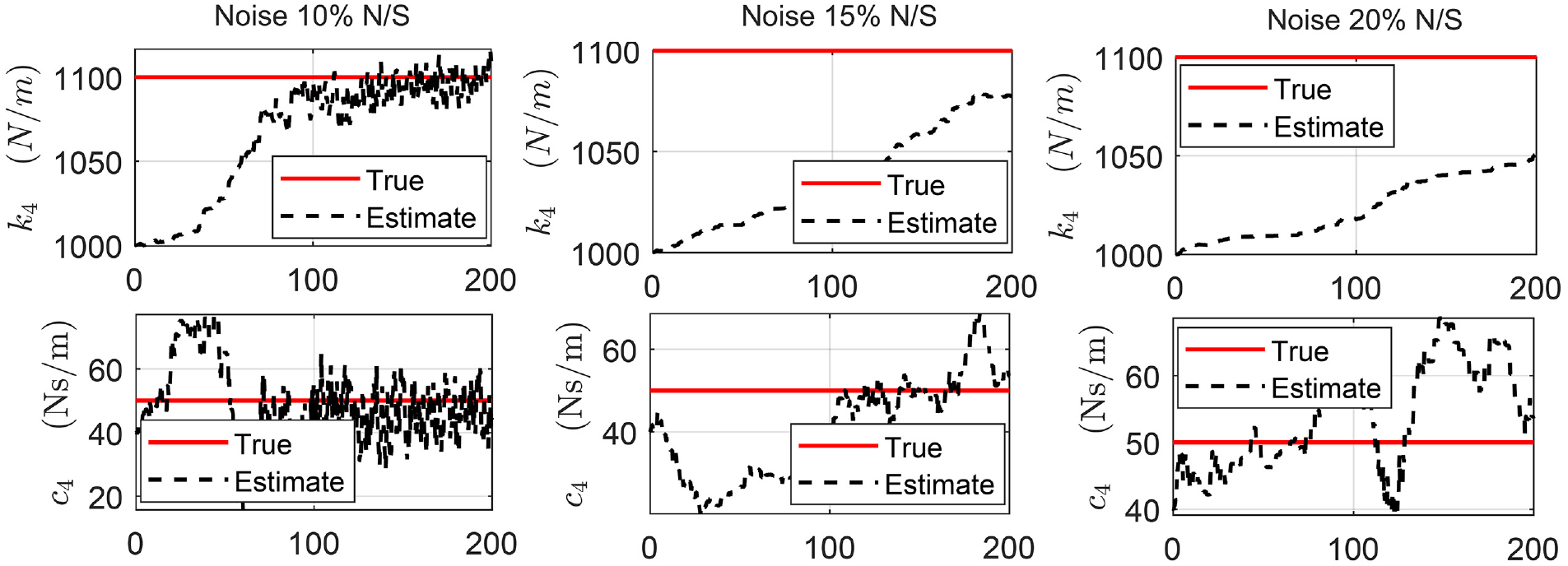
Structure of section “Structural loading identification in a 6-story building” in section “Discussion”: Results for the 6-story shear-type building when the data are contaminated by a Gaussian white noise sequence with a
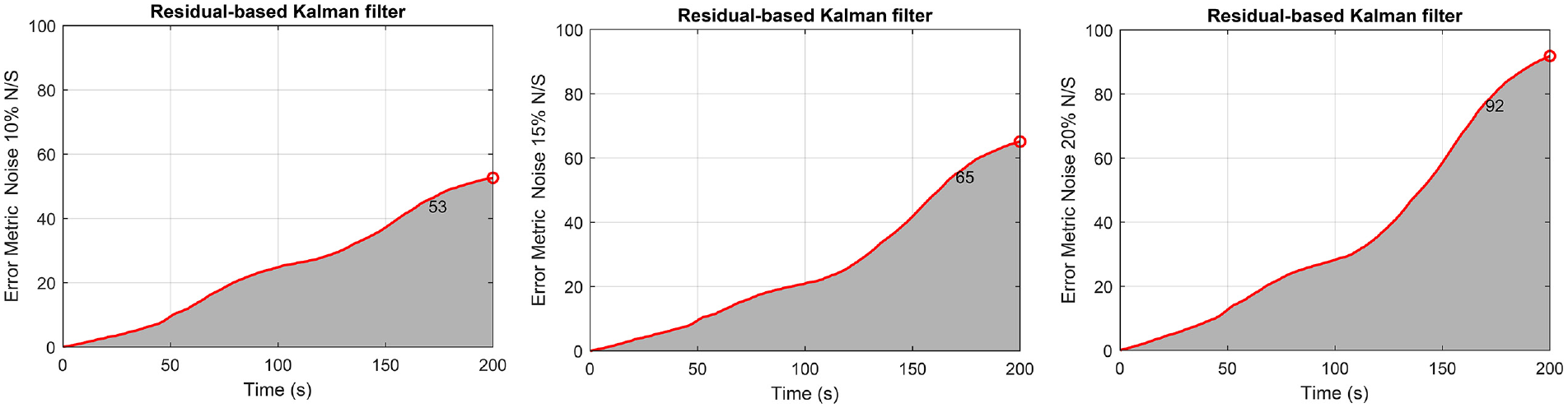
An investigation is also made for the networks when the data are contaminated by a Gaussian white noise sequence with a
Structure of section “Structural loading identification for a hotel in San Bernardino” in section “Discussion”: Results for the 6-story hotel in San Bernardino when the data are contaminated by a Gaussian white noise sequence with a
Finally, Figure 20 shows the Kalman filter approach for the impact load identification case for the section “Structural loading identification in a 6-story building” building case. It is not applied directly to the IASC-ASCE structural health monitoring benchmark problem to avoid first creating a nonphysically parametrized reduced order model; a task suggested for future research.
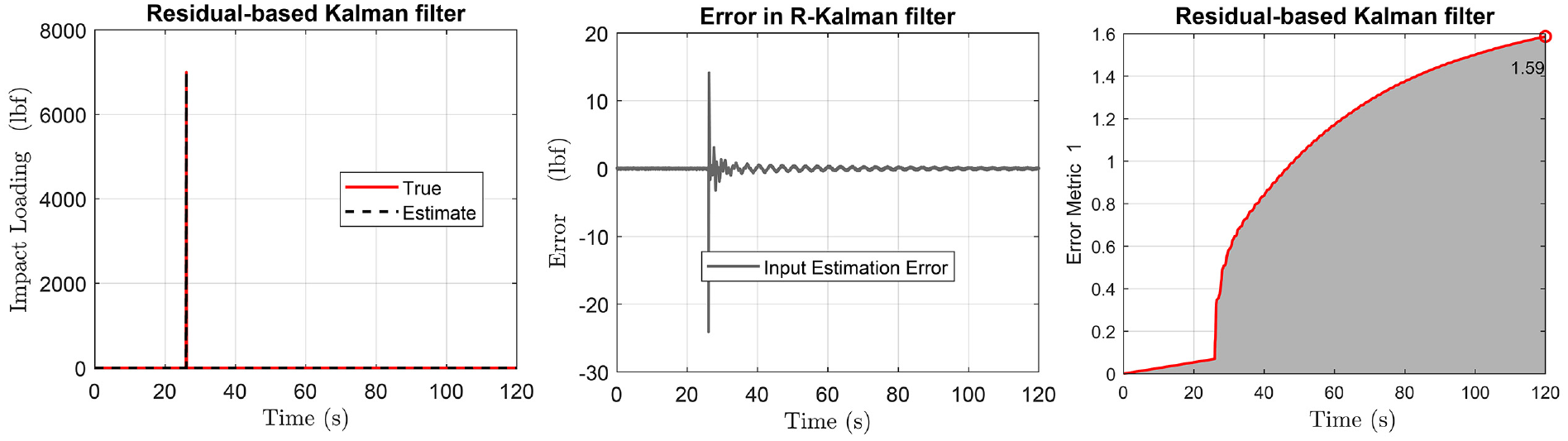
Structure of section “Structural loading identification in a 6-story building” in section “Discussion”: results for the 6-story shear-type building when the impact load of section “Structural loading identification in the IASC-ASCE structural health monitoring benchmark problem” is examined with the residual-based Kalman filter. True and estimated loading (first plot), error compared to true loading (middle plot), and accumulated error of Equation (25) (last plot).
Another concern is related to the data-driven only training of the presented tools. It has observed110,119–126 that by including a physics-aware constraint or a mathematical model, the training is improved. However, this is not always practical for large-scale structures as it requires full system identification, which finally results in the need of even greater data collection. The tools presented here do not require any parameter estimation in order to perform the structural load identification. It is important to mention that in the case where a physics-based model is available, the computational cost of the training is reduced for all neural networks, and the accuracy is improved. Specifically for the training time, it was shown in this study that the CNN has the lowest one, while between the rest two, GRU has the shorter convergence time. Table 2 shows the computational time for training the presented networks in minutes per 1000 epochs for all networks and applications. The computer used has processor 12th Gen Intel(R) Core(TM) i7-12850HX (24 CPUs), 2 NVIDIA RTX A2000 8 GB GPUs, and RAM 32.0 GB.
Future research
Relating to the joint input-state estimation, the methodologies require knowledge of the structural model and parameters. This may be infeasible, or it may require the collection of additional data to perform full system identification. A way to address this issue is by the use of the joint input-parameter-state estimation methodologies such as the RKF of section “Dynamic load identification using physics-based residual Kalman filtering.” However, these methodologies also have main deficiencies. For instance, the nature of the loading has to be of zero mean value to be filtered, or the requirement of having a known location of the loading, or known zero-values inputs at known location for identifiability reasons.113,127,128 Contrastingly, for a different combination or number of measurements, different convergence timing is observed for all networks, but unidentifiability issues are not occurred.
By performing a data-driven only approach, the user also does not have to consider different model classes and the select the optimal one. Those approaches calculate the evidence of each candidate model given the available measured data, and they finally select the simpler ones over the unnecessarily complicated ones. The importance of those methods is highlighted by the fact that a more complicated model fits the data better than one which has fewer adjustable uncertain parameters. This is attributed to the parameter fitting which depends too much on the detail of the data and the measurement noise. On the other hand, the presented networks solve the structural load identification problem without a need to select the structural model class.
Another concern is related to the investigation of different structures than buildings. In reality, in another case such as in a bridge investigation, the loading may not be directly sensitive to all responses. As a result, the networks could perform poorly. Additional research is therefore suggested for civil structures different than buildings.
Another concern is related to the investigation into the extrapolation capabilities of the approach since only the inputs–outputs are used for the training and the load identification. The examinations so far showed the potential of the method when the structural model remains the same. However, this assumption may not be true if a change happen to the structure, some damage for instance, or any other modification on the structure. The author slightly changed the simulated structural model of section “Structural loading identification in a 6-story building,” keeping the same trained neural network models, and they all underperformed. This does not occur in the physics-based Kalman filter approach. As a result, the deep learning approaches are not capable of some form of extrapolation to predict structural load for structures with properties outside of the training dataset to ensure good performance. When employed on a real engineering system where the structure may change, one must have some prior belief about the expected model patterns in order to generate comprehensive training datasets. This will lead to retrain the network for future good prediction. This is a pertinent test for structural load approaches in engineering applications as there could be high-cost or safety critical ramifications if the loading is confidently predicted incorrectly.
Regarding applying the Kalman filter approach for input estimation in the case study of base-excited building section “Structural loading identification for a hotel in San Bernardino,” the current work did not assume the extra information of known model parameter in Kalman filtering for a fair comparison with the network in the same dataset. This case obviously results in an even better performance of Kalman filtering presented already by Eftekhar Azam et al. 114 A limitation and future suggestion is then how to implement the residual-based Kalman filtering for scenario of base excitation (which excites all DOFs) where input-parameter-state estimation fails the identifiability tests. 113 Similarly, for the case of section “Structural loading identification in the IASC-ASCE structural health monitoring benchmark problem,” it requires a reduced order modeling which results in a nonphysical parameter estimation not examined here, and it is suggested for future research. A future suggestion lies also in combing Kalman filtering and neural networks as exists for dynamic state estimation. 3
A final concern is related to the uncertainty quantification where the structural load identification methodology should provide.129–131 This is a desirable property for the structural load prediction approaches to possess that accurately representing the uncertainty around predictions. In the framework of GRU, LSTM, and CNN, this may be crudely achieved by retraining the model multiply times and take the average and the rest statistical properties of the network prediction, or by using a variational inference approach, while for the Kalman filter by incorporating the unknown input in the state vector. 23
Conclusion
The dynamic structural load identification capabilities of the GRU, LSTM, and CNNs were examined herein. The examination was on realistic small dataset training conditions, and on a comparative view to the physics-based RKF. The dynamic load identification suffers from the uncertainty related to obtaining poor predictions when in civil engineering applications only a low number of tests are performed or are available, or when the structural model is unidentifiable. In considering the methods, first, a simulated structure was investigated under a shaker excitation at the top floor. Second, a building in California was investigated under seismic base excitation, which results in loading for all DOFs. Finally, the IASC-ASCE structural health monitoring benchmark problem was examined for impact and instant loading conditions.
Overall, these network methods allowed for structural load identification with
No need for data filtering for reasonable noise levels.
No need for system identification, known structural parameters, or a structural model.
Real-time prediction when the networks are trained.
Capability of providing the structural load identification for all loading types, with respect to the use of the appropriate network each time.
Reasonable computational cost for small datasets scenarios.
Importantly, the methods were shown to outperform each other on different loading scenarios, while the RKF was shown to outperform the networks in physically parametrized identifiable cases.
Footnotes
Acknowledgements
The author would like to gratefully acknowledge the reviewers for their constructive comments, Editor T.C. for the friendly communication, Andrew W. Smyth for the previous insightful discussions on residual-based Kalman filtering, and the Center for Engineering Strong Motion Data and the Structural Health Monitoring Task Group for providing the data.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.