
Abstract
Illustrating data visually through graphs enables the examination of valuable insights and the identification of crucial patterns that are beneficial for the user. However, as the volume of data grows, it becomes increasingly challenging to organize corresponding graphs and zero in on specific objects and/or relations of interest. Various techniques have been developed to tackle the complexity of large graphs, yet these methods operate independently, potentially resulting in inconsistencies and incorrect behaviors, as well as inefficient use of computing resources when mixed together and applied in a certain order. Furthermore, administering these methods can lead to significant changes in the layout of the graph, potentially disorienting the user and disrupting their mental map. This study aims to design a framework and associated algorithms for efficiently and effectively managing complexity during visual analysis of large relational data represented as graphs, by seamlessly integrating various complexity management techniques and making adjustments to the graph layout after each operation to preserve the user’s mental map. A rendering-independent implementation of this framework and associated algorithms, as well as its integration with a popular graph rendering library named Cytoscape.js, can be accessed freely on GitHub.
Keywords
Introduction
The rapid accumulation of data in today’s world requires efficient analysis to make informed decisions in all kinds of industries. Visualization aids in this analysis by highlighting patterns, relationships, and trends for a better understanding.
Graphs or networks are a popular way to represent relational data visually. A clear layout of objects and links is essential for understanding the information presented in a graph. Poor layouts can lead to confusion for the viewer, and users may spend a significant amount of time adjusting the layout manually. 1 As a result, a reliable automatic layout feature is crucial for software that performs graph visualization-based analysis. 2 The idea of using compound graphs, 3 where nodes can hold entire other graphs within them, allowing for easy nesting, is a popular way to depict intricate connections and different levels of abstraction in data.
Effective analysis of large networks, such as those in systems biology, requires the ability to interact with and navigate the network quickly.4,5 However, traditional methods for performing operations on these networks, such as automatic layout or calculating graph-theoretic properties, do not scale well. Additionally, even if the entire network can be rendered on a computer display, the resulting visualization may be overwhelming and difficult to understand. To overcome these challenges, complexity management techniques are used to reduce the complexity of the network.5–8 Such techniques include filtering nodes or edges, collapsing compound nodes, and temporarily hiding parts of the topology.
Various methods and software libraries have been developed to manage the complexity of large graphs, but they happen to work independently, which can cause inconsistencies and incorrect results as well as inefficient use of computing resources when applied in certain mixed orders (see Figure 9 for examples). Additionally, using these methods can lead to significant changes in the layout of the graph, which can cause confusion and disrupt the user’s mental map of the data.
To fill this void, this paper introduces a novel framework named CMGV (Complexity Management in Graph Visualization) for efficiently and effectively managing complexity during the visual analysis of large relational data represented as graphs. Our design seamlessly integrates various complexity management techniques and continuously adapts the graph layout to preserve the user’s understanding, making it easy to navigate and understand even the most complex relational data sets. As far as we know, the implementation of the resulting framework and layout algorithms is the first open-source and free component empowering tool developers to swiftly incorporate complexity management into their domain-specific graph-based visualization applications. Although our demonstration implementation is tightly coupled with Cytoscape.js, 9 the framework itself is independent of any specific rendering library, ensuring compatibility with all graph visualization components. We presume that compound graphs, with their ability to handle complexity and abstraction, are the ideal way to represent and analyze large relational data.
The experimental findings align with the theoretical assessment of the framework’s runtime efficiency. Moreover, the framework adheres to anticipated standards for the quality of the generated drawings, as per widely accepted graph drawing quality metrics. Additionally, the layouts derived from these operations also meet the criteria well for preserving the mental map, as also verified by a user study.
Basics
A graph (aka network)
A compound graph is a graph that consists of multiple components or subgraphs, each of which is a graph on its own. To be formal, a compound graph
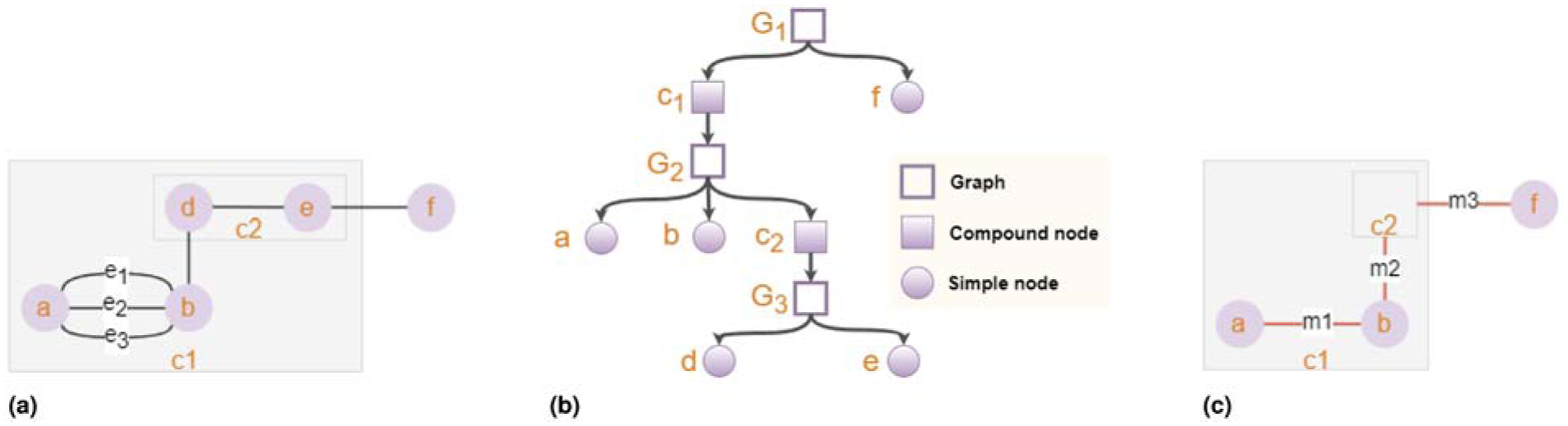
(a) A compound graph
An induced graph
Graphs are typically presented using pictorial representations.2,11,12 A poorly laid-out graph may lead to confusion for the user, whereas a well-organized one can provide aesthetic appeal and enhance the user’s comprehension of the underlying data. While the criteria for a good layout may be subjective, some generally accepted criteria include minimizing the number of edge-to-edge crossings, minimizing the total edge length, maintaining uniform edge length throughout the graph, and minimizing the drawing area. 13
In the context of interactive visual data analysis, any graph with a non-trivial size (more than several nodes and several edges) requires automatic layout, and any graph greater than about a hundred nodes and a similar number of edges is considered “large,” requiring some sort of complexity management to enable effective analysis.14,15 The complexity of any graphs larger than this should be reduced on the server side or through appropriate filtering/querying operations to the associated knowledge base.
Related work
The most popular and easily implemented layout algorithms for graphs are force-directed algorithms, also known as spring embedders. These algorithms simulate a physical system that follows the fundamental laws of physics. Nodes in the graph are treated as particles with the same electrical charge, causing them to repel each other when they are too close. Meanwhile, edges in the graph are modeled as springs that attract their endpoints when they are too far apart.13,16 The objective of these algorithms is to iteratively move the particles towards a stable state, where all forces balance out or the energy of the system is minimized. Many force-directed algorithms use a temperature, which is a variation of the simulated annealing technique, to help the algorithm quickly reach a local minimum of the energy function. fCoSE is an example of a force-directed layout algorithm that supports compound nodes. 17
Graphs that alter over time are frequently used in interactive visualization applications; this necessitates an adjusted layout. Incremental layout is the method of calculating a new layout while taking into account any current locations.13,18 An incremental layout aims to clean up the drawing while maintaining the user’s mental map, which alludes to the nodes’ present locations. The similarity of two graphs using orthogonal ordering (relative positions of the nodes about each other within the layout) and neighborhood proximity (a measure of separation between nodes within the layout) has been used in the past to measure the success of an incremental layout algorithm. 19
The need to view ever-larger sets of relational data has increased the demand for more sophisticated complexity management methods. The complexity management issue in the setting of large graphs has been the subject of some studies.7,8,20–26 Unwanted information can be concealed or ghosted and subsequently revealed upon request, using simple hide/show or more sophisticated semantic zooming techniques.27,28 Some methods29,30 make use of lenses, such as fisheye lenses, which enlarge a particular area of the drawing to enable users to zoom in on a particular area of a vast network. Others,31,32 which support multiple views and nesting and use aggregation or expand-collapse operations to manage complexity, rely on techniques for building clusters. Such techniques are based on the node/link attributes or the graph-theoretic properties of the given dataset, if not any domain-specific information. Various edge bundling and edge collapsing strategies33–35 have also been developed to specifically address the complexity caused by dense and overlapping edges in graph visualizations, helping to reduce visual clutter and making the underlying structure and relationships in the data easier to understand.
In-depth studies on complexity management often fail to address implementation concerns, such as preserving the user’s mental map when modifications are made to the graph’s topology and geometry. More importantly, when used in combination and applied in a specific order, these complexity management methods will operate independently, leading to potential inconsistencies, incorrect behaviors (see the section titled Motivation in the Supplemental Material), and inefficient utilization of computing resources.
With respect to existing tools and libraries, only a few commercial products—such as Tom Sawyer Perspectives, 36 Linkurious, 37 and yFiles 38 —support compound structures and expand/collapse functionality. However, these tools do not provide built-in support for other complexity management operations like hide/show or filter/unfilter, leaving their implementation to the end user, which is not straightforward at all. On the other hand, free tools such as Graphviz, 39 Gephi, 40 Tableau, 41 and D3 42 generally lack support for complexity management operations, including compound structures or expand/collapse. Cytoscape.js is the only free library that offers support for compound structures as well as features like expand/collapse and hide/show. However, these complexity management operations rely on external extensions, 43 which suffer from numerous reported bugs and issues, and are no longer maintained by their original authors.
Framework
We designed a framework named CMGV to solve the aforementioned problems in complexity management. It mainly consists of the following components (Figure 2):
A graph model (CMGM) that will unify various complexity management techniques and allow them to work together seamlessly, and comes with specialized layout algorithms protecting the user’s mental map after each complexity management operation is applied.
A complexity management extension (EXT) specific to the library (RL) that renders/displays users’ graphs.
A specific rendering library (RL).
The details of the low-level architecture of CMGV can be found in the Supplementary.
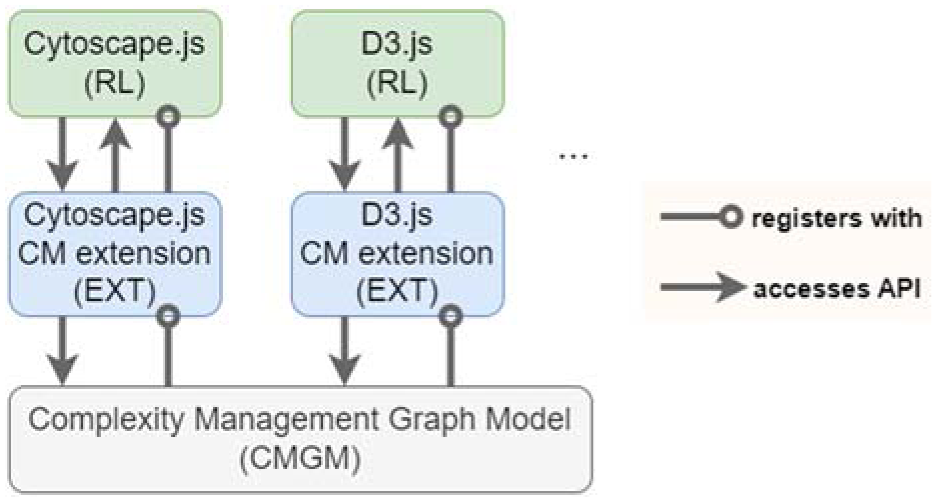
A diagram summarizing the architecture of an application using our CMGV framework.
A unified graph model
We first present a novel complexity management graph model (CMGM) that will support three kinds of most commonly used complexity management operations on graph elements:
filter / unfilter a set of graph objects based on one or more of their properties,
hide / show a set of graph objects specified by the user, and
collapse / expand contents (i.e., child graph) of a compound node or multiple edges between a pair of nodes.
CMGM is designed to be rendering layer-independent, allowing its use with varying graph rendering libraries (RLs). A graph on the renderer’s side will be represented with two compound graphs in CMGM, isolating the viewable graph in the rendering library, and avoiding any potential interference with what the user actually sees. One of these graphs, called the visible graph, is for only the currently visible graph elements, and the other one, called the main graph, is for all, including the invisible elements that are removed temporarily due to complexity management operations. This is the popular model-view architecture in action, where the main graph forms a model for the two view graphs (the visible graph in CMGM and the graph rendered by RL). This might come at an additional cost, but it is necessary to clearly separate what is visible from what the original topology is.
Each of the compound graphs in CMGM is managed by a graph manager object based on graph managers in. 7 A graph manager manages individual graphs (i.e., the root graph and the graphs nested within any compound nodes) as well as the inter-graph edges between them (see the class diagram in Figure 10 of the Supplemental Material).
We assume that communication between RL and CMGM is facilitated via an extension (EXT) of RL, ensuring the necessary flow of information and synchronization of their respective graphs (Figure 2). Changes initiated by a user, such as topology modifications or complexity management operations, are reflected in both views through the model-view architecture. This communication occurs via the associated EXT, utilizing the API provided by the CMGM, as detailed in the Supplementary. Maintaining separate graphs for RL and CMGM necessitates that changes made in one are promptly mirrored in the other to ensure synchronization of operations and structures, underscoring the importance of establishing a consistent communication structure between the two graph models.
The CMGM architecture, together with further details of the proposed operations and sample scenarios, and the communication structure between RL and CMGM are detailed in the Supplemental Material.
Complexity management operations
As listed earlier, our framework supports three kinds of complexity management operations. Most of these operations (filter/unfilter and hide/show) solely require making a graph element visible or invisible in the RL graph view by changing its visibility, which may, in turn, be based on their filtered and hidden statuses. Applying expand/collapse operations, however, might require the use of so-called meta edges, a proxy representation of an edge that can not be directly represented in the visible graph. Hence, we focus on these operations in the context of the creation and destruction of meta edges in the remainder of this section.
We use three separate hash maps (nodes, edges, and meta-edges maps) to easily map IDs to objects and keep track of a respective graph element with a common ID in other graph models. Additionally, there is a fourth hash map called the edgeToMetaEdgeMap, which tracks all edges by their parent meta edge ID.
Collapsing nodes or edges
There are two ways for meta edges to be created. The first is edge collapse, where multiple edges between the same pair of nodes are collapsed into a single so-called meta edge. The second way, on the other hand, is node collapse, where a compound node is collapsed and its contents (child graph) are no longer viewable. Since the collapse node operation removes child nodes of the collapsing compound from the visible graph, either the source or target node of an inter-graph edge with exactly one end in the collapsing node is bound to be removed; thus, a meta edge is created as a proxy representation between the compound node and the original end node outside the collapsing compound (see Figures 1 and 3 for examples).
In our framework, every meta edge maintains an original edge list containing the IDs of all the edges that it represents. Considering a meta edge as a parent and the edges it represents as its children, which in turn may be other meta edges, results in some kind of an ancestry relationship, which we call a meta edge lineage (see Figure 3 for examples). Note that an original edge list will be of length one for all meta edges created due to a node collapse operation (one per each inter-graph edge) and of length at least two in the case where the meta edge is created on an edge collapse operation. This distinction in the length of the original edges list may be explicitly used in the implementation to differentiate a node collapse meta edge from the others in a meta edge lineage.
An exception to the rule of creating a new meta edge for an inter-graph edge may happen during node collapse. If a meta inter-graph edge for which a new meta edge is to be created is encountered, an optimization measure is taken, and instead of creating a new meta edge, either the source or target of the existing meta edge is changed to be the collapsing node. This is done to reduce both the number of meta-edges created and the length of meta-edge lineages.
The collapse node algorithm (Algorithm 1) iterates over each child node and then their respective edges, removing them from the graph and introducing meta edges as needed. This is accomplished through a BFS-based traversal that recursively identifies all graph content contained within the collapsed node


Expanding nodes or edges
Expand node operation, which is the reversal of the collapse node operation, starts by bringing back all the child nodes of the expanding compound node to the visible graph unless they are filtered or hidden. Keep in mind that an edge will only become visible if both ends are expanded, and the edge itself is neither filtered nor hidden, under the assumption that all three types of operations function in sync. This is followed by bringing back and making visible any intra-graph edges between newly visible child nodes, again assuming they are not filtered or hidden. To reverse the creation of meta edges during the matching collapse operation, such meta edges need to be destroyed, any references to them need to be removed, and corresponding original edges need to be restored.
To accomplish these tasks and achieve the desired result, we first need to determine the current standing of the edge we are processing. Only the edges not in the visible graph, which are inter-graph edges with source/target outside the expanding node, can be part of any node collapse meta-edges. Thus, we begin by finding and filtering out any edges meeting these criteria and destroying them.
As we established in the previous section, a meta edge can potentially be part of a meta edge lineage; so when we destroy a meta edge, we must remove all its instances from the lineage as well. In order to do that, we must pinpoint the node collapse meta edge in the lineage, by starting from the simple edge and going upwards from its parent to its parent’s parent and so on and so forth, until we find a meta edge whose original edges list only contains a single edge. For future reference, let’s call such an edge a target meta edge. Then, we start by removing the target meta edge from the lineage and divide it into two; the first lineage will begin from the child of the target meta edge, and the second one will end at the parent of the target meta edge. The second lineage will need a slight reconfiguration after the loss of a member. One of the following can happen:
The target meta edge has no parent (i.e., a single-member lineage).
The target meta edge has a parent with only two children; with one gone, the parent meta edge is unnecessary. When this is the case, the sibling of the target meta edge becomes part of its grandparent’s original edge list. If there are none, then it will be a single-member lineage.
The target meta edge has multiple siblings. Then, the lineage reconfiguration is unnecessary.
After reconfiguration, we destroy the target meta edge and bring back the top meta edges of both lineages to the visible graph (assuming they are not filtered or hidden).
To bring any edge back to the visible graph, both its source and target nodes need to be visible. Hence, when exactly one end node is not visible, we create a new meta edge between the visible end node and the visible parent of the invisible end node, and add the edge to the original edges list of our new meta edge. Where both end nodes are invisible, a new meta edge is created between each end node’s lowest visible ancestor in the nesting hierarchy.
To expand a compound node by making its child graph visible and updating the relevant meta edge accordingly, we iterate over each child node and then their respective edges, making them visible (Algorithm 3). This is done by simply checking each direct or indirect child of the expanded node to determine whether it should be visible, as previously explained in this section. The algorithm is expected to have a runtime complexity linear in the number of graph objects involved since the expand node function traverses over all children nodes and edges and makes them visible. Hence, the worst-case runtime complexity is


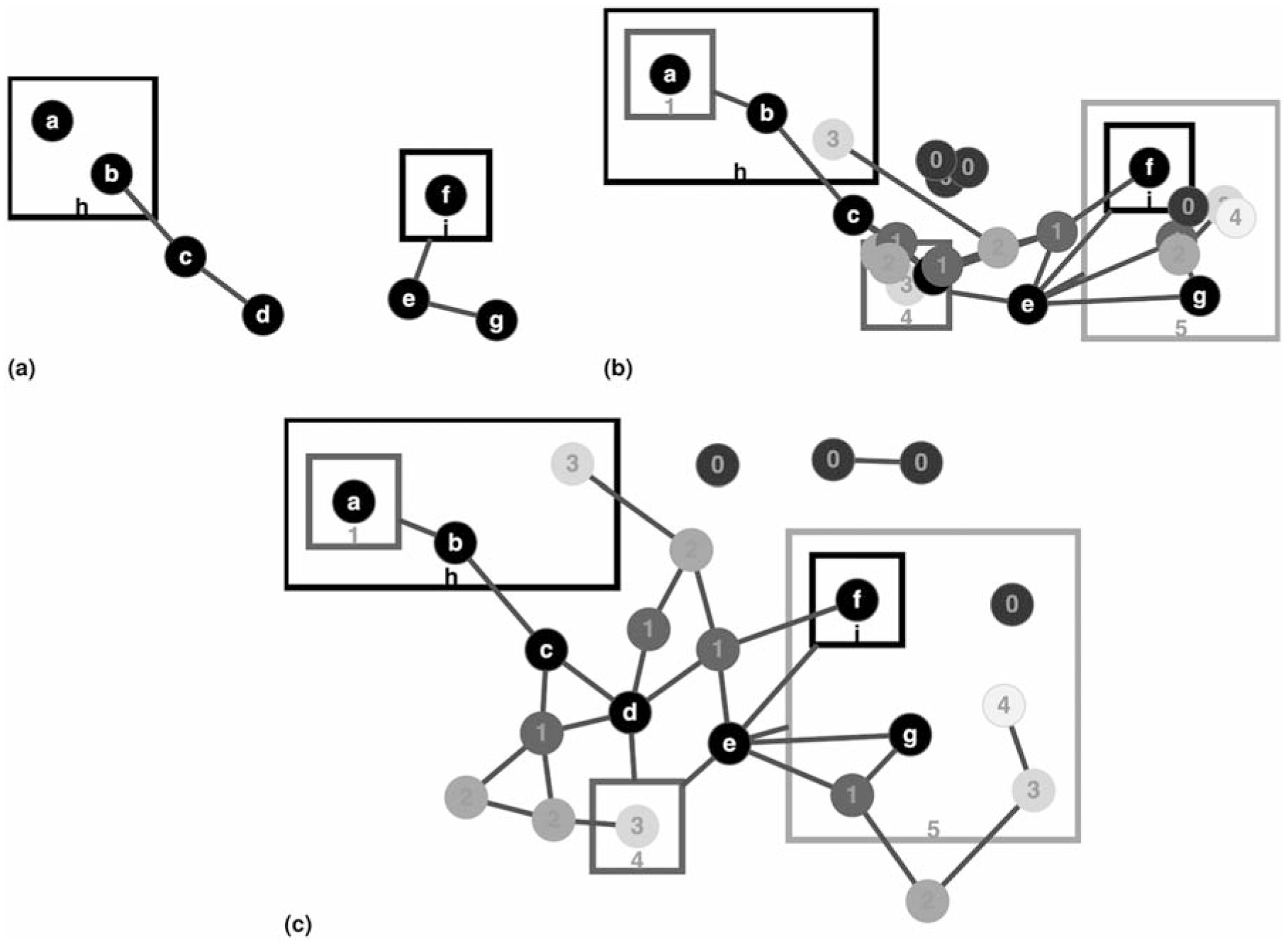
Figure 3 shows a sample scenario, where a series of mixed node and edge collapse/expand operations are performed, to illustrate how the internal representation changes as the operations take place. Below is the notation we use for this purpose:
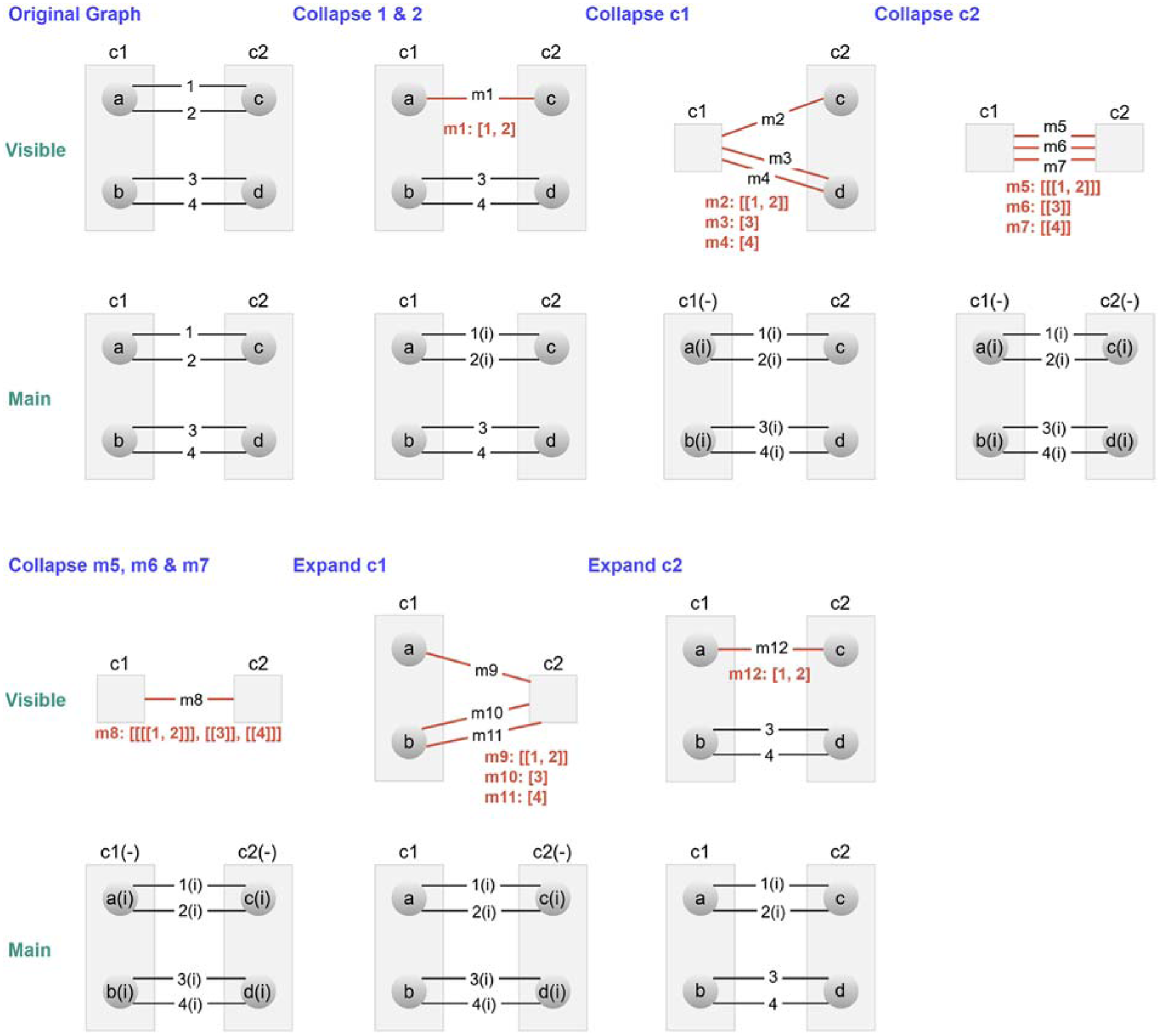
A series (from left to right and top to bottom) of mixed node and edge collapse/expand operations. Notice how visible and main graph models, as well as any meta-edge lineages (in red), change.
(−): collapsed (isCollapsed = true)
Note here that if there is only one element inside square brackets, it corresponds to a node collapse. If there are more elements, however, the associated elements must have gone through an edge collapse. For example,
The Supplemental Material presents further scenarios to illustrate how the CMGM graph models change as a combination of various complexity management operations is applied.
Methods
It is imperative that, as complexity management operations take place, the user’s mental map is not destroyed, impairing the analysis. Furthermore, the layout algorithm used by the complexity management operations should produce compatible/consistent results with the base layout algorithm used by the application. This base algorithm should support compound structures and incremental layout, and should be easily customizable for adjusting layout during complexity management operations. For our work, we chose fCoSE 17 as our base layout algorithm since it satisfies the aforementioned requirements.
Some complexity management operations may be handled using the base layout algorithm in incremental mode, where the current respective positions of graph elements are maintained. In the case of force-directed layout algorithms such as fCoSE, this simply corresponds to starting the iterative algorithm from the current node positions, instead of randomly placing them. Adjustment of the layout after a collapse operation is exemplified in Figure 4. However, the expand node and show/unfilter operations require specialized incremental layout algorithms to ensure newly introduced, possibly large content, does not overlap and, hence, tangle surrounding graph elements, tarnishing the existing nice layout. An expand operation in the middle of the nesting hierarchy of multiply nested compound structures makes things even more difficult.
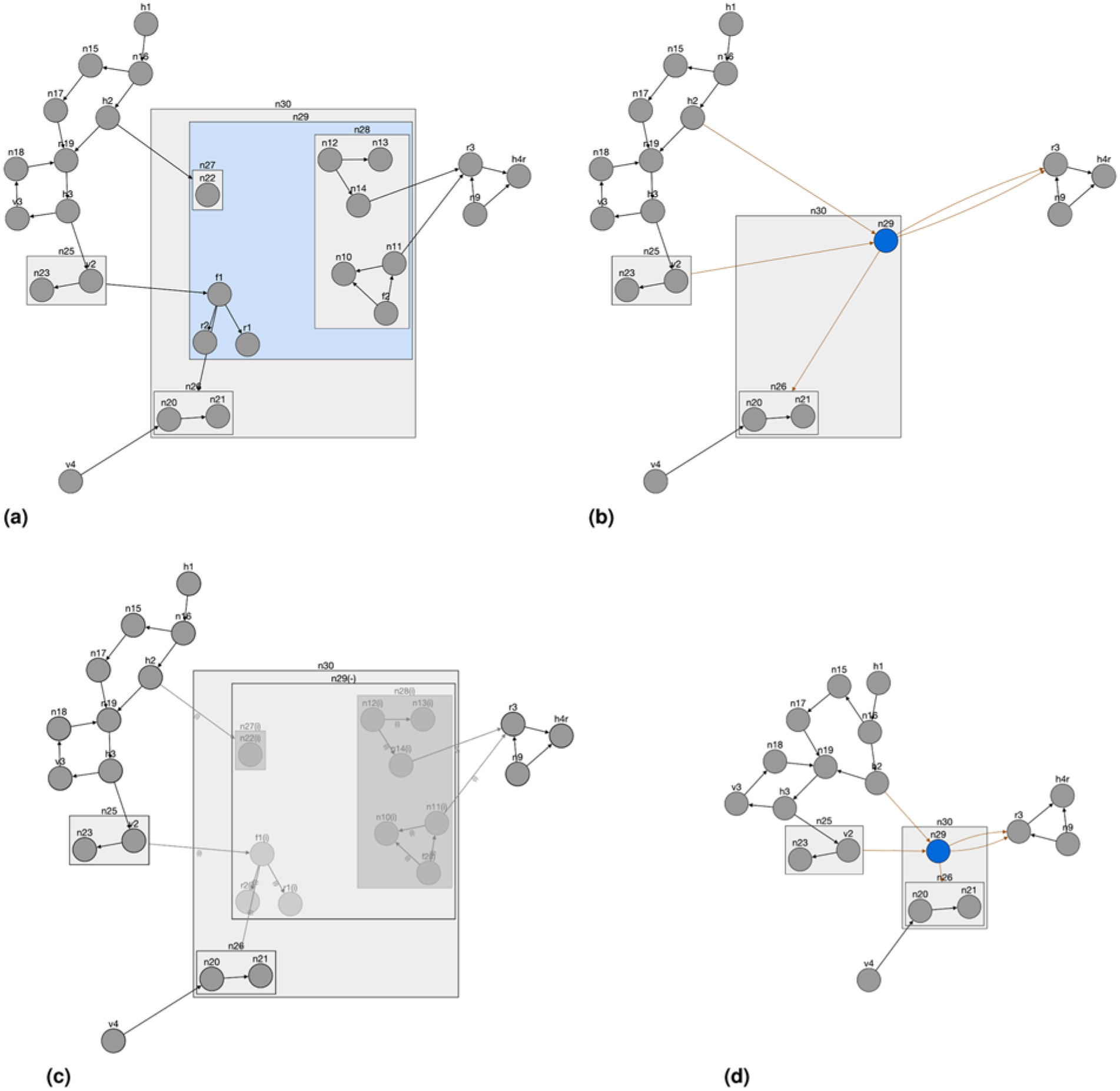
A sample layout adjustment on a collapse operation (a) original visible graph (b) visible and (c) main graphs after collapsing
Adjusting layout on expand
Our base layout fCoSE was customized with a post-processing step for the expand operation as follows. The main idea here is to estimate the amount of additional space needed by the expanding node and create a “proxy graph” with just the main components of the visible graph, with appropriate node dimensions and no edges. In other words, the proxy graph consists of one node per component of the main graph, and two nodes
We then lay out
and
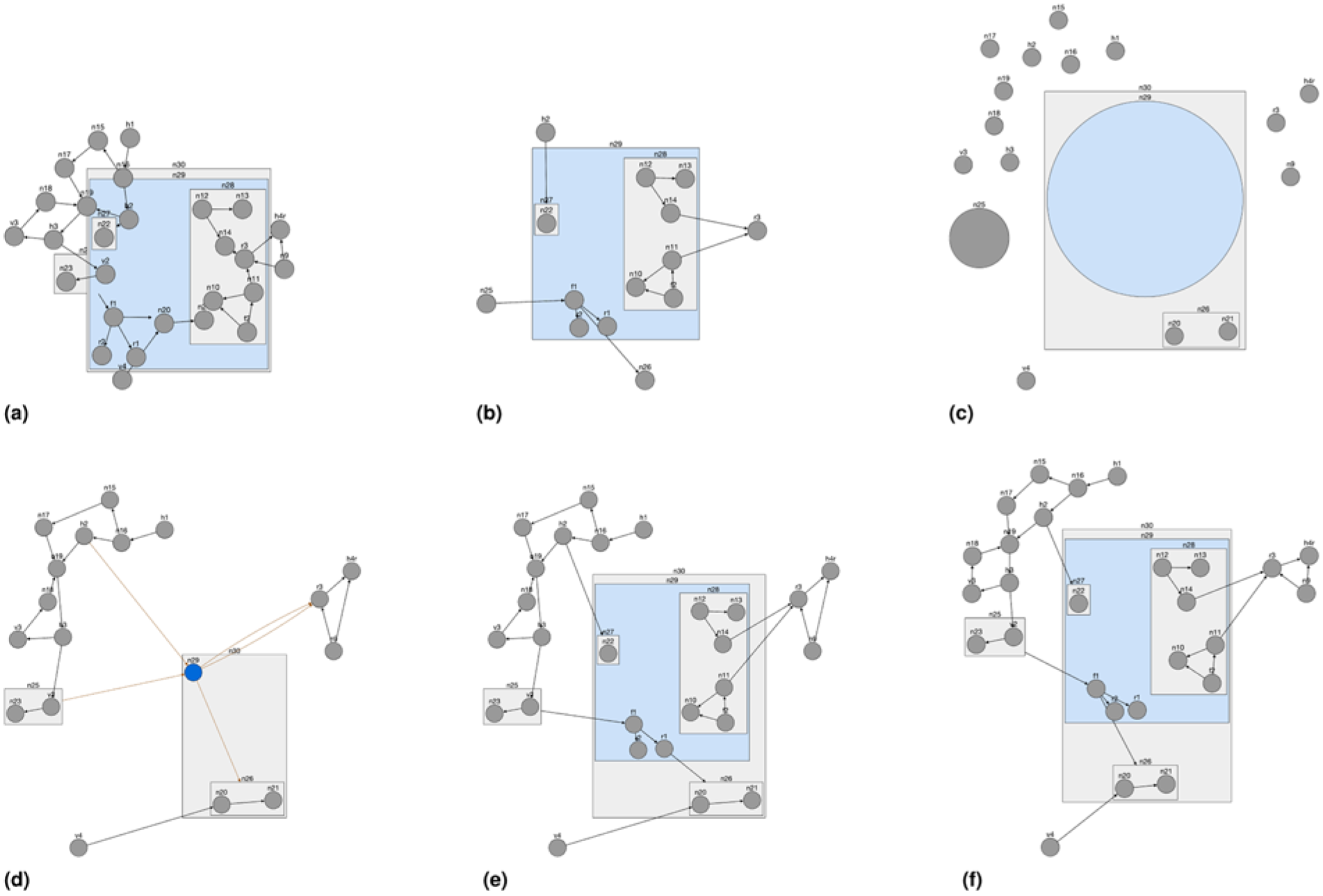
A sample layout adjustment on an expand operation (a) an original visible graph without any layout adjustment after expanding n29 in the graph of Figure 4(d) (notice how expanded content tangles the surrounding graph objects; some graph objects stay behind compound boxes) (b) an incremental layout of the immediate neighborhood graph (notice how nonimmediate neighbors such as h3 are excluded in this stage) used to estimate expanding node's size after expansion (c) proxy graph after an incremental layout (d) visible graph after graph components are repositioned based on the layout of the proxy graph (e) expanded visible graph before a final incremental layout is applied, and (f) final layout, after which node separation and edge lengths become more uniform.
An incremental layout of
After the nodes of the proxy graph representing the components of the original graph are finalized, we move the compounds of the original graph to those positions suggested by the proxy graph (see Figure 5d and 5e). Lastly, a final incremental layout polishes the drawing (see Figure 5f). Algorithms 5 through 7 provide the pseudocode for the expand node operation, including the customized layout calculations.




Adjusting layout on unhide
Adjusting the layout during an unhide (i.e., show or unfilter) operation can be challenging, particularly when the hidden content has neighboring nodes within the network. This complexity arises because hiding a portion of the network often causes significant changes to the layout of the remaining visible structure. Even a simple uniform translation of the entire drawing can misalign or distort the coordinates of the hidden elements. Consequently, when unhidden, neighboring nodes must be carefully reintegrated into the drawing to avoid overlaps. To address this, a greedy algorithm that incrementally reintroduces hidden neighbors level by level, using iterative layout adjustments, was introduced. 8 In this approach, the initial position of each unhidden node is determined by dividing the surrounding space into quadrants and scoring their density based on first- and second-degree neighbors. The least crowded quadrant is selected, and nodes are placed randomly within it at an ideal edge length. This process integrates neighbors recursively with iterative adjustments to ensure a cohesive layout. This approach differs from traditional methods, where layout adjustments occur as a post-processing step following complexity management. Instead, it integrates layout adjustment directly into the complexity management process, ensuring seamless reintegration of hidden content into the network.
Here we introduce an improved algorithm that relies not only on the neighborhood of newly introduced nodes but also on other properties such as compound parents or siblings, node degree, and whether or not the neighboring nodes were previously laid out (i.e., already have coordinate information). In addition, our algorithm takes compound nodes into account. Our greedy algorithm, detailed in Algorithms 9 through 11, uses an advanced ranking scheme for new nodes. Here, a node
(a) A sample compound graph. (b) New nodes/edges are introduced by unhiding, where the nodes (the higher the rank, the lighter the fill color is) are placed using our algorithm in Algorithm 9, (c) followed by an incremental layout that tidies up the drawing, where the relative positions of original nodes (labeled
Implementation & evaluation
As stated earlier, CMGV stands as an independent platform tailored for the management of graph complexity, featuring a cohesive model called CMGM. This model was meticulously implemented using JavaScript. Its primary design objective encompasses compatibility with diverse graph rendering libraries, facilitated through a dedicated CMGM API associated with the respective rendering framework. To exemplify its utility and evaluate its efficacy, we have adopted Cytoscape.js 9 as our rendering library of choice. Consequently, an interface has been implemented to establish seamless communication between the Cytoscape.js rendering engine and the CMGM. For an exhaustive exposition on the architecture and operation of this interface, refer to the Supplemental Material.
Experiment setup and dataset
Furthermore, we have designed and implemented a demo and test environment using our Cytoscape.js implementation of the framework. Test scripts implemented in this environment aim to test for the integrity of the framework as well as the measurement of various performance metrics using some test scenarios (see the Supplementary for details). A Supplemental Material video showing our framework in action, through a number of scenarios, using this demo, is also available.
These scenarios were executed on an ordinary computing platform (featuring an Intel i7-11700 2.50GHz CPU and 16GB of RAM) across a suite of randomly generated compound graphs. These compound graphs varied in size, spanning from 188 to 1032 nodes, and were sourced from the compound graph dataset established by Balci et al. 17 As detailed in their paper, they based this compound graph dataset on a subset of 81 graphs randomly chosen from the Rome dataset 44 with a density not exceeding 3. In our study, we included denser graphs up to density 4.5 as well (Figure 12 of the Supplemental Material). To further refine the dataset, the Markov Clustering Algorithm 45 was employed to identify clusters within each graph. Subsequently, nodes residing within each identified cluster were consolidated into a solitary compound node. This process was reiterated multiple times, leading to the generation of compound graphs with variable depths. Further information on properties of the experiment data and the scenarios used may be found in the Supplementary under Performance Evaluation.
Experiment results
Integrity tests performed on test graphs using the predetermined test scenarios were all completed successfully, leaving the topology of each compound graph intact.
We also measured the performance of the complexity management operations in terms of running time using two predefined scenarios on the test graphs. Scenario 1 includes a mixture of the three kinds of complexity management operations, while Scenario 2 also includes adding a random neighborhood to a randomly chosen node and repeating the test. Furthermore, we have a third scenario, which is randomly generated by selecting a do operation (e.g., collapse) before its undo (e.g., expand), where all kinds of operations are randomly determined and mixed (see the Supplemental Material for details). By varying the structure across these three scenarios, we aimed to simulate an arbitrary ordering of complexity management operations on graphs with randomized topology. Results are in line with our theoretical findings of the asymptotic linear run times of these operations (Figure 7).
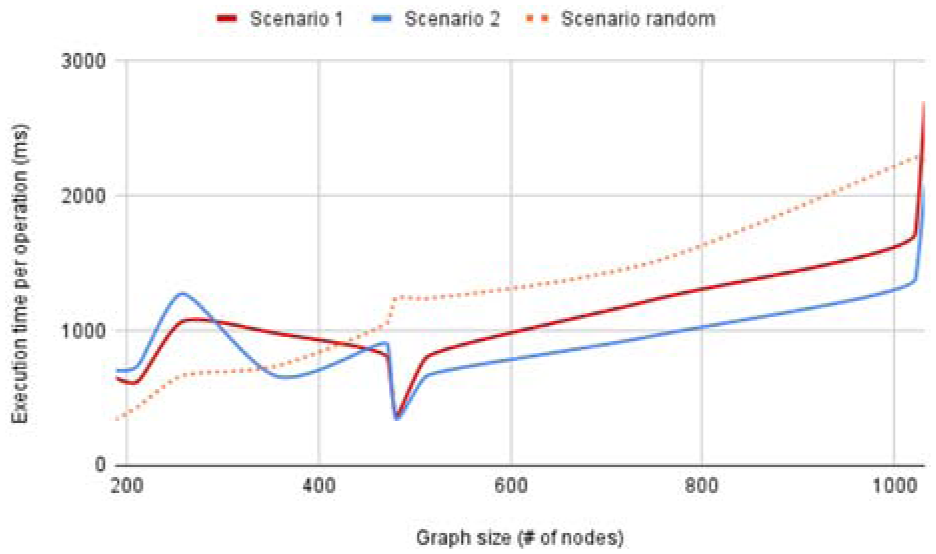
Graph size versus execution time for two predefined and one randomly generated scenario; results comply with asymptotic theoretical results of linear growth.
Furthermore, we investigated how complexity management operations and our customized layout affect the quality of the drawings. As can be seen in Figure 8 (and Figure 12 of the Supplemental Material for denser graphs), layout quality either improves or worsens marginally as complexity management operations are executed.
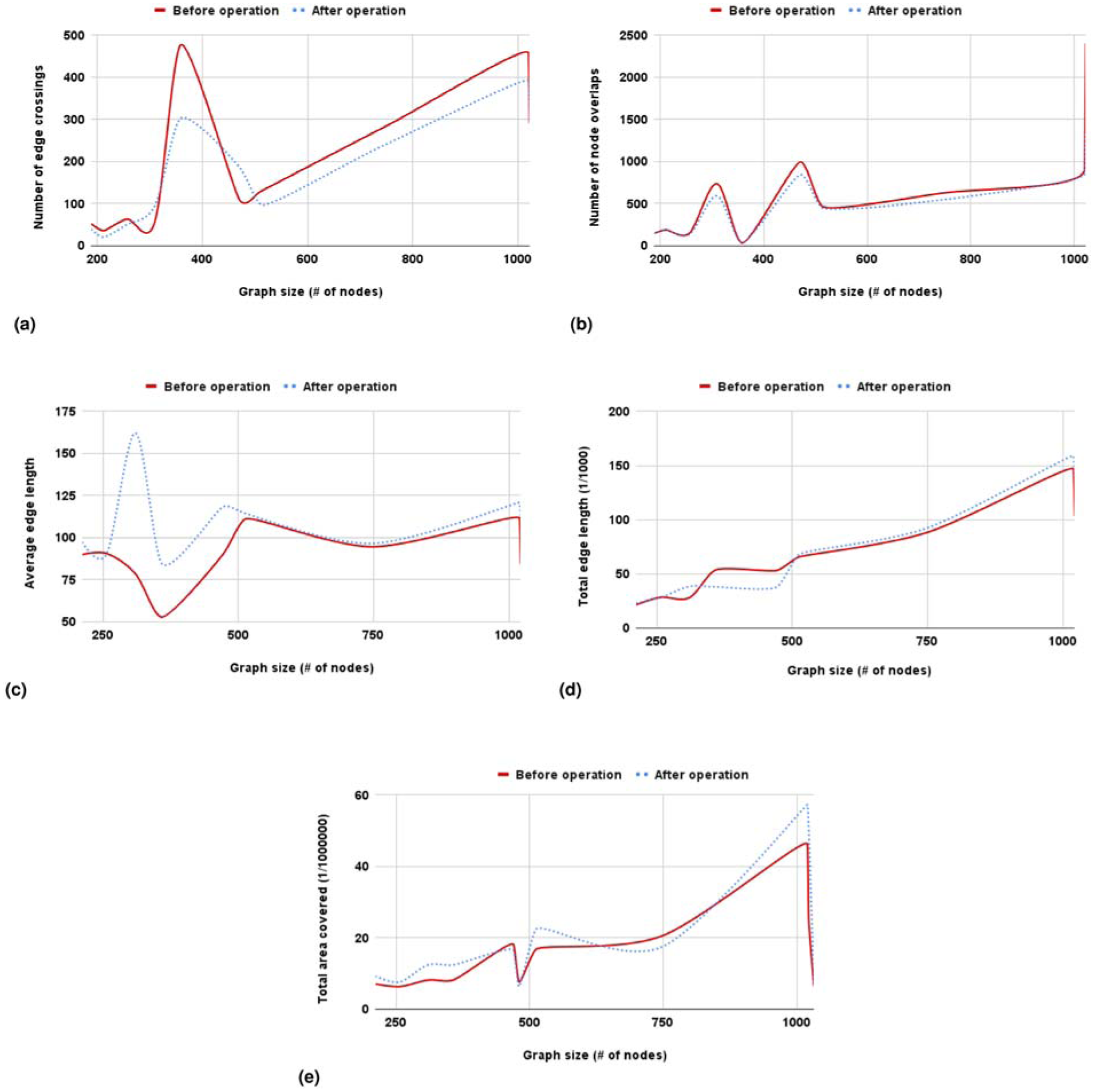
How various metrics of layout quality are affected by complexity management operations. The quality of the drawings across these five metrics remains largely consistent, with only occasional slight improvements or degradations. The results for node overlaps, total edge length, and total area are nearly identical. The observed reduction in edge crossings is likely due to the repeated incremental layouts triggered by each complexity management operation, which enhances layout quality in this aspect. The initial increase in average edge length can likely be attributed to expand/collapse operations, which introduce and remove inter-graph edges that tend to span longer distances. However, this effect is mitigated over time as successive incremental layouts are applied.
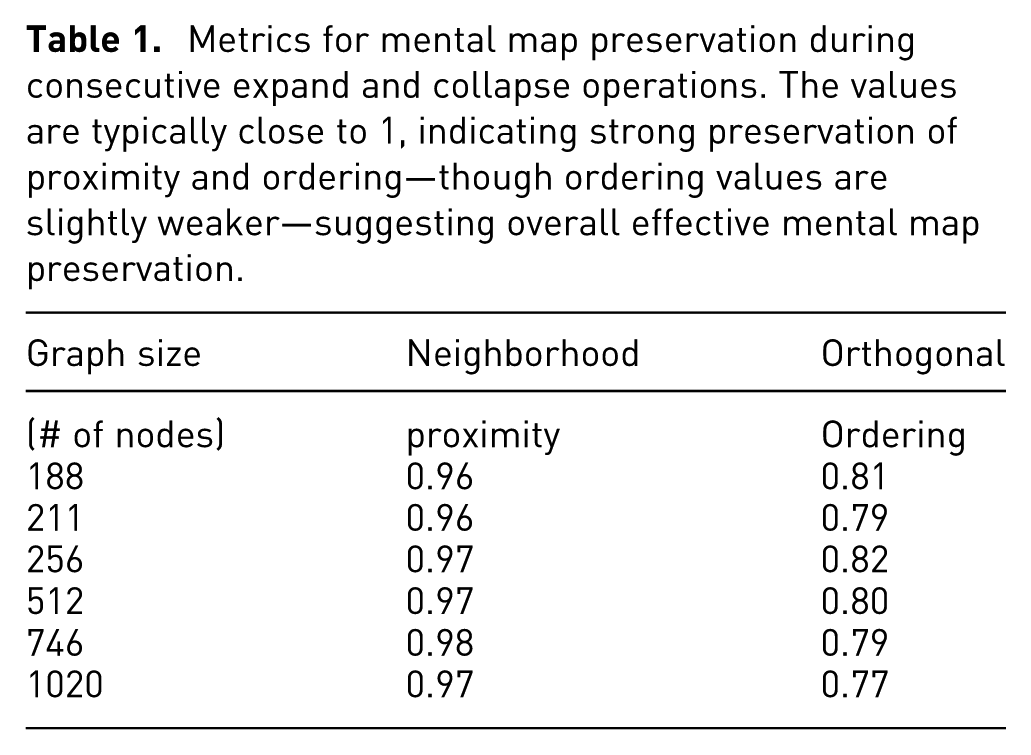
Finally, we also measured how the user’s mental map is preserved as these complexity management operations take place. Results show that neighborhood proximity is maintained almost fully, whereas orthogonal ordering is compromised slightly as taking out the unnecessary space around a collapsed node and introducing the space back on expand will inevitably disturb such ordering (Table 1).
Metrics for mental map preservation during consecutive expand and collapse operations. The values are typically close to 1, indicating strong preservation of proximity and ordering—though ordering values are slightly weaker—suggesting overall effective mental map preservation.
To further evaluate the preservation of the mental map, we conducted a user study involving 24 participants with varying levels of expertise in graph visualization tools, including students, researchers, and software developers. Users were asked to perform a predefined set of operations and their corresponding undo actions in an order of their choice. They were then asked to comment on the difficulty of completing these tasks and whether they were able to maintain their mental maps throughout. The complete list of questions, along with participant profiles, is provided in the Supplemental Material under the User Study section.
As the results indicate (Figures 13–15 of the Supplemental Material), the framework was found to be easy to use, and users were able to keep track of the objects of interest as operations were carried out, giving an overall rating of 8.71 out of 10. Answers to specific questions include:
Only three participants reported occasionally encountering errors or illegal states; however, follow-up indicated that these reports were due to misunderstandings—such as mistaking a suboptimal layout for an error—or a failure to carefully read the instructions. As a result, no genuine errors or illegal states were present.
Again, only three participants responded “Occasionally” to the question regarding whether they felt lost or disoriented during the operations, while 12 responded “Never” and 9 responded “Rarely.”
As there are no existing frameworks or modules that can handle a similar set of operations in a mixed order, which is the very main motivation for our work, we were not able to make a comparison of results. Similarly, no existing specialized layout algorithm, such as fisheye lenses, can be used or would be rather inefficient for compound graphs with arbitrary levels of nesting.
Conclusion
Through manipulations on randomly generated graphs, we demonstrate the newly introduced framework CMGV’s proficiency in executing successive graph complexity management operations while upholding the integrity of the underlying data and maintaining the mental map of the user via customised layout algorithms. Another notable attribute is that the framework functions independently of rendering libraries and seamlessly integrates with various graph rendering libraries. This adaptability empowers CMGV to cater to diverse visualization needs, establishing its relevance across various domains.
In terms of future avenues, there is potential to introduce supplementary complexity management and analysis procedures. For instance, the incorporation of semantic zooming, wherein expansion and contraction of compound nodes occur in tandem with incremental and decremental graph zoom levels, is managed by the framework. Similarly, the novel layout algorithm introduced in this study primarily focuses on the expansion operation, but there are exciting prospects for further developments. This could encompass the integration of other complexity management operations involving the addition of graph elements, such as showing or unfiltering elements. Identifying the initial positions for unfiltered elements becomes crucial. These positions could be proximate to visible nodes linked to unfiltered graph nodes or aligned with their previous placement prior to the filtration process. Subsequently, the existing algorithm can expand the graph around these positions to assimilate the unfiltered elements. The current algorithm’s triumph in safeguarding the user’s cognitive map during the expansion operation serves as a solid foundation for subsequent investigations and advancements.
An implementation of our framework and methods is available on GitHub (https://github.com/ivis-at-bilkent/cmgm). An example usage of our framework is also implemented with the Cytsocape.js rendering library as a separate GitHub repository (https://github.com/ivis-at-bilkent/cytoscape.js-complexity-management). In this repository, a demo and a test application are also available for integrity and performance tests of our framework. All scenario and test graph-related files can also be found in a test directory of this repository.
Supplemental Material
sj-pdf-1-ivi-10.1177_14738716251383173 – Supplemental material for CMGV: Algorithms and a unified framework for complexity management in graph visualization
Supplemental material, sj-pdf-1-ivi-10.1177_14738716251383173 for CMGV: Algorithms and a unified framework for complexity management in graph visualization by Osama Zafar, Ugur Dogrusoz, Hasan Balci and Ahmet Feyzi Halac in Information Visualization
Footnotes
Acknowledgements
We thank Google Inc. for their support through the Google Summer of Code program.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Scientific and Technological Research Council of Turkey (121E230).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.