
Abstract
This article presents a novel transfer learning approach for evaluating structural conditions of rail in a progressive manner, by using acoustic emission monitoring data and knowledge transferred from an acoustic-related database. Specifically, the low-level layers of a model pre-trained on large audio data are leveraged in our model for feature extraction. Compared with conventional transfer learning approaches that transfer knowledge from models pre-trained on normal images, the proposed approach can handle acoustic emission spectrograms more naturally in terms of both data inner properties and the way of data intaking. The training and testing data used for rail condition evaluation contains two months of acoustic emission recordings, which were acquired from an in situ operating rail turnout with an integrated acoustic emission –based monitoring system. Results show that the evolving stages of rail from intact to critically cracked are successfully revealed using the proposed approach with excellent prediction accuracy and high computation efficiency. More importantly, the study quantitatively shows that audio source data are more relevant to the acoustic emission monitoring data than Image data, by introducing a maximum mean discrepancy metric, and the transfer learning model with smaller maximum mean discrepancy does lead to better performance. As a by-product of the study, it has also been found that the features extracted by the proposed transfer learning model (“bottleneck” features) already exhibit a clustering trend corresponding to the evolving stages of rail conditions even in the training process before any label is annotated, indicating the potential unsupervised learning capability of the proposed approach. Through the study, it is suggested that selecting source data more correspondingly and flexibly would maximize the benefit of transfer learning in structural health monitoring area when facing heterogenous monitoring data under varying practical scenarios.
Keywords
Introduction
Acoustic emission (AE) is the radiation of acoustic (elastic) waves in solids and occurs when a material undergoes irreversible changes in its internal structure, such as crack expansion or plastic deformation due to aging, temperature gradients, or external mechanical forces. In addition, some other processes that are reversible, such as friction and impact, can also emit AE. Structural changes subject to mechanical loadings are localized sources of elastic waves, which are generated when the accumulated elastic energy reaches the threshold and is rapidly released. Based on this principle, AE-based techniques have been used in various scenarios from locating the event source to evaluating the inner conditions of structures. 1
In railway systems, non-destructive evaluation (NDE) techniques, such as eddy current detection, 2 magnetic induction tests, 3 ultrasonic tests,4,5 guided wave detection,6–8 non-contact ultrasonic inspection,9,10 and alternating current field measurement, 11 are extensively used for regular inspection. Most NDE techniques have to be conducted offline to avoid interrupting normal rail service while getting to know the real-time conditions of rail infrastructure is one of the top concerns among rail operators and researchers. There are also some methods that utilize axle box accelerations from onboard monitoring systems to identify singular track defects such as squarts 12 and bolt tightness of fish-plated joints 13 or to detect rail corrugation. 14 Although these methods can cover a long distance, there may be a long interval between the inspections for a specific location. In contrast, AE-based techniques, as a type of passive inspection methods, enable online monitoring of rail conditions by capturing the sudden energy release due to wheel–rail interactions or crack expansion in rail tracks.15–17 The applicability of AE for online monitoring of rail crack progression was demonstrated in laboratory tests on rail segments carried out under normal load. 18 In previous research work done by the authors, an AE-based online monitoring system had been developed for rail turnout crack detection. Pilot lab investigations and test line experiments proved the effectiveness of the system in detecting AE bursts generated from abrupt crack expansion. 19 The system was then implemented in an operating freight line and had been taking AE recordings over a long period. However, unlike results from the lab environment, the AE signals acquired under in situ circumstances are often accompanied by other signals including mechanical vibrations and broadband noises induced by intense wheel–rail interactions (especially wheel–rail creepage). These vibrations and noises obscure the crack-induced AE signatures of interest. As demonstrated in authors’ previous research work, for damage detection purpose, conventional time–frequency methods (e.g. power spectrum density (PSD) analysis, wavelet analysis) are able to identify large rail cracks before fractures at the point rail;19,20 while detection of smaller cracks or damages may refer to a frequency domain Structural Health Index (SHI) updated under a Bayesian framework. 21 However, beyond damage detection, rail operators are keener on the condition evolvement of rail structures over a period of time before significant cracks literally take place, but both methods cannot well reveal the structural health conditions of rail tracks in a progressive manner using the AE data and are not sensitive enough to identify the early stages of rail deterioration when micro cracks are initializing. Yet, micro fatigue cracks or subtle structural changes at early stages would also generate tiny AE bursts subject to train impacts, and implicitly influence the time–frequency spectrogram with hidden features. However, AE bursts are distributed in a wide frequency band depending on different sizes, orientations, and distributions of the early-stage micro cracks as well as different rail operating environment. Therefore, the optimal damage-sensitive features can be varying from case to case and it is often time-consuming to manually extract the optimal one. In light of this, advancement from semi-auto damage detection to automatic online condition evaluation is one target of this study, and deep learning (DL), in this sense, would be a promising option to adaptively find out the features and realize the target.
DL models learn nonlinear representations that disentangle different underlying factors of variation.22,23 Conventional methods requiring manually analyzing signals or proposing health-relevant features. For example, component analysis was performed to extract AE features, which were then fed to a multi-class relevance vector machine to extract and identify various types of defect bearings. 24 The study in Pandya et al. 25 manually extracted statistical and acoustic features by Hilbert–Huang transform and then used K-nearest neighbor algorithm to classify five bearing conditions. In comparison, DL can directly map the acquired raw data to the targets, and thus prevent subjective judgments or labor-intensive feature handcrafting. Thus, DL-based approaches have been gradually introduced to structural health monitoring (SHM) in recent years.26,27 Among the DL models, convolutional neural networks (CNNs), through the hierarchical architecture consisting of multiple convolutional and pooling layers, are able to capture robust representations of a given image. 28 For audio data, CNNs also exhibit their capability of digging out suitable salient features that typically outperform handcrafted features in a variety of scenarios including acoustic event detection 29 and music onset detection. 30 It is also possible to diagnose faults of roller bearings using acoustic recordings and CNN model. 31 The good performance of CNNs in audio recognition promotes their application in AE-based monitoring. For fault diagnosis of mechanical systems, the diagnostic accuracy can be enhanced by fusing the vibration signals with AE signals 32 and integrating CNNs with another kind of network. 33 For plate-like structures, the reflections and reverberations generated by irregular geometric features may hinder the performance of AE source location. This drawback was overcome by some recent work in the study by Ebrahimkhanlou and colleagues34,35 that leveraged the power of DL (specifically, stacked autoencoders) of capturing complex patterns. Regarding the monitoring of railway systems, a CNN model was formulated to classify the rail state based on the AE signals collected by tensile testing machines, which involved the probability analysis of multiple AE events to improve the classification performance. 36 CNNs were also used to identify three mechanisms that induce AE in the railway field: operational noise, impact, and crack propagation. 37 Bayesian optimization was utilized to tune the hyper-parameters and transfer learning (TL) was involved to improve efficiency.
DL relies on large datasets to discover the complex relationship between the raw data and the desired output. 22 However, the amount of monitoring data collected from engineering field scenarios, for example., AE data from the rail turnout in this study, is often relatively limited (normally hundreds or thousands of data sequences) and not sufficiently “large” for a “deep” learning process. For example, the study by Li et al. 37 had to mix up both field and lab data to handle the data insufficiency of crack propagation-induced AE waves. When the signature of interest caused by structural damage is altered, the DL model may suffer from the overfitting issue and fail to separate factors of variation. This issue is particularly obvious and tricky for rail circumstances where the structural and operating conditions are remarkably different under various open environment. To compensate for the data insufficiency, there has been some limited but pioneering research work in DL-based SHM by introducing TL as a novel improvement of conventional DL methods that learn from scratch. For a typical CNN structure, the low-level layers trained on a large database (e.g. ImageNet) have learned to extract low-level features such as edges, corners, and shapes, which can be shared across tasks. 38 Therefore, they can be frozen and transferred to a new model and only the high-level layers need to be fine-tuned using the data of interest. In this way, sufficient data can be guaranteed for new model training, and the training process is dramatically accelerated. Specifically, for civil infrastructures, a pioneering study has been conducted on TL-aided SHM, 39 in which a relatively small number of images (2000) about structural damages were available. The low-level layers of VGGNet, 40 which had been pre-trained on a large-scale off-the-shelf dataset named ImageNet 41 containing more than 1000 types of objects, were utilized for extracting features from structural damage images for four structural damage recognition tasks: component type identification, spalling condition check, crack level evaluation, and damage type determination. In a population-based SHM scenario, 42 three kinds of TL approaches were used so that models trained on the labeled feature data obtained from one structure can be applied to the unlabeled data of a different structure.
For AE-based SHM cases, there has been a very recent work that utilizes TL. 37 This study leverages the low-level layers of a model pre-trained on images (Alexnet) to extract features from the time–frequency wavelet spectrograms. This practice, however, has one limitation: AE spectrograms (in target domain) and natural images (in source domain) are not analogous to each other in nature. An AE spectrogram is the time–frequency representation of acoustic waves and not necessarily exhibits edges, corners, or shapes, which appear in an image presenting the spatial distribution of electromagnetic wave frequency. Thus, it is crude and questionable to utilize image-oriented models for spectrograms of AE. The data insufficiency issue mentioned in the previous paragraph could have been overcome if a more reasonable source domain was selected. After all, when the source domain and target domain are more related, less amount of data are required and fewer layers need to be fine-tuned. 28 In contrast, each crack-induced AE burst can be considered as an acoustic event and a segment of online audio recording also contains one or multiple acoustic events. Thus, online audio databases that contain various kinds of sound events can be a good alternative source, based on which our “acoustic-homologous” approach is proposed. This is the second and core objective of the study.
This article presents a TL approach to evaluate the rail condition in a progressive manner with AE monitoring data and a large-scale online audio database AudioSet. The AE monitoring data were acquired by an AE-based monitoring system previously developed by the authors and implemented on an operating rail freight line. The low-level layers of the CNN model leverage knowledge transferred from AudioSet, and the remaining layers of the model are trained on AE monitoring data for condition assessment of the rail structure. To the authors’ knowledge, it is for the first time pre-trained model from audio database rather than image database is adopted to more precisely extract the acoustic-specific features of our AE monitoring data. Furthermore, a maximum mean discrepancy (MMD) metric is introduced to quantitatively measure the relevancy between different source data (AudioSet, ImageNet) and target data. The effectiveness of the proposed approach is demonstrated by comparing the performance of the developed network (NA-AE) with two baselines: one network (NI-AE) relies on the knowledge from ImageNet in VGGNet, another network (NAE) is learned from scratch without the involvement of TL. This study stresses the importance of data source selection correspondingly in TL-aided SHM, which can be highly beneficial when facing various types of SHM data.
The organization of this article is as follows: The section “TL and MMD” briefly introduces the basic principles of TL and the concept of MMD; the section “In-situ AE-based monitoring system” describes in detail the in situ AE-based monitoring system and AE monitoring data used for this study; the section “Methodologies” presents the detailed procedures of the proposed approach and the methodologies to validate its effectiveness; the section “Results and discussion” demonstrates and discusses the results; and the section “Conclusion and future work” summarizes the article with conclusions and future work.
TL and MMD
This section introduces the basic principles of TL and the concept of MMD in the context of supervised DL. Given a dataset
Unlike conventional machine learning (ML) approaches that require preliminary hand-crafting features from x, DL models can directly map the acquired data x in its raw form to the desired output y. 22 The process of feature extraction is embedded in the model. A typical DL model, such as a CNN, consists of a series of layers. Each layer intakes the output of its previous layer, conducts some operations and outputs the features. Each output is a more abstract representation of the original input. It should be noted that lower the level of a layer, less task-specific it is. 28 For example, the low-level layers in a CNN can only detect edges and corners in an image, while the high-level layers can output the feature maps that indicate the existence and location of shapes or objects. This finding motives the application of TL in DL applications to increase efficiency and prevent overfitting.
Technically, there has been some knowledge learned from the source domain
The feature extractor can be approximately shared as long as the
Basically, MMD is a concept in functional analysis defined by the distance between Kernel embedding of two distributions in the reproducing kernel Hilbert space (RKHS)
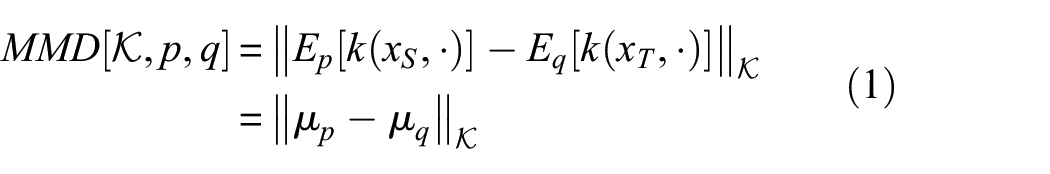
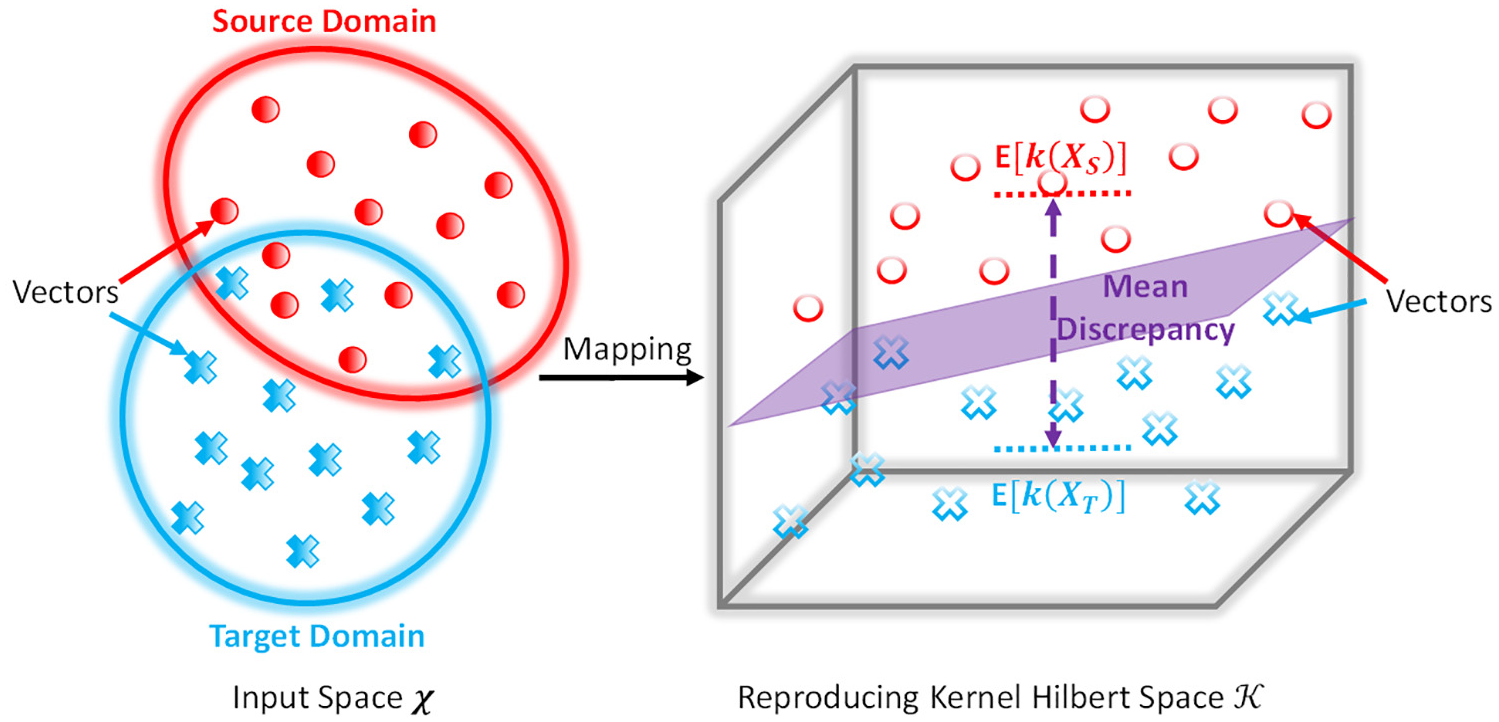
Mean discrepancy between source domain and target domain.
The inner products of embedding samples can be simply calculated by the kernel trick
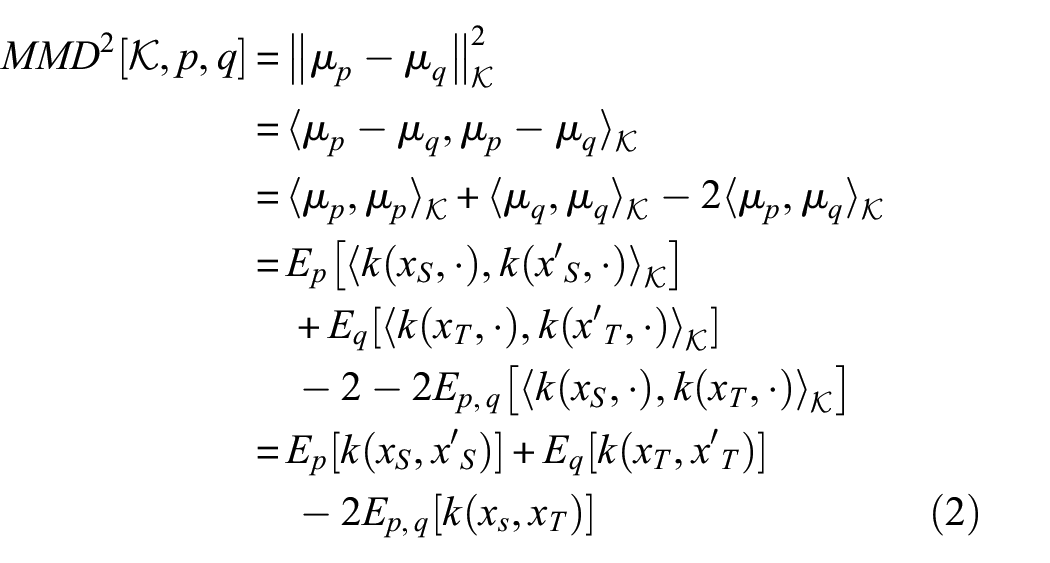
Finally, the empirical estimate based on
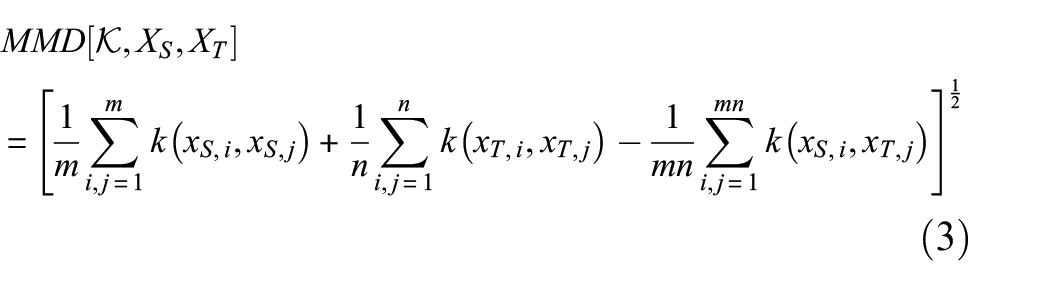
As a non-parametric estimate, MMD does not require an intermediate density estimate, unlike other metrics such as the Kullback–Leibler (KL) divergence. Besides, KL divergence is mainly used to determine information loss rather than discrepancy. To map the terms of TL and MMD into the AE-based SHM case of this study,
In-situ AE-based monitoring system
Monitoring system
An AE-based monitoring system was previously developed by the authors19,21,49 for online rail turnout crack detection. The system includes a set of encapsulated piezoelectric (PZT) sensors, a four-channel National Instrument 9223 Pickering card (1 MHz sampling rate) that is able to collect data from four sensors simultaneously, and a computer for data storage. Specific parameters of the PZT sensors are displayed in Table 1. The schematic of the system can be seen in Figure 2, and the collected data were eventually stored in the database located in the control room near the rail turnout area for further analysis.
Parameters of the PZT sensors.

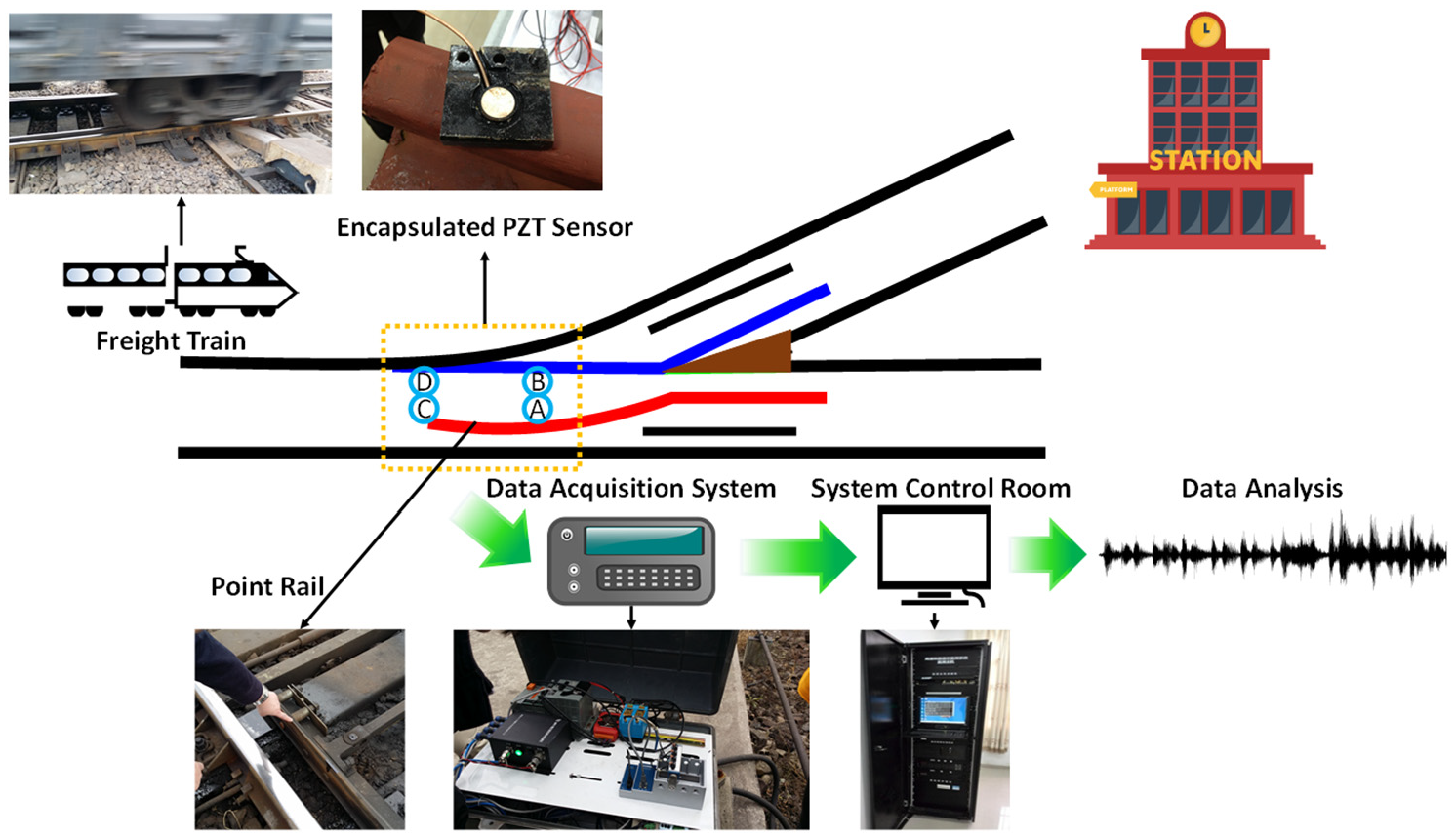
The AE-based monitoring system for rail turnout crack detection.
The system was initially deployed at a rail turnout area of an in-service freight line near a freight station in mainland China. According to reports from the partner rail operators, the point rails on the two sides are most vulnerable to damages due to the irregular rail profile, frequent switching, and constant impacts from freight trains. In recognition of this, four PZT sensors were mounted at the rail foot of the point rails on the inbound route (two sensors numbered as A and C on the left rail and two sensors numbered as B and D on the right rail), as shown in Figure 3, covering a 10 m monitoring area. When any train passes through the monitored rail turnout area, the data acquisition component would be triggered and start taking measurements for 8 s adequate to record full responses induced by a common eight-cargo freight train that normally passes at a speed of around 20–40 km/h within the station’s nearby area. It has been investigated in the pilot study that the acoustic burst frequency caused by rail crack expansion mostly lies in a range from ultrasonic frequency (20 kHz) to 140 kHz, 19 and the sampling rate is set to be 600 kHz to fully capture the frequency range of interest. The monitoring system was in-service for three years taking acoustic recordings intermittently. Despite the large number of data points (4.8 million) in every 8 s recording, it should be noted that each recording is treated as one sample for DL, and thus the number of samples is relatively small due to the trigger-measure mechanism. Passing locomotives are either multiple-cargo freight trains (in normal operation hours) or one-cargo train (in rail shunting period). Typical recordings triggered by one-cargo train and multiple-cargo train is shown in Figure 4. It can be observed from Figure 4 that in one single recording, each passing cargo induced significant and relevant vibrations and noises, manifested as acoustic peaks with amplitude ranging from 0.4 to 15 V. While according to our pilot lab testing, the acoustic peaks excited by crack expansion are often relatively small, obscured by wheel–rail interaction-induced waveforms in the time domain.

Sensor implementation position at rail turnout area.
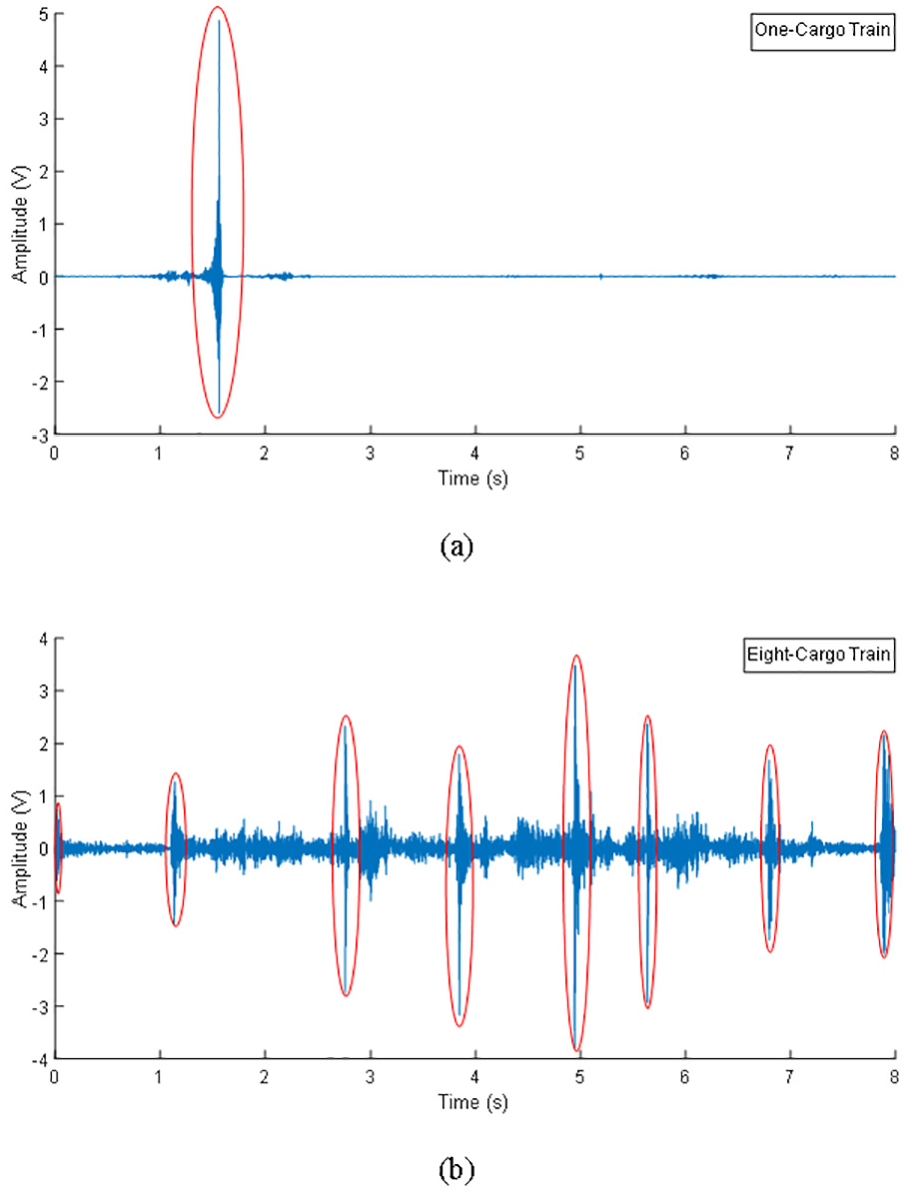
AE recordings triggered by (a) one-cargo train and (b) eight-cargo train.
Data description
A significant crack at the railhead of the right point rail corresponding to the inbound direction was spotted in mid-November 2014 by manual detection (Figure 5). The crack occurred 2 m away from sensor C but was missed by the monitoring system. The point rail was confirmed by our partner rail operator to be intact before early October. Therefore, the data recorded from September to November 2014 was used in this study covering a continuous deterioration period of the point rail from intact to cracked. When the rail was intact, no AE induced by crack expansion can be measured. When microcrack had initialized, it would increase in size every time a freight train passed by and generated AE burst hidden in the strong background noises. The pattern of the burst, in turn, reflected its current condition. This is the basic assumption of monitoring turnout crack based on AE techniques. To reveal the progressing crack, we divided the crack growing period into several stages. The dataset is divided into four stages: Stage I-intact, Stage II, Stage III, and Stage IV-significantly cracked. This four-stage option is a balance between sufficiency and necessity in proving the concept. According to the mechanism of fatigue growth, a typical rail crack growing under heavy freight loading condition where the crack growth rate is increasing with respect to time,50–54 the period of each stage should be decreasing, as schematically shown in Figure 6. Therefore, 1-month AE recordings (3524 samples) were used as Stage I data, 2-week recordings as Stage II data (946 samples), 1-week recordings (482 samples) as Stage III data, and 4-day recordings (584 samples) as Stage IV data. Time gaps are reserved between neighboring stages of data selection to guarantee distinction, and more recordings were chosen in Stage IV for better training performance. Figure 7 demonstrates the AE recordings of rail under four stages and the PSDs of these signals are shown in Figure 8, focusing on the frequency interval between 20 and 140 kHz. It should be noted that Figures 7 and 8 are just samples grabbed from the dataset for demonstration and we do not expect to directly observe the pattern that can reflect the crack progress in either time domain or frequency domain.

The rail with significant crack.
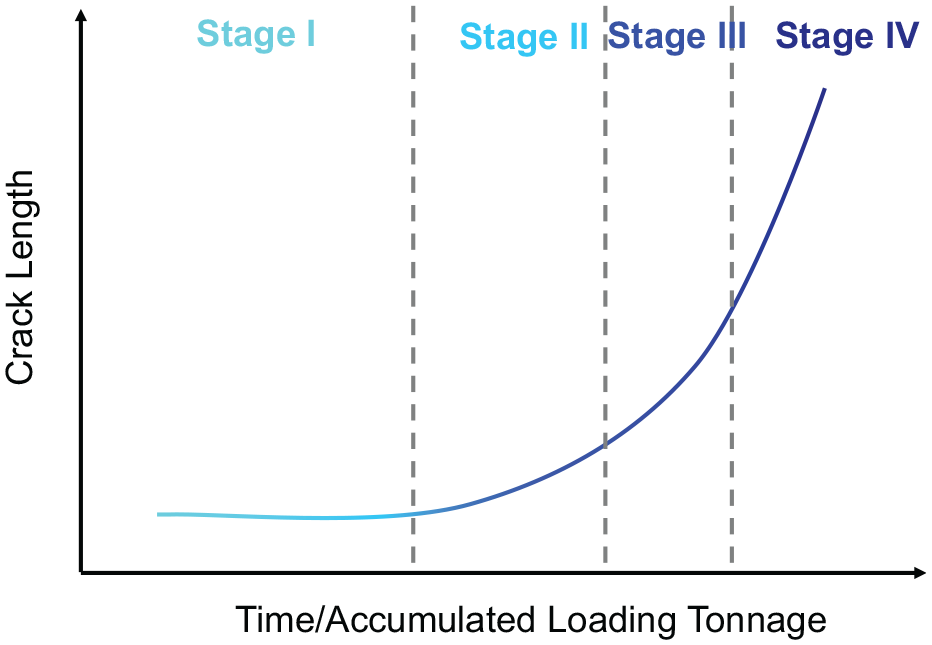
Progress of rail crack and stage classification.
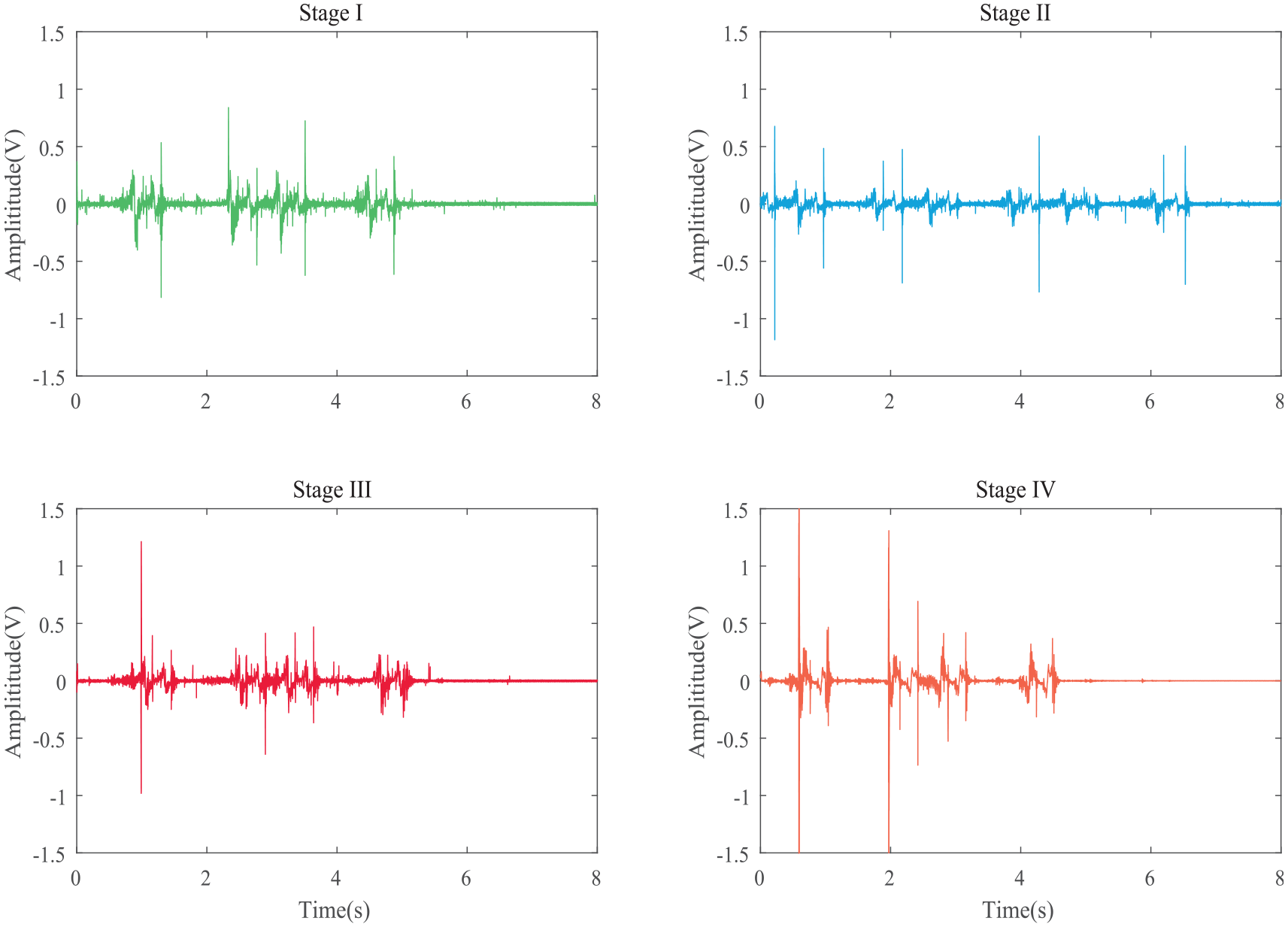
AE recordings of rail under four stages subject to impact of eight-cargo trains.
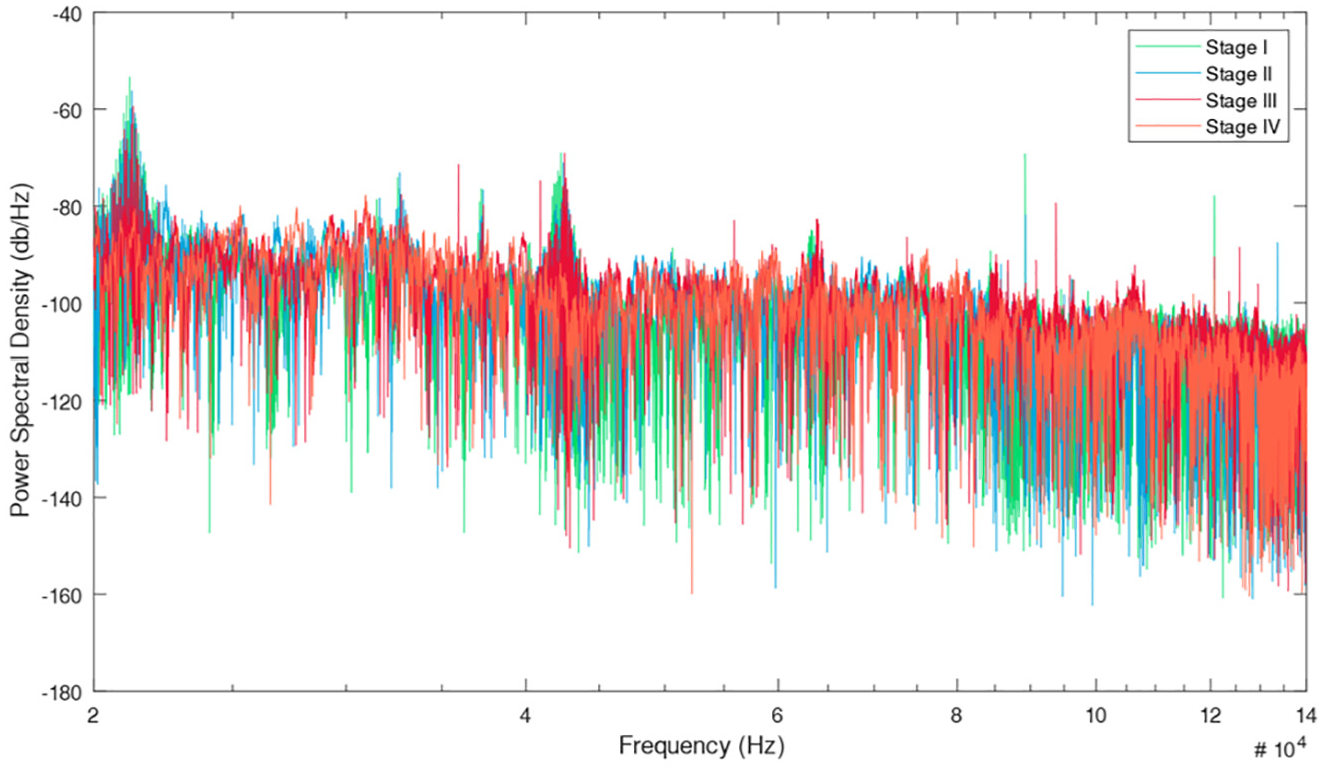
Power spectral density of AE recordings of four stages.
Methodologies
The flowchart of the proposed approach is illustrated in Figure 9. First of all, the raw AE signals were represented in the time–frequency domain. An audio source domain that is closely related to our target domain as well as the model NA pre-trained on it with a sophisticated source task (527 categories) was selected. Subsequently, the low-level layers of NA were transferred to our model and the parameters were frozen. Then, the high-level layers were further developed and trained using the AE monitoring data in the target domain. When new AE monitoring data arrives, it first goes through the frozen layers and then the trainable layers to evaluate the stages of rail conditions. MMD was calculated between the output of audio source data and AE monitoring data to quantify the relevance. The proposed approach is demonstrated in detail through the following subsections.
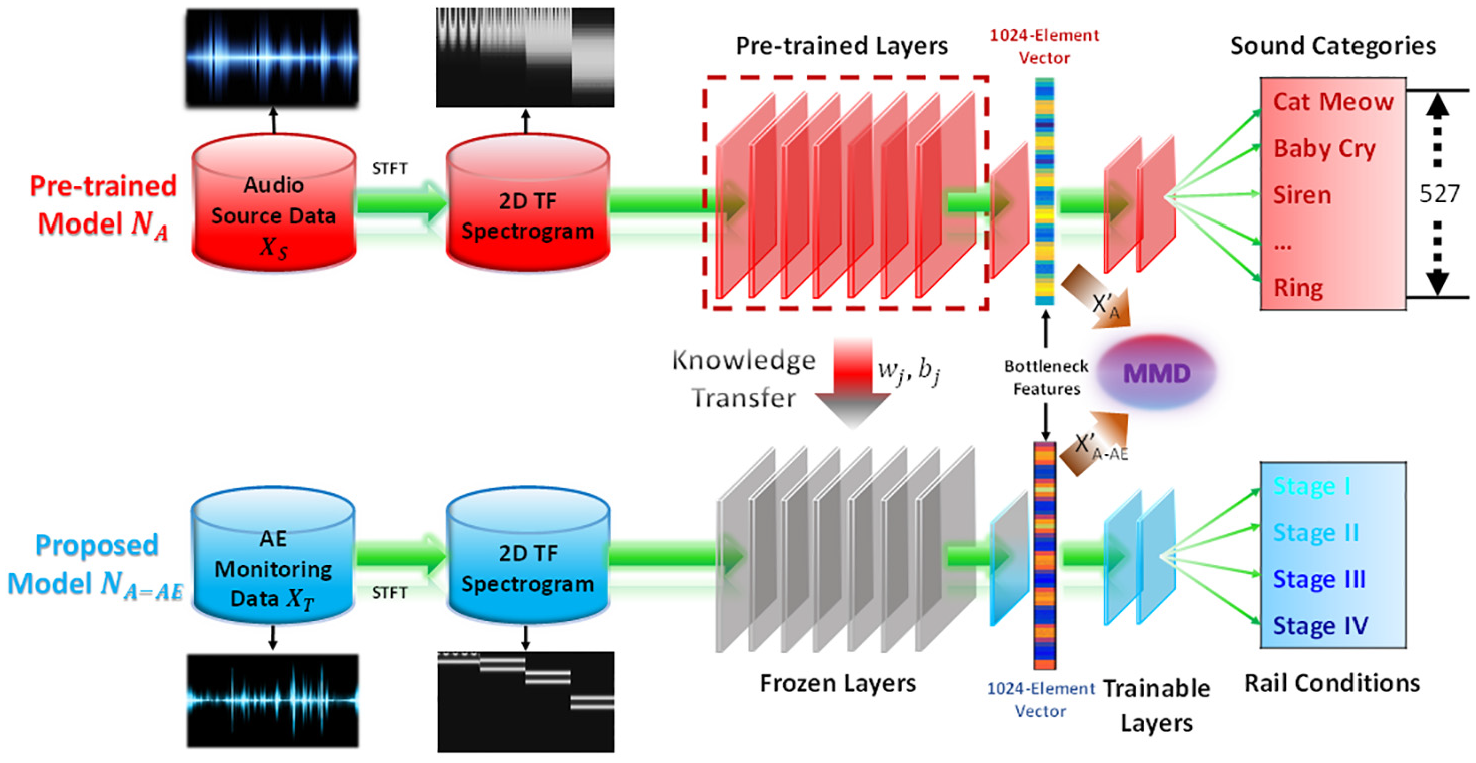
Flowchart of the proposed approach.
Time–frequency representation
Before the construction of the model, it is necessary to conduct pre-processing on the AE monitoring data. For acoustic waveforms, time–frequency spectrograms that contain rich information in both time and frequency domains are often used for further analysis. 55 Specifically, we conducted short-term Fourier transform (STFT) to the AE signals and obtained their spectrograms as
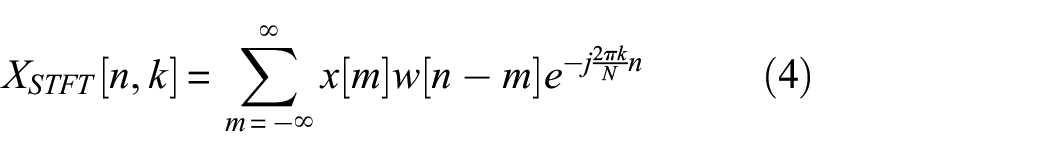
where w is a window function and
One AE signal was divided into 4688 segments using a Hann window with a size of 2048 (assuming that the signal within 3.41 ms is stationary) and overlap of 1024. The PSD was calculated for each segment to generate a spectrogram.
According to our previous study, 21 the PSD values of signals containing damage information reaches 90 to 140 kHz among all the frequency bands. To ensure the information in the ultrasonic level is fully made use of, we adopted the spectrum under a frequency range between 20 and 140 kHz. The PSD values were then combined into 128 frequency bins. Therefore, the size of the spectrogram is 128 × 4688. Figure 10(a) and (b) illustrate one AE signal and its spectrogram. It should be noted that the spectrum is displayed in Gray Plot because we were using the direct PSD values rather than the red, green and blue (RGB) decompositions as input to our model, and this will be further explained in the section “Construction of A-AE TL model.”
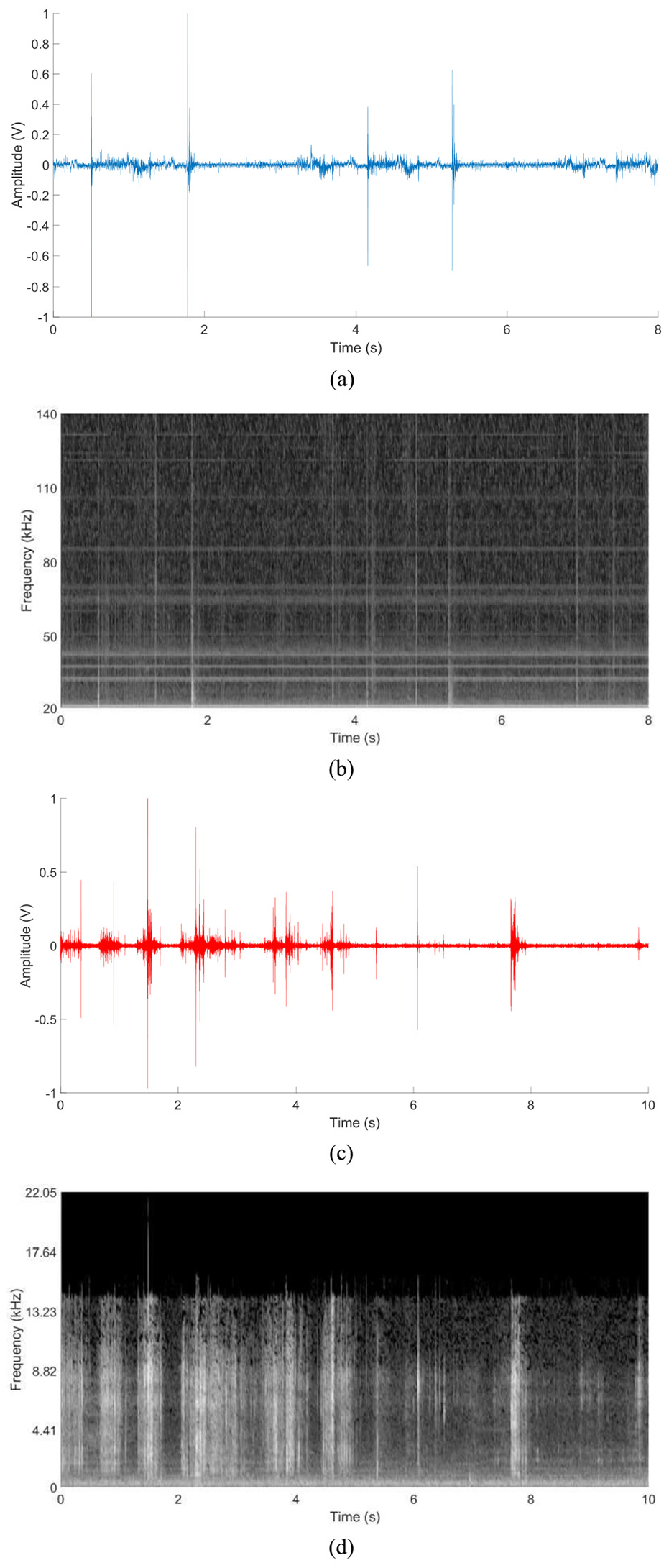
(a) AE recording, (b) AE spectrogram, (c) audio recording, and (d) audio spectrogram.
Selection of source domain
As illustrated at the beginning of this article on source domain selection, we would like the source data to be as close as possible to the target data. Basically, each AE burst (subject to impact, noise, and crack expansion) is considered as an audio event, and a segment of online audio recording also contains one or multiple audio events. This motivates us to use an online audio database as the source domain aiming at a better performance. The intuitive thinking is validated through MMD and will be elaborated in the section “MMD comparison.”
There are multiple online open-access audio database options, among which AudioSet dataset, 56 a large-scale dataset of manually annotated audio events, is considered to be a good source dataset. The dataset consists of around 2.1 million 10 s audio recordings for 527 sound events, 57 each of which at least contains 59 samples. The advantages of this dataset are two-fold. First, it has a close domain relation to our dataset, which contains different kinds of sound events. One recording is shown in Figure 10(c). The waveform is found similar to ours. More importantly, it has a large vocabulary (527 kinds of sound events), which makes the model it nurtures able to extract robust enough features for generic tasks. These sound events include sounds of things (engine, bell, alarm, mechanisms, etc.) and source-ambiguous sounds (generic impact sounds, surface contact, deformable shell, etc.) among others. Another typical audio dataset, in comparison, ESC-50 dataset 58 is too small because it consists a total of only 2000 recordings of 50 sound events.
It is found that CNN-like structures work well on audio classification by analyzing popular CNN architectures such as VGG, 40 ResNet 59 for large-scale sound event classification on web videos. 60 The import properties of CNNs are local connectivity and parameter sharing in convolutional layers, which means that the filters can extract local features even when the frequency range is different between spectrograms of source data and target data. Thus, a CNN trained on AudioSet, 61 dominated as NA, is leveraged in our study.
NA can be divided into two parts. The first part is a feature extractor, which intakes the spectrogram of an audio recording, such as Figure 10(d), and outputs generic features, based on which, the second part, a classifier, can identify 527 sound events occurred within 10 s. Due to the underneath relation between audio data and AE data, the feature extractor is very likely to be applicable for AE data, and thus be transferred as the frozen layers in our model. The construction of our model is detailed in the section “Construction of A-AE TL model.”
Construction of A-AE TL model
The developed model is named NA-AE, which means that it is a “Network trained on AE data with knowledge transfer from Audio.” NA-AE intakes a spectrogram directly, and, like a typical CNN model, transforms this input into a more and more abstract and composite representation layer by layer, and finally predicts the rail condition. This process is forward propagation.
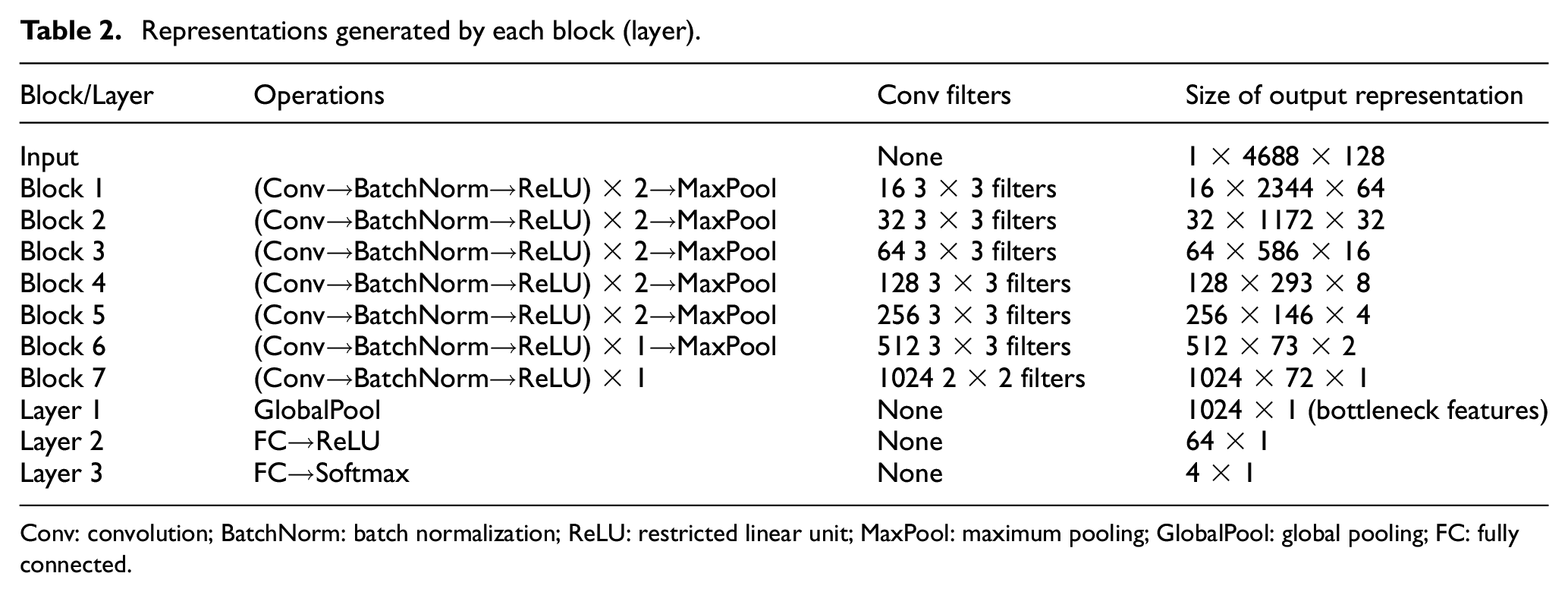
Figure 11 shows the architecture of NA-AE, which consists of seven blocks (each block with multiple layers) for segment-level feature extraction, a fusion layer for the integration of extracted features and two layers for mapping the bottleneck features to the prediction of condition. The output representation x of each block (layer) is summarized in Table 2. The three dimensions donate [depth, height, width], that is., [feature, time, frequency]. The operations conducted in a Block for an input volume, including Convolution (Conv), Batch Normalization (BatchNorm), Restricted Linear Unit (ReLU), Maximum Pooling (MaxPool), Global Pooling (GlobalPool), and Fully Connected (FC) feedforward, will be introduced in the sub-subsections.
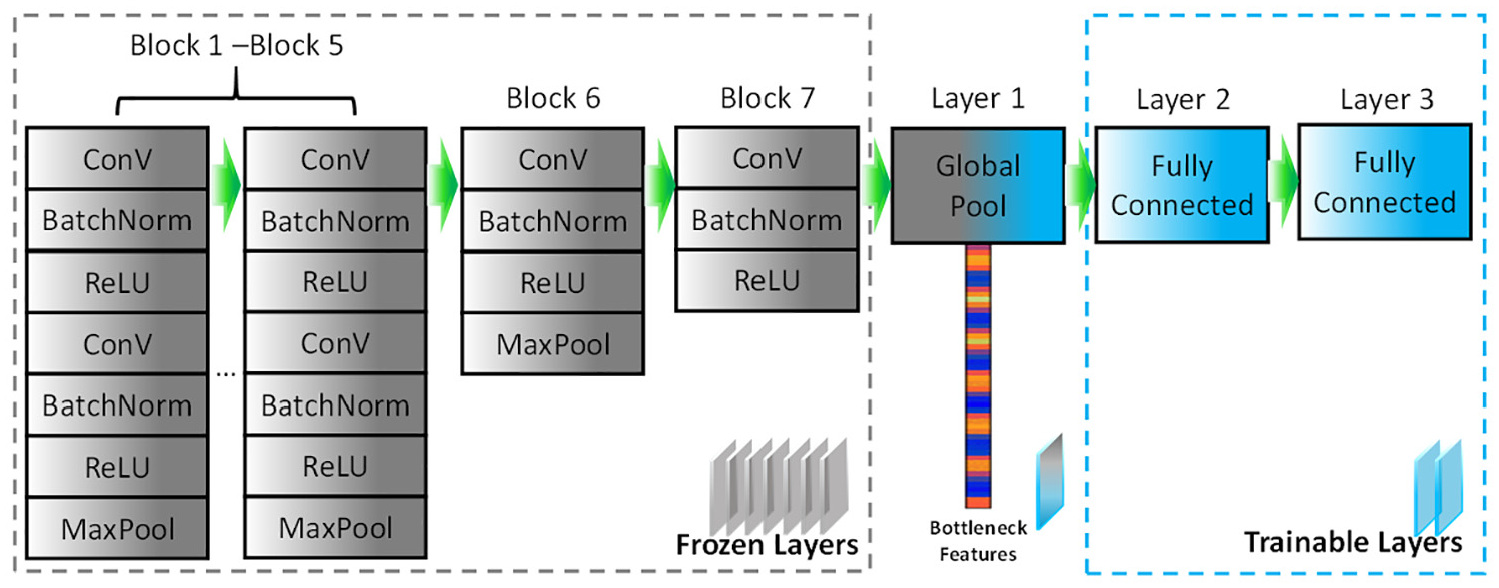
Architecture of the proposed model.
Representations generated by each block (layer).
Conv: convolution; BatchNorm: batch normalization; ReLU: restricted linear unit; MaxPool: maximum pooling; GlobalPool: global pooling; FC: fully connected.
Frozen layers
Block 1 to Block 5 consists of two Conv layers (with BatchNorm) followed by a MaxPool. Block 6 consists of one Conv layer, followed by a MaxPool layer. ReLU is used in all cases. For convolutional layers in all six blocks,
Conv layer consisting of a set of learnable filters is used to extract local feature maps. Each filter is spatially small but extends through the full depth of the input volume. During the forward propagation, each filter slides across the width and height of the input volume and compute dot products between the weights of the filter and the entries of the receptive field (the region that the filter is looking at). This convolution can be considered as feature extraction and finally produces a two-dimensional (2D) feature map containing the activations of that filter at every spatial position. The set of filters generates a number of feature maps. In summary, in a Conv layer numbered

where * represents the convolutional operator;
BatchNorm
62
is used to mitigate this internal covariate shift issue and thus accelerate the convergence of the training. During training, in the intermediate layers, the distribution of activations from the previous layer is constantly changing, which slows down the training process because each layer must learn to adapt themselves to a new distribution at every training step. Given the activations from the previous layer numbered
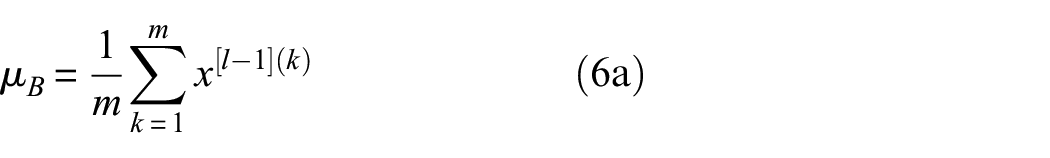
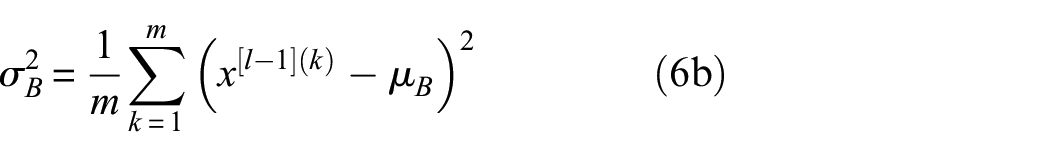
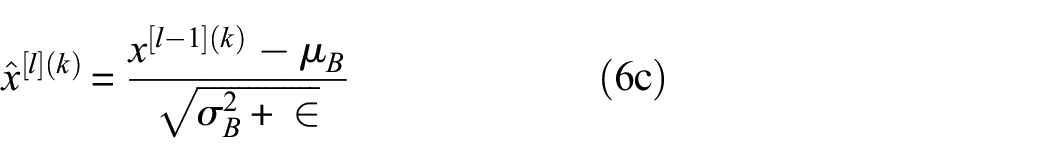
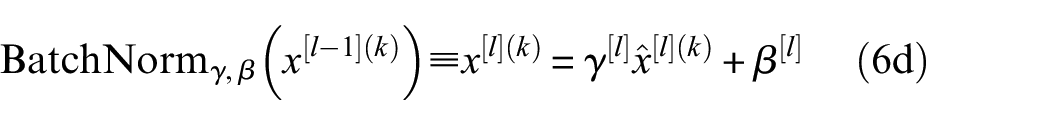
The feature maps are passed through a nonlinear activation function, ReLU, 63 which is elementwise and remains the size of the volume

Pooling layer is used to shrink the volume of representation and reduce the number of parameters in the next layer to train. MaxPool is commonly used, which takes the max over four numbers in every 2 × 2 region of the input volume. The layer can maintain the depth dimension
Segment integration and trainable layers
As shown in Table 2, the frozen layers intake the spectrogram of [1 × 4688 × 128] and produce the plate-like representation (after Block 7) of [1024 × 72 × 1] (order: feature, time, frequency). These segment-level features retain the information on the time axis. To integrate the segment-level representation into recording-level representation, GlobalPool is used. Basically, it takes the largest value along the time axis and generates 1024 features for the whole recording. This process enables our approach to flexibly handle AE recordings with different lengths. The 1024 features can be considered as a highly condensed version of the whole recording and they are called bottleneck features because they exactly locate in the bottleneck position before the classifier.
A multi-layer perceptron (MLP) consisting of several fully connected layers is used as a classifier after the global pooling to nonlinearly map the bottleneck features to the evaluation of rail condition corresponding to the AE data. For an input volume
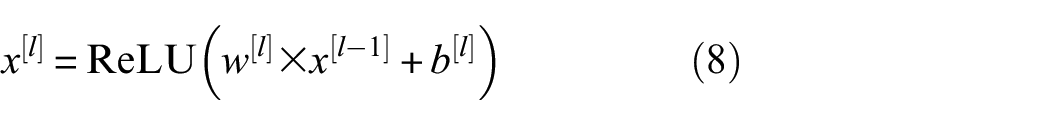
The final score for four classes is given by

where
The hyper-parameters of MLP, including the number of layers and the size of each hidden layer, are selected using fivefold cross-validation. 64 Specifically, the training dataset is randomly partitioned into five equal-sized sub-datasets. For each sub-dataset, the remaining four sub-datasets are used for training. For one hyper-parameter setting, the evaluation is conducted for five sub-datasets and the average cost (cross entropy) reflects the performance of current setting. Finally, a two-layer (Layer 2 and Layer 3) perceptron with a hidden layer size of 64 is selected due to its lowest cost.
In the process of training, the model typically takes a mini-batch with m samples and compares the final predictions to the ground truth. The cost (error) is back-propagated to update the parameters of each layer and thus gradually reduced by traversing all mini-batches within the training set for many epochs. The cost function is cross entropy
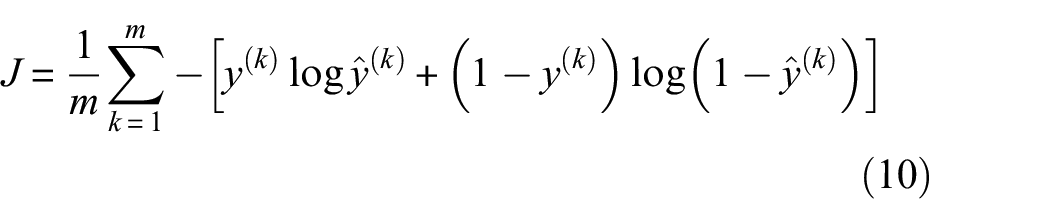
where for the kth sample in the mini-batch,
The training set contains 2880 samples, taking around 55% of the data. Of them, 320 samples are used as a validation set during the training. Based on these samples, the NA-AE was trained in the Pytorch framework. As described in the section “Construction of A-AE TL model”, the parameters of Block 1 to Block 7 were frozen and those in Layer 9 to Layer 10 were tuned. Dropout 65 with a rate of 0.5 was used in Layer 2 to prevent overfitting. The cost function was cross entropy. The optimization was conducted using an Adam optimizer 66 with a learning rate of 0.0001. The training will be conducted until the cost function on the validation set converges. The minibatch size was set as 32 so there are 90 mini-batches in the training set.
After learning from the training data, the model represents an inferred function, which can be used to map new samples. The performance of the NA-AE is investigated in the section “Performance comparison” in comparison with other baselines.
Baseline methods
VGGNet 40 is a highly successful model in the field of computer vision (CV) for image classification, which has been pre-trained on ImageNet. 41 Its ability to extract robust features from normally taken photos have been proved. On this basis, one baseline network, named NI-AE is developed. The formulation of NI-AE basically follows the idea of NA-AE. VGGNet consists of five convolutional blocks (Conv1–Conv5) and three fully connected layers (FC0–FC2). The convolutional blocks and FC0 are frozen and copied to NI-AE followed by an MLP with two FC layers. The whole NI-AE is then retrained on AE data.
The process is illustrated in Figure 12. The source model NI requires an input of a three-channel image with a size of 224 × 224. Since the spectrogram itself is typically wider and has only one channel, it has to be cropped or resized and then either stacked three times or decomposed into RGB compositions to pretend a three-channel image to fit the requirement of VGGNet. The matrix stacking or RGB decomposing behavior in NI-AE may be brutal and does not increase any information compared to the straightforward data intaking way in NA-AE as shown in Figure 9. In addition, it should be noted that the source domain seems to be far away from the target domain in nature, especially in comparison with the case in Figure 10. The MMD results measuring their discrepancy are also shown in the section “MMD comparison.”
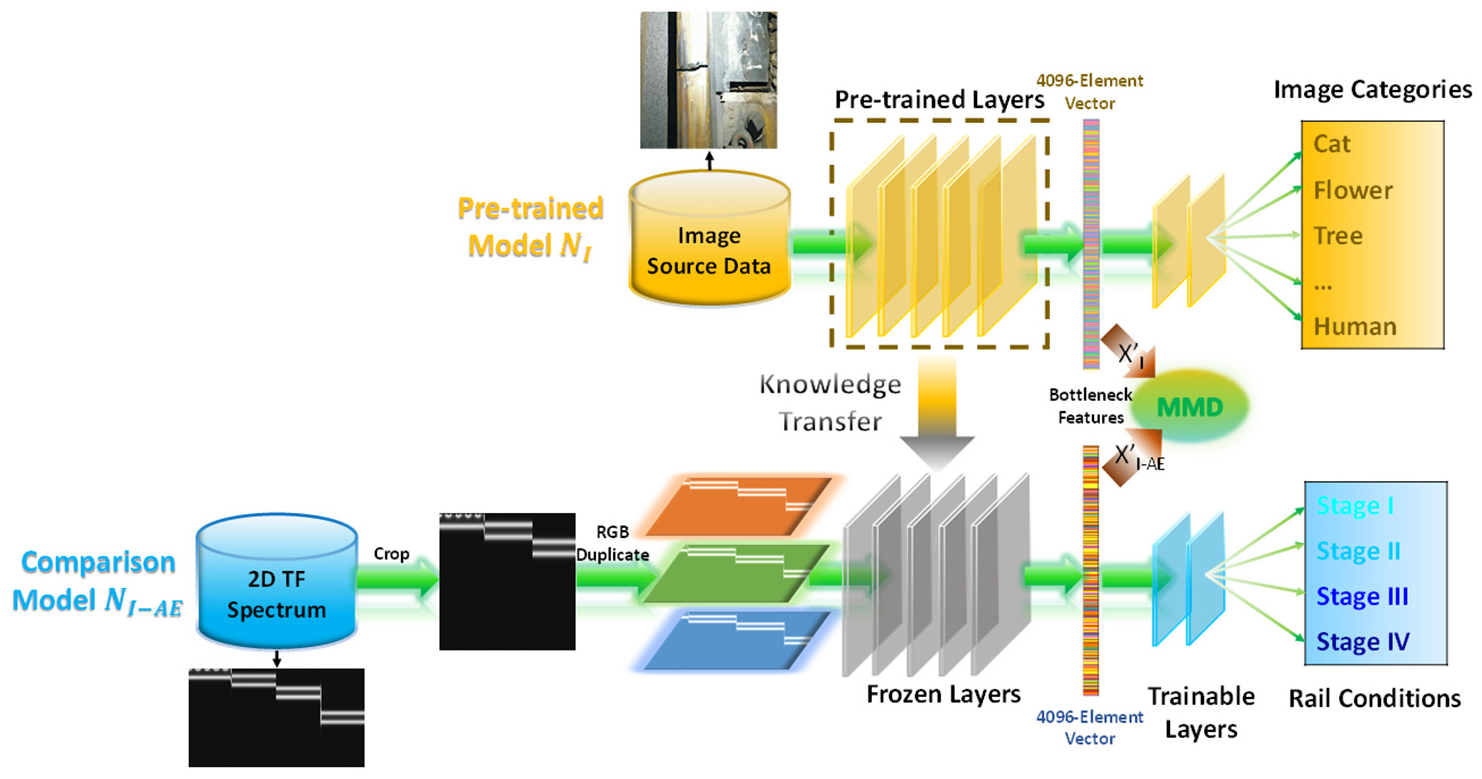
Flowchart of TL model NI-AE.
Another baseline network for comparison is a conventional CNN model that is trained from scratch, noted as NAE. The parameters in the frozen layers (referred to Figure 11) are unfrozen and randomly initialized rather than transferred from NA, and the whole model is trained on AE data.
To make the comparison more comprehensive, another method without the involvement of DL is also used. One MLP is developed so as to learn and evaluate the rail condition based on the PSD of the AE waveforms. It should be noted that an MLP is a classic feedforward neural network with an input layer, an output layer, and several trainable weight layers. This method is named “PSD + MLP.”
MMD calculation
Calculating MMD between distributions of input spectrograms is certainly possible, but normally we would like to know the discrepancy of inner essence (e.g. acoustic-specific) between datasets, while an original spectrogram may contain a lot of unwanted information that would dilute the MMD outcomes. Therefore, in practice, many studies tend to measure the domain discrepancy between distributions of bottleneck features rather than those of the original data (spectrograms),44,45 and this is what we use in this study.
General MMD calculation is demonstrated in the section “TL and MMD.” For the case of this study, given data
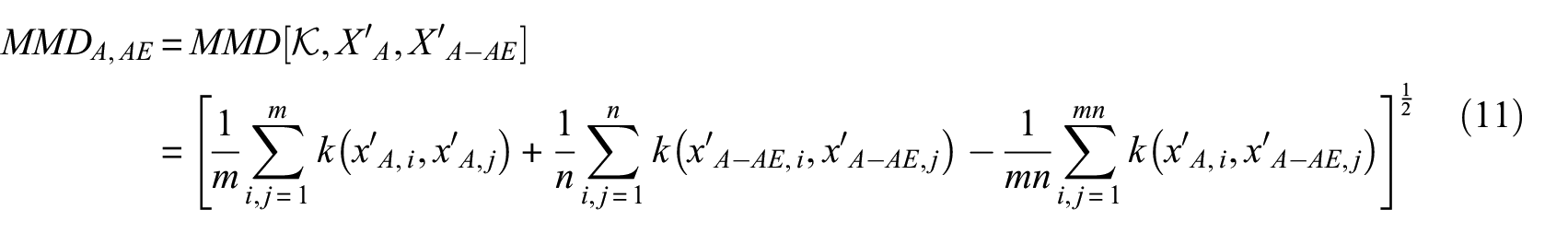
In this study, three kinds of kernels were used including linear kernel
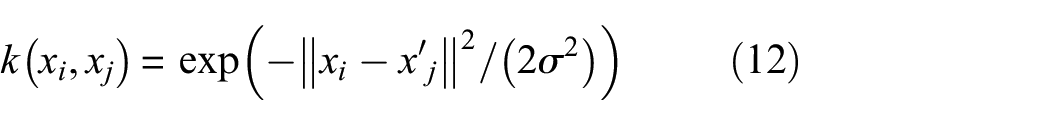
where
For TL model NI-AE, MMD between the source domain
Results and discussion
Performance comparison
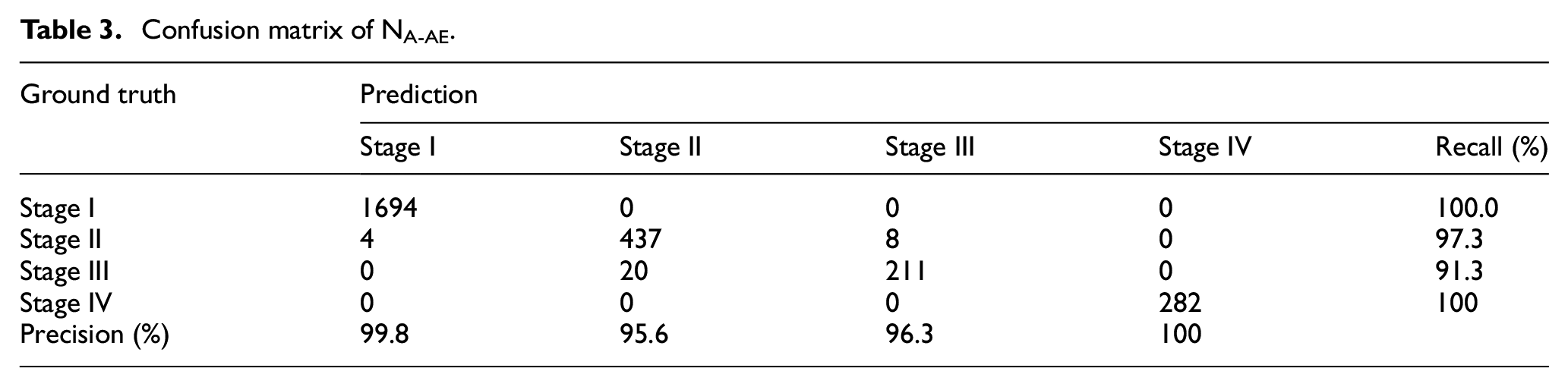
Model training, validating, and testing process was conducted on a workstation with an Intel(R) Core(TM) i7-7700HQ 2.8 GHz processor, 12 GB RAM, and an Nvidia GTX1070 Graphic Card. The well-trained NA-AE was used to infer the unseen data (size = 2656) in the testing set. The inferred rail condition is the category with the highest probability. Table 3 shows the confusion matrix. The recall and precision for each condition are also calculated. It is found that the model can well classify the AE recordings of each condition. The high precision of Stage I means that false alarm is very rare. On the contrary, the high recall of Stage II and Stage III means that the development of crack can be identified as early as possible, although few Stage III recordings are mistaken as Stage II.
Confusion matrix of NA-AE.
The F1 score for each class i is shown in the first column of Table 4, which is calculated by
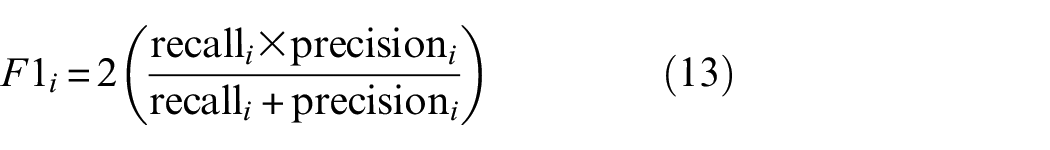
Comparisons between NA-AE and baseline methods in terms of F1.
PSD: power spectrum density; MLP: multi-layer perceptron.
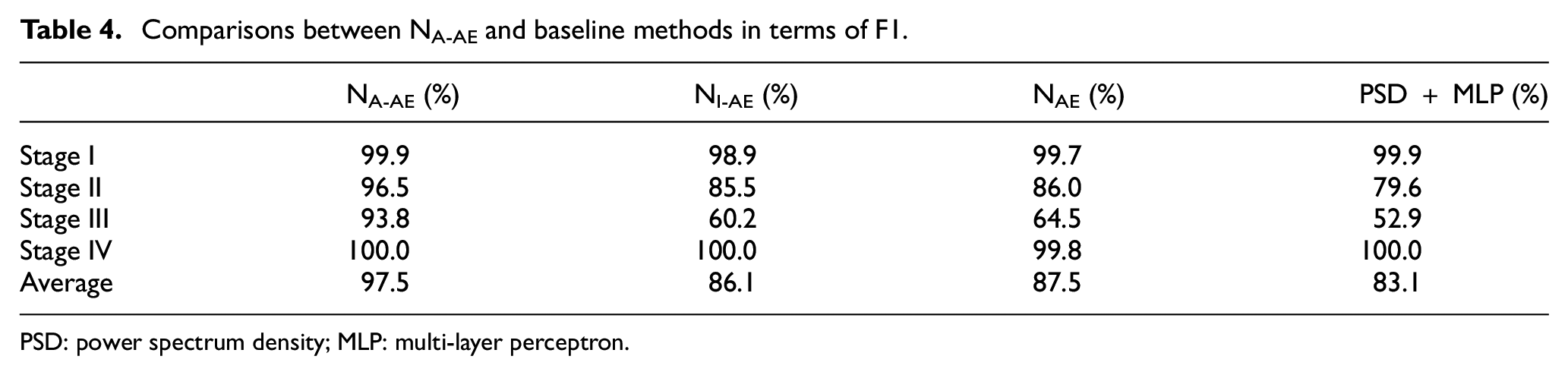
The mean of F1 for four classes, called macro-F1 was used as a summarized metric. Overall, the macro-F1 of NA-AE is 97.5%. In comparison, the macro-F1 of NI-AE and NAE is 86.1% and 87.5%, respectively. This indicates that the knowledge transferred from ImageNet has no benefits or even negative influences on the evaluation performance. Details for each stage are shown in Table 4. Although all three models can well identify the Stage IV, that is., the existence of critical crack, the F1 score of Stage III in NI-AE and NAE recordings is only 60.2% and 64.5%, respectively, which means these two models can hardly distinguish the middle transition stages of rail conditions, while NA-AE can classify Stage II and Stage III with satisfactory performance.
It should be noted that the method without the involvement of DL does not perform well in terms of F1 score, which should be blamed on the non-optimal features. After all, the PSD throws out the time information.
It is worth mentioning that it is also possible to unfreeze and fine-tune more high-level layers as an attempt to elevate the performance of NI-AE for a more comprehensive comparison with NA-AE. For NI-AE, three configurations of fine-tuning are investigated: (1) Tuning F0; (2) Tuning F0 and Conv5; and (3) Tuning F0, Conv5, and Conv4. The corresponding models are named NI-AE-1, NI-AE-2, and NI-AE-3, respectively. The average macro-F1 scores under different fine-tuning configurations are plotted in Figure 13. It can be seen from Figure 13 that despite the increasing F1 score under more layers unfrozen and profound fine-tuning, NA-AE without any fine-tuning process still outperforms NI-AE for all configurations. Moreover, unfreezing more layers would definitely increase the labor of training and lower the status and function of transferred knowledge in TL. Under the extreme state when all low-level layers are unfrozen, the TL model degenerates back into a conventional CNN model.
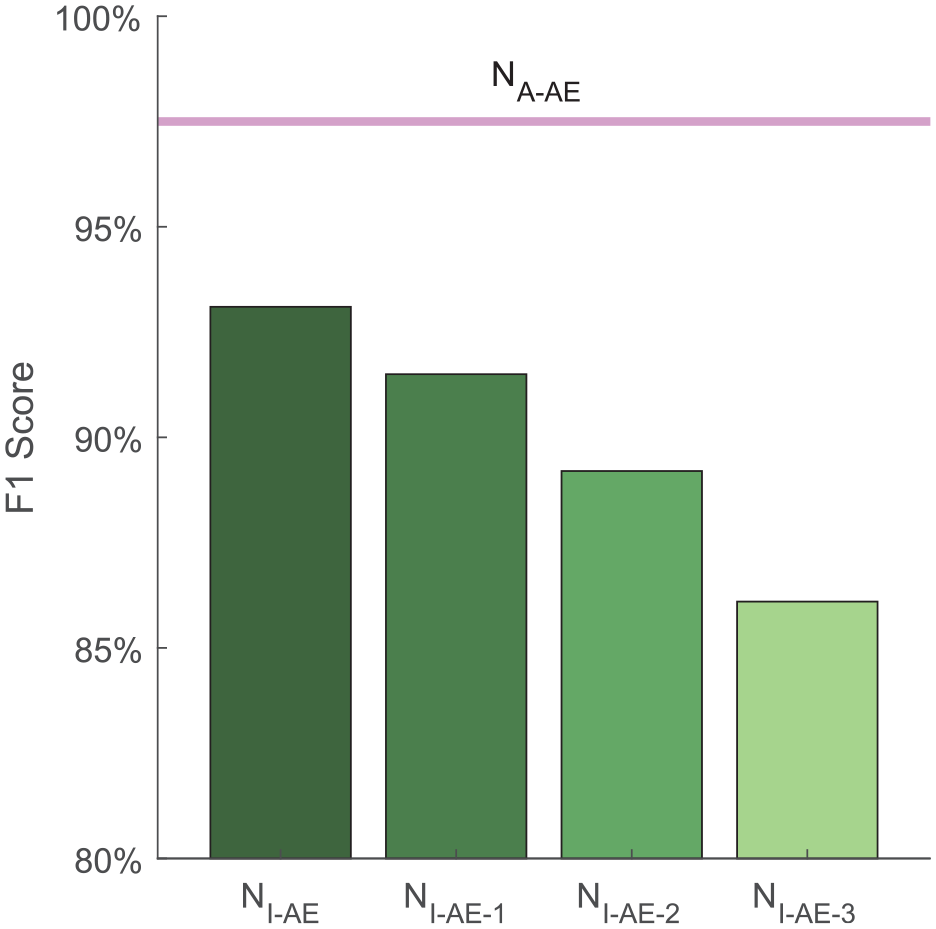
F1 score of NI-AE after fine-tuning.
MMD comparison
Following the calculation procedures in the section “MMD calculation,” the MMD between
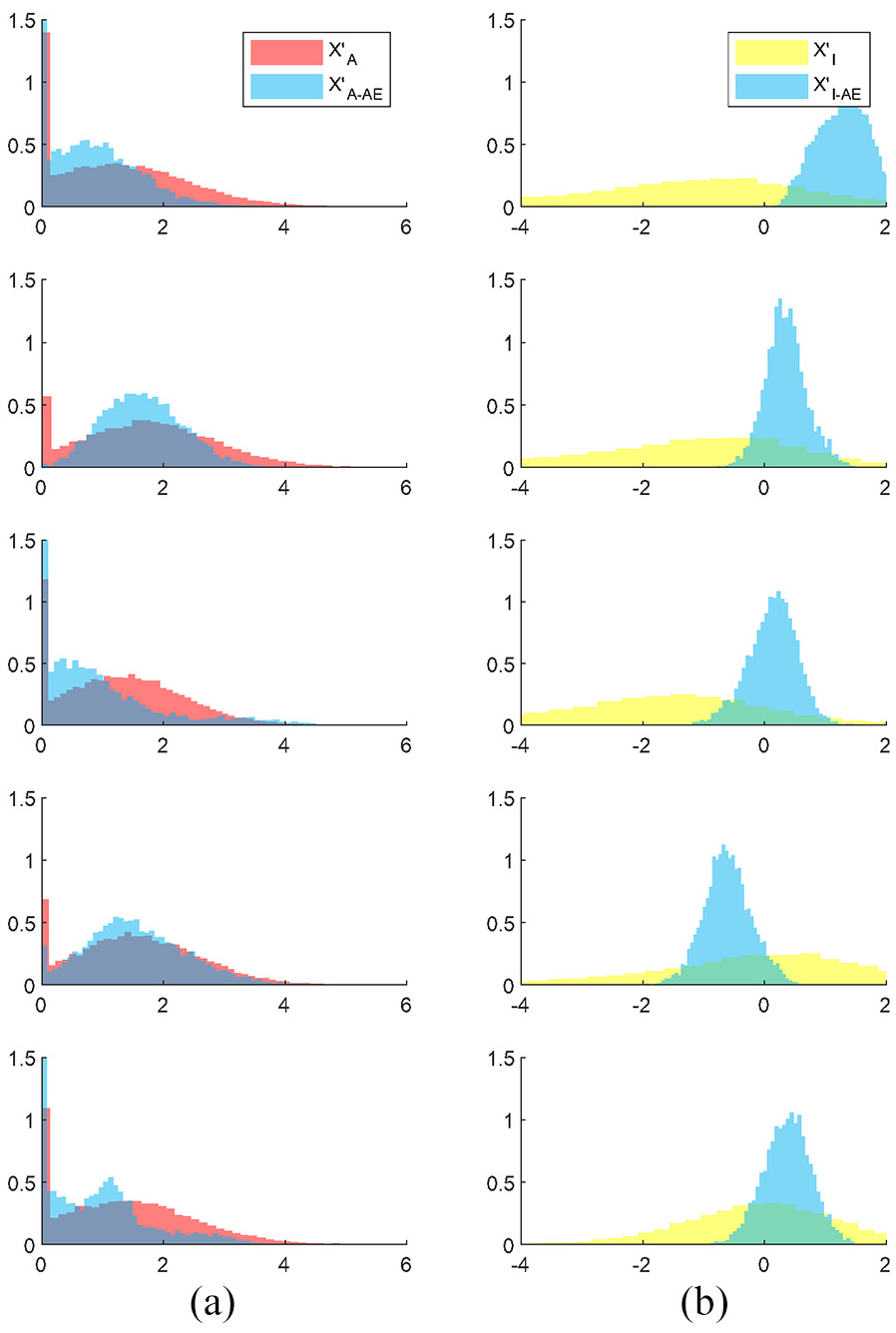
Distribution comparison between elements in (a)
To guarantee the MMD comparison is sufficiently general and convincing, four kernel functions under three types (RBF, Linear, and Polynomial) were used in this study. As introduced in the section “TL and MMD,” each kernel represents one kind of mapping to RKHS. The kernel width parameter
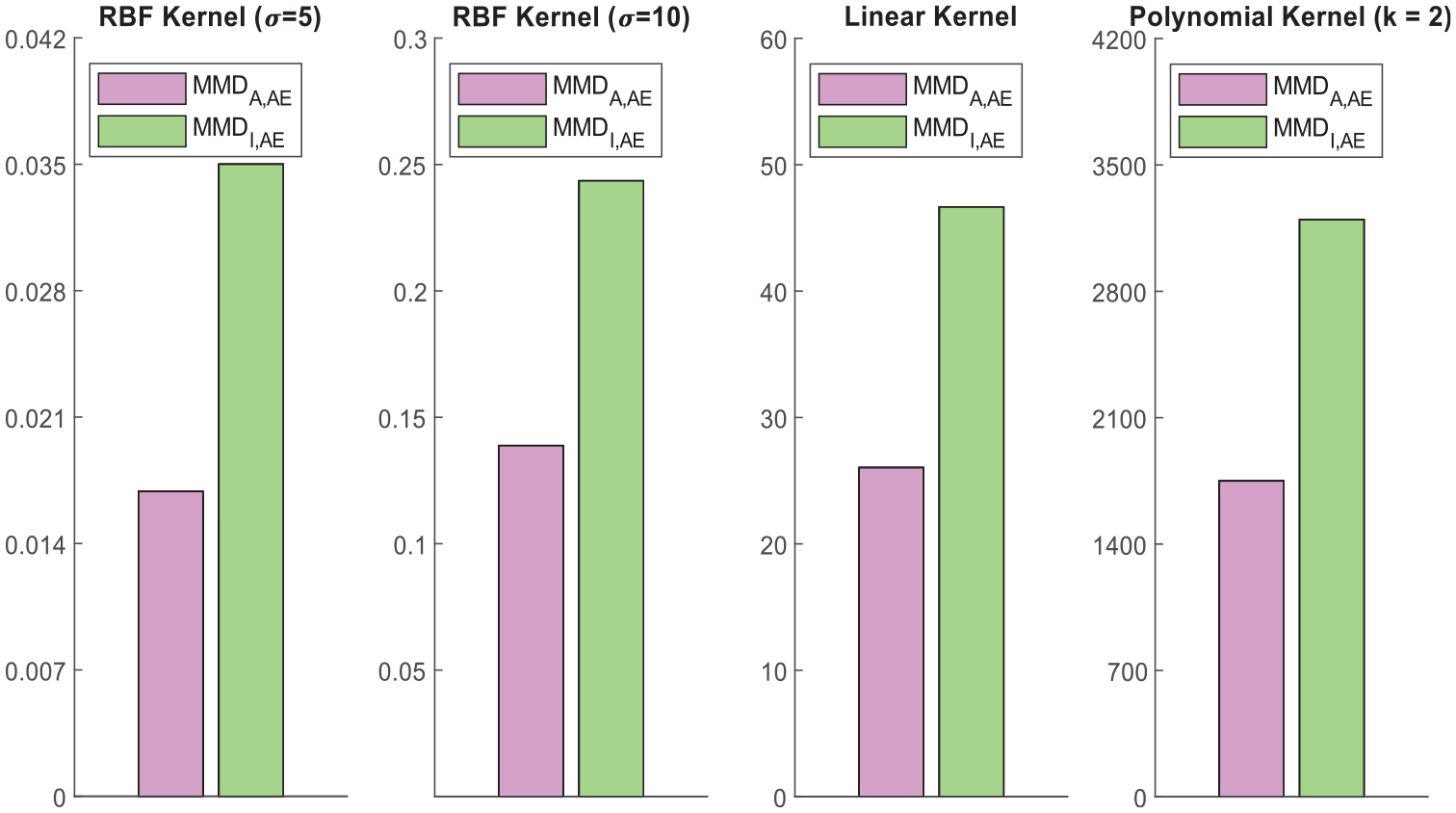
Domain discrepancy between AE and Audio and that between AE and Image.
Visualization of bottleneck features
There are 5536 AE recordings totally. When they are fed to NA-AE or NI-AE, 5536 sets of bottleneck features can be generated, denoted as
The results are illustrated in Figure 16. Each point in the figure represents the embedding features of an AE record. In Figure 16(a), bottleneck features from NA-AE seem to exhibit several clusters; while in Figure 16(b), features from NI-AE seem to mix up. When they are colored according to the type, it can be found that features from the same rail condition tend to cluster and there exists obvious borders between clusters in Figure 16(c). It should be noted that there is also a subtle trend of the points that reflect the progress of cracks. This result shows that the frozen layers of NA-AE are able to extract meaningful features for further classification. In comparison, the features of Stage I to class Stage III from NI-AE are mixed up in Figure 16(d). This indicates that the useful information is corrupted by a not-so-relevant model and to some degree lead to a performance decay.
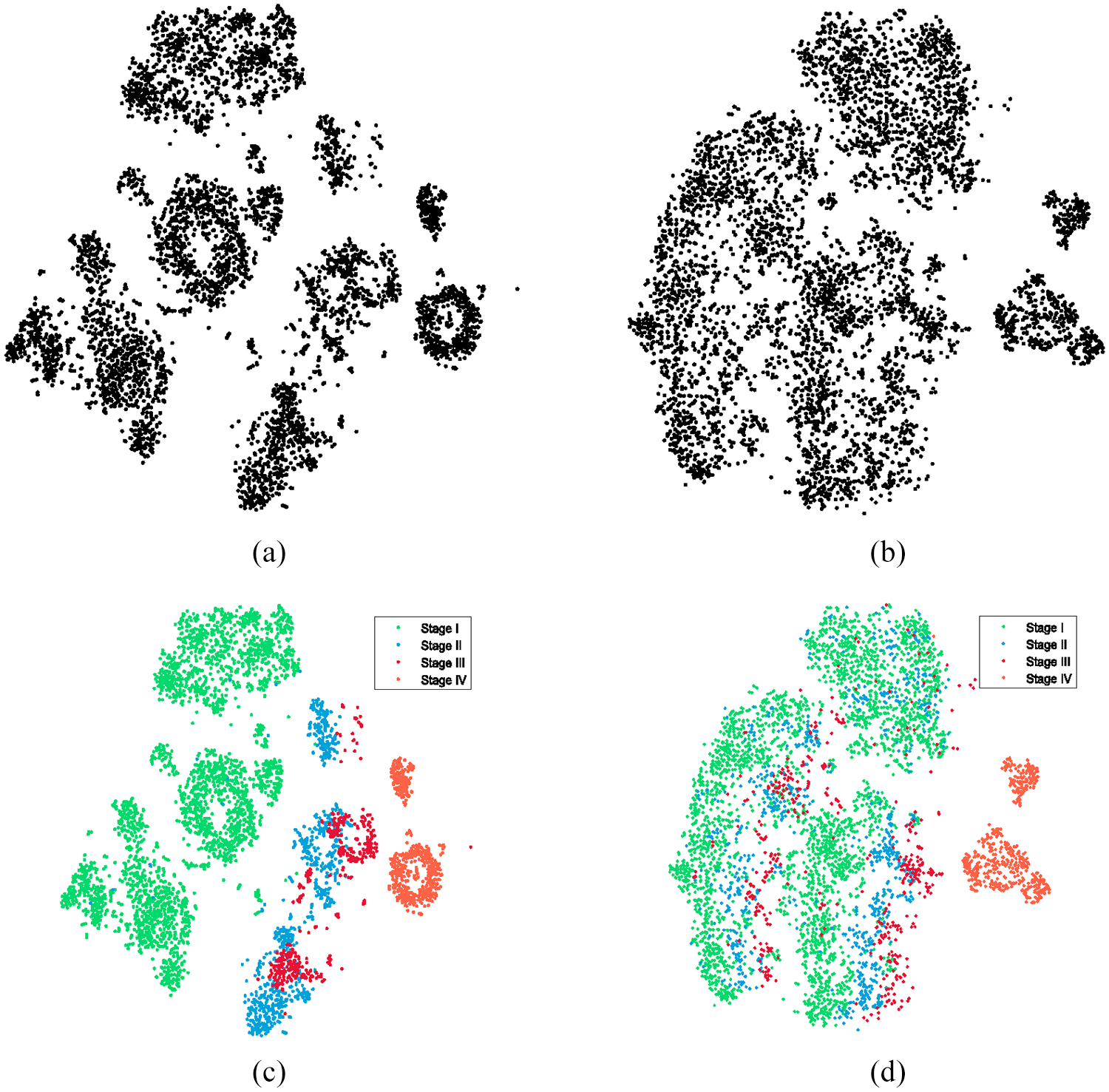
Visualization of bottleneck features
After labels were annotated in Figure 16(c), when we investigate 16(a) again it is found that although Stage II and Stage III cannot be clearly separated in the figure, the clustering phenomena of features from Stage I (intact) and Stage IV (critically cracked) implies the possibility to evaluate the rail condition in an unsupervised way.
Computation time comparison
To demonstrate the effectiveness of TL, the training processes with and without TL were traced and shown in this section. One-ninth training data (320 samples) were taken out as a separate validation set during the training. The cost (cross entropy) and the F1 score on the validation set were measured when each epoch of training is finished. The results of 50 epochs are shown in Figure 17.
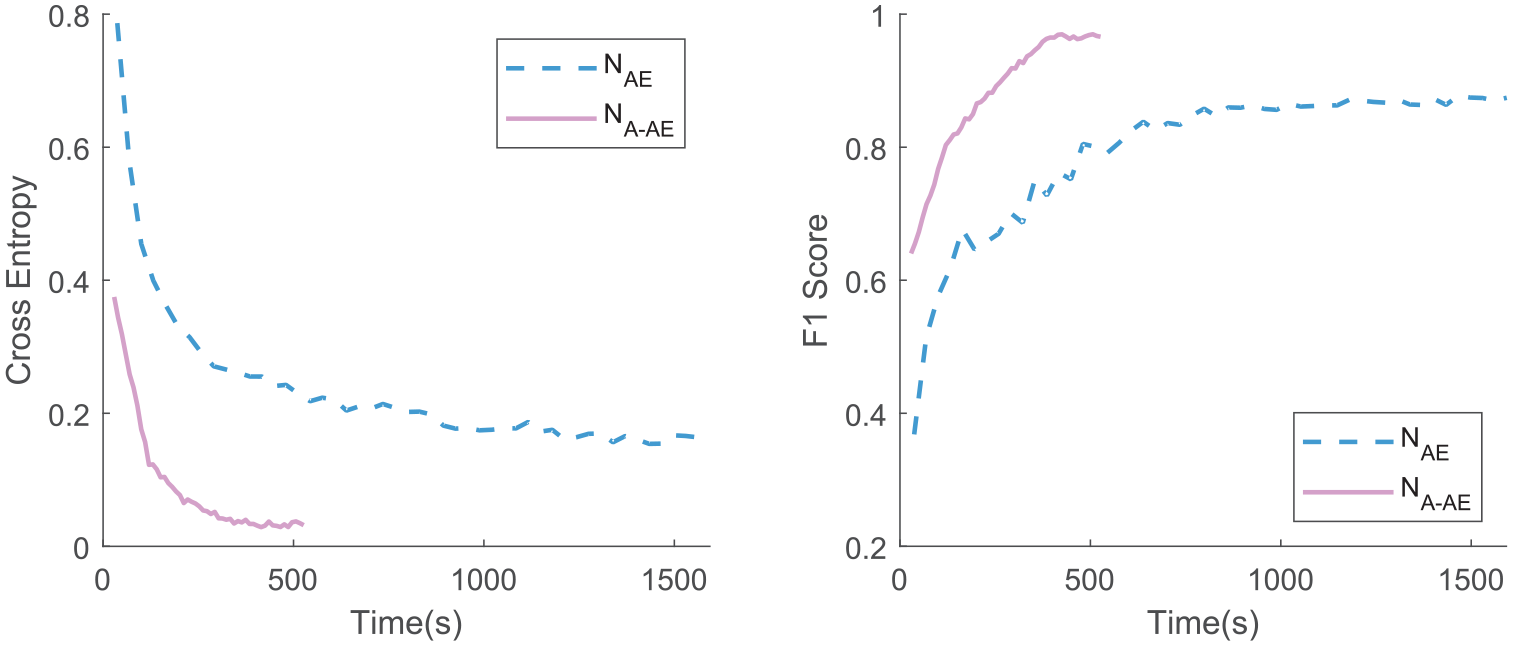
Training progress of NAE and NA-AE on the validation set.
It is found that the NA-AE can learn to reduce the validation cost much faster than NAE since it has much fewer parameters to be tuned. Without calculation details given, the number of parameters in NAE to be trained is 4,527,732, while this number in NA-AE is only 65,860. To achieve an acceptable cost lower than 0.2, the NAE requires around 700 s, which is seven times the time of NA-AE. Although 700 s seems to be acceptable, this only corresponds to one rail turnout zone in this study. Once AE-monitoring systems are implemented in a large scale, considering numerous rail turnouts with various operating environments, passing trains and rail conditions, computation efficiency is extremely vital in quickly establishing corresponding models in time.
Even neglecting the time limit, the cost curve of NAE eventually converges at a higher level than NA-AE. This is owing to the overfitting problem. The model volume is relatively large in comparison with the training size, and its continuous learning on the training set is not helpful for its performance on the validation set, as well as the unseen testing set. Although the F1 score on the training set is almost 100%, on the unseen testing set, the NAE only shows moderate performance with macro-F1 of 87.5%. As mentioned in the section “Performance comparison,” the F1 score on the testing set reaches 97.5% using NA-AE.
Conclusion and future work
In this study, a TL approach has been developed using in-situ AE monitoring data and a pre-trained model from an audio source. In summary, the study contains three primary contributions. (1) The approach is able to evaluate the structural conditions of in-service rail tracks in a progressive manner from intact to critically cracked, as an advancement of crack detection in the authors’ previous work. It enables alarming of rail cracks at early stages and would help rail operators to conduct in-time maintenance work. (2) Compared to conventional CNN models, the proposed CNN model (NA-AE) transfers lower-layer knowledge from a pre-trained AudioSet model, to help extract the acoustic-specific features of the time–frequency spectrograms of two months AE monitoring data collected from an in-service point rail, and only higher layers of the proposed model needs to be trained. To the authors’ knowledge, it is the first time we use massive audio recordings as “acoustic-homologous” source data to AE-based SHM evaluation. Testing results demonstrate that the developed model NA-AE performs well on the rail condition assessment task based on AE data, with a high macro-F1 score of 97.5% and relatively short computation time. While subject to the lack of training data amount and overfitting problem, the model learning from scratch (NAE) has a macro-F1 score of 87.5% and tripled computation time. Although the advantage of TL computation efficiency is not obvious in this study for one rail turnout, it will definitely be manifested upon numerous operating rail lines implemented with monitoring systems. (3) The closeness between source data (ImageNet, AudioSet) and the target AE monitoring data are quantitatively determined with a metric MMD, and the influence of different source data on the learning performance is investigated. It is found that the training model with knowledge transferred from images has no positive or even negative influence on the performance with a result of 86.1% macro-F1 score. This result aligns with the image-AE data MMD values, which are obviously higher than those between audio data and AE monitoring data under different calculating Kernel functions. The study provides a suggestion that when using TL in SHM evaluation, selecting source data correspondingly and appropriately would be necessary facing heterogenous monitoring data in varying SHM scenarios. It should be noted that the AE technique can only monitor a small portion of any rail. Therefore, it is more applicable for the critical zones of rail such as the rail turnout in this study or for critical components in other mechanical systems. For long-distance rails, some vehicle-based inspection methods may be more suitable, such as those based on track inspection trains.
Apart from the contributions listed above, several improvements can be made in our future work based on findings in this study:
In this study, the discrepancy between the source domain and target domain is measured by MMD as guidance for source domain selection. Recently, there are some inspiring research efforts on another kind of TL named domain adaptation, where the source task and the target task are exactly the same while the
Despite the excellent performance of the proposed model, the optimization of hyperparameters is still worth investigating, such as the optimum layer to be unfrozen. Besides, the window width of STFT on acoustic waveforms can also be further studied for a better representation. Moreover, it is worth looking into whether using more relevant data categories (crackle, crack, shatter) available on AudioSet as source data rather than the entire database will achieve better evaluation performance on rail crack identification.
The clustering phenomenon of visualized bottleneck features is observed in Figure 12(c) where the AE data from healthy turnout exhibit obvious borders from other conditions. This provides a possibility of unsupervised learning, and it is expected that rail condition evaluation can be conducted even when only healthy data are available. Histogram-based Outlier Score (HBOS) 69 and k Nearest Neighbors (KNN) are all potentially effective algorithms for this, and the authors are currently researching into this.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a grant (RIF) from the Research Grants Council of the Hong Kong Special Administrative Region, China (Grant No. R5020-18). This research was also funded by the grants from the Ministry of Science and Technology of China and the Innovation and Technology Commission of Hong Kong SAR Government to the Hong Kong Branch of Chinese National Rail Transit Electrification and Automation Engineering Technology Research Center (Grant No. K-BBY1).