
Abstract
Conventional structural health monitoring (SHM) evaluates the condition of civil structures by analyzing the data acquired by advanced sensors. The requirement of overinvestment in specialized equipment and labor for implementation prevents the traditional SHM from large-scale usage. On the other hand, computer vision techniques offer cost-effective solutions for SHM thanks to its inherent advantage in data acquirement and processing. More importantly, it has been demonstrated that these emerging solutions can produce reliable condition diagnoses for civil structures using pure image data. In this article, a novel transformer-based neural network is proposed for vision-based structural condition assessment which is formulated to a semantic segmentation problem. The network employs Swin Transformer as the backbone and MaskFormer as the overall architecture to recognize components (sleepers, slabs, columns, etc.) and damage (concrete damage, exposed rebar) of structures. Unlike the commonly used fully convolutional networks, the proposed model tackles semantic segmentation as a mask classification rather than a pixel classification problem. To deal with the lack of training data, an image data augmentation method called Copy-Paste is extended and applied for training data generation, resulting in an increase of around 40% data for component segmentation and 71% data for damage segmentation. Experimental validations on the Tokaido railway viaduct dataset show that the proposed approach is very accurate, achieving 97% and 90% mean Intersection Over Union for component and damage segmentation, outperforming the existing methods by a significant margin. The accurate segmentation results can provide meaningful information for downstream SHM tasks.
Keywords
Introduction
Many of the essential civil infrastructures, such as bridges, dams, roads, and buildings, were built decades ago. Regular and proper maintenance, repair, and rehabilitation are usually required for the civil infrastructure to ensure their safety and functionality. Structural damage is defined as changes in the material, or the geometric properties caused by cracks, spalling, corrosion, and so on. Such changes may affect the functionality and safety of structures and in extreme cases lead to catastrophic collapse resulting in significant loss in economy and lives. Therefore, structural health monitoring (SHM) and condition assessment are critical for tracking the operational status, assessing the conditions and identifying damages in civil infrastructure. 1 Traditionally, SHM involves civil engineers performing visual inspections of structures, which is expensive, inefficient, risky, and subjective, or conducting field measurements for monitoring the structural condition, which is also costly. A cost-effective and reliable approach for structural condition assessment should be developed to minimize structural risks and reduce maintenance costs. Recently, computer vision-based methods, such as deep learning algorithms, have been recognized as a critical component in the field of SHM that greatly improves inspection and monitoring processes in terms of both reliability and efficiency.2,3 The impressive and rapid progress of deep learning algorithms in computer vision motivates many researchers to apply such algorithms to vision-based SHM applications.4–6 Specifically, the civil infrastructure condition assessment tasks, including critical structural components recognition and structural damage detection that use images as input are closely related to the classic computer vision tasks, including image classification, object detection, and semantic segmentation. The key difference among these tasks and the corresponding approaches lies in the level of details of recognition, which are image level, region level, and pixel level from coarse to fine.
Image classification-based methods, such as convolutional neural networks (CNNs), have been applied for various damage detection applications.7,8 These models take an entire image as input and output a label or class to that image. For example, Kim et al. 9 presented a CNN-based method for crack and non-crack classification from concrete surface images. Yeum et al. 10 developed a CNN framework for the automatic classification of post-disaster images. The images with collapsed structures or components can be accurately distinguished from normal ones. Xu et al. 11 employed a modified fusion CNN to conduct crack identification from real-world images containing complicated background information inside steel box girders of bridges. The fatigue crack distribution map was created by concatenating the predicted sub-images (64 × 64 pixels) using image binarization.
Region-based damage detection has been studied using object detection-based methods to create bounding boxes around the damaged regions instead of classifying an entire image. Yeum et al. 10 used region-based CNNs (R-CNNs) 12 for detecting spalling from post-disaster images. Cha et al. 13 trained a Faster R-CNN 14 -based framework to detect multiple types (steel delamination, steel corrosion, bolt corrosion, and concrete cracks) of damage from the structural surface. As the Faster R-CNN provides a remarkably fast test speed, this framework is used for quasi-real-time damage detection on videos. In addition, a single-stage object detection method known as You Only Look Once (YOLO) 15 and its advanced versions have also been successfully employed for structural damage detection. 16 One of the main advantages of YOLO is its fast processing speed as it can identify damage in an image in a single pass. This makes YOLO suitable for real-time damage detection applications where speed is important. Zhang et al. 17 proposed a single-stage detector based on YOLOv3 18 for detecting multiple concrete damages of highway bridges. Yu et al. 19 developed a crack detection model named YOLOv4-FPM based on YOLOv4. 19 Its detection speed can meet the requirement of real-time detection on unmanned aerial vehicles. However, single-stage region-based methods are limited in the capacity that they can only identify the location of damage but cannot provide quantitative information about the extent or severity of the damage. To address this limitation, researchers have developed two-stage damage detection frameworks20,21 that use region-based methods to locate damage and then employ postprocessing or semantic segmentation techniques to segment the damage. This allows for more detailed analysis and damage assessment.
Pixel-wise classification, or semantic segmentation, offers the most fine-grained recognition of images. Since the pioneering fully convolutional network (FCN) 22 dramatically improves the performance of semantic segmentation, it has been extensively used for structure/damage segmentation tasks. Semantic segmentation provides more precise object detection by classifying each pixel in an image into a certain class. As a result, the precise location and shape of the structural component/damage can be delineated. For instance, Li et al. 23 used an FCN-based method to detect four types of concrete damages: cracks, spalling, efflorescence, and holes. Rubio et al. 24 evaluated FCNs for damage segmentation on a database of bridges in Niigata Prefecture. Besides, other CNN-based architectures, such as SegNet 25 and U-Net, 26 have also demonstrated great advances27–30 in vision-based SHM. Narazaki et al. 31 developed a vision-based automated bridge component recognition framework by exploring FCNs and SegNet. 25 Liu et al. 32 claimed that a trained U-Net is able to identify the crack locations from the input raw images under various conditions. An object instance segmentation algorithm, Mask R-CNN, 33 has also recently been applied for structural condition assessment, which can perform object detection and semantic segmentation simultaneously. A crack assessment framework proposed by Kim et al. 34 uses Mask R-CNN to detect cracks using the input images taken from a real concrete wall.
CNN-based architectures have dominated the computer vision community since AlexNet 35 and VGGNet 36 won the renowned competition 37 on object recognition in 2012 and 2014, respectively. On the other hand, a novel neural network architecture, transformer, has also gained prominence in the natural language processing (NLP) community. Vaswani et al. 38 proposed the architecture first in 2017, based solely on the attention mechanism without using convolution. Later, transformer-based architectures, like BERT 39 and GPT-3, 40 achieved significant results in NLP due to their high representation capacity. Motivated by these significant results, transformers have recently been applied to computer vision tasks. In 2020, Dosovitskiy et al. 41 proposed a vision transformer model. This model applies a pure transformer directly to sequences of image patches and achieved state-of-the-art results on multiple image recognition benchmarks. Then, Liu et al. 42 introduced a new vision Transformer in 2021, namely the Swin Transformer, which can serve as a general-purpose backbone for computer vision tasks. A novel image segmentation method, the MaskFormer, 43 is proposed very soon after the Swin Transformer. It formulates semantic segmentation as a mask classification problem and outperforms the current state-of-the-art per-pixel classification models.
This article aims to achieve precise semantic segmentation on structural components and damages. Due to the lack of publicly available datasets that contain sufficient structural damage in the real scene, a synthetic dataset 44 that includes 2000 viaducts generated with random geometry and damage scenarios is used. This synthetic dataset, termed as Tokaido dataset, 44 consists of 8648 images for structural component recognition, as well as 7990 images for damage recognition. However, two main challenges are identified in the Tokaido dataset that makes per-pixel segmentation even harder using existing CNN-based segmentation methods: (1) Class-imbalance challenge: the minority classes such as “Sleeper” and “Exposed rebar” only occupy less than 1% of pixels in the original dataset. This may result in models biased toward the majority class. More importantly, the model may underfit the minority class because of limited training samples; (2) Small and thin object challenge: concrete damage and exposed rebar are often thin and subtle, which makes it difficult to perform accurate pixel-level localization of these objects. Motivated by the above observations, this article proposes a novel transformer-based framework for vision-based structural condition assessment. To the best of the authors’ knowledge, very few studies on structural condition assessment use the more advanced transformers for semantic segmentation. The main contributions of this work can be summarized as follows:
(1) A simple yet strong augmentation method, Copy-Paste, 45 is extended and adopted to address the class-imbalance problem in the Tokaido 44 dataset. Data augmentation is also performed at the same time to further boost the performance.
(2) A novel condition assessment framework is proposed based on the state-of-the-art semantic segmentation method, MaskFormer. 43 Besides, a state-of-the-art transformer architecture, Swin Transformer, 42 is used as the backbone in this framework for feature extraction.
(3) The performance of the proposed framework for structural condition assessment is evaluated on two tasks, structural component recognition and damage recognition. Besides, three state-of-the-art methods are compared to demonstrate the advantage of the proposed method. Our method outperforms existing methods by a significant margin with 97% and 90% mean Intersection Over Union (mIoU) for component and damage segmentation, respectively.
The rest of the article is organized as follows: Section “Methodology” describes the methodology; section “Experimental validations” presents the evaluation of the proposed approach for component and damage recognition, and conclusions are drawn in section “Conclusions.”
Methodology
In this study, a novel transformer-based framework for vision-based structural condition assessment is proposed. As shown in Figure 1, this framework is composed of four components: (1) a simple data augmentation component that randomly copy-and-paste objects, such as rails, from one image to another; (2) a transformer-based backbone that generates low-resolution feature maps from the original images; (3) a mask classification component that converts the per-pixel classification to mask classification seamlessly; and (4) an inference component that produces the semantic segmentation outputs from the mask classification outputs via simple matrix multiplication. The first three components are trained end-to-end as a deep neural network, while the last component is used only for inference. In the following subsections, each component is introduced in detail.
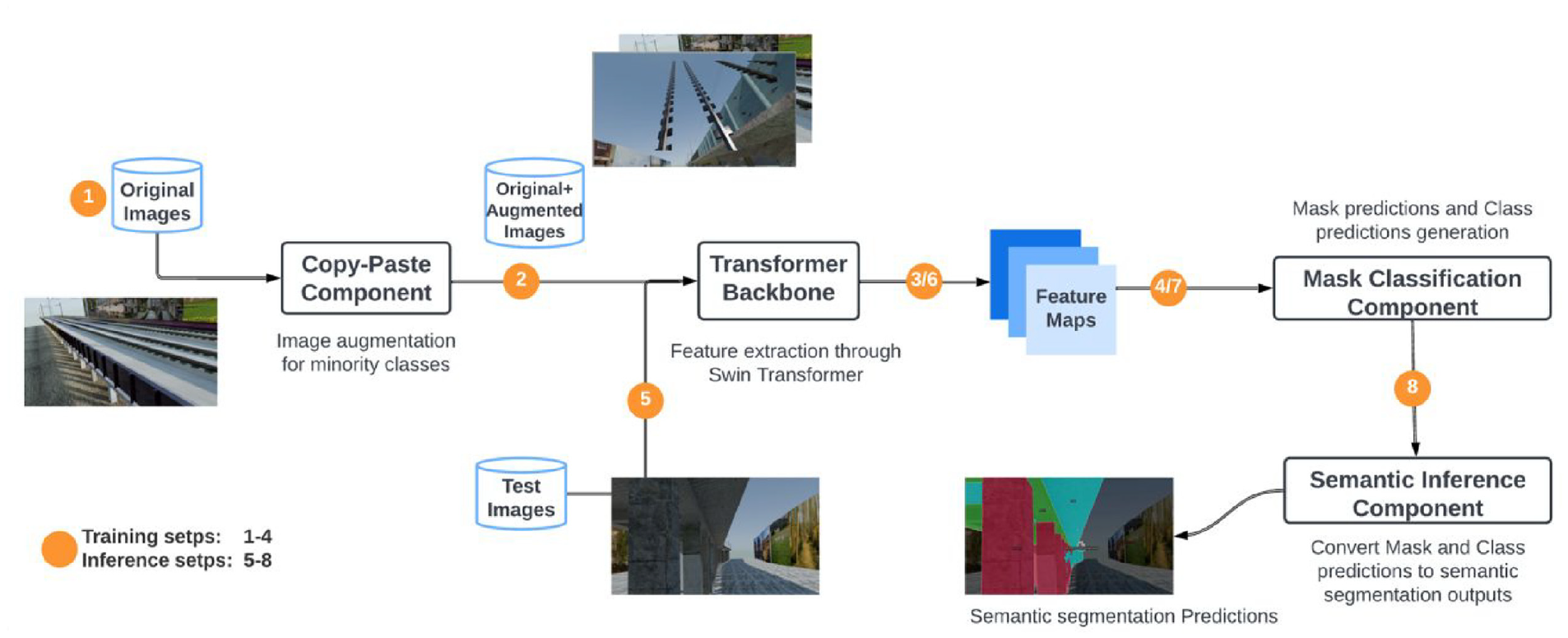
The proposed transformer-based framework for structural condition assessment.
Copy-Paste data augmentation
Data augmentation techniques have shown great promise for reducing the number of annotated images required for model training. Geometric transformations, flipping, color jittering, random cropping, rotation, and noise injection are widely used to augment images for achieving state-of-the-art results. 46 However, these transformations are standard augmentations used for general purposes and are not object aware. Recently, a novel data augmentation method, called Copy-Paste, 45 has been designed specifically for instance segmentation, demonstrating that it is a strong data augmentation method to copy and paste random objects from one image to another.
In this study, the Copy-Paste augmentation is extended and employed for semantic segmentation of structural components and damage with two modifications: (1) Copy-Paste is used only for minority classes. It is observed that the Tokaido dataset has a severe class-imbalance problem, where minority classes, such as “Sleeper” and “Exposed rebar,” occupy less than 1% pixels (see section “Data preparation” for statistic details). Instead of selecting a random subset of objects, we purposely copy and paste image regions of minority classes from one image to another, which addresses the data augmentation and class imbalance at the same time; (2) Related semantic classes are copied and pasted simultaneously. In the original Copy-Paste, 45 objects are separated into individual instances and copied and pasted from one image to another independently. It is specifically designed for instance segmentation on generic datasets with many classes (such as Common Objects in Context (COCO) 47 ) . The Tokaido dataset, in our case, is a specific railway viaduct dataset with limited component or damage categories and among which, there are physical structure bindings. For example, “Rail” comes together with “Sleeper” and “Exposed rebar” and usually appears on top of “Concrete damage.” It would dramatically alter the underlying data distribution if these relations are broken.
The revised Copy-Paste works as follows: we first split the training images into source images and target images, where source images are those that contain a significant number of pixels of the minority class and target images are others that contain little or no pixels of the minority class. Next, image regions of minority classes are copied from a random source image and pasted onto another random target image. To further improve the data diversity, additional transformations, including large-scale jittering and horizontal flips, are randomly applied to both source and target images before adding them together. For the Tokaido dataset, the minority classes being copy-pasted are “Rail” and “Sleeper” for component recognition, and “Concrete damage” and “Exposed rebar” for damage recognition. The transformations used are large-scale jittering and horizontal flips. It is noted that these transformations together with Copy-Paste result in augmented images that may be unrealistic. These unrealistic images, however, provide additional cues for training deep learning models and can improve the model performance significantly, as shown in the original paper 45 and our ablation study. Sample images generated by Copy-Paste are presented in Figure 2.

Example images generated by Copy-Paste.
Swin Transformer backbone
The backbone is one of the most critical components for deep-learning-based vision models, which is responsible for extracting features from input images. Convolutional networks, in particular Residual Convolutional Networks (ResNet), have been widely used as the de facto backbone for most deep vision models, because of their inherent inductive bias on capturing local information. Transformers that use the attention mechanism to model long-range dependencies in data have achieved tremendous success in natural language processing. Recent studies 41 investigated how it could be adapted to vision tasks and demonstrated the superior scalability of vision transformers, that is, when trained with large-scale data vision transformers yield even better results than CNNs. In this study, a state-of-the-art transformer architecture, namely Swin Transformer, 42 is employed as the backbone of the proposed framework.
Figure 3 provides an overview of the backbone architecture. It consists of four main modules: patch partition, linear embedding, Swin Transformer block, and patch merging. Each of these components is briefly introduced.
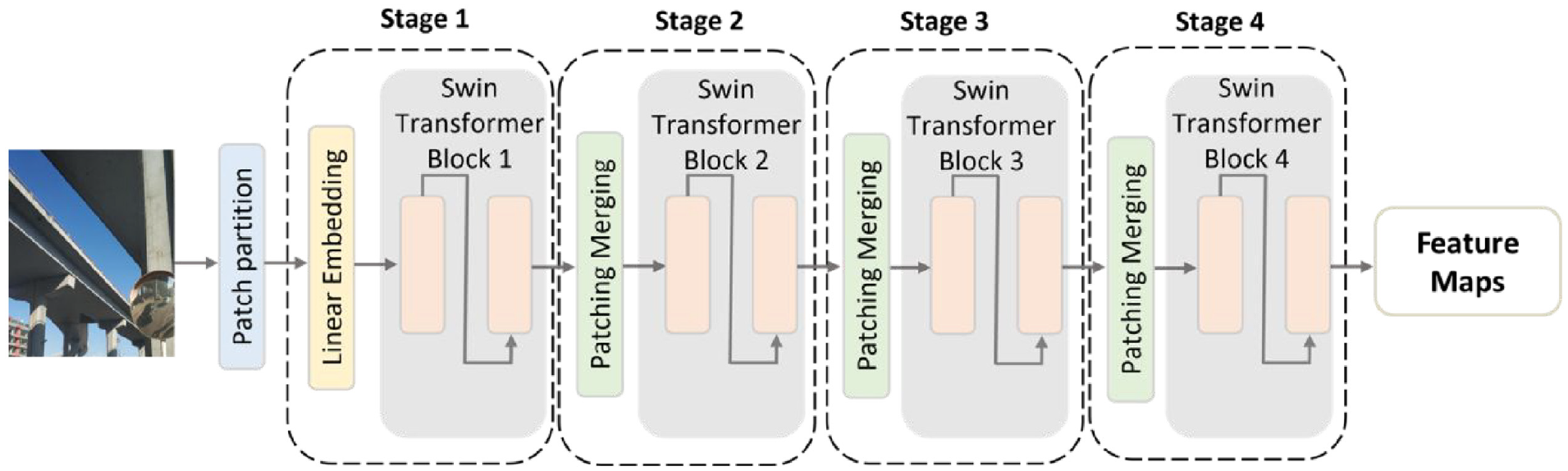
Transformer-based backbone: Swin Transformer. 42
Patch partition is used to divide RGB images into non-overlapping patches or tokens. For each patch, the feature is set as a concatenation of the RGB values of raw pixels.
Linear embedding is generally a vanilla neural network that converts the input feature to an arbitrary dimensional vector.
Swin Transformer block: For a standard transformer, multi-head self-attention (MHSA) blocks are used to compute the relationships between a patch token and all other patch tokens, which learn the global attention with a very high computational complexity. The Swin Transformer block modifies the MHSA that computes self-attention within local windows to improve the computation efficiency. However, window-based self-attention (W-MHSA) may limit the modeling power due to the lack of connections across windows. Thus, a shifted window self-attention (SW-MHSA) that introduces cross-window connections is used after W-MHSA successively in the Swin Transformer blocks.
Patch merging is a linear layer that is used to reduce the number of tokens to produce a hierarchical representation as the network gets deeper.
As illustrated in Figure 3, these four modules stack successively that form the Swin Transformer. A hierarchical representation of the original images with the same feature map resolutions as those of typical CNNs is produced. This allows the Swin Transformer to easily replace existing backbone networks in computer vision tasks.
Mask classification component—MaskFormer
Most deep-learning-based methods for semantic segmentation, including convolutional network-based and transformer-based methods, treat semantic segmentation as a per-pixel classification problem. It aims to partition an image into different regions by labeling each pixel with its corresponding semantic class. In contrast to per-pixel classification, mask classification-based methods predict a set of binary masks, each corresponding to a single class prediction. Research using mask classification shows more advancement in instance-level segmentation, such as Mask R-CNN 33 and Detection Transformer, 48 but a new model named MaskFormer shows superior semantic segmentation performance over existing per-pixel methods. Also, MaskFormer requires only a cross-entropy classification loss and a binary mask loss for training, whereas most existing mask classification methods require auxiliary losses, such as a bounding box loss.
In this study, MaskFormer is employed in the proposed framework as the third component which automatically converts the per-pixel classification backbone into a mask classification. As illustrated in Figure 4, the Mask Classification Component contains (1) a pixel-level module that generates per-pixel embeddings from the low-resolution feature maps by the backbone component. A pixel decoder is used to up-sample those feature maps gradually to the original image height and weight; (2) a Transformer module computes N per-segment embeddings using a stack of Transformer decoder layers, and (3) a segmentation module produces predictions from these N per-segment embeddings. A linear classifier with softmax activation is trained to compute class predictions for each segment, and two Multi-Layer Perceptron layers transform the N per-segment embeddings into N mask embeddings. The mask predictions are then determined by making a dot product between the mask embeddings and the pixel-level embeddings obtained from the pixel-level module.
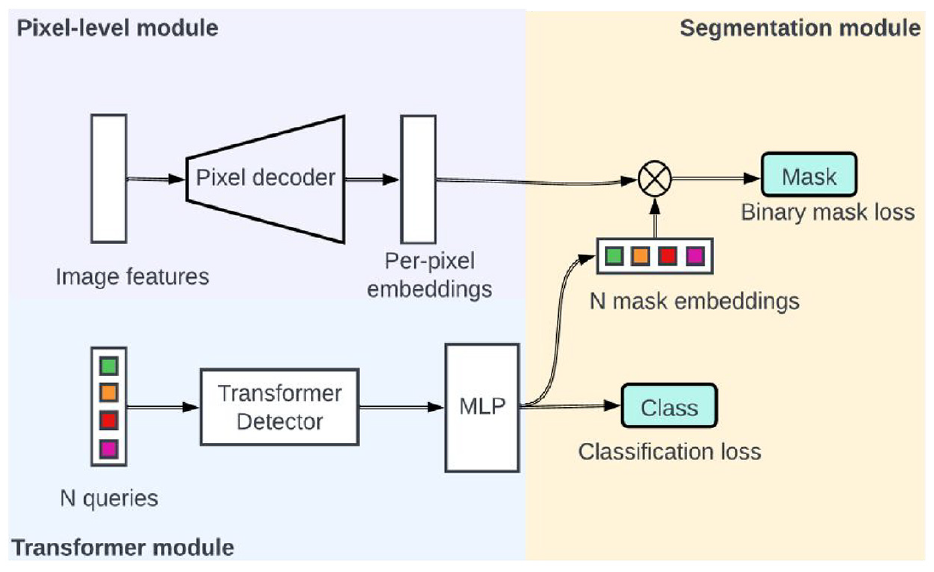
The mask classification component of the proposed framework.
To train this model, the classification predictions and mask predictions are directly used to compute the costs, that is, the cost function is composed of a cross-entropy classification loss
Semantic inference component
The output of the third module consists of two parts: binary mask predictions and per-mask class predictions. The former indicates the mask location, and the latter identifies the class label associated with the mask. These are still per-mask predictions rather than per-pixel predictions. The last component is to convert these predictions to the semantic segmentation output format for inference and is therefore only used during testing. It is noted that the mask predictions are represented by a binary matrix of size N × H × W, where each entry represents if a pixel in the position (H,W) belongs to one of the N masks or not. The class predictions are denoted by a matrix of size N × (K + 1) where each entry represents the probability of the N masks belonging to K + 1 classes (adding a null class). By dropping the null class, the per-pixel predictions K × H × W is obtained with a simple matrix multiplication operation, where each entry represents the probability of one pixel belonging to one component or damage class.
Experimental validations
Data preparation
Image resolution
The provided Tokaido dataset 44 consists of 7575 training images and 1073 testing images for structural component recognition, 7081 training images (including 2700 pure texture images) and 909 testing images (including 300 pure texture images) for damage recognition. Training images are associated with ground truth label images, which are referred to as masks, while the masks of testing images are not given. All images, including training and testing, are of the same resolution of 1920 × 1080, while the provided mask images are of the same size of 640 × 360. To make full use of the high-resolution image, the mask is resized to the image size 1920 × 1080 instead of downsizing the image, using the nearest neighbor interpolation (so no new label will be generated).
Dataset split
As no official validation data are given, 20% of the training data is used as the validation dataset for the sake of model selection and hyperparameter tuning.
Copy-Paste augmentation
For component recognition, there are eight predefined classes, namely “non-bridge,”“slab,”“beam,”“column,”“non-structural components,”“rail,”“sleeper,” and “other components.” Among them, “non-bridge” and “other components” are not of interest in component recognition and are thus not considered in the performance evaluation. In addition, it is observed that the class labels are significantly imbalanced in the original dataset. As shown in Table 1, the majority class “non-bridge” takes more than half of the total pixels, while the minority classes “rail,”“sleeper,” and “other components” have less than 1% pixels. The severe class-imbalance problem may result in models biased toward the majority class. More importantly, the model may be underfitting to the minority class due to limited training samples.
Statistical distribution of class labels before and after copy-paste.
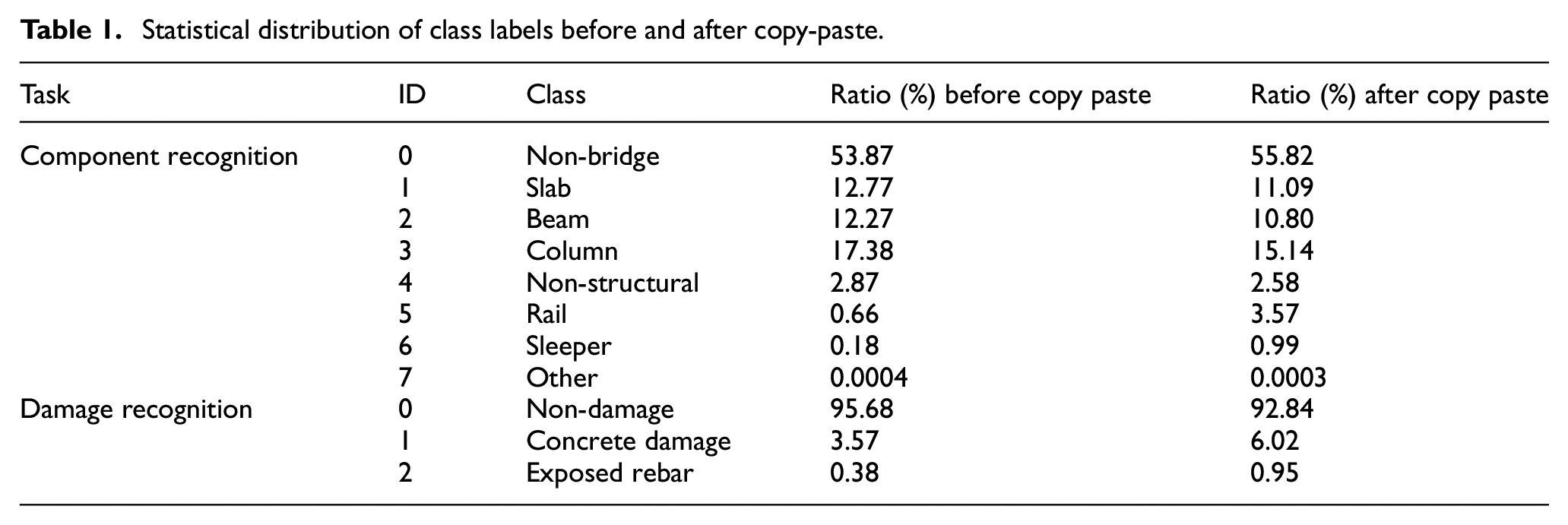
This problem is addressed using the technique “Copy-Paste” described in section “ Copy-Paste data augmentation.” In all, 3000 images are generated for component recognition and 5000 images for damage recognition (to increase the minority class to roughly 1%). The class distribution after copy-paste is also shown in Table 1. The generated images are added to the training set, resulting in 8951 (training) and 1623 (validation) images for component recognition, and 10,593 (training) and 1486 (validation) images for damage recognition. It is noted that the official test set remains untouched during the whole training and validation process and is only used for the final blind testing.
Training protocol
The model training consists of three stages, namely ImageNet pretraining, Ade20k pretraining, and Tokaido fine-tuning. All training data are publicly available and public model weights are used for the first two stages.
ImageNet pretraining of the backbone
The backbone module, Swin Transformer, is pretrained using ImageNet22k 51 dataset, which involves classification with 14.2 million images and 22k classes. The training involves two stages: pretraining on ImageNet22k with 224 × 224 inputs for 90 epochs and fine-tuning on the regular ImageNet1k 51 with 384 × 384 inputs for another 30 epochs. A more detailed configuration can be found in Liu et al. 42
ADE20k pretraining of MaskFormer
The pretrained backbone is integrated with the MaskFormer module and trained on ADE20k 52 dataset for the semantic segmentation task, which contains 20k images from 150 semantic classes. The model is trained with the input size 640 × 640 for 160k iterations. More configuration details can be found in Cheng et al. 43
Fine-tuning on the Tokaido dataset
The entire model is finally fine-tuned on the Tokaido dataset, described in section “Data preparation.” The popular Facebook Detectron2 53 library is used and the commonly used training protocols are followed for both component and damage recognition. More specifically, AdamW 54 optimizer is used with a poly-learning rate schedule, a base learning rate of 0.0001, and a weight decay of 0.05. A learning rate multiplier of 0.1 is applied to the backbone network to slow down its update speed. In addition to the manual copy-paste augmentation, the standard data augmentation is used on the fly, including random scale jittering between 0.5 and 2.0, random horizontal flipping, and random color jittering. Due to GPU memory limitation, random cropping with the size of 960 × 540 (a quarter of the input image of resolution 1920 × 1080) is also used, which means the model would see different patches for the same image among epochs. The model with a batch size of 16 for 160k iterations on 8 TITAN RTX GPUs is trained.
Evaluation
The model performance is evaluated using two semantic segmentation metrics: mIoU and mean accuracy (mAcc). mIoU is the average over the IoUs of each class, given IoU = TP/(TP + FP + FN) where TP is true positive, FP is false positive, and FN is false negative. “mAcc” denotes the fraction of correct pixels per class averaged over all classes.
Training curves
To monitor the model performance during training, an evaluation is conducted every 5k iterations on the validation set. The training curves, including training loss and segmentation performance, are shown in Figures 5 and 6 for component and damage recognition, respectively. It can be seen that the training loss decreases smoothly, while the validation performance keeps increasing.
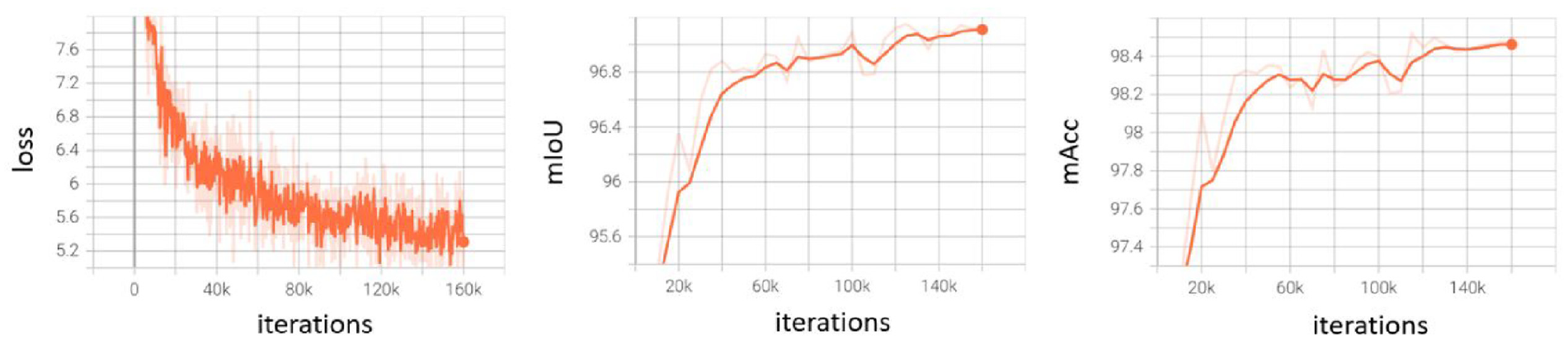
Training curves for component recognition. Left: loss curves on the training set. Middle and right: performance curves on the validation set.
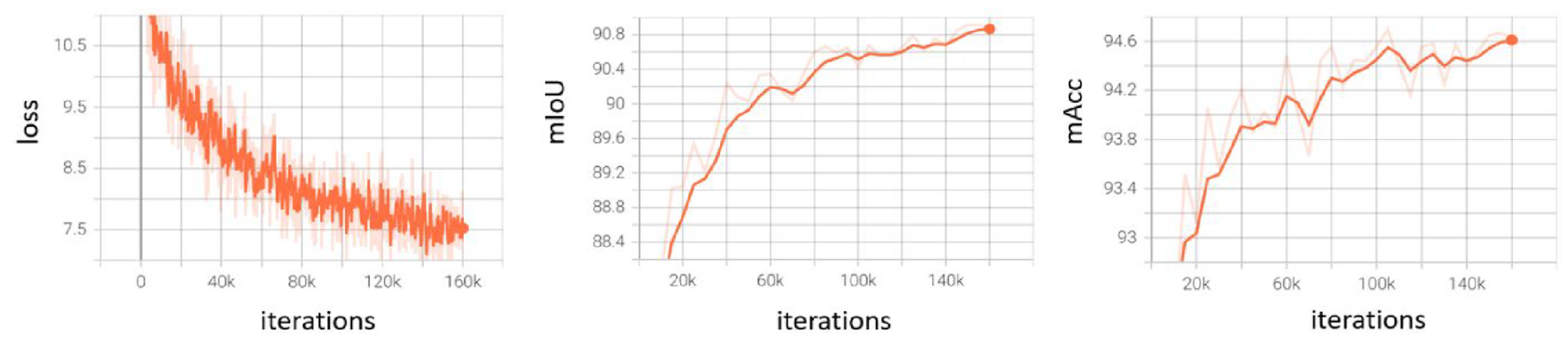
Training curves for damage recognition. Left: loss curves on the training set. Middle and right: performance curves on the validation set.
Structural component recognition results
Once the training is done, the trained model is applied to the validation set for the final evaluation. The IoU is compared with three state-of-the-art models, that is, the FCN58 network reported in the original Tokaido dataset paper, 44 the best version of ensembled models proposed by Liu et al., 55 and the multi-task high-resolution net (MT-HRNet: composed of multiple ResNet architectures) proposed by Ye et al. 56 . Table 2 shows the performance of the structural component recognition task on the validation set. As the testing set is not officially provided, the validation performance is compared with the testing performance reported by Narazaki et al. 44 Table 2 shows the comparisons of the IoU per semantic class, as well as the mIoU. Besides, the pixel accuracy (Acc) and mAcc values are presented for further demonstration. The mIoU is compared with the MT-HRNet since Ye et al. 56 only reported the mean IoU across all classes. Our model achieved around 97% mIoU for component recognition, which is a significant improvement compared to 87.9%, 83.6%, and 71.9% as reported by Narazaki et al., 44 Liu et al., 55 and Ye et al., 56 respectively. Interestingly, the per-class metrics indicate that the higher the class ratio (Table 1) the better the performance, which makes sense as discussed that the model may underfit the minority class. For the least three minority classes, “Non-structural,”“Rail,” and “Sleeper,” our model still shows more than 20% improvement in IoU compared to either Liu et al. 55 or Narazaki et al. 44 A 2% performance gain (89%–91%) is also observed in the minority class “Sleeper” after applying copy-paste, which also indicates the importance of having sufficient training data.
Model performance for structural component recognition (%).
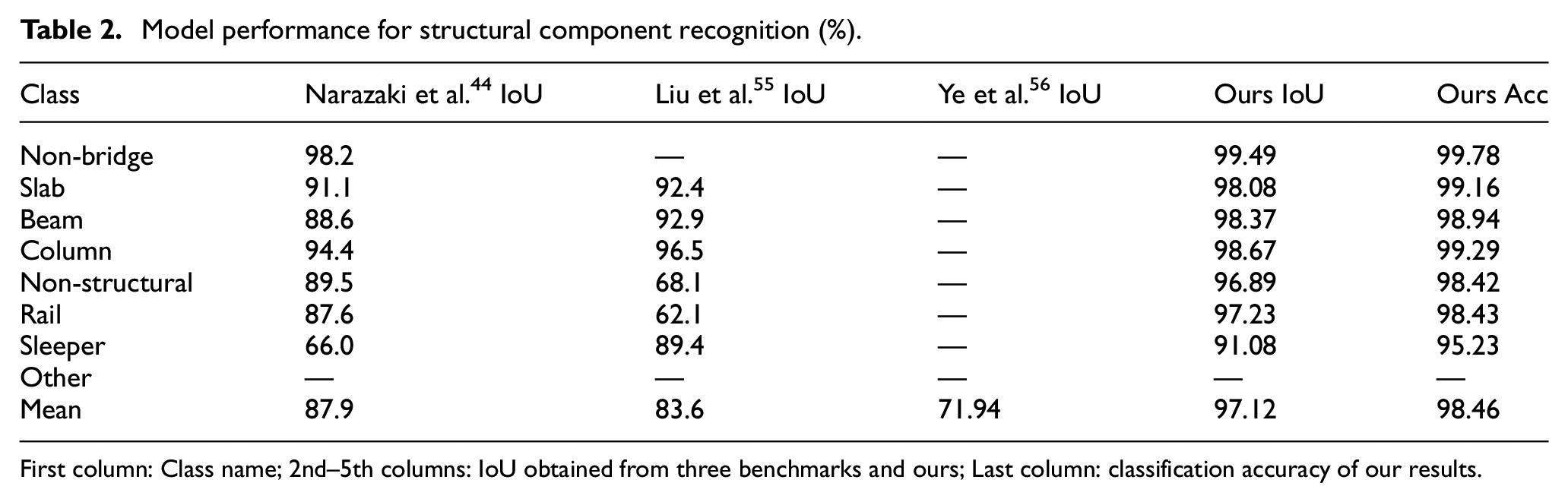
First column: Class name; 2nd–5th columns: IoU obtained from three benchmarks and ours; Last column: classification accuracy of our results.
Damage recognition results
Table 3 reports the performance of the damage recognition task on the validation set. Similarly, our model is compared with the three state-of-the-art models, namely an FCN 44 network, an ensembled model 55 and the MT-HRNet. 56 The damage dataset is composed of three classes, with the “Non-damage” class accounting for the majority of pixels (Table 1). The proposed model significantly outperforms the previous state-of-the-art in all classes. In detail, the proposed model achieves +2.20%, +20.61%, and +9.84% higher IoU than the previous state-of-the-arts in “Non-damage,”“Concrete damage,” and “Exposed rebar,” respectively. Overall, the proposed model achieves the highest mean IoU (90.89%) in comparison to the reported state-of-the-art results.
Model performance for damage recognition (%).
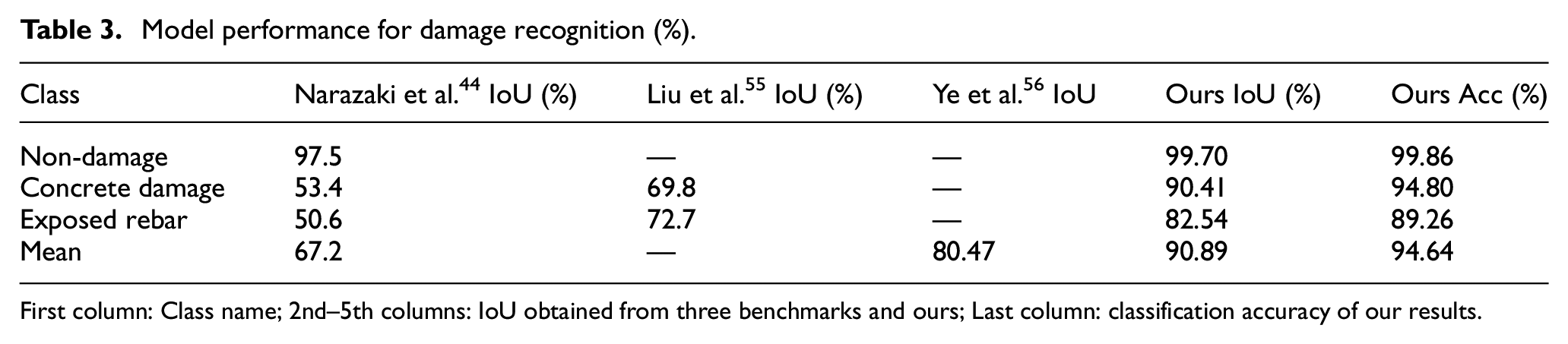
First column: Class name; 2nd–5th columns: IoU obtained from three benchmarks and ours; Last column: classification accuracy of our results.
Ablation study
Next, an ablation study is conducted on component recognition to investigate the effect of several techniques used in our model, including Swin Transformer backbone, Ade20k pretraining, copy-paste, larger input size, and longer training, as shown in Table 4. Each technique indicates the following: “transformer backbone” means that the backbone from ResNet101 57 is switched to Swin Transformer; Without “Ade20k pretraining,” means that all modules except the backbone will be trained from scratch (while the backbone is still pretrained on ImageNet); “Copy-Paste” means that 3000 synthetic images are added to boost the ratio of minority classes; “Larger input size” means the crop size of input images increases from 640 × 512 to 960 × 540, while “Longer training” means that the training iterations are increased from 90k to 160k.
Ablation study of model performance on the validation set.

It can be seen that using Swin Transformer as the backbone significantly improves the performance (8%), which is aligned with the results using MaskFormer. 43 Pretraining on additional datasets for semantic segmentation also gives a large boost (4%), despite the semantic gap between Ade20k and Tokaido datasets. It is hypothesized that the Tokaido dataset does not have enough “meaningful” data to train such a big model (noting that more than half of the pixels are background). Copy-Paste is shown to be an effective data augmentation technique, especially for the minority class. Higher image resolution and longer training improve the performance marginally, with the cost of memory and time consumption.
Result analysis
Figure 7 presents several sample images from the validation set, where the left column is the input image, the middle column is the model prediction, and the right column is the ground truth mask. It is seen that the model generates high-quality masks for most scenarios. It is shown in the error case (the 4th row) that the model has difficulty separating different components in the far end of the picture (where the depth is large). This is expected as the model generates prediction largely based on local texture rather than global structure information, which makes it challenging to recognize components in regions where everything collapses together. On the other hand, it is also hard for the model to recognize “small and thin” stuff, such as electrical wires and sleepers in component recognition which generally outspread to the far end, and exposed rebar in damage recognition which is usually very small. These limitations explain why the model underperforms in these component classes.

Sample images from the validation set. The left column is the input image, the middle column is the prediction, and the right column is the ground truth provided. Zoom-in to visualize the class name.
It is found that there are incorrect annotations in the ground truth. For example, in the last row and last column of Figure 7, the damage in the middle pillar is missed while the model successfully picked it up (last row middle column). Another interesting finding is that the model produces a smoother boundary around objects compared to the ground truth, as shown in Figure 8. It is obviously desired to have smooth edges as it aligns better with physical objects in the real world. It is noted that edges (white lines) are pixels with no label assigned, and they are discarded during both training and evaluation. The Kaggle evaluation does not ignore edge pixels, resulting in a big difference between validation and testing performance. This will be discussed in more detail in the next section.
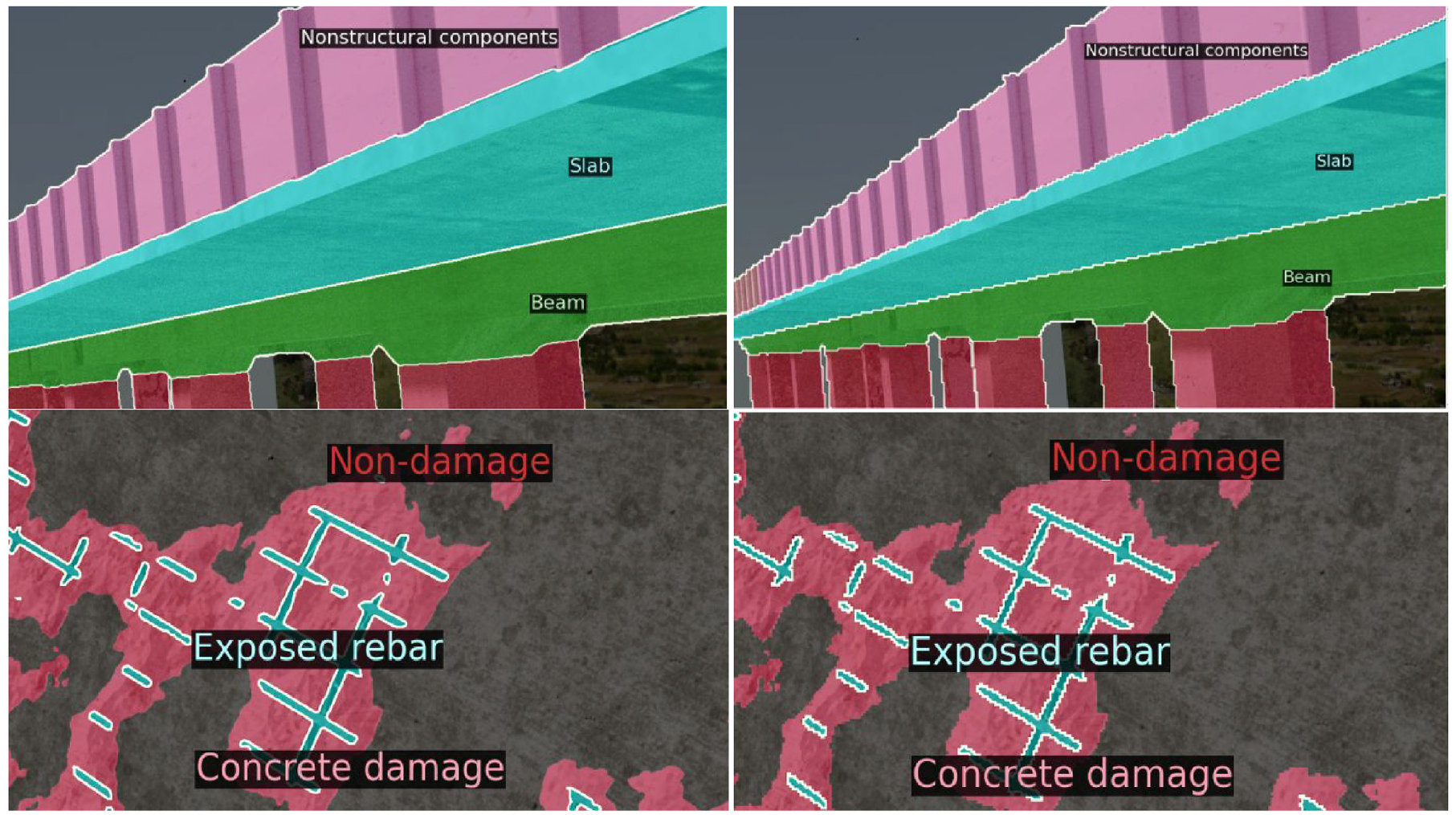
Zoom-in comparison of model predictions (left) and provided ground truth annotations (right). The model produces smooth edges.
Blind testing on Kaggle
After model selection and hyperparameter tuning on the validation set, the validation set is added to the training set and train the model again with the same hyperparameters (noting this is fine as the validation set comes from training data anyway). The obtained model is applied to testing images of full resolution (1920 × 1080) and the predicted segmentation mask is then downsized to 640 × 360, as per the submission guideline.
The proposed approach achieves 86.97% and 53.53% mIoU on the test datasets for component and damage segmentation, respectively. These results are both ranked number one out of 31 teams in the Kaggle competition leaderboard, I outperforming the second-best significantly (which are 84.48% and 44.28%). It is noted that these scores are lower than those obtained on the validation set (97.12% and 90.89%), and it is due to the different ways of calculating the metric. There is a much larger performance difference for the damage recognition, and it is hypothesized that this is because of the edge inconsistency mentioned in section “Evaluation.” As shown in Figures 7 and 8, more arbitrary edges are present in images of damage recognition due to the nature of concrete damage and exposed rebar. The edge inconsistency between model prediction and ground truth results in plenty of false positives within the boundary. This is not a problem when edge pixels are completely discarded during the evaluation (as done by the competition panel and us), but it lowers the score significantly when the false positive on edges is counted (as done by Kaggle evaluation). A large performance boost is expected when the standard semantic segmentation evaluation is used.
Conclusions
This article proposes an accurate transformer-based model for vision-based structural condition assessment that can recognize and localize critical structural components and damage to those components. To enhance the synthetic Tokaido dataset that is used, an advanced data augmentation technique called Copy-Paste is employed to address both data scarcity and class-imbalance problems. Instead of using a classic fully CNN, state-of-the-art transformer architectures are adopted, including Swin Transformer and MaskFormer, which tackle semantic segmentation as a mask classification rather than a per-pixel classification problem. The proposed model takes an image of arbitrary size as input and produces a segmentation map (mask) as output, indicating the per-pixel category of component or damage. The trained model yields fairly promising results on the Tokaido dataset, achieving 97.12% mIoU and 98.46% pixel accuracy for component segmentation, and 90.89% mIoU and 94.64% pixel accuracy for damage segmentation, with an inference speed of less than a second for a 1920 × 1080 image. The proposed approach can serve as an autonomous tool to facilitate the study of vision-based structure condition assessment. The superior result of the proposed approach also suggests the necessity to use the state-of-the-art deep learning techniques for structural engineering problems, which in general leads to better identification results.
Several future works are identified: (1) real-world images. The proposed model is trained and tested using synthetic data only. It will be interesting to study how it performs on real data and how to bridge the gap between synthetic and real data; (2) depth maps. Depth estimation and semantic segmentation are two similar problems from the computer vision perspective. It is worth investigating if these two tasks can facilitate each other and can be addressed by a unified model.
Footnotes
Acknowledgements
The authors would like to acknowledge the committee of the 2nd International Competition for Structural Health Monitoring (IC-SHM 2021) for organization and material sharing.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.