
Abstract
Society is concerned about maritime accidents since pollution, such as oil spills from ship accidents, adversely affects the marine environment. Operational and strategic pollution preparedness and response risk management are essential activities to mitigate such adverse impacts. Quantitative risk models and decision support systems (DSS) have been proposed to support these risk management activities. However, there currently is a lack of computationally fast and accurate models to estimate oil spill consequences. While resource-intensive simulation models are available to make accurate predictions, these are slow and cannot easily be integrated into quantitative risk models or DSS. Hence, there is a need to develop solutions to accelerate the computational process. A fast and accurate metamodel is developed in this work to predict damage and oil outflow in tanker collision accidents. To achieve this, multiobjective optimization is applied to three metamodeling approaches: Deep Neural Network, Polynomial Regression, and Gradient Boosting Regression Tree. The data used in these learning algorithms are generated using state-of-the-art engineering models for accidental damage and oil outflow dynamics. The multiobjective optimization approach leads to a computationally efficient and accurate model chosen from a set of optimized models. The results demonstrate the metamodel’s robust capacity to provide accurate and computationally efficient estimates of damage extents and volume of oil outflow. This model can be used in maritime risk analysis contexts, particularly in strategic pollution preparedness and response management. The models can also be linked to operational response DSS when fast, and reasonably accurate estimates of spill sizes are critical.
Introduction
Marine shipping contributes enormously to economic and societal advancement globally. Although maritime safety has improved over time, ship accidents still occur. 1 Among accidents, oil spills undesirably affect not only economic areas but also the maritime ecosystem. Therefore, maintaining appropriate preparedness and response capability is crucial for coastal areas.2,3 Several risk analysis and risk management models and approaches have been developed to support strategic marine oil pollution preparedness planning.4,5,6 Likewise, several tools and approaches have been established to facilitate operational response to spills.7,8
In an oil pollution context, a Decision Support System (DSS) can help response authorities, vessel traffic managers, and other pertinent stakeholders to obtain a common operational picture of the oil spill, its predicted drift and weathering, and its expected impact on ecological and socio-economic use values of the marine space. Several DSS has been developed to assist in mitigating the risks of marine oil spills. Through such DSS tools, operational response activities can be better coordinated and the negative impacts of an ongoing spill minimized. 9 In essence, a DSS can help decision-makers utilize data, models, and other information to improve situational awareness and decide on appropriate mitigation measures and response strategies.
In the maritime risk analysis context of strategic planning, many approaches have been proposed to model maritime accidents and oil spills. 10 Comprehensive reviews of academic work proposing approaches and tools for assessing the risks of maritime shipping accidents are conducted by Li et al. 11 and Kulkarni et al. 12 Oil spill modeling tools can help managers with strategic preparation of response, for example, determining and allocating response resources. 13 An overview of strategic and decision support frameworks for offshore oil spill response is given by Li et al. 14 focusing on oil spill diagnosis and emergency in severe offshore conditions.
To be effective, DSS and risk analysis for pollution preparedness and response (PPR) rely heavily on consequence models. Such models are used to identify and simulate accident scenarios as a basis for estimating the characteristics of oil spills and their consequences. Given the dearth of accidental spill data, especially in areas with low traffic volumes and without historic oil pollution accidents, such as the Canadian Arctic, consequence models have an essential use in pollution preparedness risk assessment, 15 and are also essential in operational DSS. 9
A first element of such consequence models concerns oil spill drift forecasting. 16 Such models can simulate the movement of the oil slick in the sea area. Several such models have been proposed, see for example, Spaulding 17 for a review. A second element concerns accidental oil outflow models which can quickly provide an estimate of the likely spill size. This estimation is often one of the significant uncertainties in the early stages of the accident response. 18
Most existing consequence models have significant limitations. For instance, experimental consequence models are constrained to small and medium scale structures. Furthermore, large or full-scale experimentations involve mammoth testing facilities and high costs. 19 Numerical methods such as Finite Element Analysis suffer from extensive modeling effort (as each accident case requires its simulation) and high computational costs. Influence of ship bulkhead on grounding resistance and size of damage can be estimated by numerical methods. 20 Furthermore, there often is a lack of detailed information about hull structures in the immediate response phase needed to perform such computations. Analytical methods can often mitigate the limitations of numerical ones; for instance, the structural response of collision scenarios, 21 the damage openings in grounding 22 can be assessed using analytical methods with reasonable performance. A fast and accurate modeling approach is necessary to counteract the limitations of existing modeling approaches for damage and oil outflow for collision accidents. Metamodeling techniques have been commonly used as alternatives for models with a long runtime in various engineering applications. 23 Metamodels can provide economical and reasonable substitutes for applications where Monte Carlo Simulation (MCS) or other uncertainty quantification approaches are needed.24,25 Given the importance of considering uncertainties in risk assessment, 26 metamodeling therefore present a plausible approach to develop fast and accurate spill models.
This research aims to create an accurate, fast-running metamodel for estimating damage and oil outflow in tanker collision accidents, as ship collision is one of the most hazardous accidents with severe consequences. 27 This model is targeted to be used in operational DSS and maritime risk analysis. Figure 1 outlines the impacts and consequences of oil spill disaster on the ecosystem and human society, and addresses inputs connected to the oil spill risk. 13 For example, quick shoreline and offshore response may lead to a short-term economic impact. Nevertheless, this short-term impact is compounded by further impacts on health, societal and ecosystem services which can exacerbate long-term economic impacts. Models capturing the complexities of these short- and/or long-term impacts of spills can assist both operational (DSS) and strategic (long-term preparedness planning) risk management.
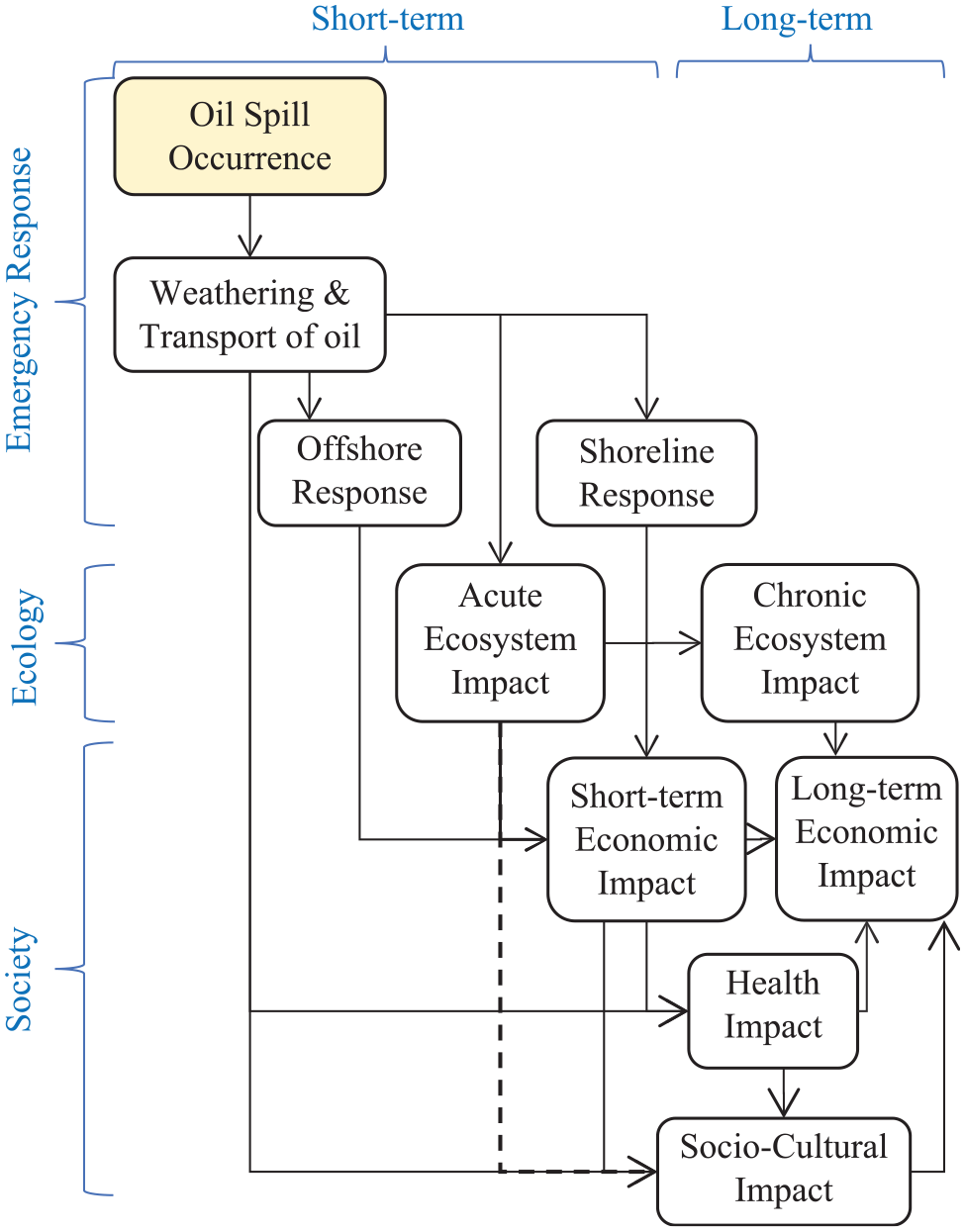
An oil spill response framework within the context of PPR; adapted from Parviainen et al. 13
The current work aims to contribute to the Oil Spill Occurrence context in the upper left corner of Figure 1. In particular, the aim is to develop a model for quickly and accurately estimating damage and spill sizes in tanker collision accidents, using a multiobjective optimization metamodeling approach.
The remainder of this paper is organized as follows. In Section 2, the literature on oil spill modeling and metamodeling and their limitations to estimating damage and oil outflow in a collision is briefly reviewed. The dataset and the methodology of developing an optimized metamodel are presented in Section 3. In Section 4, metamodels are developed and optimized based on their hyperparameters; consequently, one metamodel is selected from the developed ones. Section 5 discusses the advantages and limitations of the approach and resulting model, while Section 6 concludes.
Literature review
Modeling of oil spill
Oil spill models are essential elements of maritime risk assessment and DSS tools for pollution response operations. Oil outflow models can be categorized into numerical, experimental, probabilistic, or semi-analytical models. Although numerical models of collision damage assessment have high accuracy, especially Finite Element models, they are time-consuming and computationally expensive. 28 Ehlers and Tabri 29 developed a faster semi-analytical procedure based on FEM models, which therefore is more appropriate for risk analysis contexts. This simplified approach was further developed in Heinvee and Tabri 30 and provides as a output the description of the extent of damage size that is central information for direct oil outflow simulations.
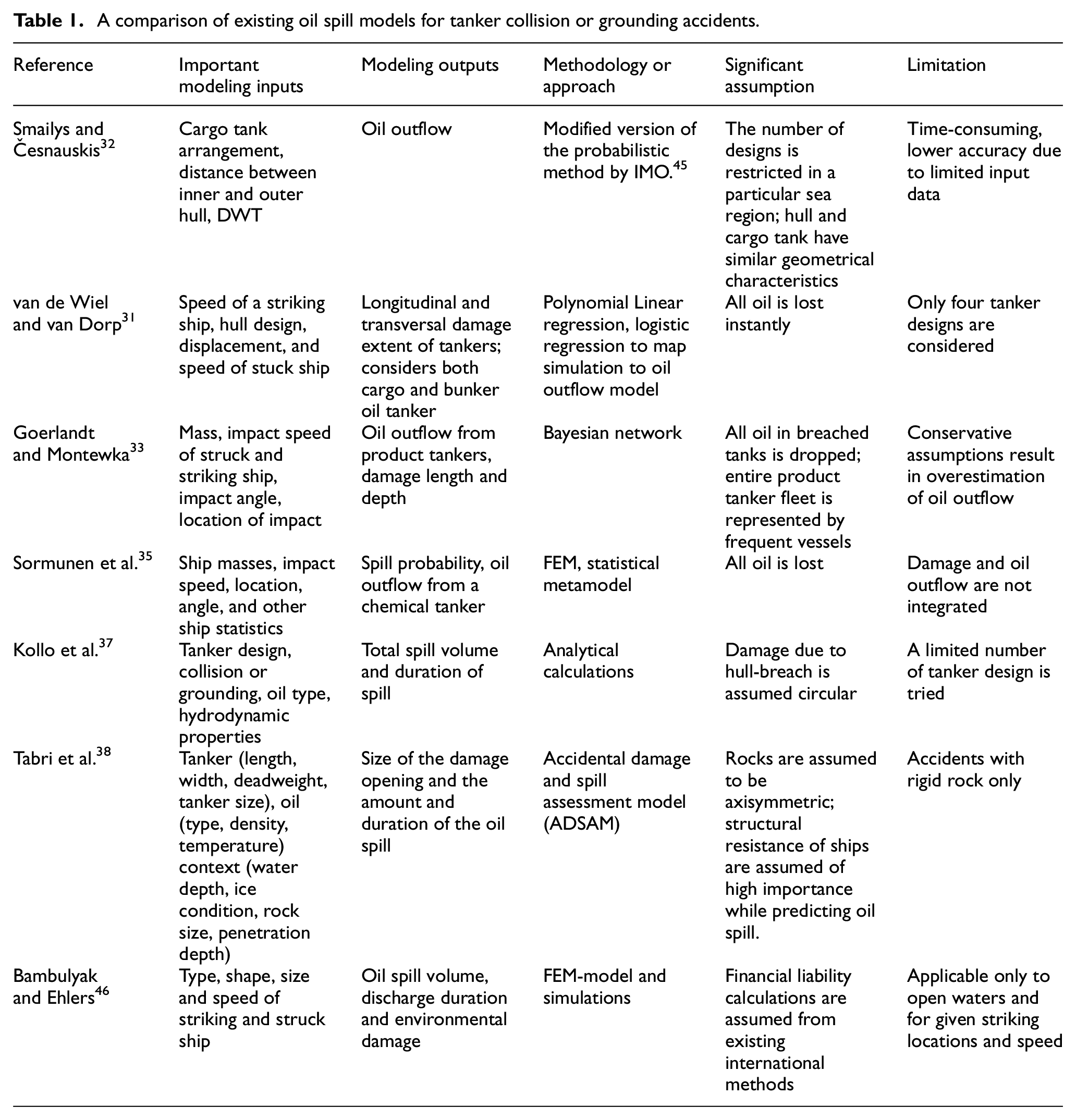
Many analytical and semi-analytical outflow models have a significant runtime, which effectively precludes their use in uncertainty quantification contexts. A summary of previous work to develop oil outflow models for tanker collision accidents is presented in Table 1. The oil spill model, proposed by van de Wiel and van Dorp 31 presents the volume of oil outflow from longitudinal and transversal damage extents during tanker collisions and groundings accidents obtained from the SR259 report. However, they consider only a few tanker designs and significant assumptions are made, for instance that all oil from a damaged tank is spilled. Estimating oil outflow from a tanker vessel in collisions or grounding casualty with limited input data and tanker design is proposed by Smailys and Česnauskis. 32 A Bayesian network (BN) model is proposed by Goerlandt and Montewka 33 for assessing accidental cargo oil outflow and its uncertainty during a collision. Another BN-based model to counteract the assumption that all oil is spilled upon accident is proposed by Goerlandt. 34 A spill model based on logistic regression is proposed by Sormunen et al. to estimates collision consequences for chemical tankers. 35 These types of models can be helpful for DSS design and risk analysis. However, several simplifications are made during the modeling process, for example, the assumption that no oil is spilled when the striking location is closer to the struck ship’s bow, or the assumption that all oil is instantly spilled, result in lower performance accuracy for real situations. In addition, many models for oil outflow from a damaged ship of tanker accidents, such as Tavakoli et al., 36 Kollo et al., 37 and Tabri et al., 38 do not integrate damage estimates with oil outflow calculations.
A comparison of existing oil spill models for tanker collision or grounding accidents.
Considering the limitations of consequence modeling tools discussed above, the overall purpose of this paper is to build a faster, accurate oil spill model based on state-of-the-art damage and outflow models. Disadvantaged by the computational burden to achieve good accuracy, existing engineering models of hull damage and oil outflow require improvement, especially in their runtime. Metamodeling is expected to alleviate this limitation. 39
Metamodeling
A metamodel is a model of another model which captures the underlying relationship between input and output variables. 40 A metamodel or surrogate model mimics a physical or computational model. 41 An oil spill estimation metamodel can help reduce computational resources needed for physical engineering models. 16 Popular metamodeling methods originate from the machine learning literature.39,42 Collision damage probability and spill volume to chemical tankers have been estimated by a logistic regression metamodel proposed in Sormunen et al. 43 Metamodels can help decision-makers to consider risk associated with failure probability. 44
Among various metamodels, Deep Neural Network (DNN), also known as Artificial Neural Network, is a quite promising approach for the current objectives. Papanikolaou 47 proposed a DNN to predict collision damage. Neural Network-based metamodeling has been used in different areas, such as in ship motion modeling of offshore operations. 48 However, there is limited literature on DNN based metamodels to address the integrated collision damage and oil spill problem, whereas DNNs have been used in other maritime applications. The DNN in Li et al. 49 offers a fast and accurate approach for ship-ice interaction calculation. DNN model combined with MCS to assess collision damage quantitatively is proposed by Sun et al. 50 This modeling replaces iterative FEM runs within the MCS procedure. Fuel consumption of sailing vessels is estimated using DNN, as proposed by Tran. 51 The DNN modeling can predict ship-ship collision damage size, influenced by dropped objects’ collision. 52
The polynomial regression metamodel proposed in Montewka et al. 53 connects the impact scenario variables to the longitudinal and transversal damage extents. A metamodel based on quadratic polynomial regression to approximate oil or other outflows from a reservoir is proposed. 54 Polynomial metamodel has been used to perform risk analysis via simulation of an oil spill. 55
Gradient Boosting Regression Tree (GBRT) is an ensemble data learning algorithm that combines decision trees to model a given problem. A gradient boosted tree and other algorithms are implemented to compare oil spill identification performance from imagery data in Xu et al. 56 Shoreline oiling probability is predicted using boosted regression tree to help tactical decision-making in pollution preparedness and response. 57
Methods and data
In this section, the problem formulation and the dataset are outlined. Thereafter, an explanation of the metamodels’ architecture and performance measures is given, as well as the multiobjective optimization approach to find a better performing metamodel for tanker collision damage and oil spill. The overall process is summarized in Figure 2.
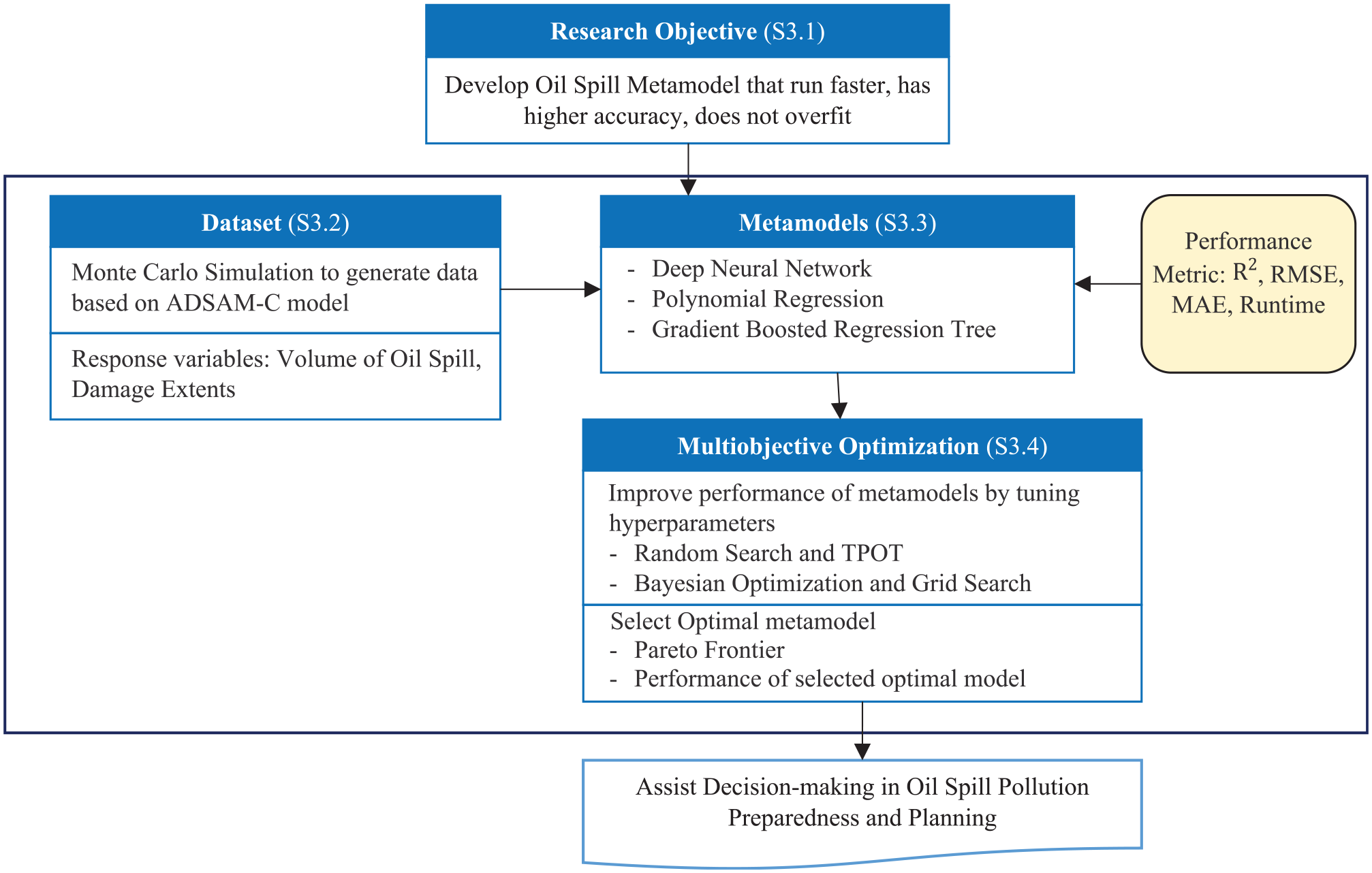
The overall methodology to develop metamodels of oil spill; “S” stands for Section in S3.1, S3.2.
Problem formulation
Like other engineering analyses, modeling an accidental damage extent and oil spill can be formulated by supplying input variables

The current work aims to develop a metamodel that runs significantly quicker than the underlying base model. Furthermore, it should have a high accuracy of predicting the output variables (damage extent and oil outflow), while not overfitting the data (generalize on test data). These objectives can be rephrased as below in more specific machine learning terminology:
Maximize an accuracy-related performance metric during the training and validation stage
Maximize a performance metric on an unseen dataset so that the metamodel does not overfit the data
Minimize the run time of the metamodel
Description of data
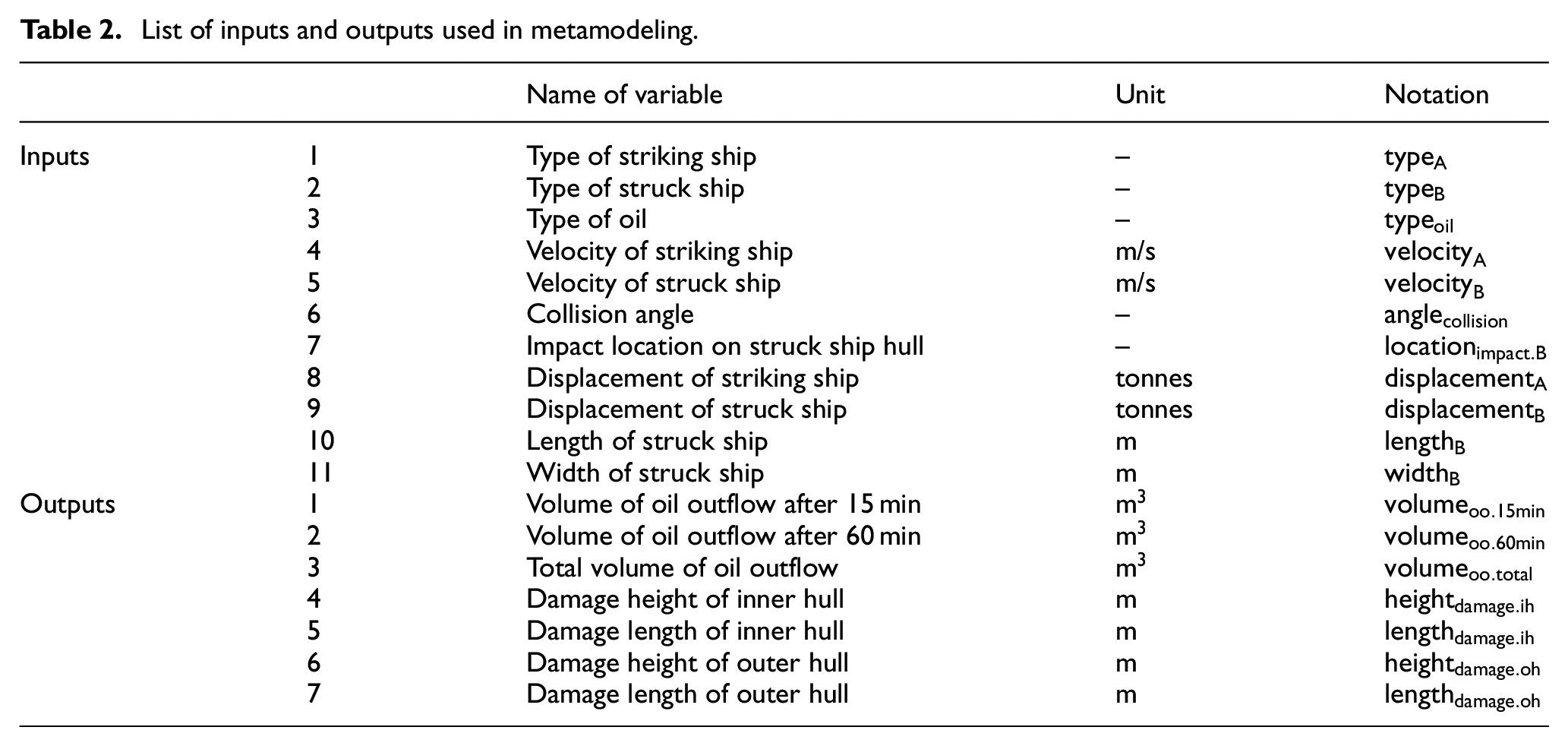
The dataset is generated using the MCS of the ADSAM-Collision model, introduced in Section 3.3. An oil spill dataset containing different ship properties such as velocity, length, and type of the striking and struck ships for individual accidental scenarios is generated. Each record in the dataset corresponds to a possible accidental oil spill and associated damage length, height, and depth, with the oil spill volume estimated in different time steps. Since actual data on accidental oil spills are scarce, MCS is leveraged to simulate the dataset representing oil spills’ accident cases. The MCS is performed based on the input parameters presented in Table 2, their sampling distribution and evaluation of accident cases and subsequent oil spills. A stable distribution of outputs can be obtained by running different combinations of inputs. In this study, seven types of striking ship, fourteen types of struck ship, and four types of oil of ADSAM-C leads to 392 combinations (260 of these combinations are feasible as not all ships carry all types of oil). Running each 260 combinations of scenarios 400 times results in 104,000 accident cases. Although many distributions for inputs are proposed in different literature, the uniform distribution of inputs is used to generate the dataset. Uniform distribution seems adequate for model development, as it ensures that the whole space is adequately covered. 58
List of inputs and outputs used in metamodeling.
ADSAM-C
The Accidental Damage and Spill Assessment Model Collision (ADSAM-C) is used to generate the input-output relationships in the dataset used in this research. ADSAM-C is an integrated model, based on tanker vessel design from Goerlandt et al., 59 collision damage models developed in Ehlers and Tabri, 29 Heinvee and Tabri 30 and an oil outflow model proposed in Kollo et al. 37 The input variables in the ADSAM-C model are the types of the tanker and impacting vessels involved in a collision, the speeds of the tanker and impacting vessel, the type of oil, and the impact location. The output variables are the volume of oil spills after 15 min, 1 h, and 24 h. As the dataset of training scenarios is based on designs of tankers, the resulting metamodels will primarily be applicable for risk analyses of such ship type (i.e. tankers) and for sea areas where comparable tankers operate.
Input and output variables of metamodeling
The types and velocity of the striking and struck ship, type of oil, and impact location (inputs of ADSAM-C) are taken as inputs in metamodeling of oil spill, shown in Table 2. Some additional inputs, including displacement of striking ship and displacement, length, and width of the struck ship, are also utilized. The selection of the displacement of striking and struck vessels as an input of oil spill modeling is justified in van de Wiel and van Dorp.
31
According to Sormunen et al.,
35
length and width of the struck ship are statistically significant input variables. In strategic and operational risk analysis contexts, the above input variables are readily accessible – for instance, main ship dimensions can be accessed from Automatic Identification System (AIS) – to analysts and decision-makers during response planning. The striking vessel and struck vessel speeds range from 1 to 15 and 0.5 to 15, respectively. Four types of oil are considered including Gasoline with density of 764
In light of outputs (also known as response variables or targets) of the model, the volumes of oil spills from ADSAM-C are considered. Additionally, damage length, and height of the struck ship’s inner and outer hull are taken as outputs. Since there are seven outputs, the problem becomes a multivariate regression problem. To sum up, eleven inputs and seven outputs are considered for modeling, as listed in Table 2. This selection is reasonable (because of the availability of inputs needed and the key outputs decision-makers are seeking knowledge about) in strategic pollution preparedness and response contexts and for a rapid estimation for operational response DSS. 60
Train and test dataset
Data splitting is a crucial step in the development of machine learning models. From the dataset, 80% of the records are taken as a training dataset (10% of this training dataset is considered as the validation set). The remaining 20% of the records are taken as a test dataset (never used during training). The test dataset’s fundamental purpose is to verify whether the developed models will perform well enough to unseen data. This train-test splitting is in line with broadly accepted practices. 61 The development and optimization of machine learning algorithms use a training dataset, whereas comparison among models is conducted on the test dataset.
Premodeling data exploration
Data exploration is performed to find meaningful patterns or insights from the data, which is valuable in data modeling processes. A small portion of the dataset (10%) is taken for data exploration. Each output can be communicated as a distribution. Figure 3 delineates the distributions of responses: the damage height and length of the stuck ship’s inner and outer hull. It is observed that none of these outputs are following normal distribution. For instance, in Figure 3(a) nearly 70% of records of the output variable
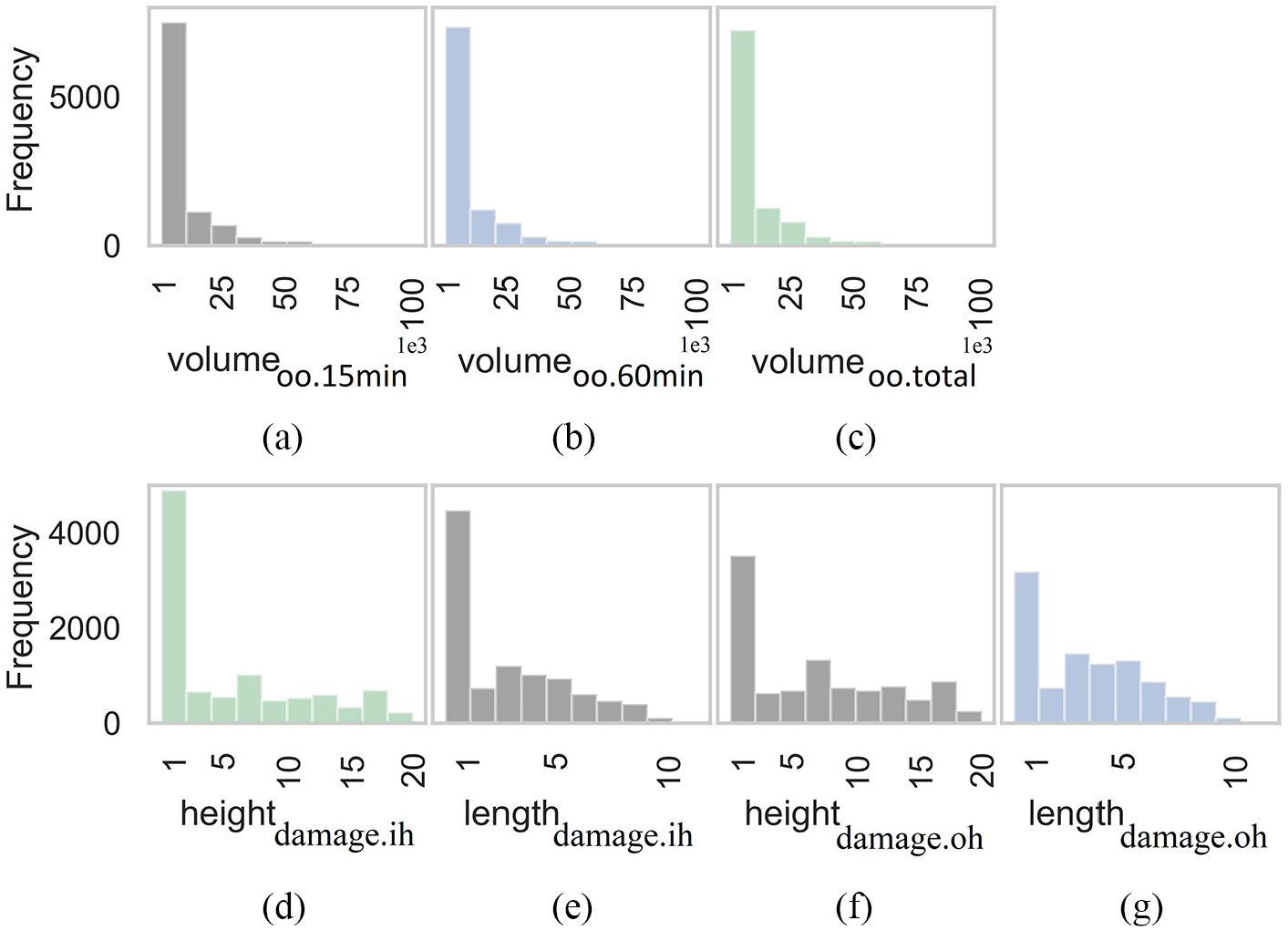
Histograms of outputs: (a–g) represent distributions of seven output variables.
Furthermore, Figure 4 displays the Pearson correlation between diffident inputs and
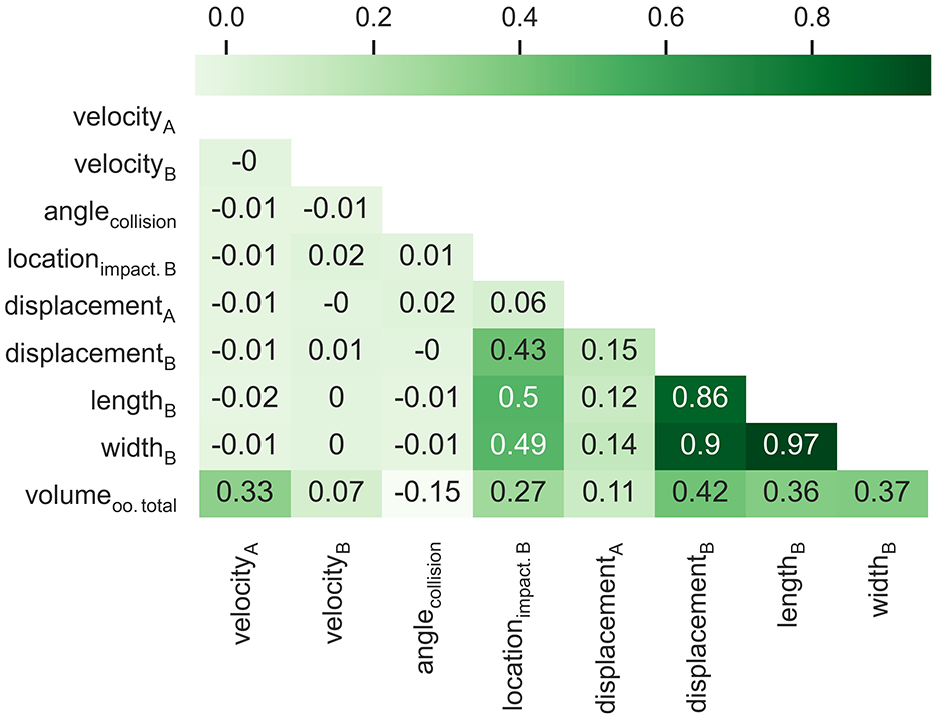
Correlation between numerical inputs and

Scatterplot representing Nonlinear relation between inputs and outputs.
The data is preprocessed as required for modeling. For example, all input and output variables are normalized between zero to one before modeling as DNN, PR, and GBRT expect normalized data. 61 Since regression models will not correctly handle categorical inputs, a ordinal encoder is used to convert them into numerical values.
Development of metamodels
The choice of the metamodel is not always straightforward. The dataset constructed in Section 3.2 contains 104,000 records, and most inputs maintain a nonlinear relationship with outputs, shown in Figure 5. A list of metamodels for computer-based engineering design proposed in Simpson et al. 63 is inspected. Three model types are selected for the nonlinear metamodeling problem: DNN from neural network-based models, PR from traditional statistical models, and GBRT from tree-based models. A DNN performs well for highly nonlinear and computationally expensive applications with more than 10,000 training data points. 63 PR is another popular algorithm to capture nonlinear non-Normal data. 64 Furthermore, GBRT is easily interpretable in identifying necessary inputs for output in nonlinear cases. 65 Hence, applying DNN, PR, and GBRT appear sensible.
Metamodel based on DNN
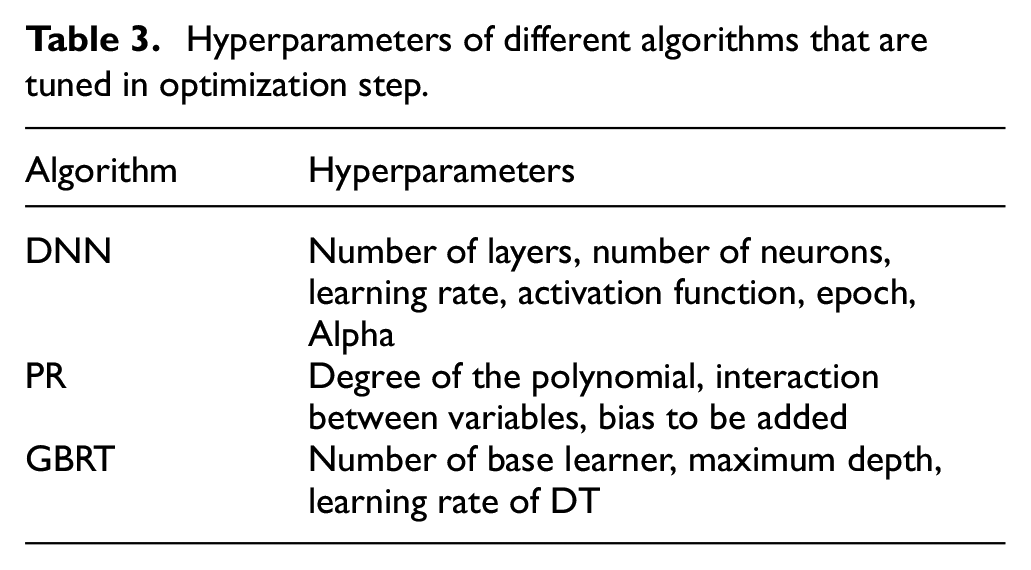
Neural networks are nonlinear statistical data modeling or decision-making tools. They can be used to model complex relationships between inputs and outputs or to find patterns in data. Designing a DNN architecture involves making choices of model’s hyperparameters: activation function, the number of hidden layers, the number of hidden neurons per layer, the shape of the loss function, the learning rate. 66 In this study, there are eleven inputs and seven outputs, as shown in Table 2. Hence, there should be eleven input layers and seven output layers. An optimum combination of hidden layers (and number of neurons) and the learning rate will be determined during the optimization step explained in Section 3.4.
Metamodel based on PR
Polynomial Regression (PR) is a modeling technique where the relationship between inputs and outputs is established as a polynomial of degree k as shown in equation (2) where
Hyperparameters of different algorithms that are tuned in optimization step.
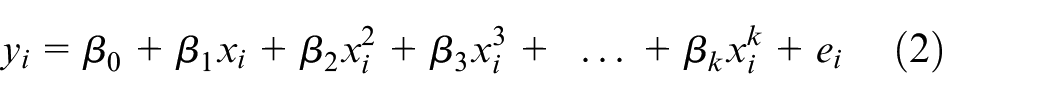
Metamodel based on GBRT
Gradient Boosting is an ensemble technique (sequentially fitting a simple model to the residuals) based on regression trees. 68 In this study, a collection of Decision Tree (DT) is taken as a base learner to be boosted. The DT’s hyperparameters include the number of estimators, the maximum depth (the number of nodes in the tree), and the learning rate that governs how much each tree’s contribution will shrink.
Optimizing metamodels
Choosing random values of hyperparameters often leads to poorly performing models, so finding better values is imperative. The performance of machine learning algorithms can largely depend on particular hyperparameters. Thus, finding an appropriate combination of hyperparameters is crucial to ensure the metamodels will gain better performance measures such as a lower error or higher
In this study, Random Search and Tree-based Pipeline Optimization Tool (TPOT) 72 are applied into a more extensive sample space, then Grid and Bayesian Search are applied in more refined search space. In other words, a random combination of larger sample space of different hyperparameters (e.g. 15 different values of learning rate and 12 different number of hidden layers in DNN) is explored by Random Search & TPOT. Then, within the potential space obtained by them, a smaller combination of different hyperparameters (e.g. two different learning rates with two different number of hidden layers in DNN) is exploited by Grid Search & Bayesian Optimization.
In random search, unlike grid search where all values are used, only a predefined number of combinations (selected by statistical distribution of hyperparameters) are attempted. A TPOT 72 is also applied to automate machine learning pipelines utilizing Evolutionary Algorithm (EA). The knowledge about hyperparameters’ values obtained from random search and TPOT is used as prior knowledge in Grid Search and Bayesian Optimization. In Grid Search, all values within the selected search space are tried. Bayesian optimization73,74 is another state-of-the-art optimization framework for machine learning algorithms’ hyperparameter tuning. It is an iterative algorithm comprised of two main ingredients: a probabilistic substitute model and an acquisition function to determine which point to assess after that.
Performance metrics
Model evaluation is crucial in data science as it assures the model’s adequacy for its intended use. In this study, model evaluation is conducted using four performance metrics:
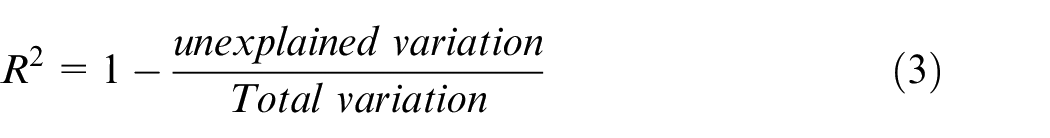
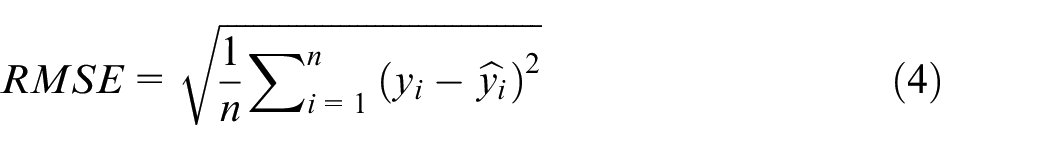
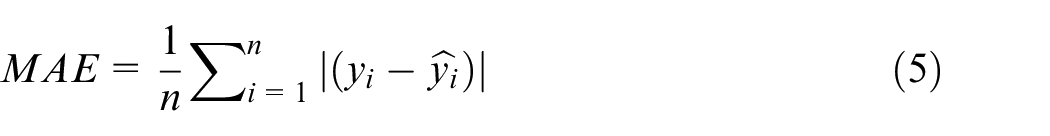
Model development and optimization of hyperparameters of each model are conducted using only
Determining optimal metamodels
The performance of metamodels is statistically and visually compared. First, the
Results
In this section, the different metamodels’ performance is described first. After that, the final optimal model and its parameters are demonstrated (refer to Figure 2 for the metamodeling workflow). The algorithms are executed on a laptop equipped with Intel Core i5 1.6 GHz processor (64-bit operating system) for running all experiments. GridSearchCV, RandomSearchCV, MLPRegressor, PolynomialFeatures, and GradientBoostingRegression from Scikit learn 76 are utilized.
Model development and optimization
A DNN is initially built with one hidden layer of 16 neurons, learning rate of 0.8 and a logistic activation function. With these hyperparameter settings, the DNN model has a
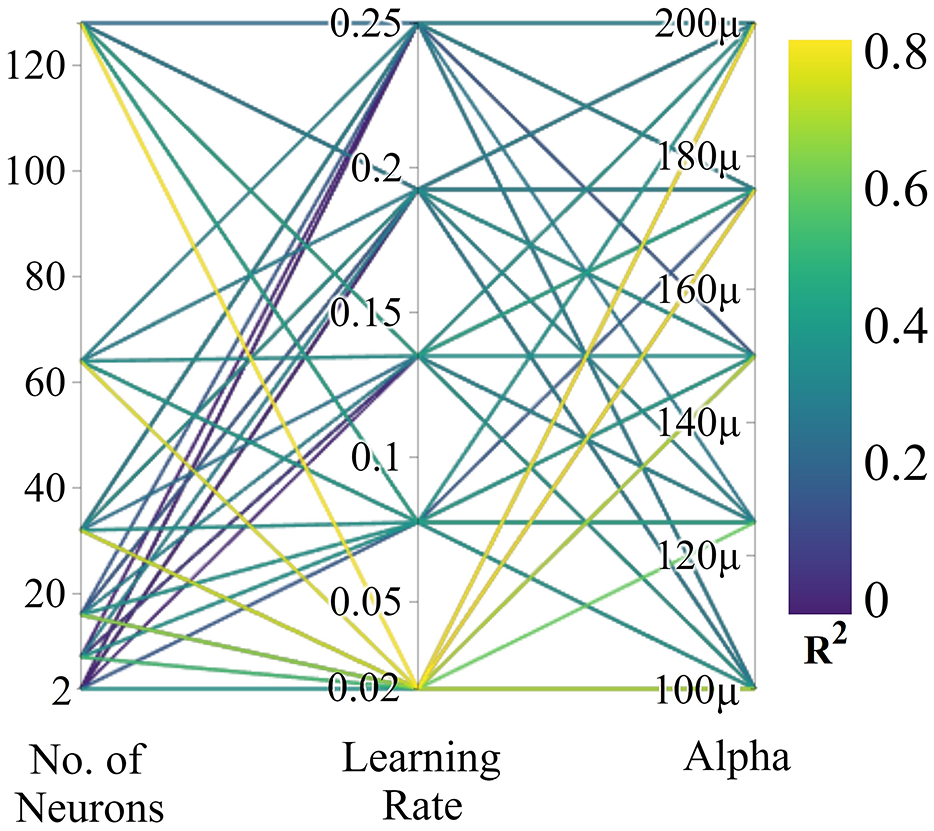
Parallel coordinate plot, produced in random search of hyperparameters in DNN development. Vertical colorbar represents
The values of hyperparameters of different algorithms in Random Search (RS), Evolutionary Algorithms using TPOT, Grid Search (GS), Bayesian Optimization (BO) using HyperOpt are illustrated in Table 4. During hyperparameter tuning of DNN-based models, it is observed that TPOT leads to the highest value of
Possible best results obtained by combination of hyperparameters in training dataset.
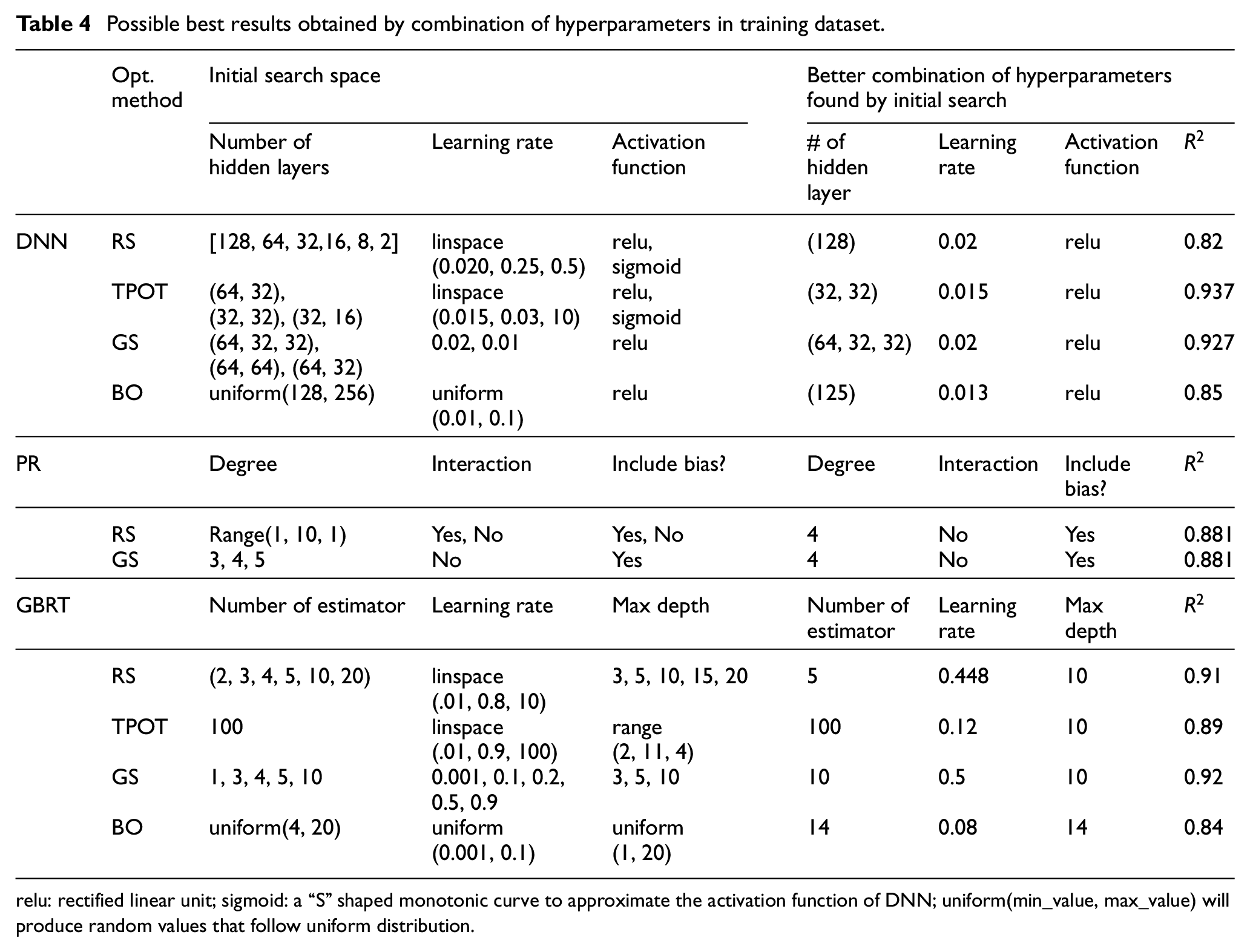
relu: rectified linear unit; sigmoid: a “S” shaped monotonic curve to approximate the activation function of DNN; uniform(min_value, max_value) will produce random values that follow uniform distribution.
Selection of optimal metamodel
Comparing models
All models’ performances are compared using test data (accident cases that are not used during training or hyperparameter tuning stages). Point plot is a reasonable way to perform a comparative study on several machine learning algorithms, as mentioned in Section 3.6. Figure 7 represents the values of
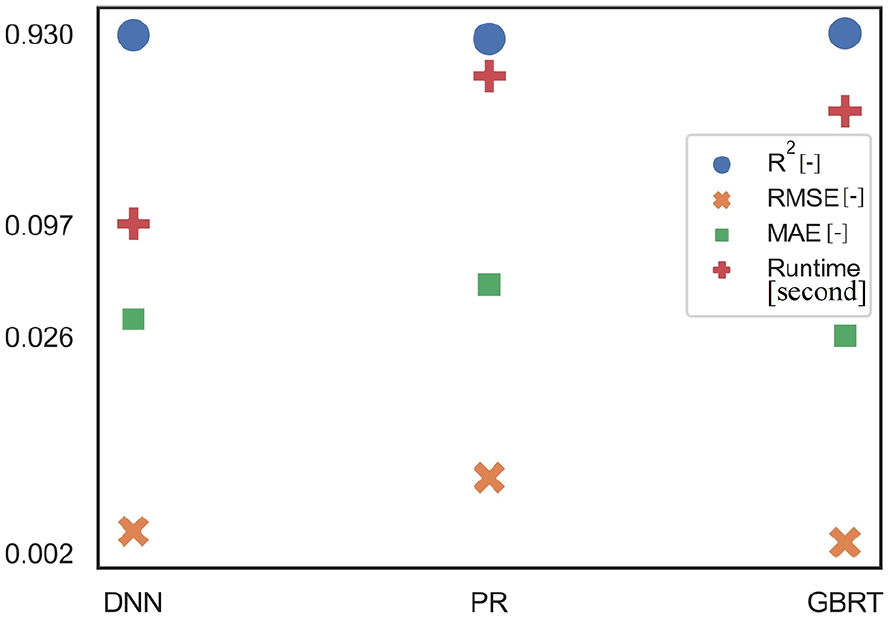
Visualizing performance metrics for the best metamodels using test data; [−] represents unitless in
Although GBRT has the lowest MAE value, it comes with the algorithm’s cost of the runtime. DNN provides higher predictive accuracy and takes less time to run compared to PR and GBRT. The DNN took only 0.09 s, whereas PR and GBRT took 0.57 and 0.37 s, respectively, to run a test on accidental oil spill scenarios. This gap in a calculation time of about a quarter of a second between GBRT vs. DNN may appear insignificant but is significant. Such importance is due to oil spill risk analyses; thousands of accident scenarios may need to be computed and further analyzed for response decision-making of oil spills. Furthermore, the original ADSAM-C model has an average runtime per scenario of about 1.6 s. This runtime confirms that the developed metamodels run considerably faster, indicating their significance for oil spill risk analysis.
DNN ensures a proper balance by providing optimized values of
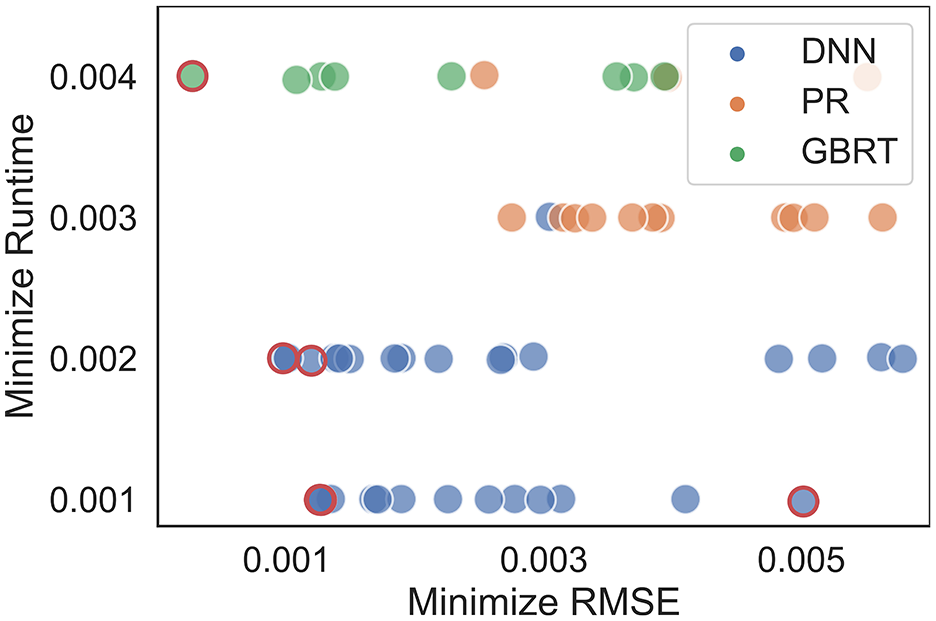
Scatterplot to show trade-off between predictive accuracy versus computational time; red circles construct Pareto Front.
Optimal metamodel and its parameters
As introduced in Section 3.6, the optimal metamodel structure and estimators are presented in Figures 9 and 10, respectively. The final DNN architecture contains 64 neurons in first and second hidden layers with relu activation function and a learning rate of 0.009, as shown in Figure 9.
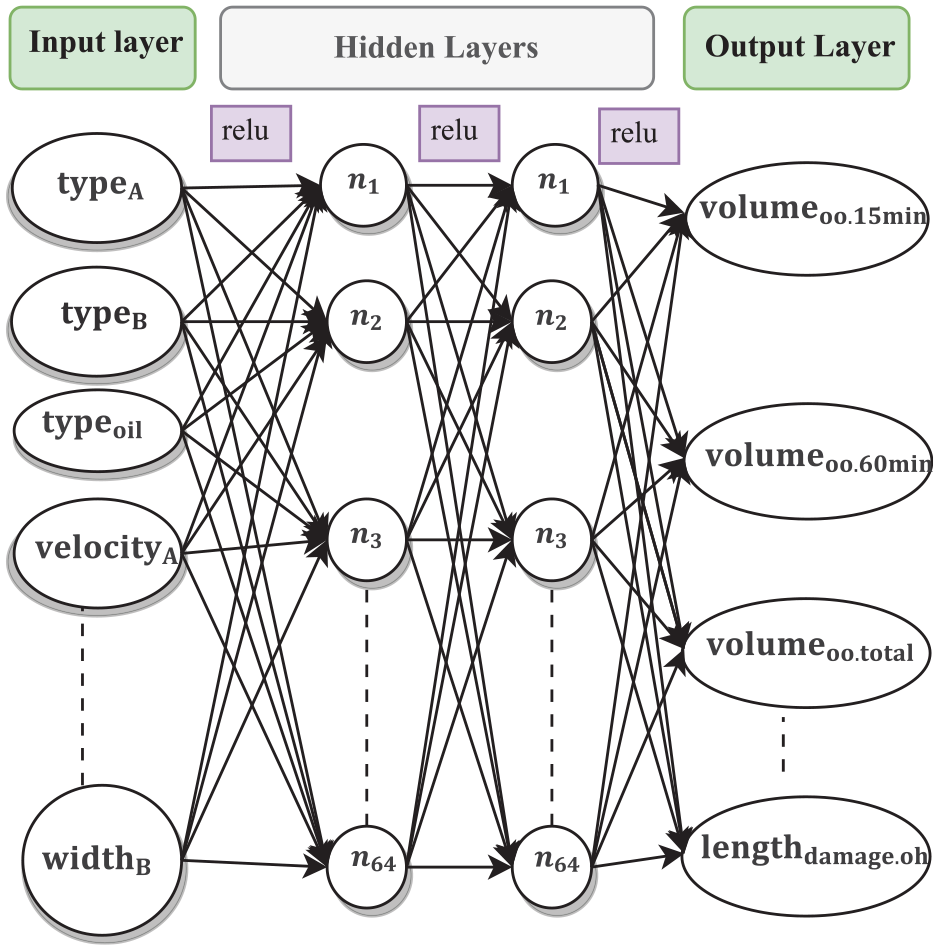
Architecture of the best-performing DNN.
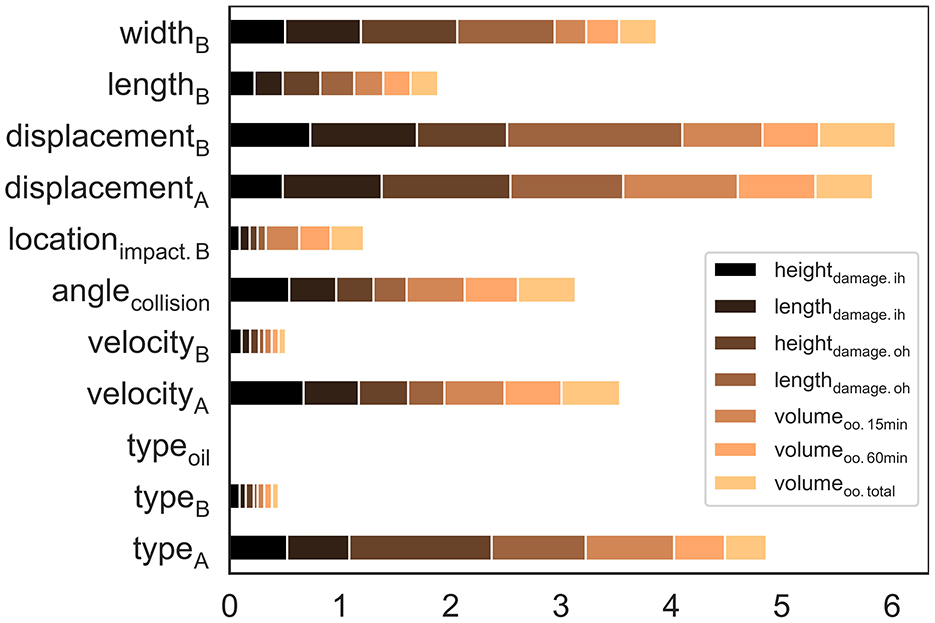
Variable importance plot of DNN metamodeling.
Figure 10 demonstrates the variable importance plot of the final DNN-based metamodeling. Importance in this context refers to how much the model uses a particular input variable to predict output variables. Some input variables namely
Discussion
Based on the need for a model that uses comparatively little computational resources while providing accurate estimates of damage dimensions and oil outflow sizes from tanker collision accidents, a metamodeling approach is proposed in this work. The performance of these metamodels is assessed using performance metrics introduced in Section 3.5. This research has proposed a novel methodology, outlined in Figure 2, to develop a metamodel for accidental oil spills and hull damages under a range of ship-ship collision accident scenarios. A set of models is developed which provide a reasonably accurate and computationally efficient way to characterize the immediate consequences of ship-ship collision accidents involving tankers without relying on time-consuming and computationally exhaustive physical simulation. Consequently, the metamodels developed in this work are valuable tools to support various maritime risk management activities, especially for making risk-informed decisions for pollution preparedness and response and operational spill response operations.
Considering multiobjective optimization of maximizing test accuracy and minimizing runtime of algorithms, Pareto Front (in red) has been developed in Figure 8. A few well-performed metamodels’ RMSE and Runtime are drawn as scatterplot. When both computational time and accuracy matter, the five models demarcated by a red circle would be helpful. Decision-makers will likely find DNN more convenient as it runs faster (blue filled circles in the Pareto Front). For instance, a DNN-based metamodel can take only one millisecond to estimate an accidental collision. To sum up, the choice between data learning models is a goal and preference dominated.
The proposed approach (multiobjective optimization of model designs) advances state of the art in an oil spill and damage modeling because in earlier work, for example, presented in Table 1, just one model design is made, without further investigation of that one model’s performance in light of choices made concerning hyperparameters. In future work, this optimal model can be utilized to estimate the volume of oil outflow in different accident scenarios, and the model can be integrated into oil spill risk analysis models 13 and operational DSS.9,38
The proposed modeling approach will contribute to maritime risk modeling. However, considering Black Swan (rare and massive oil spills), the regression plot in Figure 11 substantiates that all metamodels perform poorly after
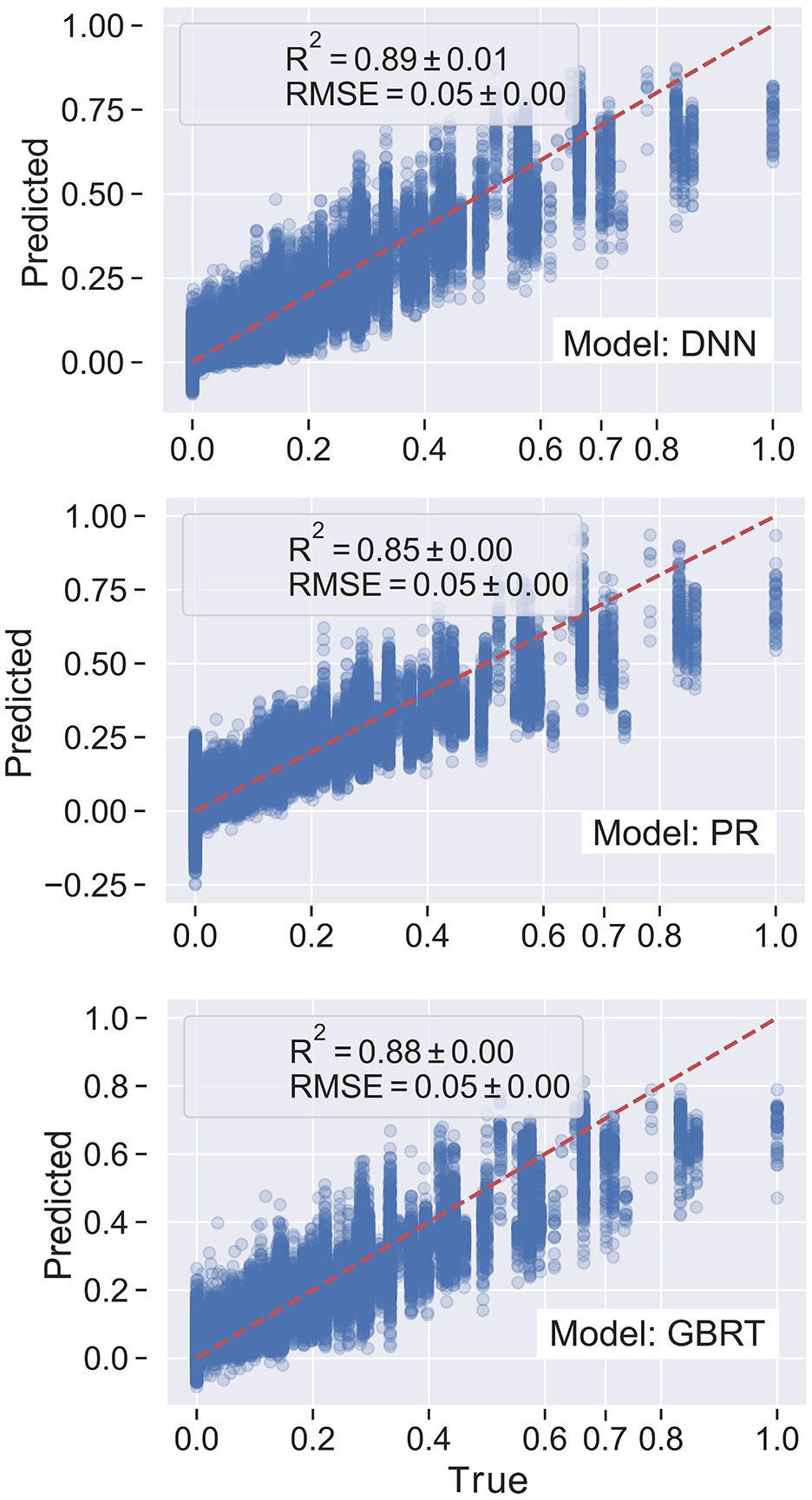
Examining Black Swan (or any extremities) and models’ performance.
Conclusions
Estimating damage extents and the volume of oil spills during ship-ship collision is a prime concern for decision-makers in maritime pollution preparedness and response risk management. This paper reviews the state-of-the-art models and metamodel-based methods for estimating oil spills and damage extents in tanker collision accidents. A metamodeling technique is proposed to estimate the volume of the oil spill and damage extents in accidents by formulating the problem, designing the models’ architecture, tuning hyperparameter, and improving the model’s performance. Hence, a simple but accurate and fast calculation tool is introduced in the form of metamodels for estimating the volume of oil in the event of tanker collision. Such estimation models can assist marine PPR risk analysis and operational DSS for oil spill response.
A decision support system can be developed as a future work that will incorporate oil outflow prediction from the proposed metamodel with other aspects of the oil spill impacts outlined in Figure 1, eventually contributing to collision risk preparedness and planning.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work presented in this paper has been performed in the context of the project “Shipping Accident Oil Spill Consequences and Response Effectiveness in Arctic Marine Environments (iSCREAM),” which is financially supported by the Marine Observation, Prediction and Response (MEOPAR) Network of Centres of Excellence. This research is also financially aided by Nova Scotia Graduate Scholarship (NSGS) within the scope of Ph.D. research at Dalhousie University. The financial support is gratefully acknowledged.