
Abstract
In recent years, electrical tomography, namely, electrical resistance tomography (ERT), has emerged as a viable approach to detecting, localizing and reconstructing structural cracking patterns in concrete structures. High-fidelity ERT reconstructions, however, often require computationally expensive optimization regimes and complex constraining and regularization schemes, which impedes pragmatic implementation in Structural Health Monitoring frameworks. To address this challenge, this article proposes the use of predictive deep neural networks to directly and rapidly solve an analogous ERT inverse problem. Specifically, the use of cross-entropy loss is used in optimizing networks forming a nonlinear mapping from ERT voltage measurements to binary probabilistic spatial crack distributions (cracked/not cracked). In this effort, artificial neural networks and convolutional neural networks are first trained using simulated electrical data. Following, the feasibility of the predictive networks is tested and affirmed using experimental and simulated data considering flexural and shear cracking patterns observed from reinforced concrete elements.
Keywords
Introduction
Background
Structural health monitoring (SHM), in a broad sense, aims to assess the integrity, condition and/or damage state of target structures. 1 Respectively, SHM frameworks have proposed clear hierarchies including, for example, aspects such as detection, localization, classification, assessment, and prediction which serve as facets for monitoring. 2 For such hierarchies to be satisfied, SHM modalities should therefore include systematic, automatic and continuous data acquisition followed by accurate post-processing and analysis. To address the latter needs, specifically rapid and accurate damage assessment of structural concrete elements, this work focuses on rapid probabilistic crack prediction and localization enabled by machine learned models.
Prediction and localization of cracking in concrete elements is well documented in the field of non-destructive testing (NDT) literature. Various traditional approaches include ultrasonic, magnetic, electromagnetic, radiographic, photographic, and infrared modalities.3–7 In contrast to these well-established methods, electrical-based modalities have recently shown promise in non-destructive testing and evaluation of cement-based materials and structures. 8 For example, in their seminal work, Karhunen et al. 9 demonstrated industrial applicability of electrical modalities for assessing the degree of cracking, localization of reinforcement, corrosion state and depth of the cover in concrete elements. Additionally, previous studies have shown that electric impedance spectroscopy (EIS) is relatively inexpensive and can be applied on concrete elements to detect cracks to include their width/depth, reinforcement and internal moisture.10,11 On the other hand, electrical tomography, more specifically electrical resistance tomography (ERT, a specific electrical tomography modality), has been recently demonstrated as an effective modality for detecting simple and complex cracking patterns in concrete elements 9,12–14; meanwhile, ERT has low experimental costs, energy consumption, fast data collection, high temporal resolution and potential of continuous spatial monitoring. 15 However, the potential disadvantages of ERT include its lower spatial resolution compared with other contemporary modalities and (traditionally) high computational cost. 16
In assessing the former realizations regarding ERT, relatively low spatial resolution may be sufficient in terms of localizing cracks – especially in large members. 17 Furthermore, the high computational cost that traditionally arises in ERT stems from solving the ill-posed inverse problem. Though previous research has demonstrated that incorporating non-iterative reconstruction methods can reduce the computational time at a significant cost to spatial resolution (often overly smooth), computational demand and interpretability of reconstructions remain factors inhibiting implementation of ERT in field applications. As such, a new methodology promoting rapid and accurate cracking prediction from ERT data sets is needed. To address this issue, the following article proposes and investigates the implementation of neural networks (NNs) to directly solve an analogous ERT inverse problem affording (a) massive reduction in computing demand and prediction time relative to high-fidelity ERT reconstruction frameworks and (b) improved interpretability of (predicted) cracking patterns.
Machine learning and damage prediction
The concept of using NNs for pattern recognition and parameter space mapping originated in mid-20th century 18 and has drawn large research interest since the discovery of back-propagation while computational power has been increasing exponentially. In fact, previous studies have indicated that a well-trained network with two neurons is sufficient to recognize any linear functions between the input and output data sets theoretically. 19 However, realistically, a deeper network with nonlinear activation functions is required to predict more complex representations. 19 For this reason, we investigate the use of supervised deep learned NNs for mapping input data to desired output parameters, as detailed in the following.
Feed-forward artificial neural networks (ANNs) have architectures consisting of at least one hidden and one output layer. In a pioneering work, Baum 20 proved that a simple one-layer network can recognize a linear pattern. Following, work by Papert et al. 19 discovered that an ANN network with N − 1 neurons should be sufficient to learn an arbitrary function with N data points. Subsequent early research also indicated that networks having M ≪ N − 1 weights have approximately 50% probability of successfully predicting a random function. 21 Later, Lecun et al. 22 identified that a well-trained binary classifier is capable of linearly separating the error space by a hyper-plane. This enabling feature is key in the ability of NNs to recognize highly nonlinear patterns. However, despite tremendous research progress in ANN research, tailoring ANN parameterizations still remains an ‘art’ in practice.
In contrast to ANNs, convolutional neural networks (CNNs) are NN architectures first trained with back-propagation by Lecun et al. and inspired by human ventral visual stream.23,24 Convolutional neural networks are widely used for handwriting, image, and voice classification – along with other recognition applications. 25 A typical CNN’s functionality depends on four basic layers which are input layer, convolutional layer, pooling layer and fully connected layer. 26 Firstly, in the input layer, CNNs take input information via an image matrix where (broadly speaking) each entry is either a continuous entry or assigned a whole number varying from 0 to 255 representing the scale of each pixel from black to white. Secondly, within the convolutional layers, learnable kernels are glided through the raw input while the scalar products are calculated for each entry in the kernels; the output of this convolution operation is referred as feature maps. Each kernel has its corresponding feature map which is stacked along the depth of the input. 27 Kernels can help the network to extract more characteristic information from input data. 26 The convolution operation is mainly governed by the following three hyperparameters: 1. depth of the convolutional layer, 2. stride of the kernels and 3. padding. 28 Reducing the depth of the convolutional layers can lead to a significant decrease in network’s recognition capability. Meanwhile, stride controls the overlap when kernels are glided through the input data, by reducing the stride, one can reduce the output volumes however at the risk of missing potential features. In addition, the use of zero padding ensures that features at the extents of the image input can be efficiently extracted. Furthermore, parameter sharing can be used to reduce the number of parameters in the network by constraining the learned feature maps to have the same weight and bias. 26 Thirdly, a pooling layer aims to further downsample convolved data. For example, a max pooling layer is applied on the feature maps and only returns the maximum value within the region. Finally, data are propagated to a fully connected layer which has a similar structure to a typical ANN. Of importance here, the inputs of the (first) fully connected layer are the outputs of the last pooling layer which are subsequently propagated through the remaining fully connected layers during the training. 27
Specifically, we are interested in direct classification of spatially distributed damage (cracking) which is assigned a binary form (0 or 1). As such, the use of probabilistic cross-entropy classification is most appropriate given the binary nature of the information to be mapped (i.e. classical regression is not appropriate). Therefore, we select the binary cross-entropy function as the loss functional to be minimized in the network training, written as follows
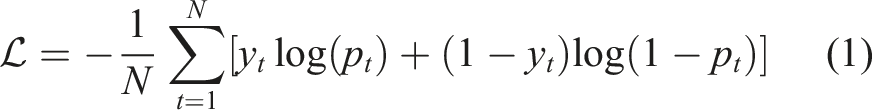
In equation (1),
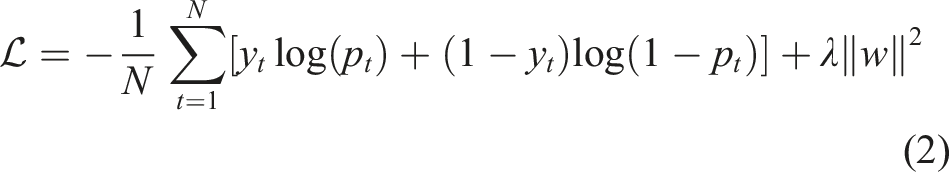
Generally speaking (and herein), equation (2) is minimized by implementing gradient decent and back-propagation via locating the minimum point within the loss space. It is worth noting that, despite developments of, for example, the Hopfield network and Boltzmann machine which offer new insight of training networks with statistical mechanics,30,31 many modern networks still rely on gradient decent and back-propagation. Moreover, while local minima can be reached by adjusting the weights of individual neurons in the network iteratively, there exist studies indicating a global minimum could be attained providing a deep neural network with non-convex objective function, 32 although the evidence supporting that is not substantial. Therefore, for the purposes of this initial work, a local minimum can be assumed to yield results deemed sufficient for the purposes of damage detection.
It is worth highlighting that, in the context of contemporary SHM research, machine learning has been successfully used in damage detection applications. For example, Bao et al. 33 utilized neural networks for optimization considering non-convex sparse time–frequency analysis and consequently achieved more accurate instantaneous frequency identification. Moreover, Mousavi et al. 34 trained deep neural networks to extract damage-sensitive features from vibration data. In addition, convolutional neural networks were also explored to retrieve missing strain data due to sensor fault by Oh et al. 35 while Mohtasham used CNNs to detect cracks on gas turbines with filtered image data. 36 Inspired by such works, in this article, neural networks are also utilized for the intended purposes of SHM.
Article structure
This article first reviews the historical development and application of ERT as well as a conventional solution to the ill-posed ERT problem. Then, the deep learned direct inversion framework is proposed. Thereafter, the data acquisition and training methodology consisting of the training data generation, neural network architecture as well as the training process are detailed. Following, predictive results for experimental and simulated crack patterns are reported and discussed considering both their advantages and drawbacks. Lastly, conclusions are provided.
Electrical resistance tomography and direct inversion
Electrical resistance tomography is a modality which aims to reconstruct internal conductivity distributions from boundary electrode measurement. To achieve this, a prescribed number of electrodes are installed on the boundary of the specimen, from which electrode potentials are measured and electric currents are injected into. Resultingly, potential differences are taken between one pair of electrodes for each injection. As a whole, the measurement protocol should be planned in a systematic manner to ensure sufficient data can be collected during each injection.
Historically speaking, ERT was initially developed and utilized for medical imaging by classifying organs based on their different conductivities, 37 later considering capacitive and inductive tomographies. 38 In the recent years, ERT has been the source of significant research interest in the NDT/SHM community. For this, ERT has been coupled with sensing skins to detect damage in reinforced concrete 13,39,40 as well as imaging damage, strain and stress fields in a broad suite of composite materials.41–48 Previous related studies also demonstrate that ERT is capable of imaging internal moisture flow within cement-based material in both 2D and 3D settings.8,49
Until recently, high-fidelity solutions to the ERT reconstruction problem have generally required solving an optimization problem using conventional iterative regularized computational methods (readers are referred to 16 for a comprehensive review of ERT inversion methods used in NDT). However, as earlier alluded to, such methods can be demanding and pragmatically inhibiting. On the other hand, linearized difference imaging schemes offer much faster solutions at the cost of spatial resolution. 50 As such, we herein take a different approach to the ERT inversion problem by utilizing direct inversion enabled by trained NNs in order to attain rapid high-fidelity predictions. Related work has, for example, aimed at using NNs for solving the continuous ERT problem. 51 Additional research has shown that CNNs are capable of reconstructing ERT image data 52,53 however not for detecting cracking in structural applications. Recently, researchers in Reference 54 also used NNs to optimize the electrode locations in ERT measurement aiming at achieving more efficient data acquisition. In the following section, written for contextualization, we will first discuss the forward problem underlying ERT physics (and used for generating training data), then discuss the conventional ERT inverse problem and finally propose the analogous ERT direct inversion framework.
The ERT forward model
In order to reconstruct the internal conductivity distribution, an ill-posed ERT inverse problem needs to be solved. The ill-posed nature of this problem results from a number of factors, including (a) ill-conditioning of matrices used in the optimization, (b) experimental measurement noise and (c) the diffusive nature of electric fields.
2
Nonetheless, in order to implement ERT computationally, a numerical forward model is required in order to map the internal conductivity to boundary measurements. For this, we utilize the complete electrode model (CEM), which is implemented using finite elements55,56 discretizing the following equations
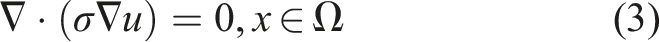
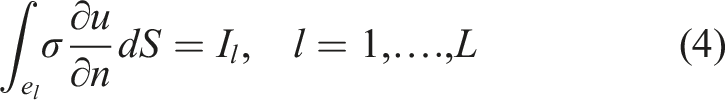
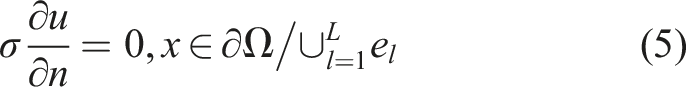
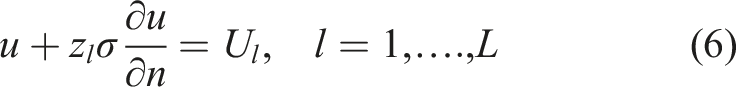
Equation (3) is the Laplace equation which describes steady-state diffusion
47
in a target domain Ω with a boundary ∂Ω. Further, x represents Cartesian coordinates within the domain while σ(x) and u(x) represents the conductivity distribution and potential distribution within the target. Equations (4)–(6) provide the necessary boundary conditions to solve equation (3), where e
l
represents the l
th
electrode; hence, U
l
is the potential measurement on the corresponding electrode. I
l
represents the current injection on l
th
electrode. dS represents the infinitesimal surface of Ω while z
l
represents the contact impedance between the l
th
electrode and the internal domain. Equations (4)–(6) provide an accurate forward model solution by taking the shunting effects of electrodes and their contact impedance into account.
57
Lastly, in order to satisfy the current conservation law and fixed potential reference level which would ensure an unique solution, the following equations are written to complete the CEM


We would like to emphasize that the CEM describes the forward problem where the internal conductivity is known, from which the electrode potentials can be computed. As such, we adopt the CEM in generating training data sets which consist of boundary voltage measurements accompanied by corresponding internal conductivity distribution is known. However, in pragmatic imaging scenarios, the internal conductivity distribution is unknown. Therefore, conductivity estimates must be obtained using an inverse methodology as described in the forthcoming sections.
The ERT inverse problem
The traditional nonlinear ERT inverse problem can be conceptually characterized by the following observation model


Unfortunately, due to the presence of noise, numerical modelling error, nonlinearity of U(σ), and ill-conditioning of resulting ERT matrices used in solving the inverse optimization problem, there are infinite solutions to equation (10). Thus, we require advanced regularization to incorporate biasing prior information and, often, physical constraints in optimizing/solving the nonlinear (absolute imaging) inverse problem. In order to avoid such complexities, the observation model may be linearized in order to obtain solutions with less up-front computational demand/complexity. 58
Linearized ERT, or simply difference imaging as we will herein refer to it, is a framework which aims to reconstruct the difference of internal conductivity Δσ based on differences of boundary voltage measurements ΔV from two different states (subscripts 1 and 2 representing baseline and damaged states, respectively) expressed in the following


As a consequence, the following linearized observation model can be written

Based on the observation model in equation (13), the ERT reconstruction problem is generally facilitated by a one-step least squares solution minimizing the following objective function
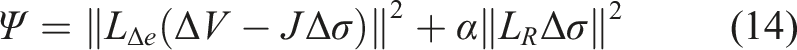
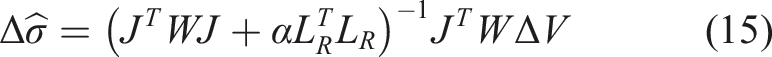
The advantages in adopting linearized schemes, such as the difference imaging approach described previously, are numerous. Firstly, since one-step optimization is used, inverse solutions are significantly less computationally demanding than nonlinear absolute imaging solutions. Secondly, and of principle importance to this work, the use of difference data ΔV results in subtraction of systematic errors. Therefore, in cases where measurements are simulated for use in training data, a significant portion of modelling errors are subtracted – thereby reducing the influence of modelling error corruption in training. In the following subsection, we will detail the incorporation of difference data into the learned direct inversion scheme analogous to the traditional linearized scheme previously described.
Analogous ERT direct inversion framework
This section introduces the learned framework used to directly solve the analogous ERT (crack reconstruction) inverse problem. Following, we provide rationale for the ANN and CNN architecture selections and learning approaches used in direct inversion.
Analogous ERT direct inversion approach
The overarching aim of the proposed direct inversion approach is to map ERT difference measurements ΔV to probabilistic binary crack distributions. The purpose for choosing a binary cracking representation is to simplify the interpretability of damage predictions. More technically, we aim to predict the probability of local cracking p
σ
∈ [0, 1], where a predicted value of 1 indicates that a pixel contains a crack with 100% predicted confidence. Conversely, a predicted value of 0 refers to 0% confidence of a crack within the pixel while intermediate predicted values convey uncertainty in the local occurrence of cracking. Summarily, we aim to learn the following mapping

The function
Selection of machine learning architectures and learning approach for cracking classification
In this section, we introduce the potential algorithm options for solving a classification problem and justifications for our ANN and CNN selections. A significant analysis and discussion on classification techniques by Kotsiantis and coauthors 59 show that there are options as following: 1. logic based algorithms such as decision trees, 2. perceptron-based techniques such as single layered perceptrons and deep neural networks, 3. statistical learning algorithms such as Naive Bayes classifiers (NB) and Bayesian networks (BNs), 4. instance-based learning such as k-nearest neighbour (kNN) and 5. support vector machines (SVMs). Generally speaking, SVMs and neural networks yield more accurate outputs with multi-dimension input features. A quantitative study by Osisanwo et al. 60 shows that SVMs and NNs have better accuracy when tested with larger data sets and more attributes. However, SVMs are designed to be binary algorithms, and as a result, this feature can potentially limit its applications when dealing with non-binary classification problems. In addition, logic based algorithms are highly interpretable; however, the accuracy of such algorithms are significantly affected by the input features which need to be discretized in exchange for a higher classification accuracy. 61 Furthermore, NNs have been found to be more reliable in providing incremental learning compared to decision trees. 62 For statistical learning algorithms, although most of them require less computational time when compared to NNs, the assumption of independence between nodes has been shown to result in comparatively lower accuracy. 59 As a result, BN classifiers need large networks to reach high accuracy which is often not feasible; therefore, these algorithms may not be suitable when using large feature data sets. 63 For instance-based learning such as kNN, the choosing of k is essential especially when noise is present in the training input sets. However, currently there is a dearth in rigorous selection approaches for choosing k in pragmatic applications, thereby leading to large computational time for classifications. 64 Taken together, the above analysis suggests that NNs are the most suitable selection for this work, owing to their overall accuracy when solving classification problems having large feature inputs. Additionally, from a practical standpoint, NNs (a) have the ability to train using (input) data in the absence of prior knowledge on their distribution 65 and (b) without specifying an optimized mathematical model. 66
To further examine the performance of different neural networks for classification problems, Jeatrakul compared the performance between back-propagation neural network (BPNN), general regression neural network (GRNN), radial basis function neural network (RBNN), probabilistic neural network (PNN) and complementary neural network (CMTNN). Each network was tested against three benchmark data sets; in their work, the BPNN turned out to be the most robust across all three training tasks. 67 Furthermore, Pasupa and Sunshem compared a CNN with an ANN using smaller data sets showing that a CNN with regularization and dropout can provide comparable results to ANN, 68 thus supporting the selection of CNN classifiers for the purposes of this work.
Summarily, the studies reviewed in this subsection suggest that ANN and CNN architectures are suitable for the crack classification tasks investigated herein. Therefore, these two neural networks are adopted for the analogous ERT direct inversion framework, namely, the mapping of input data ΔV to the probability of local cracking p σ .
Training data acquisition and training methodology
Overview
Training data were generated using the CEM equipped with quadratic triangular discretizations. A set of training samples herein consists of simulated electrode potential differences generated using sampled conductivity distributions and complimentary binary crack distributions described in the previous subsection. Regarding the potential measurements more specifically, each simulated difference measurement set results from subtracting baseline (undamaged) ERT measurements V1 from ERT measurements V2 generated from a cracked configuration.
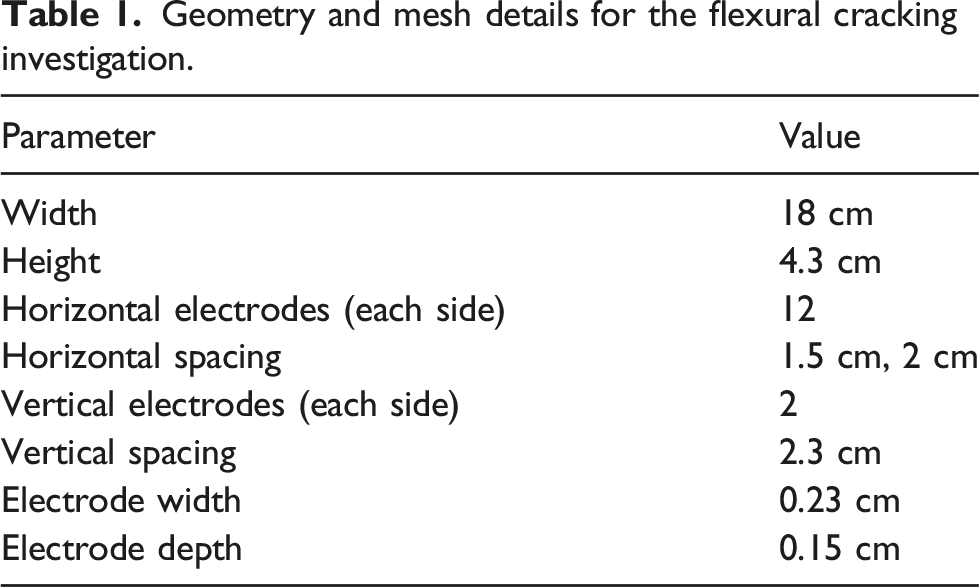
Geometry and mesh details for the flexural cracking investigation.
Geometry and mesh details for the shear cracking investigation.

The discretizations for both investigations are shown in Figures 1 and 2. Spacing and locations of electrodes can be seen in the meshes with reference to Tables 1 and 2. In all cases, internal conductivity distributions were mapped on the discretizations in order to form a continuous distribution within the domain. For this, prior Gaussian background conductivity information was incorporated when generating the samples. In generating homogeneous backgrounds, conductivities in the range of 8–10 mScm−1 were assumed in order to mimic realistic silver sensing skins (following Reference 69) in the flexural case as well as incorporating isotropic smoothness with a correlating length of 4 cm to incorporate spatial inhomogeneity. In the case of shear cracking, homogeneous background of 0.1 mScm−1 was reasonably assumed in all instances to simulate potentially low-conductive large elements (Tables 3–5). Domain discretization for the flexural cracking investigation consisting of 2557 nodes and 4896 elements. Domain discretization for the shear cracking investigation consisting of 5047 nodes and 9680 elements. Summary of the artificial neural network architecture used for reconstructing flexural cracks. Summary of artificial neural network architecture used for reconstructing shear cracks. Summary of convolutional neural network architecture used for reconstructing shear cracks.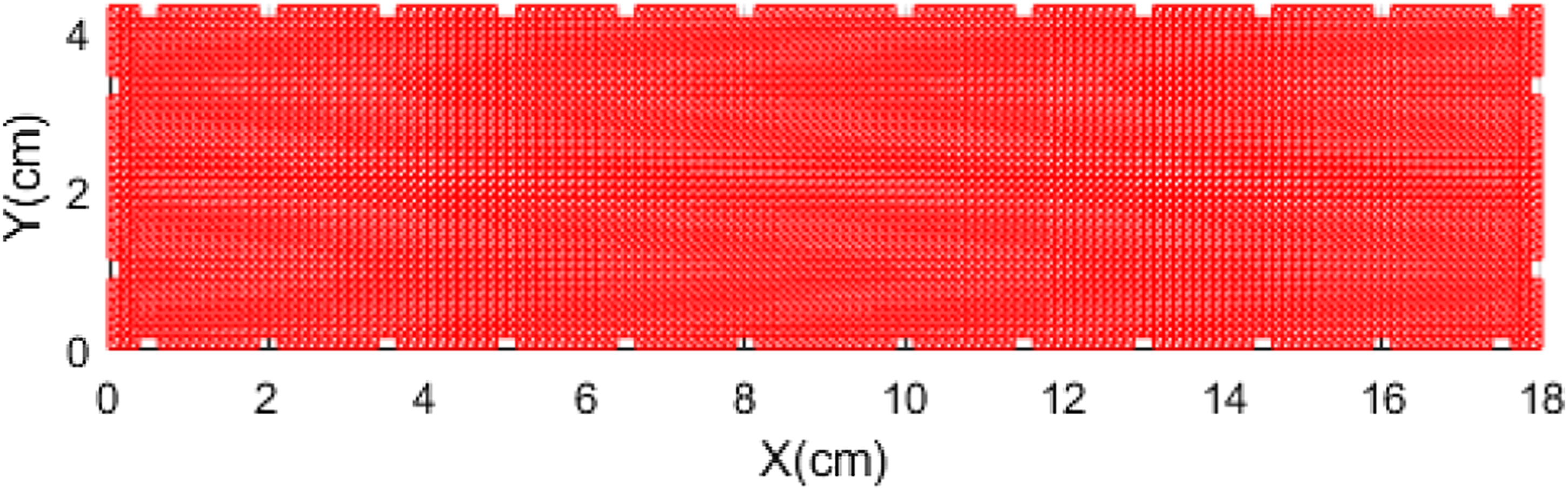
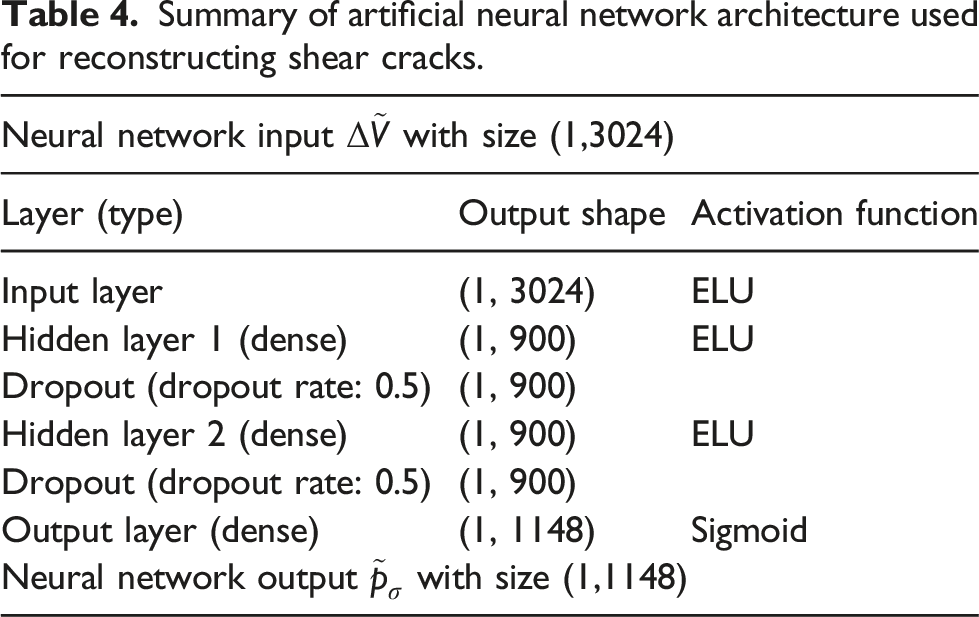
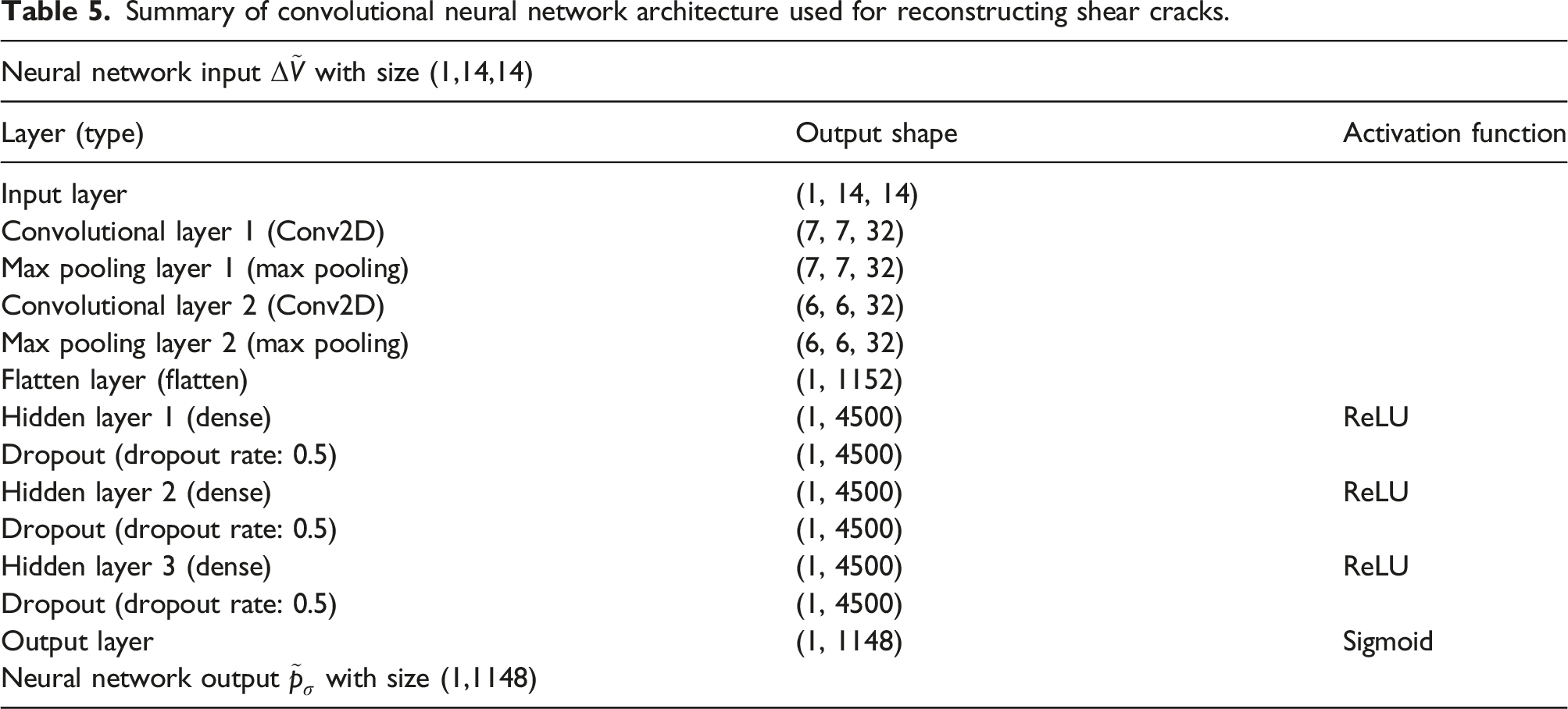
In order to simulate measurement data with the ERT forward model, we adopt opposite current injection patterns while voltage measurements were taken via adjacent electrode pairs. Each flexural crack training sample consists of 3024 voltage measurements and a corresponding conductivity vector with 5047 (nodal) entries. Downsampled flexural crack training samples consist of the same number of measurements; however, the size of conductivity vector is reduced to 915 entries using bi-linear interpolation. Similarly, shear crack training samples consist of 196 voltage measurements (which are reshaped to the 14 × 14 input size for use in CNNs). Additionally, each shear crack training sample also contains a conductivity vector having 1148 entries. Lastly, 2% Gaussian noise was added to all voltage and conductivity training data sets to improve regularization, prevent over fitting and improve network generalizability.70–72
Crack pattern generation
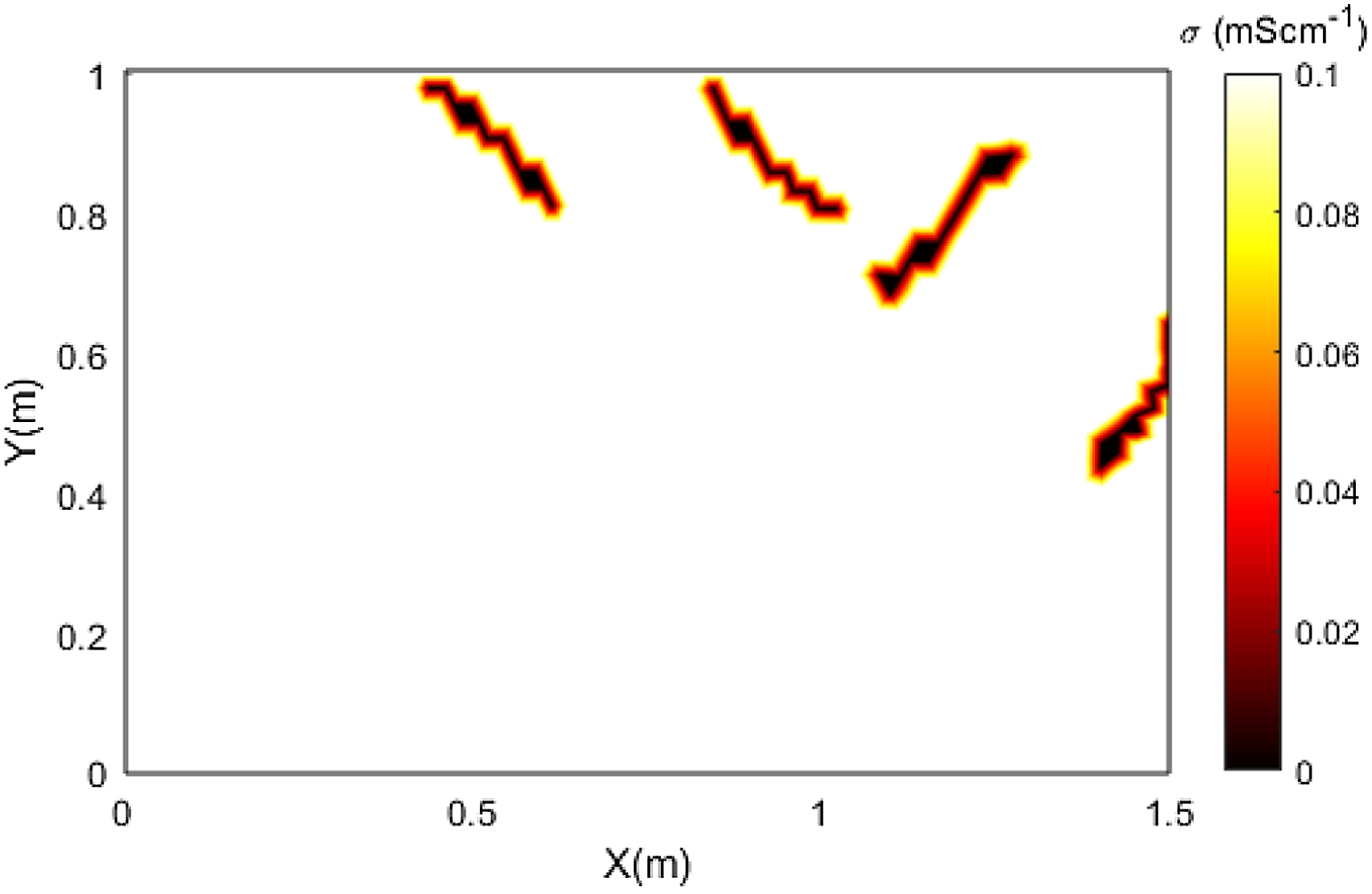
In order to train the NNs, artificial cracks need to be generated and incorporated into the training samples. For the flexural cracking training set generation, cracks were initialized at the bottom of the domain using prior knowledge of the loading and boundary conditions (i.e. three-point bending). For this, generators consisting of one or two cracks were initialized at different starting locations with various progressing directions. Cracks were simulated by random incremental steps of which the total number is randomized, leading to cracks that could reach arbitrary length within the boundary, such that a sufficient number of training samples were available. Meanwhile, shear cracks were initialized within the domain, while crack progression directions were controlled within a range of 0–45° resulting from the experimental shear testing boundary condition information. Representative internal conductivity distributions for both cracking mechanisms are shown in Figures 3 and 4. Sample conductivity distribution used in flexural cracking training data. Sample conductivity distribution used in shear cracking training data.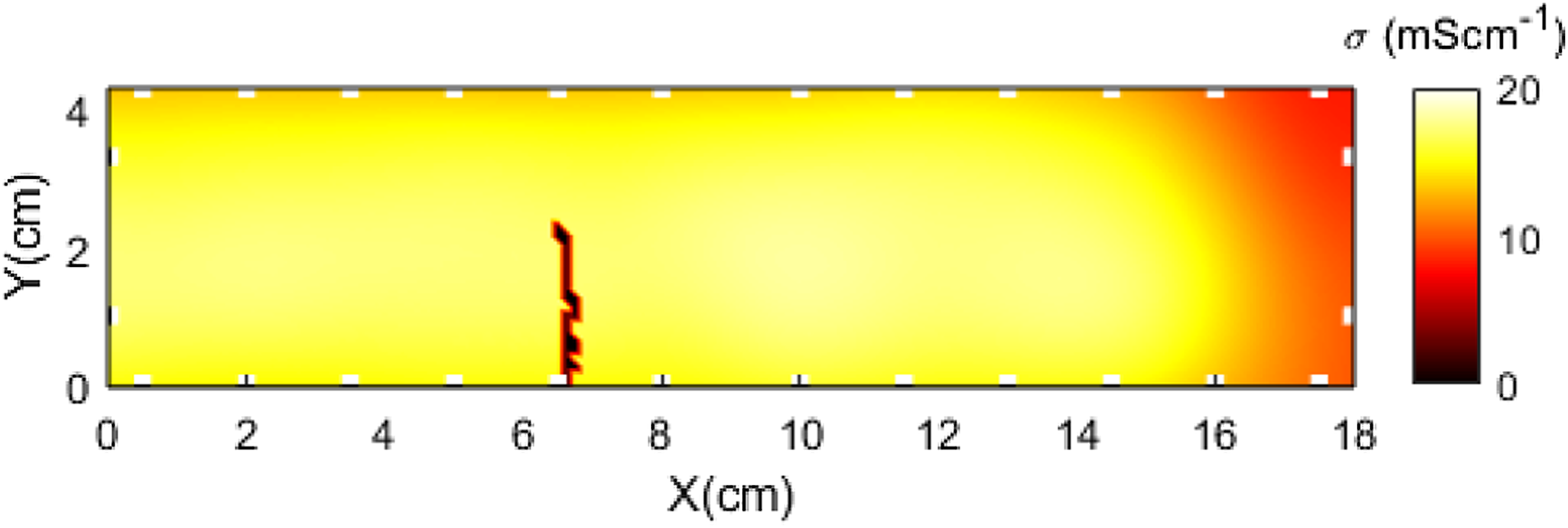
Data processing and training
As indicated previously, the aim of the network training process is to learn the nonlinear mapping between ERT difference measurements and binary crack distributions. To do this, Keras
73
is implemented in a Python environment for both generating NN architectures and training. In training an individual NN, 
Based on this information, we may now explicitly write the desired training loss function as follows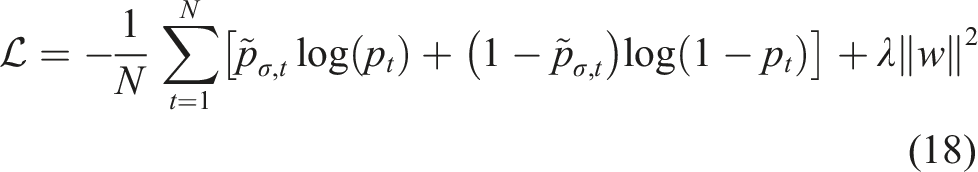
The preceding loss function minimization is augmented with a dropout rate of 50%, effectively supplementing L2 weight regularization and noise addition to data, to further improve network generalizability and prevent over fitting. 74
Regarding the generated training data, the overall dimensionality of both inputs
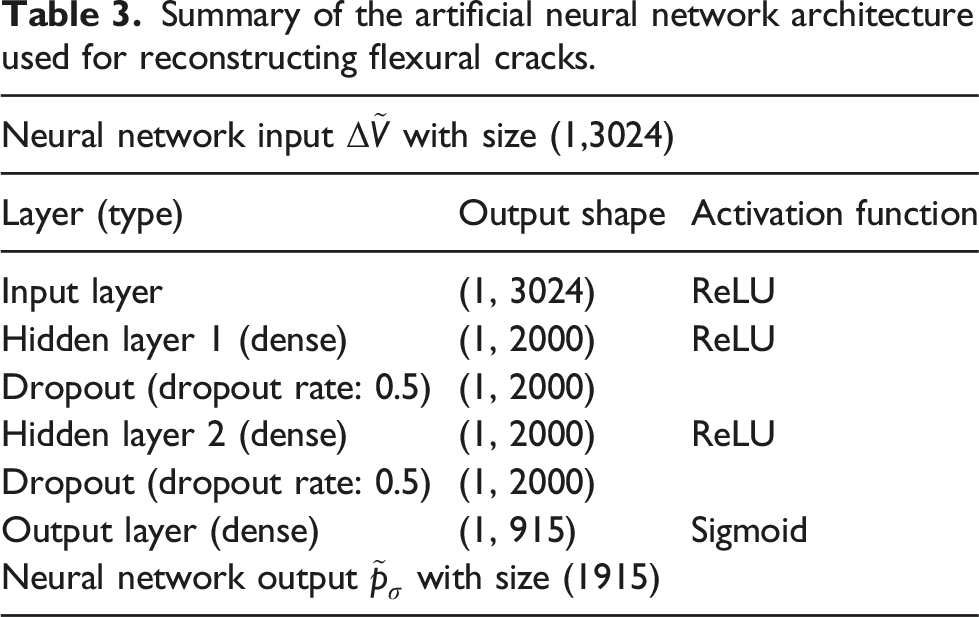
Owing to the fact that the dimensionality of Schematic trained artificial neural network architecture. Schematic trained convolutional neural network architecture.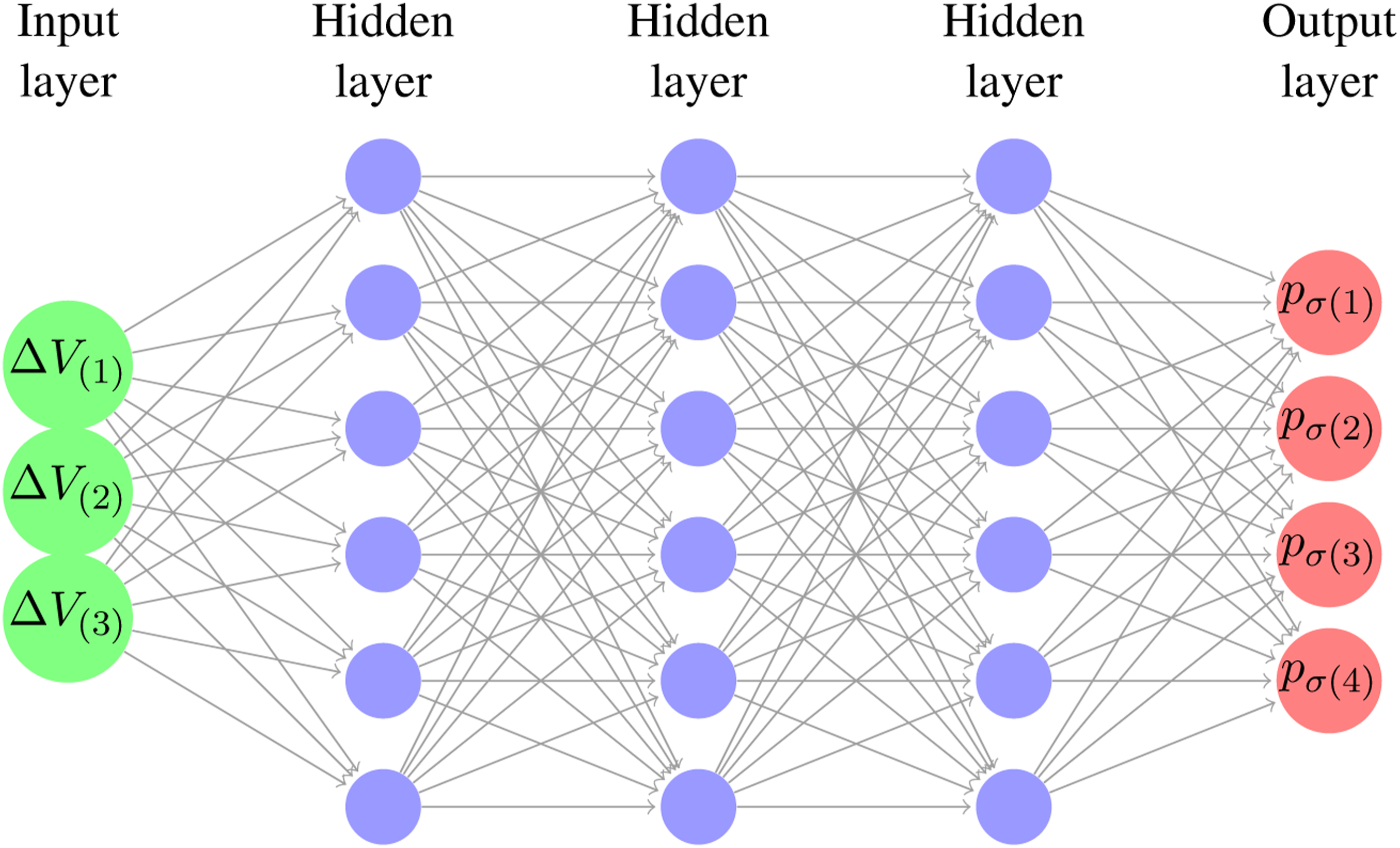
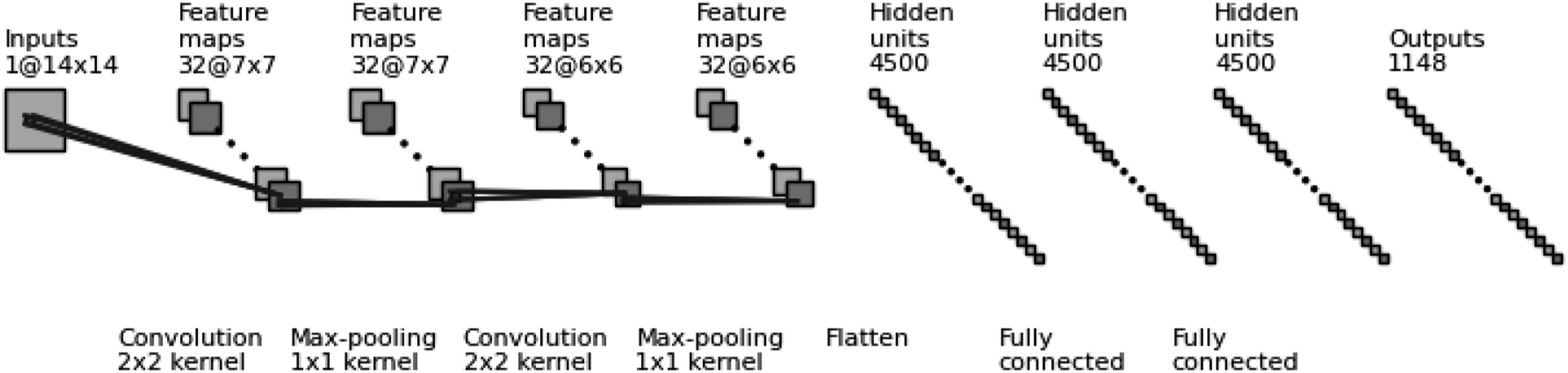
The finalized ANN architecture used for flexural crack predictions is comprised of one input layer, two hidden layers each consisting of 2000 neurons equipped with ReLU activation functions, and an output layer consistent with the number of entries in an individual sample in
Unlike in the straightforward implementation of ANNs where we map a vector to a vector, we utilize image-based CNNs. As such, we require a rectangular input; consequently, we choose to reshape the input data
Based on the former preliminary realizations, we propose and investigate an alternative approach to CNN predictions where the conductivity vector is segmented to five pieces. As a result, five different NNs are trained and developed with reduced dimensionality aiming at improving prediction accuracy for individual segments and overall domain predictions after the final assembly of segments. Another advantage of this methodology relates to regions where information is poor – especially the central region – where (a) more training samples can be added or (b) other parameters could be adjusted to improve the training performance avoiding the need to retrain a large (entire domain) CNN.
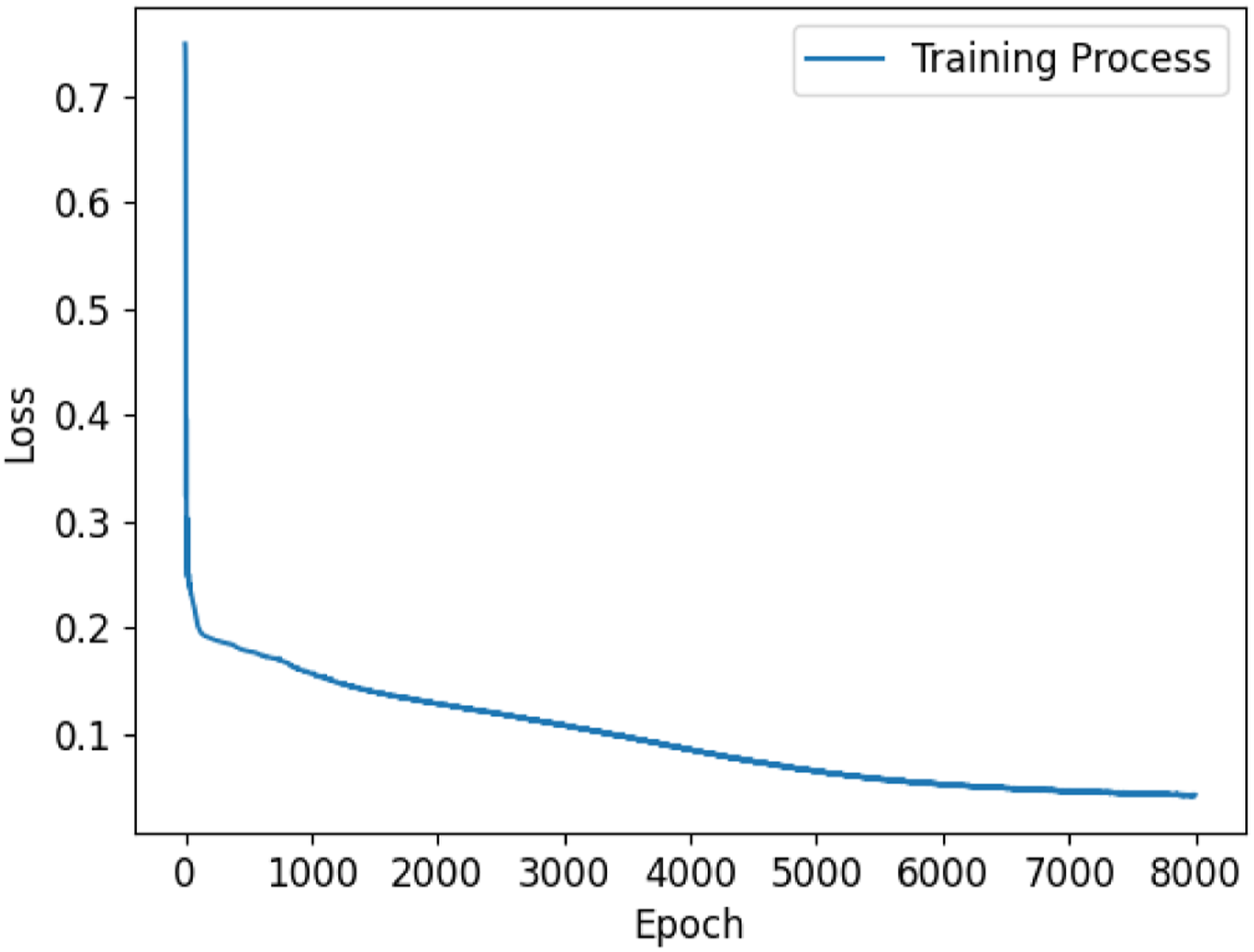
Lastly, to provide more detailed information on network training, Figures 7 and 8 show the training processes for two typical NNs. In these figures, we observe a near immediate reduction in the loss indicating rapid learning. Following this initial phase, a gradual decrease in the loss function is observed, characterized by fine-tuning of the network weights and biases. It is worth noting here that, since different network architectures and training samples are used in this work, the number of epochs varies needed to reach respective stopping criteria varies significantly. Loss function minimization for an artificial neural network used in this work. Loss function minimization for a convolutional neural network used in this work (non-segmented data).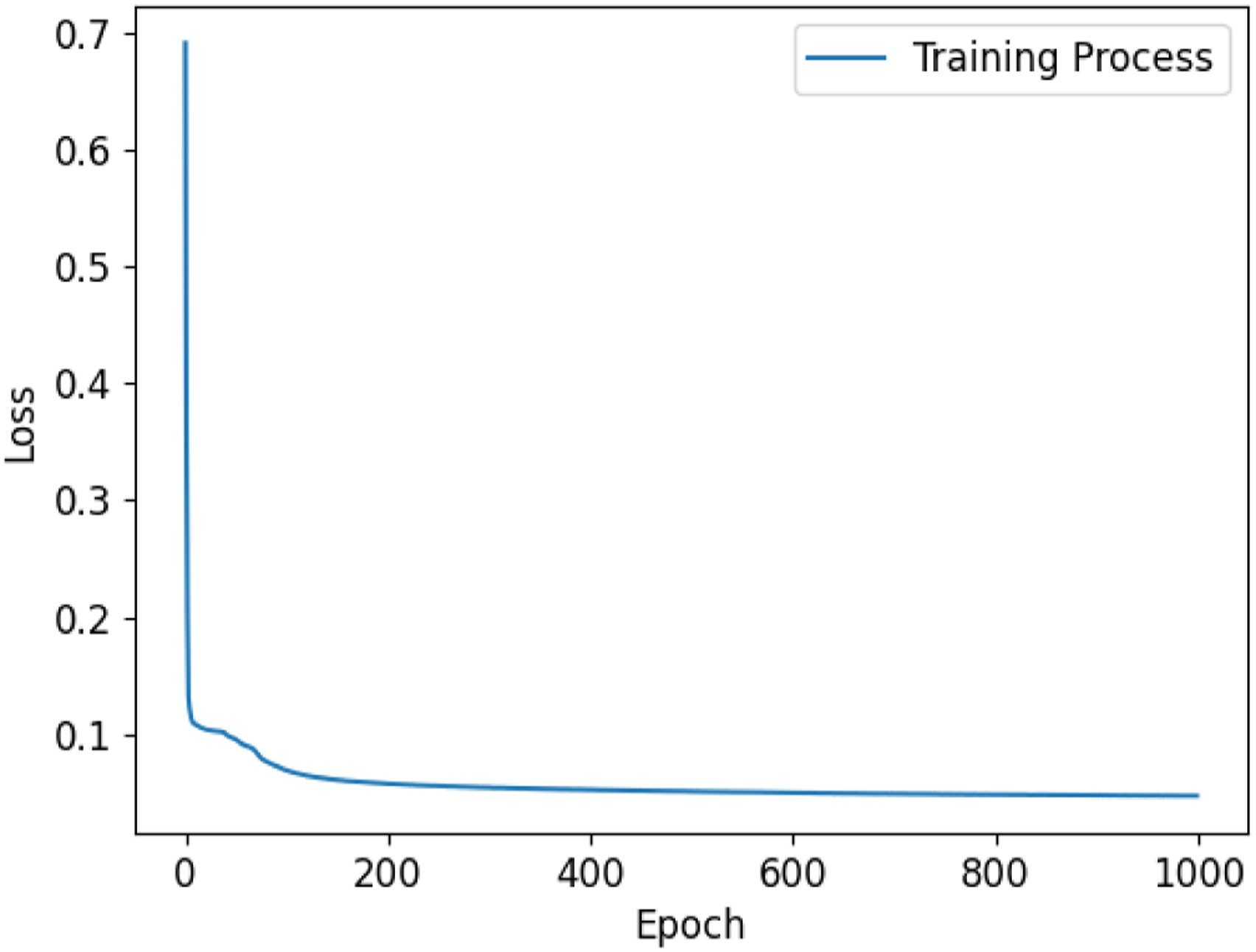
Results and discussion
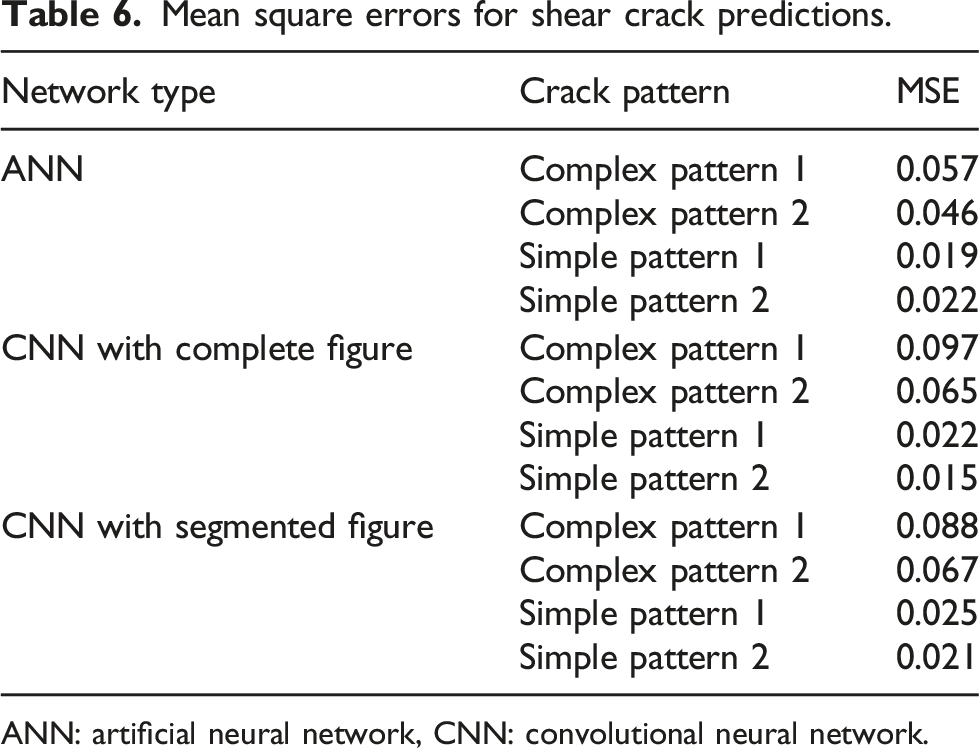
In this section, we report and discuss cracking predictions from experimental flexural and simulated shear testing campaigns. Tabulated images showing these cracking predictions are reported in Figures 9 and 10. In the spatial mappings reported, colour bars represent the probability of cracks existing at a nodal location. For the purpose of quantitative comparison, the mean square error (MSE) metric, measured between the predictive results and simulated results, for shear cracks are summarized in Table 6. In the forthcoming subsection, we will detail results for flexural testing, followed by a subsection detailing shear testing predictions, and lastly, discussion will be provided. NN predictions of experimental flexural cracking patterns. NN predictions of simulated shear cracking patterns. Mean square errors for shear crack predictions. ANN: artificial neural network, CNN: convolutional neural network.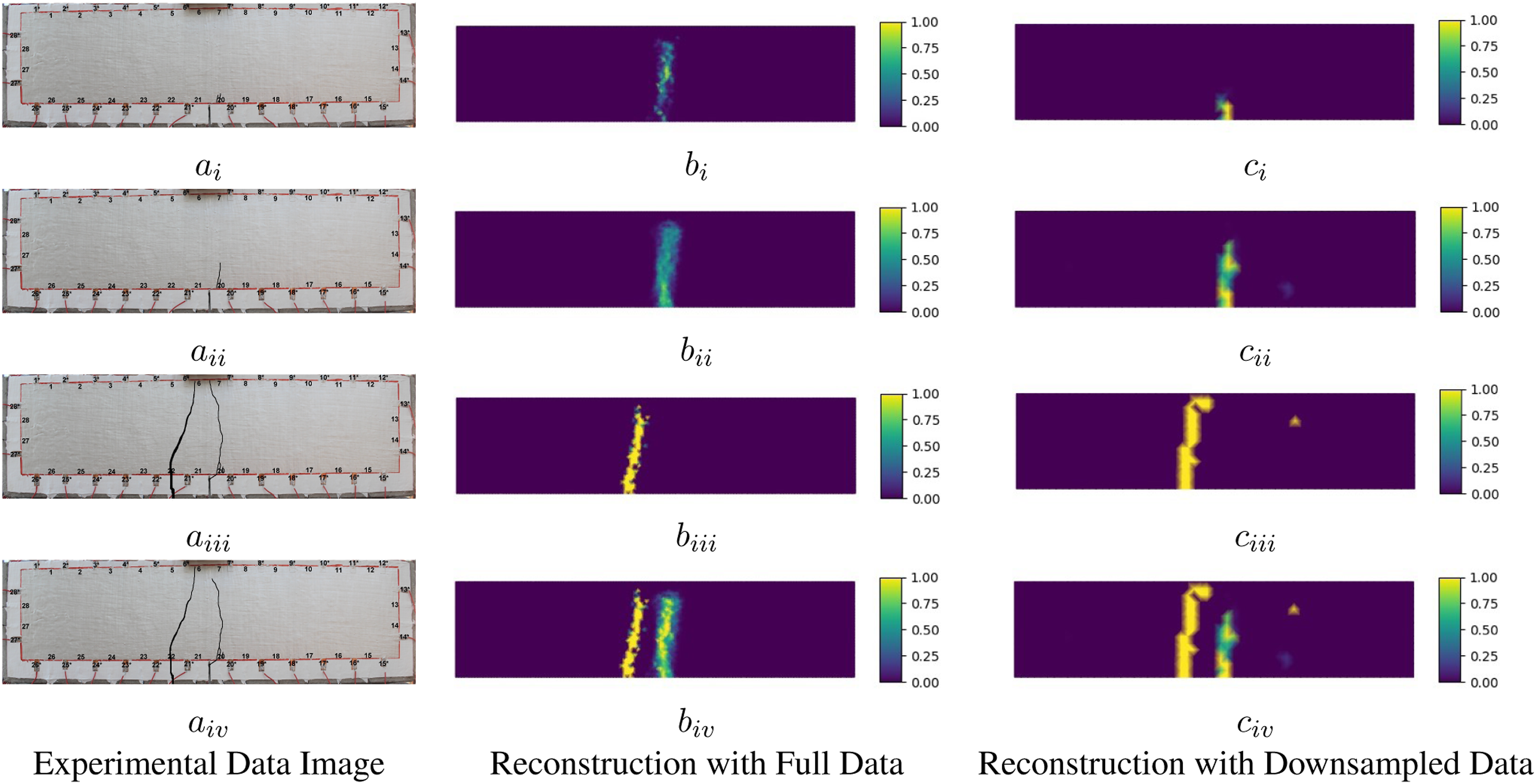
Flexural crack reconstruction
Flexural cracking predictions are shown in Figure 9 alongside experimental photographs with highlighted crack. Column a shows the experimental photographs, column b shows the crack predictions based on full conductivity sampling, and column c reports predictions using based on downsampled conductivity. Generally speaking, NN predictions correctly localize the initial crack topology (top row) in comparison to the experimental photographs as observed in a i , b i and c i . In addition, crack growth can be observed in b ii and c ii for both data types while the downsampled data prediction visually outperforms the full data prediction in terms of the actual length of the growing crack. In b iii and c iii , only a single crack can be observed, which matches the left crack shown in a iii . Further, in b iv and c iv , both the full and downsampled predictions accurately capture both cracks.
As a whole, we observe improved predictions when utilizing downsampled data. It is worth nothing, however, that this qualitative observation comes at a loss of spatial resolution in predictions p σ . It can also be observed that in predictions b iii and v iii , the reconstructions do not capture the right crack, irrespective of sampling fidelity, this drawback can be potentially explained by the presence of the left crack, which effectively shields electric fields and leads to a reduction in measurement information needed in resolving the right crack. 13 In addition, the inability to accurately predict the right crack in the third row could also be due to the relatively large width to depth ratio of this domain, where electric fields flowing horizontally are, in as rough sense, more constrained than in geometries having aspect ratios approaching 1:1. Moreover, the presence of small artifacts can be observed in c iii and c iv which result from NN predictive errors (a function of, for example, measurement noise and geometrical discretization error); however, these errors are small relative to topological crack prediction errors and do not significantly corrupt the overall assessment of crack predictions.
Shear crack reconstruction
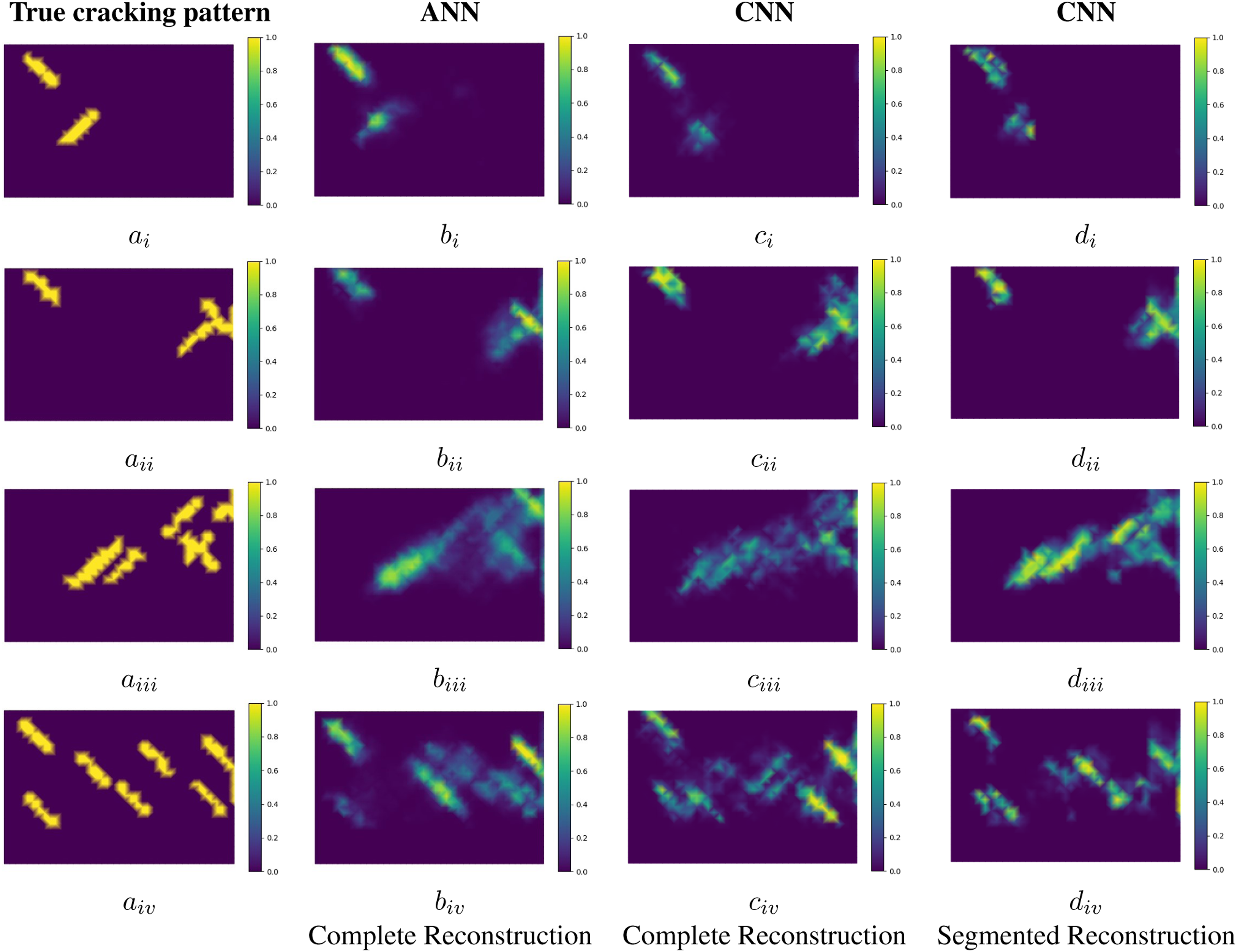
Artificial neural network and CNN shear cracking predictions based on downsampled data are reported in Figure 10. Column a shows the true cracking binary representation. Column b reports ANN predictions for the entire domain. Column c reports CNN predictions results for the entire domain. Lastly, column d reports segmented CNN predictions. In addition, consolidating five segmented networks. In total, four differing cracking patterns of increasing complexity are considered (least complexity in the top row and most complexity in the bottom row).
Generally speaking, for simple crack patterns (i.e. the first and second rows), both the ANNs and CNNs provide valid predictions in terms of crack lengths and locations. However, when observed in closer detail, the ANN visually outperforms the CNN predictions slightly as in b i and b ii where the length of cracks are more accurately predicted. For more complex crack patterns (i.e. the third and fourth rows), all NN cracking predictions are satisfactory near the domain boundaries. On the other hand, near the centre of the domains (the area of least sensitivity), CNNs appear to localize and separate complex cracks better than ANNs as observed from c iii , d iii c iv and d iv . Furthermore, segmented CNN predictions consistently show improved qualitative results in comparison to the conventional CNN network.
In totality, both the ANNs and CNNs predict less accurately towards the central region of the domain relative to the boundary. This is likely caused by the diffusive nature of electricity and is also a common feature of ERT. 39 However, despite the generally better qualitative results predicted by CNNs, we require a quantitative metric to more closely assess predictions. For this, we utilize the MSE metric, effectively comparing true and predicted images; these metrics are reported in Table 6.
In contrast to visual observations, assessment of MSEs reported in Table 6 indicates that ANNs generally perform quantitatively slightly better than CNNs – with the notable exception of one cracking pattern. This could potentially be due to fact that the CNNs’ architecture and data processing add additional nonlinearity in the training and prediction process. While this initially seems counterintuitive, as CNNs are commonly regarded as more powerful predictive tools than ANNs, additional discussion is required to attain a more full picture of the realizations made in this subsection. Such discussion will be provided henceforth.
Discussion
The feasibility of NNs for probabilistically predicting cracking patterns was qualitatively and quantitatively affirmed in the preceding subsections using experimental and simulated data. Generally speaking, the networks were able to localize binary crack representations with regional certainty exceeding 50% – with the notable exception of cases where measurement quality was impeded by crack shielding. As alluded to, the use of NNs for predicting cracks using boundary voltage measurements is analogous to ERT, with the caveat that the learned methodology proposed herein predicts binary cracking representations rather than reconstructing continuous conductivity distributions. Interestingly, the proposed NN crack prediction framework also exhibits similar susceptibilities present in ERT; the primary weaknesses include (a) insensitivity to the central region of the prediction domain and (b) low spatial resolution. Conversely, and again similar to ERT, the NN prediction framework also has analogous advantages including (i) high sensitivity near the boundaries and high temporal resolution. In contrast to ERT, however, the NN prediction framework enables substantial computational speedups and simpler representation of cracking topology relative to conventional ERT.
Despite the noted advantages, two observations made in the results subsections remain yet to be explained. Realizations from these observations have key implications on the potential use of predictive networks for probabilistic crack assessment in future work. Firstly, the use of spatial downsampling proved highly effective and generally improved prediction quality. Secondly, the use of CNNs, commonly considered a more powerful classification network, only outperformed ANNs in one case considered.
In response to the first observation, we need to first investigate the general structure of input and output data sets used herein. We note that, when binary crack representation data (output) are not downsampled, the output dimensionality is an order of magnitude larger than input measurement data. As such, information stemming from measurements is significantly diffused and stretched before reaching the outputs. This is similar to the process of decoding, that is, mapping low dimensional information to high dimensional information, as commonly adopted in autoencoder applications.75,76 A primary challenge presented in the decoding process lies in the preservation of information transferred from input to output. Potential for corruption in decoding, however, can be reduced by optimizing the NN architecture and decreasing discrepancy between input/output data size. Regarding the latter, downsampling of the outputs (as used herein) is an effective method for matching data sizing discrepancies and therefore underscores the effectiveness of downsampling in crack prediction quality observed.
Responding to the second observation, regarding the reduced effectiveness of CNN cracking predictions in comparison to those of ANNs, we would like to remark that this was an unexpected result. Nowadays, applications of CNNs range from image processing to inverse problems. Recent scholarly work has even investigated the ‘unreasonable effectiveness of CNNs’. 77 Yet, like many machine learning tools, the use of specific architectures and data processing techniques should be considered with respect to the application and underlying data structure(s).
In this work, the input data (potential differences) may have a positive or negative sign and the magnitude can vary significantly, depending on the cracking pattern, domain geometry, electrode configuration, and measurement/stimulation protocol. In turn, reshaping such data into a rectangular ‘voltage image’ unquestionably represents a much more complex data structure than if it were, for example, a black and white image consisting of positive integer values ranging from 0 to 255. Therefore, the use of convolutional operations in comparison to feed-forward (ANN) operations may not be ideal in many cases. Such a realization may contribute to the fact that CNNs performed less favourably than ANNs in predicting all but one cracking representation.
The former deduction is not a general conclusion of this work, however, as CNNs (and fully connected networks) offer opportunities for deeper data representation. For example, derivative operations have equivalencies to convolution operations78,79 meaning that higher order data representations are possible using CNNs. Therefore, the use of deeper non-fully connected networks highly tailored to data and prediction may, in eventuality, lead to substantially improved predictions of cracking representations than those reported herein, and this is the source of ongoing research.
Conclusions
In this article, fast neural network–driven direct inversion frameworks were proposed to predict binary cracking distributions in concrete elements. The aim of the proposed framework was to map boundary electrical measurements to probabilistic binary crack distributions. The purpose for choosing a binary cracking representation was to simplify the interpretability of damage predictions. To test the feasibility of the approach, experimental flexural cracking representations were successfully predicted with using ANNs. To facilitate quantitative evaluation of networks’ efficacy, simulated shear cracking representations were predicted using ANNs and CNNs. Simulation results generally indicated that ANNs slightly outperformed CNNs quantitatively, while both architectures showed the potential to accurately reconstruct simple and complex crack patterns. In summary, the feasibility of the proposed learned frameworks was affirmed and discussion was provided to offer guidance on the potential for improving network predictions.
Footnotes
Acknowledgements
DS thanks Professor Moe Pour-Ghaz (North Carolina State University), Professor Aku Seppänen (University of Eastern Finland) and Dr Milad Hallaji (Fernandez & Associates) for providing experimental data.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: DS was supported by Engineering and Physical Sciences Research Council Project EP/V007025/1. DL was supported by the National Natural Science Foundation of China under Grant 61871356.