
Abstract
Essays that are assigned as homework in large classes are prone to cheating via unauthorized collaboration. In this study, we compared the ability of a software tool based on Latent Semantic Analysis (LSA) and student teaching assistants to detect plagiarism in a large group of students. To do so, we took two approaches: the first approach was in vivo; that is, we observed whether LSA and the teaching assistants could detect plagiarism during the term. The second approach was in vitro; that is, we had 14 teaching assistants and LSA evaluate, after the term had ended, a sample of N = 60 essays of which two essays were identical. Results showed that the responsible teaching assistant did not detect the duplicates during the term (in vivo) and that the majority of the teaching assistants did not notice that they had read two identical essays (in vitro). Some of them even scored the duplicates in markedly different ways. However, the duplicates were easily identified and evaluated as equally good by LSA. We conclude that using LSA can improve assessment at universities in terms of detecting plagiarism.
The advantages of assigning written essays in teaching have been highlighted by several authors (e.g., Foltz, Gilliam, & Kendall, 2000; McGovern & Hogshead, 1990; Miller, 2003; Wade, 1995). In addition, there are some problematic aspects of traditional exams (e.g., multiple-choice tests); for example, they do not resemble future tasks and they promote shallow learning (e.g., Ritter, 2000) or that ‘they are insufficient for teaching, learning and measuring the full range of study and knowledge-application skills that competent adults need’ (Landauer & Psotka, 2000, p. 73). Consequently, Isaksson (2008) justified the teaching practice of having students write some kind of essay instead of using a final exam because the final-exam format fosters surface learning.
Although there are benefits to having students write essays, there is also a risk: if students write the essays at home, they might try to cheat and copy from other sources; that is, they might commit plagiarism. According to Park (2003), plagiarism can be seen as a form of cheating or academic misconduct or dishonesty. It is obvious that any behaviour falling in this category is not acceptable; hence, it is best avoided and should be detected if it occurs.
A great deal of research has addressed a broad range of different aspects of academic dishonesty or cheating, and especially important for us, it has been shown that it occurs – and that some forms seem to increase – at university level (e.g., McCabe, 2005; Newstead, Franklyn-Stokes, & Armstead, 1996; Vandehey, Diekhoff, & LaBeff, 2007; Whitley, 1998). There is a large literature on unintentional plagiarism and how to educate students to avoid it (e.g., Belter & Du Pre, 2009; Elander, Pittam, Lusher, Fox, & Payne, 2010; Landau, Druen, & Arcuri, 2002).
However, another – probably more severe – problem is intentional plagiarism. Strategies that teachers can use to avoid (intentional) plagiarism include regularly modifying the tasks, asking for analysis, evaluation, or synthesis, and using open-ended questions for which many solutions are possible (e.g., guidelines published by Nottingham Trent University, 2013, referring to e.g., Carroll & Appleton, 2001). However, none of these strategies can ensure that no student will copy another student’s text. There might be understandable reasons to give away one’s essay, for example, to help a friend (e.g., Ashworth, Bannister, & Thorne, 1997; Franklyn-Stokes & Newstead, 1995; Newstead et al., 1996; Owens & White, 2013). Nevertheless, there is a deliberate intent to cheat in these cases and hence this form of cheating must be expected, detected and avoided.
With this paper, we compare the abilities of student teaching assistants and a computerized system in detecting plagiarism in a large university course. The current paper is not aimed at addressing common forms of intentional plagiarism by which students copy from textbooks, the Internet, and so forth. Rather, we are suggesting a solution for large courses in which students answer questions that include giving one’s personal opinion, analysing and evaluating research findings, and connecting these with personal experiences or the like. These answers cannot directly be found in a textbook or the course material; consequently, students cannot copy from such external sources. Thus, although this concept includes factors that make plagiarism less likely (e.g., Austin & Brown, 1999; Culwin & Lancaster, 2001a; Warn, 2006), students might work together and fail to provide independent work.
Because it is impossible for a university instructor to read all essays, it is a well-established policy to employ teaching assistants who read the essays and give feedback to the students. However, if two students work together or one student copies another student’s text and these two students are not supervised by the same teaching assistant, plagiarism cannot be detected. Even if the same teaching assistant is responsible for the work of both students, he or she might not notice plagiarism. Moreover, there is quadratic growth in the number of single comparisons that can be made between students’ essays. To directly compare all of the essays written for a course, n*(n−1)/2 single comparisons would be necessary. In a course with 500 students, this would result in 124,750 comparisons – a task that cannot be carried out manually. This is where a software tool might be helpful if it could detect plagiarism more reliably.
Plagiarism Detection
There are several plagiarism-detection methods and services that have relative advantages and disadvantages (for a review of these tools and some tests of or comparisons between systems, see e.g., Kakkonen & Mozgovoy, 2010; Lancaster & Culwin, 2005; Maurer, Kappe, & Zaka, 2006; McKeever, 2006; Purdy, 2005; Weber-Wulff, Möller, Touras, & Zincke, 2013). The functioning of most systems is similar: their algorithm is based on the assumption that two writers will usually not use the same words and thus, the system identifies overlapping word strings. Most systems can check for duplicates across the submitted texts, and some of the products claim that they can also detect slight linguistic modifications. However, the majority of the systems primarily detect verbatim plagiarism.
For plagiarism detection, Culwin and Lancaster (2001a, 2001b) suggested a four-stage process: collection, detection, confirmation, and investigation. With regard to the system used in this work, the first two steps can be facilitated by the use of software tools. We used the self-developed learning platform ASSIST at the University of Würzburg which was a former version of βASSIST which is now available at the University of Heidelberg (http://assist.psi.uni-heidelberg.de/). By (β)ASSIST students can hand in essays electronically so that the essays are collected immediately. Further, because this learning platform uses Latent Semantic Analysis (LSA; e.g., Landauer, McNamara, Dennis, & Kintsch, 2007), it is possible to detect both verbatim and semantic plagiarism (see next paragraph). 1 However, as there is a risk of false positives, human judgement will always be necessary to decide whether a text really is a duplicate (confirmation) or whether the author has cited another person’s ideas correctly, and whether there is enough evidence to accuse the author of cheating (investigation).
Thus, although software tools might be helpful within the plagiarism-detection process, one should also be aware of the terms and conditions of their use. Whenever software tools are used to detect plagiarism, legal and ethical aspects such as intellectual property and copyright are important (e.g., Butakov & Barber, 2012; Foster, 2002; Mozgovoy, Kakkonen, & Cosma, 2010; Purdy, 2005). However, these might not be as significant when the students’ texts are stored within the university only.
Using an LSA-based System to Detect Plagiarism
LSA is a statistical technique that can be used to generate automatic evaluations of texts on the basis of their semantic similarity. To do so, texts are represented as vectors within a semantic space (for details of the modus operandi, see Deerwester, Dumais, Furnas, Landauer, & Harshman, 1990; Landauer & Dumais, 1997; Landauer, Foltz, & Laham, 1998; Martin & Berry, 2007). LSA has been shown to be powerful in essay assessment in the English language (e.g., Foltz, Laham, & Landauer, 1999; Landauer, Laham, & Foltz, 2000; Landauer, Laham, & Foltz, 2003a, 2003b; Landauer, Laham, Rehder, & Schreiner, 1997) as well as in the German language (e.g., Lenhard, Baier, Hoffmann, & Schneider, 2007; Seifried, Lenhard, Baier, & Spinath, 2012).
Further, LSA has also been used to detect plagiarism: Cosma and Joy (2012) used LSA to detect source-code plagiarism (with their tool called PlaGate), and Britt, Wiemer-Hastings, Larson, and Perfetti (2004) integrated LSA into their Sourcer’s Apprentice Intelligent Feedback (SAIF) system, which is aimed at enhancing students’ sourcing and integration skills. Both author groups stated that LSA can detect cases in which sentences have been reordered (structural changes) and cases in which synonyms have been substituted/renamed (semantic changes); these changes are said to be the most common types of plagiarism (Britt et al., 2004). However, the performance of an LSA-based system is not predictable in general but relies on several parameters (e.g., the corpus), and this also renders comparisons with other tools that depend on string-matching algorithms almost impossible (Cosma & Joy, 2012; Mozgovoy et al., 2010). Thus, it seemed worthwhile to us to test the ability of an LSA-based system to detect plagiarism in our course and compare its performance with our student teaching assistants’ performance.
With LSA, it is possible to execute a semantic comparison of each essay in a given set with every other essay in that set. Thus, it is possible to detect verbatim as well as semantic plagiarism; that is, LSA will detect plagiarism even if students try to cheat by substituting synonyms for some words or by paraphrasing the content. If there is a pool of n essays, LSA can compute all possible n*(n−1)/2 single comparisons within (milli)seconds .
By means of our learning platform, (β)ASSIST, texts can be compared within or across cohorts. Thus, it should be helpful for detecting what we want to detect, that is, intentional intracorporal plagiarism. After the number of comparisons is defined, (β)ASSIST will return a rank order of (all pairs of) texts that is based on the semantic similarity of the texts; this similarity is also expressed in a similarity score. Further, the authoring students’ names, email addresses, and a link to their submissions are provided. With this link, it is possible to see details about the submissions (e.g., the exact date and time of the submissions). If a text is identified as a duplicate, the text can be marked as plagiarism.
After having identified semantically similar texts, an in-depth analysis of the text surface is implemented using the Smith-Waterman algorithm (Irving, 2004), an approach commonly used in genetics to identify similar genes. This allows teachers to retrieve text passages, even when words are omitted or replaced or their sequence is altered. By combining the LSA-based ranking with the surface analysis, the restrictions of the two approaches are compensated for and false positives are avoided. Identical or similar text passages are highlighted in the same colour, which facilitates the visual inspection of plagiarized text. Further, there is a percentage score that represents the proportion of coloured text (i.e., possible plagiarism) in each text.
However, human judgement is indispensable because (β)ASSIST does not classify a text as conspicuous or inconspicuous but only gives back a list of (all pairs of) texts – ordered according to their semantic similarity. Some highly ranked text pairs might not include real plagiarism but might rather be similar due to the fact that some students copied the question into their text and thus their texts shared a large number of words. Thus, the decision where to draw the line between plagiarism and random or irrelevant similarity is up to human judgement. Some studies have shown that automatic plagiarism detection is very helpful as the systems ‘found’ (i.e., indicated as conspicuous) texts that had already been identified as plagiarism as well as further undetected cases (e.g., Badge, Cann, & Scott, 2007). Moreover, studies have shown that automatic plagiarism-detection systems contribute to the reduction of plagiarism when students are told that a plagiarism-detection technique will be applied to their papers (e.g., Braumoeller & Gaines, 2001).
However, although it might be a widespread belief that computer programs are better than humans at ‘detecting’ plagiarism, direct evidence of this superiority is scarce. We could not find any study that directly compared the ability of a software system to that of human graders in detecting plagiarism or that at least systematically analysed either the ability of software or human graders to detect plagiarism in a real learning setting. Park (2004) stated that marker vigilance has been the traditional way to detect plagiarism and that some markers might be more vigilant than others, but this idea has yet to be tested. Landauer et al. (2003a) reported an instance involving a professor who did not notice the similarity of two essays that he had read only some minutes apart. Further, Shermis, Raymat, and Barrera (2003) stated only that it is very difficult for human scorers to detect students’ plagiarism. Finally, in their paper on the Ferret copy detector, Lyon, Barrett, and Malcolm (2006) alluded to the potential problem that there are many graders when cohorts are large, and thus, that plagiarism detection is very difficult (unless the potential instances of plagiarism are graded by the same person). In their paper, they also included a section on the ‘Comparison of Plagiarism Detection By Man and Machine’, but they did so on a very theoretical basis: they looked at differences in language/memory processing (i.e., humans remember the semantics, machines store exact word strings). Hence, we wanted to add to the literature by testing an idea that is almost part of the folklore of higher education: that is, that software tools are superior to human graders in detecting plagiarism.
Method
Research Questions
In the present paper, we investigated the potential of LSA and student teaching assistants to detect plagiarism. We analysed whether teaching assistants and LSA were sensitive to duplicates. The research question was whether LSA and human teaching assistants could detect partially and completely identical essays, and even if they could not detect plagiarism, would they at least rate completely identical essays as being equally good. Specifically, we investigated the following:
Is our software tool superior to human teaching assistants in detecting plagiarism? In other words, can LSA identify plagiarism more reliably than human teaching assistants both in vivo and in vitro, that is, respectively, in partially identical essays during the term and in completely identical essays in a specially constructed sample of essays? Do human teaching assistants and LSA evaluate duplicates as equally good (i.e., are the evaluations of human teaching assistants and LSA reliable)?
Participants
The setting for this research was a university psychology course for pre-service teachers. To pass the lecture ‘Introduction to Educational Psychology’, pre-service teachers answered two or three complex questions about the lecture material every second week. Fourteen teaching assistants who had attended the lecture in a previous term and who had received training for teaching assistants provided feedback to the students. Every teaching assistant had to supervise about 20 to 30 students (i.e., 10 to 15 students every week) and the same students throughout the term.
Text Material and Procedure
Analyses in vivo
We smuggled a fake person into the lecture whose name, Lina-Tessa Gropp, was an anagram of the German word for a person who commits plagiarism (i.e., ‘Plagiatsperson’). She seemed to be a regular student to the teaching assistants and was supervised by one of them throughout the term (i.e., Teaching Assistant 10). Under Lina-Tessa Gropp’s name, we submitted some fake essays. To create the fake essays, we used passages from essays that had already been submitted by fellow students and deleted or added or substituted some words (i.e., minor changes). We ensured that the fake essays were of average quality (i.e., inconspicuous in this regard). Thus, their content was meaningful but not original because the fake essays were partially identical to some of the real essays which were submitted by ordinary students. Lina-Tessa Gropp became cockier during the term: for Session 1 and 2, the fake essays included slightly modified passages from students whose texts were not read by the teaching assistant who read the fake person’s essays. Thus, it was almost impossible that she would be detected. However, the third fake essay – handed in for Session 3 – included slightly modified passages from two other students who were supervised by the same teaching assistant, who also was responsible for the fake person (i.e., Teaching Assistant 10). Thus, at least this case of plagiarism could be detected by the responsible teaching assistant. These data were used for the in vivo analysis to obtain a first impression of the efficiency of teaching assistants and the software tool in detecting plagiarism in a natural setting.
Analyses in vitro
To investigate the plagiarism-detection abilities of the teaching assistants and the software tool more systematically, after the term had finished, we had the 14 teaching assistants and LSA evaluate a sample of N = 60 essays on the topic of one lecture, retrospectively. In this sample, there were two completely identical essays (apart from a heading in one text). These data were used for the in vitro analysis. We observed whether the teaching assistants and the software tool could detect plagiarism and whether these two completely identical essays were evaluated as equally good. The teaching assistants were told that they scored the essays to analyse their inter-rater reliability. The sample consisted of a mixture of essays that were read by different teaching assistants during the term. Thus, some of the teaching assistants read some of the texts a second time.
Human evaluations
The N = 60 essays that were evaluated by the teaching assistants after the term were anonymized and presented in a random order. The teaching assistants were told to score the essays independently of each other but with the help of a specimen model solution and a scoring scheme. The essays could be assigned a minimum of 0 and a maximum of 10 points. The scheme listed the requirements for allocating a certain number of points and included the maximum number of points for each of the two tasks (with a graduation of 0.5 points).
LSA-based evaluations
A full description of how LSA works is beyond the scope of this article (see e.g., Landauer & Dumais, 1997; Martin & Berry, 2007). For the present investigation, we used a semantic space that was previously used in another study (Seifried et al., 2012).
The students’ essays were represented as vectors in this semantic space. LSA based its scores on a comparison with an ideal answer (i.e., a ‘gold standard’). The ideal answer was the specimen model solution that was available to the teaching assistants as well. The cosine between each text and the ideal answer was computed, and texts were ranked according to their proximity to this ideal answer. In order to project the rank of each essay to the raw point score used by the human graders, a normal rank transformation was applied by computing the respective z-score by means of the inverse normal cumulative distribution. One teaching assistant’s scores for two texts (i.e., those texts at the 10th and 90th percentiles) were used to adjust the scores for the remaining essays via linear regression.
To apply the LSA check for plagiarism, three teaching assistants were told to check all texts for plagiarism by using LSA after the term. The teaching assistants were instructed to compare all texts within ASSIST and list potential cases of plagiarism. They were not told that there were some partially or completely identical texts that they were supposed to identify. Thus, the check was conducted under real conditions.
Results
Detection of Plagiarism
In vivo (i.e., during the term), we had one fake person submit partially identical fake essays. None of them raised the suspicion of the responsible teaching assistant who supervised the fake person throughout the term. This had to be expected for Sessions 1 and 2 because the fake essays handed in for these sessions were made up of passages by students who were supervised by other teaching assistants and hence the duplicates were read by different teaching assistants. However, even when the fake essay included passages from students who were supervised by the same teaching assistant and hence this teaching assistant could have been able to detect plagiarism as she read both the original texts and the duplicate (Session 3), she did not detect it.
Single Teaching Assistants’ Evaluations, Teaching Assistants’ Average Evaluations, LSA-Based Evaluations, and Differences between the Evaluations of the Two Duplicates in the Sample of N = 60 Essays.
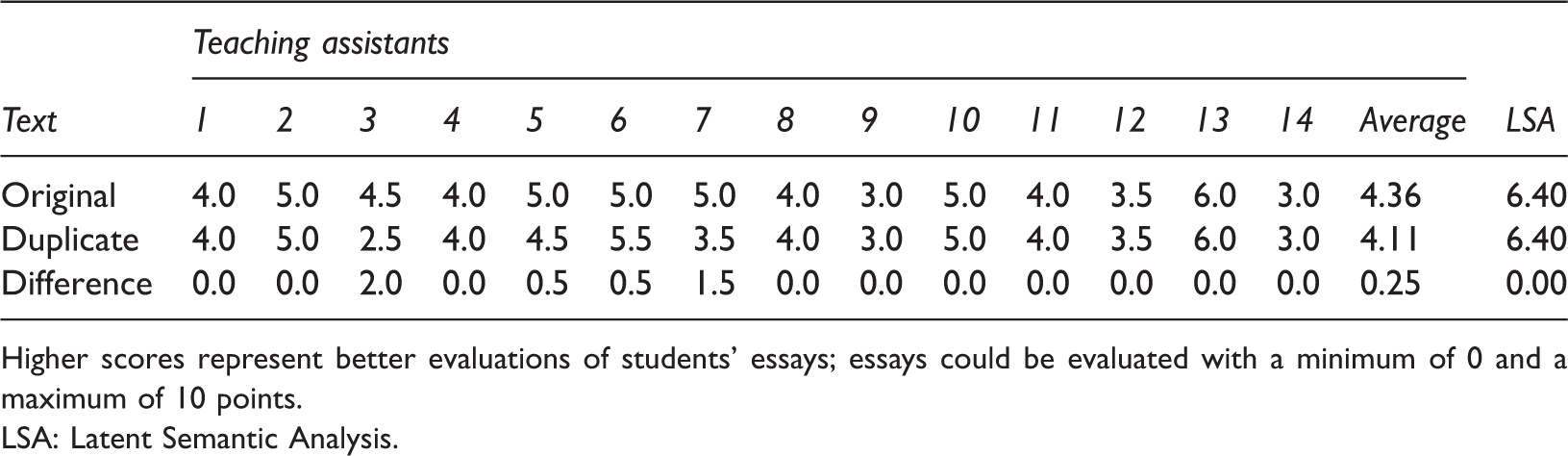
Higher scores represent better evaluations of students’ essays; essays could be evaluated with a minimum of 0 and a maximum of 10 points.
LSA: Latent Semantic Analysis.
When LSA was applied, the suspicious texts were easily identified by the plagiarism check at the end of the term. This was true for both the completely identical texts from the sample (in vitro analysis) and the complex duplicates that were composed of passages from several other students’ essays (including those partially identical essays that were used for the in vivo analysis). The completely identical texts that had been scored by all teaching assistants were at the top of the rank list for the respective session in ASSIST; the modified copies of other students’ texts were ranked at the top of the list for the respective session when it was copied from one other student only (Session 1) and at Ranks 81 and 29 (Session 2) or Ranks 83 and 5 (Session 3) when the texts were composed of modified copies from two different fellow students. These lower rankings were probably due to the fact that (a) the texts were ranked with respect to their semantic similarity rather than with respect to verbatim overlaps, (b) the essays included passages from more than one text (i.e., from one text for each subquestion), and (c) the plagiarism check was conducted on the texts as a whole. However, skimming the texts led to a clear suspicion of plagiarism because of the coloured text passages within the subtasks, and thus, these clusters of similar responses were identified as illicit teamwork. Further, because of the check at the end of the term, some more cases of plagiarism that had been undetected during the term were identified. By contrast, there were no cases of plagiarism that were identified by the teaching assistants but not identified by LSA.
Evaluation of Identical Essays
The single teaching assistants’ evaluations, the teaching assistants’ averaged evaluations, the LSA-based evaluations, as well as the differences between the evaluations of the two completely identical essays in the in vitro sample of N = 60 essays are shown in Table 1. 2
Although the majority of the teaching assistants (i.e., 10 teaching assistants) evaluated the duplicates as equally good, four teaching assistants did not score the essays the same: the identical essays were scored with a difference of 0.5 points by two teaching assistants (Teaching Assistants 5 and 6), 1.5 points by Teaching Assistant 7, and 2.0 points by Teaching Assistant 3. When LSA was applied, the identical texts were scored exactly the same.
Discussion
The present study was conducted to test whether human teaching assistants and LSA could detect plagiarism. If LSA was superior to human teaching assistants, there would be a benefit of using a software tool within the teaching format of having students write essays because cheaters might be detected more reliably. Further, applying a software tool to detect plagiarism might also help to reduce plagiarism in the future because studies have shown that ‘in deterrence, actions speak louder than words’ (i.e., students are not deterred from plagiarism by verbal or written warnings, but they are deterred when they know that teachers will check for it; Braumoeller & Gaines, 2001, p. 836).
The analyses computed to address Research Question 1 revealed that LSA was superior to human teaching assistants in detecting plagiarism; that is, LSA identified plagiarism more reliably than human teaching assistants. The in vivo data showed that the teaching assistant who had read partially identical texts during the term was not sceptical about this plagiarism. Further, although two texts in a sample of essays were completely identical, most of the teaching assistants did not notice the plagiarism (in vitro). This finding is in line with previous findings that showed that human graders are not good at detecting plagiarism (e.g., Landauer et al., 2003a; Shermis et al., 2003). On the other hand, all duplicates were easily detected by LSA.
The analyses computed to address Research Question 2 on the in vitro data showed that some of the human teaching assistants reached only a poor reliability and assigned considerably different grades to the identical essays. The same essay quality was not evaluated as equally good by four of the 14 teaching assistants. It is known that different markers can assign different marks to the same essay and that criteria and marking schemes might be helpful to improve inter-rater agreement (e.g., Newstead & Dennis, 1994). However, our study indicates that there might also be problems of intra-rater agreement despite the use of scoring schemes. It might be an interesting topic for future research to identify the features of a text or a marker that make for different evaluations of the same essay. However, the majority of the teaching assistants assigned the same score to both texts and thus, their evaluations were reliable. When LSA was applied, the two identical texts were evaluated as absolutely identically good or bad. This is a fact that might be an indicator of LSA’s potential to evaluate even our complex essays (semi-)automatically and thus another possible field of application for the software tool. We have addressed this in another paper (Seifried, Lenhard, & Spinath, submitted). While ranking the texts according to their semantic similarity might not be the best way to identify verbatim plagiarism, it is definitely useful to identify attempts to conceal plagiarism and to score essays based on their content.
Practical Implications
In our courses, we have one or two pairs of people who work together too much (i.e., who copy one another’s texts) every semester. The results of the present study imply that the common practice of employing teaching assistants to accompany a lecture might be improved by the use of a software tool. It is impossible for teaching assistants to detect plagiarism if they do not read all texts that make up the collusions. However, duplicates that are authored by several students who are not supervised by the same teaching assistant and therefore cannot be detected by teaching assistants will easily be identified with the help of our software tool. The same is true for sophisticated duplicates that are made up of the ideas of several students or that include synonyms or paraphrasing to disguise plagiarism because LSA is sensitive to semantic similarity. However, Mozgovoy et al. (2010) and Cosma and Joy (2012) pointed to the gaps in research concerning LSA’s use in plagiarism detection and to the fact that there are several parameters that influence the power of LSA. Thus, the results cannot easily be generalized.
However, because LSA was reliable in its evaluation of two completely identical texts, whereas this was not true for some of the teaching assistants, an implication for educational contexts might comprise the use of our software tool for scoring essays. We have already conducted studies that show that the correlation between LSA-based scores and human scores does not differ significantly from the inter-rater correlations of human graders (Seifried et al., 2012) and that LSA can be used to identify poor essays (Seifried et al., submitted). Another aspect might be to use LSA as a ‘second opinion’ to achieve objective scores as was suggested, for example, by Landauer et al. (2003b).
The present study shows that LSA can be useful for detecting plagiarism and possibly as a reliable second marker. Further, texts are easily collected within the system, texts can be compared within or across cohorts of students, and feedback can be assigned directly to the texts by teaching assistants. By using complex questions that ask students to give their personal opinion or analyse or criticize aspects, we can be quite sure that students will not find the answers to the questions in a textbook or on the Internet. Thus, it is sufficient to compare the texts only within our own database and, therefore, we do not have to deal with legal concerns that arise when using an external system (Purdy, 2005). However, students should be informed that their texts will be collected and stored for reasons of plagiarism detection. In our experience, students who are accused of plagiarism usually deny their misconduct at first, but then it is interesting to see that the accused persons come to defend themselves together in couples even though we have told them only that there has been ‘considerable overlap with another student’s text’. Often, one of the students then states that he/she is the one who is guilty and that the other person only wanted to help him/her. This (i.e., helping a friend) is a common cause of plagiarism (e.g., Ashworth et al., 1997). So, however or because of this, it is important to have students sign a pledge stating that they will not give away their own texts to another student (to optimize honour codes in different ways, see Gurung, Wilhelm, & Filz, 2012).
If students are aware of the application and efficiency of the software tool, they will most likely not dare to hand in duplicates of other students’ ideas. This might lead to a reduction in plagiarism (e.g., Braumoeller & Gaines, 2001). In fact, in the last few semesters, we noticed a decrease in the plagiarism rate as the only clearly plagiarized texts were self-plagiarisms (i.e., students were asked to improve their text and obviously used their former text as the basis of their new text). We also think that it is not easy to outwit a system that bases its evaluations and comparisons on semantic similarity: attempts to conceal plagiarism by the use of synonyms or the like should not influence the performance of LSA. Thus, although there is a fear that students might adapt to the software in order to avoid detection (Warn, 2006), this seems unlikely in our case because cheating the detection of plagiarism would require as much work as writing the essay on one’s own. Plagiarism would lose its function as a labour saver in this way (also see Owens & White, 2013). Thus, our results show that a desirable teaching format (i.e., having students compose essays, giving feedback to them, as well as assessing students’ achievements) can clearly be improved by the use of software tools.
Footnotes
Funding
This research was supported by the Innovation Fund FRONTIER at Heidelberg University (project number D.801000/10.25). We want to thank Dr. Herbert Baier for his work on ASSIST (i.e., a former version of βASSIST at the University of Würzburg) and Fabian Grünig for his work on βASSIST, Jane Zagorski for proofreading the manuscript and Steve Newstead, former editor of PLAT, for handling this paper.