
Abstract
The dataset in the application scenario of existing fault diagnosis methods is often balanced, while the data collected under actual working conditions are often imbalanced. Directly applying existing fault diagnosis methods to this scenario will lead to poor diagnosis effect. In view of the above problems, we proposed a method called dual generative adversarial networks (DGANs) combining conditional assistance and feature enhancement. The method uses data augmentation as a basic strategy to supplement imbalanced datasets by generating high-quality data. Firstly, a new generator is designed to build the basic framework by sharing the dual-branch deconvolutional neural networks, and combining the label auxiliary information and the coral distance loss function to ensure the diversity of generated samples. Secondly, a new discriminator was designed, which is based on deep convolutional neural networks and embedded with auxiliary classifiers, further expanding the function of the discriminator. Thirdly, the self-attention module is introduced into both the generator and the discriminator to enhance deep feature learning and improve the quality of generated samples; finally, the proposed method is experimentally validated on datasets of two different testbeds. The experimental results show that the proposed method can generate fake samples with rich diversity and high quality, using these samples to supplement the imbalanced dataset, the effect of imbalanced fault diagnosis has been substantially improved. This method can be used to solve the problem of fault diagnosis in the case of sample imbalance, which often exists in actual working conditions.
Introduction
Rolling bearings are the core components of the transmission device of rotating machinery, and their reliability affects the operation of the entire rotating machinery. Therefore, timely and effective fault diagnosis of rolling bearings provides an important guarantee for the safe and reliable operation of rotating machinery.1–3 At present, the fault diagnosis methods based on artificial intelligence have the ability to learn features independently, which avoids the drawbacks of methods based on signal processing that require a lot of prior knowledge support and human support for feature selection, achieving good diagnosis results.4–6 So, the method based on artificial intelligence is currently the mainstream method of bearing fault diagnosis.
To ensure better and stable fault diagnosis effects of rolling bearings, methods based on artificial intelligence often require a large number of balanced samples for driving.7–9 However, in real working conditions, the bearings of rotating mechanical equipment are often running in a normal state. Considering safety and economy, when bearing failures occur, mechanical equipment will be immediately stopped. Therefore, there are often more normal samples collected, but fewer fault samples, and the number of fault samples is far less than that of normal samples. Due to the large difference between the number of normal samples and the number of fault samples, there is an imbalance between normal samples and fault samples. It is difficult for a small number of fault samples to meet the needs of artificial intelligence fault diagnosis methods that require a large number of balanced samples to drive, resulting in the reduction of fault diagnosis accuracy.
Since the samples collected in actual working conditions are often imbalanced, imbalanced fault diagnosis has always been a difficult and hot topic in the field of fault diagnosis.10,11 In recent years, scholars have put forward many solutions for imbalanced fault diagnosis, which can be generally summarized into three categories: data augmentation method, feature learning method, and classifier design method. 12 The method of data augmentation starts from the perspective of data preprocessing, the original limited amount of fault data is supplemented by data generation or data oversampling. For example, Yi et al. 13 proposed a minority class clustering SMOTE method to improve the imbalanced classification performance. Liu et al. 14 introduced an imbalanced fault diagnosis method based on improved multi-scale residual generative adversarial network (GAN) and feature enhancement-driven capsule network, which achieved the enhanced performance of imbalanced fault classification. The method based on feature learning takes feature extraction as an entry point, without generating data, and learns fault features from limited fault data by designing a regularized neural network or feature extraction model. For instance, Saufi et al. 15 designed a deep learning model based on stacked sparse autoencoder model to deal with limited sample data, and achieved good diagnostic performance on experimental gearbox and wind turbine gearbox datasets respectively. Li et al. 16 raised a fault diagnosis method called deep balanced domain adaptation neural network for fault diagnosis, which achieved satisfactory results in the case of limited labeled data of planetary gearbox. The method based on classifier design starts from the aspect of conditional classification, and directly classifies the imbalanced samples by designing a classifier adapted to the imbalanced samples, without generating data or designing a feature extraction model. For instance, Jia et al. 17 came up with a framework called deep normalized convolutional neural network (CNN) and developed a weighted Softmax class weighting strategy to classify imbalanced faults. He et al. 18 presented a support tensor machine with dynamic penalty factor and applied it to the fault diagnosis of rotating machinery, which achieved good classification results when the training samples were imbalanced data. Although the methods based on feature learning and methods based on classifier design have achieved good diagnostic results in imbalanced fault diagnosis, they cannot be flexibly applied to the imbalanced scene with variable number of fault samples due to the limitation of their basic motivation (directly processing imbalanced data), which leads to the poor generalization ability of the model and certain limitations in the application scope. However, the method based on data augmentation avoids the drawbacks of the above methods due to different basic motivations (supplemental data to imbalanced data), and becomes a very practical and promising method to improve the accuracy of imbalanced fault diagnosis and ensure the generalization ability of the model.
GAN 19 is a data augmentation method. Comparing with other data augmentation methods, such as SMOTE, ADASYN, etc., GAN is often used for data enhancement, due to its own structural characteristics, which has the ability to continuously learn. Numerous GAN variant networks emerged. For example, Wang et al. 20 proposed an enhanced GAN, based on the use of degree convolution Generative Adversarial network to generate samples, the integral K-means clustering algorithm was introduced into the CNN fault diagnosis model to improve the classification accuracy. Zhang et al. 21 put forward a fault diagnosis method based on deep learning to address the data imbalance problem by explicitly creating additional training data. Zhou et al. 22 used a scheme of global optimization to design a new generator and discriminator, aiming to generate those fault features extracted from a few fault samples via Auto Encoder instead of fault data sample. Zhao and Yuan 23 raised an improved GAN to improve the fault diagnosis performance of imbalanced data. The above-mentioned GAN variant networks have achieved good diagnostic results in imbalanced fault diagnosis. However, since the basic structure adopted the GAN model, the adversarial mechanism brought by its unique structural characteristics can also make it difficult to maintain a balance between the generator and the discriminator; there are still problems of mode collapse or gradient disappearance, which may lead to insufficient diversity of generated samples and unstable convergence of model, affecting the quality of generated samples. In order to better overcome the above problems, this paper proposed dual generative adversarial networks (DGANs) combining conditional assistance and feature enhancement for imbalanced fault diagnosis. The method combines the label auxiliary information, and integrates the shared dual-branch strategy that embed with the coral distance to increase the diversity of generated samples; meanwhile, a self-attention module is introduced to enhance the depth features to improve the quality of the generated samples.
The method proposed in this paper is a novel data augmentation method, and the detailed description is as follows. Firstly, the label auxiliary information is introduced into both the generator and the discriminator to ensure the diversity of sample generated. Secondly, a new generator is designed with a shared dual-branch deconvolutional neural network (DCNN), and the coral distance loss function is embedded to increase the diversity of generated samples by maximizing the coral distance. Thirdly, a CNN is used to design a discriminator to extract useful feature information and degradation information of input samples, and an auxiliary classifier is embedded to further expand the function of the discriminator. Then, the self-attention module is introduced into the generator and the discriminator to promote the ability of the network to automatically learn important global information, improve the discrimination performance of discriminator and the ability of generator to generate samples, and compensate for the possible reduction in similarity due to sample diversity. Finally, through continuous adversarial training between the generator and the discriminator, the generator generates fake samples with rich diversity and high quality, and supplements the generated fake samples into the imbalanced dataset for fault diagnosis. The main contributions of the proposed method are as follows:
A new generator is designed using a shared dual-branch DCNN, and a new loss function is designed to help the generation of sample diversity by embedding label auxiliary information and a coral distance loss function to prevent mode collapse.
A new discriminator is designed by using CNN and embedding auxiliary classifier, and a self-attention module is introduced in both the discriminator and the generator to enhance deep feature learning and improve the quality of generated samples.
The experimental results show that the proposed method is used to generate data and supplement imbalanced datasets to substantially improve the performance of imbalanced fault diagnosis.
The rest of this paper is structured as follows. In section of theoretical background, the theoretical background of the basic knowledge used in the proposed method is introduced in detail. In section of the proposed method, the specific process of the proposed method is introduced in detail. In section of experimental verification, the effectiveness and superiority of the proposed method are proved by experiments on two different datasets. In section of conclusion, the proposed method is summarized and further prospected.
Theoretical background
Convolutional neural networks and deconvolutional neural networks
Convolutional neural networks
CNNs are widely used in the field of fault diagnosis.24,25 The deep CNNs can extract the deep features of the input signal through the deep network, and can make effective judgments on the extracted deep features and identify the fault type. Deep CNNs are mainly composed of convolutional layers, activation layers, pooling layers, and fully connected layers.
The convolution layer actually uses the convolution kernel to downsample the input signal, and the result obtained after downsampling is expressed as a specific local feature extracted from the input signal. The mathematical expression of the convolution operation is as follows:

where,
The main function of the activation layer is to non-linearly map the result after the convolution operation. Common activation functions mainly include tanh, Sigmoid, Relu, LeakyRelu, Selu, etc. The corresponding activation function can be selected according to the network architecture and actual needs. For example, the mathematical expression of LeakyRelu is as follows:
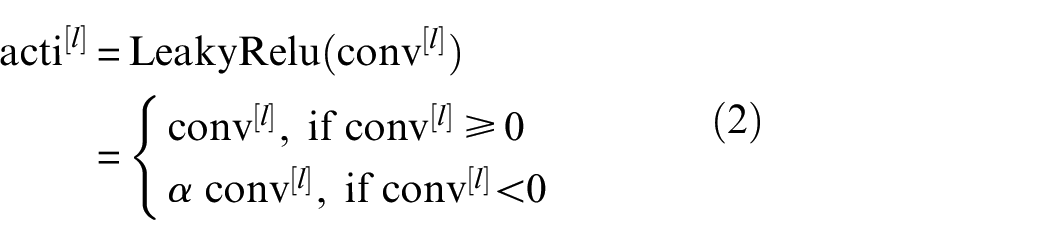
where, the value of
The pooling layer further filters the activated features, extracts representative features that can better represent the original signal, and can effectively reduce the scale of the output features, reduce the amounts of parameters of the model, and improve the computational efficiency of the model. The pooling layer is usually divided into maximum pooling and average pooling according to different operation types. The most commonly used is maximum pooling, which takes the largest feature value extracted in the receptive field as the output. The mathematical expression is as follows:

The fully connected layer is responsible for recombining the pooled features and mapping the multi-dimensional feature input to the two-dimensional feature output. The mathematical formula is as follows:
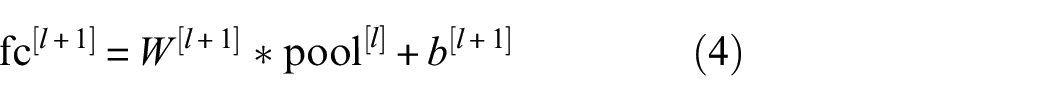
Among them,
The output of the fully connected layer is regressed or classified according to task requirements. Generally, classification tasks are most common in fault diagnosis. Softmax activation function is generally used for classification, and its mathematical expression is as follows:
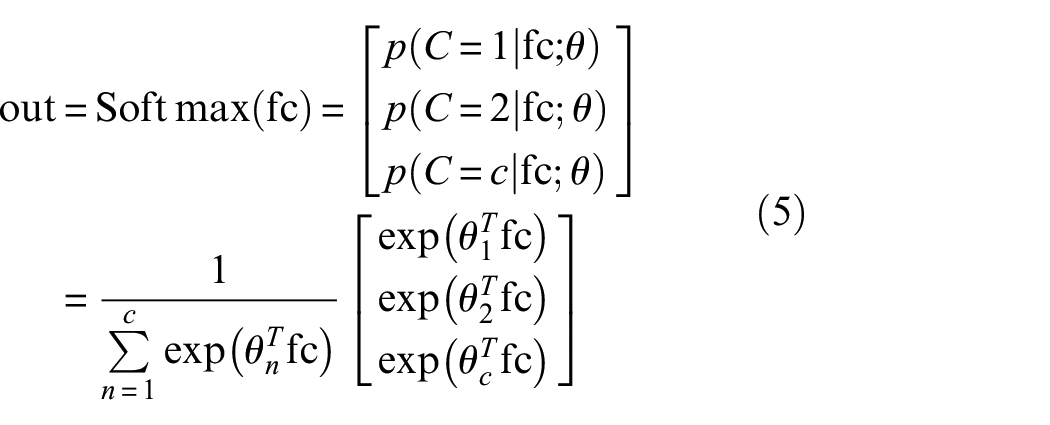
where
Finally, calculate the classification loss function of Softmax, the mathematical formula is as follows:

Among them,
Deconvolutional neural networks
DCNNs is also called transposed CNNs. As the name implies, it is generally opposite to the function of CNNs. Each layer of DCNN can be regarded as the inverse process of the corresponding layer of CNNs. 26 Therefore, the DCNNs can be understood as the process of reconstructing the features extracted by the CNNs and restoring the input. The general composition of DCNNs is composed of deconvolution layers, activation layers, and unpooling layers. The deconvolution layer is a deconvolution operation on the original feature matrix to expand its dimension to match the input of the corresponding convolution layer. Its input-to-output dimensional transformation relationship is exactly the opposite of that of convolution. The operation of the activation layer is consistent with the operation of the CNNs, both to increase the nonlinearity of the network. The operation process of the unpooling layer is also the inverse process of the pooling layer of the CNNs, to supplement the reduced features and further restore the original input. For example, the unpooling operation process of maximum pooling is to place the input value at the position index of the maximum value recorded during the corresponding maximum pooling, and other positions are supplemented with 0, and the input size is equal to the output size of pooling layer of the corresponding CNNs. Due to the special properties of the DCNNs, it has a wide range of applications, such as image restoration and speech recognition.
Auxiliary classifier generative adversarial networks
GAN is a classic adversarial neural network, which is mainly composed of generator and discriminator, as shown in Figure 1(a). The core of GAN is to introduce the idea of the game in Go. The generator and the discriminator continue to play, prompting the generator to generate fake samples that are closer to the real samples. The overall optimization objective formula is as follows:
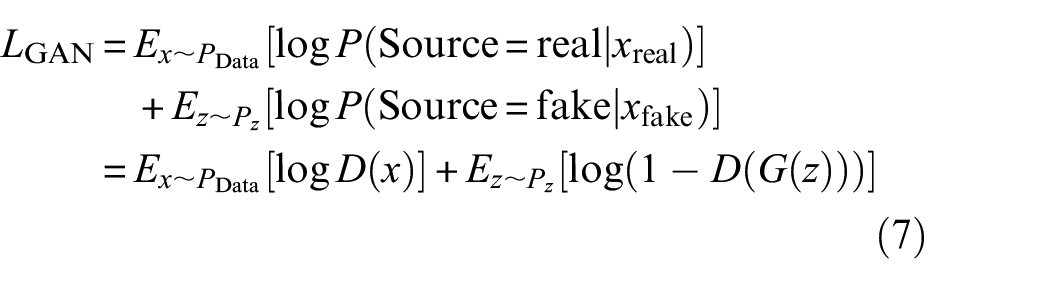
where, x represents the real sample, G(z) represents the generated sample, and z represents the random noise; D(x) and D(G(z)) represent the discriminant probability of the discriminator to the real sample and the generated sample respectively;
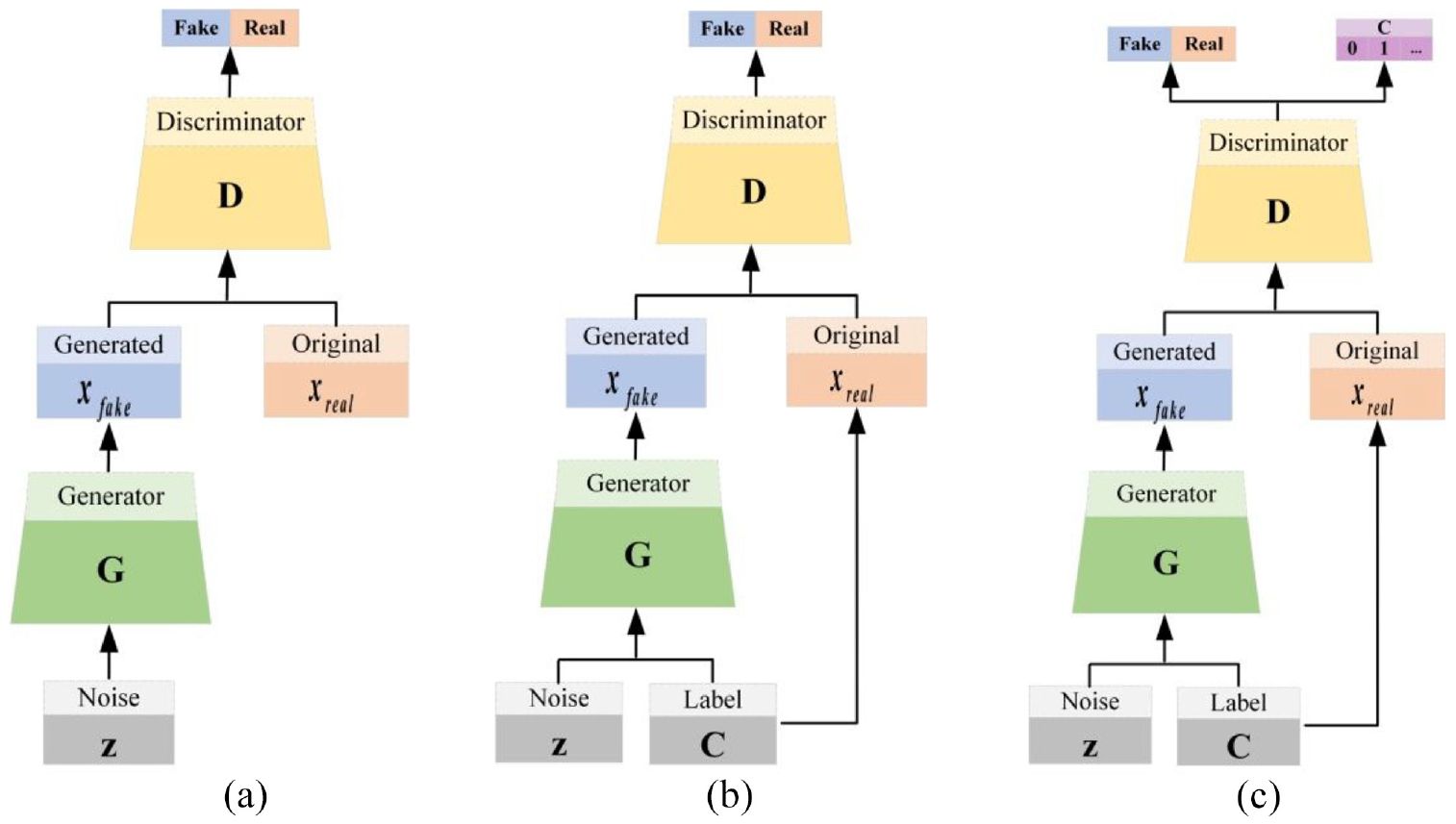
The basic structure of (a) GAN, (b) CGAN, and (c) ACGAN.
Auxiliary classifier generative adversarial networks (ACGANs) 27 is gradually developed on the basis of GAN, and its main purpose is to solve the problem of GAN mode collapse. The formation process is mainly divided into two stages. First, the category labels are added as auxiliary information on the basis of the GAN model, namely conditional generative adversarial networks (CGAN), 28 as shown in Figure 1(b). CGAN overcomes the disadvantage that the original GAN cannot control the categories of generated samples, and then guides the sample generation process. The overall optimization objective function of CGAN is as follows:
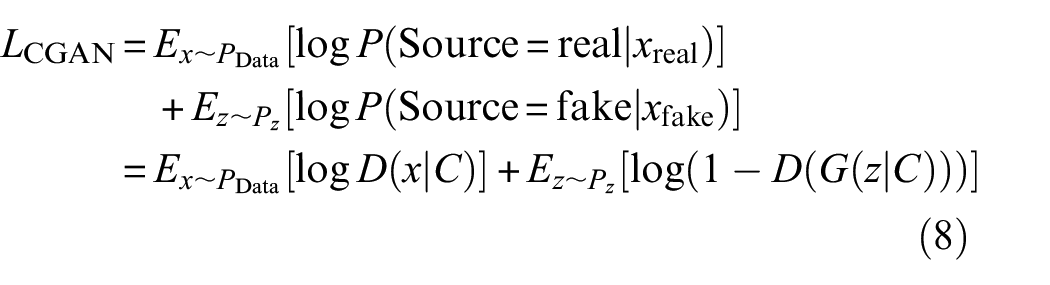
Then CGAN is further improved by embedding auxiliary classifiers in the discriminator, named ACGAN, as shown in Figure 1(c). This improvement further expands the function of the discriminator, which can not only judge the source of the sample (real or fake) but also classify the sample category. So, the loss function of ACGAN is mainly composed of discriminative loss and classification loss. The mathematical expressions of the loss function are expressed respectively:

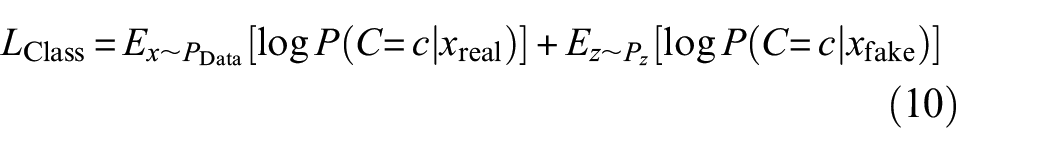
To achieve the purpose that both the discriminator and the classifier expect the samples generated by the generator to be the samples of the specified class, the overall optimization objective of the discriminator is to maximize
Distance criterion
Kullback–Leibler divergence
Kullback–Leibler (KL) divergence
29
is used to measure the difference between two distributions. The value range of KL divergence is
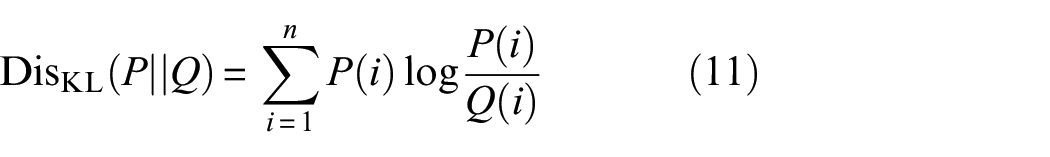
Maximum mean discrepancy
Maximum Mean Discrepancy (MMD)
30
is also a function used to measure the distance between two distributions, but it is different from the general distance measurement function. It maps the two distributions into the Reproducing Kernel Hilbert Space (RKHS), and then measures the distance between two distributions in the RKHS. The value range of MMD divergence is also
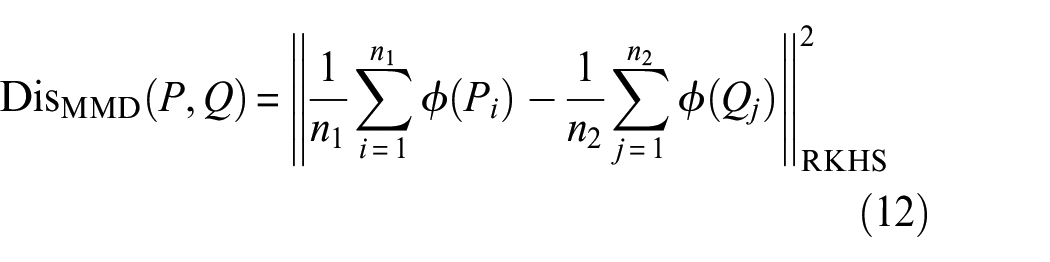
Among them,
The proposed method
Aiming at the problem of sample imbalance, this paper proposed DGANs combining conditional assistance and feature enhancement. The overall framework of the proposed method is shown in Figure 2. The main content of the proposed framework includes three aspects: the diversity of generated samples using coral, deep feature learning using self-attention, and the specific process of the proposed method.
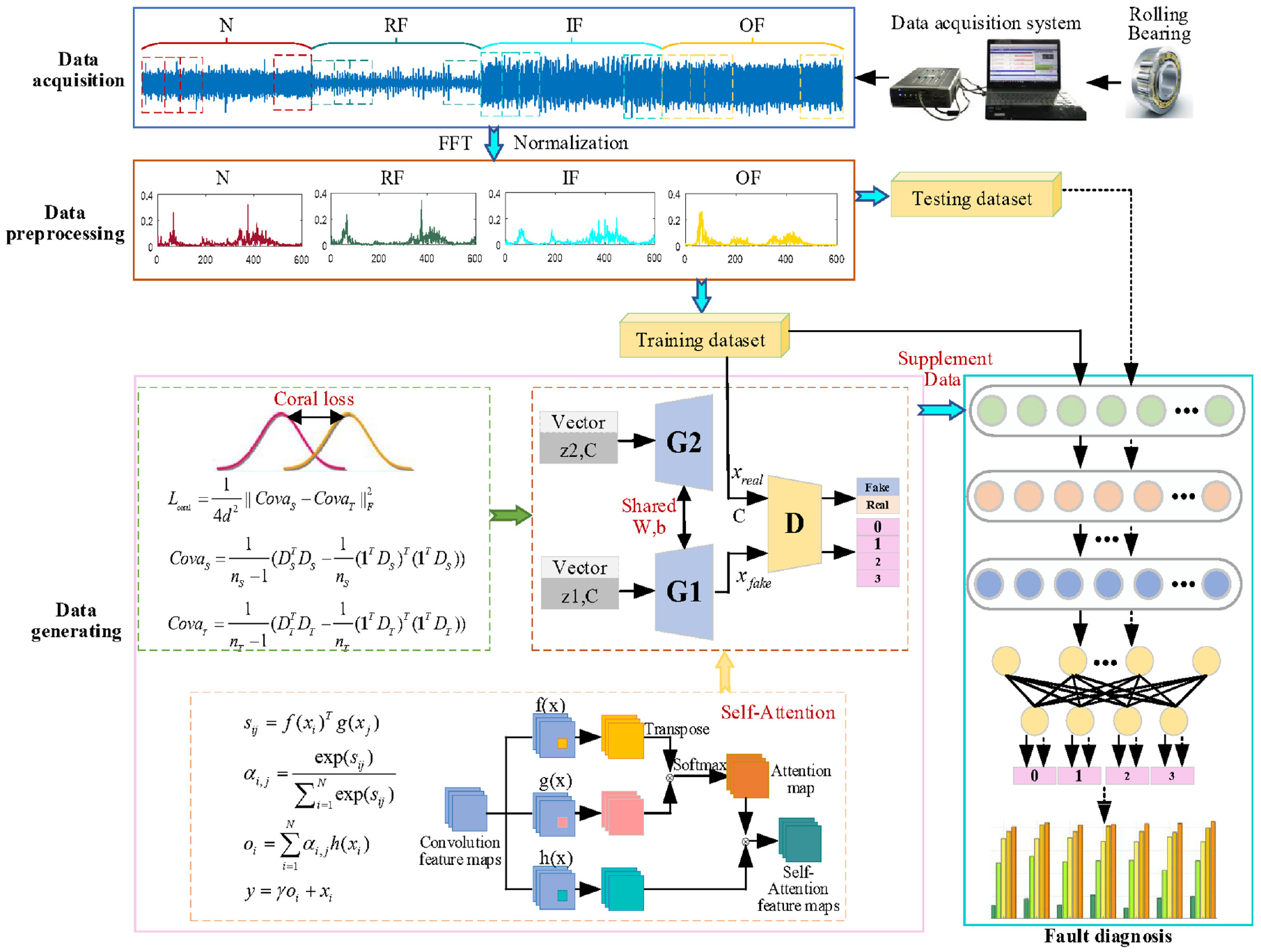
The overall framework of proposed method.
Diversity of generated samples using coral
GAN uses the idea of a game to continuously train the model to generate fake samples. But it may lead to less diversity of generated samples, making mode collapse. To solve the mode collapse problem that often occurs in GANs, we design a new generator. Firstly, the basic framework of the generator is built by using shared dual-branch DCNNs. Then adding the class label auxiliary information. Finally, the loss of the coral 31 is introduced into the last deconvolution layer. Here, coral embedded in the deep deconvolution network is called deep coral. Deep coral is a high-dimensional spatial feature alignment method, which completes the alignment of second-order statistics of two domain features by calculating the mean value and covariance. In addition, deep coral is also a distance measurement method and can be used as a similarity measurement method to calculate the similarity degree of two domain features in high-dimensional space. According to the requirements, the function can be minimized to increase the similarity of two domain features in high-dimensional space or the function can be maximized to reduce the similarity of two domain features in high-dimensional space to increase the diversity of two domain features. According to the proposed method requirements, maximizing the coral loss of the reconstructed features of the two in the last deconvolution layer of the shared dual-branch in high-dimensional space, the generated fake samples tend to be more evenly distributed, increasing the diversity of generated samples. The coral loss function is as in Equation (13).
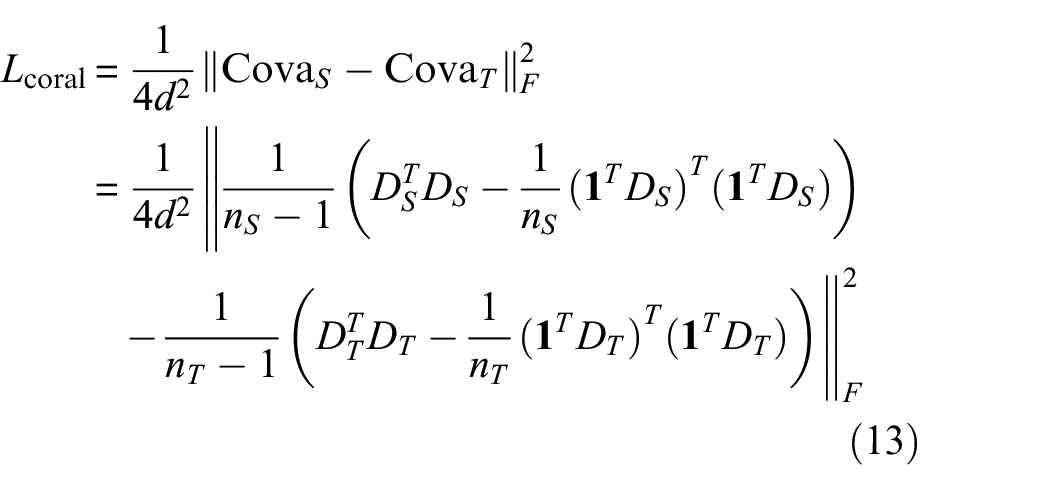
where,
In order to increase the diversity of generated samples, the coral distance loss function between two shared double branches is maximized. In addition, without adding additional computing resources, the new generator can also generate diverse fake samples. To achieve the above objectives, in the part of the generator, we only use the first branch to generate samples to complete the competition with the new discriminator and thus generate high-quality diverse fake samples. Therefore, the objective loss function of the new generator is as Equation (14):
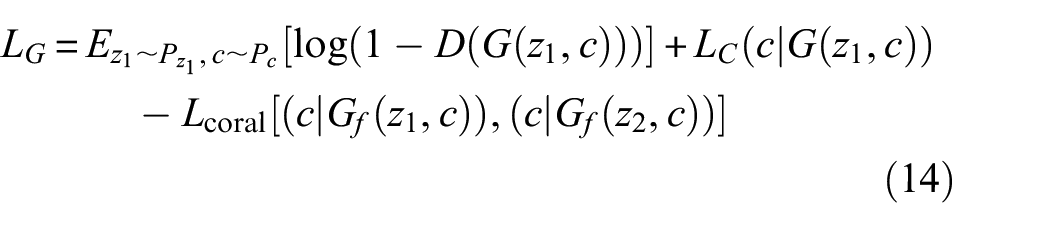
where,
In order to generate fake samples that are closer to the real sample distribution and ensure the diversity of generated samples, the final optimization objective of the generator is to minimize the generator objective loss function.
Deep feature learning using self-attention
In the field of fault diagnosis, convolutional networks, recurrent networks, 32 or fully connected networks 33 are usually used to build diagnostic models. However, due to the limitation of the local receptive field, the convolutional network only models the local dependencies of the input information, and only has long-distance dependencies when it has a multi-layer convolutional network, but increasing the number of layers will reduce the computational efficiency of the network. Due to the capacity of information transmission and the problem of gradient disappearance, the recurrent network is actually a local encoding method, and it can only establish short-distance dependencies. Although the fully connected network establishes long-distance dependencies between input sequences, its parameters are too large, which may cause it to fail to calculate when dealing with long input sequences.
The attention mechanism 34 is a computer imitation of the internal process of biological observation behavior. Its essence is to align internal experience with external sensation to increase the observation precision of some areas. Therefore, the attention mechanism can quickly capture the important information of sparse data, and focus on important information to extract its features. The self-attention mechanism 35 further improves the attention mechanism, further increasing the ability to capture the internal correlation of data or features by reducing the dependence on external perception. So, a self-attention module is introduced to establish long-range dependencies between input sequences, enhance the feature learning ability, realize the learning of the deep features of the original vibration signal, endow the generator and the discriminator with stronger global important information learning ability, and improve the discriminator’s discriminative function, while promoting the generator to generate higher quality fake samples.
The structure of the self-attention mechanism is shown in Figure 2. The detailed process of the whole module is as follows:
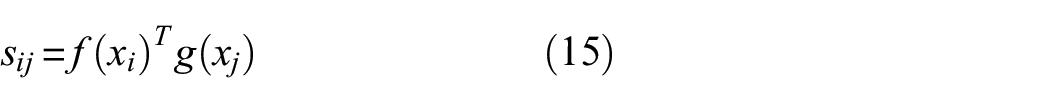
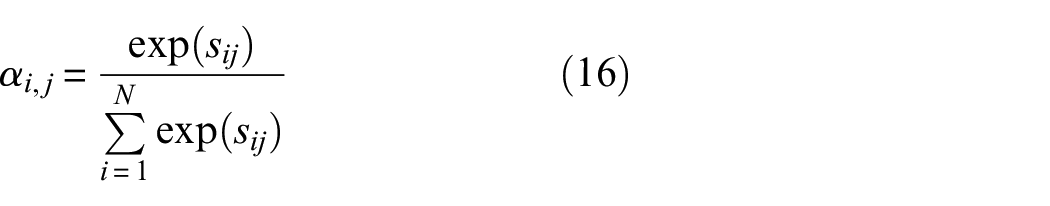
where,
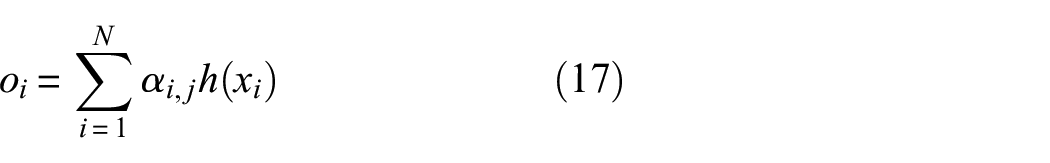
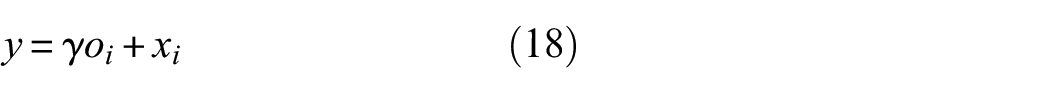
where,
The specific process of the DGANs
This paper proposed DGANs that combine conditional assistance and feature enhancement to solve the problem of sample imbalance. The specific implementation processes are as follows:
The detailed configuration of the CNNs for fault diagnosis.

CNN: Convolutional neural network.
Among them, the new discriminator uses deep CNNs architecture, as shown in Figure 3. At the same time, the real samples with a dimension of 600 and the fake samples generated by the generator are input into discriminator, and 4 convolution layers are used to extract the signal deep features, and the extracted features are used for real and fake discrimination and fault classification. The new generator is a shared dual-branch DCNNs structure, as shown in Figure 4. Each branch inputs a Gaussian random noise z with dimension 100, mean 0, and standard deviation 1, z goes through 4 deconvolution layers and 1 convolution layer to reconstruct the noise into fake samples with the same dimension as the original real samples. In order to speed up the training convergence, InstanceNorm is added to both the generator and the discriminator. The batch size for adversarial training is set to 64 and the number of iteration steps is 2000. Taking into account the adversarial balance, the learning rates of the generator and discriminator are set to 0.0002 and 0.0004 respectively.

Specific structure and parameter configuration of the new discriminator.
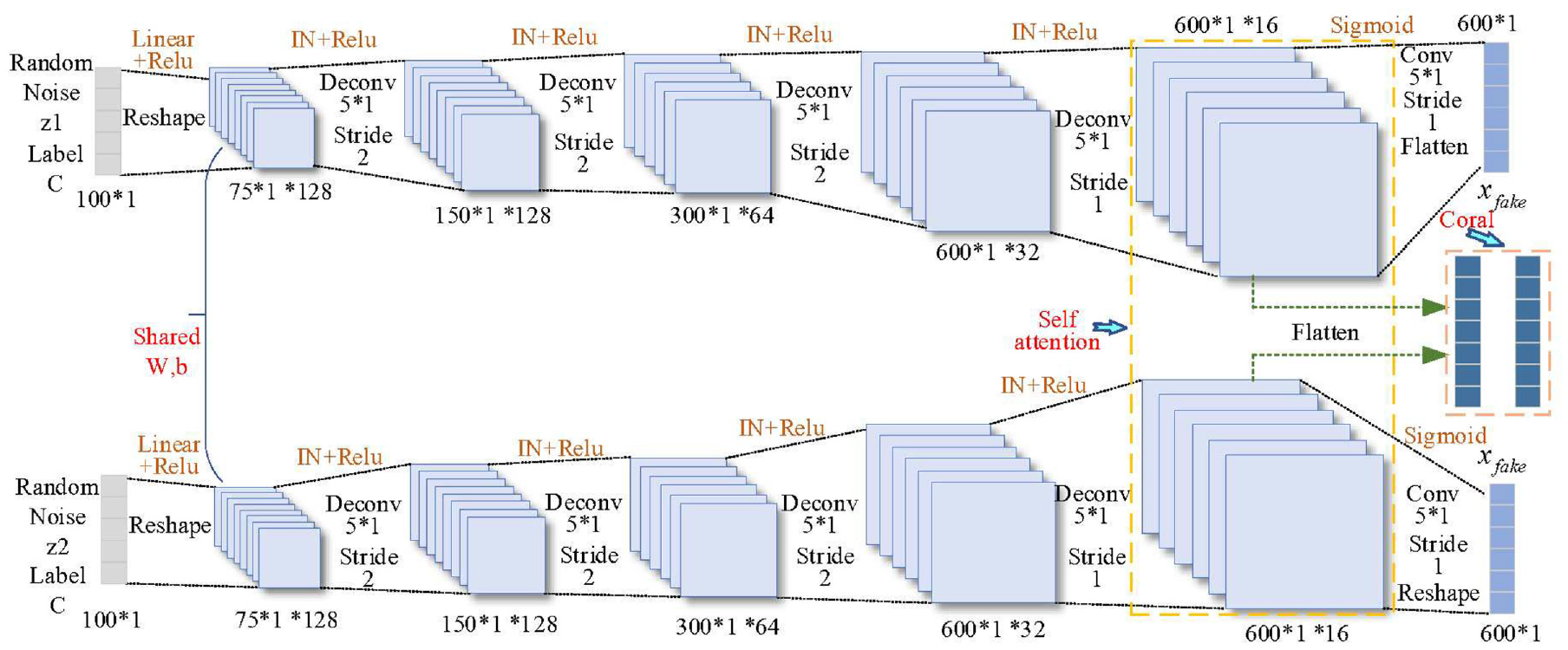
Specific structure and parameters configuration of the new generator.
Experimental verification
Datasets description
Case Western Reserve University(CWRU) Bearing Dataset, published by Case Western Reserve University, the experimental platform is shown in Figure 5. The dataset mainly includes bearing fault data at the drive end and the fan end. The drive end bearing fault data also includes 12 k drive end bearing fault data and 48 k drive end bearing fault data. The driving end bearing type is deep groove ball, the model number is SKF6205. Bearing faults are processed by Electrical discharge machining (EDM), including fault in roller, fault in inner race and fault in outer race. Each fault type contains three different diameters of damage: 0.18, 0.36 and 0.54 mm. Installing the faulty bearing into the test motor, and recording the vibration data of the motor load at 0–3 hp respectively. In this experiment, the motor load is 3 hp, the damage diameter is 0.18 mm, and the fault data of the 12 k drive end bearing is selected. For the convenience of description, the normal data is denoted as N, and fault in roller, fault in inner race and fault in outer race fault data are denoted as RF, IF, and OF in turn.

The bearing dataset of Case Western Reserve University.
Private Platform Bearing dataset, Collected by the customized platform of our research group, and the experimental platform is shown in Figure 6. The rated power of the motor is 0.75 kW, and the bearing type is roller bearing, the model number is NU205EM. The bearing fault is also processed by EDM. The fault types are fault in roller, fault in inner race and fault in outer race. The damage diameter of each fault type is 0.5 mm. Installing the faulty bearing into the test motor, and recording the vibration data of the motor with speed at 1000–1300 rpm. In this experiment, the bearing fault data are selected when the speed is 1300 rpm. Marking the normal, fault in roller, fault in inner race, and fault in outer race as N, RF, IF and OF in turn.

The bearing dataset of private platform.
Data preprocessing, for the datasets collected from the above two experimental platforms, to prevent information leakage, the sliding pane overlap is used to sample the data under each health state. After sampling, 400 original time domain samples are obtained in each healthy state, each sample contains 1200 data points, and 400 frequency domain samples are obtained after fast FFT, each sample contains 600 data points. Then normalize the transformed data. For normal samples, the first 200 samples are used as the training dataset, and the last 200 samples are used as the test dataset. For the fault samples, in order to simulate the actual situation, it is assumed that the number of samples is limited, so only the first 10 samples are used as the training dataset, and the last 200 samples are used as the test dataset. Details are shown in Table 2. In this experiment, 200 normal samples and 10 fault samples of different fault types were used to generate 64 samples corresponding to their health condition.
The specific configuration of CWRU imbalanced dataset and private imbalanced dataset used in the experiment.

N: normal data; RF: fault in roller fault data; IF: fault in inner race fault data; OF: fault in outer race fault data; CWRU: Case Western Reserve University.
The effectiveness of coral
The core purpose of embedding the coral in this paper is to assist in generating more diverse samples and prevent the mode collapse of the GAN. To prove the effectiveness of the coral, the samples generated by the three models of GAN, ACGAN, and ACGAN-coral (adding the coral module on the basis of ACGAN) were visualized with the original true samples by t-distributed stochastic neighbor embedding (t-SNE). On two different datasets, the t-SNE visualization results are shown in Figures 7 and 8. In the figure, circles represent imbalanced real samples and triangles represent generated samples. From the comparison of Figure 7(a) to (c), it can be seen that on the CWRU dataset, the samples generated by the ACGAN model are intra-class relatively scattered compared to the samples generated by the GAN. While compared with the ACGAN model, the clustering of samples generated by the ACGAN-coral model is relatively weak. Especially as shown by the yellow triangle. Therefore, it can be inferred that the diversity of samples generated by the model is enhanced after embedding the coral.
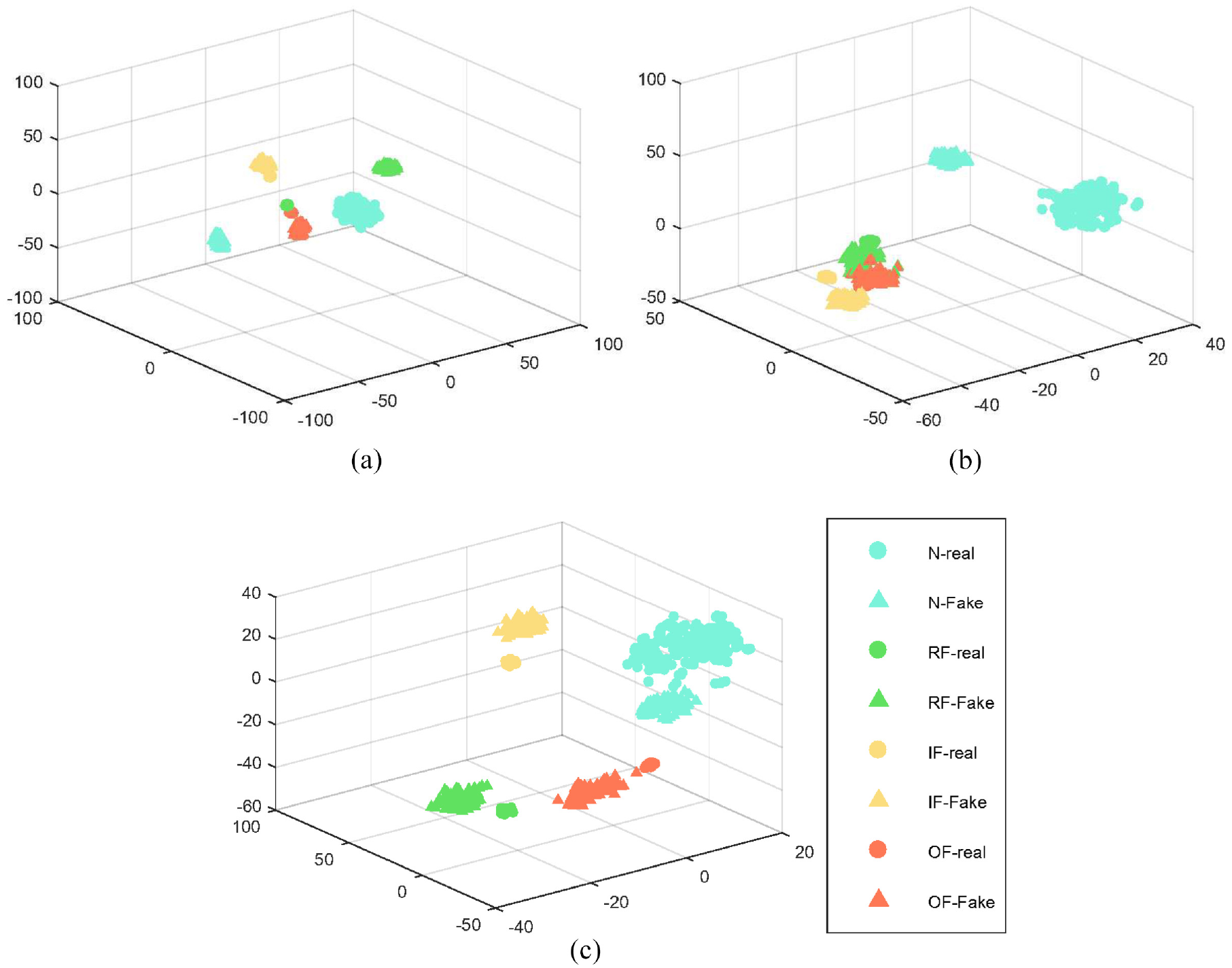
t-SNE visualization of (a) GAN, (b) ACGAN, and (c) ACGAN-coral in CWRU dataset.
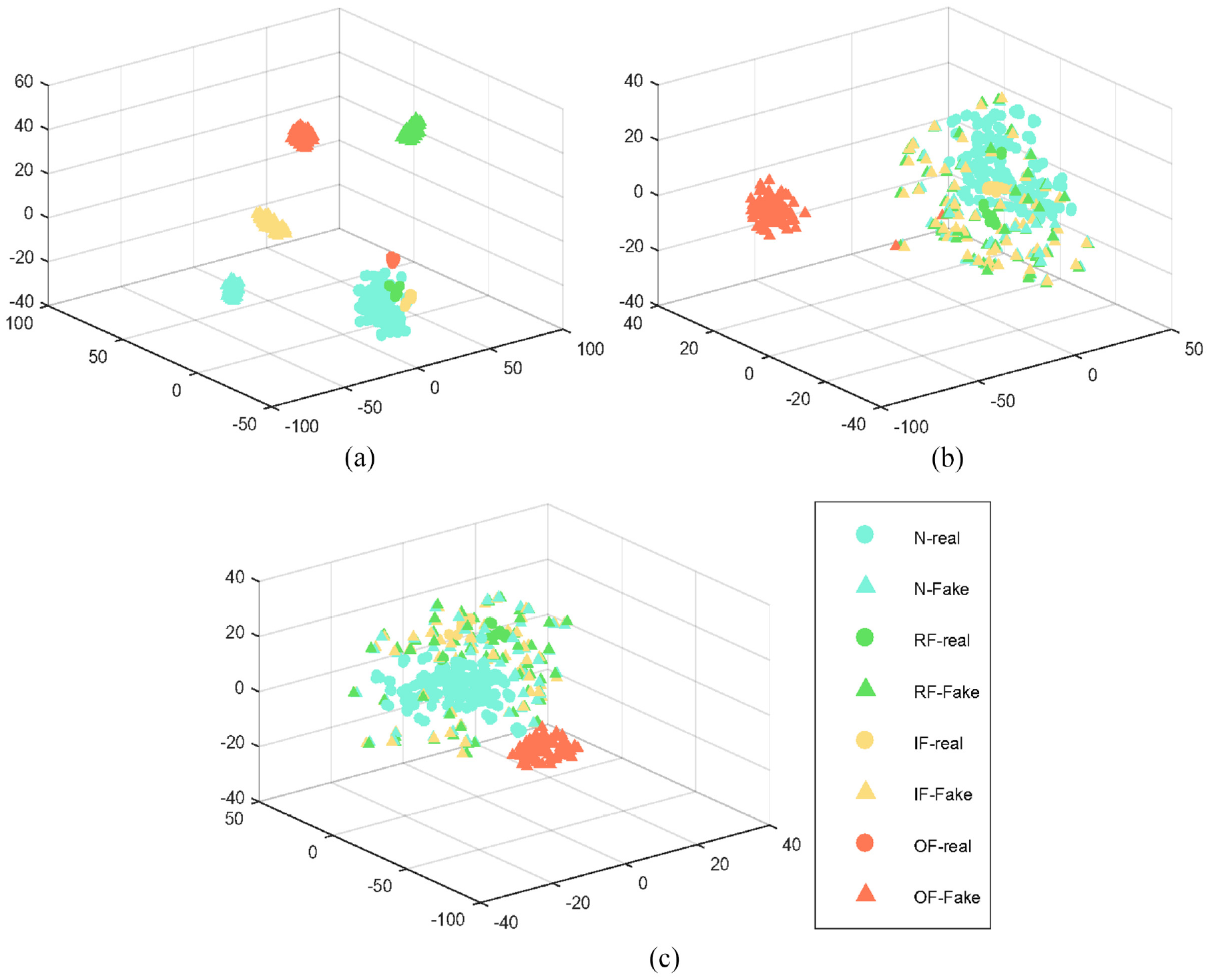
t-SNE visualization of (a) GAN, (b) ACGAN, and (c) ACGAN-coral in private dataset.
In addition, from the analysis of Figure 8(a) to (c), on the private dataset, it can be seen that the ACGAN-coral model has the weakest intra-class clustered compared with the samples generated by the GAN and ACGAN models, and the ACGAN model is slightly second, the GAN model is the best. Especially as shown by the green triangle in the picture. Therefore, on the private dataset, it is also proved that the coral can assist the model to generate more diversity of samples, and prevent mode collapse of GAN to a certain degree.
The effectiveness of self-attention
This section verifies the effectiveness of self-attention. In order to make the conclusions more accurate, two network architectures are set up here, namely ACGAN and ACGAN-attention (self-attention module added on the basis of ACGAN). Under the three fault types of two datasets, the original real sample, the sample generated by ACGAN, and the sample generated by ACGAN-attention are visualized by spectrogram. The experimental results of the two datasets are shown in Figures 9 and 10 respectively. As can be seen from Figure 9, on the CWRU dataset, compared with ACGAN, the frequency domain signal of ACGAN-attention with self-attention module is significantly enhanced at the signal shock compared with the original real sample, especially marked by the red square in the Figure 9. While the frequency domain signals generated by the ACGAN model are roughly the same at the signal shock compared with the original real sample, and even individual fault categories are weaker than the original real sample, such as RF.
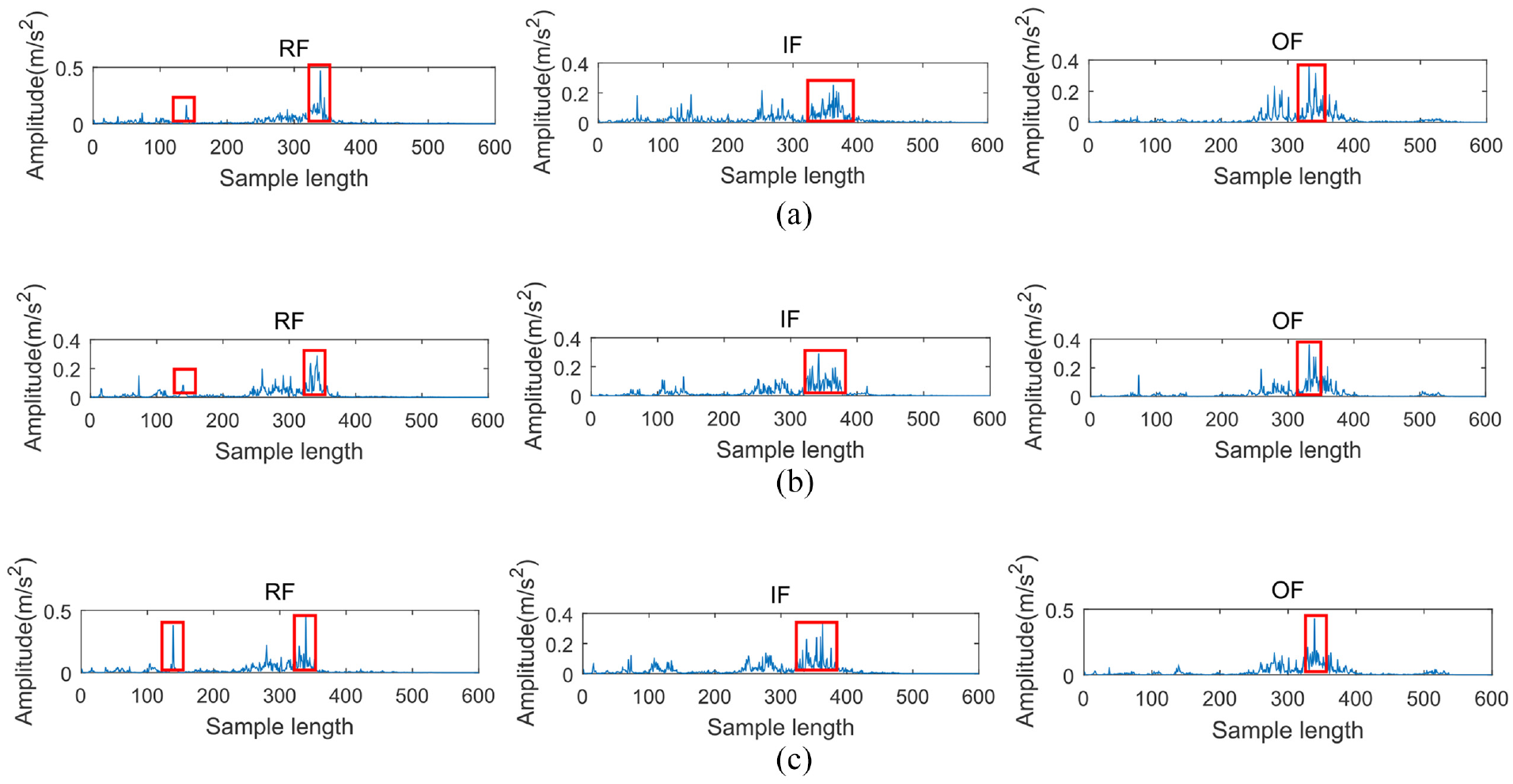
Spectrogram of (a) Real samples, (b) ACGAN generated samples, and (c) ACGAN- attention generated samples in CWRU dataset.
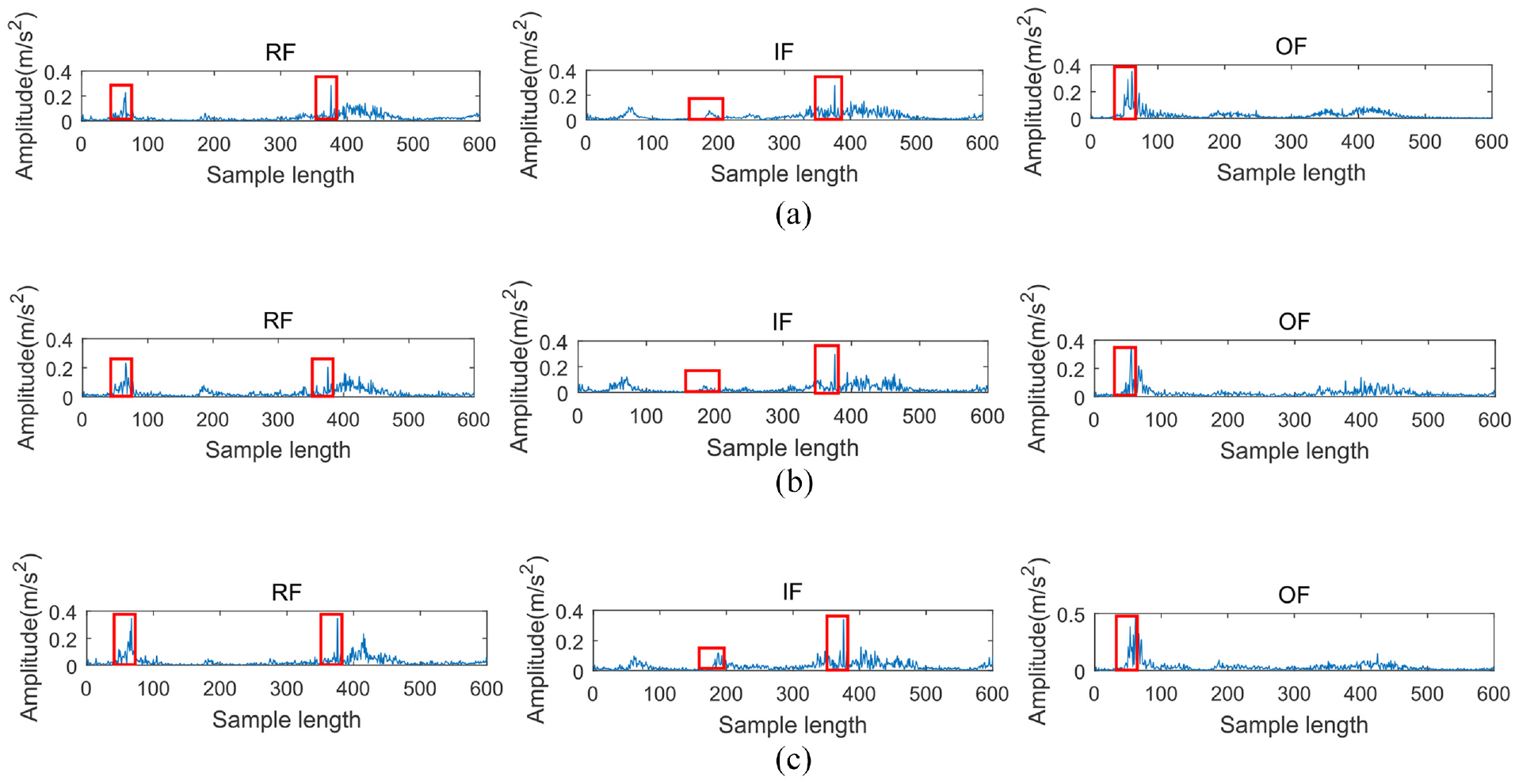
Spectrogram of (a) Real samples, (b) ACGAN generated samples, and (c) ACGAN- attention generated samples in private dataset.
In addition, on the private dataset, it can be concluded from Figure 10 that under various fault types, at the signal shock, the sample in frequency domain generated by the ACGAN-attention model has also been significantly enhanced compared to the original real sample, as shown in Figure 10 marked by the red square. The frequency domain signal of the samples generated using ACGAN remains roughly the same as the original real samples at the shock signal, and even weaker than the original real samples under the IF fault type. Therefore, through the analysis of Figures 9 and 10, it can be comprehensively inferred that the use of self-attention can enhance the features to a certain extent.
Sample generation and quality assessment
The core idea of this paper is to use only a small number of fault samples to generate fake samples with similar distribution to real fault samples through adversarial training. Therefore, before supplementing the imbalanced dataset with fake samples, the quality of the generated fake samples needs to be evaluated to measure whether the generated fake samples can be used to supplement the imbalanced dataset. To prevent the accidental occurrence of a single quality assessment method, the quality of the generated samples is assessed by using two statistical indicators with large differences in the principles of MMD and KL divergence. In addition, it is compared with other methods. The MMD and KL divergence results of each method on two different datasets are shown in Table 3.
Details of training set and testing set.
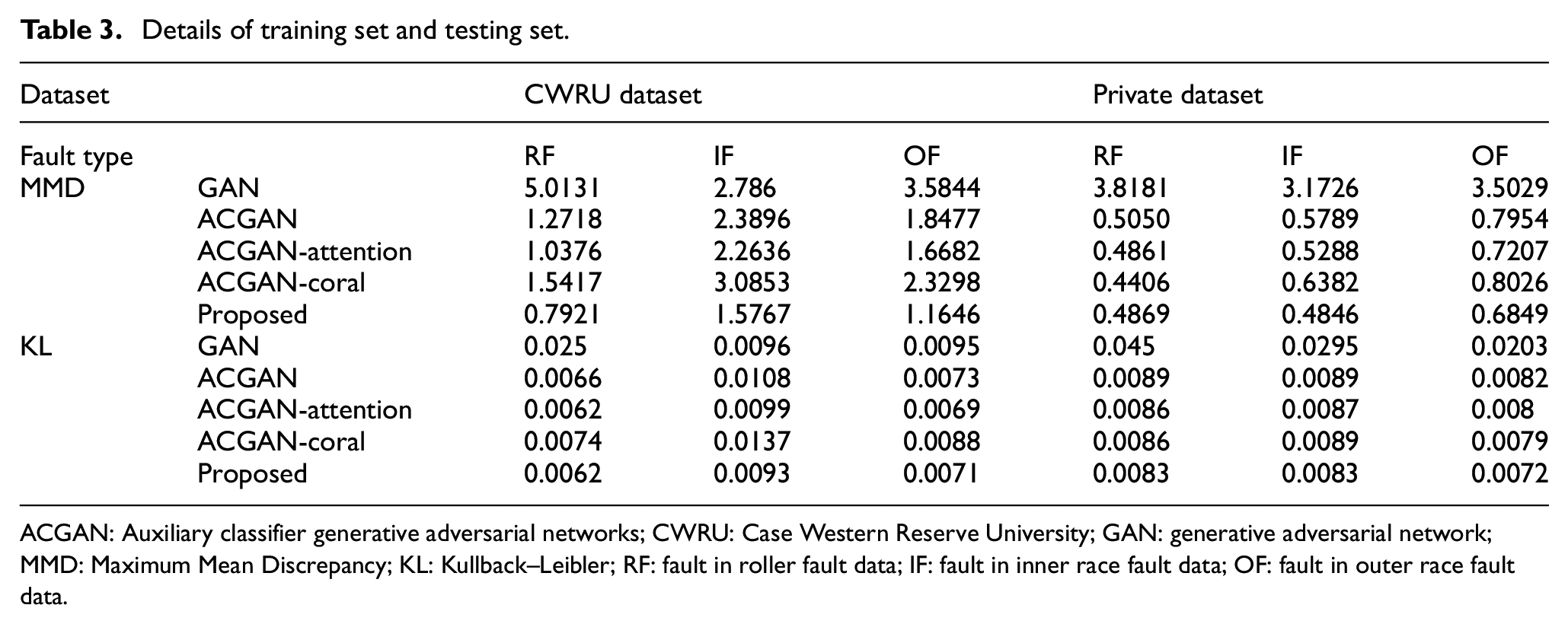
ACGAN: Auxiliary classifier generative adversarial networks; CWRU: Case Western Reserve University; GAN: generative adversarial network; MMD: Maximum Mean Discrepancy; KL: Kullback–Leibler; RF: fault in roller fault data; IF: fault in inner race fault data; OF: fault in outer race fault data.
According to the analysis in Table 3, whether on the CWRU dataset or on the private dataset, compared with other methods, the MMD and KL divergence of the proposed method under various fault types are relatively small. So, the results indicate that the data generated using the proposed method has a high similarity to the real data distribution. The MMD and KL divergence of ACGAN-coral are larger than those of ACGAN, which indicates that the use of coral increases the diversity while reducing the similarity. While adding a self-attention module on the basis of ACGAN-coral, that is, the proposed method, MMD and KL divergence are greatly reduced, and the distribution of generated samples is closer to the original real sample distribution. It is further proved that self-attention can make up for the reduction of similarity caused by sample diversity and improve the quality of generated samples.
Imbalanced fault diagnosis
At present, fault diagnosis methods can be roughly divided into two categories: one is based on signal processing, and the other is based on deep learning. The fault diagnosis method based on signal processing is to judge the fault category of the signal according to the specific fault characteristic frequency, and the fault discrimination according to the specific fault characteristic frequency needs to match the prior diagnosis knowledge of experts. The fault diagnosis method based on deep learning can identify the fault characteristics mainly based on mathematical characteristics and statistical characteristics.36,37 The fault characteristics are not specific fault characteristic frequency corresponding to the signal processing but the edge frequency oscillation peak fault characteristic information excited by the fault characteristic frequency in the full frequency band (low frequency band, medium frequency band, high frequency band), and these fault characteristic information represents the difference between the signals of fault types. The fault diagnosis method based on deep learning is to further mine and extract fault characteristic information through the deep network, and send the extracted characteristic into the classifier to automatically complete the fault identification, so as to realize the fault diagnosis. Therefore, the fault diagnosis method based on deep learning is to automatically discriminate faults without the prior knowledge of experts. Therefore, at present, the fault diagnosis method based on deep learning is increasingly favored by scholars in the fault diagnosis field, and has also become the mainstream method in the current fault diagnosis field.
The fault diagnosis method of CNNs set earlier in this paper is one of the deep learning fault diagnosis methods, it is mainly a deep learning fault diagnosis method similar to image processing, image classification. It also classifies these images like image classification. As long as these image categories are distinguished, the convolution deep learning fault diagnosis method can distinguish the fault categories. As mentioned in above sections, the synthetic data generated by the data generation network model (DGANs) actually contains the characteristics of the fault frequency information, and the fault frequency information is not the fault characteristic frequency in the traditional sense, but the edge frequency oscillation peak fault characteristic information excited by the fault characteristic frequency in the full frequency band (low frequency band, medium frequency band, high frequency band). Therefore, the fault diagnosis method of CNNs can correctly distinguish the fault category of the signal according to the fault characteristic information image generated by the signal in the full frequency band. It is also the theoretical basis for improving the accuracy of imbalanced fault diagnosis by supplementing the synthetic data generated by the DGANs. The experiment confirmed as follows:
From the experiments in the previous sections, it is proved that the proposed method has outstanding advantages compared with other methods, the quality of the generated samples is higher, and the diversity is rich. To further verify the effectiveness of the proposed method for imbalanced fault diagnosis, in this section, for different fault types, on two different datasets, we compose a new training dataset by adding different number of generated samples to the original imbalanced training datasets, and the number of added samples for each fault type is set to 10, 20, 30, and 40 in turn.
The fault diagnosis model CNNs is trained by different training datasets that were set earlier. When the model training is stable, the test datasets that were set in the early stage is used to test the trained model. The average test results of seven consecutive times on two different datasets are shown in Table 4. From Table 4, it can be concluded that in the CWRU datasets, with the increasing number of supplementary samples, the test accuracy basically maintains a gradual upward trend. Especially when the number of supplementary samples is 10, the average test accuracy is 30.18% higher than the original imbalanced dataset, reaching 99.68%. When the number of supplementary samples is 30, the average test accuracy has stabilized at 100%. On private datasets, the test accuracy keeps increasing after using the proposed method to supplement the original imbalanced dataset with different numbers of samples. When the number of supplementary samples is 40, the average test accuracy increases from the original 57.93% to 91.65%, the average increase is 33.72%.
Details of training set and testing set.
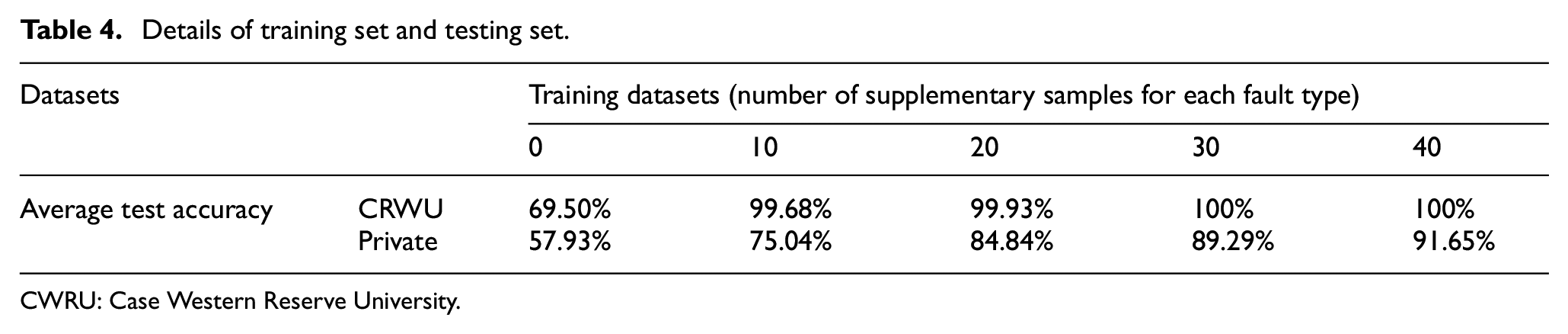
CWRU: Case Western Reserve University.
To illustrate the effectiveness of the proposed method for imbalanced fault diagnosis in more detail, on different training datasets, the test results of seven consecutive times are plotted as a column chart. On two different datasets, the column charts are shown in Figures 11 and 12 respectively. According to the analysis in Figure 11, on the dataset of CWRU, the original imbalanced dataset has a large fluctuation in the results of seven consecutive times, with a standard deviation of 5.88%. With the continuous supplement samples, the stability of test results is gradually enhanced. When the sample is replenished to 30, the test results for seven consecutive times remain at 100%. On the private dataset, the test result in seven consecutive times of original imbalanced dataset has the most prominent fluctuations with a standard deviation of 2.24%. With the increasing number of supplementary samples, the stability of the test results is gradually improving. When the number of samples is supplemented to 40, the standard deviation is reduced from 2.24% to 0.78%, and the test results for seven consecutive times are roughly maintained at about 91.65%.
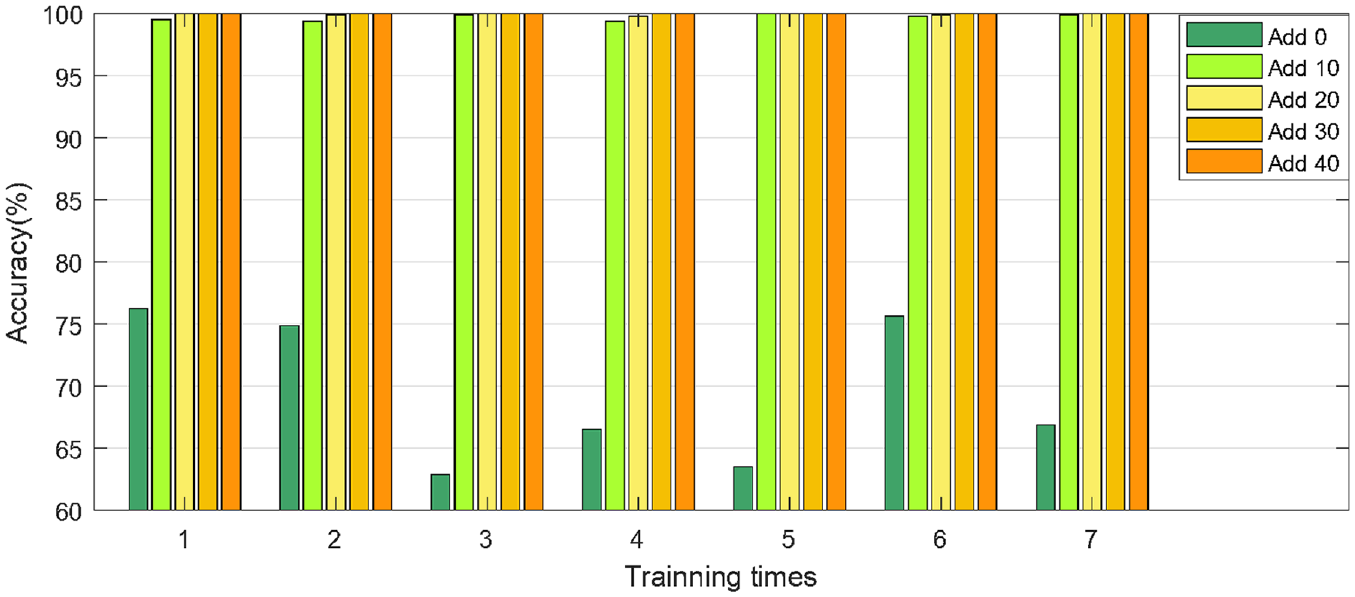
The testing accuracy in seven consecutive times of CWRU dataset.
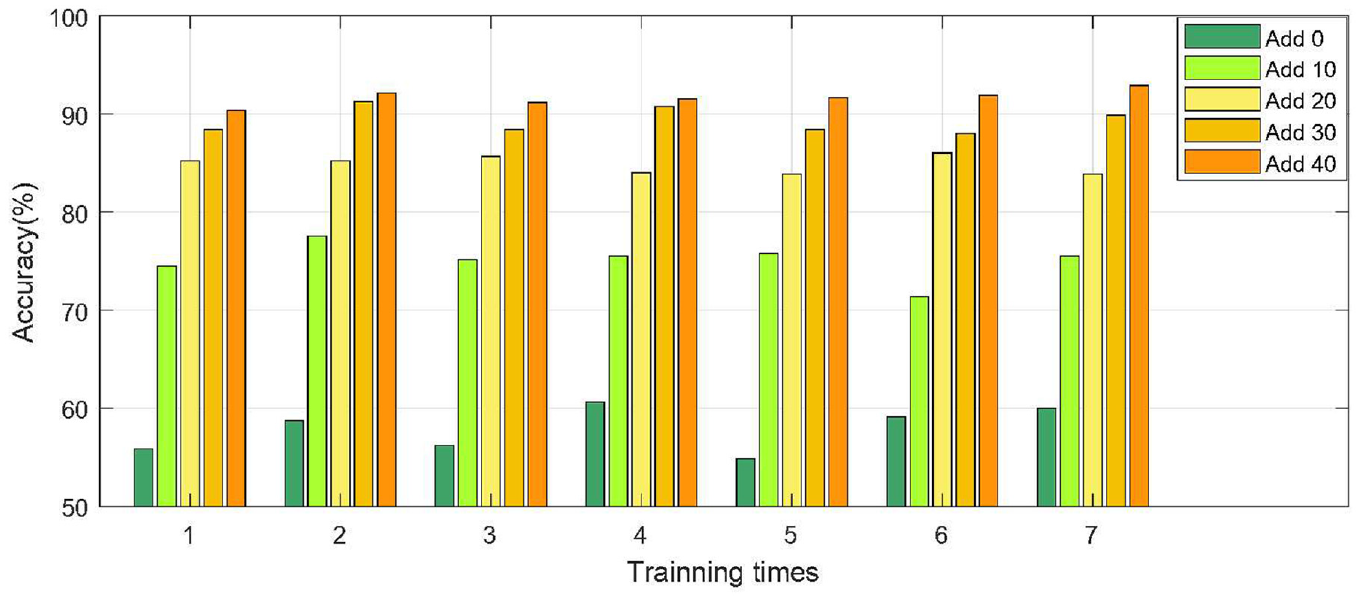
The testing accuracy in seven consecutive times of private dataset.
Through the above comprehensive analysis, it can be concluded that the fault diagnosis accuracy is not only greatly improved, but also diagnosis stability is guaranteed to a certain extent after using the proposed method to supplement the original imbalanced dataset. Therefore, the proposed method can effectively solve the problem of sample imbalance.
In order to more intuitively illustrate the classification effect of the proposed method on imbalanced fault diagnosis, on the CWRU dataset, the confusion matrix is drawn for the test accuracy respectively, which are the original imbalanced dataset as the training dataset and the dataset supplemented with 30 samples for each type of fault as the training dataset. The confusion matrix is shown in Figure 13. It can be seen from the analysis in Figure 13 that when the number of supplementary samples is 30, for the fault in roller, the original number of correct diagnosis samples increased from 107 to 200. For fault in inner race, it is increased from 147 to 200. For fault in outer race, it is also reduced from 138 to 200. According to the calculation, after using the proposed method to supplement the samples, the original test accuracy increased from 74% to 100%, and increased by 26%.
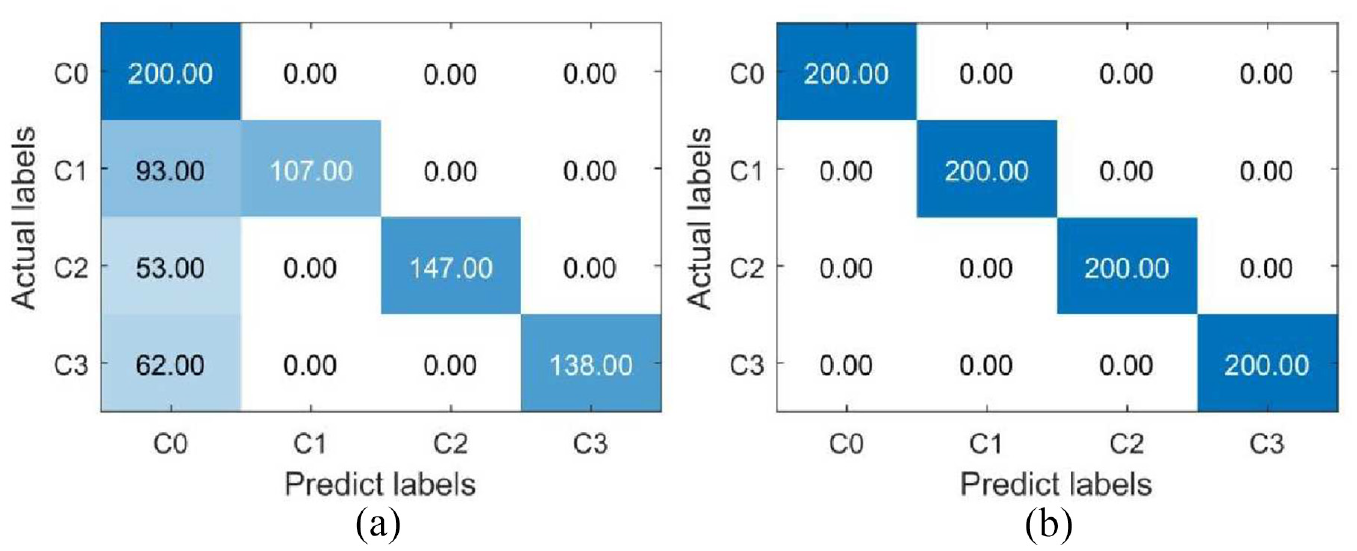
The confusion matrix of test accuracy on CWRU dataset. (a) Imbalanced, and (b) Add 30 samples.
On the private dataset, the test accuracy of the dataset when the training dataset is the original dataset and the dataset supplemented with 40 samples for each type fault visualized using the confusion matrix respectively, and the visualization results are shown in Figure 14. It can be seen from Figure 14 that when 40 samples are added, for the fault in roller, the original 178 misclassified samples are reduced to 62. For fault in inner race, it is reduced from 152 to 5. For fault in outer race, it is also reduced from 13 to 0. Therefore, it can be calculated that after the samples are supplemented through the proposed method, the overall sample misclassification rate of the testing dataset is reduced from the original 42.875% to 8.375%, that is, the test accuracy is increased by 34.5%.
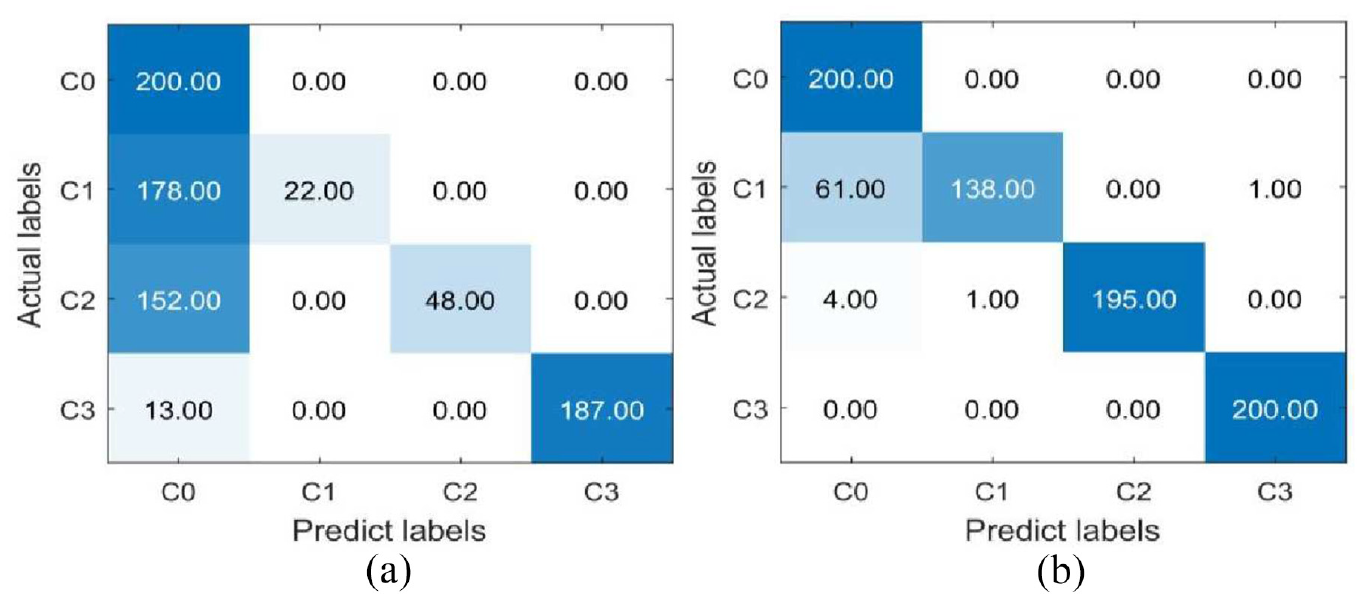
The confusion matrix of test accuracy on private dataset. (a) Imbalanced and (b) Add 40 samples.
Conclusion
In this paper, DGANs combining conditional assistance and feature enhancement for imbalanced fault diagnosis is proposed. This method flexibly combines label auxiliary information, coral distance loss function and self-attention module with an adversarial model. It overcomes the problem of mode collapse or gradient disappearance that often occurs in adversarial training on GAN, and stably generates fake samples with high quality and rich diversity. The method is verified by the public bearing signal of the CWRU and the bearings signal of the customized test bench. The experimental results show that the proposed method can generate high-quality fake samples and greatly improve the accuracy of imbalanced fault diagnosis, which is helpful to detect faults using fewer imbalanced samples in actual working conditions, laying a foundation for advancing the practical application of rotating machinery health assessment.
Although the proposed method has achieved good results in imbalanced fault diagnosis, there are still many aspects that can be improved. In future studies, we will try to focus on improving two aspects. The first is the tradeoff between sample diversity and sample similarity to find the balance point that can best guarantee the needs of both. Secondly, the knowledge learned from a small number of existing samples and generated samples is transferred to the target domain where there is a certain gap in distribution, and the fault types of unknown target domain samples are accurately predicted.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Postgraduate Research and Practice Innovation Program of Jiangsu Province (KYCX21_0230), the National Natural Science Foundation of China (51975276), the National Science and Technology Major Project (2017-IV-0008-0045), the Special Project of the National Key Research and Development Program of China (2020YFB1709801).