
Abstract
Recently, crack segmentation studies have been investigated using deep convolutional neural networks. However, significant deficiencies remain in the preparation of ground truth data, consideration of complex scenes, development of an object-specific network for crack segmentation, and use of an evaluation method, among other issues. In this paper, a novel semantic transformer representation network (STRNet) is developed for crack segmentation at the pixel level in complex scenes in a real-time manner. STRNet is composed of a squeeze and excitation attention-based encoder, a multi head attention-based decoder, coarse upsampling, a focal-Tversky loss function, and a learnable swish activation function to design the network concisely by keeping its fast-processing speed. A method for evaluating the level of complexity of image scenes was also proposed. The proposed network is trained with 1203 images with further extensive synthesis-based augmentation, and it is investigated with 545 testing images (1280 × 720, 1024 × 512); it achieves 91.7%, 92.7%, 92.2%, and 92.6% in terms of precision, recall, F1 score, and mIoU (mean intersection over union), respectively. Its performance is compared with those of recently developed advanced networks (Attention U-net, CrackSegNet, Deeplab V3+, FPHBN, and Unet++), with STRNet showing the best performance in the evaluation metrics-it achieves the fastest processing at 49.2 frames per second.
Keywords
Introduction
Deep learning–based approaches were introduced to overcome the limitations of the traditional image processing–based damage detection approaches in recent years. Cha et al. 1 proposed the detection of structural damage using deep a convolutional neural network (CNN). They designed a unique CNN, and it was trained and tested to detect concrete cracks in the various image conditions that have real and uncontrolled lighting conditions including blurry and shadowed. For practical applications, the network has been examined using the images coming from an unmanned aerial vehicle (UAV) for concrete crack detection. 2 The network adopted a sliding window technique to localize the detected cracks, but this technique requires heavy computational cost, and defining the proper size of the sliding window is another issue by considering camera and lens properties, camera and object distance, and size of cracks. Instead of the sliding window approach, faster region-based convolutional neural network (Faster R-CNN) 3 was applied for damage detection and localization. 4,5 This Faster R-CNN proposes various sizes of bounding boxes to detect and localize different sizes of damage. The network uses the same base network for detection and localization; therefore, it is faster than the other types of localization methods (e.g., sliding window technique) and became the mainstream in the deep learning–based multiple types of damage detection problems. 6–9
Localization of structural damage with bounding boxes is not enough for damage quantification. Specifically, it is too coarse to use bounding boxes or sliding window to measure the thickness and length of detected concrete cracks. U-net
10
was applied for pixel-level crack segmentation.
11
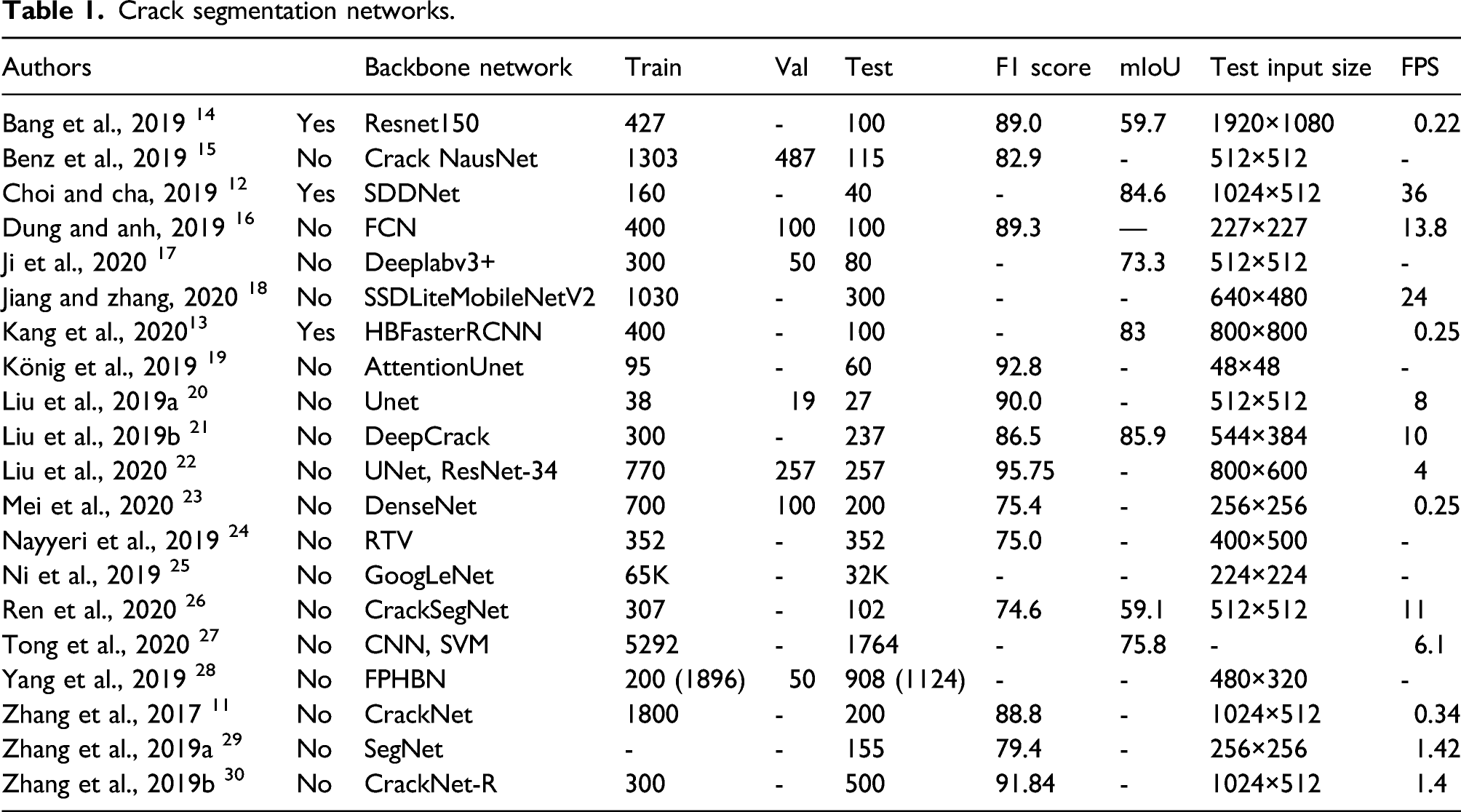
However, this method was only applied to pure asphalt surfaces without any complex objects or background scenes. There are numerous similar studies in this crack segmentation problem. From extensive literature reviews, we recognized four major limitations or disadvantages of existing studies that should be overcome or improved: (1) Although monitoring pavements without considering complex scenes may not constitute a serious problem, detecting structural damage such as concrete cracks is a major limitation if the network cannot detect only cracks in the complex scenes since many structures are located within various different visual scenes. Many researchers worldwide have conducted pixel-level detection of cracks and reported results as shown in Table 1. Only SDDNet,
12
HBFasterRCNN,
13
and Resnet150
14
considered cracks in the complex scenes. (2) Another limitation is that most existing studies did not use proper evaluation metrics. Rather, most used accuracy, precision, recall, and F1 score as presented in Table 1. However, accuracy is not proper for this crack evaluation because the size of the crack is usually too small compared to the background scenes; therefore, it usually provides a high score if the size of the crack is small. The precision and recall do not properly consider false positive and false negative detections and the F1 score can control these with parameter changes. One of the reasonable and accurate evaluation metrics at the moment is mean intersection over union (mIoU), which can consider false positive and negative accurately. Therefore, many studies in the areas of computer vision and deep learning also use mIoU as an evaluation metric and loss function to efficiently train their networks. However, for crack segmentation, only seven studies
12–14,17,21,26,27
used IoU as an evaluation metric. However, most of the claimed IoU performances should be improved. (3) Most of the existing studies used heavy networks or existing traditional networks that were originally developed for the segmentation of many objects; therefore, these networks need inherently and unnecessarily heavy computational cost due to their excessive learnable parameters. Therefore, it is impossible for real-time processing with relatively large input images or video frames (e.g., 1000 × 500) that have 30 frames per second (FPS). Fast processing is an important aspect of civil infrastructure monitoring due to its large scale and is required to process many images to inspect large-scale structures. It does not necessarily process in a real-time manner, but it reduces overall monitoring costs and provides fast updates of the structural states. For example, as presented in Table 1, DeepCrack used VGG16 as the backbone network. Liu et al.
20
used U-net
10
architecture for concrete crack detection, Dung and Anh.
16
used fully convolution network (FCN),
31
König et al.
19
used Attention network,
32
Bang et al.
14
used Resnet,
33
Mei et al.
23
used DenseNet,
34
Ji et al.
17
used DeepLabV3+,
35
and Ren et al.
26
applied SegNet.
36
Among all these networks, only SDDNet could do real-time processing with 36 FPS for 1024 × 512 RGB images. (4) Some studies used a too small number of training and testing data sets with small sizes of input images. This results in the high possibility of overfitting for the specific types of cracks with specific image conditions. For example, Ji et al.
17
used a total of 84 images of relatively small sizes (i.e., 512 × 512), and SDDNet also used only 40 images for testing with relatively large input image (1024 × 512). Further, most of the studies used very small testing input image sizes which are all below 1000 × 500 except those conducted by references
12,14,30
. Testing input image of small sizes also has the possibility of overfitting to specific types of cracks. It is also not efficient to monitor large-scale civil infrastructure, and it is also very limited in terms of detecting thin cracks in a relatively long distance of camera and object. Crack segmentation networks.
Based on our extensive literature review described above, we propose a new deep encoder and decoder based network with an improved/increased data set and performance to resolve the four issues mentioned above in this pixel-level crack detection problem in complex scenes. In order to realize this, we propose the use of sematic trainable representation network (STRNet) to improve performance in terms of mIoU by keeping the real-time network processing speed for a relatively large size of testing input image frame (1024 × 512) from Tesla V100 GPU. Also, we establish a large ground truth dataset (i.e., 1748 RGB images with sizes of 1024 × 512, 1280 × 720) for training and testing purposes to consider complex background scenes for robust detection by avoiding overfitting to specific types of cracks and background scenes. We used some publicly available datasets—deep crack 21 and concrete crack segmentation datasets 37 —by fixing severe errors. Some ground-truth images of these datasets were coarsely labeled. This can cause poor training results, even when an advanced network is designed and used. Therefore, the images of these existing datasets were re-annotated to reduce annotation errors. To improve the network’s performance, we also used focal-Tversky loss function 38 and adopted image synthesis techniques to augment the prepared ground truth training data to negate and detect crack-like features on complex scenes.
Proposed STRNet
An architecture named STRNet of deep convolutional neural network is proposed to segment concrete cracks on complex scenes in pixel-level in a real-time manner (i.e., at least 30 FPS) with a testing input size of 1024 × 512 RGB images/videos. The STRNet is composed of a new STR module-based encoder, an Attention decoder with coarse upsampling block, a traditional convolutional (Conv) operator, a learnable Swish nonlinear activation function,
39
and batch normalization (BN) to segment only cracks in complex scenes with real-time manner. The schematic view of the STRNet is shown in Figure 1. In order to develop this high-performance network with low computational cost, many advanced networks were investigated to figure out their strengths and weaknesses. The overall architecture of STRNet.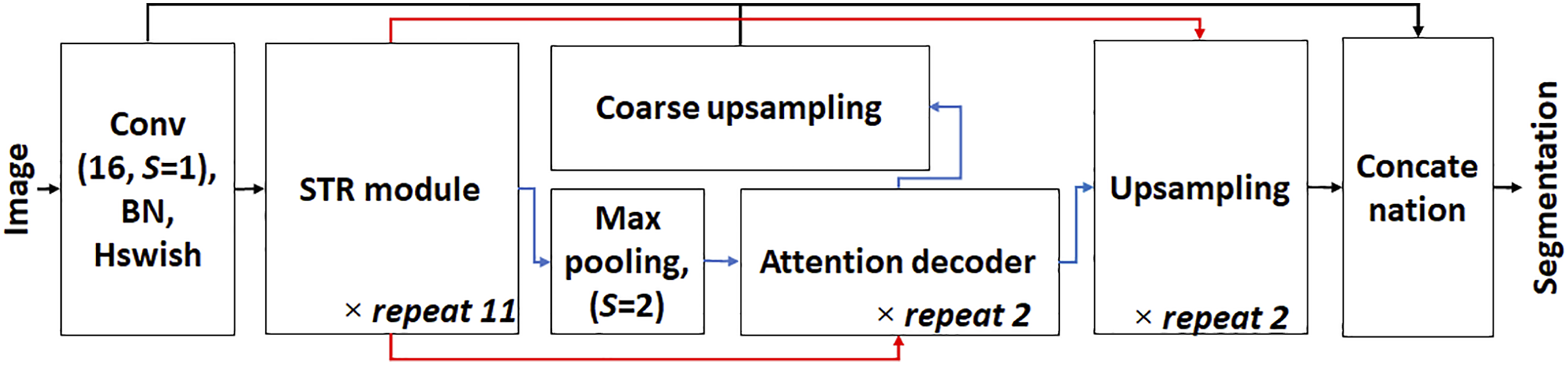
STRNet processes an input image by 16 Conv filters with a size of 3 × 3 × 3 with stride (S) 1, BN 40 and Hswish 41,42 activation function with a skipped connection. The result of these processes in the first block of Figure 1 is inputted to a newly designed STR module and final “Concatenation block” as shown in Figure 1. The STR module is repeated 11 times, and afterward, the feature map is fed into Max pooling operator and is then forwarded to the newly designed Attention decoder and Upsampling module. The result of Max pooling goes through the Attention decoder two times, and the output is fed into Upsampling and Coarse upsampling modules. The outputs of the final upsampling and coarse upsampling modules are concatenated with the output of the first Conv block as shown in Figure 1. The concatenated features are processed by pointwise convolution (PW) to match the output to the input image size for final pixel-level segmentation. The details of the developed modules and their roles are described in the following subsections.
STR module
The STR module is newly developed in this paper to improve the segmentation accuracy by reducing the computational cost for real-time processing on the complex scenes. The STR module is composed of PW, depthwise convolution (DW), BN, Swish activation function, squeeze, and extension-based attention module as shown in Figure 2. STR module has three different configurations (i.e., STR_config1, STR_config2, and STR_config3) as shown in Figure 2. STR_config1 has simple processes of 3rd block, 4th block, and 10th block with PW, DW, BN, and rectified linear unit (ReLU) activation function,
43
illustrated as the dark greenish block shown in Figure 2. STR_config2 is combined with STR_config1 and squeeze and excitation-based attention (SEA) module
44
with ReLU illustrated as the yellowish block shown in Figure 2. STR_config3 is the entire network of the STR module with blocks from 1st to 11th. STR module is repeated 11 times, and different configuration is operated in each repeat as presented in Table 2. The detail structure of STR module. Detailed hyperparameter for STR module.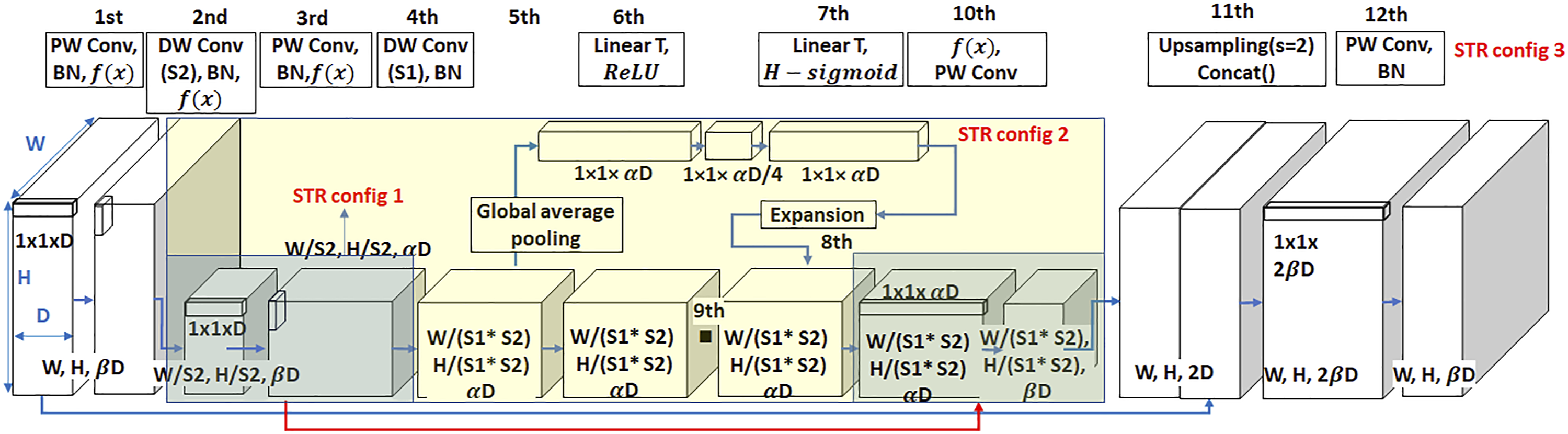
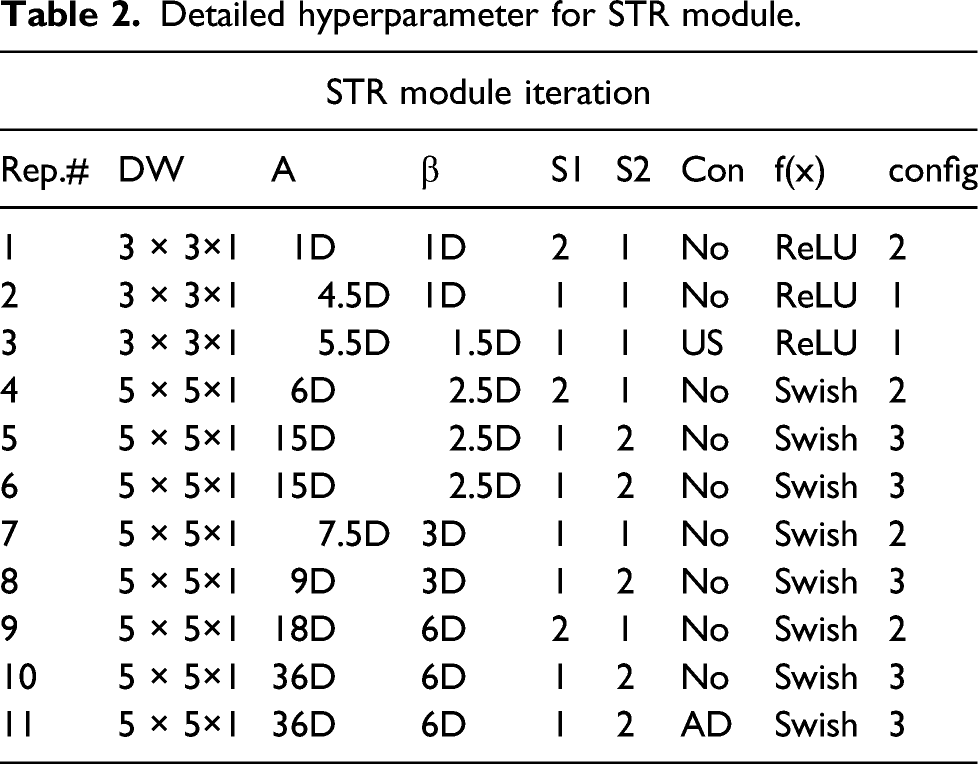
All these arrays of configurations are new and unique with different DW convolution sizes, different stride sizes (S1, S2), with/without SEA module, ReLU/Swish activation function, and skipped connection. The Con in Table 5-2 indicates the skipped connection with the red arrow line as shown in Figure 5-2, which only happens with US and AD which stand for upsamping and attention decoder, respectively. Therefore, the Connector is only used in the repeats in 3 and 11 to keep multilevel features. Publicly available segmentation networks usually apply stride 16 or 32 to the feature map in an encoder module, which means that the extracted feature map size is reduced to 16 or 32 times smaller than the original input image size. However, these large spatial contractions of the extracted feature maps compared to the input size may cause the loss of important features. This issue is found throughout our extensive experimental studies to develop this unique network, although it might be only applicable to this unique crack segmentation problem. Due to the nature of cracks with very long and thin shapes, a network may need a slightly larger feature map. Therefore, we applied stride 8 (i.e.,
To resolve this issue, and to maintain important features and real-time processing, we use different STR configuration (i.e., configs 1–3) in each repeat as presented in Table 2. Through the STR_configs1 and 2, we extracted features by keeping its relatively large feature map, but these large feature maps require large computational costs compared to small feature maps through the deep layers of the network. Therefore, to reduce its feature map by keeping the important features, we used STR_config3 with squeeze and excitation based attention operation.
The role of squeeze and excitation operation is to extract important features. In order to squeeze the extracted feature map, global average pooling at the fifth block is applied in STR_configs2 and 3. The global average pooling performs the average pooling operation entire W (input width) and H (input height) size in each feature channel, so the output feature map becomes 1 × 1 × αD at the sixth block. The physical meaning of this global average pooling is the extraction of important (i.e., mean) features from the extracted features. Here, α is given in Table 2, and D is 16 since we conducted traditional Conv 16 times, as shown in Figure 1. This process is called squeeze process, and it extracts important features while compressing information. This feature is fed into two linear functions (LinearT)
46
with ReLU and H − Sigmoid.
42,45
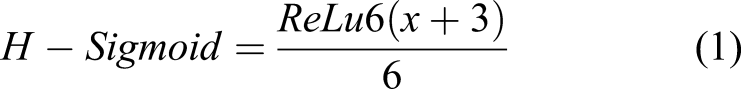
The role of STR_config3 restores an important feature map using a skip connection illustrated with a thick blue line at the bottom of Figure 2. It reduces computational cost compared with the two other configurations of the STR module, which can be validated by the following equations. The PW and DW are formulated as follows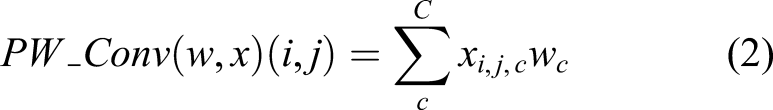
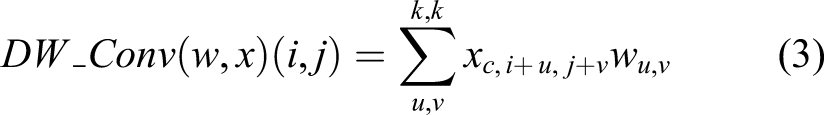
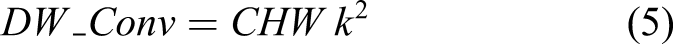
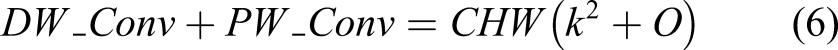
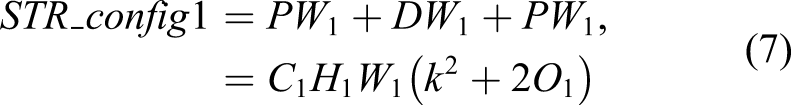
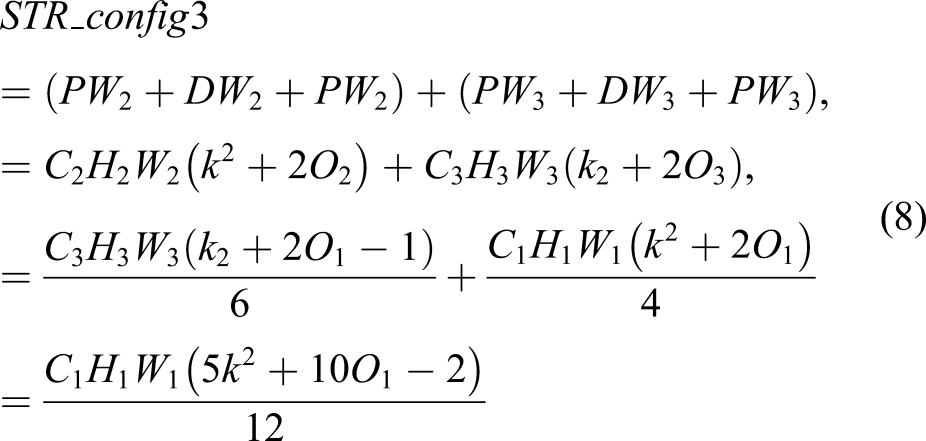
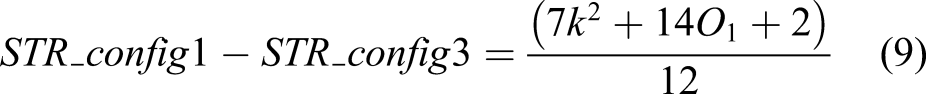
Another technical contribution of this STR module is the implementation of a non-linear activation function. Most recently, proposed networks in this area typically only use ReLU because of its simplicity in differential calculation for backpropagation and to reduce computational cost and automatic hibernation of unnecessary learnable parameters in the network. However, our objective is to develop a concise and efficient network by using a smaller number of hidden layers, meaning most of the assigned learnable parameters in each filter in each layer should be fully used to extract multiple levels of features for high performance of the pixel-level segmentation.
Therefore, using ReLU is no longer a viable option for this concise and light objective specific network. We only used this ReLU for the first three STR module repetitions for the stable training process as presented in Table 2. After that, we used a learnable Swish nonlinear activation function
39
to resolve this issue in the STR module.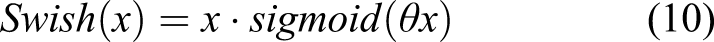
Attention decoder
The role of traditional decoders in this pixel-level segmentation problem is to recover the size of the extracted feature map from well-designed encoders. However, the performance of the encoders is not usually high enough to achieve a very high level of segmentation as we previously discussed in the Introduction section. Therefore, in this paper, we developed a unique attention-based decoder to support the role of the STR encoder to screen wrongly extracted features in the encoding process. Initially, we used existing attention decoders,
49,50
but due to their heavy computational cost, real-time processing was impossible. Therefore, we designed a unique decoder by configuration of Attention decoder, Upsampling and Coarse upsampling by using the attention operation minimally to reduce the heavy computational cost to keep its real-time processing performance as shown in Figure 3. Designed attention decoder.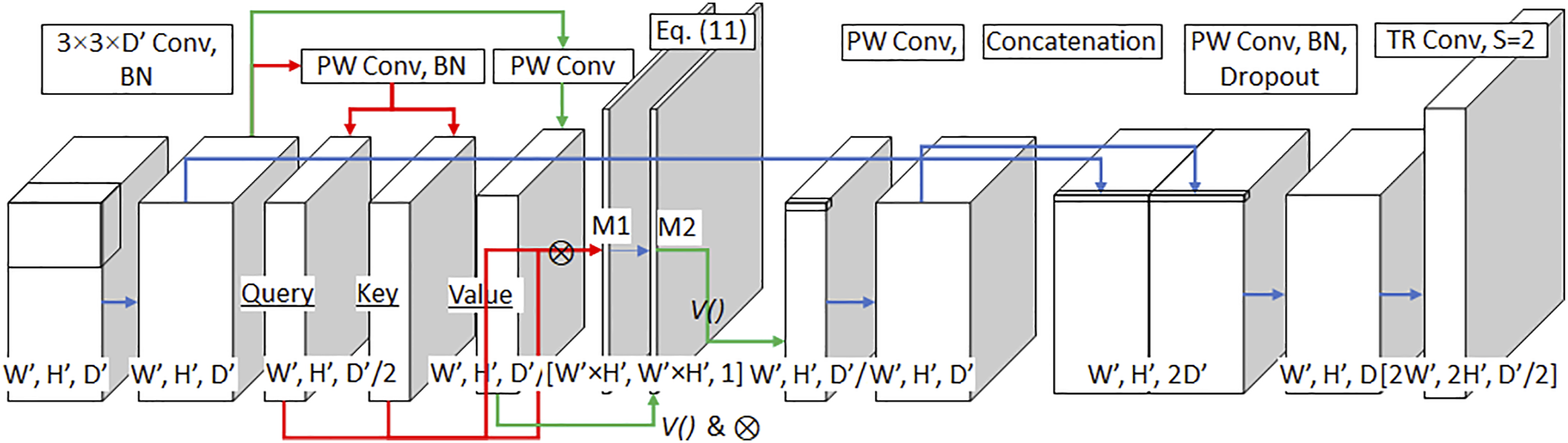
The role of “Attention decoder” shown in Figure 3 is to screen wrongly extracted features from the STR encoder and to recover the reduced feature spatial size from STR module by keeping its unique features from the original input size. Usually, an attention decoder is repeated more than 4 times in publicly available networks. 32,51 However, we only repeated it two times to reduce computational cost, and we used Upsampling and Coarse upsampling operators to supplement this reduced number of attention decoder repeat as shown in Figure 1.
In Figure 3, the first input size ([W’, H’, D’] = [64, 32, 96]) is the final output of the encoder with the result of 2 × 2 max pooling. This input is applied to 3 × 3 convolution and BN. This result is processed by PW with/without BN and produces Query 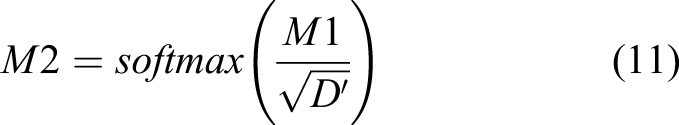
The object context produced by attention process and the output of first Conv operation from the first block of the overall architecture of the STRNet as shown in Figure 1 are concatenated as shown in Figure 3. PW_Conv condenses this concatenated feature map, and dropout 52 is applied to prevent overfitting. Finally, the transposed convolution restores the semantic mask. 53
Upsampling and coarse upsampling
The Upsampling layer is intended to double the dimensions of input, and it is commonly used in any segmentation network
10,33,35
. The input feature passes the bilinear upsampling. Bilinear upsampling increases width
Concatenation block
Skip connection or simple bilinear upsampling has been widely used for encoder and decoder-based networks
35,32
to keep multi-level features. We also use the multiple skip connections to obtain better segmentation as shown in Figure 1. As shown in Figure 4, we concatenate the results of the traditional Conv block, Attention decoder with Coarse upsampling, and Upsampling. The Concatenation block.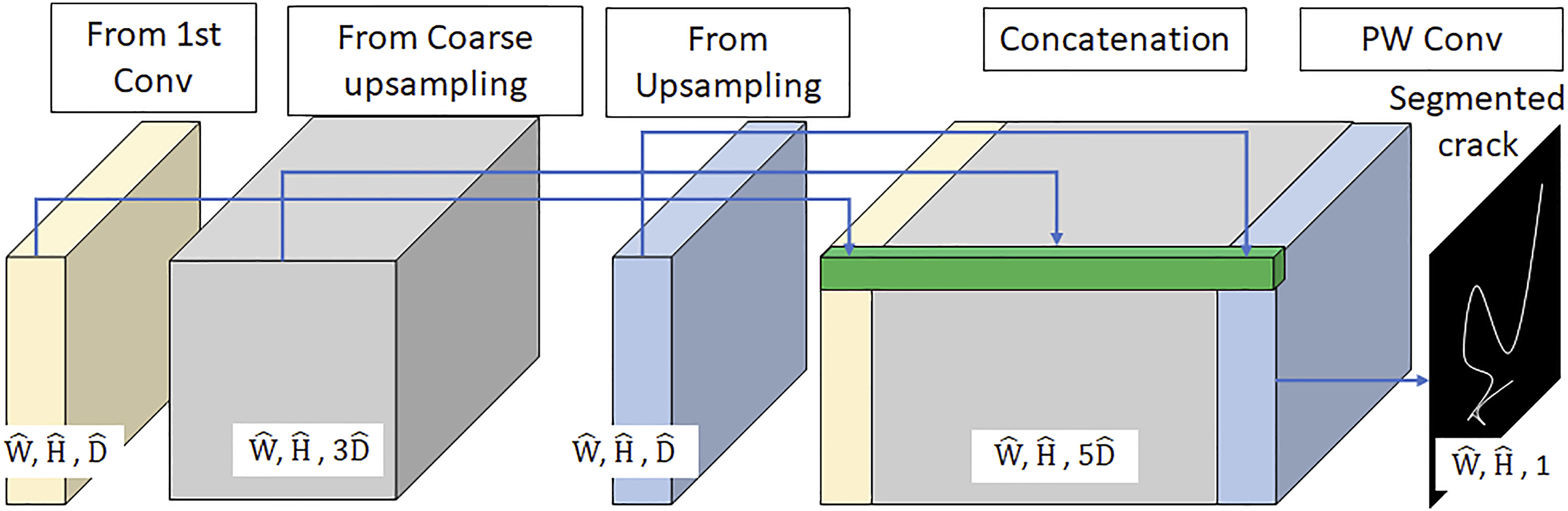
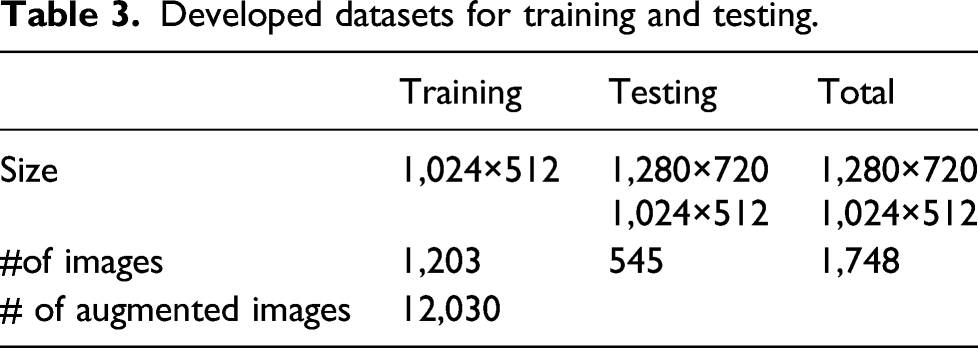
Established data bank
Developed datasets for training and testing.
Data augmentation
The prepared ground truth data presented in Table 3 is not enough to achieve high performance segmentation which can negate the detection of any cracklike features on the complex scenes. Therefore, traditional data augmentation skills such as random rotation and random cropping were conducted. Moreover, synthesis techniques of ground truth images to generate cracks on complex scenes were also applied by inserting an object of interest into another non-target image with complex scenes that would allow us to achieve a robust classifier. Figure 5 shows two approaches to generating the procedure and synthetic images. Two image synthesis approaches for training data generation.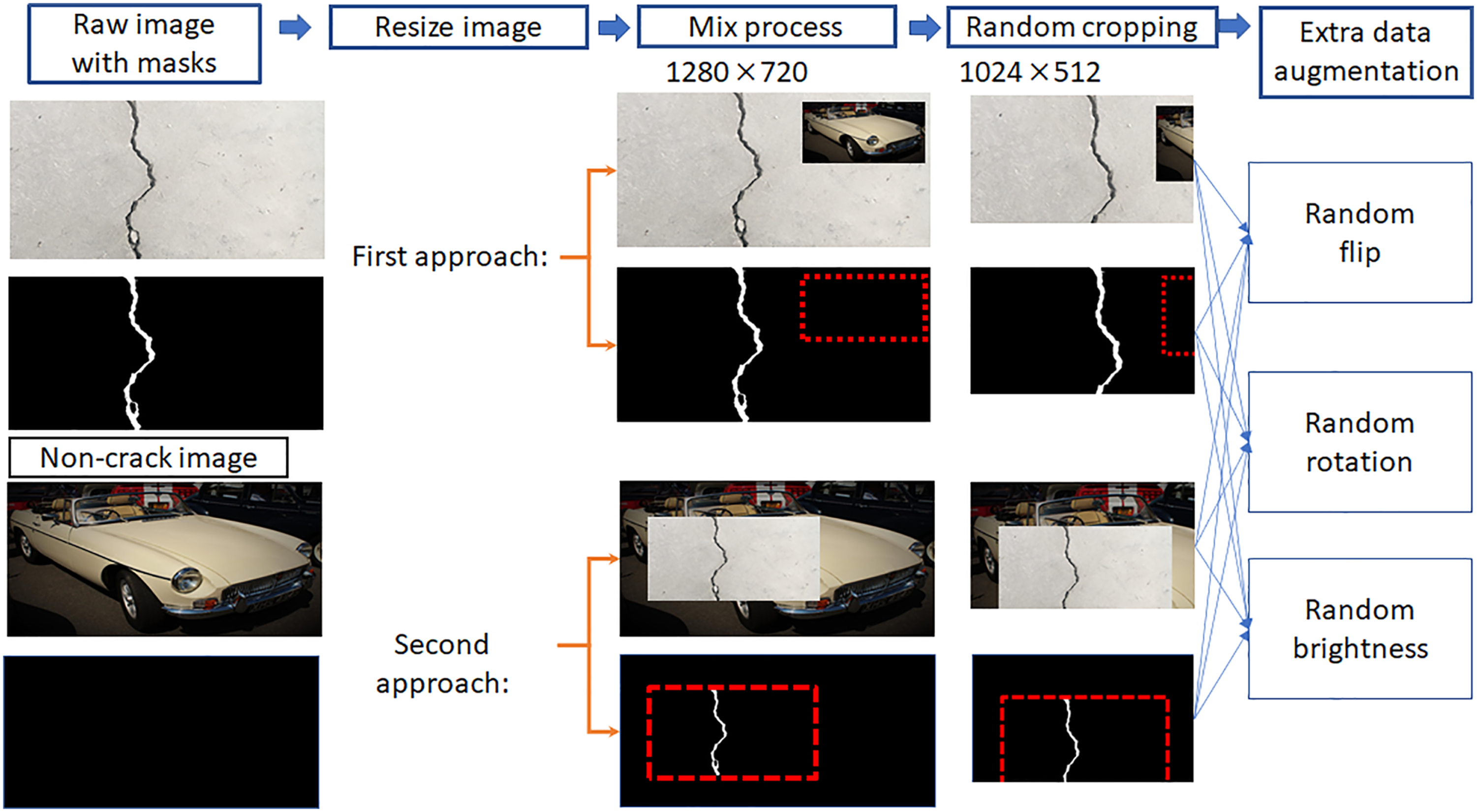
The first approach is that the image with cracks is set as a background image, and a non-target image having complex scenes but without cracks is inserted in the background image as shown in Figure 5. The second approach is vice versa. After, the synthesized images are further processed with random flipping, rotation, and brightness operations, and they are resized to 1024 × 512. The complex non-target images without cracks are collected from Open Image Dataset v4 54 . We used 1203 images from 99,999 images. In order to crop the area having crack pixels in ground truth images, the CropNonEmptyMaskIfExists function from Alns, and they are resized to 1024bumentation 55 was used, and the cropped crack area was patched to a non-target complex background image as shown in Figure 5. The cropped crack image size is randomly selected from 300 × 204 to 400 × 512, and the location of insertion is also randomly selected. Therefore, the eventual total number of augmented images for training is 12,030 as presented in Table 3.
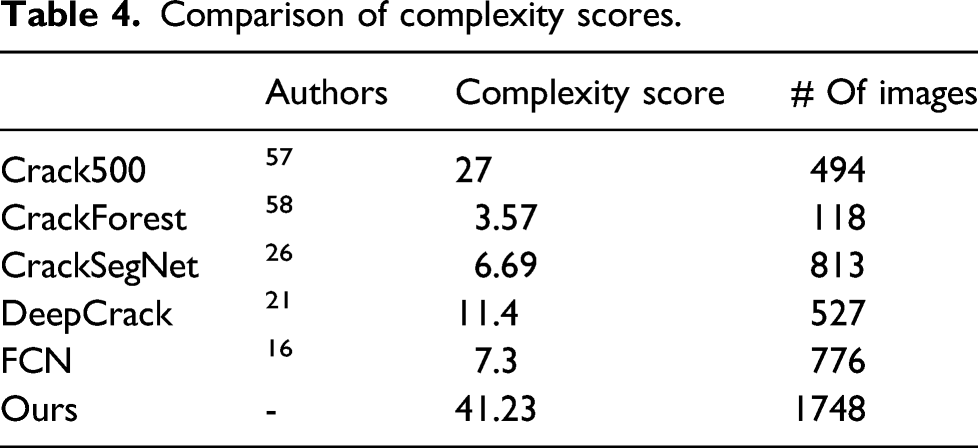
Complexity of the proposed dataset
Considering complex background scenes of structural damage in the real world is critical, as mentioned in the Introduction section. However, the evaluation of these scenes’ complexity levels can be subjective if no quantitative evaluation method is used. For this reason, we put forward an algorithm for evaluating the complexity of an image dataset. The fundamental concept of the complexity check evaluation algorithm is to count the number of objects in a scene. The higher the object number, the greater the complexity level.
To count the number of objects in an image, we used Felzenszwalb’s graph segmentation method.
56
Felzenszwalb’s algorithm verifies the relationship between pixels and edges in an image. For example, if an edge appears between two pixels, these two pixels are assumed to be located in different clusters (i.e., objects), Cn, as expressed in equation (12). If no edge appears between pixels, then they are assumed to be located in the same object.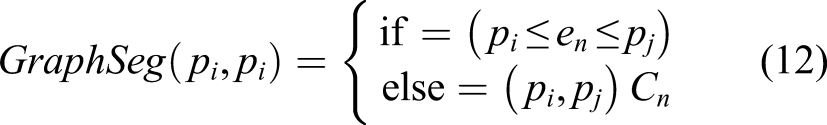

Cn is too fine a level of object segmentation without consideration of image noise. Therefore, a smooth function was adopted, as expressed in equation (14). An example of Felzenszwalb’s algorithm results.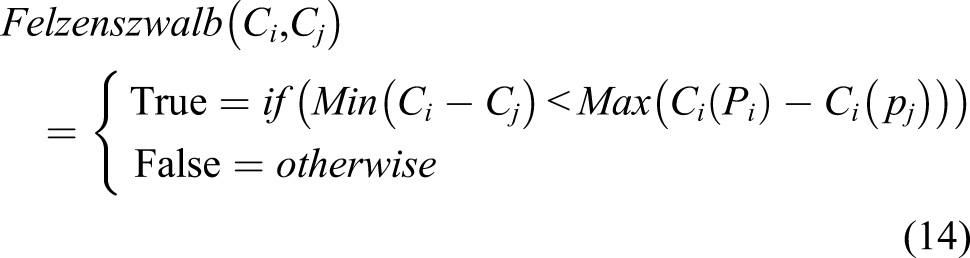

Comparison of complexity scores.
Training details
This section describes the details of the training process and hardware. Python programing language
59
with Pytorch 1.6 deep learning library
46
was used to code the STRNet. The STRNet was trained in a graphic processing unit (GPU) equipped workstation. The workstation specifications are Intel Core i76850K CPU, Titan XP GPU, and 128 GB RAM. To train our models, we set up the four Titan XP GPU using Nvidia Apex distributed data parallel (DDP) training library. The input image size is 1024 × 512, which is randomly cropped if the image size is bigger than the input size. The use of proper loss function is crucial; therefore, we investigated several recently developed functions such as cross entropy loss, dice cross entropy loss, and mIoU. Eventually, focal-Tversky loss function was used for training. The focal-Tversky loss was used as a combination of the loss function
38
as follows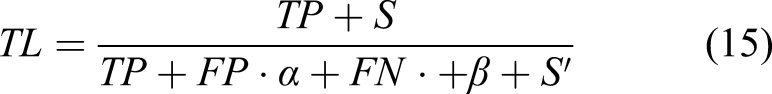
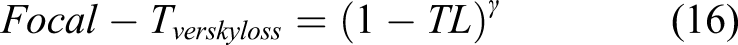
In order to do backpropagation for the learnable parameter updating, the Adam optimizer was employed . 60 The hyperparameters such as first moment, second moment, and dropout 52 rate were defined as 0.9, 0.999, and 0.2, respectively. The initial learning rate was 0.005, and dropped by 20% when the number of epochs were 30, 70, and 120, to keep a stable training process. To reduce the training time, a DDP with batch size eight was also used for four GPUs.
The progress of the focal-Tversky loss through training epoch iteration is plotted in Figure 7. As shown in the figure, we conducted two types of training and validation processes: hold-out validation and train-valid-test split validation. For the hold-out validation, we divided the total dataset into training and testing sets, as tabulated in Table 3, and conducted training and testing as the validation, which is plotted in Figure 7(a). For the train-valid-test split validation, a 10% validation dataset (170 images) of the total images (1748 images) was randomly selected from the training dataset (1203 images), and training and validation losses and scores were plotted during the training iterations, as shown in Figure 7(b). In these two validation processes, there was only a small discrepancy between the training score (93.8) and validation score (91.0), see Figure 7(b). This means that the training set is not developed/determined to achieve a high performance from the specific testing and validation datasets, because the training score (93.8) is slightly higher than the validation score (91.0) and the claimed testing score (92.6). Focal Tverskey training loss and score via epoch iteration. (a) Hold-out validation. (b) Train-valid-test splits validation.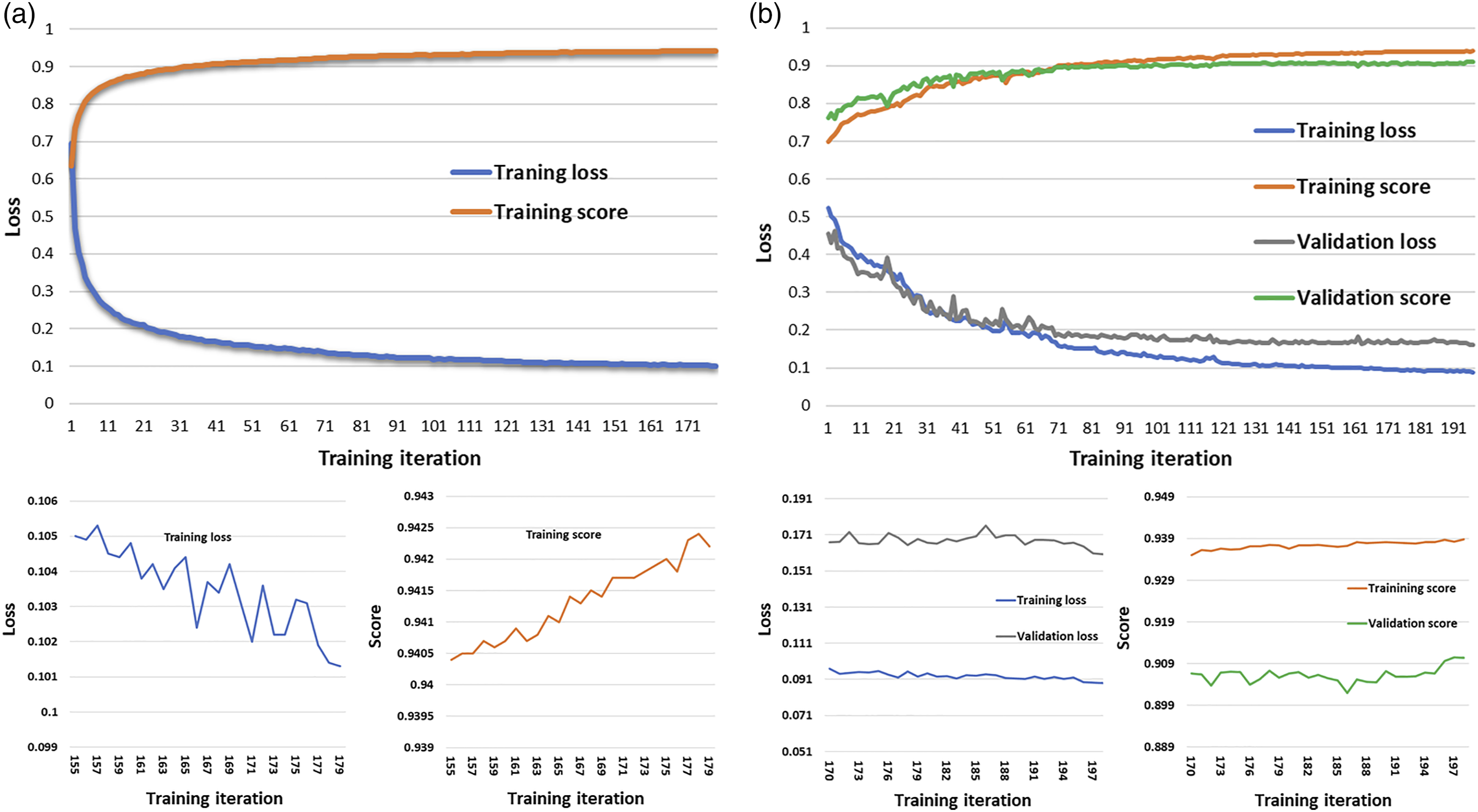
Case studies
The developed STRNet was extensively experimentally investigated. In case studies, some parametric studies were carried out to find effective image synthesis technique, loss function, activation function, and effective decoder. In Parametric studies of STRNet, the eventual STRNet based on the parametric studies was tested on many complex scenes to segment concrete cracks. In Comparative studies, extensive comparative studies were conducted in the same training and testing datasets with the same conditions of loss function for fair evaluation.
Parametric studies of STRNet
We conducted parametric studies to find the most effective parameters and architecture of STRNet. In order to train and test the developed network, the training and testing data presented in Table 3 were used. All data augmentation techniques described in Established data bank were also applied. The used evaluation metrics are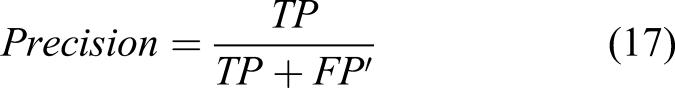
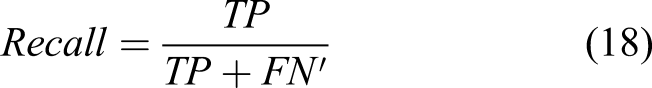
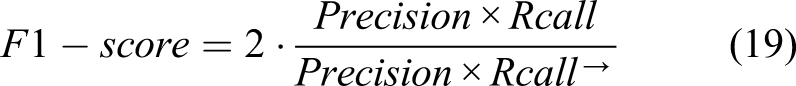
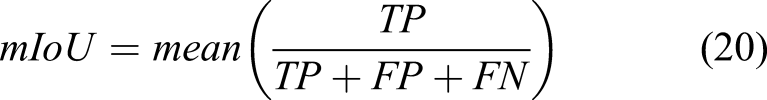
Parametric studies for STRNet.
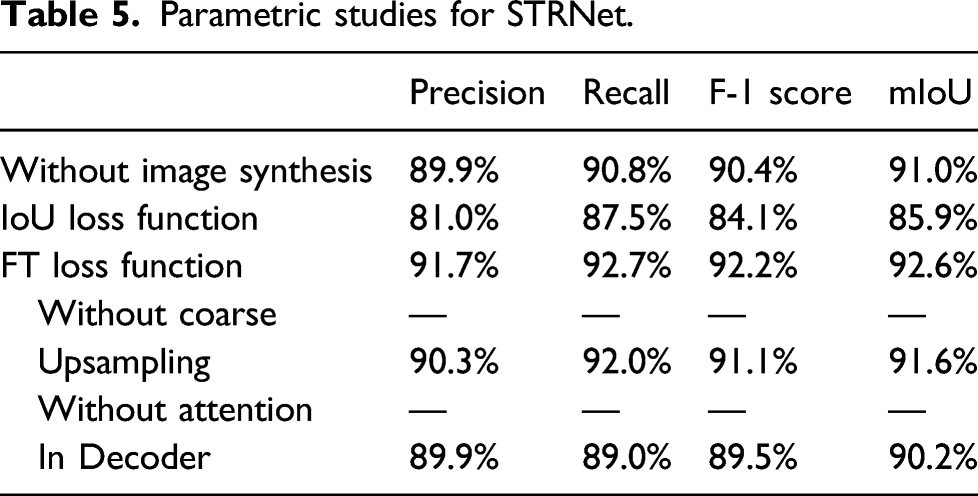
At this experimental test, the image synthesis was applied for both cases. We used the coarse upsampling technique in STRNet and tested the effectiveness. The coarse upsampling method improved the mIoU by approximately 1%. Another unique technique in this STRNet was the attention decoder. The effectiveness of the attention decoder was also investigated, which showed that it improved the mIoU by approximately 2.4%. With these parametric studies, we decided the eventual network of the STRNet with training methods such as image augmentation and loss function.
Random validation through 10-fold random selection.

Experimental testing of STRNet
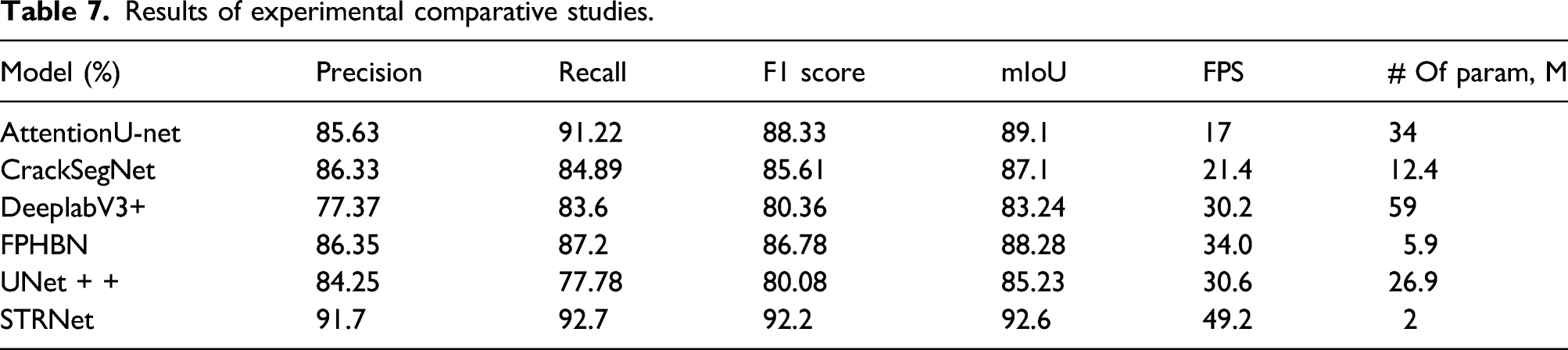
In this section, the eventual parameters and module from the experimental studies in Section V-A was selected as the final STRNet. This STRNet showed a maximum 92.6% mIoU on 545 images having complex scenes with 49.2 FPS using single V100 GPU for 1024 × 512 input images. This is much faster than required speed (i.e., 30 FPS) for real-time processing. It provides very stable performance without unbalance among false positives and false negatives based on 91.7% precision and 92.7% recall evaluation metrics including 92.2% F1 score. The reported mIoU 92.6% is considered to be a very high level of accuracy since all the ground truth (GT) data has a minimum level of annotation error because there are many unclear cases that a pixel is included in a crack or intact concrete surface. Therefore, it seems that a maximum of 5% error is unavoidable in ground truth data. Some example results of the STRNet on complex scenes are illustrated in Figure 8. The Case 1 is related to the image having shadow, so cracks in the image are unclear to the naked eye, but the STRNet segmented cracks are very accurately based on the ground truth. Case 2 depicts a very thin crack with a blurry image, Case 3's image has water stains, Case 4 portrays crack-like features on concrete wall, and Cases 5 & 6 are images with complex scenes. In each of these cases, the STRNet showed satisfactory results. Examples of STRNet results on various complex scenes.
Comparative studies
Extensive comparative studies were conducted to show the superior performances of the proposed STRNet compared to the traditional networks. The selected networks are attention Unet, 19 Deeplabv3+, 17 Unet + +, 61 FPHBN, 28 and CrackSegNet. 26 All these advanced networks are recently developed and showed state of the art performances in this segmentation area and applied them to the crack segmentation problem.
Results of experimental comparative studies.

Example results of the comparative studies.
Conclusion
In this paper, a novel STRNet, which is a deep convolutional neural network, is developed for concrete crack segmentation in pixel level. The developed network was trained using large training data set and tested on 545 images. The performances of the proposed network in terms of precision, recall, F1 score, and mIoU are 91.7%, 92.7%, 92.2%, and 92.6%, respectively, with 49.2 FPS using V100 GPU which is able to process relatively large input images (1280 × 720, 1024 × 512) with real-time manner. From the extensive comparative studies, this demonstrated the best performance in terms of the upper four evaluation criteria. New technical contributions of this paper are:
(1) A new deep convolutional neural network was designed to be able to do real-time processing using relatively large input images (1280 × 720, 1024 × 512) with 49.2 FPS. (2) The proposed network showed state of the art performance in segmentation of cracks with 92.6% mIoU. (3) The STRNet has the lightest network size among the compared networks with a 2m memory size, which offers the great benefit of being applicable to real world problems using a microcomputer. (4) The network was able to segment cracks on highly complex scenes including different area, structures, and lighting conditions. (5) The evaluation method of image complexity evaluation method was proposed, and our training and testing datasets showed the highest level of complexity among available the examined datasets. (6) The new encoder named as the STR module was developed to extract multi-level features effectively. (7) The new decoder with the attention module was developed to support the STR encoder by screening wrongly extracted features from the encoder to improve the segmentation accuracy (i.e., 2.4% mIoU). (8) Coarse upsampling was adopted for this crack segmentation problem. It improved the 1% mIoU. (9) The new loss function (Focal-Tversky loss function) was adopted to train the newly designed network to improve the crack segmentation performance (i.e., 6.7% mIoU). (10) Many training and testing data with large image sizes were established to conduct extensive evaluations (see Table 3). (11) The prepared ground truth data were drastically reduced in annotation errors compared to the publicly available crack segmentation data. (12) A new image synthesis technique was adopted to augment the ground truth training data to improve the network performance (i.e., 1% mIoU). (13) A learnable swish activation was adopted to improve the segmentation performance by keeping a concise network which enables faster than real-time processing. This may give us the possibility to increase the testing input size image.
The performance of the STRNet was outstanding on the given testing and training datasets, but a larger dataset will be required to monitor the many varying types of structures together using a single trained network. However, this problem can be resolved by grouping the structures, such as bridges, buildings, and dams. Then, depending on the specific group, the user can collect data and train the network. The trained network can be installed beneath a reinforced concrete bridge deck or girders with a vision sensor and microcomputer as an example of a real structure application. The mixed precision training strategy must test for faster speed.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was supported by the NSERC Discovery Grant (RGPIN-2016–05923) and the CFI JELF grant, (3739,4).