
Abstract
The increasing size of Big Data is often heralded but how data are transformed and represented is also profoundly important to knowledge discovery, and this is exemplified in Big Graph analytics. Much attention has been placed on the scale of the input graph but the product of a graph algorithm can be many times larger than the input. This is true for many graph problems, such as listing all triangles in a graph. Enabling scalable graph exploration for Big Graphs requires new approaches to algorithms, architectures, and visual analytics. A brief tutorial is given to aid the argument for thoughtful representation of data in the context of graph analysis. Then a new algebraic method to reduce the arithmetic operations in counting and listing triangles in graphs is introduced. Additionally, a scalable triangle listing algorithm in the MapReduce model will be presented followed by a description of the experiments with that algorithm that led to the current largest and fastest triangle listing benchmarks to date. Finally, a method for identifying triangles in new visual graph exploration technologies is proposed.
Introduction
Data, data, data, and more data! Obtaining data is just the beginning of analysis, but heaping piles of raw data are rarely useful. How data are structured or represented facilitates analysis. Data must undergo transformation, translation, transmuting and other structuring, categorization, and organization operations to enable intelligent analysis. This includes making data more concise, more relevant, and structured to improve the performance of a query or algorithm. Ultimately, data form the raw material we need to pave the roads to knowledge, and visualization is the interface to insight. The entanglement between data representation and analysis is best exemplified in the graph-theoretic study of complex networks.
With the era of Big Data 1 comes the emergence of Big Graphs, 2 and while there has been attention to improving the capacity of graph primitives, such as Breadth-First Search,3,4 it should not be overlooked that the answers to even simple questions, the algorithm output itself, can be tremendously large and complex. Consider the task of identifying all mutually connected triplets in a graph or network of entities, often depicted as a triangle where each vertex of the triangle represents an entity that is connected to the other entities by the edges of the triangle. Finding all such triangles in a graph requires a lot of computation and the number of triangles can be many times more than the number of entities. Despite a triangle being a simple graphic, visualizing all triangles in a graph is very difficult because the triangles overlap and are easily obscured.
Computing triangles in graphs is a fundamental operation in graph theory and has wide application in the analysis of social networks, 5 identifying dense subgraphs 6 and network motifs, 7 spam detection, 8 and uncovering hidden thematic layers in the World Wide Web. 9 Yet, given the attention to finding, counting, and enumerating triangles, there has been very little work done to present a visual representation of triangles that is both scalable and navigable. This may be due in part to the lack of feasible technology that can list out trillions of triangles to provide the specificity needed in a Big Graph visual analytic, where every triangle can be traced by an end-user.
This article will begin first with an exercise to convince the reader of the importance of not just more and bigger data, but also how the underlying representation of data can better enable knowledge discovery in the context of graph analytics. Then a new algebraic method to reduce the number of arithmetic operations for computing all triangles in a graph will be introduced, and additionally a new scalable algorithm that demonstrates the largest triangle enumeration to date will be presented, along with the experimental results. Finally, a method for extending existing algorithms in visual graph exploration tools to include the identification of triangles will be proposed.
An illustration of knowledge manifestation
Consider a network of things, where each thing is identified by a number and these things self-organize into a larger network of a Thing of Things. How do we represent this Thing of Things?
Tabulating
A set of binary relationships, e.g. one thing is associated with another thing, can be simply tabulated in a basic data structure, a list of pairs of things, that is compact and does not require any special management. This is illustrated by the subset of our network of Thing of Things shown in Figures 1(a) and 1(b). Note how 498 connects to 5 and 33—does this suggest a mutual relationship? Does the fact that 17 connects to 7, which connects 33 and in turn connects back to 17 denote transitive closure?
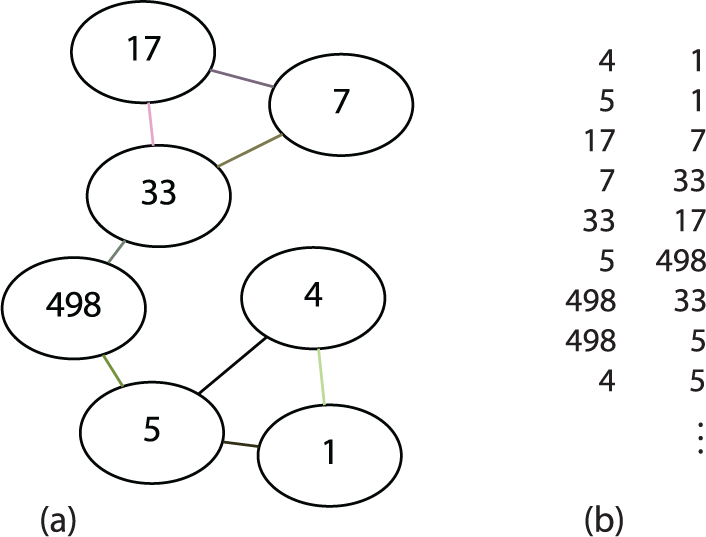
Thing of Things. (a) Sub-network. (b) List of binary relationships.
That’s just a tiny sample. Our Thing of Things comprises 500 things, which participate in 25,936 relationships. What can you identify, given all of the data as depicted in Figure 2? Displaying this very small example dataset provides very little insight. Tabulation can obscure non-direct relationships. Will a graph layout manifest information better? Complex relationships naturally form networks, which are ideal for graph treatment, so let’s Graph it!

The full Thing.
Graphing
A graph can be displayed in a node–link layout, which appears as the familiar “ball and springs” model. But layout algorithms for graph visualization can have dramatic differences. Using the Graphviz graph visualization package available at www.graphviz.org, to produce Figure 3 our Thing of Things appears more like a ball of yarn with the “force-directed” layout. This doesn’t uncover any more useful information, colorful or not, than the tabulation example in Figure 2. But when the “scalexy” layout is used, as shown in Figure 4, there is a clearly emerging structure! By a simple change in displaying the graph data, three well-defined clusters can be identified in our Thing of Things network. Other visualization approaches can manifest these clusters in more striking fashion, but require another change in the graph representation.
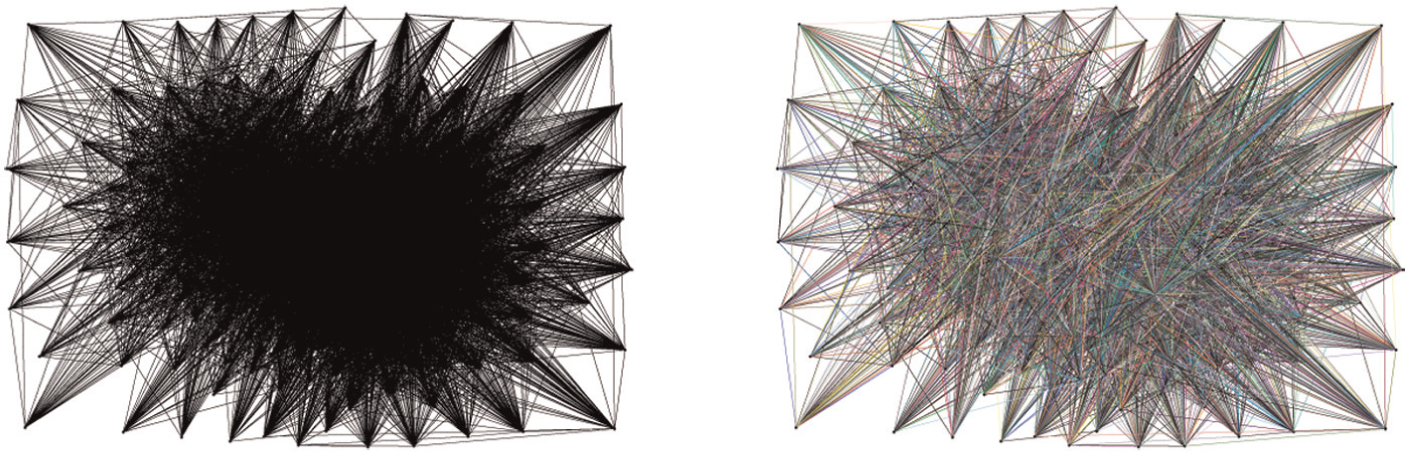
Graphviz “force-directed” layout.

Graphviz “scalexy” layout.
Graph data structures
The following terms and definitions will be used throughout this article. Let
A graph data structure can be a list of pairs, e.g. edges, as noted earlier. In this edge-list representation, there are 2m ordered pairs including permutation, e.g.

The dense matrix storage for this graph is prohibitive at nearly 230 petabytes whereas in contrast the sparse matrix is over seven orders of magnitude smaller, at just 3.2 gigabytes. A sparse matrix can be plotted and visualized in MATLAB, which can reveal patterns in the distribution of non-zero entries, so let’s Spy it!
Plotting
The Thing of Things edge list can be converted into a sparse matrix and visualized as a Spy plot in MATLAB. First annotate each edge with a 1 for the MATLAB conversion, then use the following commands:

The Spy plot from this labor is provided in Figure 5. If the reader squints carefully, a pattern, albeit fuzzy, might be apparent, especially along the diagonal, but there is nothing definite enough to justify a purchase in new eyeglasses! However, is it possible to manipulate the graph matrix to reveal the clusters that were manifested in Figure 4?
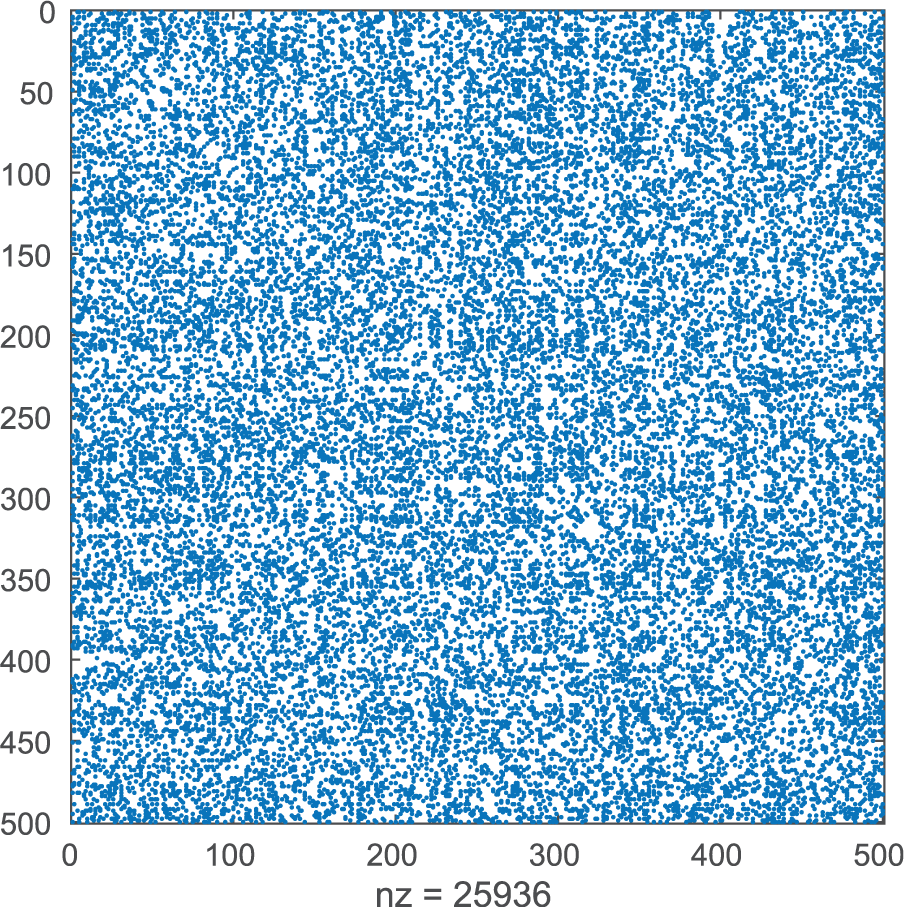
MATLAB Spy Plot.
Spectral partitioning
Let’s try spectral partitioning but this requires another change in representation of the data, specifically a new graph matrix, known as the graph Laplacian. The eigenvectors of this Laplacian can be used to partition the graph. The following definitions will be used in the next passages on spectral partitioning.
D diagonal matrix with vertex degrees along the diagonal;
L graph Laplacian,
U matrix whose columns are the eigenvectors of L.
The graph Laplacian is also symmetric and positive semi-definite, so the eigenvalues of L must be greater than or equal to zero. The multiplicity of the zero eigenvalue relates to the number of connected components in the graph. The eigenvector of the second smallest eigenvalue of L is the Fiedler eigenvector, whose namesake discovered its connection to graph connectivity and use in spectral partitioning. 10 Reordering the adjacency matrix A by the sorted elements in the Fiedler eigenvector helps in envelope reduction to avoid fill-in, increases in non-zeros, during sparse matrix computations, 11 and also to reveal small-world characteristics in graphs.12,13 This reordering technique will be helpful in visualizing clusters in the Thing of Things network. The premise in the reordering of A by a permutation vector is to align the non-zero entries close to the diagonal in A, thereby reducing the geometric distances between vertices, which results in natural partitioning of the graph. The following MATLAB commands will reorder A by the Fiedler eigenvector and Spy it!

Behold, in Figure 6 three well-defined clusters are identifiable. Data representation matters! The choice of representation facilitates knowledge discovery. But it doesn’t end with just the original data. Data begets data. Data analysis output can be many times larger than the input!
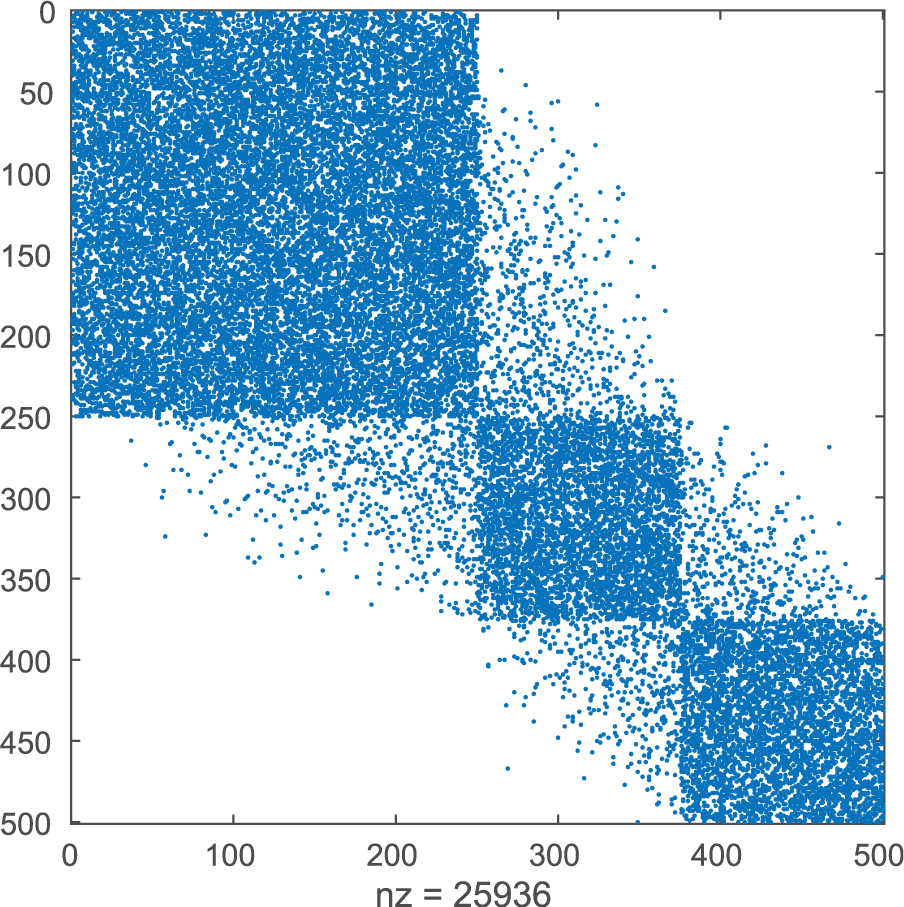
Spectral Partitioning.
Triangles in graphs
A triangle in G is a group of three vertices that are all mutually connected, thus it is a clique, i.e. a graph in which every vertex is connected to every other vertex, and a cycle, i.e. a path with identical endpoints. Triangles in graphs are useful for complex network analysis based solely on structural, i.e. adjacency, information. Let
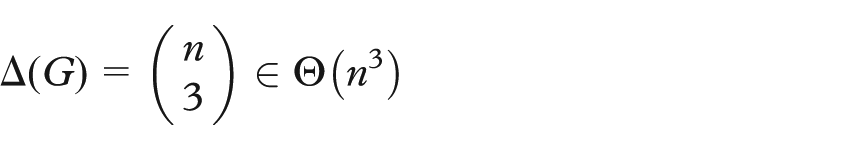
The triangles in a graph can be easily identified by testing all possible triples,
Counting triangles
Since cycles of length n are diagonal elements in
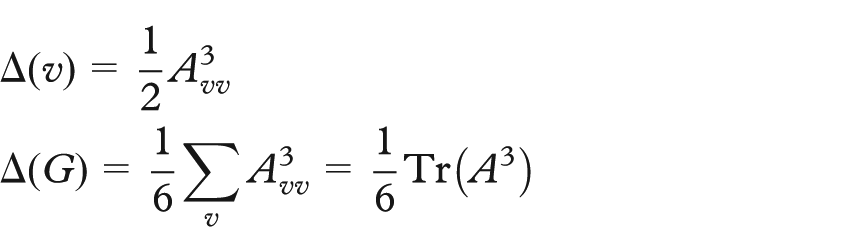
where the symbol
Computing triangles by
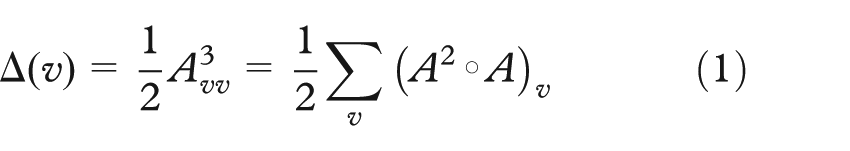
Now recall
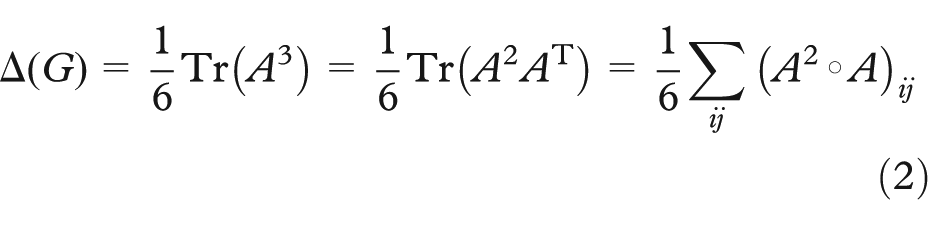
The corollary to this is that the number of arithmetic operations is cut in half when using classic matrix multiplication.
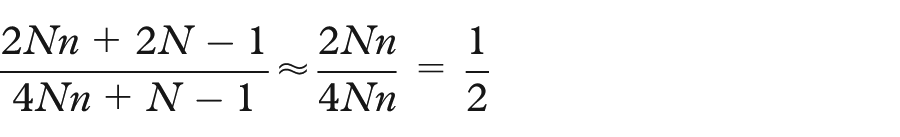
Using similar logic, it is easy to see that this result also holds for dense graphs and the local triangle count,
Computing triangles by Theorem 1 replaces a matrix multiplication requiring
Scalable triangle listing
Disk-based computation for Big Data problems was popularized by the Google MapReduce paradigm 16 and corresponding open-source Apache Hadoop framework (http://hadoop.apache.org). The theoretical model for MapReduce has been investigated,17–19 putting it in firm standing with older computational models, such as Parallel Random Access Machine (PRAM), Bulk Synchronous Parallel (BSP), and Streaming. The largest Breadth-First Search on a graph was accomplished using the Hadoop MapReduce framework. 4 The MapReduce model was also successful for the largest and fastest computation of all Jaccard similarity coefficients in a graph 20 at that time. The following sections will describe the MapReduce algorithm used in the largest and fastest enumeration of triangles in a graph to date.
MapReduce triangle listing algorithm
There are relatively few triangle algorithms in the MapReduce framework and these tend to focus on approximating triangles.21,22 The most closely related work is that of Suri and Vassilvitskii 23 but that approach does not guarantee a constant amount of working memory needed for massively scalable algorithms. Moreover, the algorithm described here requires half the I/O by not revisiting the original graph edges; rather it uses the edges filtered by degree for subsequent triangle verification. The following is an outline for a new MapReduce triangle listing algorithm:
Filter out half the edges so that the end vertex has higher degree
(use lexicographic order, in case the degrees are equal).
Create labeled, ordered pairs by lexicographic order from the filtered edges: Adjacent vertex pairs, i.e. endpoints of edges, labeled as edge; Unique neighbor pairs, i.e. endpoints of 2-paths, labeled as non-edge;
List 2-paths for an ordered pair if it also has a label for an edge.
Like other algorithms,
24
the 2-paths are emitted only from the lowest-degree vertex in a triangle. This is enabled by the first step, which reduces the neighborhood of each vertex to contain only neighbors with higher degree. Denoting the size of this reduced neighborhood
Although
Load balancing
Unique pairs from a list of elements can be constructed in parallel while ensuring that each task performs a linear amount of work with constant words of memory, which are important for scalability. Consider the straightforward method, where the first element in the list is paired with the remaining
Now to construct all the unique neighbor pairs for a vertex u, each
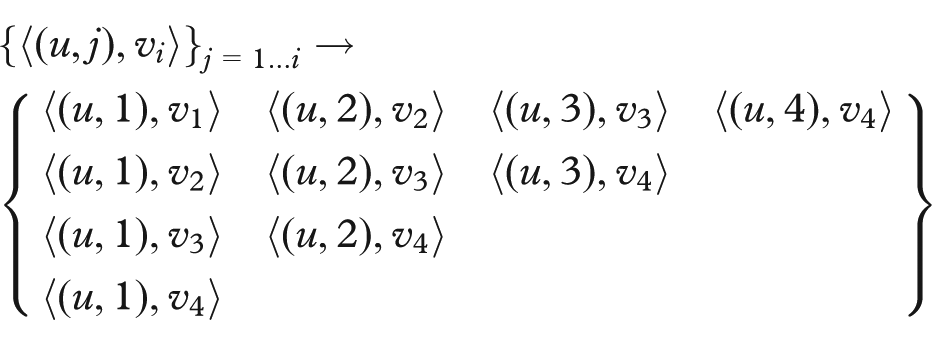
Here the pairs are displayed in matrix layout only as a visual aid; in the computation, the pairs are distributed randomly by the MapReduce framework. Then, in a subsequent round, where values are aggregated and sorted for each

The
Triangle listing benchmarks
The new MapReduce triangle listing algorithm was demonstrated in a two-part experiment. The first part was to test the algorithm on real-world graphs that would be easily repeatable by other practitioners. The second part was a scalability test. The results of the experiment were first presented in the keynote address for the IEEE Exploring Graphs at Scale (EGAS) 2015 workshop.
25
The benchmarks were carried out on a cluster of 880 nodes with 24 cores and 64 GB RAM per node. The datasets were modified so that each edge was annotated by degree, e.g.
Part 1
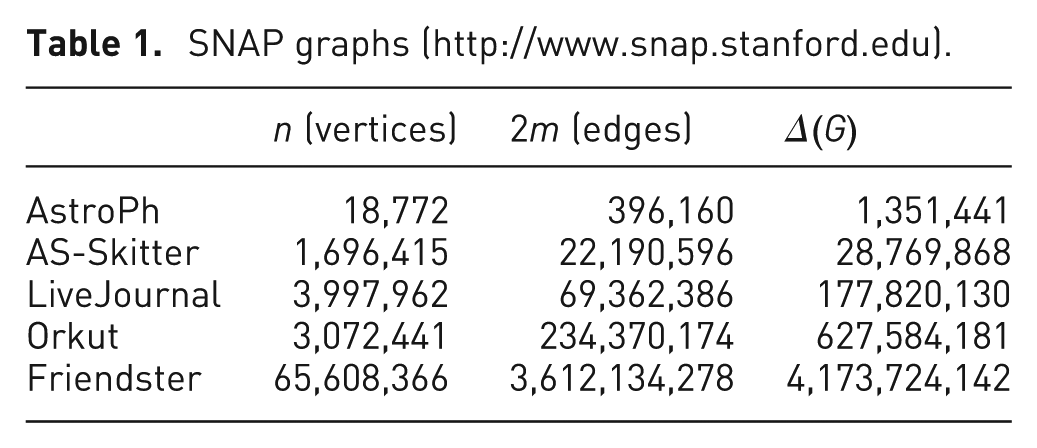
The datasets for this part of the experiment, listed in Table 1, were downloaded from the Stanford Network Analysis Project (SNAP, http://www.snap.stanford.edu). The graphs were undirected and the global triangle count was available for ground truth. The benchmark results are provided in Figure 7 and demonstrate that Algorithm 1 takes less than 5 min on average for these small graphs; this is still comparatively slow because of the overhead needed for parallel processing and reading from disk. The second part of the experiment is more compelling.
SNAP graphs (http://www.snap.stanford.edu).
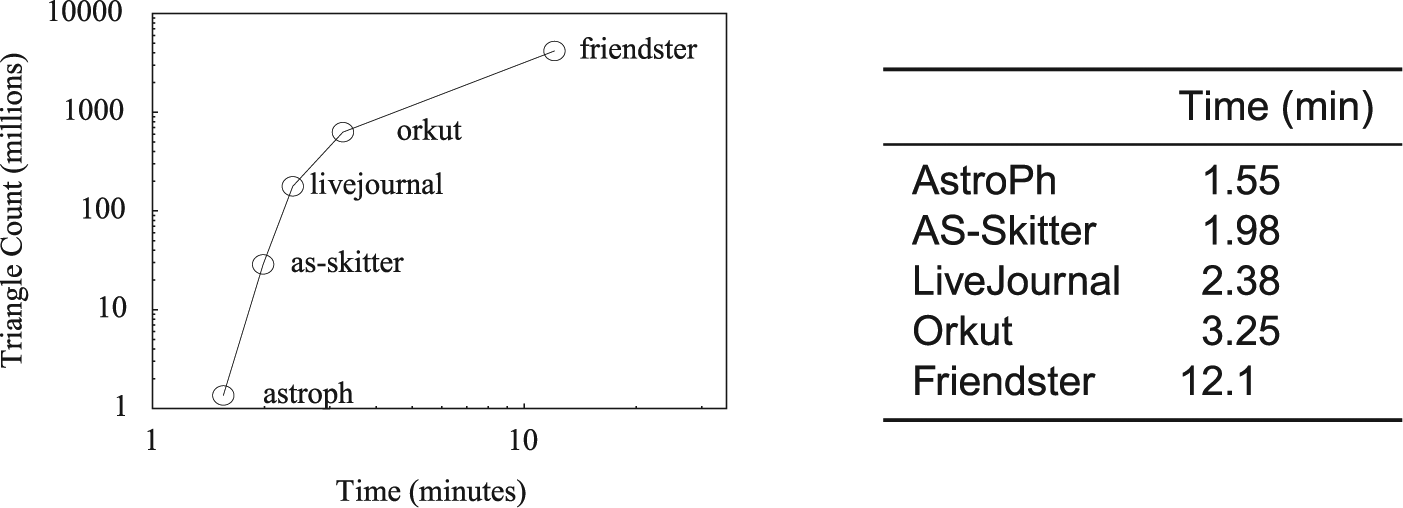
Triangle listing results for SNAP datasets.
Part 2
To test scalability, the Algorithm 1 was benchmarked on synthetically generated datasets using the Graph500 (www.graph500.org) benchmark parameters. Table 2 lists the sizes of the graphs and the triangle counts computed by the algorithm. The results of this benchmark are given in Figure 8. The top performance was listing 1.6 billion triangles per minute! This was achieved on the RMAT scale 30 graph with
Graph500 RMAT graphs (
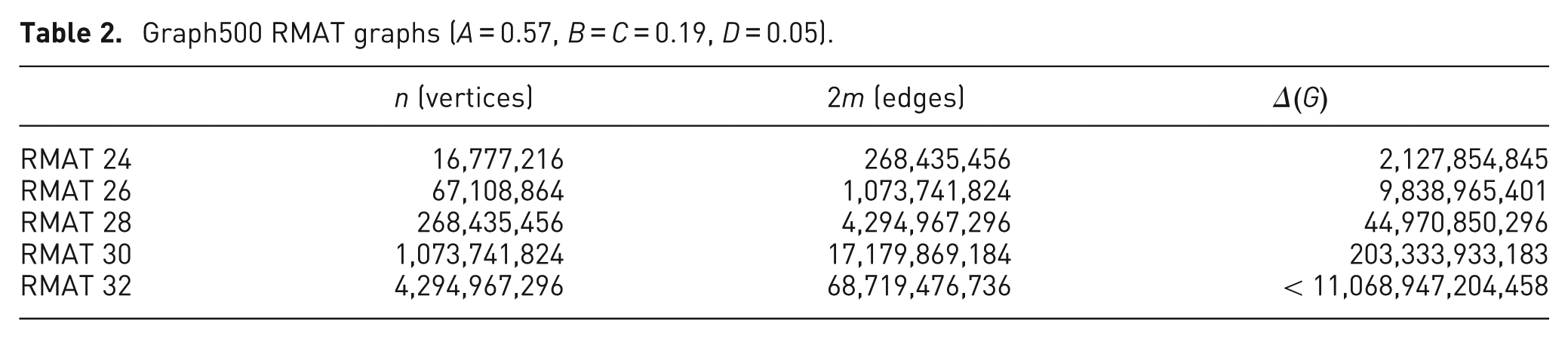
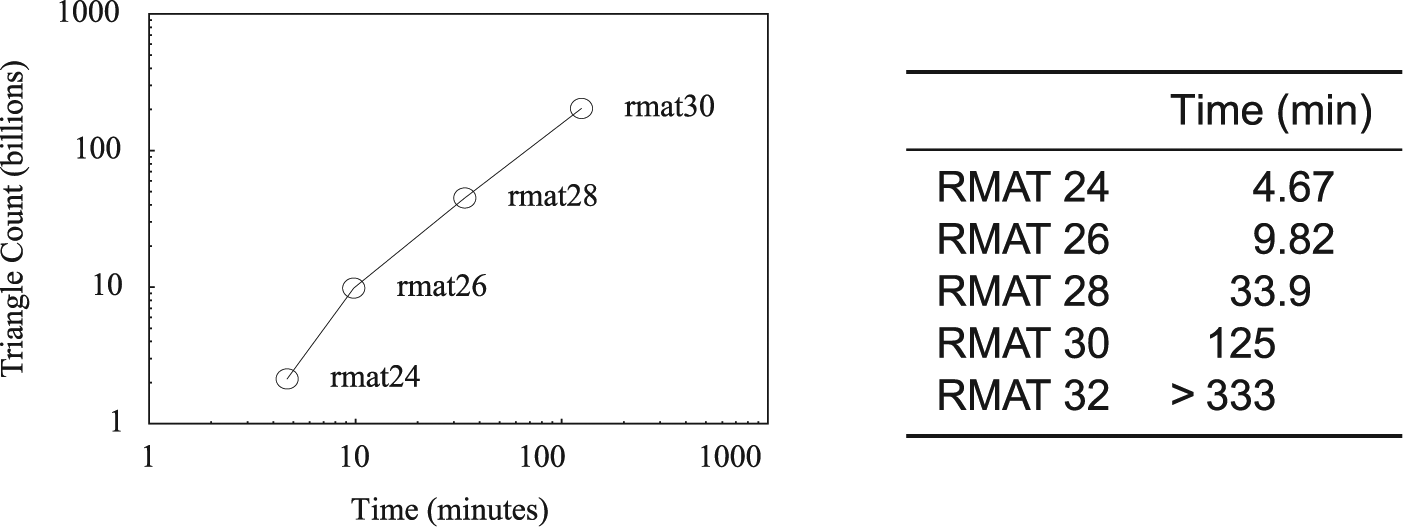
Triangle listing results for Graph500 datasets.
Visualizing trillions of triangles
Having established an algorithm capable of listing potentially trillions of triangles in a graph, the next step is to identify how to visualize the triangles. To begin, we need a scalable visual analytics platform but there are very few tools designed for large-scale graph exploration. The GreenHornet
26
visual analytics tool is designed for scalability and utilizes a hierarchical partitioning of the graph, exemplifying the importance of data representation. The data hierarchy in GreenHornet is a sequence of increasingly coarser partitions of the graph, generated by merging vertices of lowest degree to their neighbors. If this merging process also identified common neighbors of the merged vertices, it would identify triangles, performing what is widely-known as an edge iterator algorithm for counting or listing triangles where for every
Recent development is now encroaching on trillion-edge scale graph exploration, 27 which could admit the navigation of trillions of triangles in a graph. The multiscale layout algorithm of Wong et al. 27 is reported to be similar to the merging algorithm in GreenHornet and could therefore be extended in the aforementioned merging proposal of neighboring vertices to identify triangles. This will pave the way forward to Big Graph exploration not only of the input graph but also of the overlay of the graph analytic products with the input.
Footnotes
Acknowledgements
The author thanks David G Harris and Louis W Ibarra for their helpful comments.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.